原文:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Neural networks, in particular recurrent neural networks (RNNs), are now at the core of the leading approaches to language understanding tasks such as language modeling, machine translation and question answering. In “Attention Is All You Need”, we introduce the Transformer, a novel neural network architecture based on a self-attention mechanism that we believe to be particularly well suited for language understanding.
神经网络,特别是递归神经网络(RNN),现在是语言理解任务(如语言建模,机器翻译和问答)的主要方法的核心。在“Attention Is All You Need”中,我们介绍了Transformer,一种基于自我关注机制的新型神经网络架构,我们认为它特别适合语言理解。
In our paper, we show that the Transformer outperforms both recurrent and convolutional models on academic English to German and English to French translation benchmarks. On top of higher translation quality, the Transformer requires less computation to train and is a much better fit for modern machine learning hardware, speeding up training by up to an order of magnitude.
在我们的论文中,我们表明Transformer在学术英语到德语和英语到法语翻译基准上的表现优于复发和卷积模型。除了更高的翻译质量之外,变压器还需要较少的计算来进行训练,并且更适合现代机器学习硬件,加快培训速度达到一个数量级。
|
|
| BLEU scores (higher is better) of single models on the standard WMT newstest2014 English to German translation benchmark. |

|
|
| BLEU scores (higher is better) of single models on the standard WMT newstest2014 English to French translation benchmark. |

Accuracy and Efficiency in Language Understanding
Neural networks usually process language by generating fixed- or variable-length vector-space representations. After starting with representations of individual words or even pieces of words, they aggregate information from surrounding words to determine the meaning of a given bit of language in context. For example, deciding on the most likely meaning and appropriate representation of the word “bank” in the sentence “I arrived at the bank after crossing the…” requires knowing if the sentence ends in “... road.” or “... river.”
神经网络通常通过生成固定或可变长度的向量空间表示来处理语言。在使用向量表示某个单词时,通常会聚合来自周围单词的上下文信息以确定当前位置单词的含义。例如,在“I arrived at the bank after crossing the…”这句话中,想知道“bank”一词的最可能含义就必须得知道该句子是否以“... road”或“... river“结尾。
RNNs have in recent years become the typical network architecture for translation, processing language sequentially in a left-to-right or right-to-left fashion. Reading one word at a time, this forces RNNs to perform multiple steps to make decisions that depend on words far away from each other. Processing the example above, an RNN could only determine that “bank” is likely to refer to the bank of a river after reading each word between “bank” and “river” step by step. Prior research has shown that, roughly speaking, the more such steps decisions require, the harder it is for a recurrent network to learn how to make those decisions.
近年来,RNN已成为机器翻译所使用的的典型网络结构,RNN以从左到右或从右到左的方式顺序处理语句。一次读一个单词,这迫使RNN执行多个步骤后才能“看到”相距甚远的两个单词之间是否有联系。处理上面的例子,RNN只能在逐步读取“bank和“river”之间的每个单词后确定“bank”可能是指河岸。之前的研究表明,决策需要的步骤越多,RNN越难学习如何做出这些决策。
The sequential nature of RNNs also makes it more difficult to fully take advantage of modern fast computing devices such as TPUs and GPUs, which excel at parallel and not sequential processing. Convolutional neural networks (CNNs) are much less sequential than RNNs, but in CNN architectures like ByteNet or ConvS2S the number of steps required to combine information from distant parts of the input still grows with increasing distance.
RNN的顺序计算更难以充分利用现代快速计算设备,例如TPU和GPU(擅长并行而非顺序处理)。卷积神经网络(CNN)的序列性远小于RNN,但在CNN体系结构中,如ByteNet或ConvS2S,组合来自输入相隔较远的信息所需的步骤数仍随着距离的增加而增长。
The Transformer
In contrast, the Transformer only performs a small, constant number of steps (chosen empirically). In each step, it applies a self-attention mechanism which directly models relationships between all words in a sentence, regardless of their respective position. In the earlier example “I arrived at the bank after crossing the river”, to determine that the word “bank” refers to the shore of a river and not a financial institution, the Transformer can learn to immediately attend to the word “river” and make this decision in a single step. In fact, in our English-French translation model we observe exactly this behavior.
相比之下,Transformer只执行固定的步骤来学习不同位置单词之间的dependency(步骤数根据经验选择)。在每个步骤中,它应用自注意力机制,该机制直接模拟句子中所有单词之间的关系,而不管它们各自的位置如何。在前面的例子中“I arrived at the bank after crossing the river”,为了确定“bank”一词是指河岸而不是金融机构,transformer可以通过直接找到“river”这个词并利用river的信息在一步中做出这个bank是河岸的决定。事实上,在我们的英语 - 法语翻译模型中,我们确实观察到了这种行为。
More specifically, to compute the next representation for a given word - “bank” for example - the Transformer compares it to every other word in the sentence. The result of these comparisons is an attention score for every other word in the sentence. These attention scores determine how much each of the other words should contribute to the next representation of “bank”. In the example, the disambiguating “river” could receive a high attention score when computing a new representation for “bank”. The attention scores are then used as weights for a weighted average of all words’ representations which is fed into a fully-connected network to generate a new representation for “bank”, reflecting that the sentence is talking about a river bank.
更具体地,为了计算给定单词的下一个表示 - 例如“bank” - T将bank与句子中的其他单词进行比较。这些比较的结果是句子中每个单词都会产生一个注意力得分。这些注意力分数决定了每个单词应该为下一个“bank”的向量表示做出多少贡献。在该示例中,可以消除歧义的“river”在计算“bank”的新表示时会获得更高的注意力分数。此后,注意力分数会被作为权重,以计算所有单词的加权平均值,之后它被馈送到全连接网络以生成“bank”的新向量表示,反映该句子正在谈论河岸。
The animation below illustrates how we apply the Transformer to machine translation. Neural networks for machine translation typically contain an encoder reading the input sentence and generating a representation of it. A decoder then generates the output sentence word by word while consulting the representation generated by the encoder. The Transformer starts by generating initial representations, or embeddings, for each word. These are represented by the unfilled circles. Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context, represented by the filled balls. This step is then repeated multiple times in parallel for all words, successively generating new representations.
下面的动画说明了我们如何将Transformer应用于机器翻译。用于机器翻译的神经网络通常包含读取输入句子并生成其表示的编码器。然后,解码器在查阅编码器生成的表示的同时逐字生成输出语句。 Transformer首先为每个单词生成初始表示或emb。这些由未填充的圆圈表示。然后,使用自我关注,它聚合来自所有其他单词的信息,生成由整个上下文信息编码的每个单词的新表示,由填充的球表示。然后对所有单词并行地重复该步骤多次,连续地生成新的表示。
![]()
The decoder operates similarly, but generates one word at a time, from left to right. It attends not only to the other previously generated words, but also to the final representations generated by the encoder.
解码器的操作和encoder类似,但是从左到右一次生成一个字。它不仅需要其他先前生成的单词,而且还需要编码器生成的最终表示。
Flow of Information
Beyond computational performance and higher accuracy, another intriguing aspect of the Transformer is that we can visualize what other parts of a sentence the network attends to when processing or translating a given word, thus gaining insights into how information travels through the network.
除了计算性能和更高的准确性之外,Transformer的另一个有趣的方面是我们可以可视化网络所“抓取“的用于处理或翻译给定单词的句子其他部分,从而深入了解信息如何通过网络传播。
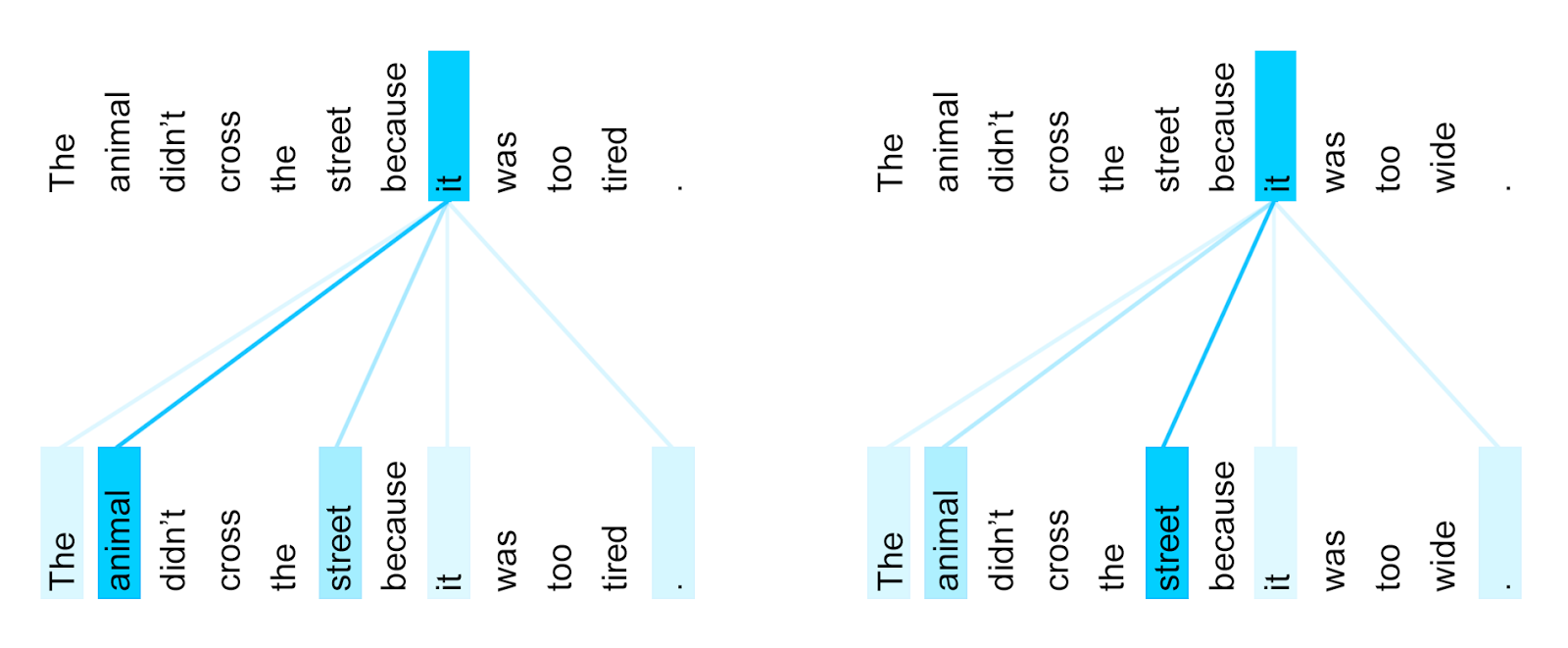
To illustrate this, we chose an example involving a phenomenon that is notoriously challenging for machine translation systems: coreference resolution. Consider the following sentences and their French translations:
为了说明这一点,我们选择了一个涉及机器翻译系统众所周知的现象的例子:coreference resolution。请考虑以下句子及其法语翻译:

It is obvious to most that in the first sentence pair “it” refers to the animal, and in the second to the street. When translating these sentences to French or German, the translation for “it” depends on the gender of the noun it refers to - and in French “animal” and “street” have different genders. In contrast to the current Google Translate model, the Transformer translates both of these sentences to French correctly. Visualizing what words the encoder attended to when computing the final representation for the word “it” sheds some light on how the network made the decision. In one of its steps, the Transformer clearly identified the two nouns “it” could refer to and the respective amount of attention reflects its choice in the different contexts.
对大多数人来说显而易见的是,在第一句话中,“it”指的是动物,而第二句指的是街道。在将这些句子翻译成法语或德语时,“it”的翻译取决于它所指的名词的类别 - 而在法语中“动物”和“街道”具有不同的类别。与当前的Google Translate模型相比,Transformer正确地将这两个句子翻译成法语。通过可视化编码器在计算单词“it”的最终表示时所”抓取“的单词,可以说明网络如何做出决定。在其中一个步骤中,T清楚地标定了“it”可以refer的两个名词,并且不同的注意力反映了它在不同上下文中的选择。
|
|
| The encoder self-attention distribution for the word “it” from the 5th to the 6th layer of a Transformer trained on English to French translation (one of eight attention heads). |
Given this insight, it might not be that surprising that the Transformer also performs very well on the classic language analysis task of syntactic constituency parsing, a task the natural language processing community has attacked with highly specialized systems for decades.
In fact, with little adaptation, the same network we used for English to German translation outperformed all but one of the previously proposed approaches to constituency parsing.
鉴于这种观察,Transformer在语法解析的经典语言分析任务上也表现得非常出色,这是自然语言处理社区几十年来一直使用高度专业化系统来做的任务。
实际上,在几乎不做改变的情况下,我们用于英语到德语翻译的同一网络优于除先前提出的选区解析方法之外的所有网络。
Next Steps
We are very excited about the future potential of the Transformer and have already started applying it to other problems involving not only natural language but also very different inputs and outputs, such as images and video. Our ongoing experiments are accelerated immensely by the Tensor2Tensor library, which we recently open sourced. In fact, after downloading the library you can train your own Transformer networks for translation and parsing by invoking just a few commands. We hope you’ll give it a try, and look forward to seeing what the community can do with the Transformer.
我们对T的未来潜力感到非常兴奋,并且已经开始将其应用于其他问题,不仅涉及自然语言,还涉及非常不同的输入和输出,例如图像和视频。我们最近开源的Tensor2Tensor库极大地加速了我们正在进行的实验。事实上,在下载库之后,您可以通过调用几个命令来训练您自己的Transformer网络进行翻译和解析。我们希望您试一试,并期待看到社区可以对Transformer做些什么。
Acknowledgements
This research was conducted by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser and Illia Polosukhin. Additional thanks go to David Chenell for creating the animation above.