意义
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程,如下图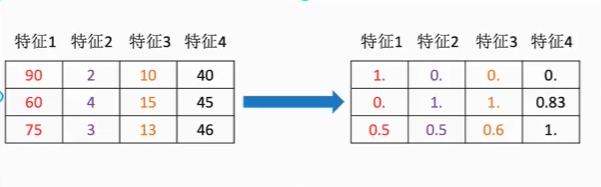
1. 包含内容
数值型数据的无量纲化
- 归一化
- 标准化
2. API
sklearn.preprocessing
3. 进行归一化/标准化的原因
- 特征的单位或大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其他的特征
4. 归一化
- 定义:通过对原始数据进行变换把数据映射到(默认为[0, 1]之间)
- 公式:

- API
from sklearn.preprocessing import MinMaxScaler
- 实现代码
def minmax_demo():
"""
归一化
:return:
"""
# 1、获取数据
data = pd.read_csv("改为打开的文件位置")
data = data.iloc[:, :3] # 此处按照数据的格式进行修改
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3]) # 目标数据的范围
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
- 特点:归一化鲁棒性较差,容易受异常点的影响,只适合精确的小数据场景
5. 标准化
- 定义:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
- 公式:

- API
from sklearn.preprocessing import StandardScaler
- 实现代码
def stand_demo():
"""
标准化
:return:
"""
# 1、获取数据
data = pd.read_csv("改为打开的文件位置")
data = data.iloc[:, :3] # 此处按照数据的格式进行修改
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
- 特点:在已有样本足够多的的情况下比较稳定,适合现代嘈杂大数据场景
