糖尿病临床试验 数据分析
一、项目背景
糖尿病(尤其是2型糖尿病)算得上是21世纪最大的流行病,在我国更是情况堪忧[^footnote]。20世纪20年代之前,人们闻“糖”色变,因为无法治疗,患病就相当于慢性死亡。这种病会让血糖升高,伴随的症状有异常口渴、尿频、容易疲劳,严重的并发症有中风、失明、截肢、肾衰竭、甚至心肌梗塞。好在1920s,一种能降低血糖的胰腺分泌物 胰岛素(insulin)被 Frederick Banting 发现,他也因此获得1923年的诺贝尔医学和生理学奖。

1.1 胰岛素工作原理
我们吃下去的食物大部分转化为葡萄糖(glucose),为身体提供能量。位于胃(stomach)附近的胰腺(pancreas),会产生一种叫做胰岛素(insulin)的激素(hormone),这种激素能促进葡萄糖被人体细胞吸收。如果一个得了糖尿病,就意味着无法分泌足够的胰岛素(insulin),或者胰岛素不能发挥正常功能,血糖便由此增多。
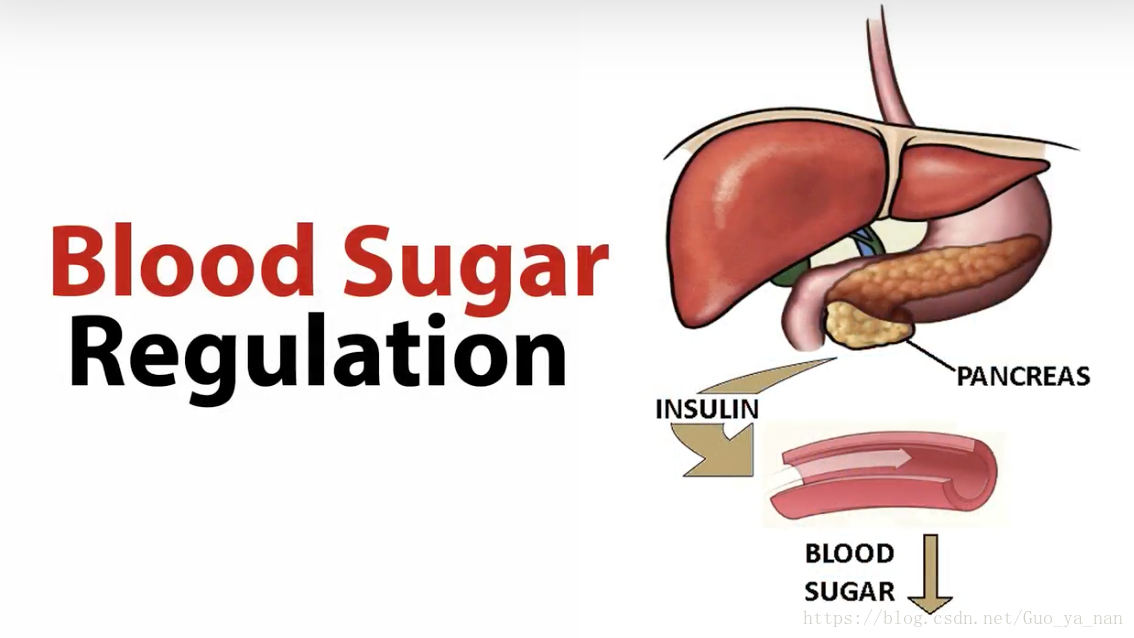
虽然胰岛素不能治愈糖尿病,但仍然是医学史上最大的重大发现之一,挽救了很多人的生命。不过当时胰岛素默认是针管注射的,一天要注射多次,现在依然如此;但这不方便也不舒服,如果能口服胰岛素就好了,比如制成药片或胶囊,随身携带多方便。
所以,口服胰岛素[^footnote](oral insulin)一直以来都是活跃的研究领域。然而,最大的拦路石在于胰岛素本质上是一种蛋白质,无法通过厚厚的胃黏膜。
1.2 临床试验及其指标
在这个背景下,我们将接触一份 II 期临床试验数据,涉及一种新型口服胰岛素叫做 Auralin[^footnote]。Auralin 的研究员认为他们研发的胶囊能解决胃黏膜问题。
II 期试验会对药品的功效和剂量反应进行测试,还会找出药品常见的短期副作用(也即不良反应),通常涉及数百位患者。
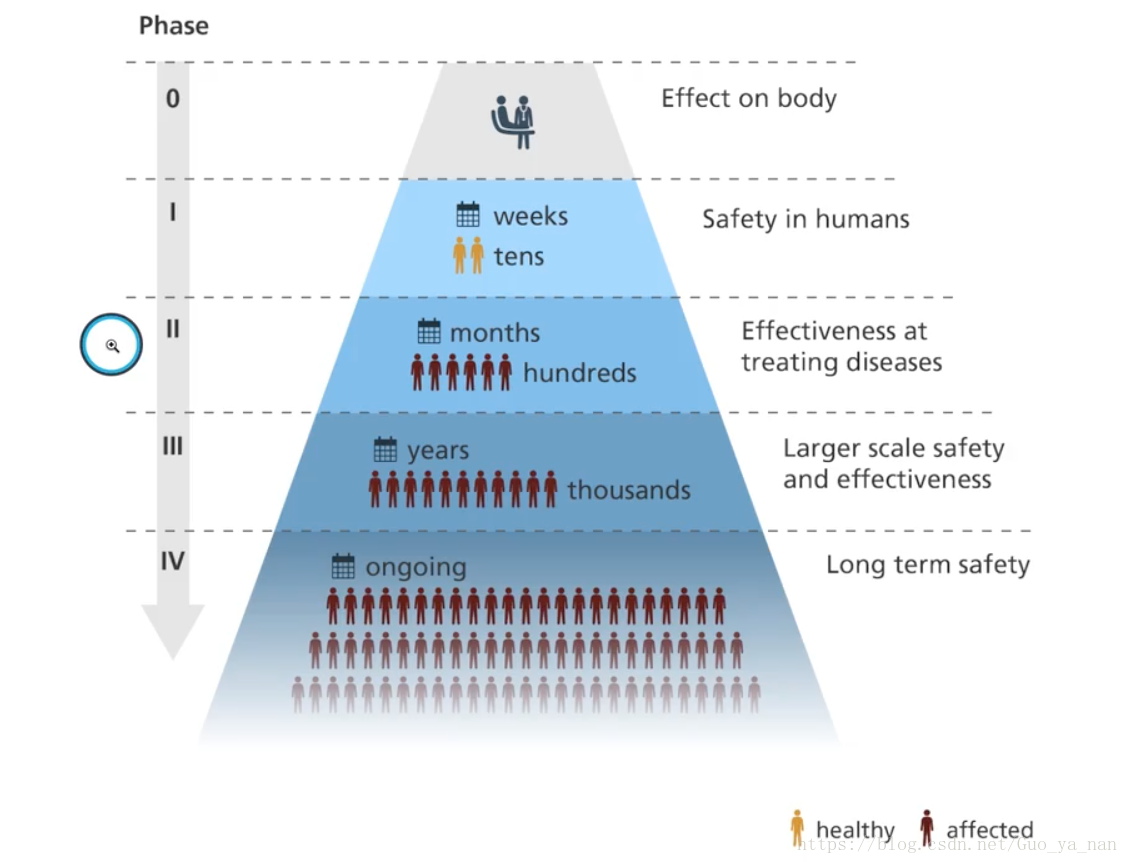
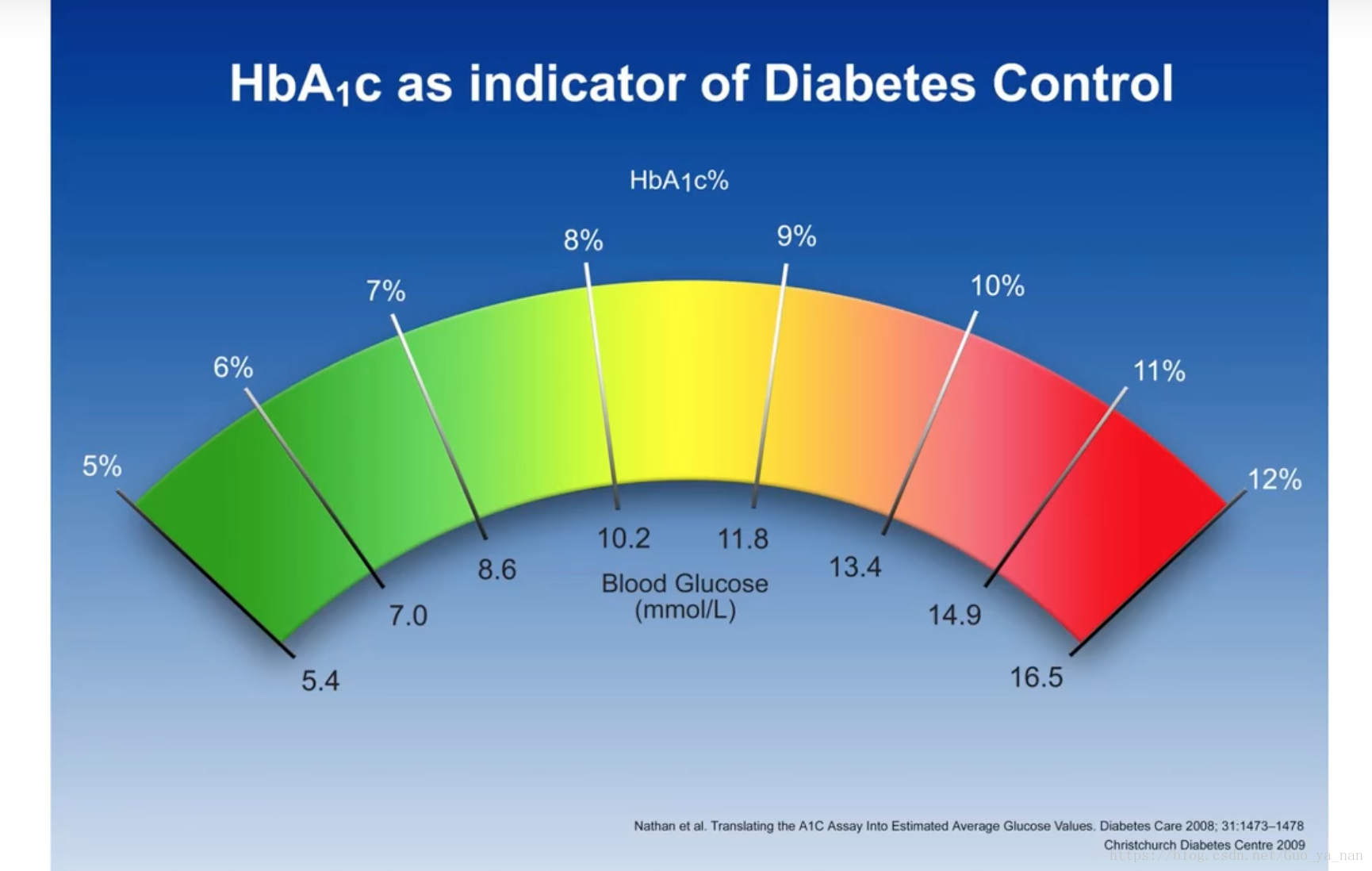
在该试验中,我们有350名患者,分为两组,进行双盲试验[^footnote]。其中175人服用 Auralin 进行治疗,另外一半人则用市面上流行的注射型胰岛素 Novodra 进行治疗。通过比较两种药物的关键指标(key metrics),可以判断 Auralin 是否有效。最重要的指标就是 HbA1c 水平。HbA1c 是血液中的一种物质(糖化血红蛋白),能够衡量过去几个月来人体血糖水平的控制情况,正常值为4%-6%。如果 Auralin 能够让 HbA1c 水平降到跟注射型胰岛素 Novodra 相似的程度,就能表明 Auralin 是有效的,能够提高患者的生活质量。(比如:能引起0.4%的下降就可以认为是成功的)
对数据集的几点说明:
- Auralin 和 Novodra 都不是真的胰岛素产品,是模拟数据;
- 为了合理性,数据集是在咨询专业医生的情况下建立的;
- 由官方授意,密切模拟了真正的 新型吸入胰岛素 Afrezza 的临床试验;
- 模拟了 医疗保健数据中的真实常见数据质量问题;
- 患者信息是使用 虚假姓名生成器 生成。
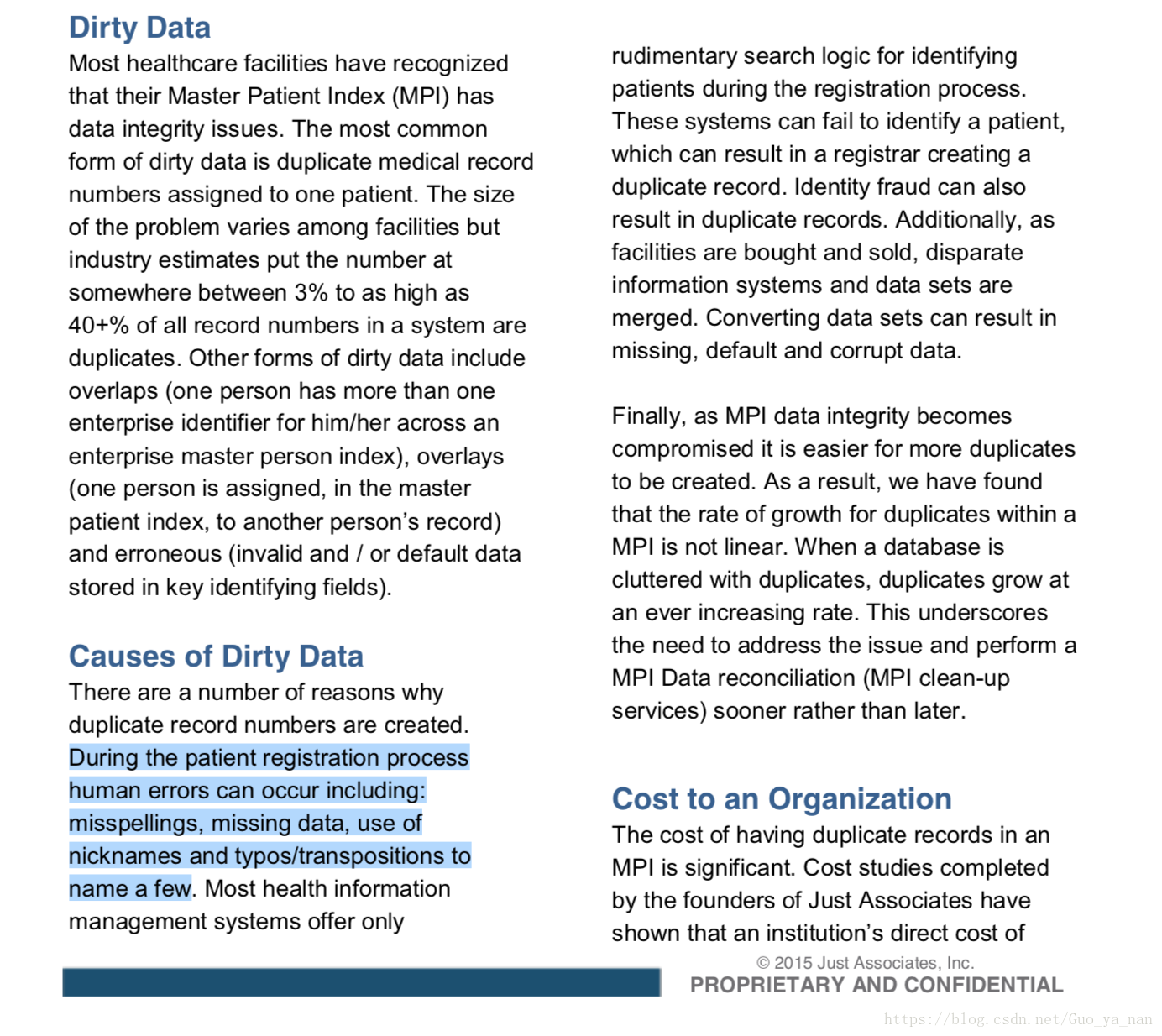
1.3 医疗数据 常见问题及原因
医疗数据中经常存在问题:数据冗余、数据缺失、数据不准确等。在我们的临床试验数据也存在以上问题。(下面是造成脏数据的原因截图,完整档案见此)
二、数据评估
Unclean data 存在两类问题:数据质量低,数据不整洁。可以从这两方面分别进行评估。(详细见此笔记)
2.1 质量评估
为了尽可能多得练习,这里先用目测的方法进行数据评估,再用编程方法进行数据评估。
目测评估
导入数据:
import pandas as pd
patients = pd.read_csv('patients.csv')
treatments = pd.read_csv('treatments.csv')
adverse_reactions = pd.read_csv('adverse_reactions.csv')查看数据:
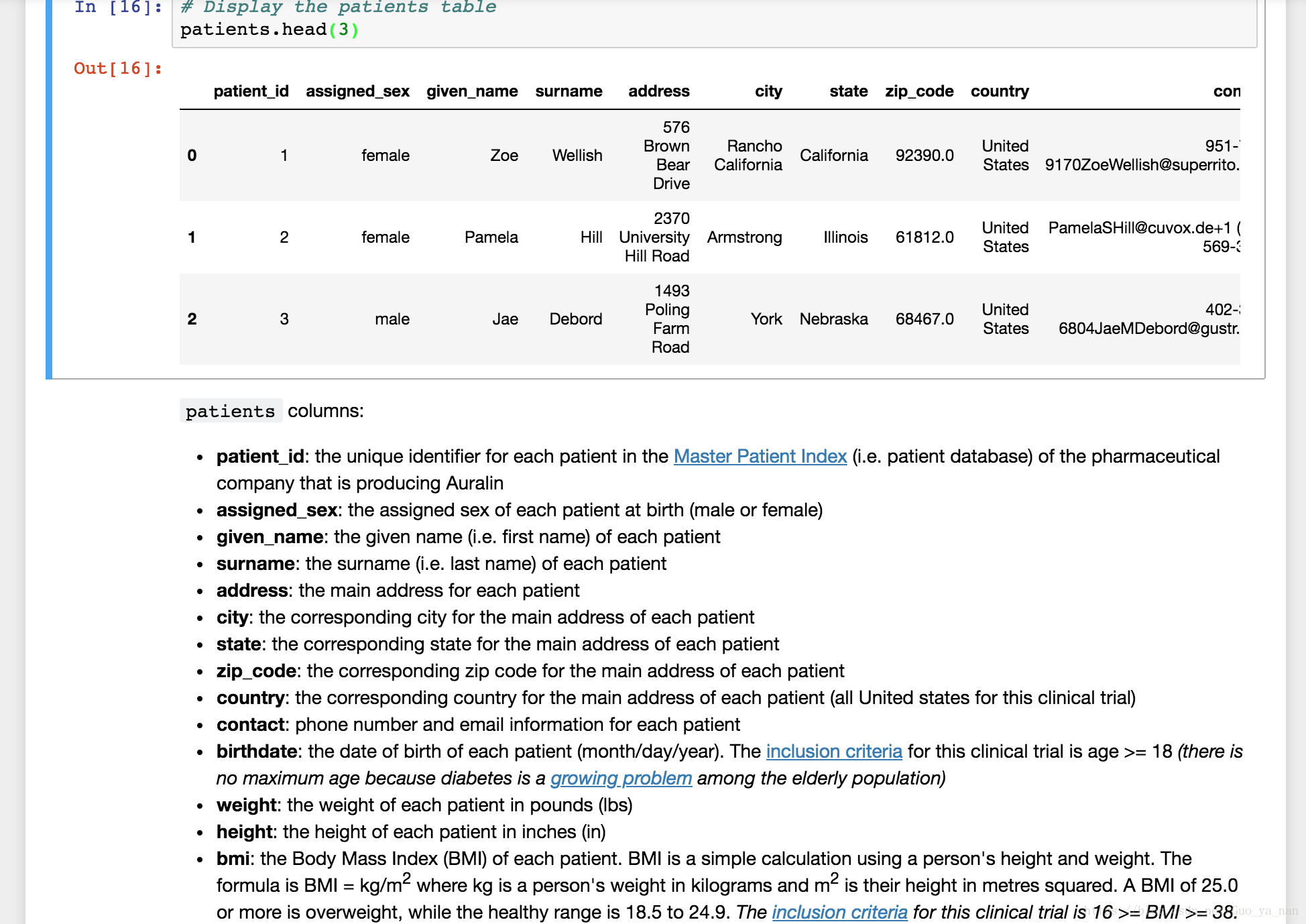
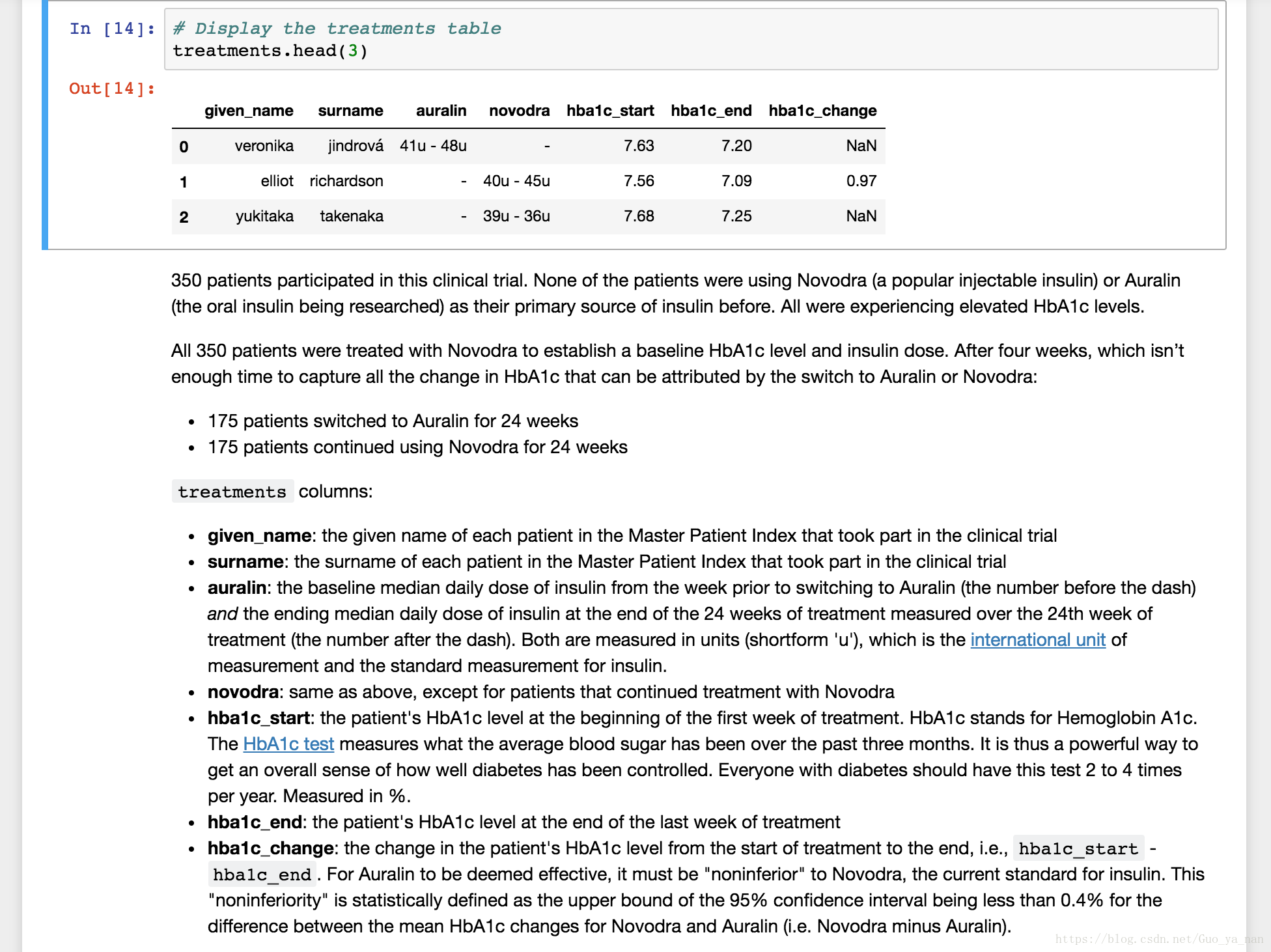
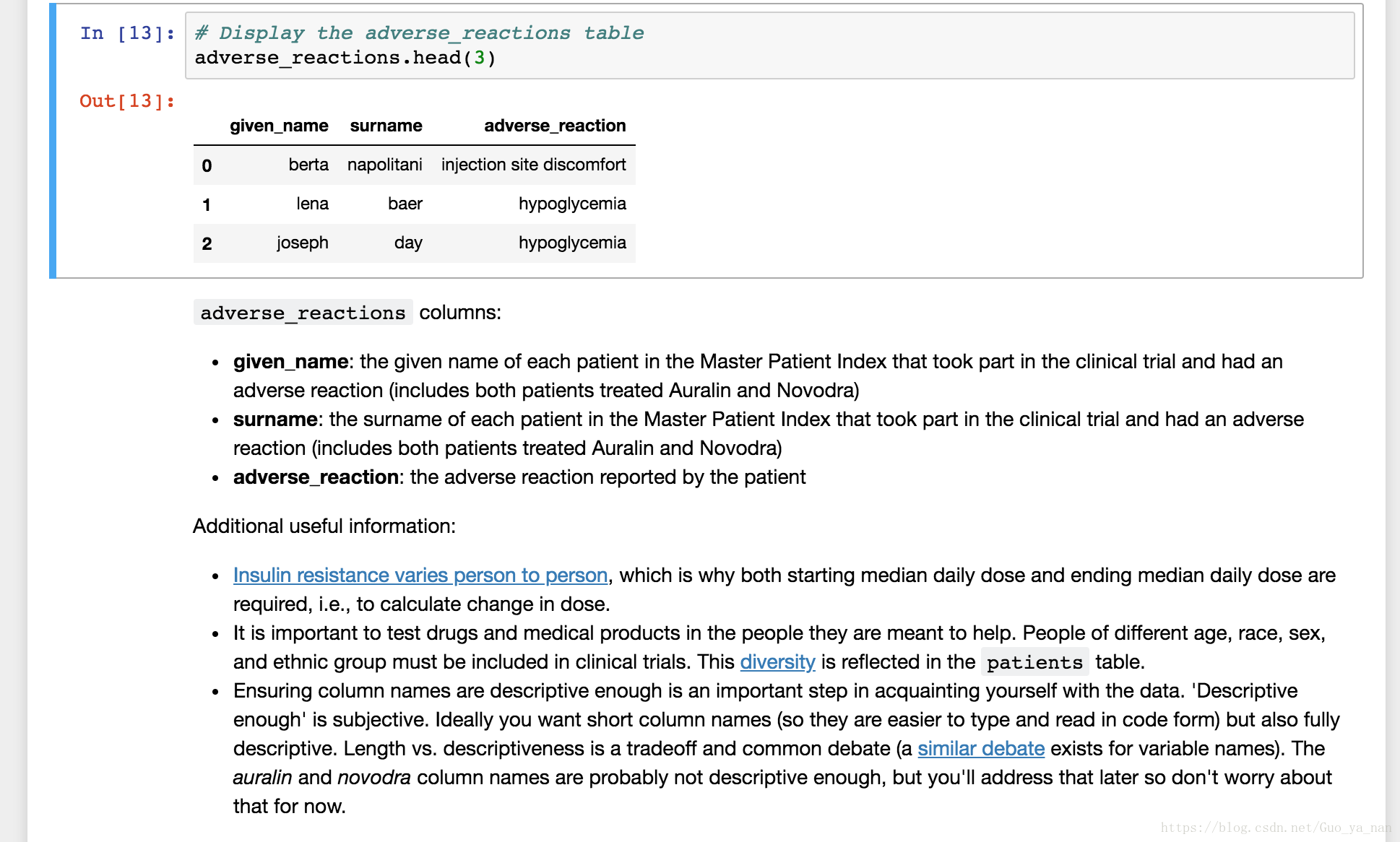
问题记录:

编程评估
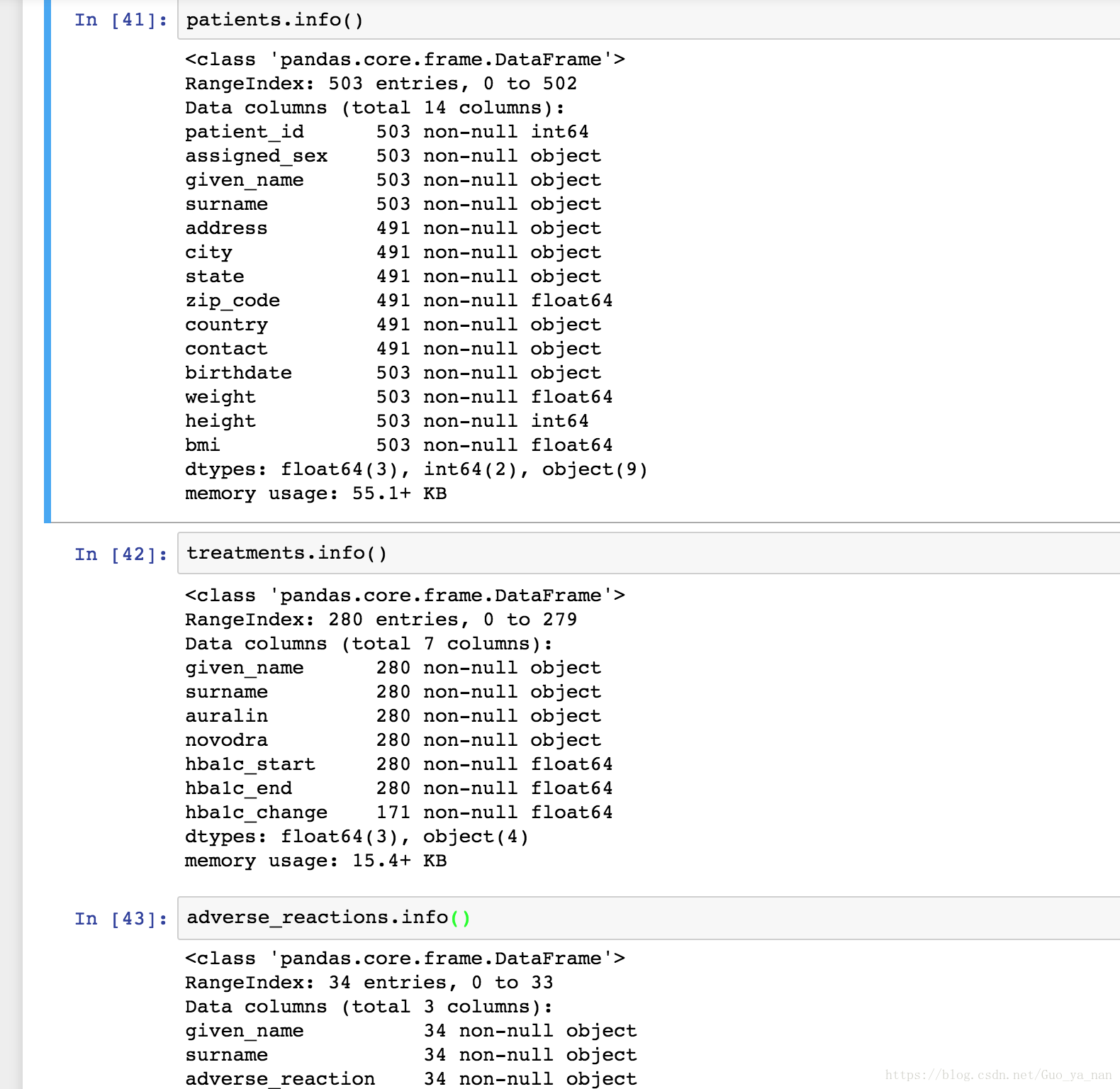
编程评估要用到代码,而不是对整个数据进行浏览。就 pandas 而言,它的很多函数和方法都可以用来检查数据的质量和整洁度,比如 .sample()、.head()、.tail()、.info()、.describe()、.value_counts() 等。
对 patients 进行数据评估:
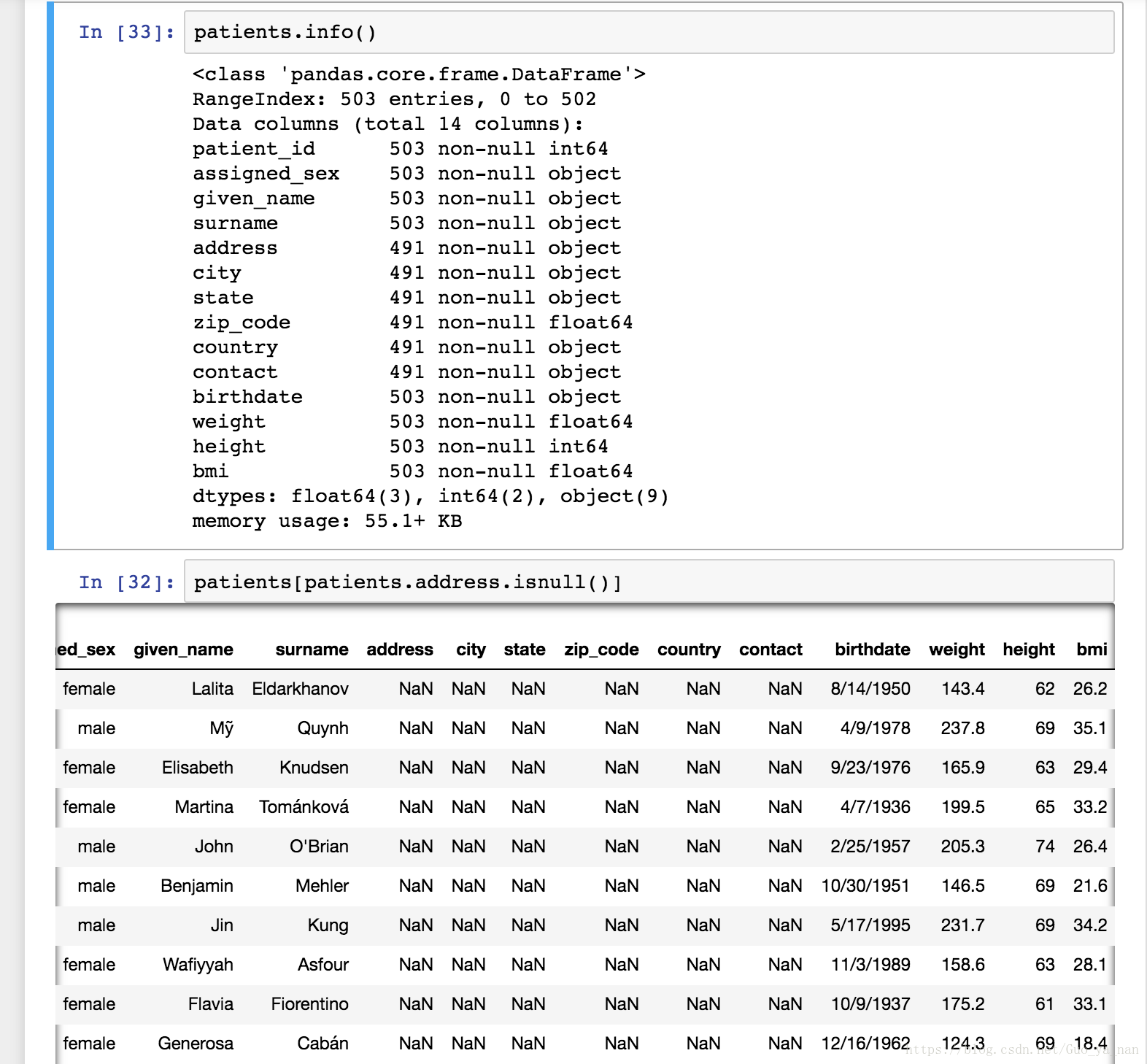
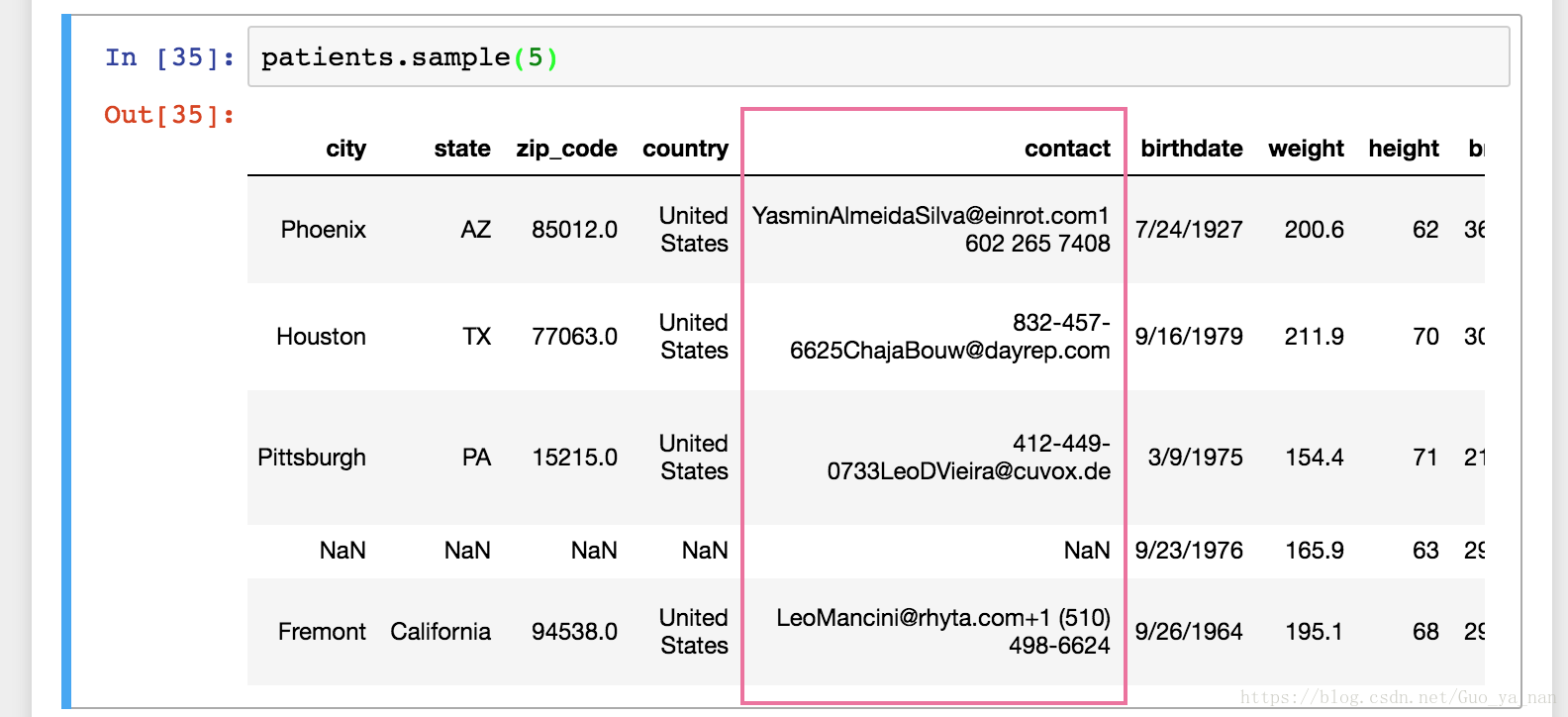
问题记录:

对 treatments 进行数据评估:
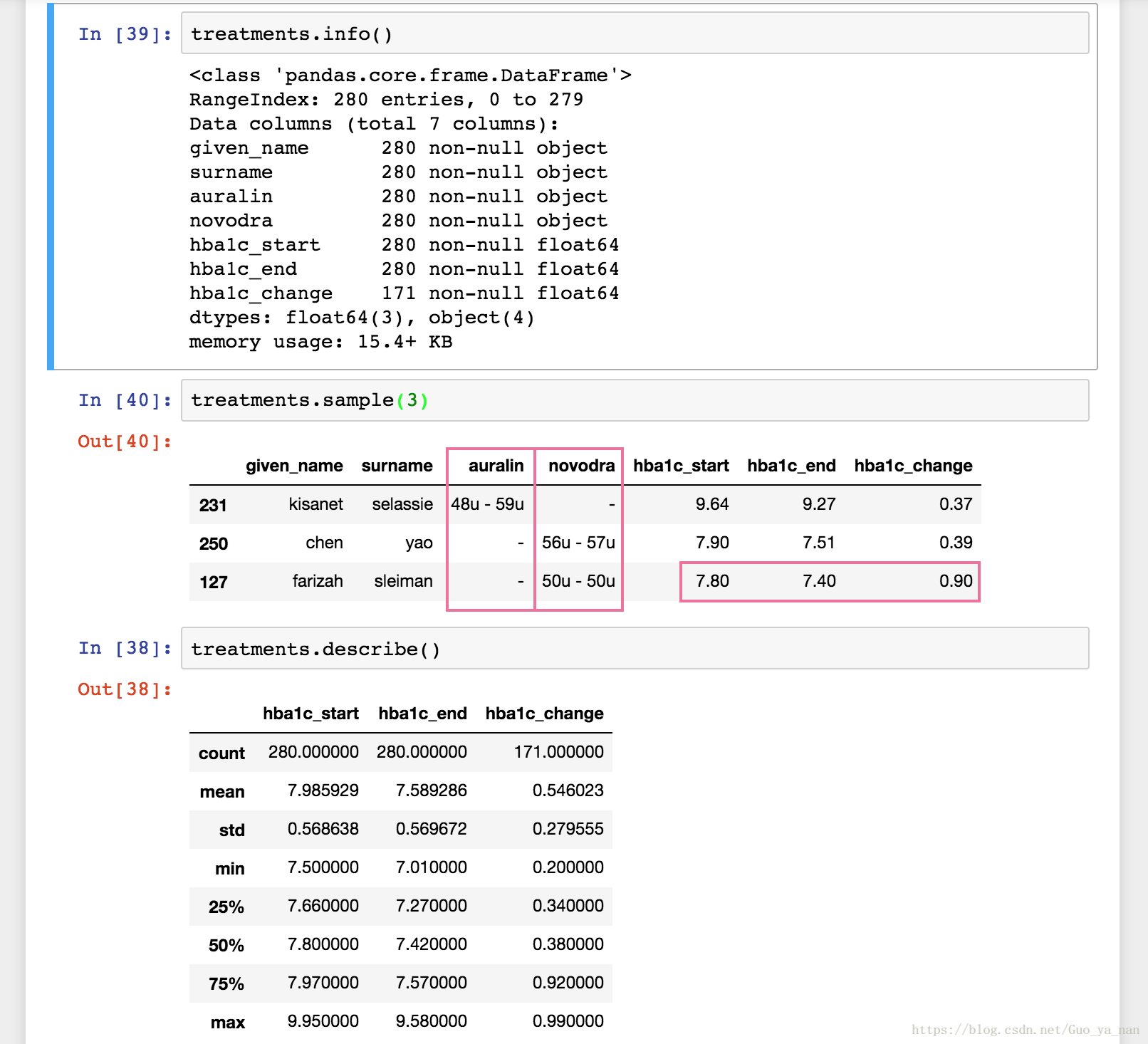
问题记录:

Q: 以上两个表中都存在数据类型错误的问题,为什么数据类型很重呢?
A: 因为在pandas中,可以对分类变量,数值变量,时间变量等进行特殊的计算和总结。比如说patients中的birthdate必须是日期时间类型,这样才使用时序或日期时间功能,方便得进行年龄计算。
继续进行编程评估:
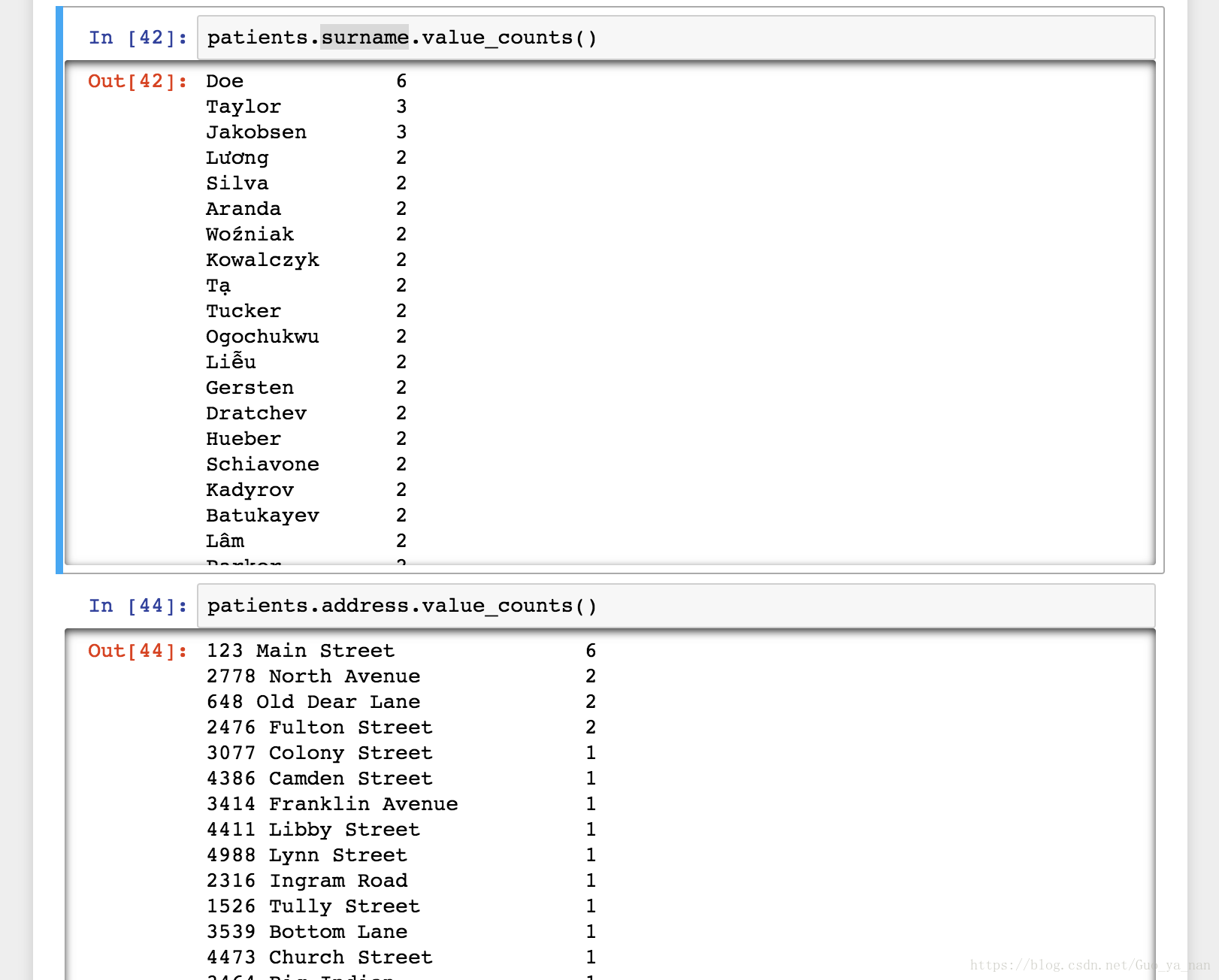
.value_counts()统计的是不同值的个数,不包括NaN。
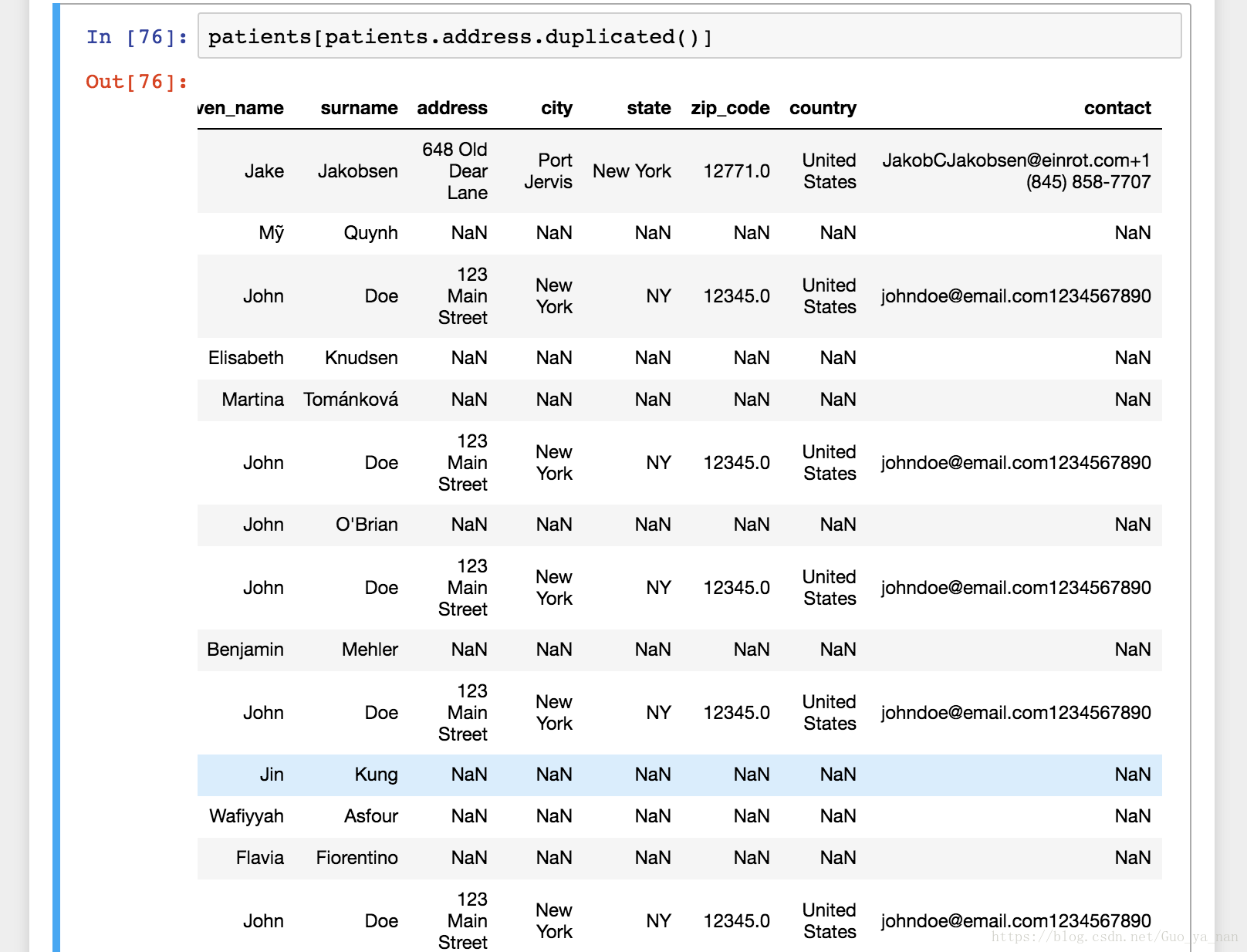
以上姓氏中‘Doe’有6个,地址中‘123 main street’也有6个,很可能是重复,用 .duplicated() 方法筛选重复地址,发现关于‘Doe’的5条数据除 patient_id 外,其他信息都一样,现实中不可能存在这样的情况。这是一个有效性问题(validity issue)。类似的重复情况还有:
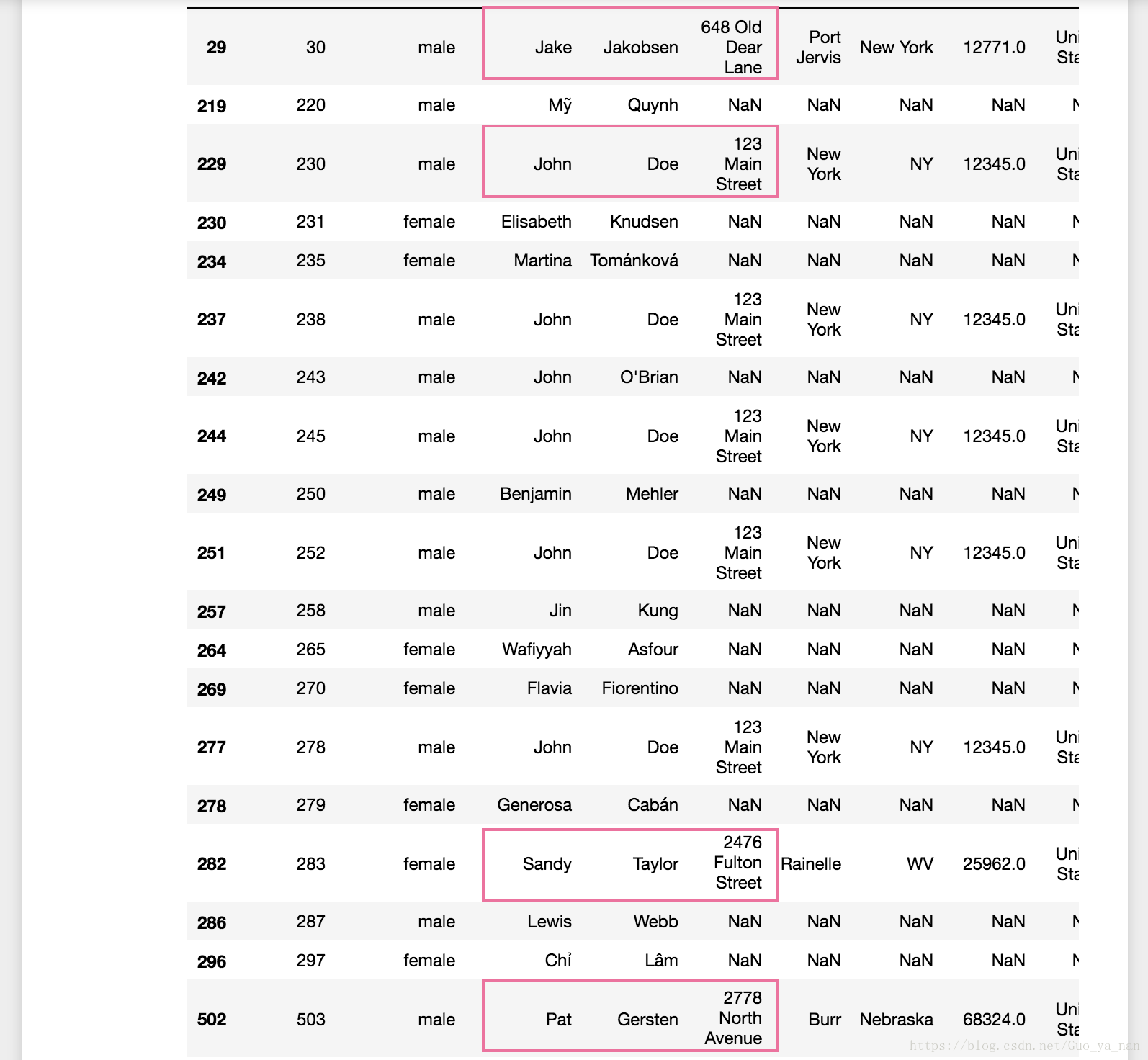

问题记录:

继续进行编程评估:

一般人的体重不太可能是48.8磅(1 lb = 0.4536 kg),所以该数据不准确,甚至是无效的,即存在有效性问题;但是如果深入思考的话,会发现情况并非如此,其实是一致性问题。48.8的单位是公斤,而不是磅。下面按照48.8kg来计算其 bmi(身体质量指数),验证一下:
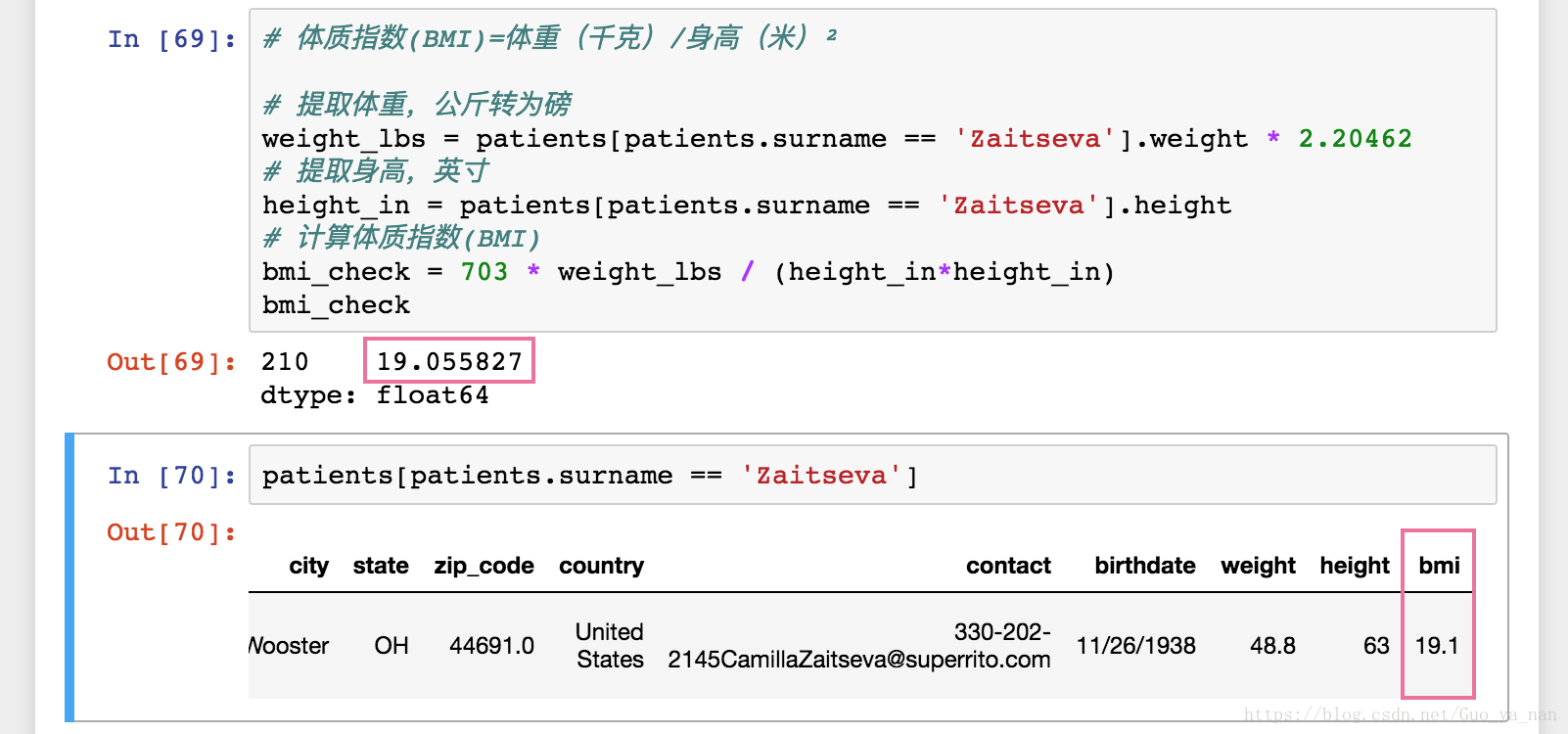
四舍五入后与记录中的 bmi 值一样,所以这条记录的体重单位有误,应该 kg。这属于一致性问题(consistency issue)。
进行最后的编程评估:
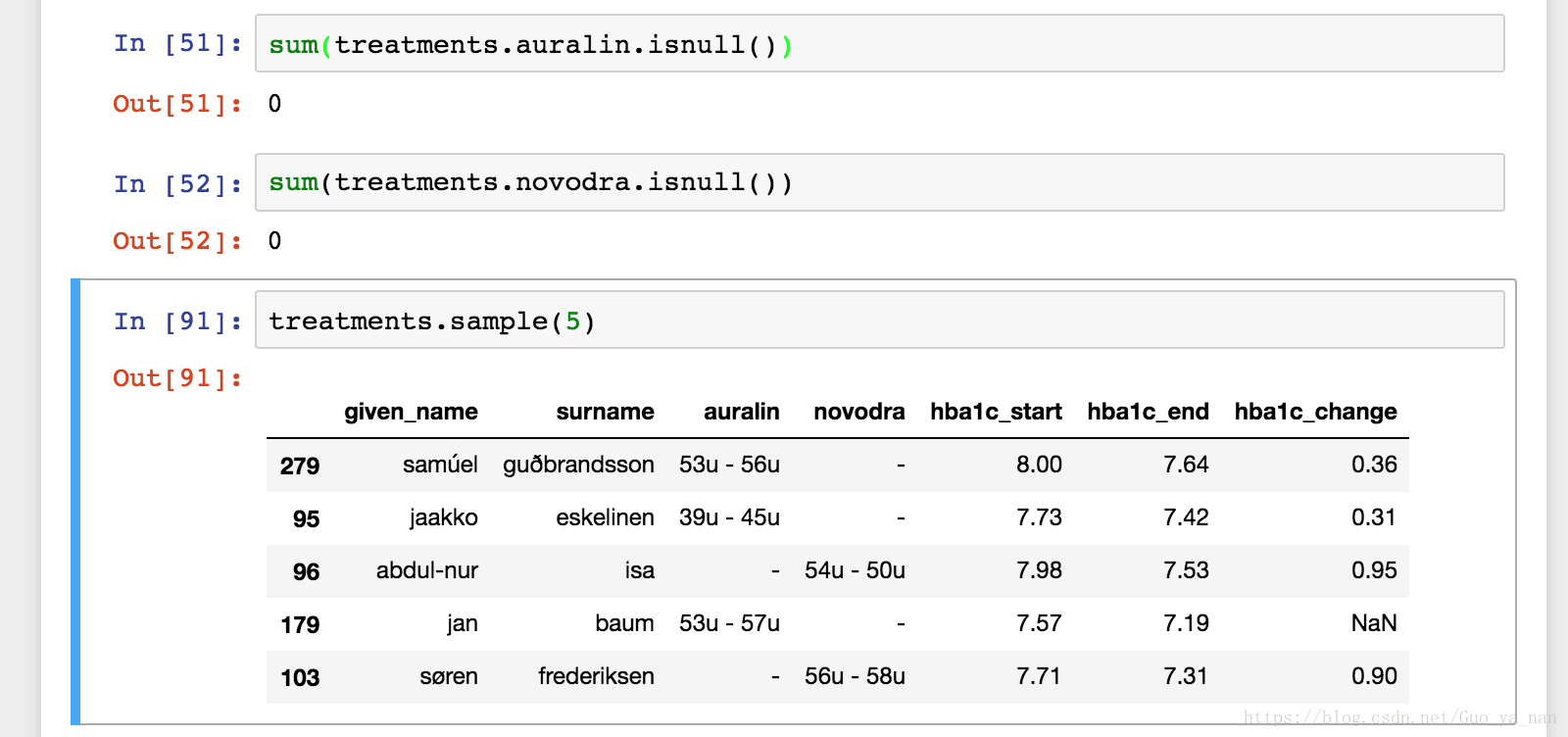
计算auralin和novodra的空值个数,结果均为0,但实际上存在空值;这是一种常见的问题,将空值存储为破折号、斜杠、‘none’等,而不存储为真正的空值。这是一个有效性问题(validity issue),因为空值应该为空值,而不是文本。
问题记录:

2.2 整洁度评估
何为整洁数据:
1. Each variable forms a column
2. Each observartion forms a row
3. Each type of observational unit form a table
by Hadley Wickham
按照以上定义对数据整洁度进行评估:
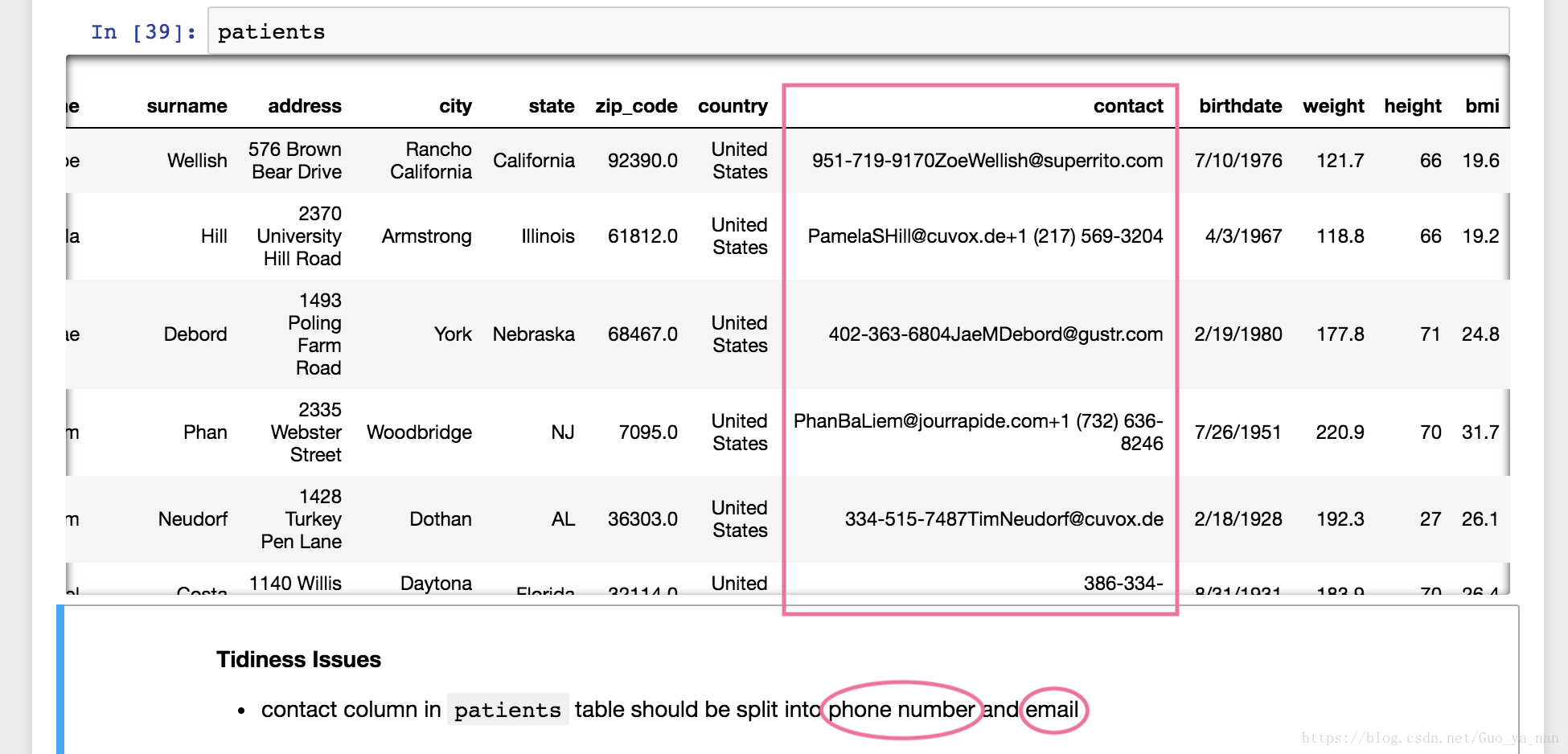
上图 patients 表中 contact 列的问题在于,一个列中存储了两个变量:电话号码,email地址。
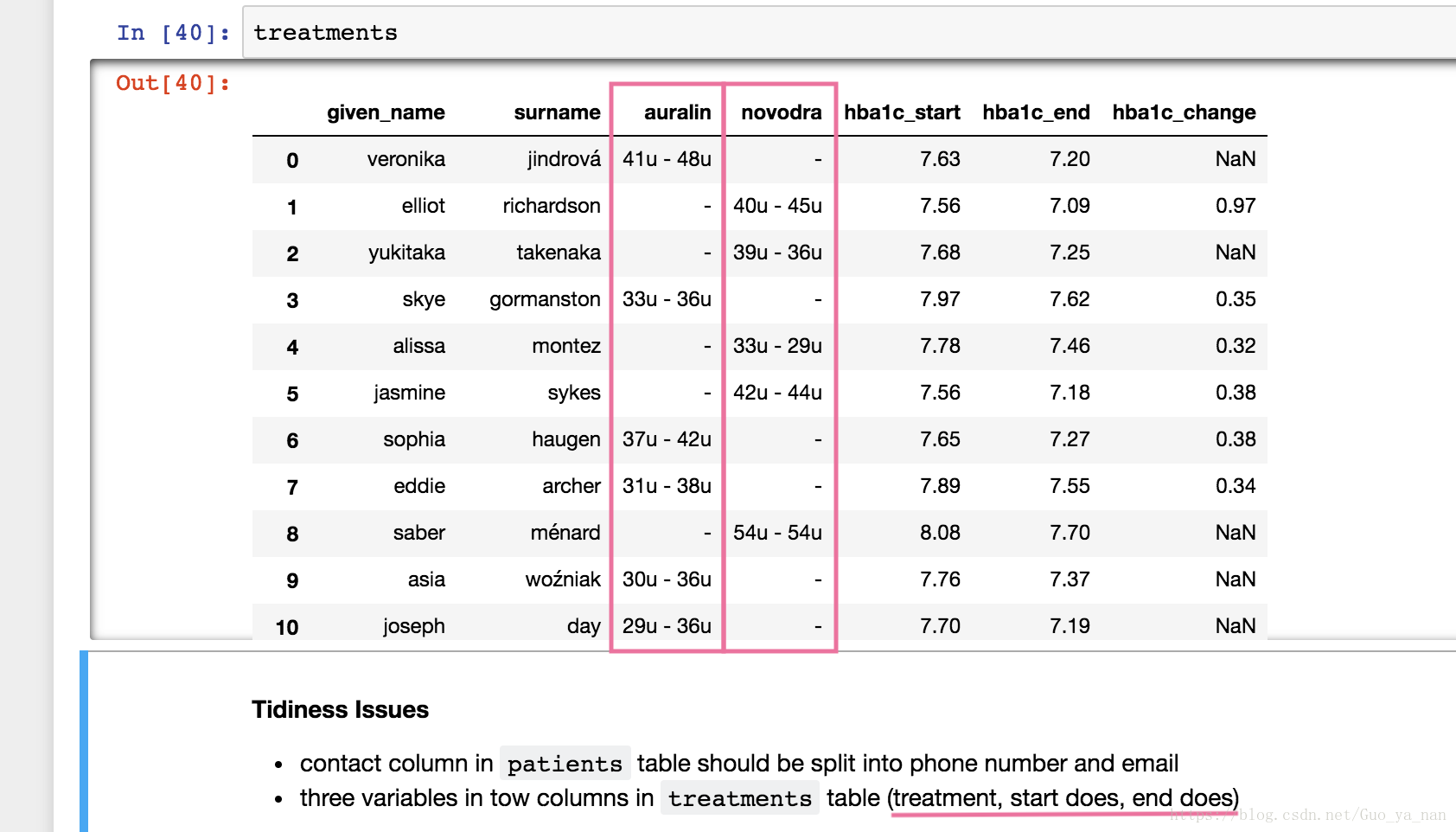
上图 treatments 表的问题在于,auralin 列和 novodra 列的名称其实是变量,不应用作列标签,同时初始剂量、结束剂量应该为两个变量。
进行最后一项评估,确定观察单元的个数:
这里体现了编程评估的优势:不必在不同table或tab之间切换,也不必滚动浏览。
上图的问题在于,该试验的观察单元应该为2张表,而非3张表。病人信息为一张表,药物用量及不良反应为一张表。所以,patients表保持不变,treatments表和adverse_reactions表应该合二为一。
编程查看重复的列:
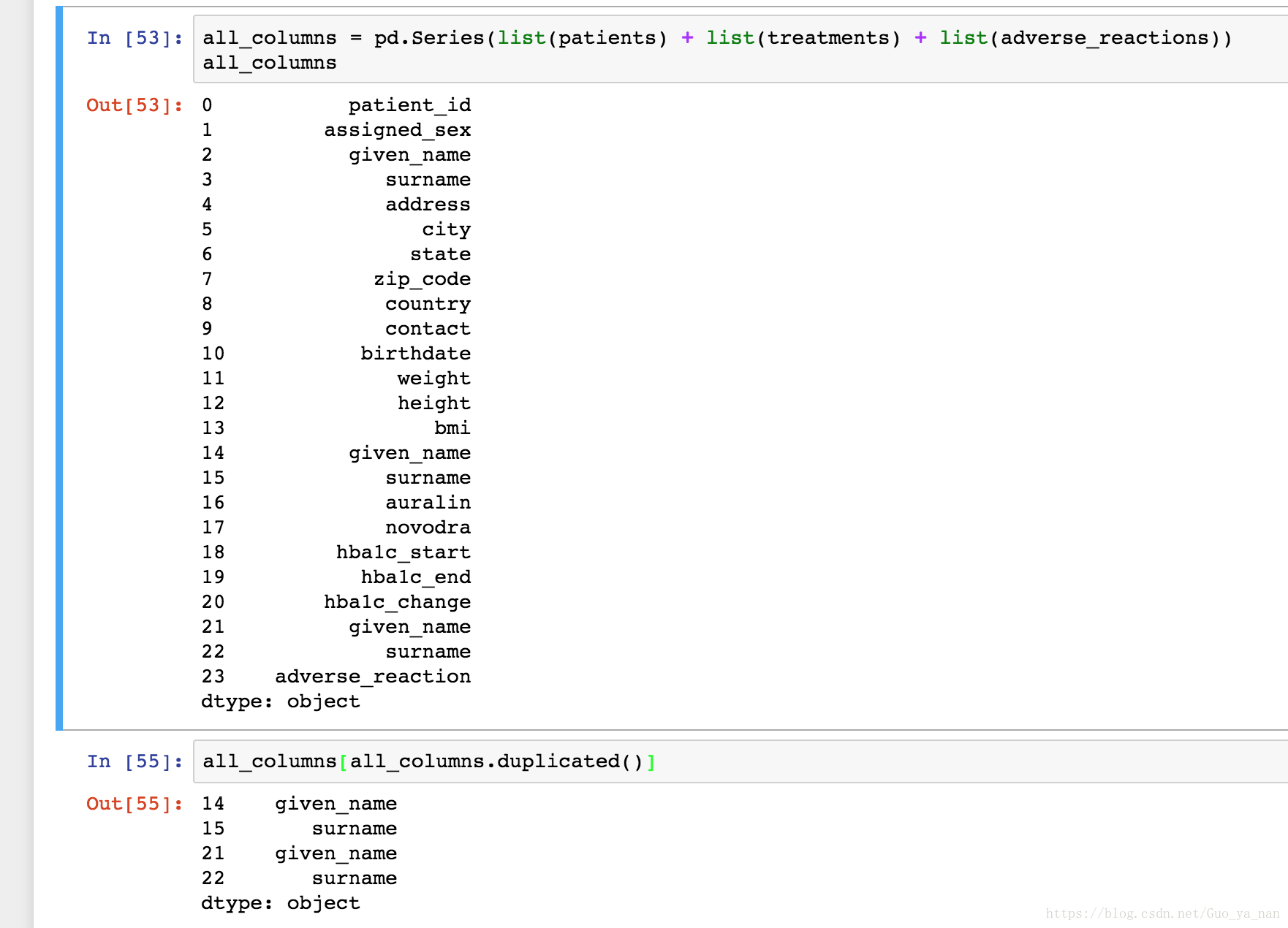
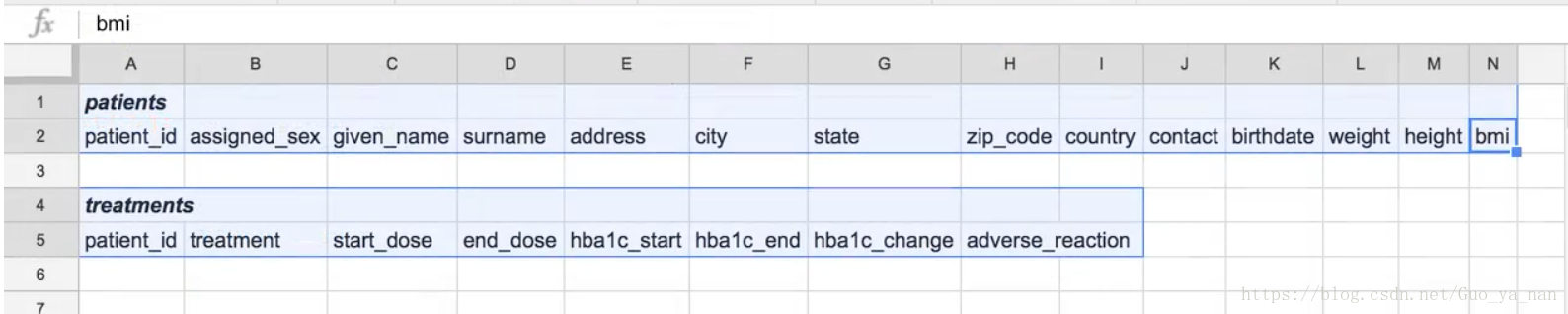
删除重复列、修复前面的两个整洁度问题,最终的表结构应该如下(两表的共有列是患者 ID):
三、数据清理
四、后记
我本人之前对于糖尿病也是懵懂无知的状态,因为做这个项目的缘故,让我主动了解了糖尿病,并查阅了一些患病数据;同时家人中也有2型糖尿病的候选人,更促使我关注2型糖尿病的诱因和防控手段。
其来势汹汹(甚至是爆炸性的增长)主要跟不良的生活方式有关,在此郑重提醒 青年们 养成好的生活习惯:管住嘴,迈开腿。
注脚
[1] 果壳网 关于中国糖尿病患者的报告,另外还有中国疾病控制预防中心对糖尿病的一些实况报道。
[2] 全球糖尿病社区(the global diabetes community)关于口服胰岛素(oral insulin)的一篇文章
[3]