参考资料
目标检测数据集(皮卡丘)
#%%
#In[1]
from mxnet import image,contrib,gluon,nd
#import numpy as np
import d2lzh as d2l
#np.set_printoptions(2)
import os
from mxnet.gluon import utils as gutils
def display_anchors(fmap_w,fmap_h,s):
fmap = nd.zeros((1,10,fmap_w,fmap_h)) #1x10 x fmap_w x fmap_h
#第一个参数,输入的特征图,一般形状为(批量大小,通道数,宽和高),框个数显示.
#第二个参数,要生成的锚框大小比例列表
#第三个参数,要生成的锚框的宽和高比例列表
anchors = contrib.nd.MultiBoxPrior(fmap,sizes=s,ratios=[1,2,0.5]) #1x48x4,3个锚框
bbox_scale = nd.array((w,h,w,h))
#原文img.asnumpy()报错,改成tolist
d2l.show_bboxes(d2l.plt.imshow(img.tolist()).axes,anchors[0]*bbox_scale)
display_anchors(fmap_w=2,fmap_h=2,s=[0.4])
#使用开源的皮卡丘3D模型生成1000张不同角度和大小的皮卡丘图像。然后在背景上随机放一张皮卡丘
#使用im2rec将图像转成二进制的RecordIO格式
#获取数据集
def _download_pikachu(data_dir):
root_url = ('https://apache-mxnet.s3-accelerate.amazonaws.com/'
'gluon/dataset/pikachu/')
dataset = {'train.rec':'e6bcb6ffba1ac04ff8a9b1115e650af56ee969c8',
'train.idx': 'dcf7318b2602c06428b9988470c731621716c393',
'val.rec': 'd6c33f799b4d058e82f2cb5bd9a976f69d72d520'}
for k,v in dataset.items():
print(k,v)
gutils.download(root_url+k,os.path.join(data_dir,k),sha1_hash=v)
# 创建ImageDetIter读取数据集。格式RecordIO,需要提供索引文件train.idx随机读取小批量到内存
# 随机裁剪95%
def load_data_pikachu(batch_size,edge_size=256): #edge_size:输出图像的宽和高
data_dir = '../data/pikachu'
_download_pikachu(data_dir)
#图像数据迭代器
train_iter = image.ImageDetIter(
path_imgrec=os.path.join(data_dir,'train.rec'), #记录的文件
path_imgidx = os.path.join(data_dir,'train.idx'),#索引
batch_size=batch_size, #读取数据大小到内存
data_shape=(3,edge_size,edge_size), #输出形状
shuffle=True, #随机读取
rand_crop = 1, #随机裁剪
min_object_covered = 0.95,max_attempts=200 #覆盖概率95%,尝试200此
)
val_iter = image.ImageDetIter(
path_imgrec=os.path.join(data_dir,'val.rec'),batch_size=batch_size,
data_shape=(3,edge_size,edge_size),shuffle=False
)
return train_iter,val_iter
#读取小批量并打印图像和标签的形状。(批量大小,通道数,高和宽)
#标签形状使(批量大小,m,5).m等于数据集中单个图像最多含有的边界框数A
batch_size,edge_size = 32,256
train_iter,_ = load_data_pikachu(batch_size,edge_size)
batch = train_iter.next() #返回下次读取的数据
batch.data[0].shape,batch.label[0].shape
#(32, 3, 256, 256),(32, 1, 5))
# print(batch.data[0][0:10]) 10x3x256x256
#transpose转换维度
imgs = (batch.data[0][0:10].transpose((0,2,3,1)))/255 #每个像素在0-1之间
#imshow显示的要求范围在0-1之间.
axes = d2l.show_images(imgs,2,5).flatten() #按行方式降维.2行5列
for ax,label in zip(axes,batch.label[0][0:10]):
# print(label) 皮卡丘的位置.
d2l.show_bboxes(ax,[label[0][1:5]*edge_size],colors=['w'])

单发多框检测SSD
单发多框检测模型,主要由一个基础的网络块和若干个多尺度特征块串联而成。基础网络块从原始图像中抽取特征,一般选用深度卷积神经网络(我们这里构造一个小的基础网络,串联3个高和宽减半块,并逐步将通道数翻倍,例如原始图像的形状为256x256,基础网络块输出特征图形状为32x32)
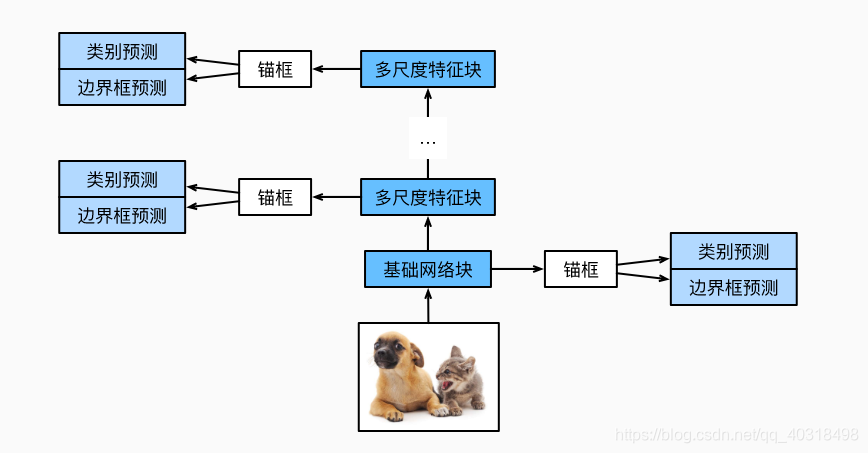
类别预测层
设目标的类别个数为q。每个锚框的类别个数就是q+1,0代表锚框只包含背景。若特征图的高和宽分别为h和w,每个单元为中心生成a个锚框,需要对hwa个锚框进行分类。具体来说,使用一个保持输入高和宽的卷积层,输出和输入在特征图宽和高是一一对应的。每一个坐标都会生成所有锚框的类别预测,因此输出通道是a(q+1)
边界框预测层
边界框预测层的设计与类别预测层的设计类似。不同的是,需要为每个锚框预测4个偏移量
高和宽减半块
为了在多尺度检测目标,下面定义高和宽减半块down_sample_blk。它串联了两个填充为1的3x3卷积层和步幅为2的2x2最大池化层。高和宽减半块使输出的特征图每个单元的感受野变得广阔
基础网络块
我们这里构造一个小的基础网络,串联3个高和宽减半块,并逐步将通道数翻倍,例如原始图像的形状为256x256,基础网络块输出特征图形状为32x32
完整的模型
单发多框检测模型一共包含5个模块,每个模块输出的特征图既用来生成锚框,又用来预测锚框的类别和偏移量。第一个模块使基础网络块,第二到第四模块是高和宽减半块,第五个是全局最大池化层将高和宽降到1.
完整的代码
#%%
#In[1]
from mxnet import image,contrib,gluon,nd,init,contrib,autograd
#import numpy as np
import d2lzh as d2l
#np.set_printoptions(2)
import os
from mxnet.gluon import utils as gutils,nn
from mxnet.gluon import loss as gloss
import time
#类别预测层
def cls_predictor(num_anchors,num_classes):
return nn.Conv2D(num_anchors*(num_classes+1),kernel_size=3,padding=1)
#保持输入和输出形状不变,每个锚框类别数q+1,中心生成a个锚框
#边界框预测层
def bbox_predictor(num_anchors):
return nn.Conv2D(num_anchors*4,kernel_size=3,padding=1)
#为每个锚框设置4个偏移量
def forward(x,block):
block.initialize()
return block(x)
Y1 = forward(nd.ones((2,8,20,20)),cls_predictor(5,10))
Y2 = forward(nd.ones((2,16,10,10)),cls_predictor(3,10))
(Y1.shape,Y2.shape)
def flatten_pred(pred):
return pred.transpose((0,2,3,1)).flatten()
def concat_pred(preds):
return nd.concat(*[flatten_pred(p) for p in preds],dim=1) #dim=1,二维,按行
concat_pred([Y1,Y2]).shape #(2, 25300),22000+3300=25300
#flatten_pred(Y1) #2x22000
#flatten_pred(Y2) #2x3300
# 高和宽减半块
# 串联两个填充为1的3x3卷积层和步幅为2的2x2最大池化层
def down_sample_blk(num_channels):
blk = nn.Sequential()
for _ in range(2):
blk.add(nn.Conv2D(num_channels,kernel_size=3,padding=1),
nn.BatchNorm(in_channels=num_channels),
nn.Activation('relu'))
blk.add(nn.MaxPool2D(2))
return blk
#测试高和宽减半的前向计算
forward(nd.zeros((2,3,20,20)),down_sample_blk(10)).shape # 2x10x10x10
#基础网络块
def base_net():
blk = nn.Sequential()
for num_filters in [16,32,64]:
blk.add(down_sample_blk(num_filters))
return blk
forward(nd.zeros((2,3,256,256)),base_net()).shape # 2x64x32x32
#完整的模型
def get_blk(i):
if i==0:
blk = base_net() #基础网络块
elif i==4:
blk = nn.GlobalMaxPool2D() #将高和宽降为1
else:
blk = down_sample_blk(128) #高和宽减半块
return blk
def blk_forward(X,blk,size,ratio,cls_predictor,bbox_predictor):
Y = blk(X)
anchors = contrib.ndarray.MultiBoxPrior(Y,sizes=size,ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y,anchors,cls_preds,bbox_preds)
sizes = [[0.2,0.272],[0.37,0.447],[0.54,0.619],[0.71,0.79],[0.88,0.961]]
ratios = [[1,2,0.5]]*5
num_anchors = len(sizes[0])+len(ratios[0])-1 # 2 + 3 -1 = 4
class TinySSD(nn.Block):
def __init__(self,num_classes,**kwargs):
super(TinySSD,self).__init__(**kwargs)
self.num_classes = num_classes #1
for i in range(5):
# 赋值语句self.blk_i = get_blk(i)
#设置属性值,如blk_0 = get_blk(0)
setattr(self,'blk_%d'%i,get_blk(i)) #完整的模型
#类别预测层.num_anchors=4,num_classes=1,通道数为8
setattr(self,'cls_%d'%i,cls_predictor(num_anchors,num_classes))
#边界预测层,num_anchors=4,通道数为16
setattr(self,'bbox_%d'%i,bbox_predictor(num_anchors))
def forward(self,X):
#[None,None,None,None,None]
anchors,cls_preds,bbox_preds = [None]*5,[None]*5,[None]*5
for i in range(5):
# getattr(self,'blk_%d'%i)访问self.blk_i
X,anchors[i],cls_preds[i],bbox_preds[i] = blk_forward(
X,getattr(self,'blk_%d'%i),sizes[i],ratios[i],
getattr(self,'cls_%d'%i),getattr(self,'bbox_%d'%i)
)
#reshape函数中的0表示批量大小不变
return (nd.concat(*anchors,dim=1),
concat_pred(cls_preds).reshape(
(0,-1,self.num_classes+1)
),concat_pred(bbox_preds))
net = TinySSD(num_classes=1)
net.initialize()
X = nd.zeros((32,3,256,256))
anchors,cls_preds,bbox_preds = net(X)
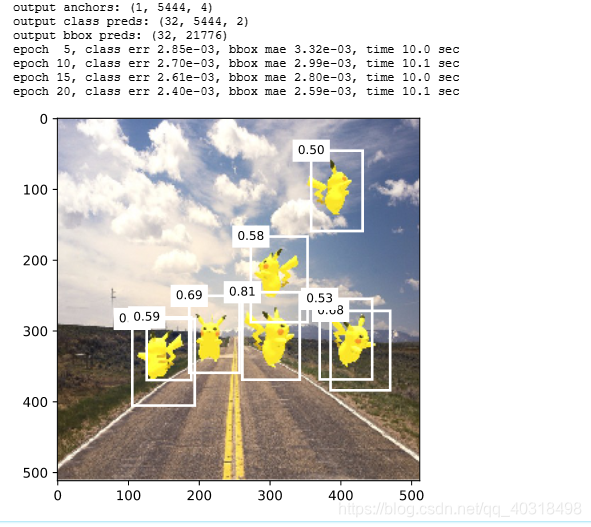
print('output anchors:',anchors.shape) #(1, 5444, 4)
print('output class preds:',cls_preds.shape) #(32,5444,2)
print('output bbox preds:',bbox_preds.shape) #(32,21776)
#训练模型
batch_size = 32
train_iter,_ = d2l.load_data_pikachu(batch_size)
ctx,net = d2l.try_gpu(),TinySSD(num_classes=1)
net.initialize(init=init.Xavier(),ctx=ctx)
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':0.2,'wd':5e-4})
# 定义损失函数和评价函数
cls_loss = gloss.SoftmaxCrossEntropyLoss()
bbox_loss = gloss.L1Loss() #平均绝对误差
def calc_loss(cls_preds,cls_labels,bbox_preds,bbox_labels,bbox_masks):
#cls_preds是预测分类标签
#cls_labels分类结果标签.
cls = cls_loss(cls_preds,cls_labels)
bbox = bbox_loss(bbox_preds*bbox_masks,bbox_labels*bbox_masks)
return cls+bbox
def cls_eval(cls_preds,cls_labels):
#类别预测结果放在最后一维,argmax指定最后一维,取预测类别最大的比较.
#最后一维是预测概率。最大的比较
return (cls_preds.argmax(axis=-1)==cls_labels).sum().asscalar()
def bbox_eval(bbox_preds,bbox_labels,bbox_masks):
return ((bbox_labels-bbox_preds)*bbox_masks).abs().sum().asscalar()
train_iter.reset() # 从头读取数据
for epoch in range(10):
acc_sum, mae_sum, n, m = 0.0, 0.0, 0, 0
train_iter.reset() # 从头读取数据
start = time.time()
for batch in train_iter:
X = batch.data[0].as_in_context(ctx)
Y = batch.label[0].as_in_context(ctx)
with autograd.record():
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = contrib.nd.MultiBoxTarget(
anchors, Y, cls_preds.transpose((0, 2, 1)))
#应该有采样的默认阈值,比如交并比大于多少,更新标签类别。
#标注类别和偏移量
#锚框形状输入,一共有5444个锚框作为输入,真实标签,预测分类,32x2x5444
#返回标签类别,掩码和偏移量
#正类锚框坐标对应的掩码均为1,形状为(批量大小,锚框总数*4)
#根据类别和偏移量的预测和标注值计算损失函数
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.backward() #反向传播
trainer.step(batch_size) #开始执行
acc_sum += cls_eval(cls_preds, cls_labels) #准确数
n += cls_labels.size #数目
mae_sum += bbox_eval(bbox_preds, bbox_labels, bbox_masks) #边框
m += bbox_labels.size
if (epoch + 1) % 2 == 0:
print('epoch %2d, class err %.2e, bbox mae %.2e, time %.1f sec' % (
epoch + 1, 1 - acc_sum / n, mae_sum / m, time.time() - start))
print(cls_labels)
print(cls_preds)
print(cls_preds.argmax(axis=-1))
print((cls_preds.argmax(axis=-1)==cls_labels).sum().asscalar())
#载入预测图片
img = image.imread('img/pikachu.jpg') #512x512x3
feature = image.imresize(img, 256, 256).astype('float32') #256x256x3
X = feature.transpose((2, 0, 1)).expand_dims(axis=0) #1x3x256x256
#卷积层需要输入四维的格式.
def predict(X):
anchors, cls_preds, bbox_preds = net(X.as_in_context(ctx))
cls_probs = cls_preds.softmax().transpose((0, 2, 1))
#非极大值抑制,第一个元素是预测的锚框概率,需要经过softmax运算,形状是批量大小,类别数+1,锚框总数
#预测锚框的偏移量,生成的默认锚框,一般形状是1,锚框总数,4
output = contrib.nd.MultiBoxDetection(cls_probs, bbox_preds, anchors)
print(output[0]) #5444x6的数组
idx = [i for i, row in enumerate(output[0]) if row[0].asscalar() != -1]
#idx返回的是列表,只要不是-1就返回,-1表示被移除
return output[0, idx] #返回列表数组
output = predict(X) #预测
d2l.set_figsize((5, 5))
def display(img, output, threshold):
fig = d2l.plt.imshow(img.asnumpy())
for row in output:
score = row[1].asscalar() #row[1]是预测概率,置信度
if score < threshold: #小于阈值,下一个
continue
h, w = img.shape[0:2] #形状
bbox = [row[2:6] * nd.array((w, h, w, h), ctx=row.context)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
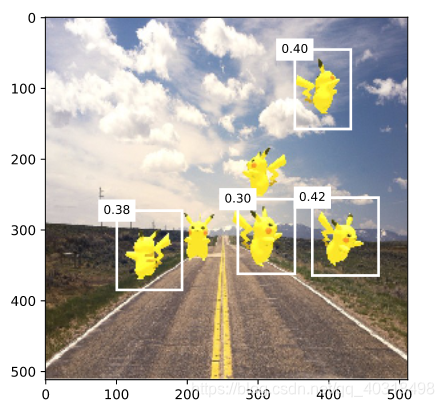
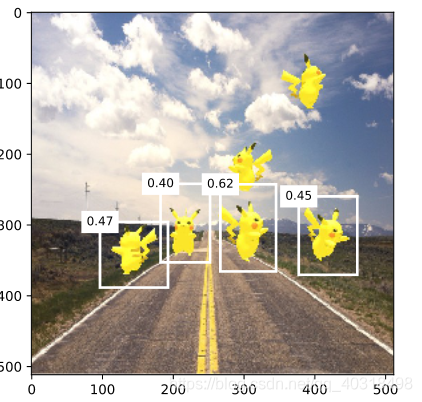
display(img, output, threshold=0.3)
原始图像

训练轮数为10
训练轮数为14
训练轮数为20
训练轮数为0
小结
- 关于参数更新,其实就是卷积神经网络的的应用。单发多框检测论文中选用了在分类层之前截断的VGG,现在也常用ResNet来代替。我们可以设计基础网络,使它输出的高和宽较大。这样一来,基于改特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。
- 如何知道要训练的是皮卡丘。在一开始中,我们从开源的3D皮卡丘模型生成1000张不同角度大小的皮卡丘图像,在每一个背景图像上随机放一张皮卡丘图像。load_data_pikachu方法我们做的就是这些。我们可以调用它的返回结果和方法next一次读取batch_size批量的数据。其中,返回结果是图像的像素集和皮卡丘的位置(左上角xy,右下角xy)。也就是说,我们的训练集含有原始图像和真实标签(只是从原来的类别,如0,1转变成位置坐标)。
- 在训练模型中,我们每次读取训练集中的batch_size大小(32)的数据,进行训练。关注方法MultiBoxTarget,第一个参数是anchors,形状是32x5444x4,表示锚框总数和锚框的坐标(锚框总数是根据我们5层模型算出),在训练中保持不变;第二个参数是Y,真实标签,形状是32x1x5,最后一维是类别标签+四个坐标值;第三个参数是预测类别分数,形状一般为(批量大小,预测的总类别数+1,锚框总数(即锚框总数个分类结果)。先迭代模型,得到预测框,调用MultiBoxTarget,让预测框与真实框做对比,比如预测框分类为0,真实框分类为1,交并比大于阈值(假设0.5),那么返回分类结果1。接着我们可以调用损失函数来更新权重。
- 这是的损失函数使用交叉熵和L1范数损失。
- 关于TinySSD中的返回结果
- 第一个参数是锚框,形状是1,锚框总数,锚框位置坐标。
- 第二个参数先是批量大小,(锚框类别数+1)x通道数,这里是8,特征图大小,如32x32,然后形状转换成批量大小,锚框总数,预测类别个数。
- 第三个参数是批量大小,锚框数x4
- 关于准确率的评估。argmax返回的是索引下标,我们知道,神经网络返回的第二个参数的预测分类信息。其中,最后一维就是分类的类别。我们将该属性跟MultiBoxTarget预测判断得到准确率的评估。