2022年圣诞节到来啦,很高兴这次我们又能一起度过~
论文题目:Deeper Text Understanding for IR with Contextual Neural Language Modeling 利用上下文神经语言模型为IR提供更深入的文本理解
神经网络为自动学习复杂的语言模式和查询-文档关系提供了新的可能性。神经IR模型在学习查询文档相关性模式方面取得了可喜的成果,但在理解查询或文档的文本内容方面却鲜有探索。本文研究利用上下文神经语言模型BERT,为IR提供更深入的文本理解。 实验结果表明,BERT的上下文文本表示比传统的单词嵌入更有效。与词包检索模型相比,上下文语言模型可以更好地利用语言结构,为用自然语言编写的查询带来很大的改进。将文本理解能力与搜索知识结合起来,形成一个增强的预训练BERT模型,可以使训练数据有限的相关搜索任务受益。
1.简介
文本检索需要理解文档含义和搜索任务。神经网络是一个有吸引力的解决方案,因为它们可以从原始文档文本和训练数据中获得这种理解。大多数神经IR方法侧重于学习查询-文档相关性模式,即关于搜索任务的知识。 然而,只学习相关性模式需要大量的训练数据,而且仍然不能很好地推广到尾部查询或新的搜索领域。这些问题使得预训练的、通用的文本理解模型成为理想。
诸如word2vec这样的预训练词表征已被广泛用于神经IR中。它们从大型语料库中的词共现中学习,提供关于同义词和相关词的提示。但是词共现只是对文本的一个浅层次的词包理解。最近,随着ELMo和BERT等预训练的神经语言模型的引入,我们看到了文本理解的快速进展。与传统的词嵌入不同,它们是上下文的–一个词的表示是整个输入文本的函数,其中考虑到了词的依赖性和句子结构。 这些模型在大量的文档上进行了预训练,因此上下文表征编码了一般的语言模式。上下文神经语言模型在各种NLP任务上的表现超过了传统的词嵌入。
上下文神经语言模型更深入的文本理解为IR带来了新的可能性。本文探讨了BERT对ad-hoc文档检索的影响。BERT是一个最先进的神经语言模型,它也很适合搜索任务。BERT被训练来预测两段文本(通常是句子)之间的关系;其基于注意力的架构为文本1中的词与文本2中的词的局部互动建模。 它可以被看作是一个基于交互的神经排名模型,因此需要最小的特定搜索架构工程。
本文检查了两个具有不同特征的ad-hoc检索数据集上的BERT模型。实验表明,用有限的搜索数据对预训练的BERT模型进行微调可以获得比强大的基线更好的性能。与传统检索模式的观察相反,较长的自然语言查询在BERT的作用下能够以较大的幅度超过短关键词查询。 进一步的分析显示,传统的IR方法经常忽略的停顿词和标点符号,通过定义语法结构和单词的依赖性,在理解自然语言查询方面发挥了关键作用。最后,用大型搜索日志中的搜索知识加强BERT,产生了一个预先训练好的模型,该模型同时具备文本理解和搜索任务方面的知识,这对标注数据有限的相关搜索任务有利。
2.相关工作
最近的神经IR模型在学习查询-文档相关性模式方面取得了可喜的进展。一个研究方向是通过点击记录或伪相关性反馈的搜索信号来学习为搜索任务量身定做的文本表示。 另一个研究方向是设计神经架构来捕捉不同的匹配特征,如精确匹配信号和段落级信号。如何理解查询/文档的文本内容,目前探讨得较少。大多数神经IR模型使用词嵌入表示文本,如Word2Vec。
上下文神经语言模型被提出来,通过纳入上下文来改进传统的词嵌入。其中一个表现最好的神经语言模型是BERT。BERT在大规模、开放领域的文件上进行预训练,以学习语言中的一般模式。预训练任务包括预测一个句子中的单词和两个句子的关系。BERT在各种NLP任务上取得了先进水平,包括段落排名任务。它在标准文档检索任务上的有效性还有待研究。
3.使用BERT的文档搜索
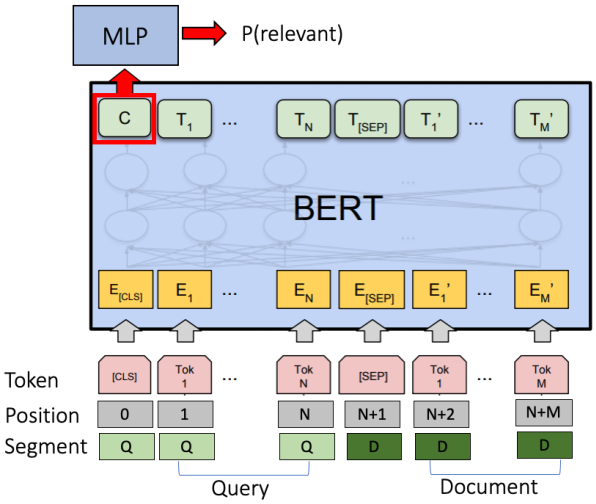
这项工作使用了一个现成的BERT句对分类架构,如图1所示。该模型将查询标记和文档标记的连接作为输入,用一个特殊的标记"[SEP]"来分隔这两个片段。标记被嵌入到embeddings中。为了进一步将查询与文档分开,在标记嵌入中加入了段嵌入’Q’(用于查询标记)和’D’(用于文档标记)。为了捕捉词序,加入了位置嵌入。在每一层,通过加权求和所有其他标记的嵌入,为每个标记生成一个新的上下文嵌入。权重由几个注意力矩阵(多头注意力)决定。具有较强注意力的词被认为与目标词更相关。不同的注意力矩阵捕捉不同类型的单词关系,如完全匹配和同义词。注意力跨越查询和文档,以便考虑到查询-文档的相互作用。最后,第一个标记的输出嵌入被用作整个查询-文档对的表示。它被送入多层感知器(MLP)以预测相关性的可能性(二进制分类)。该模型以预训练的BERT模型初始化,以利用预训练的语言模型,而最后的MLP层则从头开始学习。在训练过程中,整个模型被调整以学习更多的IR特定表示。
图1:BERT句对分类架构
段落级证明:由于每对标记的交互的复杂性,将BERT应用于长文档会导致内存用量和运行时间增加。句子训练的模型在长文本上也可能不那么有效。我们采用简单的段落级方法进行文档检索。我们将文档分成重叠的段落,神经排名器独立预测每个段落的相关性。**文档得分是第一个段落(BERT-FirstP)、最佳段落(BERT-MaxP)或所有段落得分之和(BERT-SumP)的得分。**对于训练,段落级标签在本工作中不适用。我们认为相关文档的所有段落都是相关的,反之亦然。当文件标题可用时,标题被添加到每个段落的开头以提供背景。
用搜索知识增强BERT:一些搜索任务既需要一般的文本理解(如本田是一家公司),也需要更具体的搜索知识(如人们希望看到关于本田的特别优惠)。虽然预训练的BERT编码一般的语言模式,但搜索知识必须从有标签搜索数据中学习。这样的数据往往是昂贵的,而且需要时间来收集。最好是有一个预先训练好的排名模型,它同时具备语言理解知识和搜索知识。我们通过在大型搜索日志上调整BERT来增强它的搜索知识。
讨论:为了将BERT应用于搜索任务,我们只做了一些小的调整:一种基于段落的方法来处理长文档,以及一种连接方法来处理多个文档字段。我们的目标是研究BERT的上下文语言模型对搜索的价值,而不是对架构进行重大扩展。
4.实验设置
数据集:我们使用了两个具有不同特征的标准文本检索集合。Robust04是一个新闻语料库,有0.5M的文档和249个查询,包括两个版本的查询:一个简短的关键字查询(标题)和一个较长的自然语言查询(描述)。还包括一个叙述,作为相关性评估的指导。表1中显示了一个例子。ClueWeb09-B包含50M的网页和200个带有标题和描述的查询。 段落是用一个150个字的滑动窗口生成的,跨度为75个字。对于ClueWeb09-B,文档标题被添加到每个段落的开头。对于用搜索数据增强BERT,我们遵循Dai等人的领域适应设置,并使用相同的Bing搜索日志样本。该样本包含0.1M个查询和5M个查询-文档对。
表1:Robust04搜索主题的例子(主题697)

基线和实现:无监督基线使用Indri的词包(BOW)和顺序依赖模型查询(SDM)。学习排名基线包括RankSVM和Coor-Ascent的词包特征。 神经基线包括DRMM和Conv-KNRM。DRMM使用word2vec来模拟单词软匹配;它被证明是我们两个数据集上表现最好的神经模型之一。Conv-KNRM为搜索任务学习n-gram嵌入,并在大型搜索日志上训练时显示出强大的性能。当与领域适应性训练时,Bing-adapted Conv-KNRM是最先进的神经IR模型,并与Bing-augmented BERT进行比较。BERT模型是基于Google发布的实现。 基线使用标准的停止词去除和词干提取;BERT使用原始文本。监督模型被用来通过5倍交叉验证的BOW检索到的前100个文档进行重排序。由于空间限制,我们只报告了nDCG@20;在nDCG@10和[email protected]中观察到了类似的趋势。
5.结果与讨论
本节研究了BERT在文档检索任务上的有效性,不同类型查询之间的差异,以及用搜索日志增强BERT的影响。
5.1用于文档检索的预训练BERT
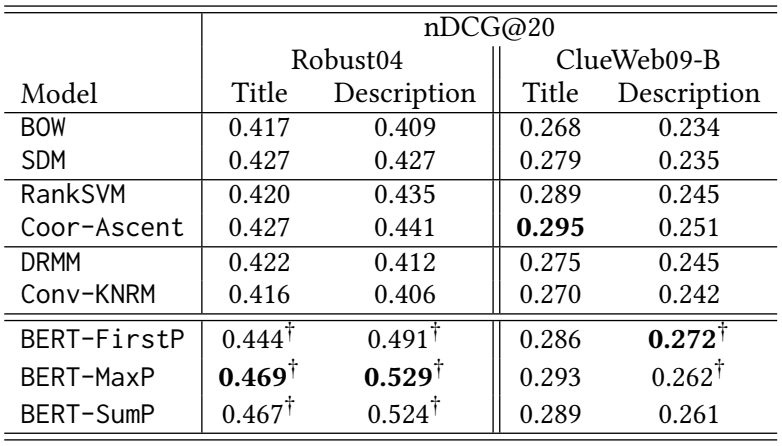
每种排名方法的排名准确率如表2所示。在Robust04上,BERT模型始终比基线取得更好的搜索准确率,在标题查询上有10%的优势,在描述查询上有20%的优势。在ClueWeb09-B上,BERT在标题查询上与Coor-Ascent相当,在描述查询上更好。 这些结果证明了BERT在文档检索方面的有效性,特别是在描述查询方面。在神经排名器中,Conv-KNRM的准确率最低。Conv-KNRM需要从头开始学习n-gram嵌入,当在大量的搜索日志上训练时,它很强大,但当只用少量数据训练时,它往往会过拟合。 BERT是预先训练好的,不容易过拟合。DRMM用预先训练好的词嵌入来表示单词。BERT模型的更好的性能表明,上下文的文本表示比词包嵌入对IR更有效。
表2:在Robust04和ClueWeb09-B上的搜索准确率。†表示在统计学上比Coor-Ascent有明显的改进,通过P<0.05的置换检验。
图2:BERT的可视化。颜色代表不同的注意头,颜色越深表示注意度越高。
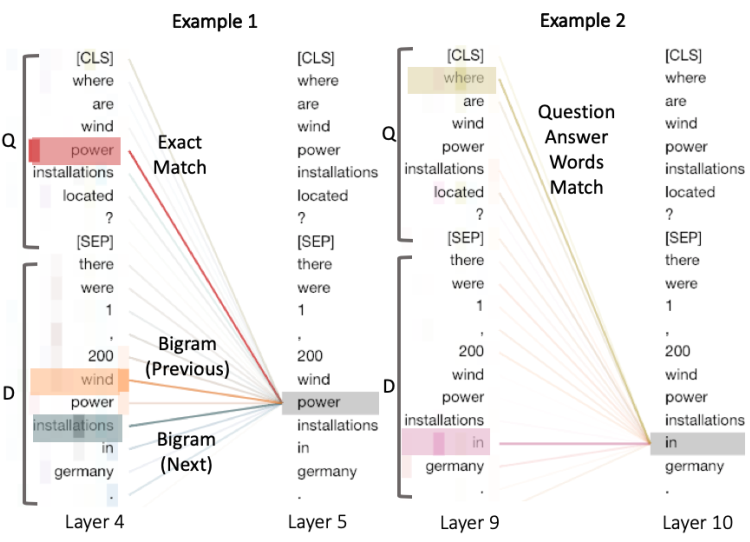
有效性来源:图2显示了BERT-MaxP模型在预测描述查询 "风力发电装置位于何处?"和句子 "德国有1200个风力发电装置 "之间的相关性时的两层。例1显示了文档中的单词 "power "受到的关注。最强烈的注意力来自于查询中的’power’(查询-文档精确术语匹配),以及’power’的上一个和下一个单词(双语法建模)。单词和n-grams的局部匹配已被证明是强大的神经IR特征;BERT也能够捕获它们。示例2显示,文档单词“in”从查询单词“where”中得到了最强烈的注意力。“in”出现在“in Germany”的上下文中,因此它满足了“where”问题。像’in’和’where’这样的词,由于在语料库中的文档频率很高,往往被传统的IR方法所忽视。这个例子表明,随着对文本理解的深入,这些停止词实际上提供了关于相关性的重要证据。总之,BERT的优势在于架构和数据。Transformer架构允许BERT提取各种有效的匹配特征。Transformer已经在大型语料库中进行了预训练,因此具有少量训练数据的搜索任务也可以从这个深度网络中受益。
标题查询与描述查询: BERT模型在描述查询上有较大的收益。在Robust04上,使用BERT-MaxP的描述查询比最好的标题查询基线(SDM)提高了23%。与标题相比,大多数其他排名方法在描述上只得到类似或更差的性能。 据我们所知,这是我们第一次看到描述查询以如此大的幅度胜过标题查询。在ClueWeb09-B上,BERT设法缩小了标题和描述之间的差距。虽然从直觉上讲,描述查询应该携带更丰富的信息,但由于难以估计术语的重要性,在传统的词袋方法中很难充分利用它们。 我们的研究结果表明,较长的自然语言查询确实比关键词更具表现力,并且可以有效地利用更丰富的信息,使用深度的、上下文的神经语言模型来改善搜索。 关于BERT理解不同类型搜索查询的能力的进一步分析,请参见第5.2节。
Robust04与ClueWeb09-B:BERT模型在Robust04上的性能优于ClueWeb09-B。这可能是由于Robust04更接近于预训练的模型。Robust04有写得很好的文章;它的查询寻找的事实主要取决于对文本意义的理解。ClueWeb09-B文档是包括表格、导航栏和其他不连续文本的网页。该任务还涉及特定于网络搜索的问题,如页面权限。学习此类特定于搜索的知识可能需要更多的训练数据。我们在第5.3节中研究了这种可能性。
5.2理解自然语言查询
本节对BERT在3种需要不同程度的文本理解的查询上进行了研究:标题、描述和叙述。为了测试语法结构的影响,通过去除停顿词和标点符号来生成描述和叙述的关键词版本。 为了测试BERT如何理解叙述中的逻辑,通过移除负面条件(例如“文档不相关……”),生成了一个“正面”叙事版本。表3显示了SDM、Coor-Ascent和BERT-MaxP在Robust04上的表现。由于BOW在叙述上的召回率较低,监督方法使用叙述来重新排列标题查询的初始结果,这使得叙述比其他类型的查询更有优势。
表3:对不同类型的Robust04查询的准确度。百分比显示与标题查询相比的相对增益/损失。
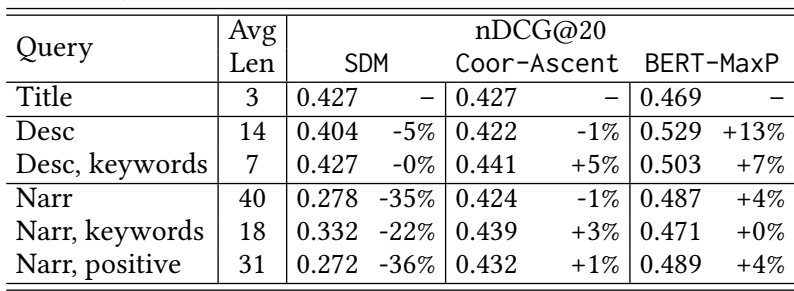
SDM在标题方面效果最好。Coor-Ascent在描述和叙述方面相对更好。这两种方法仅根据术语频率对单词进行加权,但单词的重要性应该取决于整个查询的含义。相反,BERT-MaxP通过对单词含义和上下文进行建模,对较长的查询进行了较大的改进。关键词版本对SDM和Coor-Ascent来说比原始查询表现更好,因为停顿词对TF等传统匹配信号是有噪音的。相比之下,BERT对原始自然语言查询更有效。虽然停顿词和标点符号没有定义所需的信息,但它们在一种语言中构建结构。BERT能够捕获这样的结构,实现比扁平的词袋更深入的查询理解。表3还显示了BERT的局限性。它无法利用叙述中的负面逻辑条件的证据;删除负面条件并不会损害性能。
5.3理解搜索任务
语料库训练的文本表征并不总是与搜索任务相一致。搜索特定的知识是必要的,但需要有标记数据来训练。最后一节研究了BERT的语言建模知识是否可以与额外的搜索知识叠加以建立一个更好的排名器,以及搜索知识是否可以以领域适应的方式学习以缓解冷启动问题。
表4:Bing增强的BERT在ClueWeb09-B上的准确度。†:与Coor-Ascent相比有统计学上的明显改进。
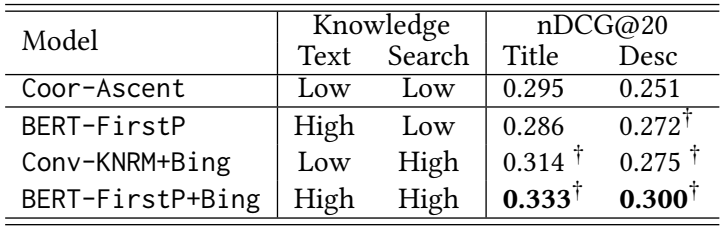
我们在Bing搜索日志样本上训练BERT,并在ClueWeb09-B上对其进行微调。结果如表4所示。BERT-FirstP是ClueWeb09-B上最好的域内BERT模型(表2)。它的预训练语言模型编码了一般的单词关联,如(‘本田’,‘汽车’),但缺乏搜索特定的知识,如(‘本田’,‘特别优惠’)。Conv-KNRM+Bing是以前最先进的领域自适应神经IR模型。它在数百万个查询文档对上进行训练,但没有显式地建模通用语言模式。BERT-FirstP+Bing取得了最好的性能,证实了文本检索需要同时理解文本内容和搜索任务。BERT的简单领域适应性导致了一个预训练的模型,它具有这两种类型的知识,可以改善标记数据有限的相关搜索任务。
6.结论
文本理解是文本检索长期以来所期望的功能。上下文神经语言模型为理解单词上下文和语言结构建模提供了新的可能性。本论文研究了深度神经语言模型BERT对ad-hoc文档检索任务的影响。
调整和微调BERT在两个不同的搜索任务上实现了高准确度 ,表明BERT的语言建模对于IR的有效性。语境化模型给自然语言查询带来了巨大的改进。语料库训练的语言模型可以通过简单的领域适应性来补充搜索知识,从而导致一个强大的排名器,在搜索中同时模拟文本的含义和相关性。
人们习惯于使用关键词查询,因为词袋检索模型不能有效地从自然语言中提取关键信息。我们发现,当系统可以模拟语言结构时,用自然语言写的查询实际上可以获得更好的搜索结果。我们的发现鼓励对具有自然语言界面的搜索系统进行更多的研究。