How Machine Learning Is Solving the Binary Function Similarity Problem [USENIX 2022]
Andrea Marcelli Cisco Systems, Inc.
Mariano Graziano Cisco Systems, Inc.
Xabier Ugarte-Pedrero Cisco Systems, Inc.
Yanick Fratantonio Cisco Systems, Inc.
Mohamad Mansouri EURECOM
Davide Balzarotti EURECOM
精确计算两段二进制代码之间的相似度的能力在许多不同的问题中起着重要的作用。安全、编程语言分析和机器学习等几个研究团体已经在这个主题上工作了五年多,发表了数百篇关于这个主题的论文。人们会期望,到目前为止,有可能回答一些研究问题,这些问题超越了论文中提出的非常具体的技术,而是可以推广到整个研究领域。不幸的是,这一主题受到许多挑战的影响,从可重复性问题到研究结果的不透明,这阻碍了有意义和有效的进展。
在本文中,我们着手对这一研究领域的现状进行第一次测量研究。我们首先将现有的研究体系系统化。然后我们确定了一些相关的方法,这些方法代表了最近由三个不同的研究团体提出的广泛的解决方案。我们重新实现了这些方法,并创建了一个新的数据集(使用不同的编译器、优化设置和三种不同的体系结构编译的二进制文件),这使我们能够执行公平和有意义的比较。这一努力使我们能够回答许多研究问题,这些问题超出了通过阅读个别研究论文所能推断的范围。通过发布我们的整个模块化框架和我们的数据集(以及相关文档),我们也希望在这个有趣的研究领域激发未来的工作。
一句话:系统评估二进制相似度方法
导论
Challenges
第一个挑战是目前既不能重现也不能复制以前的结果。令人遗憾的是,这是安全领域的一个常见问题,而二进制相似性是这个问题的一个特别好的例子。在Haq等人[27]的调查中报告的61个解决方案中,只有12个向其他研究人员发布了他们的工具。即使工件是可用的,它们也经常是不正确的(例如,它们没有实现论文中描述的完全相同的解决方案),不完整的(例如,缺少重要的组件,例如用于特征提取的组件),或者代码甚至可能无法在与其作者使用的数据集不同的数据集上运行。由于重新实现以前的技术非常复杂且非常耗时,因此每个解决方案通常只与以前的几个技术进行比较,这些技术有时甚至不是为了解决相同的问题而设计的,并且在某些极端情况下,只与同一作者的先前论文进行比较。
第二个挑战是评估结果往往是不透明的。不同的解决方案通常是针对略有不同的目标(例如,搜索漏洞vs.发现类似的恶意软件样本),在不同的设置(例如,交叉编译器vs.交叉架构),通过使用不同的相似性概念(相同的代码vs.相同的语义),并在不同的粒度(例如,代码片段vs.整个函数)操作。实验也在不同大小和性质的数据集上进行(例如,firmware vs.命令行实用程序),并通过使用不同的指标(例如,ROC曲线vs. top-n vs. MRR10)报告结果。
前两个挑战的综合影响导致了该领域的极度分散,存在数十种技术,但没有明确了解哪种技术在哪种环境下有效(或无效)。这给我们带来了最后一个挑战:很难理解二进制相似性研究的方向。每个新的解决方案都采用了一种更复杂的技术,或者是多种技术的新组合,很难判断这是由更简单方法的实际限制驱动的,还是由需要说服审稿人相信每个工作的新颖性驱动的。
Contributions
在本文中,我们在这一研究领域进行了第一次系统的测量。我们首先探索现有的研究,并根据所采用的方法对每个解决方案进行分组,特别关注最近基于机器学习的成功技术。然后,我们选择、比较和实现十种最具代表性的方法及其可能的变体。这些方法代表了广泛的趋势,跨越了三个不同的研究社区:计算机安全,编程语言分析,以及机器学习社区。
通过重新实现各种方法(不一定是“论文”),我们分离出现有的“原语”,并在单独使用或相互结合使用时对它们进行评估,以获得见解并确定隐藏在先前作品复杂性中的重要因素,并回答各种开放的研究问题。为了使评估工作更具可比性,我们还提出了一个新的数据集,作为不同方面(如编译器系列、优化和体系结构)的通用基准。
我们的评估突出了几个有趣的见解。例如,我们发现,虽然简单的方法(例如,模糊散列)在简单的设置中工作得很好,但在处理更复杂的场景时(例如跨架构数据集,或多个变量同时变化的数据集),它们就失败了。在机器学习模型中,基于图神经网络的模型在几乎所有任务中都取得了最好的结果,并且在比较推理时间时是最快的。另一个有趣的发现是,许多最近发表的论文在同一数据集上进行测试时都具有非常相似的准确性,尽管有几篇论文声称在技术水平上有所改进。
虽然我们不声称我们的代码或数据集比以前的作品更好或更有代表性,但我们发布了我们的模块化框架,重新实现了所有选定的方法,完整的数据集,以及如何重新创建和调整它的详细说明通过允许社区对单个组件进行实验并直接相互比较,我们希望鼓励和减轻未来对接近这一活跃研究领域感兴趣的研究人员的努力。
方法
The Binary Function Similarity Problem
在其最简单的形式中,二进制函数相似性旨在计算一个数值,该数值捕获一对函数在其二进制表示中的“相似性”,即由编译器生成的构成函数体的原始字节(即机器代码)。请注意,在本文中,我们关注的是使用函数作为代码单元的方法,研究人员也研究了专注于低级抽象(例如,基本块)或高级抽象(例如,整个程序)的技术。
二进制函数相似度已经在一百多篇论文中得到了研究。使情况更加复杂的是,大多数现有的方法不能映射到单一的技术类别,因为它们通常构建在不同的组件之上。
Measuring Function Similarity
直接比较与间接比较 我们可以将测量函数相似性的技术分为两大类。第一类解决方案通过考虑原始输入数据或实现某种特征提取来实现函数对的直接比较。这些解决方案通常需要了解两个看似不相关的值可以表示相似的函数,反之亦然,接近的值不一定表示相似的东西。当从二进制函数中提取的特征不能通过使用基本相似性度量直接进行比较时,就会出现这种情况,因为它们可能没有在线性空间中表示,或者可能在相似性得分上没有等效的权重。因此,研究人员建议使用机器学习模型来确定两个函数是否相似,并给出一组提取的特征作为输入。有几种方法可以通过利用贝叶斯网络[2]、卷积神经网络[44]、图匹配网络(GMN)[40]、规则前馈神经网络[67]或它们的组合[37]来实现这种类型的相似性。在这些情况下,该模型用于输出一对函数之间的相似性得分。
为了找到类似的函数,这些方法需要搜索整个数据集,并将查询函数的特征与数据集中的每个条目进行比较,这不是一个可扩展的解决方案。出于这个原因,许多方法实现了索引策略,通过诸如基于树的数据结构、局部敏感散列 (近似最近邻搜索)、bloom过滤器、基于更简单数据的自定义预过滤器、聚类技术,甚至分布式搜索方法(如map-reduce[15])来预过滤潜在的相似候选。
第二类解决方案实现了间接比较技术。这些方法将输入特征映射为“浓缩”的低维表示,可以使用距离度量(如欧几里得距离或余弦距离)轻松地相互比较。这些解决方案允许高效的一对多比较。例如,如果需要将一个新函数与整个数据集进行比较,可以首先将存储库中的每个函数映射到其各自的低维表示(这是一次性操作),然后对新函数执行相同的操作,最后通过使用近似最近邻等有效技术比较这些表示。
模糊哈希和嵌入 低维表示的一个流行的例子是模糊散列。模糊哈希是由与传统加密哈希不同的算法产生的,因为它们被有意设计为将类似的输入值映射到类似的哈希。结论是输入原始字节的微小变化会显著影响生成的散列。然而,即使普通模糊哈希可能不适合函数相似性,一些方法(如FunctionSimSearch[18])已经提出了更专门的哈希技术来比较两个函数。
另一种流行的低维表示形式依赖于嵌入。这个术语在机器学习社区中很流行,指的是一个低维空间,在这个空间中,语义上相似的输入被映射到彼此接近的点,而不管输入在其原始表示中看起来有多么不同。机器学习模型的目标是学习如何产生嵌入,使相似函数之间的相似性最大化,并使不同函数之间的相似性最小化。在文献中,我们可以识别出两种主要类型的嵌入:一种试图总结每个函数的代码,另一种试图总结它们的图结构。
代码嵌入 许多研究者试图利用现有的自然语言处理(NLP)技术,通过将汇编代码作为文本处理来解决二值函数相似问题。这些解决方案处理令牌流(例如,指令、助记符、操作数、规范化指令),每个代码块输出一个嵌入,每个指令输出一个嵌入,或者两者都输出。
第一类方法(如Asm2Vec[14]和[64])基于word2vec[52,53],这是自然语言处理领域的一种知名技术。尽管这些模型不是为跨架构嵌入生成而设计的,但它们可以同时在不同的指令集上进行训练,学习不同语言的语法(但不能跨语言映射语义),或者它们可以应用于中间语言之上。
第二种解决方案基于seq2seq编码器-解码器模型[69],该模型允许将不同架构的语义映射到相同的嵌入空间,从而学习跨架构的相似性。
第三种类型的模型建立在BERT[12]之上,这是基于NLP中最先进的预训练模型[71]。例如,OrderMatters[78]使用在四个任务上预训练的BERT模型来生成基本的块嵌入,而Trex[60]使用分层转换器和掩码语言建模任务来学习近似的程序执行语义,然后将学习到的知识转移到识别语义相似的函数。
汇编代码嵌入通常受到它们可以处理的不同指令的数量(所谓的词汇表外问题(OOV))以及可以作为模型输入提供的最大指令数量的影响。因此,某些方法计算指令级嵌入,基本块嵌入或函数级嵌入。指令或基本块嵌入有时利用其他算法(如最长公共子序列)来计算函数相似性,或者它们被用作更复杂模型的一部分。
图嵌入 另一项研究建立在计算图嵌入的机器学习方法上。这些非常适合捕获基于函数控制流图的特性,本质上是跨架构的。这些嵌入可以通过自定义算法或更复杂的机器学习技术生成,例如图神经网络(GNN)。最近来自机器学习社区的一些方法提出了GNN的变体,例如GMN。这些变化能够在向量空间中产生可比较的嵌入,其特殊性在于这些嵌入对作为模型输入的两个图中的信息进行编码。
图嵌入方法还经常将每个基本块的信息编码到图的相应节点中,以增加表达性。例如,一些解决方案为每个节点计算一组属性,从而产生有属性控制流图(attributecontrolflow Graphs, ACFG), ACFG可以手工设计[24,76],也可以以无监督的方式自动学习[45]。其他作者利用前面讨论的一些技术利用其他嵌入计算层(例如,在基本块级别[45,78,79])。
Function Representations
二进制函数本质上是与特定于体系结构的机器码和数据相对应的字节流。从这个原始输入开始,研究人员使用了许多方法来提取更高级的信息,这些信息可以用来判断两个函数是否来自相同的源代码。该列表按抽象级别的增加排序,包括以下类别。
(1) Raw bytes 一些解决方案直接使用原始二进制信息作为相似性度量的起点
(2) Assembly 汇编指令是由反汇编器获得的,当可以根据指令大小或操作数以多种不同的方式对操作进行编码时,汇编指令是有用的
(3) Normalized assembly 汇编代码通常对常量进行编码
(4) Intermediate representations 有些方法通过将二进制表示提升到中间表示(IR),在更高的抽象级别上工作
(5) Structure 许多方法试图捕捉给定函数的内部结构,或者函数在整个程序中扮演的角色
(6) Data flow analysis 在程序集级别的算术表达式的实现可以采用不同的形式来实现相同的语义
(7) Dynamic analysis 一些方法依赖于动态分析
(8) Symbolic execution and analysis 与具体的动态执行相反,一些方法依赖于符号执行来完全捕获被分析函数的行为,并确定其输入和输出之间的关系
Selected Approaches
我们工作的主要贡献之一是为一些关键方法提供参考实现,并通过在公共和综合数据集上进行实验来比较它们。理想情况下,人们会评估尽可能多的方法,但显然,重新实现它们是不可行的。同样重要的是要明白,虽然有数百篇关于该主题的论文,但其中许多都是相同技术的小变化,而新颖解决方案的数量明显较少。
可伸缩性和现实世界的适用性。我们对有可能扩展到大型数据集的方法感兴趣,这些方法可以应用于现实世界的用例。因此,我们不评估那些固有的缓慢且只关注直接比较的方法,例如基于动态分析、符号执行或高复杂性图相关算法的方法。
关注有代表性的方法,而不是特定的论文。有许多研究工作提出了相同方法的小变化——例如,通过重用以前的技术,同时稍微改变使用的特征。这通常会导致相似的总体精度,这使得它们在我们的比较中不那么有趣。
覆盖不同的社区。对二值函数相似度问题的研究贡献来自不同的研究团体和学术界和工业界。
优先考虑最新趋势。虽然这一研究领域的第一个贡献可以追溯到十多年前,但最近兴趣激增。
在过去十年中发表的许多论文中,只有一小部分符合上述标准。根据我们的分析,我们确定了30种技术,如图1所示,然后我们从中选择了10种具有代表性的解决方案用于我们的研究。
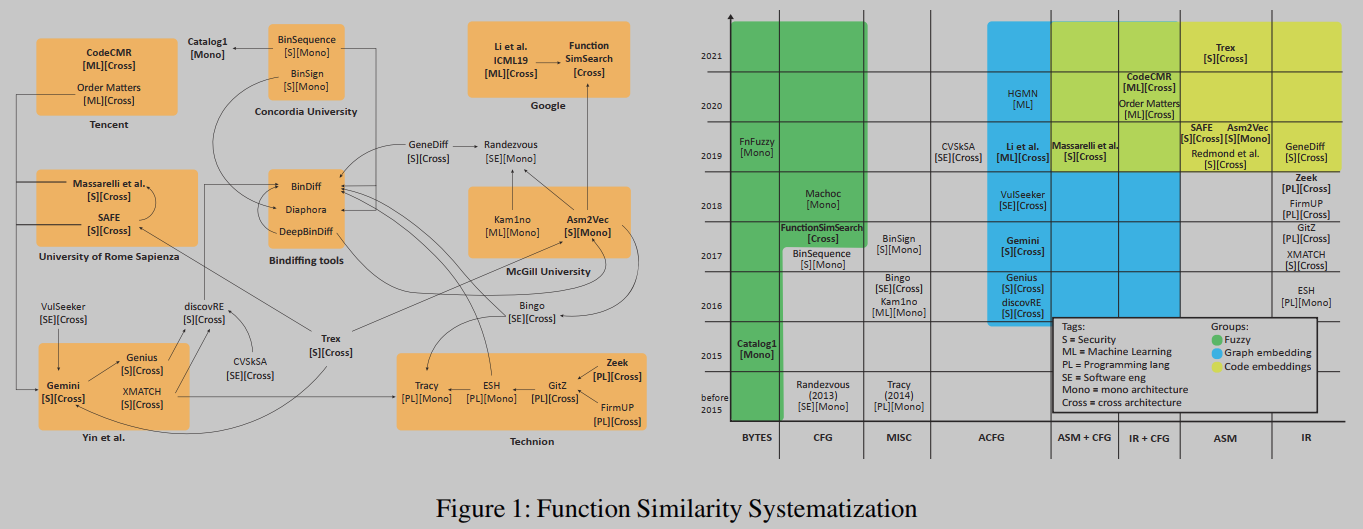
图1左侧的图表显示了根据各自研究小组聚类的方法。这些团体来自学术界和工业界——谷歌和腾讯在这一领域都非常活跃。边线代表其他的解决方案,每篇论文将其结果与之比较。例如,Gemini和Genius之间的箭头表示作者将Gemini的结果与Genius先前获得的结果进行了比较(两者来自同一组)。图1的右侧部分在Y轴上显示发布的时间轴,在X轴上显示不同类型的输入数据。然后根据计算相似度的不同方法将这些方法聚类为三大类,即模糊哈希、图嵌入和代码嵌入。
这两个图都使用标签(括号内)来标识社区([S]安全、[PL]编程语言、[ML]机器学习和[SE]软件工程)。我们还使用[Mono]和[Cross]标签来表示所提出的方法分别关注于单架构场景还是跨架构场景。
即使图1中的图表并不全面,只显示了我们选择的论文,它也再次描述了几篇论文如何仅与之前有限的一组方法进行比较。我们还可以从这些图中提取出其他有趣的信息。首先,在中间框中分组的二进制区分工具都是为直接比较两个二进制文件而设计的(例如,它们使用调用图),并且它们都是单一架构的。其次,图表显示,不同的社区往往是相当封闭的,他们很少与其他领域的论文进行比较。这是推进函数相似度研究的明显局限性,我们希望本文能够促进不同领域之间的合作。最后,我们可以找出一些开创性的论文,如Gemini[76]和discoverRE[20],这些论文在其他研究中被重新实施和广泛测试。这些工作显然激励了其他研究人员提高技术水平。
右边的时间轴图显示了一个明显的趋势:解决方案的复杂性和机器学习的使用随着时间的推移而增长。我们使用这些信息和图中描述的关系来选择10个最先进的解决方案,这些解决方案是可伸缩的、具有代表性的和最新的。与此同时,我们试图最大化研究团体之间的差异。




实验
Implementation
本研究的目标之一是在不同的方法之间进行公平的比较。出于这个原因,我们以统一的方式实现了评估的每个阶段,包括二进制分析、特征提取和机器学习实现。这样,就有可能建立一个共同的基础,对不同的方法进行有意义和公平的比较。
对于二进制分析阶段,我们使用IDA Pro 7.3,而对于特征提取,我们依赖于使用IDA Pro api, Capstone和NetworkX的一组Python脚本。我们在Tensorflow 1.14中实现了所有的神经网络模型,唯一的例外是Trex[60],它是建立在Fairseq[57]之上的,Fairseq是PyTorch的序列建模工具包。最后,我们使用Gensim 3.8[65]实现Asm2Vec[14]并运行指令嵌入模型[45,49]。
在这个过程中,我们采用了统一的实现来最小化计算差异,并引入了几个代码优化。当代码不可用时,我们联系了作者,但我们要么没有得到答复,要么得到有限的支持。Zeek[67]和Asm2Vec[14]两种方法已经完全重新实现,而CodeCMR由于模型的高度复杂性和几个未在本文中讨论的“隐藏”变量,作者对其进行了测试。
我们所有实现的其他技术细节,以及我们联系各自作者的努力和关于使用预训练模型的考虑的信息,可在[47]中找到。

Datasets
我们创建了两个新的数据集,Dataset-1和Dataset-2,旨在捕捉现实世界软件的复杂性和可变性,同时涵盖二进制函数相似性的不同挑战:(i)多个编译器家族和版本,(ii)多个编译器优化,(iii)多个架构和位,以及(iv)不同性质的软件(命令行实用程序与GUI应用程序)。我们使用数据集1来训练机器学习模型,并使用两个数据集来测试评估的方法。

根据我们对函数相似性的定义,我们禁用了函数内联来比较来自完全相同源代码的函数:函数内联实际上是在原始源代码中添加的代码,它可能会污染我们的结果并导致误导性的结论。

为了社区的利益和方便未来在该领域的工作,我们向公众发布了完整的数据集,可在[47]中获得。我们还发布了用于编译它们的脚本和补丁,以便未来的研究人员可以重新创建数据集,并在我们的工作基础上进行构建。
Fuzzy-hashing Comparison
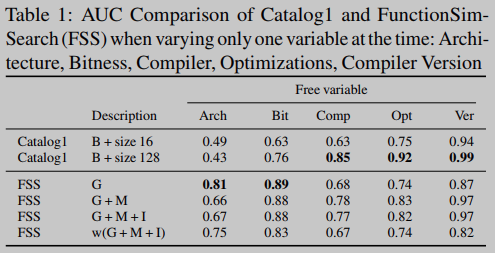
Catalog1使用原始字节作为输入特征和不同的签名大小(即哈希函数的数量):我们显示了两个变体的结果,一个大小为16,另一个大小为128。相比之下,FunctionSimSearch (FSS)使用graphlet (G)、助记符(M)和即时性(I)的组合:我们通过增量启用不同类型的输入特征来进行不同的测试,包括它们的加权线性组合 w w w。
由于模糊哈希方法不受训练阶段的影响,因此我们使用它们来对每个编译变量如何影响二进制函数的比较进行有针对性的评估。因此,对于这些方法,我们首先执行多个实验,其中我们改变一个变量(即,编译器家族,版本,选项,体系结构和位),而我们保持其余的不变。表1中的结果清楚地表明,当一次只考虑一个自由变量时,即使是模糊哈希这样的简单方法也是有效的:“原始”字节被证实是相同架构比较的好特性,而graphlet在跨架构比较中是有效的。对于Catalog1,签名大小越大,性能越好,但它们受到实现中包含的散列函数总数的限制。
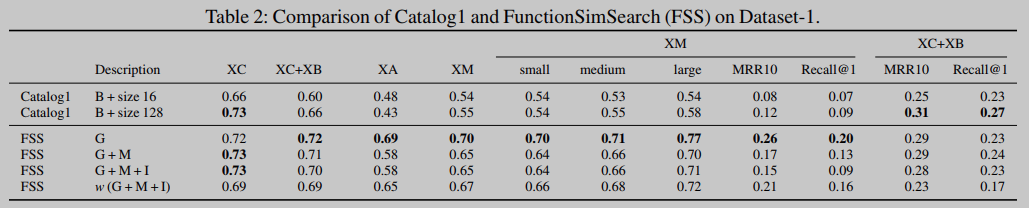
然后,我们用前面提出的六个任务来评估这两种方法。表2和表4显示了数据集1和数据集2上的结果:同时拥有多个自由变量是一个更加困难的问题,简单的方法不再有效。在XC任务中(表2),Catalog1和FSS具有相同的AUC。对于FSS,除了XC和XO之外的所有任务中,仅使用graphlet (G)配置是最好的,在XC和XO中,使用带有助记符(G+M)的graphlet具有更高的AUC。
Machine-learning Models Comparison
我们通过使用从dataset -1中提取的公共训练数据集(Trex除外[60])评估所有选择的方法,并使用与XM任务相似的标准来创建正样本和负样本。然而,重要的是要注意,通过使用特定于任务的训练数据,可以进一步改善每个任务的结果。我们确实执行了这个评估,但我们忽略了结果,因为我们注意到在最通用数据(XM)上进行训练可以获得接近每个任务最佳的总体性能。
比较机器学习模型,特别是深度神经网络,是一项具有挑战性的任务,因为有几个变量可能会影响最终结果,包括模型的实现和配置(例如,层数或循环神经网络的类型),不同的超参数(例如,学习率和批大小),损失函数,优化器和训练时代的数量。为了在我们的比较中尽可能保持一致,所有模型都使用从256,625个唯一二进制函数中提取的相同随机生成的数据进行训练。此外,我们进行了大量的实验来评估不同的特征集、不同的模型配置、超参数和损失函数。每个模型的结果都可以通过使用广泛的网格搜索方法来改进,我们提出的结果可以用作未来工作的起点。
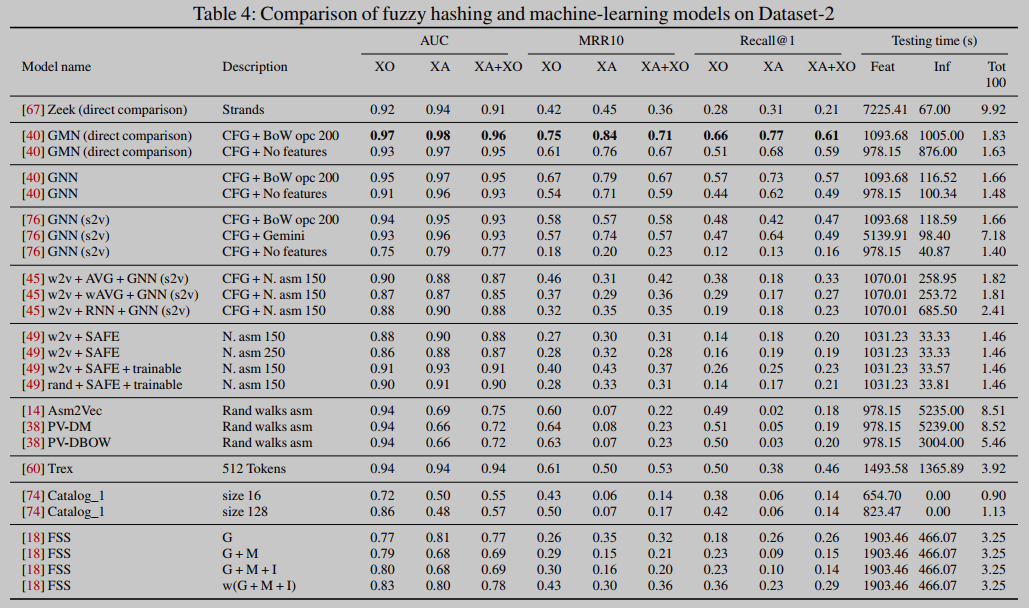
表3和表4显示了在两个数据集上测试模型及其各自变体的结果。表8包含了一些关于模型及其训练的一般信息,例如参数的数量、批大小、epoch的数量以及每个epoch的训练时间。
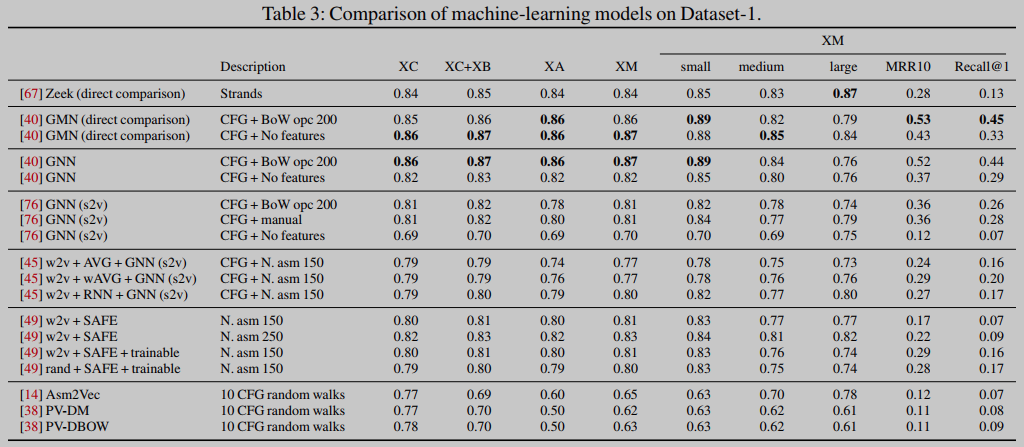
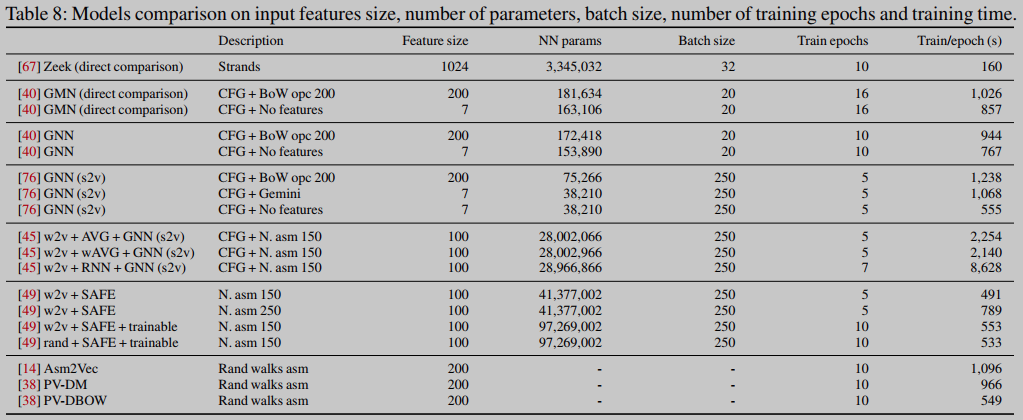
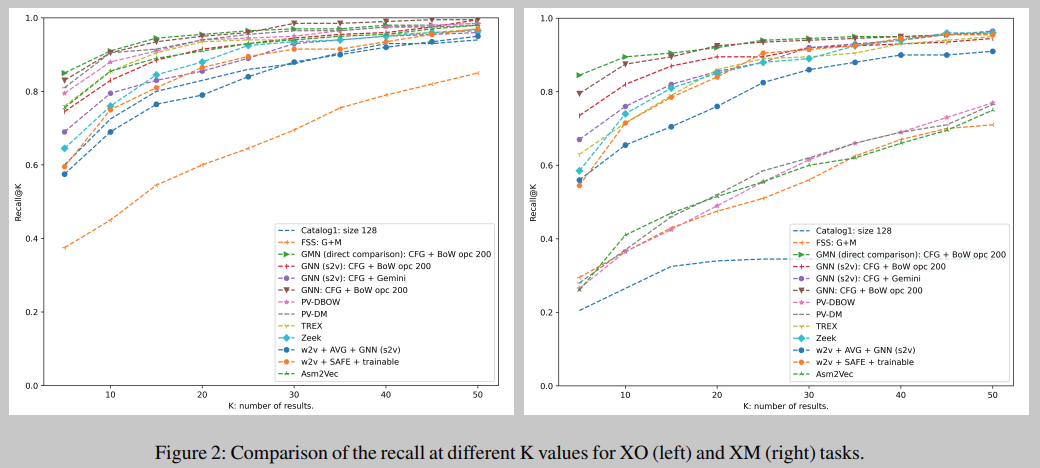
结果表明,在产生函数向量表示(即嵌入)的模型中,来自[40]的GNN在所有指标和所有任务中都达到了最佳值。我们还注意到,大多数机器学习模型在AUC上的表现非常相似,但在排名指标(MRR10和recall@1)上却有所不同,如图2所示。然后,对于其他嵌入模型,SAFE[49]提供的AUC优于具有无监督特征的GNN[45],并且在一个特定配置下的AUC略好于Gemini[76]。对于执行直接比较的方法,[40]中的GMN是所有任务中表现最好的模型,而Zeek的AUC略低(除了大型函数),但MRR10和recall@1要低得多。
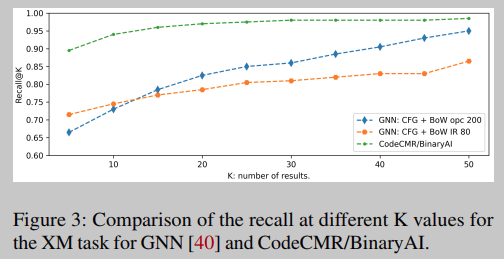
如表5所示。使用IDA微码指令的BoW的GNN模型比使用操作码的BoW的GNN模型具有更高的AUC,但第二个模型对于大K值具有更高的召回率(图3)。一般来说,BinaryAI/CodeCMR模型的所有指标都高于我们测试的其他模型。如果这些结果得到社区独立研究的验证,这可能是一个非常有前途的研究方向。

Vulnerability Discovery Use Case
作为安全应用程序的一个示例,我们在漏洞发现任务上测试了所有模型。为此,我们从OpenSSL1.0.2d中选择了10个易受攻击的函数,总共覆盖了8个cve。作为目标,我们选择了嵌入在两个固件映像中的libcrypto库:Netgear R7000 (ARM 32位)和TP-Link Deco M4 (MIPS 32位)。[47]中包含了影响每个固件映像的漏洞的详细信息。我们为四种架构(x86、x64、ARM 32位、MIPS 32位)编译了十个易受攻击的函数,并进行了排名评估,类似于我们在之前的测试中提出的评估。在评估漏洞发现结果时,我们仅将特定固件映像的易受攻击函数用作查询。
结果如表7所示: 我们使用MRR10作为比较度量来评估每个模型如何对每个查询函数的目标脆弱函数进行排序。

然而,与Netgear R7000相比,具有自定义权重的FSS型号在x64比较中具有最高的MRR10。我们使用了代码中附带的权重,这些权重已经针对OpenSSL的比较进行了优化。这证明FSS实现的优化过程具有实际用例,但它不能扩展到其他配置。表7还显示了不同体系结构之间的比较,特别是Netgear的ARM32列和TP-Link的MIPS32列显示了相同体系结构的比较。Netgear R7000固件为ARM 32位编译,而TP-Link Deco-M4为MIPS 32位编译:这显示了Asm2Vec在相应列中具有高MRR10值的原因。最后,表6包含了Netgear R7000图像的脆弱函数的实际排名结果,可以看出在实践中,较高的MRR10值可能隐藏着较低的排名。

总结
Discussion
与更简单的模糊哈希方法相比,新的机器学习解决方案的主要贡献是什么? 深度学习模型提供了一种学习函数表示(即嵌入)的有效方法,强制在不同类型的函数之间进行空间分离。与模糊哈希方法不同,机器学习模型即使在多个编译变量同时发生变化时也能实现高精度,并且它们受益于构建在编译选项定义的可靠基础真理之上的大型训练数据集的优势。
不同的特征集的作用是什么? 结果表明,机器学习模型类型的选择,特别是GNN和损失函数的选择与输入中的特征同样重要。使用基本块特征(例如,ACFG)可以提供更好的结果,但是在精心手工设计的特征和更简单的特征(例如基本块操作码的单词包)之间存在很小的区别。
不同的方法在不同的任务中效果更好吗? 特别是,跨体系结构比较是否比使用单一体系结构更困难? 我们的评估表明,大多数机器学习模型在所有评估任务上的表现非常相似,无论是在同一架构还是跨架构中。
有没有什么特定的研究方向看起来更有希望成为未来设计新技术的方向? 结果表明,深度学习模型对于不同的函数相似度任务具有可扩展性和精度要求,特别是由于能够学习适合于多个任务的函数表示。虽然GNN模型提供了最好的结果,但还有几十种不同的变体需要测试。
References
[2] Saed Alrabaee, Paria Shirani, Lingyu Wang, and Mourad Debbabi. Fossil: a resilient and efficient system for identifying foss functions in malware binaries. ACM Transactions on Privacy and Security (TOPS),21(2):1–34, 2018.
[12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186. Association for Computational Linguistics, 2019.
[14] Steven H. H. Ding, Benjamin C. M. Fung, and Philippe Charland. Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization. In 2019 IEEE Symposium on Security and Privacy (SP), pages 472–489, San Francisco, CA, USA, May 2019. IEEE.
[18] Thomas Dullien. Searching statically-linked vulnerable library functions in executable code . https://googleprojectzero.blog
spot.com/2018/12/searching-statically-linked-vulnerable.html.
[24] Qian Feng, Rundong Zhou, Chengcheng Xu, Yao Cheng, Brian Testa, and Heng Yin. Scalable Graph-based Bug Search for Firmware Images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 480–491, Vienna Austria, October 2016. ACM.
[37] Nathaniel Lageman, Eric D Kilmer, Robert J Walls, and Patrick DMcDaniel. Bindnn: Resilient function matching using deep learning. In International Conference on Security and Privacy in Communication Systems, pages 517–537. Springer, 2016.
[40] Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. Graph matching networks for learning the similarity of graph structured objects. In International conference on machine learning, pages 3835–3845. PMLR, 2019.
[44] Bingchang Liu, Wei Huo, Chao Zhang, Wenchao Li, Feng Li, Aihua Piao, and Wei Zou. adiff: cross-version binary code similarity detection with dnn. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, pages 667–678, 2018.
[45] Luca Massarelli, Giuseppe A. Di Luna, Fabio Petroni, Leonardo Querzoni, and Roberto Baldoni. Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis. In Proceedings 2019 Workshop on Binary Analysis Research, San Diego, CA, 2019. Internet Society.
[47] Andrea Marcelli, Mariano Graziano, Xabier Ugarte-Pedrero, Yanick Fratantonio, Mohamad Mansouri, and Davide Balzarotti. How Machine Learning Is Solving the Binary Function Similarity Problem — Artifacts and Additional Technical Details. https://github.com/Cisco-Talos/binary_function_similarity.
[49] Luca Massarelli, Giuseppe Antonio Di Luna, Fabio Petroni, Leonardo Querzoni, and Roberto Baldoni. Safe: Self-attentive function embeddings for binary similarity. In Proceedings of Conference on Detection of Intrusions and Malware & Vulnerability Assessment (DIMVA), 2019.
[52] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. 2013.
[53] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26:3111–3119, 2013.
[57] Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations, 2019.
[60] Kexin Pei, Zhou Xuan, Junfeng Yang, Suman Jana, and Baishakhi Ray. Trex: Learning execution semantics from micro-traces for binary similarity. arXiv preprint arXiv:2012.08680, 2020.
[64] Kimberly Redmond, Lannan Luo, and Qiang Zeng. A cross-architecture instruction embedding model for natural language processing-inspired binary code analysis. In NDSS Workshop on Binary Analysis Research (BAR), 2019.
[65] Radim Rehurek and Petr Sojka. Gensim–python framework for vector space modelling. NLP Centre, Faculty of Informatics, Masaryk University, Brno, Czech Republic, 3(2), 2011.
[67] Noam Shalev and Nimrod Partush. Binary Similarity Detection Using Machine Learning. In Proceedings of the 13th Workshop on Programming Languages and Analysis for Security - PLAS ’18, pages 42–47, Toronto, Canada, 2018. ACM Press.
[71] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
[76] Xiaojun Xu, Chang Liu, Qian Feng, Heng Yin, Le Song, and Dawn Song. Neural network-based graph embedding for cross-platform binary code similarity detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS ’17, page 363–376, New York, NY, USA, 2017. Association for Computing Machinery.
[78] Zeping Yu, Rui Cao, Qiyi Tang, Sen Nie, Junzhou ouang, and Shi Wu. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection. Proceedings of the AAAI Conference on Artificial Intelligence, 34(01):1145–1152, April 2020.
[79] Zeping Yu, Wenxin Zheng, Jiaqi Wang, Qiyi Tang, Sen Nie, and Shi Wu. Codecmr: Cross-modal retrieval for function-level binary source code matching. Advances in Neural Information Processing Systems, 33, 2020.
Insights
(1) 统一评估10种代表性方法,https://github.com/Cisco-Talos/binary_function_similarity
(2) 使用基本块特征(例如,ACFG)可以提供更好的结果,但是在精心手工设计的特征和更简单的特征(例如基本块操作码的单词包)之间存在很小的区别。