2、降维的意义
首先我们为什么要降维?
假如我们拿到的数据很多很多,有上百个数据特征(x1,x2,x3…),这些样本对于你的预测值y真的起到作用吗?就比如说我要预测你是男是女,你的标签有一个是你是否四肢健全。这个显然是没关系的!
而对于主成分而言,我们得找到对于预测值y作用最大的几个标签,其实一般有用的特征都不多。那么对于一些有点用的标签,而且这些标签之间往往又有一丢丢关联那咋办呢?
那就是把这几个关联的标签映射到一个维度,尽可能保留标签的特征,这就是PCA啦!(是不是很完美的解析,网上很多解释没看懂,有错请指出!)
PCA降维
下面看点图理解一下
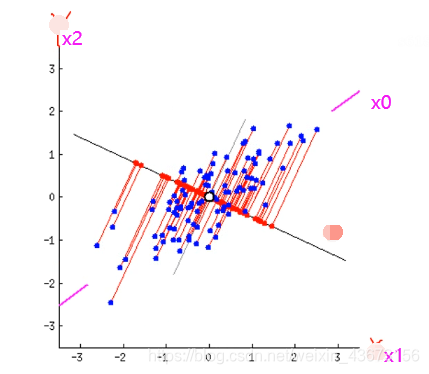
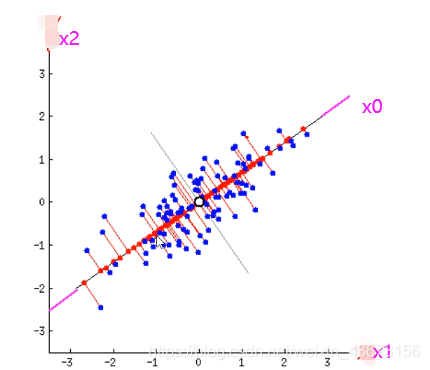
一条线是在定点(中心点,均值点)上转动,找到方差最大的位置,这两个轴表示的是x1,x2,这就验证了上面说的这两个标签之间或多或少存在一定的关系。下图就是最大方差的位置!
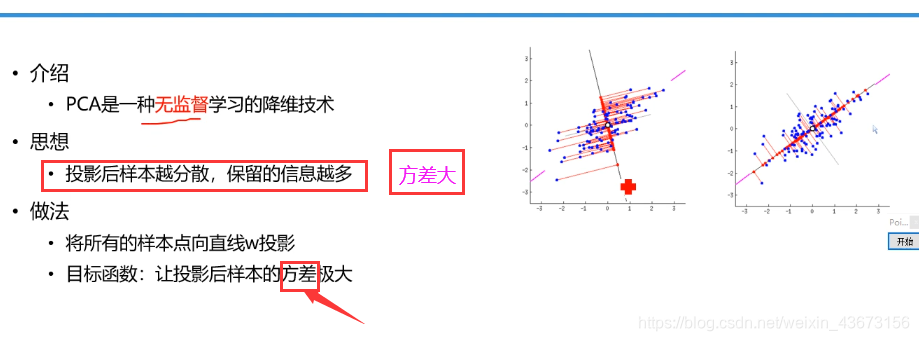
小结
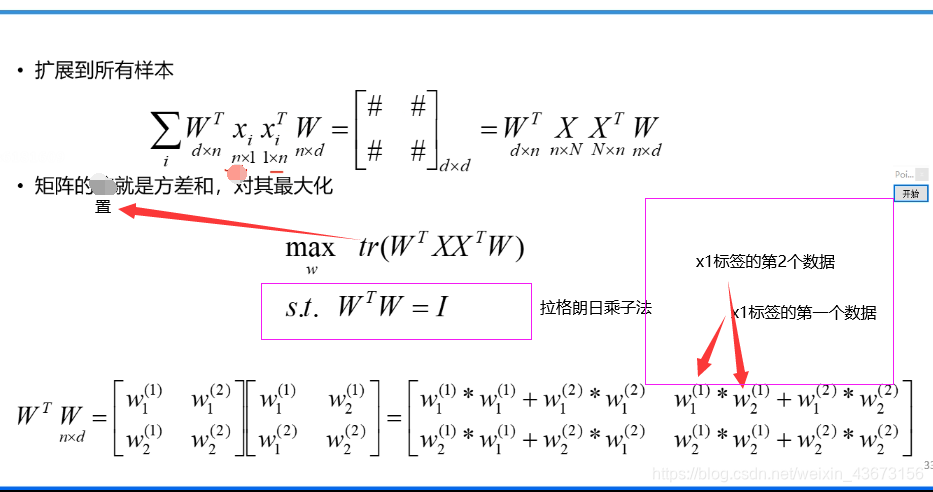
算法原理(数学)
n 上图W表示的是一个矩阵,W=(x1,x2,x3,x4…xn)同一个标签里面的不同取值,不是多个标签!
上图W表示的是一个矩阵,W=(x1,x2,x3,x4…xn)同一个标签里面的不同取值,不是多个标签!
 底层代码实现
底层代码实现
import numpy as np
方法封装 X 数据 k 取几个维度
def pca(X,k):
m_samples , n_features = X.shape
#中心化 去均值 均值为0
mean = np.mean(X,axis=0)
normX = X - mean #去均值
cov_mat = np.dot(np.transpose(normX),normX) #协方差矩阵
#对二维数组的transpose操作就是对原数组的转置操作 矩阵相乘
vals , vecs = np.linalg.eig(cov_mat)# 得到特征向量和特征值
print('特征值', vals)
print('特征向量', vecs)
eig_pairs = [(np.abs(vals[i]),vecs[:,i]) for i in range(n_features)]
print(eig_pairs)
print('----------')
#将特征值由大到小排列
eig_pairs.sort(reverse=True)
print(eig_pairs)
print('------------')
#获取多少个维度
feature = np.array(eig_pairs[0][k])
print(feature)
#将数据进行还原操作 normX 中心化后的数据 和 特征向量相乘
data = np.dot(normX,np.transpose(feature))
return data
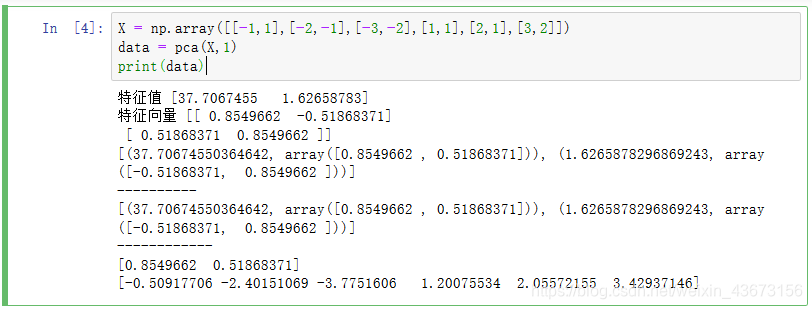
X = np.array([[-1,1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
data = pca(X,1)
print(data)
API代码实现
from sklearn.decomposition import PCA
p = PCA(n_components=1)
a = p.fit_transform(X)
print('----------------------')
print(a)
out:
----------------------
[[ 0.50917706]
[ 2.40151069]
[ 3.7751606 ]
[-1.20075534]
[-2.05572155]
[-3.42937146]]
其实数学那方面还是不能深入,慢慢来,哪位大佬懂的话留个言呗!!
