Abstract
概述:我们提出了一种新的方法,利用最近的发展神经机器翻译(NMT),生成对抗性网络(GANs)和运动生成来生成手语。我们的系统能够从口语句子中生成手语视频。与当前依赖于大量注释数据的方法相反,我们的方法需要最少的注释和骨架级别的注释来进行培训,我们通过将任务分解为专门的子流程来实现这一点。
方法:我们首先将一个NMT网络和一个运动图(MG)结合起来,将口语句子翻译成手语姿势序列。生成的姿态信息用于生成生成模型,生成逼真的手语视频序列。这是第一种不使用经典图形头像的连续符号视频生成方法。
数据集:我们在PHOENIX14T手语翻译数据集上评估了我们的方法的翻译能力。
我们为文本到注释的翻译设置了基线,开发/测试集BLEU-4的分数为16.34/15.26。
我们还将使用广播质量评估指标,定性和定量地演示我们的方法对于多手势者和高清的视频生成功能。
Introduction
和口语一样,手语也有自己的语法规则和语言结构。这使得口语和手语之间的翻译成为一个复杂的问题,它不是简单地将文本映射到手势的逐字逐句的练习。图1演示了语言的标记化和它们的顺序是不同的,它需要机器翻译方法来找到一种口语和手语之间的映射,这需要考虑到它们的语言模型。
SLR的工作: 将手势序列映射为口语,提供手势序列的文本,如【17】【48】,那是因为觉得耳聋的人能自如地阅读口语,因此不需要翻译成手语的错觉。然而,并不能保证一个人的第一语言是,例如,
英国手语,熟悉书面英语,这两种语言是完全不同的。
此外,从口语生成手语是一项复杂的任务,不能通过简单的一对一映射来完成。
与口语不同,手语使用多个异步通道传播信息(在语言学中被称为发音器),这些渠道包括手势(即上半身运动,手的形状和轨迹)和非手动(即面部表情,口型,身体姿势)的特征。
SLP工作1: SLP的问题通常是通过动画化身来解决的,[12][20][38] 当使用动作捕捉数据驱动时,化身可以生成栩栩如生的签名,但是这种方法仅限于预先录制的短语,并且动作捕捉数据的生成是昂贵的。
SLP工作2:另一种方法是将口语翻译成符号注释(代表个体符号的词汇实体)并将每个实体连接到参数表示,如动画角色所需的手形和运动.
存在问题:但是,这种方法有几个问题。将口语句子翻译成符号注释是一项艰巨的任务,因为注释的顺序和数量与口语句子的单词不匹配。此外,通过将手语视为孤立注释的串联,上下文和非手势信息特征被忽略了,这会导致粗糙、错误的翻译,结果在许多基于动画形象的方法中看到指示性的“机器人”运动。
我们的方法:为了推动SLP领域的发展,我们提出了一种新的方法,利用NMT、计算机图形学和基于神经网络的图像/视频生成方法。该方法能够生成手语视频,给定一个书面或口头语言句子。
1)一个编码器-解码器网络从口语文本输入中提取注释概率序列,用来调整一个运动图(MG)找出代表输入的姿态序列。
2)最后,使用这个序列对GAN进行条件处理,生成包含输入语句符号转换的视频

本文贡献:
- 一个基于nmt的网络和一个实现连续文本到姿态转换的运动图的结合
- 基于姿势和外观的生成网络。
- 第一个口语手语视频翻译系统,不需要昂贵的动作捕捉或化身。(废话
这项工作的初步版本在[51]这个扩展的手稿包含一个改进的管道和额外的公式。
我们引入一个MG,在这个过程中,与NMT网络相结合的MG能够实现文本到姿势(text2pose)的转换。
此外,我们还演示了不同外观的多个手势者的生成。
我们还研究了高清(HD)标识的生成
提供了广泛的新的定量和定性评估,探索我们的方法的能力
图3给出了我们的方法的输出的比较(右)到其他基于角色的方法(左和中)
本文的其余部分组织如下:第2节概述了NMT以及使用化身的传统SLP的最新发展。在描述生成图像模型的最新进展之前,我们将解释运动图的概念。
第3节介绍了我们的方法的所有部分。在第4节中,我们在第5节结束之前,对我们的系统进行了定量和定性的评估。
Related work
我们将手语生产(SLP)视为一个从口语到手语的翻译问题。因此,我们首先回顾神经机器翻译领域的最新发展。
与传统的翻译任务不同,它本质上要求生成可视化的内容。通常这是通过动画一个3D头像来实现的。因此,我们将给一个概述过去和目前的符号化身技术。
最后,我们讨论了运动图(MGs)的概念,这是一种在计算机图形学中用于动态动画角色的技术,以及条件图像生成领域
2.1 Neural Machine Translation
NMT采用了基于递归神经网络(RNN)的序列对序列(seq2seq)架构,学习了一个统计模型来在不同语言之间进行转换,Seq2seq[52,10]在口语翻译方面取得了成功。
它由两个rns组成,一个编码器和一个解码器,学习将源序列转换为目标序列。
LSTM、GRU,这两种体系结构都具有允许每个单元只将相关信息传递给下一个时间步骤的机制,从而在长期依赖关系的基础上改进翻译性能
注意力机制 进一步提高长序列的翻译
Bahdanau等人介绍了注意机制。它通过允许解码器观察编码器的隐藏状态,为解码器提供额外的信息。这一机制后来被Luong等人改进
Camgoz等人将标准的seq2seq框架与卷积神经网络(CNN)相结合,将手语视频翻译成口语句子。他们首先使用CNN从视频中提取特征,然后翻译成文本。这可以看作是我们的问题的反面,将文本翻译成pose。
最近,人们探索了一些基于非rnn的NMT方法。ByteNet[27]使用扩张卷积进行翻译,Vaswani等人在[53]中引入了transformer,这是一种纯粹基于注意力的翻译方法
用NMT方法将文本翻译成pose是一个相对未被探索和开放的问题
Ahn等人使用RNN=based的编码器-解码器模型,从文本中生成人体动作的上半身姿势序列,并将其映射到Baxter机器人上,然而,他们的结果是纯粹定性的,依赖于人类的解释。
在我们的工作中,我们首先使用一个带有Luong改进attention和GRU的seq2seq架构,将文本转换为有注释的文本,类似【6】。
然而,在翻译文本成pose的时候我们不使用CNN作为第一步,相反,我们使用解码器在每个时间步长的概率来解决一个运动图形(MG)的手语姿势数据,以获得文本的姿势翻译。
已有seq2seq方法与改进:
两个RNN构成编码-解码网络
LSTM\GRU 实现长时间依赖信息
Luong等人改进的注意力机制
seq2seq框架与CNN的结合
我们的方法:
seq2seq架构:Luong改进attention机制+GRU
不使用CNN——使用MG进行pose的翻译
2.2 Avatar Approaches for Sign Language Production
符号化身可以直接从动作捕捉数据驱动,也可以依赖一系列参数化注释,自21世纪初以来,已经有几个研究项目探索从参数化注释中生成动画的化身。所有这些方法都依赖于使用转录语言对符号视频数据进行注释。
这是由于发音不清晰和不自然的动作,但主要是由于缺少非手动操作,如眼睛凝视和面部表情。重要的意义和上下文就这样丢失了,使得角色很难被理解。此外,前面提到的角色的机器人动作会让观众感到不舒服(恐怖谷效应)。
最近的工作已经开始将非手册集成到注释和动画过程中【14】【15 】 。然而,这些特征的正确排列和表达是一个未解决的问题,这限制了最近的化身,如[38]和[30]
为了使角色更容易理解,并增加观众的接受度,最近的符号角色依赖于从动作捕捉收集的数据 Sign3D
为了使合成签名更真实、可扩展,并避免上述3D头像的问题,我们使用最新的机器翻译、生成图像模型和运动图,直接从弱注释数据生成签名视频
Avatars 存在问题:
1)缺少上下文和非手势信息
2)恐怖谷效应
3)数据采集昂贵
2.3 Motion Graphs
运动图(MGs) 是计算机图形学中用来对角色进行动态动画的图形,它可以表示为由运动捕捉数据构造的有向图,它允许生成新的栩栩如生的序列,在运行时满足特定的目标
MGs是由Kovar等人独立引入的。[31], Arikan等,[2],Lee等,[33]
Kovar[31]通过计算两个点云之间的距离来定义两个帧之间的距离。为了创建过渡本身,运动是对齐的,位置是关节旋转间的线性插值。作为一种搜索策略,使用了分支和界限。
Arikan等人使用关节位置和速度之间的差异以及躯干速度和加速度之间的差异来定义两帧之间的距离,对两个剪辑间的不连续性应用平滑函数。首先对图进行汇总,然后对汇总执行随机搜索,从而搜索图
Lee等人选择了两层方法来表示运动数据。
在底层,所有数据都被建模为一阶马尔可夫过程,其中马尔可夫过程由一个包含帧间转移概率的矩阵表示,概率是通过测量加权关节角和速度的距离得到的.低概率的转变被修剪。混合过渡采用分层运动拟合算法。
高层通过执行聚类分析来概括低层中保留的运动,以便更容易地进行搜索。每个集群表示相似的运动,但是为了捕获帧之间的连接,在每个运动帧上形成一个集群树。整个较高的一层叫做forest
通过将连续的符号序列分割成单独的注释,并通过注释对所有的动作序列进行分组,建立了手语姿态数据的语义模型.这些运动序列构成了MG的节点。
然后,我们使用我们的NMT解码器在每个时间步长的概率来实现节点之间的转换
2.4 Conditional Image Generation
随着深度学习的发展,图像生成领域出现了各种利用神经网络架构的方法
一般神经网络:
陈和Koltun[9]使用基于CNN的级联细化网络生成给定语义标签地图的图像。
类似地,van den Oord et. al.[42]开发了PixelCNN,它根据向量生成图像,可以是图像标记或由另一个网络提供的特性嵌入
Oord et. al.[43]还探索了使用RNNs生成和完成图像
所有这些方法都依赖于丰富的语义或空间信息作为输入,如语义标签映射,否则它们就会受到模糊和空间不连贯的影响。
GAN
自从GANs[21]出现以来,它们被广泛地用于图像生成任务。
Mirza和Osindero[40]通过向生成器和鉴别器提供条件信息,开发了一个条件GAN模型。Radford等人[46]提出了Deep Convolutional GAN (DCGAN),将有条件GAN的一般架构与一组架构约束相结合,例如用strided convolutions代替了spatial pooling。
这些变化使系统更稳定的训练,并很适合生成现实和空间相干的图像的任务。通过对DCGAN模型的扩展,建立了多种条件图像生成模型
值得注意的是,Reed【47】 等人利用文本嵌入和二进制位姿热图,建立了一个系统来生成基于位置信息和文本描述的鸟类图像
VAEs
可变自动编码器(VAEs)提供了一种替代基于gan的图像生成模型的方法。
与经典的自动编码器类似,VAEs由两个网络组成,一个编码器和一个解码器。然而,VAEs约束编码网络遵循一个unit高斯分布。Yan等人开发了一种条件VAE[56],它能够生成空间连贯但模糊的图像,这是大多数VAEbased方法的发展趋势
最近的研究将GANs和
VAEs创建健壮和通用的图像生成模型。Makhzani等人引入了对抗自编码器,并将其应用于监督、半监督和非监督学习中的问题。
Larsen等人结合了VAEs和GANs,可以在无监督的情况下对样本进行编码、生成和比较
Perarnau等人开发了可逆条件GAN,该算法使用编码器来学习输入图像的潜在表示,并使用特征向量来改变人脸的属性
VAE/GAN混合模型已被证明在生成基于人体姿态的图像方面特别受欢迎,如Ma等人的[36]和Siarohin等人的[50]
Ma et al. [36] 以两阶段的过程合成任意姿势的人的图像。将一个人的输入图像和一个提供姿势信息的热图融合到一个网络中的新图像中,在第二个网络中完善它。
Siarohin等人使用了类似的方法,但还使用了仿射变换来帮助改变身体部分的位置。
在图像-图像翻译的子领域,Isola等人引入了pix2pix [25] a conditional GAN,由于其信息丰富的输入和避免完全连接的层,也是第一批产生高清晰度图像内容的竞争者。
基于pix2pix和Johnson等人[26]提出architecture的成功,
Wang等人最近提出了pix2pixHD[54],一种能够产生来自语义标签映射的2048x1024张图像的网络,使用生成器和多尺度鉴别器架构:一个由卷积编码器组成的全局生成器,一组剩余块和一个卷积解码器。
此外,一个类似架构的局部增强器网络提供了来自语义标签映射的高分辨率图像。
三个不同尺度的鉴别器用于区分真实图像和生成的图像
在我们的工作中,我们采用了两种条件图像生成技术:我们建立了一个以人的外貌和姿态为条件的多人符号生成网络,类似于Ma、Siarohin 等人的工作。此外,我们还研究了单签名者高清手势生成。基于王等人的工作
3 Text to Sign Language Translation
我们的text-to-sign-language (text2sign)翻译系统包括两个阶段:
我们训练一个NMT网络,获得一个用于求解生成人体姿态序列的运动图(MG)的注释概率序列(图4中的text2pose)。
然后,一个以编解码器作为鉴别器结构的手势生成网络产生输出手势视频(参见图4中的pose2video)。
3.1 Text to Pose Translation
我们采用了最新的基于RNN的机器翻译方法,即基于注意力的NMT方法,实现口语句子到手语注释序列的翻译。我们使用一个编码器-解码器架构[52]与Luong注意[35]
给定一个口语句子,
SN = fw1;w2;:::;wg, N个单词,我们的编码器映射序列到一个潜在的表示,如
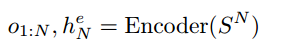
其中o1:N是编码器对每个单词w的输出,he N是被编码句子的隐藏表示。在图5中,编码器用蓝色表示。
这个隐藏的表现形式和编码器的输出然后传递给解码器,它利用一个注意机制,并产生一个注释上的概率分布:
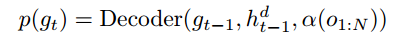
α(.)是注意力函数,gt是时间步t产生的注释,hd−1是前一个时间步解码器的隐藏状态。在译码开始,即t = 1时,hd t−1设为输入语句的编码表示,即h0=hN
我们之所以使用基于注意力的方法而不是普通的基于序列到序列的架构,是为了通过向解码器提供额外的信息来解决长期的依赖问题。
为了训练我们的NMT网络,我们在每一步的注释概率上使用交叉熵损失
我们构建了一个运动图(MG),它允许生成一个给定注释序列的2D骨骼姿态序列。
MG是一个马尔科夫过程,可以用来产生新的运动序列,代表真实的运动,而不是实现一个动画的目标:用一种特定的运动方式从A点到达B点。
MG的标准形式是是运动原语的有限有向图,图中的节点vi 2v对应于一个或多个运动序列(运动原语),以及这些运动原语(xi)上的先验分布函数p(xi),节点的每个运动原语都是节点所代表的运动样式的一个示例。因此,在一个节点中可以有一个可变数量的运动原语,最小值为1。
表示允许从节点vi过渡到vj的一条边ei; j 属于E,存储了一个可变形函数Yi;j = M(xi;xj),这使得混合运动成为可能,以及给定节点vi的运动原语xi,其在节点vj上的概率分布p(xjjxi)
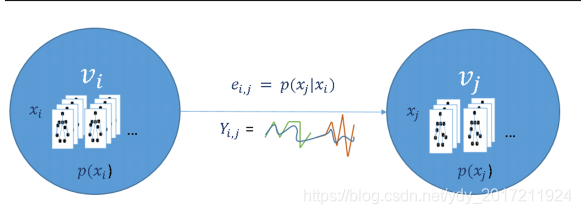
图节点vi和vj包含一个或多个运动原语(由骨骼姿态图表示)xi和xj,以及一个先验分布p(xi)和p(xj)。我们将节点vi和vj之间的转移概率定义为运动原语xj在xi下的概率。在运动原语之间进行平滑。
运动原语需要从一组更大的运动捕获数据中提取。这可以通过识别运动数据中位于运动之间的过渡点的关键帧来实现 如:行走序列中的“左脚撞击地面”动作。然后使用这些关键帧将数据分割成更大的运动原语xi集合,其中每个运动原语是两个关键帧之间的连续运动.
对于更复杂的运动数据集,一种典型的方法是定义骨骼姿态之间的距离度量,可以用来识别可能的过渡点,即那些低于给定阈值的点。阈值设置得足够小,这样两个姿势之间的插值就不会对运动的流畅性造成视觉干扰
在我们的应用中,使用注释边界来自动将手势序列切割成单独的手势,因此|V|等于注释的数量,x g包含手势注释g的示例。
在图形环境中,通过观察原始数据中图形节点之间的转换,可以直接从数据中学习E,然而,在我们的例子中,给定先前生成的注释和编码序列,E是由解码器网络在每个时间步长生成的,如下图:
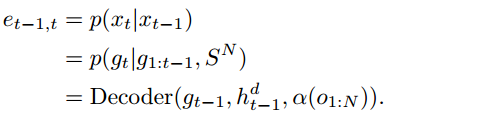
Yi;j的目的是在不同的运动原语之间实现平滑的过渡。在我们的例子中,它对于图中的所有节点都是常数。我们使用SavitzkyGolay过滤器[49](不就是最小二乘吗??您直接说不好吗????)来创建平滑的过渡。这是在搜索图形时动态完成的。SavitzkyGolay滤波器通过将一个低阶多项式拟合到相邻的数据点来平滑运动原语。我们使用5的窗口大小和2的多项式阶来平滑当前运动原语的最后5帧和即将到来的原语的前5帧,这允许我们保留每个运动原语的表达,但避免过渡点的不连续和人工制品。
为了找出口语句子中最可能的动作序列,我们对运动图进行了波束搜索,我们从特殊的x0 = (序列开始)节点开始生成序列。在每个运动步骤,我们考虑一个假设列表,HB = fH1;:::;Hb;:::;HBg,其中B为波束宽度,每一步我们都用一个新的动作来扩展我们的假设:
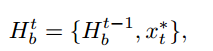
式中,ht b为Hb在步骤t处的运动集合。
我们选择x t的方法是:
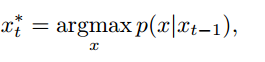
我们继续扩展我们的假设,直到所有的假设都达到特殊的x =
(结束序列)节点。然后我们选择最可能的运动序列H
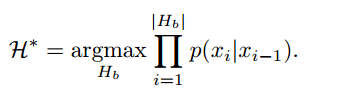
3.2 Pose to Video Translation
pose2video网络结合了卷积图像编码器和GAN。
GAN由两个模型组成,它们被联合训练:生成器G创建新的数据实例,鉴别器D评估这些数据是否属于与训练数据相同的数据分布。G的目标是最大化D错误地预测G生成的样本是训练数据的一部分的可能性,而D试图正确地识别样本是假的还是真的。使用这个最大化的游戏设置,生成器学习生成越来越多的真实样本,最理想的情况是D不能将它们与实际的真相分开。
G是一个编-解码器,用于约束人类的姿势和外观。潜在空间可以是一个固定大小的一维向量,也可以是一个可变大小的剩余块。
一个固定大小的一维向量潜空间使用全连接层,可以生成具有大外观和空间变化的图像,并用于多位手势者(MS)输出。然而,生成空间变化的能力和对完全连接层的需求增加了内存消耗,并限制了生成的图像的输出大小
一个完全卷积的潜在空间,比如一些剩余的层,允许外观的变化,比如从一个姿势标签映射到一个人在那个姿势下的图像,但是不允许大的空间变化。
这使得网络能够传输类似于Wang等人的pix2pixHD的样式。
然而,由于避免完全连接的层和使用一个额外的增强网络,它能够产生清晰的高清晰度输出。
我们研究用于生成高清晰(HD)标志视频的第二种配方
3.2.1 Image Generator
作为生成器的输入,我们将Pt和Ia连接为单独的通道,其中Pt是一个人类姿态标签映射,对MS来说,Ia一代是一个任意的人类主体的持续姿势(基础姿势)的图像。高清信号发生器不能以基本姿态为条件,因为它不允许大的空间变化。相反,它以前一个时间步长的生成图像为条件。除了帮助外观外,这还加强了时间一致性
生成器的输入通过生成器的卷积编码器部分推入并编码到潜在空间中,生成器的解码器部分使用上卷积和大小卷积将潜在空间解码为使用标签映射Pt提供的嵌入骨骼信息的图像。
这就产生了一个图像G(Pt;Ia)在Pt所指示的姿势中的签名者(参见图7)。
在HD手势变体中,增强器网络En被用来提升和细化生成器G生成的输出图像。它的结构与G非常相似,由卷积编码器、剩余块和上卷积解码器组成。
在联合训练这两个网络之前,G和En依次单独训练。
3.2.2 Discriminator
鉴别器D接收生成图像或真实图像,和姿势标签映射P作为输入。在MS中,D还需提供Ia。
D决定图像的真实性。
在MS下,系统针对多个手势者进行训练,则使用Ia来确定生成的图像是否与所需的签名者相似。Pt提供的骨骼信息用于评估生成的图像是否具有所需的关节配置。
对于高清标识的情况,像Wang等人的[54],我们使用一个具有三个尺度的多尺度鉴别器(在我们的例子中为1080x720, 540x360, and 270x180)
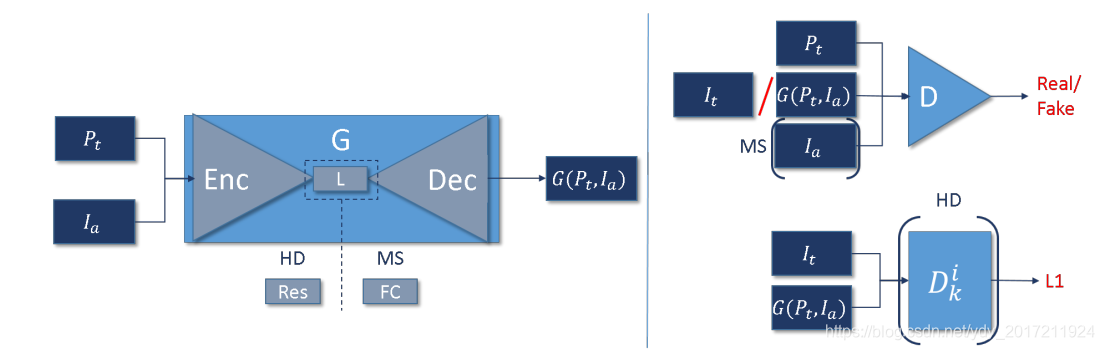
我们的手势生成器G有一个编码器-解码器结构。它可以取决于人的姿势和外表。为此,我们使用了人体姿态标签映射Pt和签名者Ia的框架。HD生成器的潜在空间Res是一组剩余层,而MS生成器的潜在空间FC是使用全连接层编码在一维向量中。我们使用两个损失:一个是使用鉴别器D的对抗性损失,另一个是L1损失。对于MS情况,我们采用基于像素的L1丢失,而对于HD情况,我们匹配从多层D中提取的特征并进行计算
3.2.3 Loss
我们使用GAN的对抗损失,以及生成的图像和地面真实图像之间的L1损失来训练我们的网络。图7给出了一个可视化视图。因此,总损失定义为: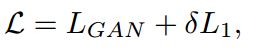
δ为L1的影响。
对于MS生成,我们将Ia赋予发生器和鉴别器来区分签名者。因此,对抗性损失的定义如下: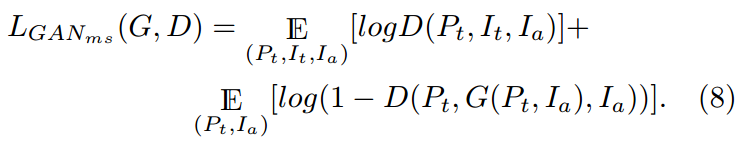
MS L1损耗定义为ground truth与生成图像的绝对像素差之和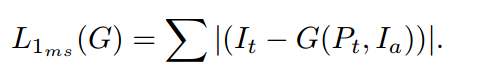
对于HD生成 ,对抗损失为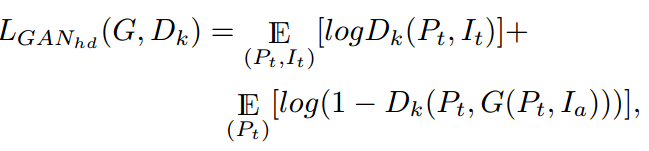
其中k为鉴别器的尺度数量。将所有Dk的对抗性损失合并为: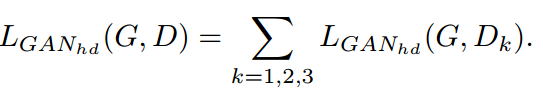
对于HD生成,L1 loss基于[54]中提出的特征匹配loss。从鉴别器的多个阶段提取的特征进行匹配,而不是像素:
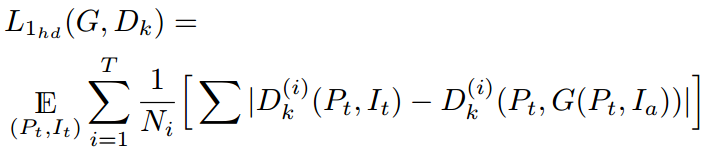
其中T为Dk的层数,i为Dk的当前层数,Ni为每层元素的总数,Dk(i)为的第i层特征提取器
Dk。再次将所有Dk的L1损耗进行求和,得到总的L1损耗: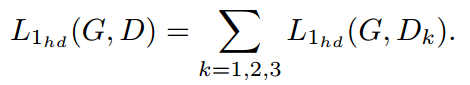
Experiments
我们首先介绍使用的数据集和任何必要的预处理步骤,然后再定量和定性地评估我们系统的所有子部分。使用广播质量评估指标,我们展示了将口语文本转换成注释序列和姿态序列,以及生成多签名者(MS)和高清(HD)签名视频的结果。一组定性的例子展示了整个初步翻译管道的当前状态。
4.1 Datasets
为了实现语音符号视频的生成,需要一个大规模的数据集,手语序列和他们的口语翻译。虽然有大量的广播数据和许多语言注释的数据集,他们缺乏口语句子符号序列(即topic-comment)对齐。然而,最近Camgoz等人发布了《RWTH-PHOENIX-Weather 2014T》(PHOENIX14T)[6],是连续手语识别基准数据集PHOENIX-2014[18]的扩展版本。PHOENIX14T由德语手语(DGS)组成,用于解释天气广播。它包含由9个签名者执行的8257个序列。它的手语词汇量为1066,口语词汇量为2887。每个序列都有符号注释和口语翻译。
MS
我们使用PHOENIX14T训练我们的口语进行手语网络训练。然而,由于数据集中的签名者数量有限,我们使用另一个大型数据集来训练多签名者(MS)生成网络,即SMILE手语评估数据集[13]SMILE数据集包含42位签名者用瑞士德语手语(DSGS)进行了三次重复,完成了100个孤立的符号。虽然SMILE数据集是多视图的,但我们只使用了Kinect颜色流,没有任何深度信息或Kinect的内置姿态估计。
HD
我们训练高清信号生成网络1280x720高清传播资料获取学习识别动态的视觉内容
广播镜头(Dynavis)项目[5]。它由多个视频组成,主题相同,表演连续的英国手语(BSL)序列。口语句子之间不存在符号序列的对齐
使用多个数据集,是因为没有单一的数据集提供文本到签名的转换、不同外观的签名者和高清晰度手势内容。使用来自不同主题领域和语言的数据集证明了我们的方法的健壮性和灵活性,因为它允许我们在专门的数据集之间传输知识。这使得该方法适用于不同的口语和手语之间的翻译,以及其他问题,如文本条件下的图像和视频生成
4.1.1 Data Pre-Processing
为了实现从口语到手语的翻译,我们需要找到表示适当注释的姿势序列。我们使用强制对齐方法通过注释分割PHOENIX14T数据集的连续样本。然后,对于每个注释,我们将所有包含该注释的示例序列归一化。
我们必须将所有签名者的不同体型和大小与选定的目标对象联系起来,此外,我们必须对所有的示例序列进行时间对齐,然后才能找到序列的每个帧的平均表示形式。
为了将不同签名者的骨架与目标对象的骨架对齐,我们使用OpenPose 为序列中的每一帧和目标主体的参考帧提取上半身关键点。
我们将颈部关节处的骨骼对齐,并按肩宽进行缩放。我们使用动态时间扭曲来对序列进行时间对齐,然后对所有样本序列的每一帧的每个关节取平均值来生成一个有代表性的平均序列。这些平均序列构成了MG的节点。我们决定使用平均序列而不是原始示例序列,因为它们提供了更稳定的性能。
我们发现,通过强制对齐获得的注释边界信息的错误会对图中每个节点的样本的质量和正确性产生巨大的变异性。补充材料包含使用平均序列构建的运动图与原始数据之间的示例比较。
4.2 German to Pose Translation
我们提供了将德语句子翻译成中间注释表示的结果,并展示了如何将其与MG相结合,从口语句子中生成人体姿势序列。
如3.1节所述,我们使用了一种用于口语的NMT架构来进行有注释的翻译。
我们的编码器和解码器网络都有4层,每层1000个门控重复单元(GRU),作为一种注意力机制,我们使用Luong等人的方法,因为它利用编码器和解码器的输出在上下文向量计算。
我们使用Adam 优化器训练我们的网络,迭代30次,的学习速率为10 - 5。在GRUs上我们也采用了0.2概率的dropout来规范训练。
在推理过程中,波束解码器的宽度B被设置为3,这意味着每个时间步长都保留了最上面的3个假设。我们发现这个数字是翻译质量和计算复杂度之间的一个很好的折衷。对于text2pose生成,平均时间为每0.79秒翻译一个注释,使用Inter
CoreTM i7-6700 CPU (3.40 GHz, 8MB缓存),大部分时间用于生成姿势映射(0.77秒/注释)
4.2.1 Translating German to Gloss
为了衡量我们的方法的翻译性能,我们使用了BLEU和ROUGE (ROUGE- l F1)评分以及单词错误率(WER),这是机器翻译领域最流行的指标之一。我们测量了不同的ngram粒度上的BLEU分数,即BLEU 1、2、3和4,以便读者更好地了解翻译性能。
我们将我们的Text2Gloss性能与Camgoz等人的glos2text网络[6]进行比较,后者是将符号注释翻译成口语序列的相反任务。我们这样做是因为就我们的知识而言,没有其他直接比较的文本到注释的翻译方法。我们的目标是为读者提供上下文,而不是声称要取代glossary 2text方法[6]。我们的结果如表1所示
Text2Gloss的表现与glos2text网络相当
BLEU和ROUGE评分,以及WER对PHOENIX-2014T开发和测试数据的评分。我们的网络执行Text2Gloss翻译。提供了词汇文本分数作为参考。
而glossary 2text则实现了更高的BLEU-4分,
我们的Text2Gloss在较小的ngram上超过了它的BLEU评分,和ROUGE分数。
我们还通过检验样本Text2Gloss译文来提供定性结果(见表2)。 我们的实验表明,该网络能够从接近于gloss ground truth的文本中生成gloss序列。即使预测的注释序列与地面真实值不完全匹配,网络也会选择意义相近的注释。在报告了这些有希望的中间结果之后,我们现在将展示如何扩展这个方法生成编码符号运动的人体姿态图。
我们的实验表明,该网络能够从接近于gloss ground truth的文本中生成gloss序列。即使预测的注释序列与地面真实值不完全匹配,网络也会选择意义相近的注释。在报告了这些有希望的中间结果之后,我们现在将展示如何扩展这个方法生成编码符号运动的人体姿态图。
4.2.2 Translating German to Pose
我们使用NMT的光束搜索来解决一个MG问题,对德语句子转换成人体姿态序列进行了定性评价。图8显示了两个示例。在这两种情况下,我们都展示了翻译注释的关键框架。
我们使用NMT的波束搜索解决了MG问题,展示了将文本转换为人体姿态序列的结果。我们展示了MS生成器的位姿标签映射。为了可视化,我们压缩了10个深度通道的姿态映射10深度通道二值图像,和反向颜色通道,其中每个连接现在都用一个黑点表示。为了更好地解释,我们添加了连接关节的蓝色骨头.
有趣的是,这两个序列都包含有注释“WIND“,两次在顶部序列和一次在底部序列。每个事件的相关关键帧(顶部序列的关键帧2和6,底部序列的关键帧4)非常相似,显示了特定注释上的姿态调节。
姿态被编码为128x128x10二进制标签映射,其中每个关节都位于10个深度通道中的一个。在4.3和4.4节中,这种类型的映射用于生成手语视频