代码:https://github.com/zihangdai/xlnet
Abstract
借助对双向上下文进行建模的能力,与基于自回归语言建模的预训练方法相比,像BERT这样的基于自动编码的去噪预训练方法可以获得更好的性能。但是,BERT依赖于使用masks,破坏输入,因此忽略了masks位置之间的依赖关系,并遭受了预训练-微调差异的困扰。鉴于这些优点和缺点,我们提出XLNet,这是一种广义的自回归预训练方法,该方法(1)通过最大化因式分解的所有排列的预期似然性来实现双向上下文的学习,并且(2)由于其自回归公式而克服了BERT的局限性。此外,XLNet将来自最先进的自回归模型Transformer-XL的思想整合到预训练中。根据经验,在可比较的实验设置下,XLNet在20个任务上的表现要优于BERT,通常包括问题回答,自然语言推论,情感分析和文档排名等方面的优势。1。
1 Introduction
在自然语言处理领域,无监督表示学习已经取得了很大的成功[7,22,27,28,10]。 通常,这些方法首先在大规模的未标记文本语料库上对神经网络进行预训练,然后对下游任务的模型或表示进行微调。 在这种共同的高级观念下,文献中探索了不同的无监督预训练目标。 其中,自回归(AR)语言建模和自编码(AE)是最成功的两个预训练目标。
AR语言建模试图通过自动回归模型估计文本语料库的概率分布[7,27,28]。 具体来说,给定文本序列x =(x1,···,xT),AR语言建模将似然因子分解为正向乘积![]() 或反向乘积
或反向乘积![]() 。 训练参数模型(例如神经网络)以对每个条件分布建模。 由于AR语言模型仅受过训练以编码单向上下文(向前或向后),因此在建模深层双向上下文时无效。 相反,下游语言理解任务通常需要双向上下文信息。 这导致AR语言建模与有效的预训练之间存在差距。
。 训练参数模型(例如神经网络)以对每个条件分布建模。 由于AR语言模型仅受过训练以编码单向上下文(向前或向后),因此在建模深层双向上下文时无效。 相反,下游语言理解任务通常需要双向上下文信息。 这导致AR语言建模与有效的预训练之间存在差距。
相比之下,基于AE的预训练不执行显式密度估计,而是旨在从损坏的输入中重建原始数据。一个著名的例子是BERT [10],它是最先进的预训练方法。给定输入令牌序列,将令牌的某些部分替换为特殊符号[MASK],并训练模型以从损坏的版本中恢复原始令牌。由于密度估计不是目标的一部分,因此允许BERT利用双向上下文进行重建。作为直接好处,这消除了AR语言建模中的上述双向信息鸿沟,从而提高了性能。但是,在预调整期间,真实数据中缺少BERT在预训练期间使用的人工符号,例如[MASK],导致预训练与预调整之间存在差异。此外,由于预测的令牌在输入中被屏蔽,因此BERT无法像AR语言建模那样使用乘积规则对联合概率进行建模。换句话说,BERT假定给定了未屏蔽的令牌,预测的令牌彼此独立,这被简化为自然语言中普遍存在的高阶,长距离依赖性[9]。
面对现有语言预训练目标的利弊,在这项工作中,我们提出XLNet,这是一种通用的自动回归方法,它充分利用了AR语言建模和AE的优点,同时避免了它们的局限性。
•首先,XLNet代替了传统AR模型中使用固定的正向或反向分解顺序,相对于分解顺序的所有可能排列,XLNet最大化了序列的预期对数似然性。多亏了全排列操作,每个位置的上下文都可以由其左右两侧的tokens组成。期望地,每个位置学会从所有位置利用上下文信息,即捕获双向上下文。
•其次,作为通用的AR语言模型,XLNet不依赖数据损坏。因此,XLNet不会遭受BERT所受的预训练-精调差异的困扰。同时,自回归目标还提供了一种自然的方式来使用乘积规则将预测tokens的联合概率分解为因数,从而消除了BERT中的独立性假设。XLNet除了改进了预训练目标之外,还改进了用于预训练的架构设计。
•受AR语言建模最新进展的启发,XLNet将分段递归机制和Transformer-XL的相对编码方案[9]集成到预训练中,从而从经验上提高了性能,尤其是对于涉及较长文本序列的任务。
•由于分解顺序是任意的并且目标是歧义,因此将Transformer(-XL)体系结构直接地应用于基于排列的语言建模是行不通的。作为解决方案,我们建议重新设置Transformer(-XL)网络的参数,以消除歧义。
根据经验,在可比较的实验设置下,XLNet在包括GLUE语言理解任务,阅读理解任务(例如SQuAD和RACE),文本分类任务(例如Yelp和IMDB)以及ClueWeb09-B文档排名等一系列问题上始终优于BERT [10]任务。
相关工作[32,12]中探讨了基于排列的AR建模的思想,但是有几个关键的区别。 首先,先前的模型旨在通过在模型中添加“无序”归纳偏差来改善密度估计,而XLNet则是通过使AR语言模型能够学习双向上下文来激发的。 从技术上讲,为了构建有效的目标感知预测分布,XLNet通过两流注意将目标位置纳入隐藏状态,而以前的基于置换的AR模型则依赖于其MLP体系结构固有的隐式位置感知。 最后,对于无序NADE和XLNet,我们要强调的是,“无序”并不意味着可以对输入序列进行随机排列,而是该模型允许分布的不同分解顺序。
另一个相关的想法是在文本生成的上下文中执行自回归去噪[11],尽管它仅考虑固定顺序。
2 Proposed Method
在本节中,我们首先回顾和比较传统的AR语言建模和BERT进行语言预训练。 给定文本序列x = [x1,...,xT],AR语言建模通过在正向自回归分解下最大化似然性来执行预训练:

where hθ(x1:t−1) is a context representation produced by neural models, such as RNNs or Transformers, and e(x) denotes the embedding of x.
In comparison, BERT is based on denoising auto-encoding. Specifically, for a text sequence x, BERT first constructs a corrupted version xˆ by randomly setting a portion (e.g. 15%) of tokens in x to a special symbol [MASK]. Let the masked tokens be x ̄. The training objective is to reconstruct x ̄ from xˆ:
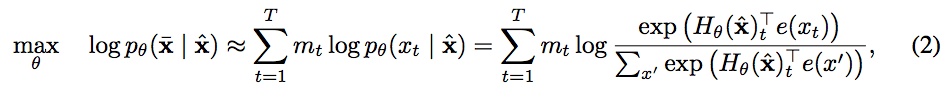
where mt = 1 indicates xt is masked, and Hθ is a Transformer that maps a length-T text sequence x into a sequence of hidden vectors Hθ(x) = [Hθ(x)1, Hθ(x)2, · · · , Hθ(x)T ]. The pros and cons of the two pretraining objectives are compared in the following aspects:
•独立假设:如等式2中的≈符号所强调,BERT基于一个独立假设,将所有被mask令牌x̄分别重建,从而分解联合条件概率p(x̄| xˆ)。相比之下,AR语言建模目标等式1使用普遍适用的乘积规则将pθ(x)分解,而没有这种独立性假设,它是严格的等号。
•输入噪声:BERT的输入包含诸如[MASK]的人工符号,这些符号在下游任务中永远不会出现,这会造成预训练-精调差异。用[10]中的原始令牌替换[MASK]不能解决该问题,因为原始令牌只能以很小的概率使用-否则等式2将是微不足道的优化。相比之下,AR语言建模不依赖于任何输入损坏,也不会遭受此问题的困扰。
•上下文相关性:AR表示hθ(x1:t−1)仅以直到位置t的令牌(即左侧的令牌)为条件,而BERT表示Hθ(x)t可以访问这两个令牌上的上下文信息双侧。结果,BERT目标允许对模型进行预训练以更好地捕获双向上下文。
2.2 Objective: Permutation Language Modeling
根据上面的比较,AR语言建模和BERT具有相对于其他语言的独特优势。 一个自然要问的问题是,是否存在一个既能带来优点又能避免缺点的预训练目标。
借鉴无序NADE [32]的想法,我们提出了全排列语言建模的目标,该目标不仅保留了AR模型的优势,而且允许模型捕获双向上下文。 具体来说,对于长度为T的序列x,有T!种执行有效的自回归分解的不同排序。 直观地,如果模型参数在所有分解排列之间共享,则可以预期,模型将学习从双方所有位置收集信息。
为了使这个想法正式化,让ZT为length-T索引序列的所有可能排列的集合[1、2,...。 。 。 ,T]。 我们使用zt和z <t表示置换z∈ZT的第t个元素和前t-1个元素。 然后,我们提出的全排列语言建模目标可以表示如下:
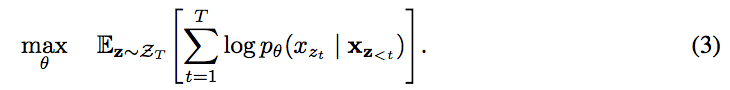
本质上,对于文本序列x,我们一次采样分解顺序z并根据分解顺序分解似然pθ(x)。 由于在训练期间所有分解因子阶上都共享相同的模型参数θ,因此,预期xt看到了序列中每个可能的元素xi != xt,因此能够捕获双向上下文。 此外,由于此目标适合AR框架,因此自然避免了第2.1节中讨论的独立性假设和预调-精调差异。
排列注意
提出的目标仅置换分解顺序,而不置换序列顺序。 换句话说,我们保持原始序列顺序,使用与原始序列相对应的位置编码,并依靠Transformers中的适当注意掩码来实现分解顺序的置换。 请注意,此选择是必要的,因为模型在微调期间只会遇到自然顺序的文本序列。

现在注意,表示hθ(xz <t)不取决于它将预测的位置,即zt的值。
因此,无论目标位置如何,都可以预测相同的分布,这无法学习有用的表示形式(具体示例请参见附录A.1)。为避免此问题,我们建议重新参数化下一个令牌分配以了解目标位置:

where gθ (xz<t , zt ) denotes a new type of representations which additionally take the target position zt as input.

编码预测单词的位置
上面提出的排列语言模型,在实现过程中,会存在一个问题,举个例子,还是输入序列[1, 2, 3, 4]
肯定会有如下的排列[1, 2, 3, 4], [1,2,4,3]
第一个排列预测位置3,得到如下公式P(3∣1,2)
第二个排列预测位置4,得到如下公式P(4∣1,2)
这会造成预测出位置3的单词和位置4的单词是一样的,尽管它们所在的位置不同。
————————————————
版权声明:本文为CSDN博主「zycxnanwang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zycxnanwang/article/details/95245507
Two-Stream Self-Attention


Partial Prediction
虽然置换语言建模目标(3)有几个好处,但是由于置换的原因,它是一个更具挑战性的优化问题,并且在初步实验中导致收敛缓慢。 为了降低优化难度,我们选择仅按分解顺序预测最后的标记。 形式上,我们将z分为非目标子序列z≤c和目标子序列z> c,其中c是切点。 目的是最大化以非目标子序列为条件的目标子序列的对数似然性

请注意,选择z> c作为目标是因为在给定当前分解阶数z的情况下,它在序列中拥有最长的上下文。 使用超参数K,以便选择约1 / K令牌进行预测; 即| z | /(| z | − c)≈K。 对于未选择的标记,无需计算其查询表示形式,从而节省了速度和内存。

预训练阶段和bert差不多,不过去除了Next Sentence Prediction,作者发现该任务对结果的提升并没有太大的影响。输入的值还是 [A, SEP, B, SEP, CLS]的模式,A与B代表的是两个不同的片段。
未完待续。。。
