code :https://github.com/yuantn/MIAL/
文章目录
1. Motivation
目前主动学习(active learning)在图像分类上取得了巨大的进步,但是在目标检测领域,还缺乏一种instance-level的主动学习方法。
在这篇文章中,作者提出了多实例主动学习(MIAL),通过观察instance-level的uncertainty,来为检测器的训练挑选最informative的图片。
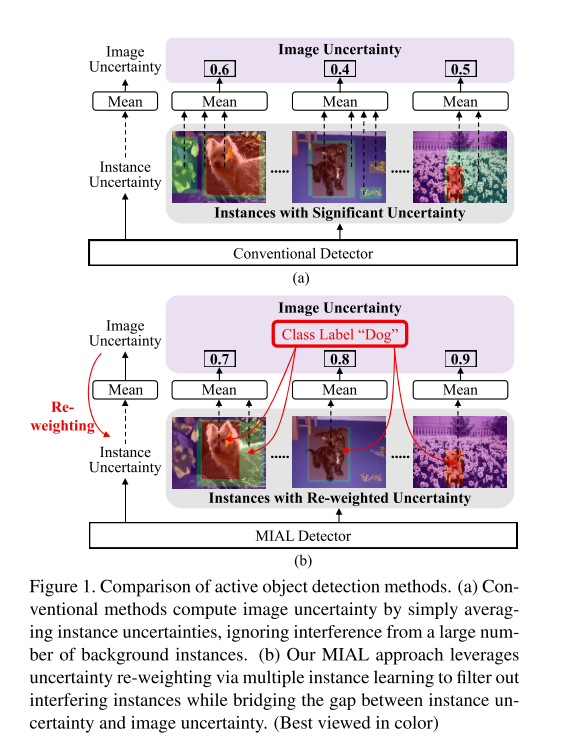
如图1所示,图a表示传统的方法,没有考虑负样本在目标检测中的不平衡问题,负样本产生了背景中的noisy instances,并干扰了image uncertainty的学习。b图表示MIAL方法。通过差异学习(discrepancy learning)和多实例学习(MIL)来learning和re-weighting 实例的不确定性,从而从未标注集合中挑选informative的图片。为了学习instance-level uncertainty,定义了实例不确定性学习(IUL)模型;为了建模instance-level 和image-level的uncertainty,定义了MIL模型。
迭代的IUL和instance uncertainty re-weighting(IUR)缩小了instance-level和image-level的gap,从而挑选出适合检测器的informative images。
2. Contributioin
- 本文提出了MIAL,建议了一个有效的baseline,来建模instance uncertainty和image uncertainty之间的关系,从而挑选最informative的图片。
- 本文制定了instance uncertainty learning(IUL)以及instance uncertainty re-weighting(IUR)模型,在目标检测中过滤噪声的同事,还提供了挑选informative实例的方法。
- 作者将MIAL用于目标检测中的常用数据集中,并且超越了目前的SOTA方法。
3. The proposed Approach
- Uncertainty-based Methods
- Distribution-based Methods
3.1 Overview
对于主动目标检测的基本流程,可以理解为:设定labeled set X L 0 X_L^0 XL0,instance labels以及unlabeled set X U 0 X^0_U XU0,lebeled set中的图片有categories以及bbox用于目标检测的annotation。首先,检测模型M0首先使用labeled set中的图片进行初始化,接着利用初始化后的M0,主动学习旨从unlabeled set X U 0 X^0_U XU0中挑选出集合 X S 0 X^0_S XS0,然后进行手动标注,并且将 X U 0 X^0_U XU0与 X L 0 X_L^0 XL0合并,得到 X L 1 = x L 0 ⋃ x S 0 X^1_L = x_L^0 \bigcup x_S^0 XL1=xL0⋃xS0。这些挑选出来的 X U 0 X^0_U XU0必须是informative,可以尽可能改善网络的性能。利用新挑选的数据集 X L 1 X_L^1 XL1,task model会被重新训练并且更新为 M 1 M_1 M1,检测模型训练和样本选择过程重复几个周期,直到标记图像的数量达到annotation预算。
在主动目标检测中,有2个关键的问题。
- 如何使用在标记集上训练的检测器评估未标记实例的不确定性?
- 如何在滤除噪声实例的同时精确估计图像的不确定性。
(1)how to evaluate the uncertainty of the unlabeled instances using the detector trained on the labeled set?
(2)how to precisely estimate the image uncertainty while filtering out noisy instances?
MIAL可以解决这两个问题,通过引入MIL以及IUL模型。
3.2 Instance Uncertainty Learning
-
Label Set Training
两个实例分类器f1和f2,以及一个regeressor(fr)。给定labeled set,对于每张图片x,网络的损失可以表示为公式1,其中FL表示为focal loss,回归表示为SmoothL1 loss:
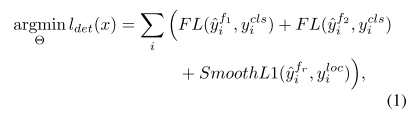
其中 y i c l s , y i l o c y_i^{cls},y_i^{loc} yicls,yiloc表示gt的类别以及bbox, y ^ f 1 = f 1 ( g ( x i ) ) , y ^ f 2 = f 2 ( g ( x i ) ) , y ^ f r = f r ( g ( x i ) ) \hat{y}^{f_1}=f_1(g(x_i)),\hat{y}^{f_2}=f_2(g(x_i)),\hat{y}^{f_r}=f_r(g(x_i)) y^f1=f1(g(xi)),y^f2=f2(g(xi)),y^fr=fr(g(xi))表示分别对于每一个实例i,分类和回归预测的结果。
-
Maximizing Instance Uncertainty
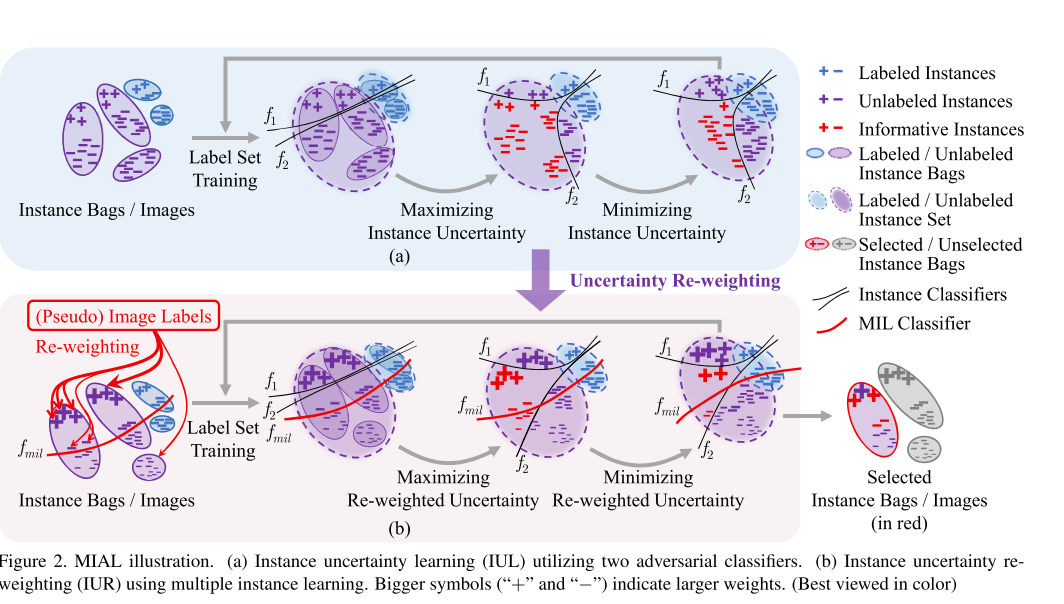
在labeled set可以精确表示unlabeled set之前,2者是存在分布偏差的。informative instances会存在于这些偏差分布地区。为了找到这些实例,作者将f1和f2设置为两种对抗的分类器,它们倾向于在接近类边界的实例上具有较大的预测差异。因此,实例的不确定性可以被定义为f1和f2在unlabeled set上的预测差异。
在最大化过程中, θ g \theta_g θg被固定,因此labeled和unlabeled的实例分布也是固定的。 θ f 1 , θ f 2 \theta_{f_1},\theta_{f_2} θf1,θf2在unlabeled set上做fine-tuned,便于最大化所有实例的predict discrepancy loss。通过优化公式2来完成:
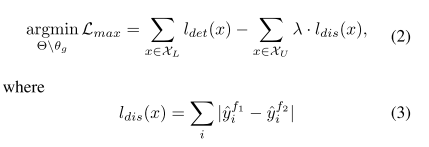
其中公式3表示prediction discrepancy。如图2所示,通过对抗分类器得到的不同预测的informative instances会有更大的预测差异,会获得更大的不确定性 score。
-
Minimizing Instance Uncertainty
在上一步操作后,作者进一步提出最小化预测差异,来对齐labeled 和unlabeled 的实例的分布。在这一过程中, θ f 1 和 θ f 2 \theta_{f_1}和\theta_{f_2} θf1和θf2被固定,通过最小化prediction discrepancy loss,来优化特征提取器参数 θ g \theta_g θg,如公式4所示:
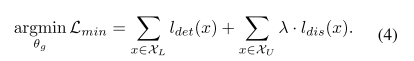
通过最小化预测差值,2个set上的分布差异就会被最小化,并且它们的features会尽可能的对齐。
总结:
在每次主动学习的循环中,max-min预测差值过程会重复好几次,从而使得实例不确定性能被学到,并且在labeled和unlabeled上的实例分布可以对齐。这也是定义了一种无监督的学习陈旭,利用unlabeled set上预测差值的信息来改善网络的性能。
3.3 Instance Uncertainty Re-weighting
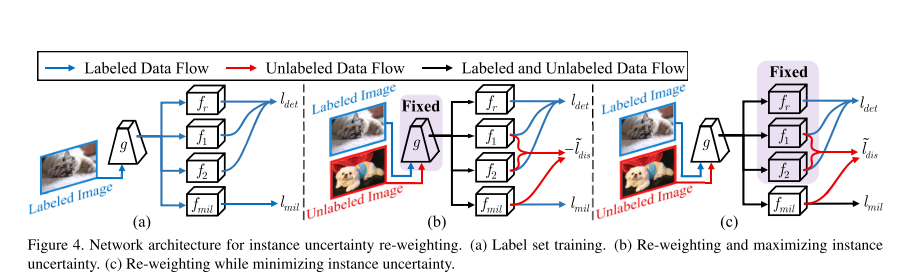
通过了IUL结构以后,可以得到informative instances,然而,在每张图片里面的实例数量太多,实例的不确定性可能不和图片的不确定性一致,一些具有高不确定性的可能是物体或者是难区分的负样本。因此,引入MIL方法,过滤噪声实例,来缩小实例级别和图像级别uncertainty的gap。
-
Multiple Instance Learning
MIL将每张图片作为一个instance bag,并且利用实例分类的预测来估算bag labels。反过来通过最小化图像分类的loss,来re-weights 实例的不确定性得分。作者添加了一个MIL 分类器 f m i l f_{mil} fmil,MIL score用 y ^ i , c f m i l \hat{y}_{i,c}^{f_{mil}} y^i,cfmil表示,是对一张图的多个实例的得分表示, y ^ i , c f m i l \hat{y}_{i,c}^{f_{mil}} y^i,cfmil由公式5计算:
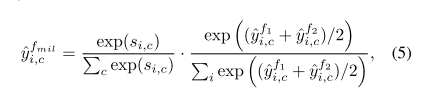
其中, s = f m i l ( g ( x ) ) s=f_{mil}(g(x)) s=fmil(g(x))是一个NxC的得分矩阵。MIL loss可以通过最小化图像分类的loss来定义:
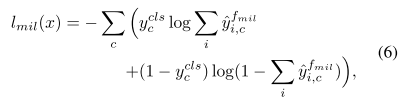
其中, y c c l s ∈ { 0 , 1 } y_c^{cls} \in\{0, 1\} yccls∈{ 0,1},表示图像类标签,可以直接通过实例的类标签 g i c l s g_i^{cls} gicls获得。公式6表示MIL分类器通过大MIL score以及分类输出来激活实例。大的分类输 出,小的MIL scores会被压缩为背景。
-
Uncertainty Re-weighting
MIL loss首先会被应用于label set中,来获得初始的检测器,接下来在unlabeled set中re-weight 实例不确定性(通过公式8所示)。为了保证实例的不确定性可以和图像的不确定性一致,作者对所有的类别的MIL scores进行聚合,得到一个score的向量 w i w_i wi,然后通过公式7,re-weight实例的非确定性:
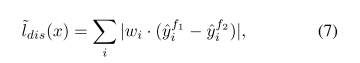
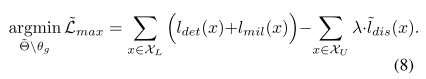
公式4会被优化为公式9:
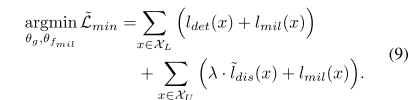
在公式9中,MIL loss用于了unlabel set中,这时候就需要通过使用instances 分类器的输出来估算pseudo image label,如公式10所示:
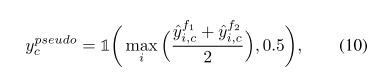
指示函数 1 ( a , b ) \mathcal 1(a,b) 1(a,b)表示的一个二进制函数,当a>b时,return 1,否则reutrn 0。公式10是基于分类器可以识别真实的instances但是容易被复杂的背景给混淆。挑选最大的实例得分来预测伪图像标签,然后利用MIL去除背景的干扰。
3.4 Informative Image Selection
IUL以及IUR过程中,作者通过观察每张图片top K的实例不确定性,从unlabeled set中挑选出最informative的图片,挑选出的图片会在下一次学习循环中加入labeled set。
4. Experiments
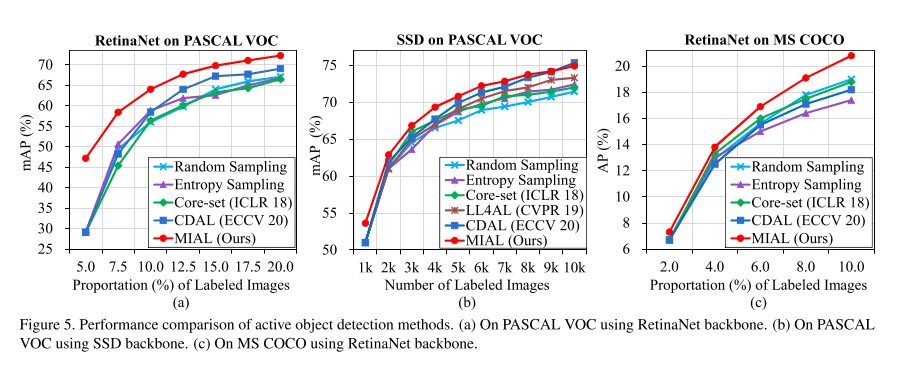
4.1 Compared with SOTA methods
4.2 Ablation Study
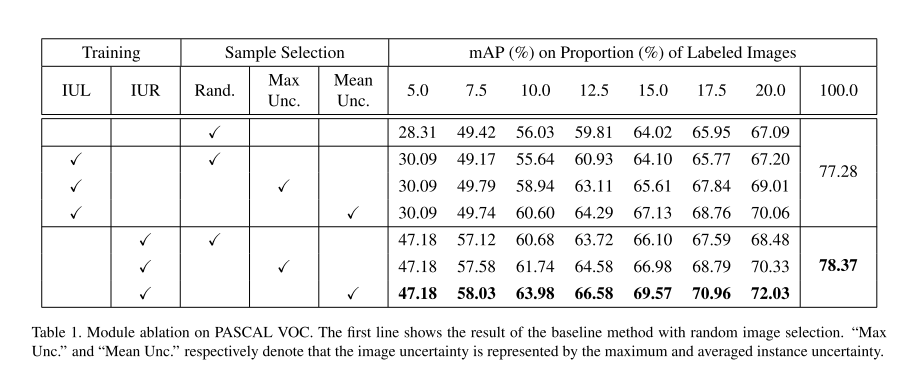
- Mudule ablation on PASCAL VOC
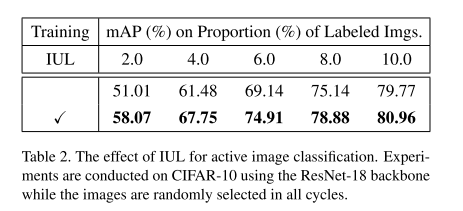
- The effect of IUL for active image classification
- Ablation study on IUR
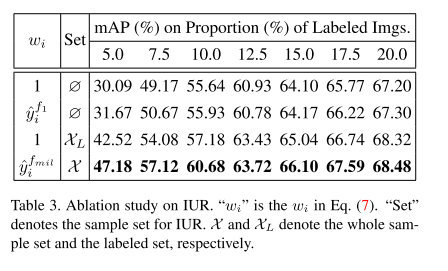
- Comparision of time cost on VOC
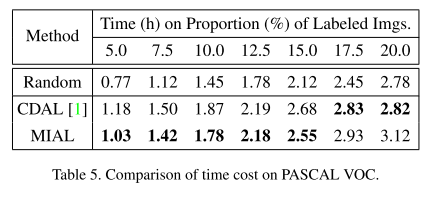
- Performance under different hyper-parameters
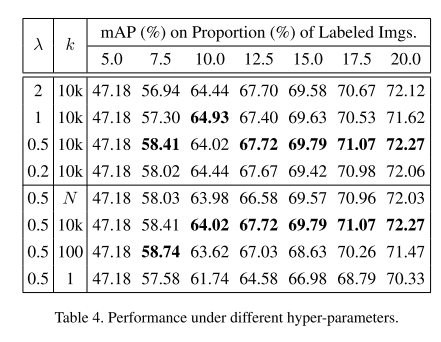
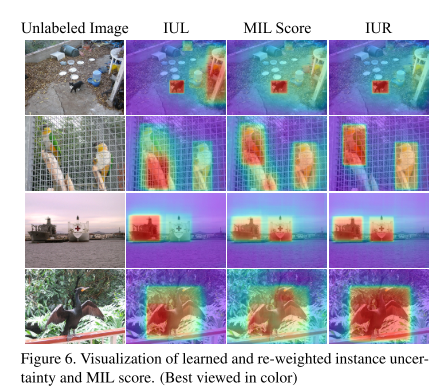
4.3 Visualization Analysis
将一张图上的所有实例不确定性得分统计分析得出的heatmap,用于可视化分析,如图6所示。只用IUL,可能只会挑选到实例的部分位置(第四行),或者完全错过(第三行),亦或者存在背景的干扰(第一行)以及存在真实实例周围物体的干扰。MIL可以压缩背景,IUR利用MIL的得分进行re-weight 实例的不确定性可以更精确的得到实例不确定性的预测值。
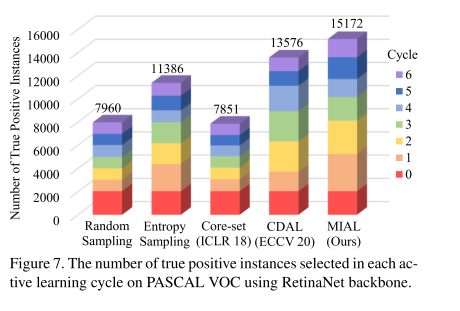
4.4 Statistical Analysis
图7实验分析得出,MIAL在每个cycle中得到的真实样本实例的数量最多。