github:https://github.com/WWangYuHsiang/SMILEtrack
arxiv:https://arxiv.org/pdf/2211.08824.pdf

一、文章贡献:
1、 提出了一种新的reid网络Similarity Learning Module (SLM)
2、SLM组件Image Slicing Attention Block (ISA)
3、提出一种新的检测框和gt框匹配的方法Similarity Matching Cascade (SMC)
二、框架

SMILEtrack采用TBD(先检测后匹配)范式。首先通过检测头得到检测框,然后通过运动近似度和外貌相似度进行数据关联。
三、Similarity Learning Module (SLM) for Re-ID

为了提取更加有区别度的外貌特征,作者提出SLM用于Re-ID。首先通过共享权重的ISA得到Attentined feature,然后再通过fully connected layer得到外貌特征,最后算两者间的相似度。
1、ISA

不同于标准的transformer的一维输入 ,为了减少2维图片的计算量,ISA首先将图片按照左上、右上、左下、右下分成四张小图片A、B、C、D,然后通过卷积层得到Image slicing。分别给四个切片添加一维的位置embedding=1,2,3,4,得到切片序列:S={Sa~Sd}。通过Q-K-V attention块,进行如下计算:
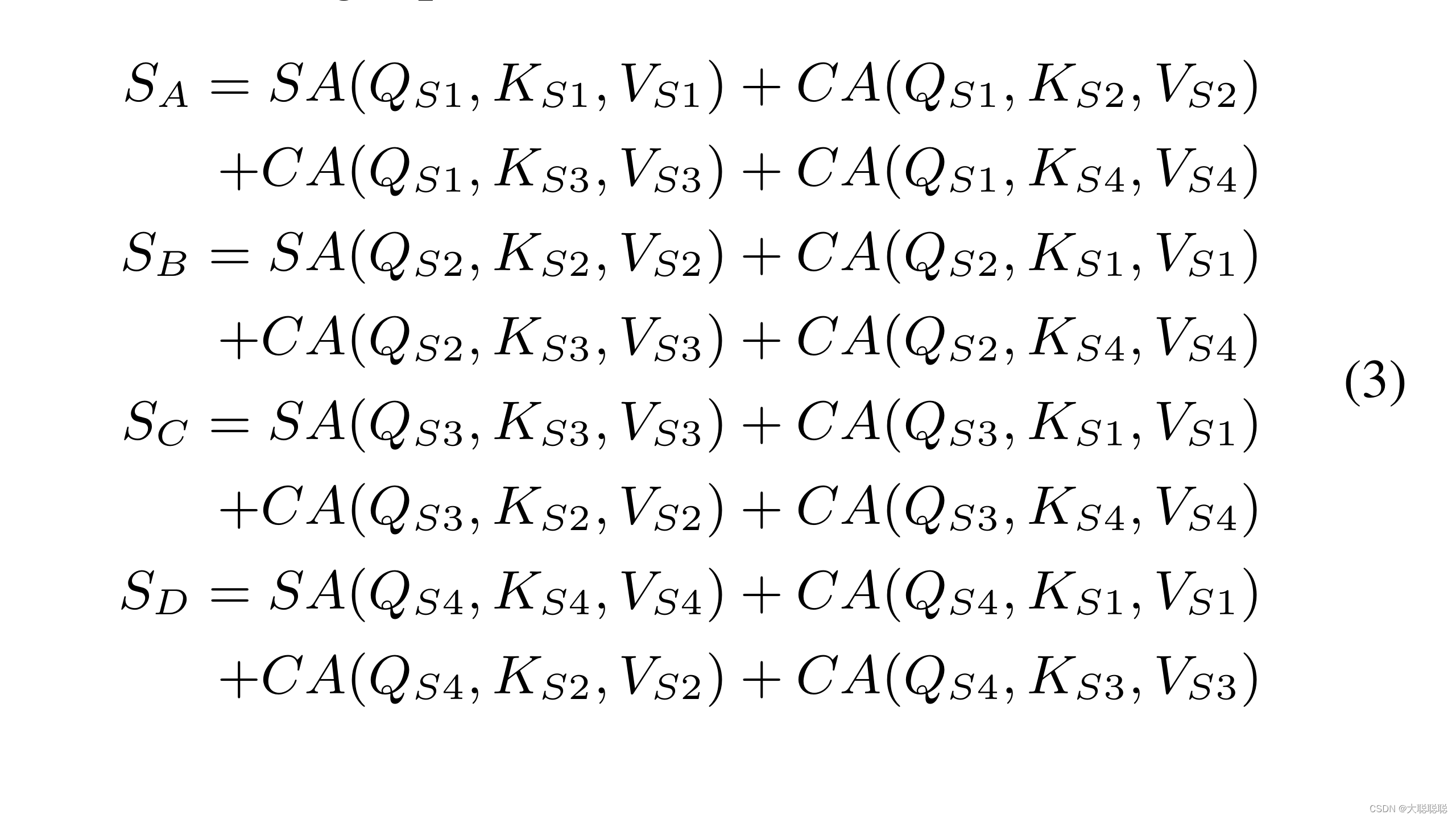
其中SA为self-attention,CA为cross-attention。再将特征拼接在一起得到最后的图像特征。
四、SMC

两阶段匹配:首先匹配高检测分数的检测框,然后匹配剩下的检测分数低的框和剩下的轨迹。
1、第一阶段匹配:
计算运动相似度矩阵、高检测分数的检测框目标和跟踪目标的外貌相似度矩阵,得cost矩阵:

2、第二阶段匹配:
首先计算低检测得分的目标和剩余未匹配轨迹的匹配的运动相似度矩阵。低检测分数的目标往往都是伴随着遮挡的发生,如果与轨迹最近的一帧计算外貌相似度,那得分必然会很低。为了解决这问题,将低检测分数的目标与一个轨迹保存的很多帧外貌特征计算外貌相似度,取最大值作为结果:

通过下面这个式子得到cost矩阵:

3、更新跟踪目标
对于未匹配检测分数大于阈值的目标,将他作为新的跟踪目标。