参考链接:
1、scikit-learn官网
2、sklearn提供的自带的数据集
3、Kaggle官网
4、数据挖掘——无量纲化
数据集有哪些?
1、经典数据集:iris,*房价,Titanic,红酒,二手房,*CANCER,TMDB5000,netflix,航空飞行数据,恐袭数据,terror,DigitalRecognizor,医疗数据
2、自建数据集:CNBOO,双色球,FZUNews,NBA,COVID19,国家社科基金,STUMOOC
调用数据集的方法?
本地,远程(数据库,数据中台…)
一、数据中台
获取红酒数据:
from sklearn.datasets import load_wine # 调用SKlearn的数据中台数据
wine=load_wine()
wine

winedf=pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
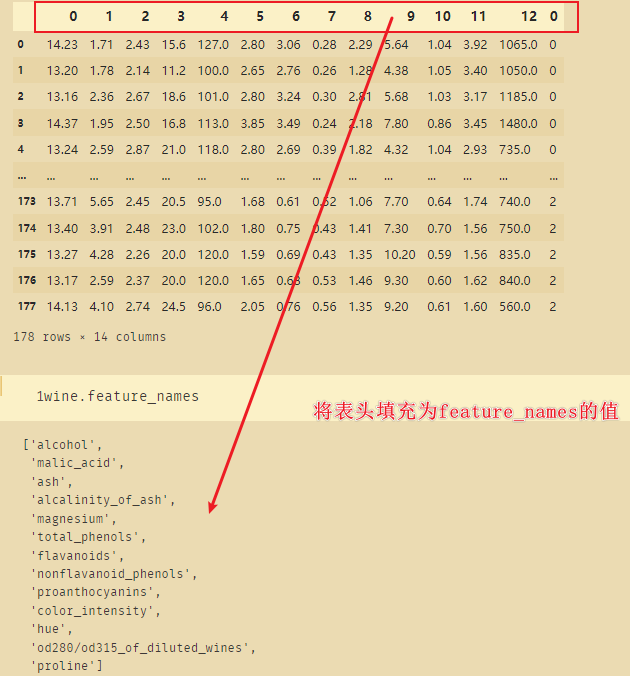
winedf.columns=['alcohol','malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline','']
winedf
获取鸢尾花数据:
from sklearn.datasets import load_iris
iris=load_iris()
iris
数据集拿来做什么用?
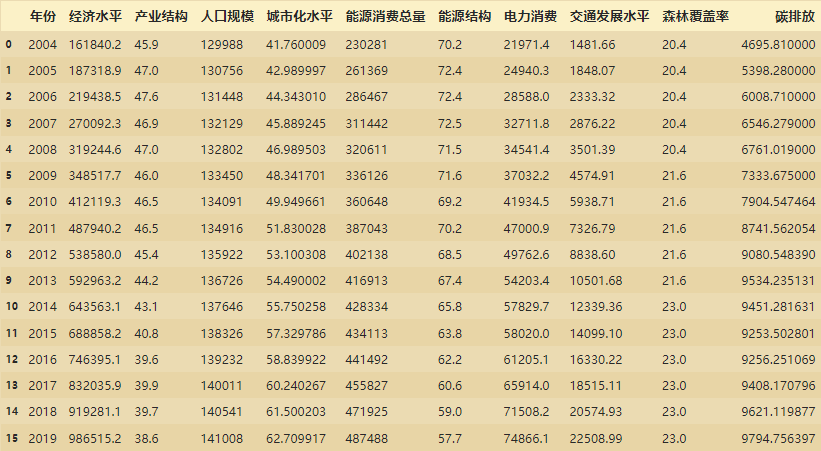
如上图这样一份数据,我们可以做的是:
- 将每个字段进行可视化,观察随着时间的推移其变化的趋势
- 研究每个字段与碳排放的相关性
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16 entries, 0 to 15
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 年份 16 non-null int64
1 经济水平 16 non-null float64
2 产业结构 16 non-null float64
3 人口规模 16 non-null int64
4 城市化水平 16 non-null float64
5 能源消费总量 16 non-null int64
6 能源结构 16 non-null float64
7 电力消费 16 non-null float64
8 交通发展水平 16 non-null float64
9 森林覆盖率 16 non-null float64
10 碳排放 16 non-null float64
dtypes: float64(8), int64(3)
memory usage: 1.5 KB

二、sklearn中的数据预处理与特征工程
特征工程:将原始数据转换为更能代表模型潜在问题(价值)的特征的过程。需要挑选最相关的特征,提取特征或创造特征来实现知识挖掘。创造特征的过程往往采用降维的方式(PCA,SVD)。
可能面对的问题:特征之间的相关性问题,特征多少的问题,特征与标签(tag,target)的关联度问题
主要目的:降低计算成本,提升模型的表现(准确度等)
- preprocessing:数据预处理模块
- Imput:缺失值补充模块
- feature_selection:特征选择模块
- decomposition:包括了降维算法
三、数据无量纲化
不同规格数据的同一化,不同分布的转换。
梯度,矩阵类,如逻辑回归,SVM,神经网络,可以加快求解速度。
距离类,如KNN,K-Means等,可以提升模型精度,避免某特征取值太大对距离计算造成的影响。
数据的无量纲化可以是线性的,也可以是非线性的。
线性的包括中心化处理,缩放处理。
中心化的核心是所有的记录-固定值,让数据样本进行平移(往往是Y轴为中心的位置)
缩放的核心是通过/固定值,将数据固定在某个范围内,如取对数等。
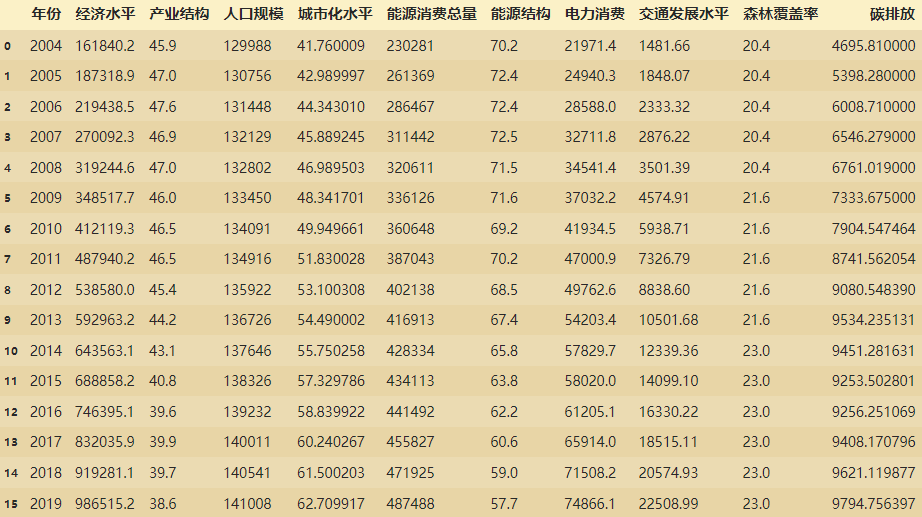
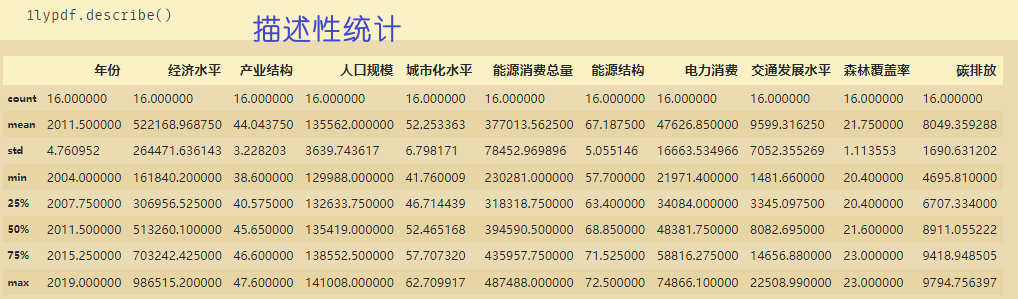
观察上面数据,每个字段之间差值过大,通过以下代码实现归一化。
scaler=MinMaxScaler() # 进行实例化
scaler=scaler.fit(data) # 生成min()和max()
result=scaler.transform(data) # 获取到转换之后的数据
result # 此时得到的数据都是0-1之间,就消除了不同数据之间极差过大的情况
(1)preprocessing.MinMaxScaler 归一化
min-max归一化
指的是对原始数据进行线性变换,将其映射到[0,1]之间,该方法也被称为离差标准化
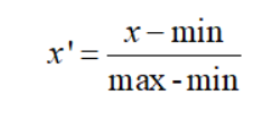
上式中,min是样本的最小值,max是样本的最大值。由于最大值与最小值可能是动态变化的,同时也非常容易受噪声(异常点、离群点)影响,因此一般适合小数据的场景。
此外,该方法还有两点好处:
-
如果某属性/特征的方差很小,如身高:
np.array([[1.70],[1.71],[1.72],[1.70],[1.73]]),实际5条数据在身高这个特征上是有差异的,但是却很微弱,这样不利于模型的学习,进行min-max归一化后为:array([[ 0. ], [ 0.33333333], [ 0.66666667], [ 0. ], [ 1. ]]),相当于放大了差异; -
维持稀疏矩阵中为0的条目。
将数据归一化,使用方法如下:
from sklearn.preprocessing import MinMaxScaler
x = np.array([[1,-1,2],[2,0,0],[0,1,-1]])
x1 = MinMaxScaler().fit_transform(x)

不难发现,x1每列的值都在[0,1]之间,也就是说,该模块是按列计算的。并且MinMaxScaler在构造类对象的时候也可以直接指定最大最小值的范围:scaler = MinMaxScaler(feature_range=(min, max)).
将归一化之后的数据进行还原:
# 数据归一化
scaler=MinMaxScaler() # 进行实例化
scaler=scaler.fit(lypdf) # 生成min()和max()
result=scaler.transform(lypdf)
result # 此时得到的数据都是0-1之间,就消除了不同数据之间极差过大的情况
# 将归一化的数据还原
scaler.inverse_transform(result)
X=scaler.inverse_transform(X):将标准化后的数据转换为原始数据。X=pca.inverse_transform(newX):将降维后的数据转换成原始数据
将归一化的结果指定在特定的范围内:
# 将归一化的结果指定在特定的范围内
scaler=MinMaxScaler(feature_range=[5,10])
result=scaler.fit_transform(data)
result

(2)preprocessing.StandardScaler 标准化
z-score标准化(zero-mena normalization,0-均值标准化)方法的公式如下所示:
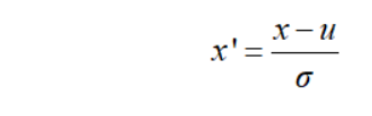
上式中,x是原始数据,u是样本均值,σ是样本标准差。回顾下正态分布的基本性质,若x~N(u,σ^2),则有:
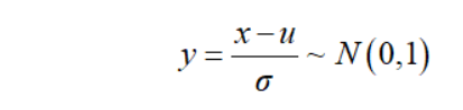
其中,N(0,1)表示标准正态分布。
于是,可以看出,z-score标准化方法试图将原始数据集标准化成均值为0,方差为1且接近于标准正态分布的数据集。然而,一旦原始数据的分布 不 接近于一般正态分布,则标准化的效果会不好。该方法比较适合数据量大的场景(即样本足够多)。此外,相对于min-max归一化方法,该方法不仅能够去除量纲,还能够把所有维度的变量一视同仁(因为每个维度都服从均值为0、方差1的正态分布),在最后计算距离时各个维度数据发挥了相同的作用,z-score标准化方法避免了不同量纲的选取对距离计算产生的巨大影响。所以,涉及到计算点与点之间的距离,如利用距离度量来计算相似度、PCA、LDA,聚类分析等,并且数据量大(近似正态分布),可考虑该方法。相反地,如果想保留原始数据中由标准差所反映的潜在权重关系应该选择min-max归一化。
from sklearn.preprocessing import StandardScaler
x = np.array([[1,2,3],[4,5,6],[1,2,1]])
x1 = StandardScaler().fit_transform(x)
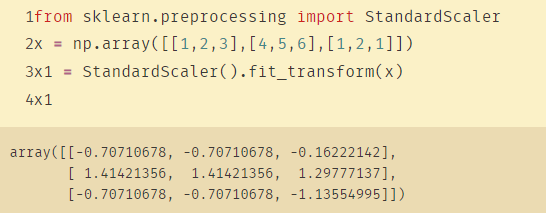
可以发现,x1的每一列加起来都是0,方差是1左右。注意该方法同样按列(即每个属性/特征)进行计算。并且StandardScaler类还有一个好处,就是可以直接调用其对象的.mean_与.std_方法查看原始数据的均值与标准差。
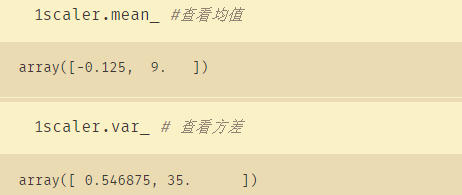
from sklearn.preprocessing import StandardScaler
data=[[-1,2],[-0.5,6],[0,10],[1,18]]
scaler=StandardScaler() # 进行标准化
scaler=scaler.fit(data)
(3)如何选择归一化和标准化
1、归一化,标准化两种算法中,NaN会被当做缺失值。在fit时会忽略,
在transform时显示NaN
2、 在fit时,只允许输入至少二维数组
data_=[-1,2,-0.5,6,0.9,10]
scaler=StandardScaler() # 进行标准化
scaler=scaler.fit(data_) # 报错 ValueError: Expected 2D array, got 1D array instead:
上面这段代码报错,原因在于data_不是而二维数据
3、大多数机器学习算法数据预处理时,会选择标准化进行特征缩放。因为归一化对异常值较为敏感,特别是在极差较大的数据维度,较大数据会被压缩到极小范围,导致计算结果不正常。
4、标准化适用于PCA,聚类,逻辑回归,SVM,神经网络等。
5、归一化在不涉及距离度量,梯度,协方差计算以及数据需要被压缩到特定区间时使用较好。比如数字图像中量化像素强度,使用归一化将数据压缩在【0,1】区间内。
6、其他选择:
- 仅仅压缩数据,却不影响数据的稀疏性–》
MaxAbsScaler - 异常值多,噪声非常大,用分位数无量纲化–》
RobustScaler
四、缺失值处理
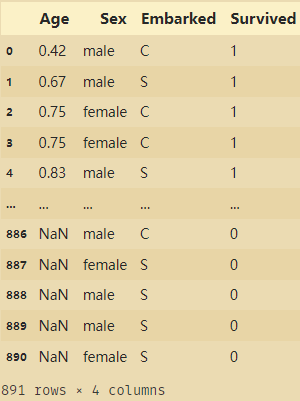
以泰坦尼克号数据为例:
import pandas as pd
data=pd.read_csv("titanic.csv")
data=data[['Age','Sex','Embarked','Survived']]
data
data.isnull().any() # 判断是否有缺失值
data.isnull().sum() # 求出有多少个缺失值
data.isnull().sum()/data.shape[0]*100 # 计算缺失值占总体的百分比

(1)impute.SimpleImputer 缺失值填充
使用SimpleImputer(),对缺失值进行填充。
! pip install SimpleImputer
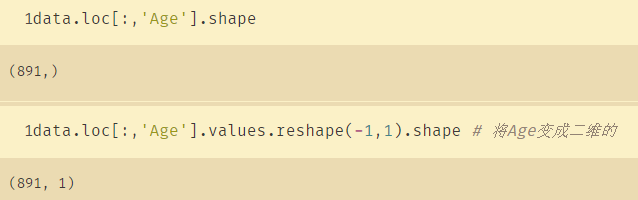
data.loc[:,'Age'].values.reshape(-1,1).shape # 将Age变成二维的
对titanic的Age的缺失值进行填充:
# 对Titanic的Age进行填充
from sklearn.impute import SimpleImputer
imp_mean=SimpleImputer() # 实例化
imp_median=SimpleImputer(strategy='median') # 使用中位数对缺失值进行填补
imp_0=SimpleImputer(strategy="constant",fill_value=0) # 用常量0对缺失值进行填充
# 实际填充步骤
imp_mean=imp_mean.fit_transform(Age) # 注意:这里的Age一定是二维的
imp_median=imp_median.fit_transform(Age) # 使用中位数对缺失值进行填补
imp_0=imp_0.fit_transform(Age) # 用常量0对缺失值进行填充
imp_mean # 此时有NaN值的地方全部都使用中位数填充了
data.loc[:,'Age']=imp_median
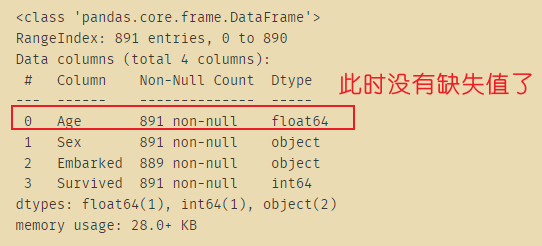
# 使用众数填充Embarked,但是Embarked默认是字符型
Embarked=data.loc[:,'Embarked'].values.reshape(-1,1) # 变成二维矩阵
Embarked.shape
imp_mode=SimpleImputer(strategy='most_frequent')
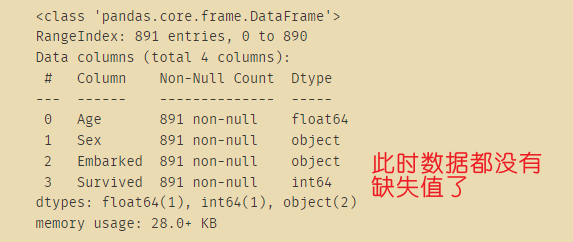
data.loc[:,"Embarked"]=imp_mode.fit_transform(Embarked)
data.info()
五、处理分类型特征:编码与哑变量
主要方法:
preprocessing.LabelEncoder标签专用法,将分类转换为分类数值preprocessing.OrdinalEncoder特征专用法,将分类特征转换为分类数值preprocessing.OneHotEncoder独热编码,创建哑变量
什么是哑变量呢?
哑变量(DummyVariable),也叫虚拟变量, 引入哑变量的目的是,将不能够定量处理的变量量化。
例如:在线性回归分析中引入哑变量的目的是,可以考察定性因素对因变量的影响,它是人为虚设的变量,通常取值为0或1,来反映某个变量的不同属性。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。如职业、性别对收入的影响,战争、自然灾害对GDP的影响,季节对某些产品(如冷饮)销售的影响等等。
这种“量化”通常是通过引入“哑变量”来完成的。根据这些因素的属性类型,构造只取“0”或“1”的人工变量,通常称为哑变量(dummyvariables),记为D。
举一个例子,假设变量“职业”的取值分别为:工人、农民、学生、企业职员、其他,5种选项,我们可以增加4个哑变量来代替“职业”这个变量,分别为D1(1=工人/0=非工人)、D2(1=农民/0=非农民)、D3(1=学生/0=非学生)、D4(1=企业职员/0=非企业职员),最后一个选项“其他”的信息已经包含在这4个变量中了,所以不需要再增加一个D5(1=其他/0=非其他)了。这个过程就是引入哑变量的过程。
此时,我们通常会将原始的多分类变量转化为哑变量,每个哑变量只代表某两个级别或若干个级别间的差异,通过构建回归模型,每一个哑变量都能得出一个估计的回归系数,从而使得回归的结果更易于解释,更具有实际意义。
(1)preprocessing.LabelEncoder 将标签转换为数值
使用LabelEncoder对目标标签进行编码,值在0到n_class -1之间。
from sklearn.preprocessing import LabelEncoder
y=data.iloc[:,-1]
y.shape
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
le=le.fit(y)
label=le.transform(y)
le.classes_ # 标签中有多少类别
label

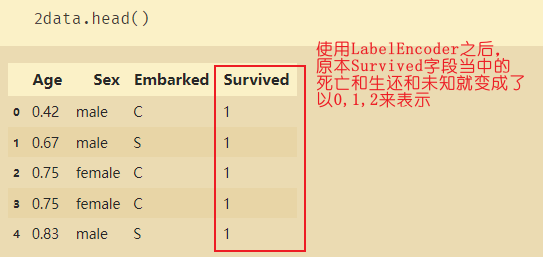
le.fit_transform(y)
le.inverse_transform(label) # 0代表死亡,1代表存活
data.loc[:,-1]=label
data.drop(['Survived'],axis=1,inplace=True)
data.rename(columns={
-1:'Survived'},inplace=True)
data.head()
(2)preprocessing.OrdinalEncoder 将特征转换为数值
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值

from sklearn.preprocessing import OrdinalEncoder
data_=data.copy()
data_
# 取出需要转换的两个字段
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
data_.iloc[:,1:-1]
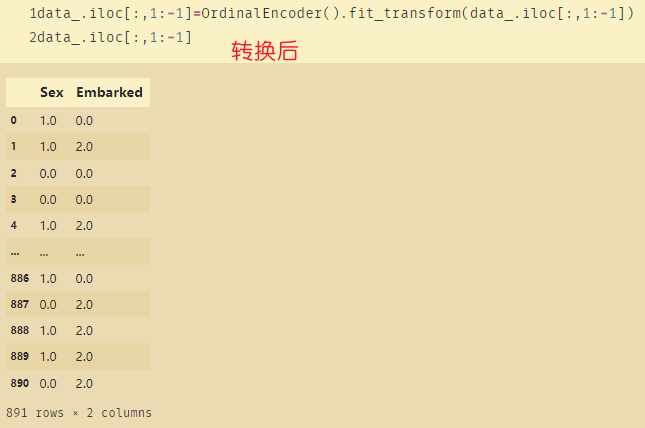
使用OrdinalEncoder将字符型变成数值
data_.iloc[:,1:-1]=OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
(3)preprocessing.OneHotEncoder 将特征转为稀疏矩阵
使用OrdinalEncoder的处理结果会让各值之间有一定的联系,比如1-2=-1,0=1-1,会对建模产生一定的影响。此时则使用OneHotEncoder。
OneHotEncoder 独热编码作用:分类编码变量,将每一个类可能取值的特征变换为二进制特征向量,每一类的特征向量只有一个地方是1,其余位置都是0
from sklearn.preprocessing import OneHotEncoder
X=data.iloc[:,1:-1]
X
enc=OneHotEncoder(categories="auto").fit(X)
enc.transform(X)
result=enc.transform(X).toarray()
result
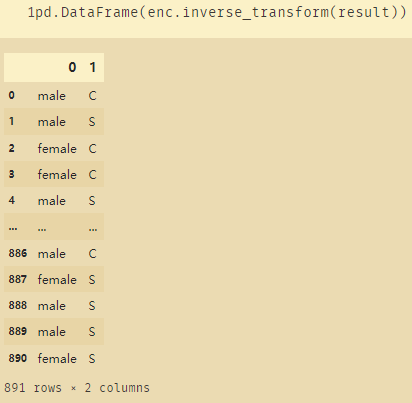
也可以将使用OneHotEncoder后的数据进行还原:
# 将使用OneHotEncoder后的数据进行还原
pd.DataFrame(enc.inverse_transform(result))
enc.get_feature_names()
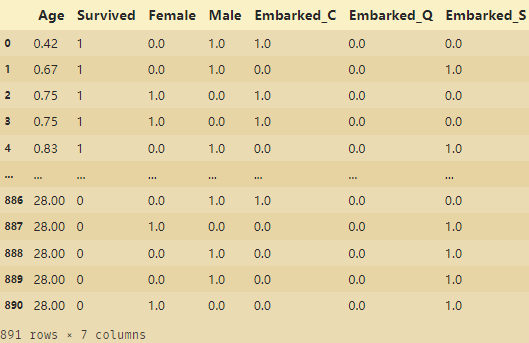
newdata=pd.concat([data,pd.DataFrame(result)],axis=1)
newdata.drop(['Sex','Embarked'],axis=1,inplace=True)
newdata.columns=['Age','Survived','Female','Male','Embarked_C','Embarked_Q','Embarked_S']
newdata
整理后的数据:
如果有缺失值的话使用众数进行填充:
imp_=SimpleImputer(strategy='most_frequent')
imp_mf=imp_.fit_transform(newdata.iloc[:,1:])
newdata.iloc[:,1:]=imp_mf
六、处理连续性特征:二值化与分段
(1)preprocessing.LabelBinarizer 标签二值化
标签可以使用sklearn.preprocessing.LabelBinarizer进行哑变量处理。
二值化:指将大于0的特征使用1表示,将等于0的特征还是用0表示。例如Binarizer(threshold=0.9) :将数据进行二值化,threshold表示大于0.9的数据为1,小于0.9的数据为0
对于二值化操作:
- 方法一: 求出大于等于1的索引值,令这些索引值对应的数值等于1,然后重新构建列
- 方法二:使用
Binarizer(threshold=0.9)表示大于0.9的数据使用1表示
这里传入的参数需要是二维的,因此需要做维度转换
data_2=data.copy()
from sklearn.preprocessing import Binarizer
x=data_2.iloc[:,0].values.reshape(-1,1)
transformer=Binarizer(threshold=30).fit_transform(x)
transformer
# 将二值化返回newdata
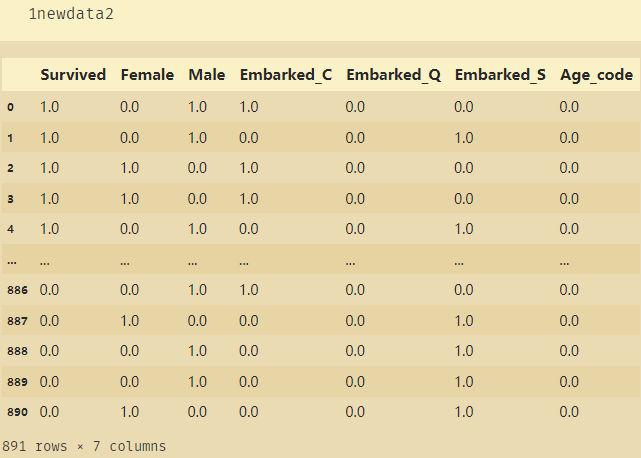
newdata2=pd.concat([newdata,pd.DataFrame(transformer)],axis=1)
# 将二值化后的数据Age_code合并到原本数据当中
newdata2.columns=['Age','Survived','Female','Male','Embarked_C','Embarked_Q','Embarked_S','Age_code']
newdata2.drop(['Age'],axis=1,inplace=True) # 删除原本的Age
# 使用众数填充缺失值
imp_=SimpleImputer(strategy='most_frequent')
imp_mf=imp_.fit_transform(newdata2.iloc[:,-1:])
newdata2.iloc[:,-1:]=imp_mf
(2)preprocessing.KBinsDiscretizer 连续属性离散化
KBinsDiscretizer 类:这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。
使用k个等宽的bins把特征离散化,默认情况下,输出是被 one-hot 编码到一个稀疏矩阵。(请看类别特征编码)。 而且可以使用参数encode进行配置。对每一个特征, bin的边界以及总数目在 fit过程中被计算出来,它们将用来定义区间。
from sklearn.preprocessing import KBinsDiscretizer
x=data.iloc[:,0].values.reshape(-1,1)
est=KBinsDiscretizer(n_bins=3,encode='ordinal',strategy='uniform')
est.fit_transform(x)
set(est.fit_transform(x).ravel())
est=KBinsDiscretizer(n_bins=3,encode='onehot',strategy='uniform')
est.fit_transform(x).toarray()
newdata3=pd.concat([newdata,pd.DataFrame(est.fit_transform(x).toarray())],axis=1) # 将年龄进行分段
newdata3.columns=['Age','Survived','Female','Male','Embarked_C','Embarked_Q','Embarked_S','Age_1','Age_2','Age_3']
此时得到的整理后的数据就都是浮点型了。
