YOLOv3框架
1.网络结构:

DBL:也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
res_n:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变
一个DBL包含一个conv、BN和leakyrelu。一个Res_unit包括两个DBL和一个add。Res_n包含一个zero padding、一个DBL和一个Res_uint。经过换算可以得出Res_1包含3个DBL(2x1+1), Res_2包含5个DBL(2x2+1), Res_4包含9个DBL(2x4+1), Res_8包含17个DBL(2x8+1)
所以整个yolo_v3_body包含252层,包括add层23层,BN层和LeakyReLU层72层(17x2+9+5+3+5x3+5+1),conv(卷积层)一共有72+3=75层,其中有72层后面都会接BN+LeakyReLU的组合构成基本组件DBL。从结构图中可以发现上采样和concat都有2次,每个res_block都会用上一个零填充,一共有5个res_block.

从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后
2.darknet-53 模型
YOLOv3使用了darknet-53的前面的52层(没有池化层和全连接层),YOLOv3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
在yolo_v2中,yolo_v2中对于前向过程中张量尺寸变换,都是通过最大池化来进行,一共有5次,经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数,而v3是通过卷积核增大步长来进行,也是5次。(darknet-53最后面有一个全局平均池化,在yolo-v3里面没有这一层,所以张量维度变化只考虑前面那5次
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。

3.输出
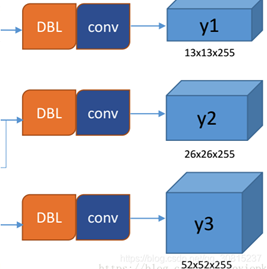
yolo v3输出了3个不同尺度的feature map,y1,y2和y3的深度都是255,边长的规律是13:26:52。预测图深度为Bx(5+C),其中B为预测的边框数(box),5是每个box的参数(x, y, w, h, confidence),C是类别。本示例中每个网格单元预测3个box, 深度255=3x(5+80)
网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此YOLOv3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同。YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(1313、2626和52*52),在多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显。
4.边框坐标
Bounding bo
yolo v3输出d的3个不同尺度的feature map,feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测以下东西:x,y,w,h, objectness prediction,以及类别
YOLOv3具有三个锚框,可以预测每个单元格三个边界框,和边界框的回归。对于有C个目标类别的数据集,每个特征图每个网格单元输出的维度为N x (C+5),其中N表示每个单元需要预测的标注框数量。在 YOLOv3中N = 3,对于每个标注框则需要预测C+5个元素。其中C个元素用于对目标类别进行预测,4个元素用于预测实际标注框相对于采用k-means聚类得到的先验框的偏移。该偏移量可以使用实际边框中心点相对于该网格单元左上角的位置和实际边框尺寸相对于先验框尺寸的缩放比例来表示,预测边框坐标表示如下;


中心坐标
通过sigmoid函数进行中心坐标预测,强制将值限制在0和1之间。YOLO不是预测边界框中心的绝对坐标,它预测的是偏移量:相对于预测对象的网格单元的左上角;通过特征图cell归一化维度。
5.边界框维度
通过对输出应用对数空间转换,然后与锚框相乘,可以预测边界框的尺寸

6.物体分数和类置信度
物体分数表示一个边界框包含一个物体的概率,对于红色框和其周围的框几乎都为1,但边角的框可能几乎都为0。物体分数也通过一个sigmoid函数,表示概率值。类置信度表示检测到的物体属于一个具体类的概率值,以前的YOLO版本使用softmax将类分数转化为类概率。在YOLOv3中作者决定使用sigmoid函数取代,原因是softmax假设类之间都是互斥的,例如属于“Person”就不能表示属于“Woman”,然而很多情况是这个物体既是“Person”也“Woman”。
7.不同尺度的预测
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box
为了识别更多的物体,尤其小物体,YOLOv3使用三个不同尺度进行预测(不仅仅只使用13x13)。三个不同尺度步幅分别是32、16和8。这意味着,输入416x416图像,检测尺度分别为13x13、26x26和52x52(如下图或者更详细如图2所示)。
YOLOv3为每种下采样尺度设定3个先验框,总共聚类9个不同尺寸先验框。在COCO数据集上9个先验框分别是:(10x13)(16x30)(33x23)(30x61)(62x45)(59x119)(116x90)(156x198)(373x326)下表是9个先验框分配情况:


8.输出处理
(1)我们通过物体分数过滤一些锚框,例如低于阈值(假设0.5)的锚框直接舍去
(2)使用NMS(非极大值抑制)解决多个锚框检测一个物体的问题(例如红色框的3个锚框检测一个框或者连续的cell检测相同的物体,产生冗余),NMS用于去除多个检测框。
注:NMS里有一个IOU实现非极大值抑制,关键:选择一个最高分数的框;计算它和其他框的重合度,去除重合度超过IoU阈值的框;一直迭代直到没有比当前所选框低的框


写的有点乱,刚开始学习,后边会慢慢整理
参考:
https://blog.csdn.net/qq_30815237/article/details/91949543
https://www.jianshu.com/p/cad68ca85e27
https://www.jianshu.com/p/043966013dde
https://blog.csdn.net/qq_40716944/article/details/114822515?
spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link