1. 数据说明: Pima Indians Diabetes Data Set(皮马印第安人糖尿病数据集) 根据现有的医疗信息预测5年内皮马印第安人糖尿病发作的概率。 数据链接:https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
2.来吧展示:
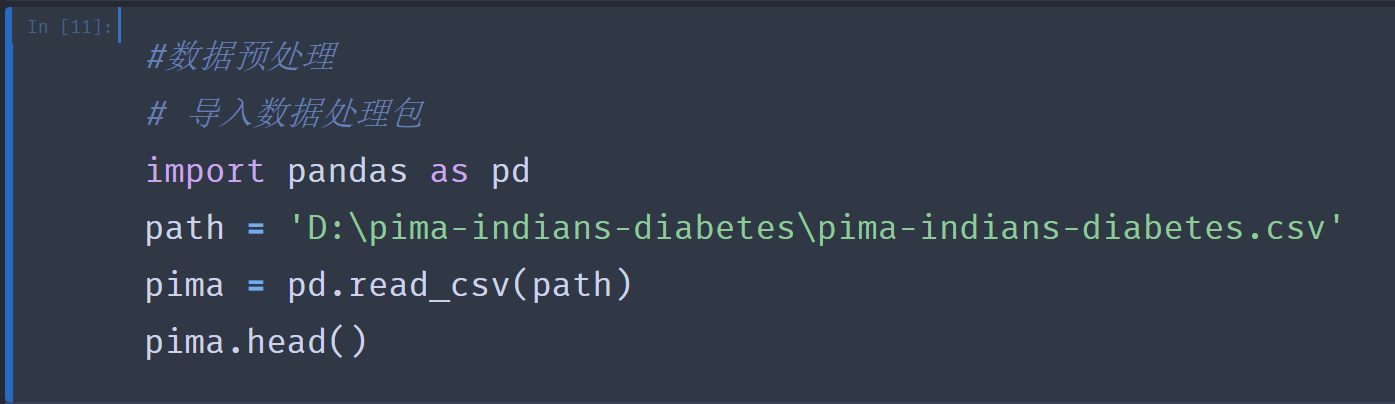
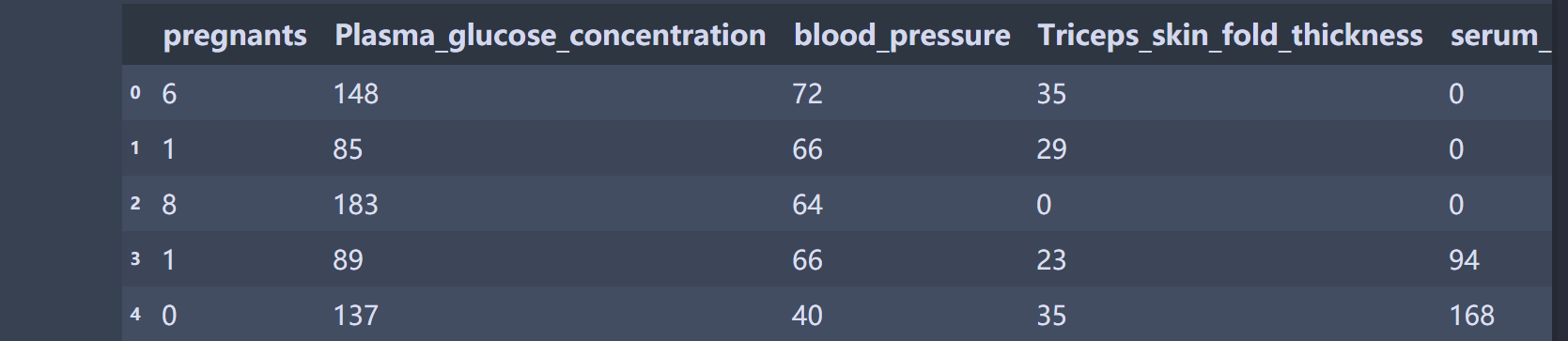
3.#数据预处理
# 导入数据处理包
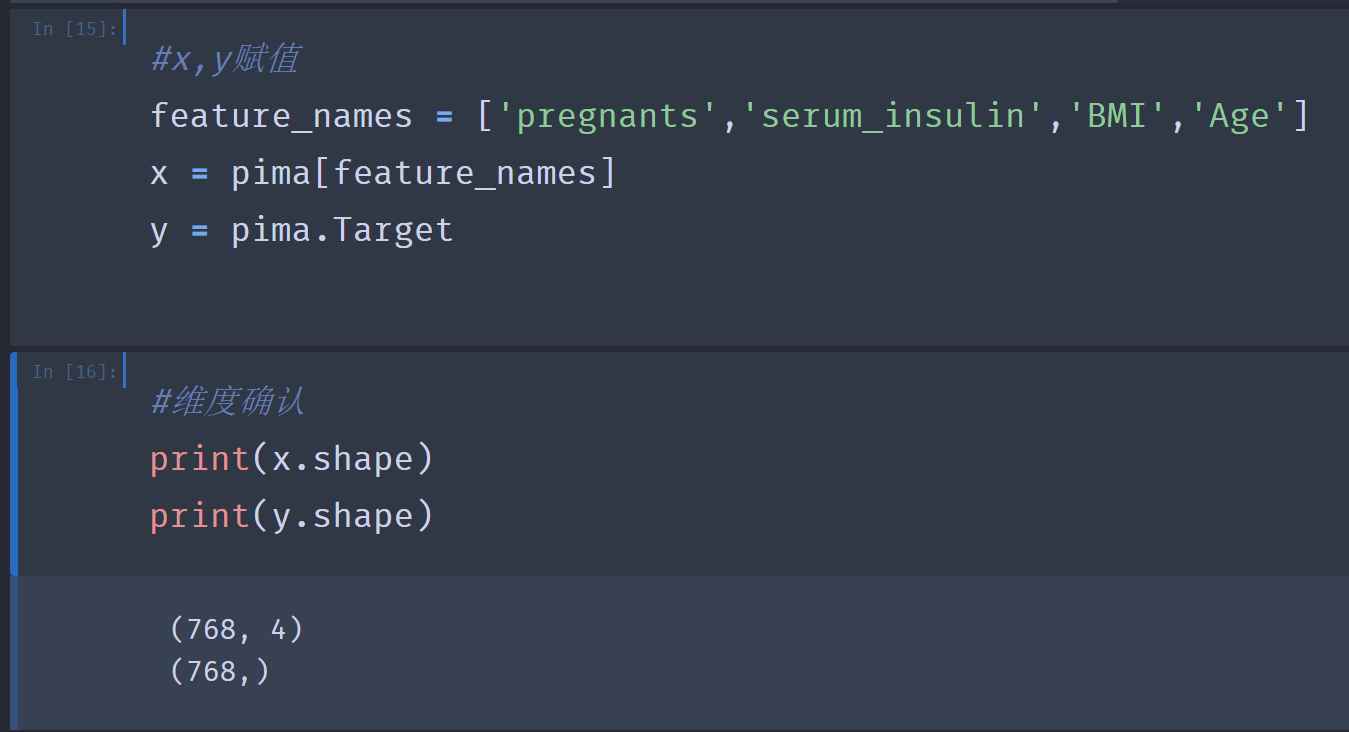
4.#x,y赋值
#维度确认
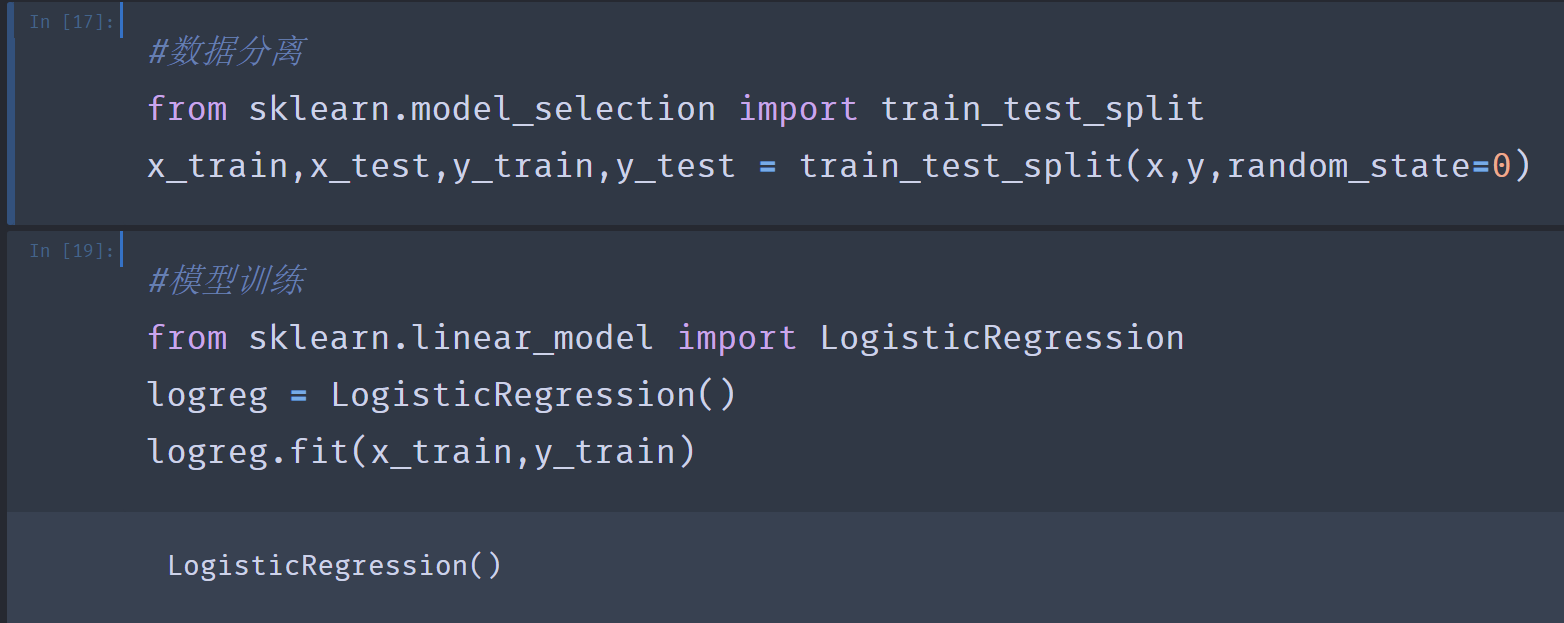
5.#数据分离
#模型训练
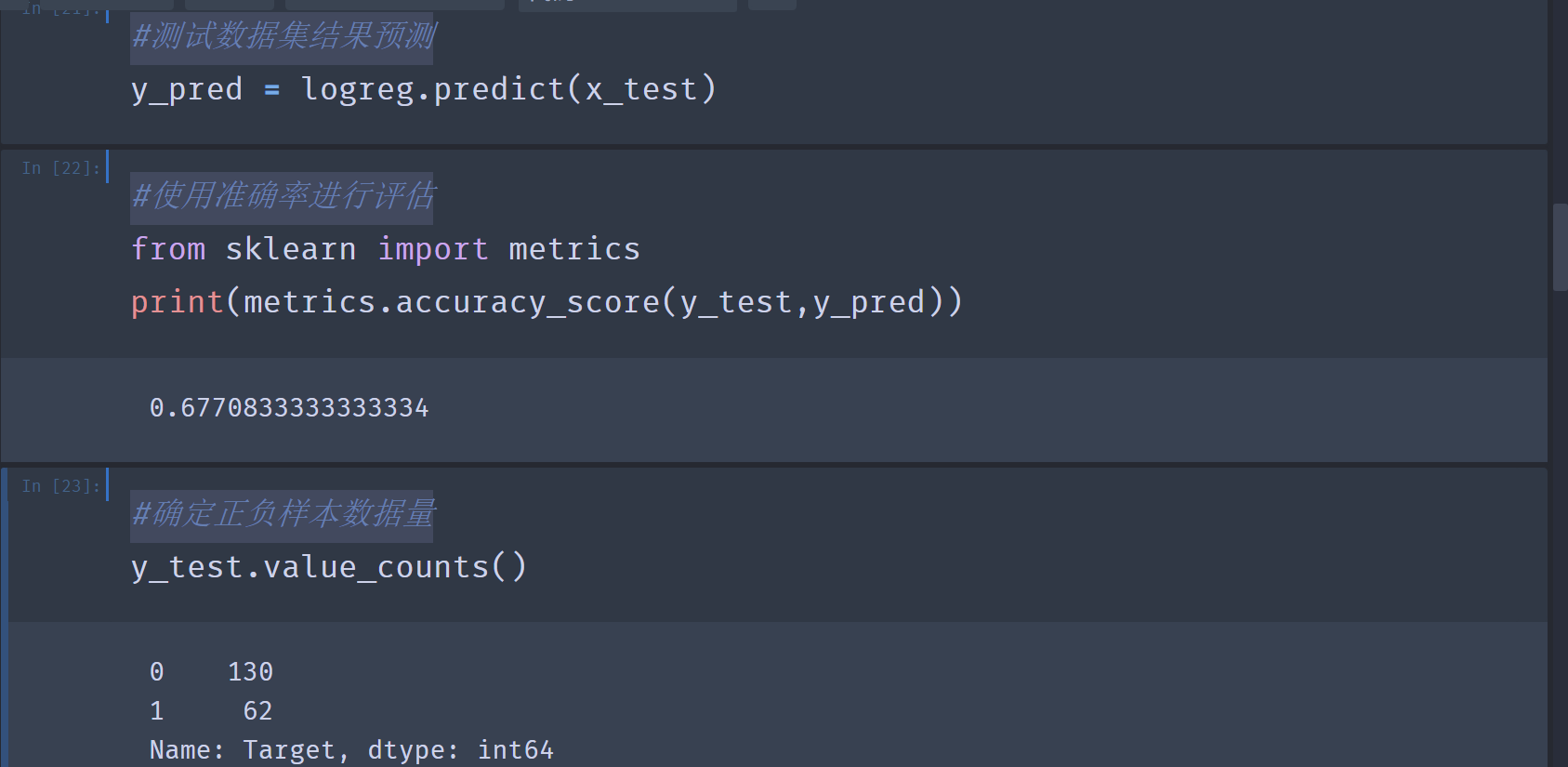
6.#测试数据集结果预测
#使用准确率进行评估
#确定正负样本数据量
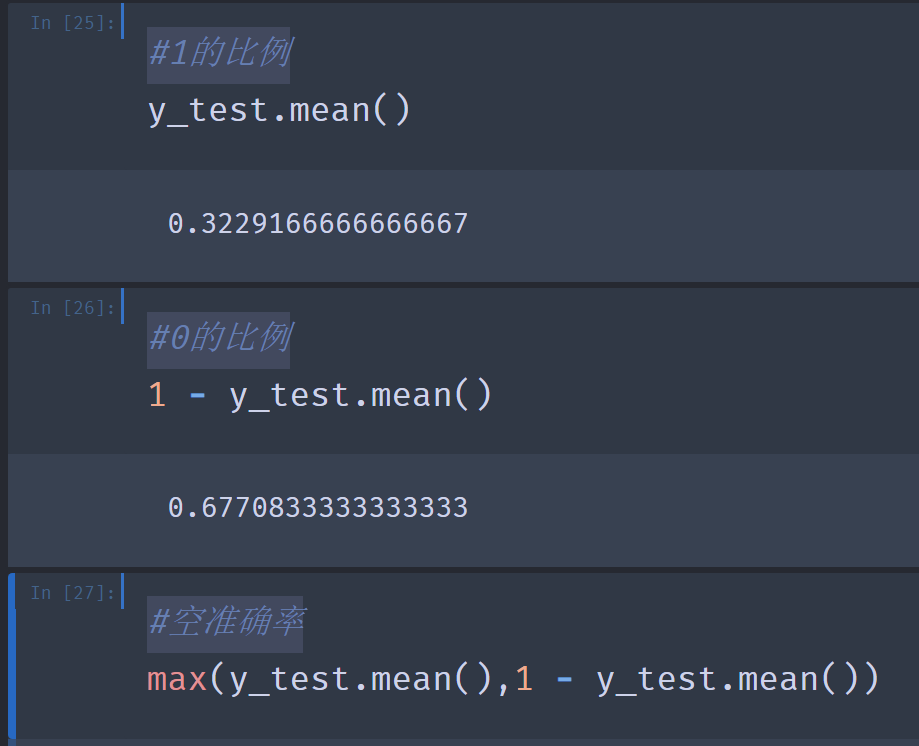
7.#1的比例
#0的比例
#空准确率
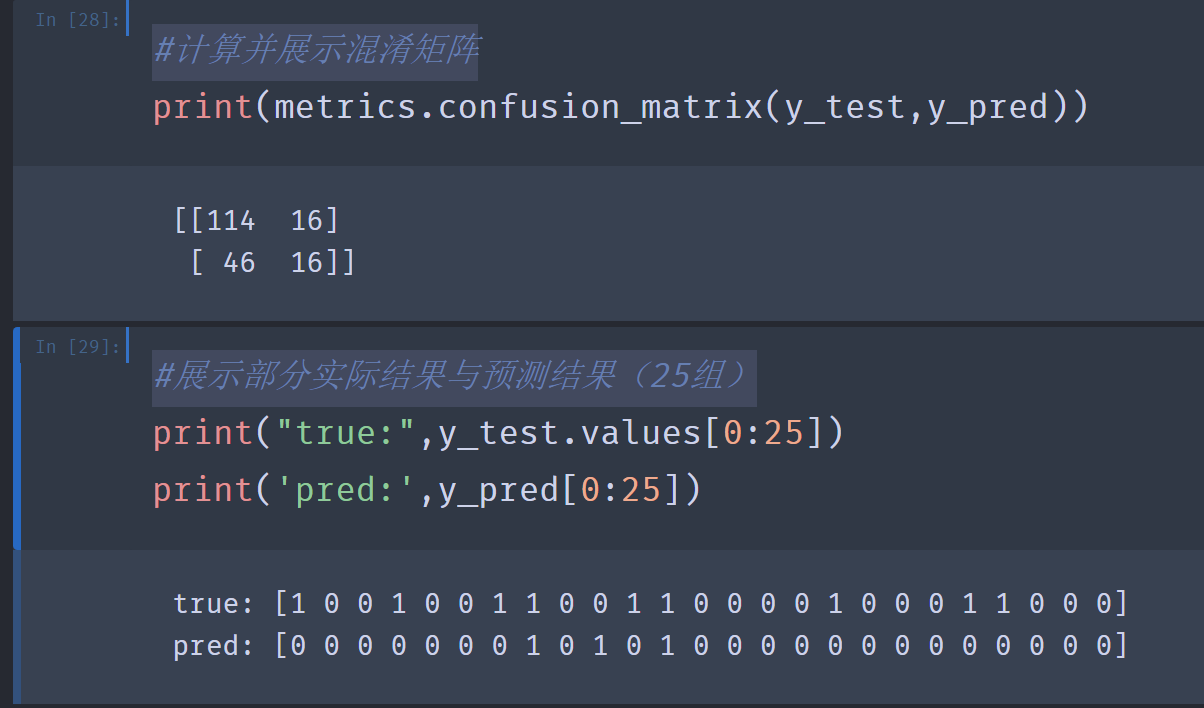
8.#计算并展示混淆矩阵
#展示部分实际结果与预测结果(25组)
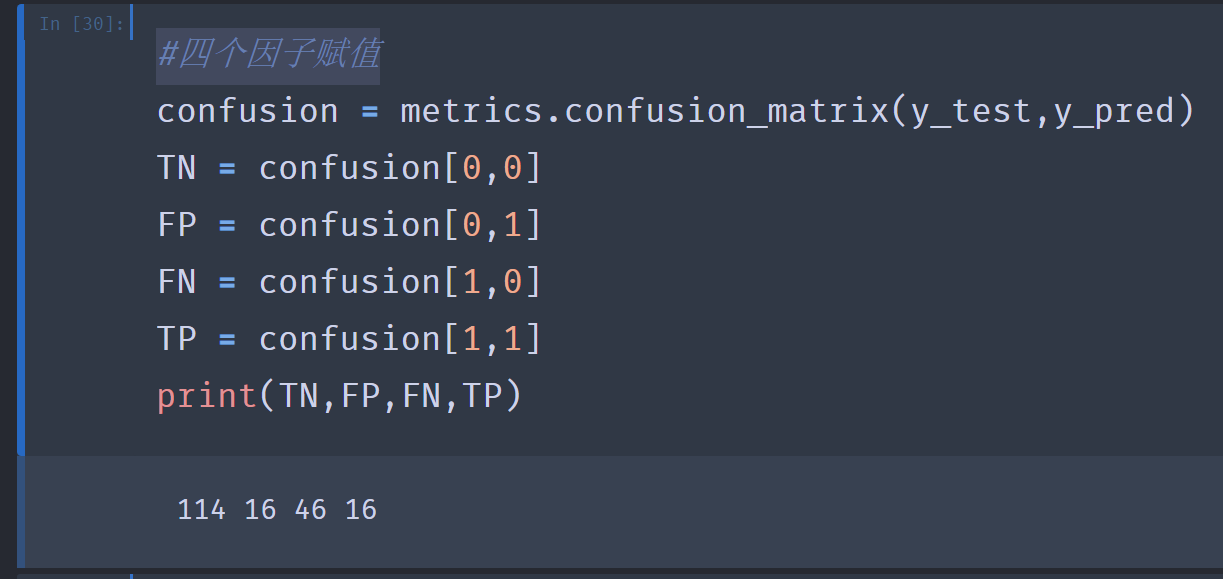
9.#四个因子赋值
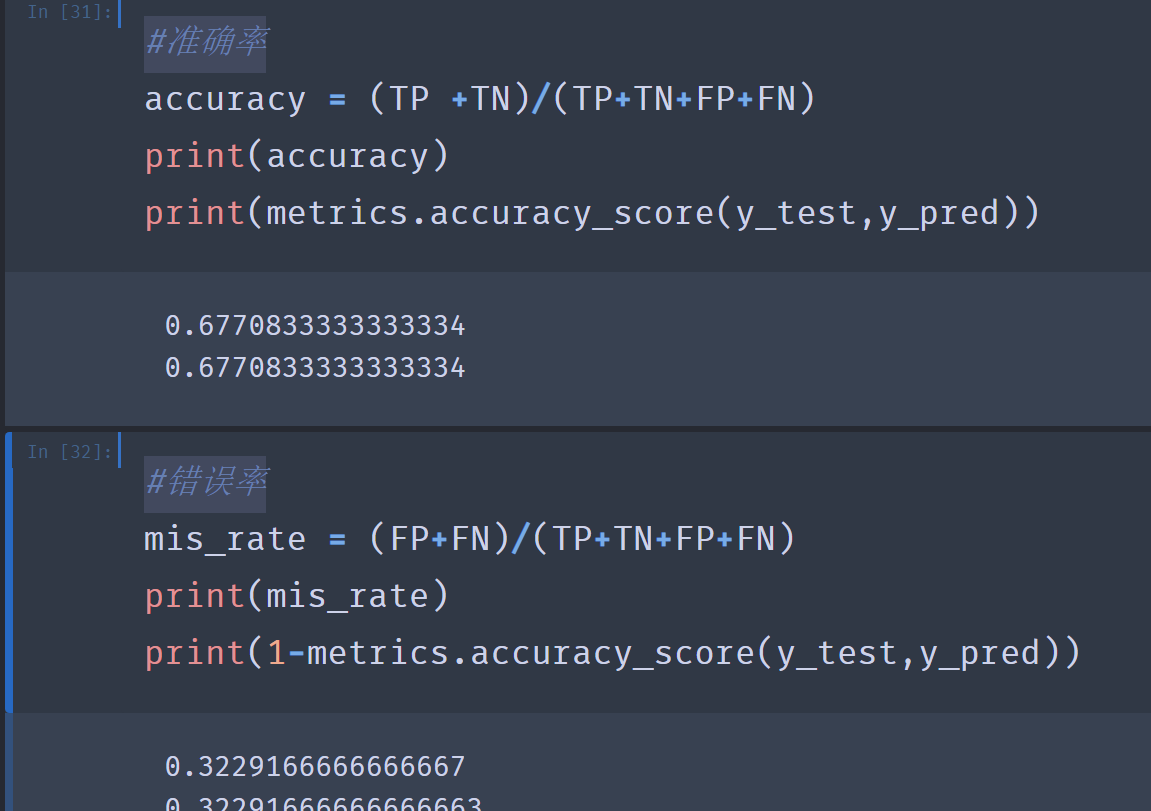
10.#准确率
#错误率
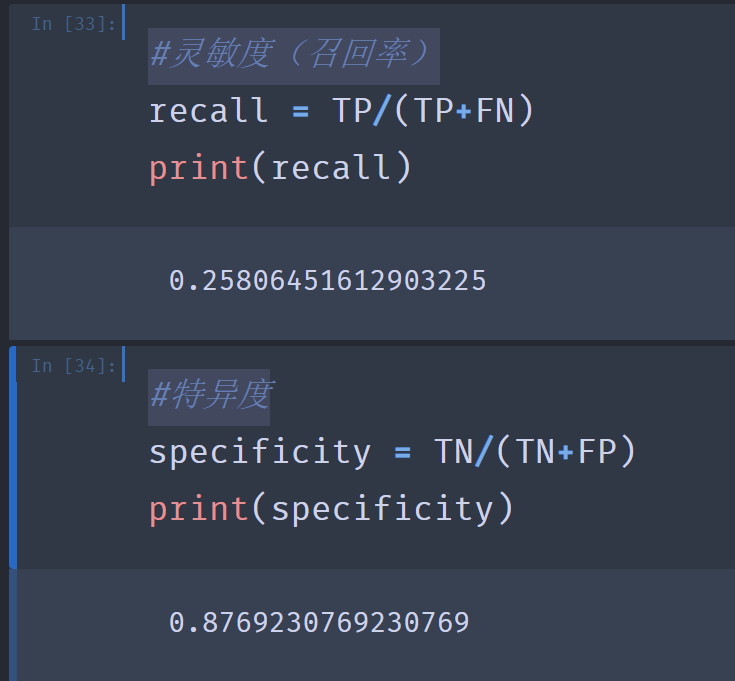
11.#灵敏度(召回率)
#特异度
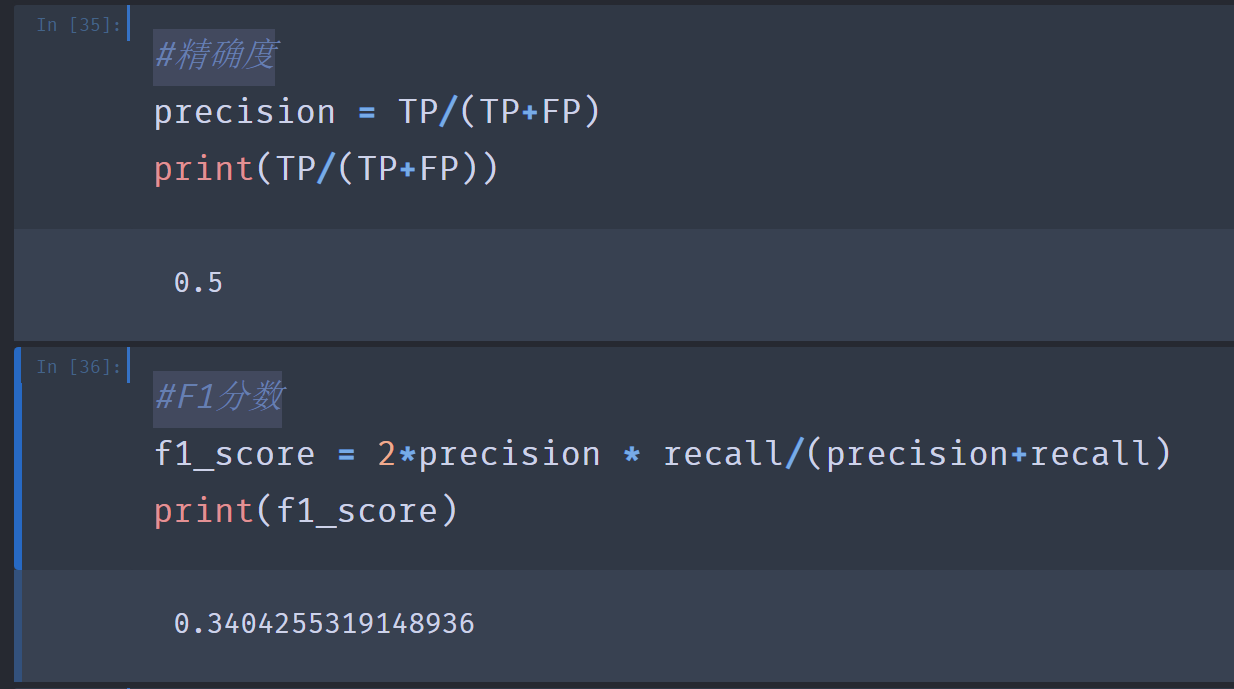
12.#精确度
#F1分数
13.到这也算是成功运行了
希望能帮到大家,问你们要一个赞,你们会给吗,谢谢大家
版权声明:本文版权归作者(@攻城狮小关)和CSDN共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
大家写文都不容易,请尊重劳动成果~
交流加Q:1909561302
博客园地址https://www.cnblogs.com/guanguan-com/