支持向量机(SVM)是在统计学习理论基础上发展起来的一种数据挖掘方法,是机器学习中的方法之一,也是核方法(kernal method)中最有名的方法之一,在小样本、非线性和高维的回归、分类问题上有许多优势。支持向量机可分为支持向量分类机(support vertor classification,SVC)与支持向量机分类机(support vertor regression,SVR)。
一:理论基础
对于支持向量机,最初研究的是分类问题(SVC),并且是二分类线性可分的情况,之后采用核方法可以解决非线性可分的问题。但是目前SVC只能用于解决二分类问题,而对于多分类问题,目前仍无法使用SVC,需要进行专门的推广。
(1)线性可分
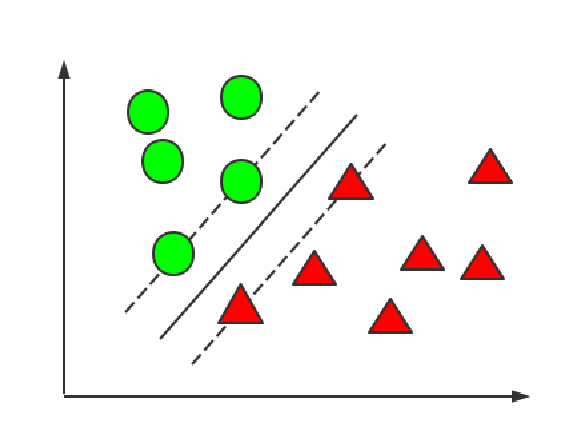
如图所示,对于只含有两类的样本,我们希望能够找到一条直线,可以完全把两类数据分开。除此之外,在这些数据中每类都有与这条分割直线距离最近的数据点(称为支持向量,support vector),我们还需要支持向量与分割线的距离最远,此时的分割线即为最终结果。
所以,对于这样的问题,本质上是极大极小问题,即找到距离分割线最短的支持向量,又使支持向量到分割线距离最大。后面的推导过程主要构造表达式、解决对偶问题、二次规划问题,这些需要涉及运筹学等相关知识。
(2)核函数与非线性SVM (nonlinear SVM)
采用核函数是为了解决线性不可分问题。它是将样本从原始空间映射到一个更高的特征空间,使样本在这个特征空间线性可分。设原始空间的一个数据向量为x,映射到高维特征空间中的向量Φ(x)。

在SVM求解过程中,需要计算两个向量的内积<x1,x2>。对于映射到高维特征空间的两个向量Φ(x1)、Φ(x2),计算<Φ(x1),Φ(x2)>时计算量较大(因为维数较高),所以可以设想有一个函数κ,使得<Φ(x1),Φ(x2)>=κ(<x1,x2>),这个函数κ即为核函数。所以我们不必关注与问题求解无关的映射函数Φ,只需关注于核函数κ即可。
二:SVC实现
(1)基本方法
scikit-learn中svm.SVC与svm.LinearSVC都可以进行支持向量分类,LinearSVC只用于线性支持向量分类,SVC可进行线性(将参数kernel设为'linear')与非线性支持向量回归,所以通常我们习惯使用svm.SVC来实现。
在svm.SVC()中,有以下参数:
C:指定目标函数中松弛因子的惩罚系数值。值越大,拟合非线性能力越强,默认为1。
kernel:指定模型的核函数,具体参数详见附录。
gamma、degree:对于一些核函数,需要指定p、r值,r值用degree参数指定,p值用gamma指定(gamma可理解为支持向量影响区域半径的倒数,值越大,影响区域越小,容易过拟合;太小容易欠拟合,degree其实表示多项式的次数)。
coef0:也可用于指定多项式函数或sigmoid核函数中参数值。
tol:指定SVM模型迭代的收敛条件,默认0.001。
epsilion:指定不敏感损失函数ε,默认为0,SVR中默认为0.1。
shrinking:是否采用启发式收缩方式,默认为True。
probability:是否对样本所属类别进行概率统计,默认为False。
class_weight:指定因变量类别权重。
verbose:是否输出模型迭代过程信息,默认为0,表示不输出。
decision_function_shape:指定SVM模型的决策树形状,如‘ovr’。
cache_size:指定核函数运算的内存空间,默认200M。
from sklearn.svm import SVC
data=np.array([[0,0],[1,1],[-0.5,0],[0,-1],[0,0.5],
[0,2],[2.5,0],[0,-3],[-0.5,-3],[1,4],[-3,0]]) #训练数据
label=np.array(['a','a','a','a','a',
'b','b','b','b','b','b']) #数据类别标签
svc=SVC(C=1.0,kernel='rbf',degree=3,gamma='auto')
svc.fit(X=data,y=label)设好SVC后,使用fit训练数据。训练完成后用predict函数对未知类别的数据进行预测。
yp=svc.predict([[10,3]])
print(yp)
'----------------------------'
>>>['b']最终的结果较为符合事实。
(2)模型准确率
通常情况下,我们会将一个数据分为训练集与测试集,用训练集训练好,再用测试集测试模型准确率。准确率采用metrics.accuarcy_score函数。
from sklearn import metrics
yp=svc.predict(data)
s=metrics.accuracy_score(label,yp)
print(s)其实label是实际类别,yp是预测类别。这里的准确率为100%。
三:SVR实现
(1)基本方法
scikit-learn中LinearSVR都可以实现支持向量回归,并且可以拟合多元函数。LinearSVR只用于线性向量回归,而SVR可以进行线性与非线性支持向量回归。
在svm.SVR()中,参数与SVM相同。后面的拟合方法fit与准确率预测等方法与SVC完全一致,并且训练数据仍需要是二维数组(例如一元函数拟合,数据为[[x1],[x2]]...[xn]),标签为一维数组(如[label1,label2...labeln]。
from sklearn.svm import SVR
import numpy as np
import matplotlib.pyplot as plt
x=np.arange(0,15,0.1)
y=np.sin(x)+np.cos(x)
x=np.mat(x).T
svr=SVR(kernel='rbf',degree=3,gamma='auto')
svr.fit(x,y)
yp=svr.predict(x)
plt.scatter(np.array(x).flatten(),y,color='blue') #
plt.plot(x,yp,color='green')
plt.legend(labels=['fit curve','data points'],loc=0)
plt.show()拟合结果如下:

附录:
(1)kernel参数值
'linear'线性核函数;'poly'多项式核函数;'rbf'径向基核函数;'sigmoid'sigmoid核函数。
(2)核函数种类
虽然在sklearn中核函数只有以上几种,实际上核函数种类是很多的。具体核函数种类与形式详见百度百科:核函数_百度百科。