今天开始整理一些之前看过的论文,一是复习巩固基础,二是可以回过头来想一想有没有新的理解。
论文链接:
Siamese Recurrent Architectures for Learning Sentence Similarity
Learning Text Similarity with Siamese Recurrent Networks
Siamese Recurrent,中文名叫孪生网络,用于比较两段文本之间的相似性,是一种非常常用的网络结构,很多之后的网络结构也在使用这种思想,比如ESIM等。另外这种思想在推荐系统中也有一些使用,比如在itemcf种学习两个item的相似度矩阵,就可以用这种网络。
背景
在深度学习还没火起来之前,大家比较两段文本的相似性,都习惯用词袋模型或者 TF-IDF 模型,但是这些模型有几个很明显的缺点,一是没有用到上下文的信息,而是词与词之间联系不紧密,词袋模型难以泛化。
这种问题直到 LSTM 的出现或者说普及,才被慢慢解决。LSTM 或者说 RNN 模型,由于其天然的结构特点(不了解的同学可以去查阅相关内容,这篇文章不讲 LSTM 原理),可以去适应变成的句子,比如我们要比较两个不同长度的句子的相似性,通过 RNN 可以将它们 encode 成一个相同长度的语义向量,这个语义向量包含了各自句子的语义信息,可以直接用来比较相似性。
Siamese Recurrent Architectures 就是将两个不一样长的句子,分别 encode 成相同长度的向量,以此来比较两个句子的相似性。
是不是听起来很简单,很直观。。。我第一次看的时候也是这么觉得的。这篇论文最早发表在2016年的 AAAI 会议上,其实离我们并不是很遥远。。。有时候甚至觉得,如果我早出生几年,或许我也能想到这个方法。。。(就好像自己早生几百年,就能发现万有引力一样)。不得不佩服这篇工作的前瞻性,来自天才辈出的MIT。
Siamese Recurrent Architectures
第一篇论文的模型很简单,如下所示

简单来说,就是用两个共享权重的 LSTM,去对用 word2vec 初始化的句子 embeding 进行 encode。
输入句子的最终被 encode 为 lstm 的最后一个 time step 的隐层输出。
作者在文章中说得到了各自句子的 encode 向量之后,对于任何一种简单相似度方程具有很好的稳定性,就是说你怎么度量相似都行,反正我的 encode 向量牛逼。
实验中效果最好的度量方法是 Manhattan distance。
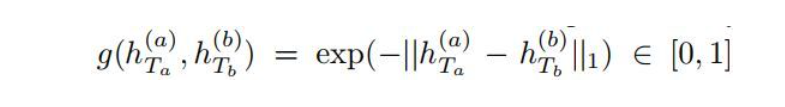
使用L1正则:
L2正则无法修正欧氏距离的梯度消失问题导致的对语义不同的句子误判为同类的error
Siamese Recurrent Networks
第二篇论文和第一篇很像很像,也是共享权值的 lstm,不同之处在于用了双向LSTM,可以看下图。这篇文章的 purpose 是通过比较句子对之间的相似度信息,将变长的文本映射成固定长度的向量。这样得到的向量可以用来作为分类器,也可以寻找相近的 job title(文章中是 Java Developer 和 HR Manager),以及表示学习。

这篇文章在工程实现上也和前一篇文章不同,输入是 character-level,可以解决未登录词的问题。
思考
牛顿说过,他之所以这么牛逼,是因为站在巨人的肩膀上,我们今天看这 2 个网络,觉得它们很简单,也是一样的道理。这两篇论文的模型并不复杂,甚至很简单,但是突出的 idea 是非常值得学习的,现在的很多很多文本匹配的方法,都是在它们的基础上衍生而来。
代码实战:
import keras
from keras.layers import *
from keras import Model
def exponent_neg_manhattan_distance(left, right):
return K.exp(-K.sum(K.abs(left - right), axis=1, keepdims=True))
class Siamese():
def model(self, embeddings_matrix, maxlen, word_index):
left_input = Input(shape=(maxlen,), dtype='int32')
right_input = Input(shape=(maxlen,), dtype='int32')
embedding_layer = Embedding(len(word_index) + 1,
embeddings_matrix.shape[1],
weights=[embeddings_matrix],
input_length=maxlen,
trainable=False)
encoded_left = embedding_layer(left_input)
encoded_right = embedding_layer(right_input)
# two lstm layer share the parameters
shared_lstm = LSTM(128)
left_output = shared_lstm(encoded_left)
right_output = shared_lstm(encoded_right)
malstm_distance = Add(mode=lambda x: exponent_neg_manhattan_distance(x[0], x[1]),
output_shape=lambda x: (x[0][0], 1))([left_output, right_output])
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, amsgrad=True)
model = Model([left_input, right_input], [malstm_distance])
model.compile(
loss='mse',
optimizer=adam)
return model