一,语言模型
1,基本定义
一个语言模型包含一个词汇集合 和一个函数 ,并且该函数满足:
- 对于任意的词序列 ,其中 表示基于词汇集合 的词序列集合,词序列就是句子。
- 此外,
因此, 本质上是基于词序列集合 中词序列的概率分布。
所以,语言模型最本质的作用就是用来衡量一个词序列符合自然语言表达的程度。
2,推导语言模型的四个步骤
- 首先使用链式法则展开
:
其中我们假设 为 ,代表句子的开始; 为STOP,代表句子的结尾。
- 然后使用马尔可夫独立性假设(这里使用二阶马尔可夫假设也称二阶马尔可夫模型),化简上面展开式中的每个式子:
最终语言模型(这里是trigram LM)会变成:这样可以大大减少要估计的语言模型参数。
- 然后使用训练语料估计语言模型的所有参数 ,一般在最大似然估计的基础上使用一些平滑估计方法。
- 最后计算语言模型在测试集上的困惑度来评估语言模型的好坏,困惑度定义如下:
其中表示测试集中的第i个句子, 表示测试集中的句子个数, 测试集中所以词语的个数。
评估准则:困惑度越小,语言模型越好。可以把困惑度看成在某一语言模型下有效词汇表的大小。
3,语言模型应用举例
语言模型是NLP中最基本的模型,被广泛应用在语音识别、机器翻译等等应用中。
应用1:音字转换问题
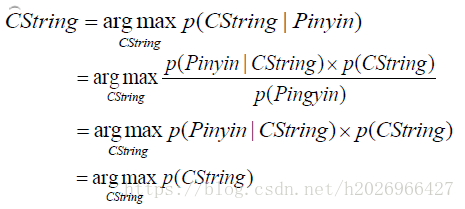
应用2:汉语分词问题
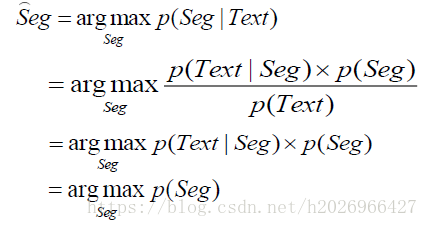
二,平滑估计方法
使用最大似然估计法估计trigram语言模型的参数为:
很容易出现零概率问题。所以需要一些平滑估计方法来估计参数。
- 平滑估计方法的基本思想:调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。
- 基本目标:最小化语言模型在测试集上的困惑度。
- 基本约束: 。
现有的平滑估计方法有:
- Laplace平滑(加一平滑法)
- Linear Interpolation(线性插值法)
- Discounting法(折扣法或减值法):①Good-Turing估计②Katz后退法③绝对减值法④线性减值法。
在实际中最常用的是线性插值法和折扣法。
1,线性插值法
使用一些低阶参数估计来避免零概率问题。例如trigram LM的线性插值法如下:

(1)首先用MLE估计出trigram、bigram和unigram下的参数
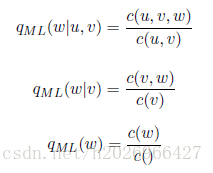
(2)然后,结合这三个估计值来估计trigram LM最终的参数估计值:

(3)通过最小化验证集上该语言模型的困惑度来确定 的值。或者最大化验证集上该语言模型的概率值,即最大化概率的对数似然。
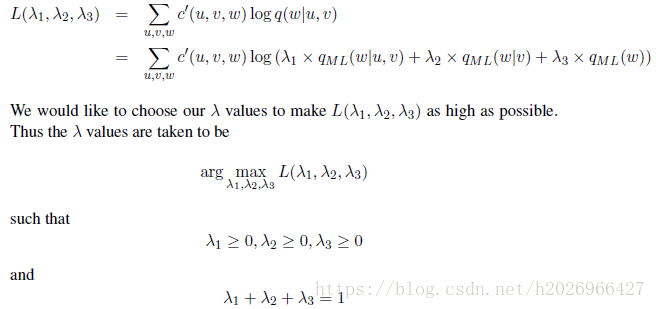
其实还可以进行一些改进, 应该随着 的增大而增大, 应该随着 的增大而增大,所以
- 改进方法1:
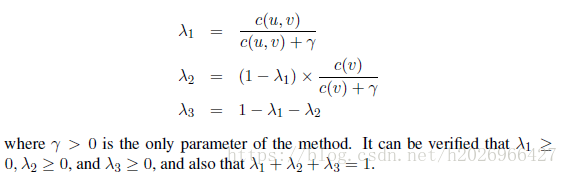
该方法虽然不是最优的,但是非常简单而且在一些应用中表现地也非常好。
- 改进方法2:Bucketing,即将 的取值分成多个取值区间,每个取值区间有一组 。
2,折扣法(又称减值法)

绝对减值法产生的n-gram一般优于线性减值法。
下面主要说一下Katz后退法:
(1)首先计算折损后的计数值:
(2)然后计算未见事件总的概率值:
(3)计算最后的估计值
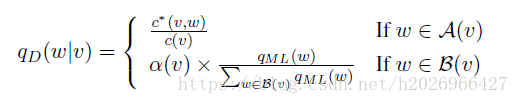
其中,
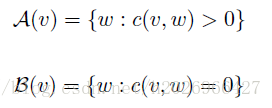


三,语言模型的自适应
由于语言模型对训练文本的类型、主题和风格等都十分敏感,所以我们需要对上述基本的语言模型进行一些自适应的改进。
自适应的方法主要有:
- 基于缓存的语言模型
- 基于混合的语言模型
- 基于最大熵的语言模型
每个方法的具体思想可参考宗成庆老师的《统计自然语言处理》
四,语言模型的应用
语言模型广泛地应用于自然语言处理的各个方面,是统计自然语言处理方法中最核心、最基本的模型。
1,基于语言模型的分词方法

所以,我们可以首先把词序列转换为类序列,然后再进行分词:
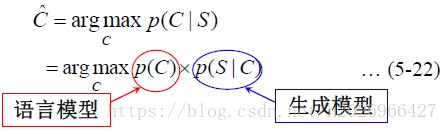
其中p(C)是基于词类别的语言模型。
2,分词和词性标注一体化方法
一种经典的模型如下:
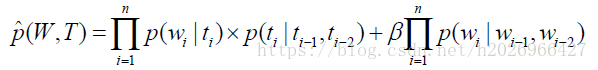
其中W是词序列,T是标注的词性序列。
该模型中就用到了基于单词的语言模型和基于词性的语言模型,前者仅增强了对分词的约束,而后者不仅对分词有帮助,也对词性标注有帮助。
总之,语言模型是极其重要的!