什么是特征预处理
通过特定的统计方法(数学方法)将数据转换成算法要求的数据
对于数值型数据,我们采用的方法为标准缩放:
1、归一化
2、标准化
3、缺失值
对于类别型数据:我们使用one-hot编码
对于时间类型:使用时间的切分
归一化
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:
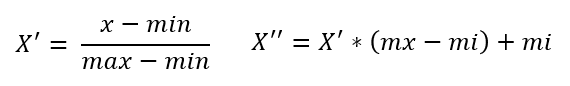
注:作用于每一列,max为一列的最大值,min为一列的最小值,x"
为最终结果,mx,mi分别为指定区间值, 默认mx为1,mi为0
那么为什么需要将数据归一化呢?来看一个例子
这是一组约会对象的数据
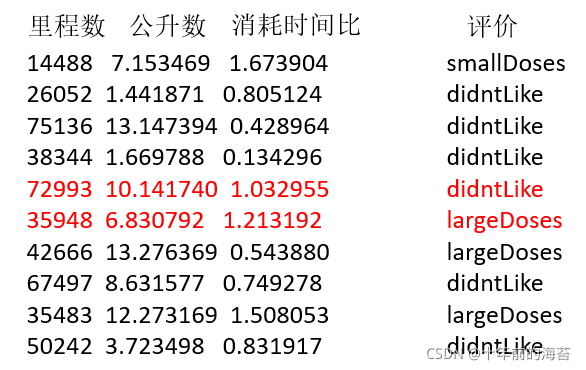
这个样本是男士的数据,包含三个特征,玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个所属类别,被女士评价的三个类别,不喜欢didnt、魅力一般small.极具魅力large也许也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要。
当特征值同等重要的时候,就需要对数据进行归一化!
假如不进行 归一化,在进行数据分类时就会出现问题,例如在k近邻算法中
(不了解k近邻算法也没有关系)
例如图中红色的两条数据,在k近邻算法中,两个样本的"距离"为:
((72993-35948)^2 )+ ((10.14-6.8)^2) + ((1.0-1.21)^2)
也就是每条数据的每个特征值分别相减的平方再求和和
显然多项式的后两项对整个多项式的值影响并不大,这样数据就并不是同等重要了
代码如下
from sklearn.preprocessing import MinMaxScaler
def mm():
"""
归一化处理
"""
mm = MinMaxScaler()
# MinMaxScaler默认范围为[0,1],如果需要更改,可以加上参数
# MinMaxScaler(feature_range=(2, 3))
data = mm.fit_transform(
[[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
)
print(data)
"""
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
"""
if __name__ == '__main__':
mm()
但是这种方法中的最大最小值非常容易受到异常点的影响
所以这种方法鲁棒性较差,只适合传统精确小数据场景
(鲁棒性Robust: 可以理解为算法对数据变化的容忍度有多高)
标准化
特点:通过对原始数据进行变换把数据变换到均值为0,方差为1范围内
公式:
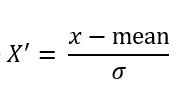
注:作用于每一列, 即每个特征列,mean为平均值,σ为标准差(标准差考量的是数据的稳定性)
标准差σ=方差开平方
方差:(M为平均值,n为数据个数)
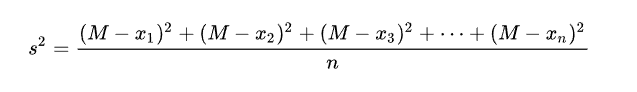
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
sklearn特征化APl:scikit-learn.preprocessing.StandardScaler
代码片段如下
# from sklearn.preprocessing import StandardScaler
def stand():
"""
标准化缩放
"""
std = StandardScaler()
data = std.fit_transform(
[[1., -1., 3.],
[2., 4., 2.],
[4., 6., -1.]]
)
print(data)
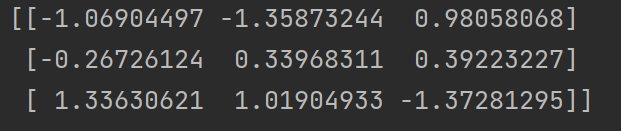
标准化在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
缺失值处理
1.直接删除
如果每列或者行数据缺失值达到一定的比例,建议放弃整行或者整列
一般缺失值不建议直接删除, 否则会造成数据量减少
2.插补
将缺失值替换成每列平均值、中位数等
sklearn缺失值APl:from sklearn.impute import SimpleImputer
代码如下:
# from sklearn.impute import SimpleImputer
def im():
"""
缺失值处理
"""
# strategy:填充策略,可以选择平均数mean,或中位数median
# missing_values默认为np.nan
# 如果缺失值不是np.nan,需要先将数据替换成np.nan
im = SimpleImputer(missing_values=np.nan, strategy="mean")
data = im.fit_transform(
[[1, 2],
[np.nan, 3],
[7, 6]]
)
print(data)
