目录
1. 作者介绍
余成伟,男,西安工程大学电子信息学院,2022级研究生
研究方向:机器视觉与人工智能
电子邮件:[email protected]
张思怡,女,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:[email protected]
2. 投票回归器VotingRegressor简介
2.1 VotingRegressor介绍
VotingRegressor是一种用于回归任务的集合学习方法,它结合了多个单独回归模型的预测结果。它源于集合学习的概念,其目的是通过结合不同模型的优势来提高预测性能。VotingRegressor算法允许将不同的回归模型,如线性回归、决策树、随机森林或支持向量回归,组合成一个集合模型。通过利用各个模型的多样性和它们的集体预测能力,VotingRegressor旨在提供比单独使用任何单一模型更准确和稳健的预测结果。值得注意的是,VotingRegressor算法的具体实现和细节可能会因使用的软件库或框架而不同。
2.2 VotingRegressor算法遵循以下关键原则:
①.在VotingRegressor中,集合中的每个单独的回归模型都会对给定的输入进行预测。最终的预测结果是通过汇总各个预测结果而得到的。汇总可以通过取预测的平均数(平均值)或加权平均数来进行。
②. VotingRegressor通常使用等额或加权投票方案来确定每个单独模型的预测的重要性。在等额投票的情况下,每个模型的预测具有相同的权重。在加权投票中,每个模型的预测根据其估计的性能或可靠性被赋予特定的权重。
③.由于VotingRegressor是为回归任务设计的,单个预测的聚合考虑了目标变量的连续性质。最终的预测是一个连续值,代表了对目标变量的汇总估计。
3. 使用投票回归器VotingRegressor对糖尿病数据集进行回归预测实验过程
3.1 代码流程介绍
①.导入所需的库,包括用于数据处理的pandas,用于回归模型的scikit-learn模块,以及用于可视化的matplotlib。
②.使用sklearn.datasets中的load_diabetes()函数加载糖尿病数据集。将特征分配给X,将目标变量分配给y。
③. 使用sklearn.model_selection中的train_test_split()函数将数据集分成训练和测试集。指定测试大小为0.2(数据的20%),并设置一个随机状态以保证可重复性。
④. 创建三个单独的回归模型:线性回归、随机森林回归和SVR(空间自回归模型)。
⑤. 创建一个VotingRegressor实例,并传递一个包含名称和相应回归模型实例的图元列表。
⑥. 通过调用voting_model对象的fit()方法,使用训练数据训练集合模型。
⑦.使用voting_model的predict()方法对测试集进行预测。
⑧. 使用sklearn.metrics中的mean_squared_error()和r2_score()函数,通过计算平均误差(MSE)和R-squared分数来评估模型。
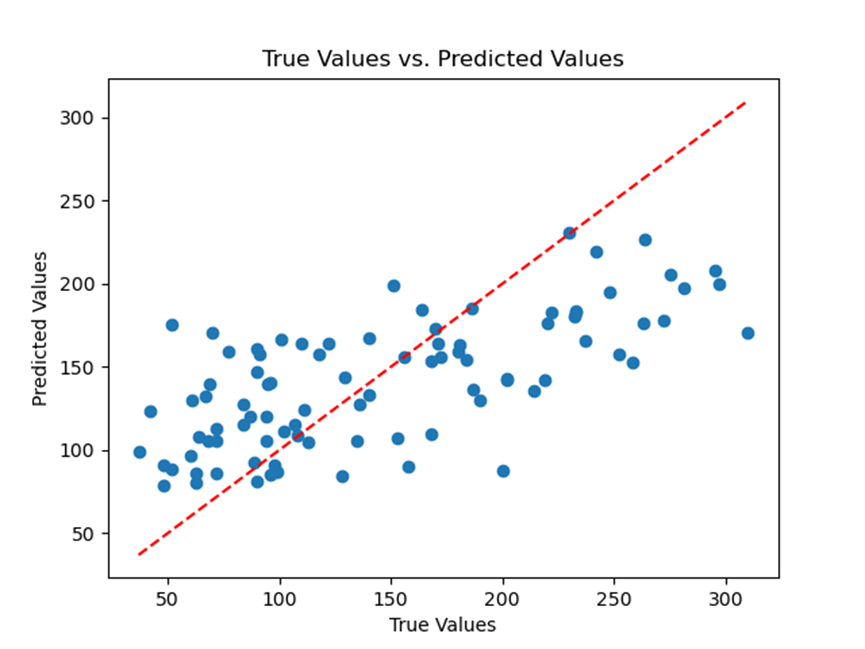
⑨. 通过使用plt.scatter()创建一个散点图,将预测值与真实值进行可视化。使用plt.plot()为完美预测添加一条参考线。给坐标轴贴上标签,并为图提供一个标题。使用plt.show()显示图。
⑩. 打印计算出的MSE和R-squared分数。
这段代码展示了VotingRegressor如何结合三种不同的回归模型的预测,并为糖尿病数据集提供一个集合预测。散点图可视化了真实值和预测值之间的关系。
3.2 完整代码
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.ensemble import VotingRegressor
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
# Load the Diabetes dataset
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create individual regression models
model1 = LinearRegression()
model2 = RandomForestRegressor()
model3 = SVR()
# Create the VotingRegressor with the individual models
voting_model = VotingRegressor([('lr', model1), ('rf', model2), ('svm', model3)])
# Train the ensemble model
voting_model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = voting_model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Plot the predicted values vs. true values
plt.scatter(y_test, y_pred)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r--')
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
plt.title('True Values vs. Predicted Values')
plt.show()
print("Mean Squared Error:", mse)
print("R-squared Score:", r2)
3.3 实验结果