梯度提升:
from sklearn.ensemble import GradientBoostingClassifier
gb=GradientBoostingClassifier(random_state=0)
gb.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb.score(x_test,y_test)))
Accuracy on training set:0.917
Accuracy on test set:0.792
我们可能是过拟合了。为了降低这种过拟合,我们可以通过限制最大深度或降低学习速率来进行更强的修剪:
gb1=GradientBoostingClassifier(random_state=0,max_depth=1)
gb1.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb1.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb1.score(x_test,y_test)))
Accuracy on training set:0.804
Accuracy on test set:0.781
gb2=GradientBoostingClassifier(random_state=0,learning_rate=0.01)
gb2.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb2.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb2.score(x_test,y_test)))
Accuracy on training set:0.802
Accuracy on test set:0.776
如我们所期望的,两种降低模型复杂度的方法都降低了训练集的准确度。可是测试集的泛化性能并没有提高。
尽管我们对这个模型的结果不是很满意,但我们还是希望通过特征重要度的可视化来对模型做更进一步的了解。
plot_feature_importances_diabetes(gb1)
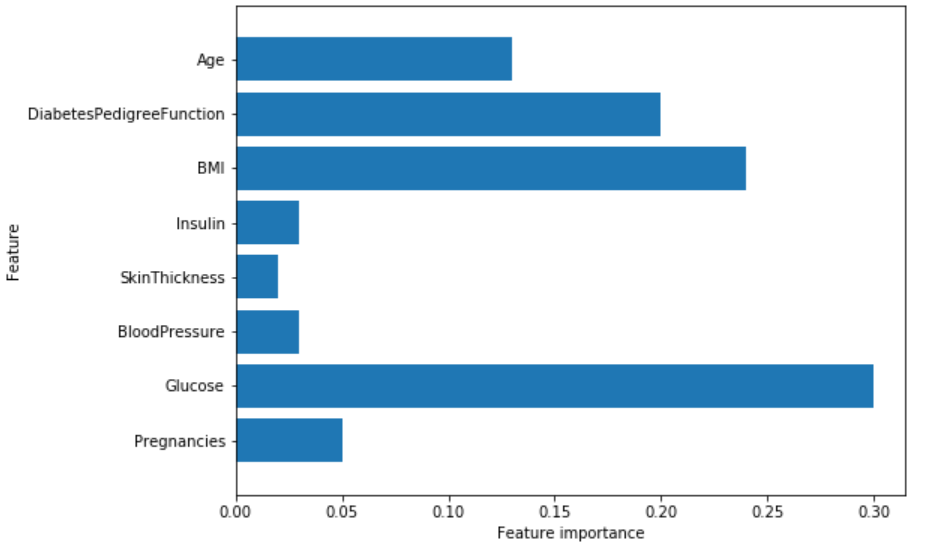
我们可以看到,梯度提升树的特征重要度与随机森林的特征重要度有点类似,同时它给这个模型的所有特征赋了重要度值。
支持向量机:
from sklearn.svm import SVC
svc=SVC()
svc.fit(x_train,y_train)
print("Accuracy on training set:{:.2f}".format(svc.score(x_train,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test,y_test)))
Accuracy on training set:1.00
Accuracy on test set:0.65
这个模型过拟合比较明显,虽然在训练集中有一个完美的表现,但是在测试集中仅仅有65%的准确度。
SVM要求所有的特征要在相似的度量范围内变化。我们需要重新调整各特征值尺度使其基本上在同一量表上。
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
x_train_scaled=scaler.fit_transform(x_train)
x_test_scaled=scaler.fit_transform(x_test)
svc=SVC()
svc.fit(x_train_scaled,y_train)
print("Accuracy on training set:{:.2f}".format(svc.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test_scaled,y_test)))
Accuracy on training set:0.77
Accuracy on test set:0.77
数据的度量标准化后效果大不同!现在我们的模型在训练集和测试集的结果非常相似,这其实是有一点过低拟合的,但总体而言还是更接近100%准确度的。这样来看,我们还可以试着提高C值或者gamma值来配适更复杂的模型。
svc=SVC(C=1000)
svc.fit(x_train_scaled,y_train)
print("Accuracy on training set:{:.2f}".format(svc.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test_scaled,y_test)))
Accuracy on training set:0.79
Accuracy on test set:0.80
提高了C值后,模型效果确实有一定提升,测试集准确度提至79.7%。
深度学习:
from sklearn.neural_network import MLPClassifier
mlp=MLPClassifier(random_state=42)
mlp.fit(x_train,y_train)
print("Accuracy on training set:{:.2f}".format(mlp.score(x_train,y_train)))
print("Accuracy on test set:{:.2f}".format(mlp.score(x_test,y_test)))
Accuracy on training set:0.71
Accuracy on test set:0.67
多层神经网络(MLP)的预测准确度并不如其他模型表现的好,这可能是数据的尺度不同造成的。深度学习算法同样也希望所有输入的特征在同一尺度范围内变化。理想情况下,是均值为0,方差为1。所以,我们必须重新标准化我们的数据,以便能够满足这些需求。
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train_scaled=scaler.fit_transform(x_train)
x_test_scaled=scaler.fit_transform(x_test)
mlp=MLPClassifier(random_state=0)
mlp.fit(x_train_scaled,y_train)
print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.823
Accuracy on test set:0.802
让我们增加迭代次数:
mlp=MLPClassifier(max_iter=1000,random_state=0)
mlp.fit(x_train_scaled,y_train)
print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.877
Accuracy on test set:0.755
增加迭代次数仅仅提升了训练集的性能,而对测试集没有效果。
让我们调高alpha参数并且加强权重的正则化。
mlp=MLPClassifier(max_iter=1000,alpha=1,random_state=0)
mlp.fit(x_train_scaled,y_train)
print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.795
Accuracy on test set:0.792
这个结果是好的,但我们无法更进一步提升测试集准确度。因此,到目前为止我们最好的模型是在数据标准化后的默认参数深度学习模型。最后,我们绘制了一个在糖尿病数据集上学习的神经网络的第一层权重热图。
plt.figure(figsize=(20,5))
plt.imshow(mlp.coefs_[0],interpolation='none',cmap='viridis')
plt.yticks(range(8),diabetes_features)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature")
plt.colorbar()
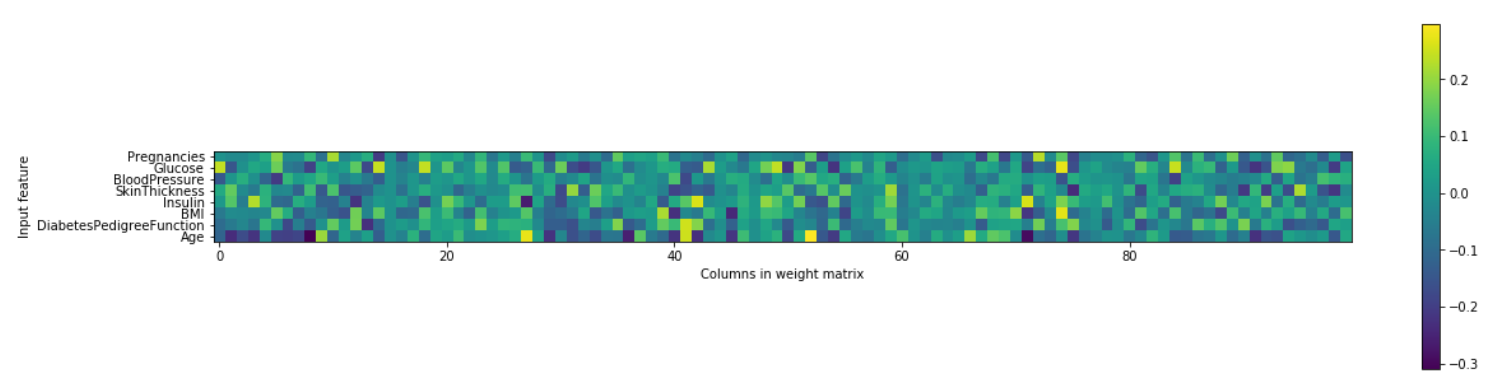
从这个热度图中,快速指出哪个或哪些特征的权重较高或较低是不容易的。
设置正确的参数非常重要:
本文我们练习了很多种不同的机器学习模型来进行分类和回归,了解了它们的优缺点是什么,以及如何控制其模型复杂度。我们同样看到,对于许多算法来说,设置正确的参数对于性能良好是非常重要的。