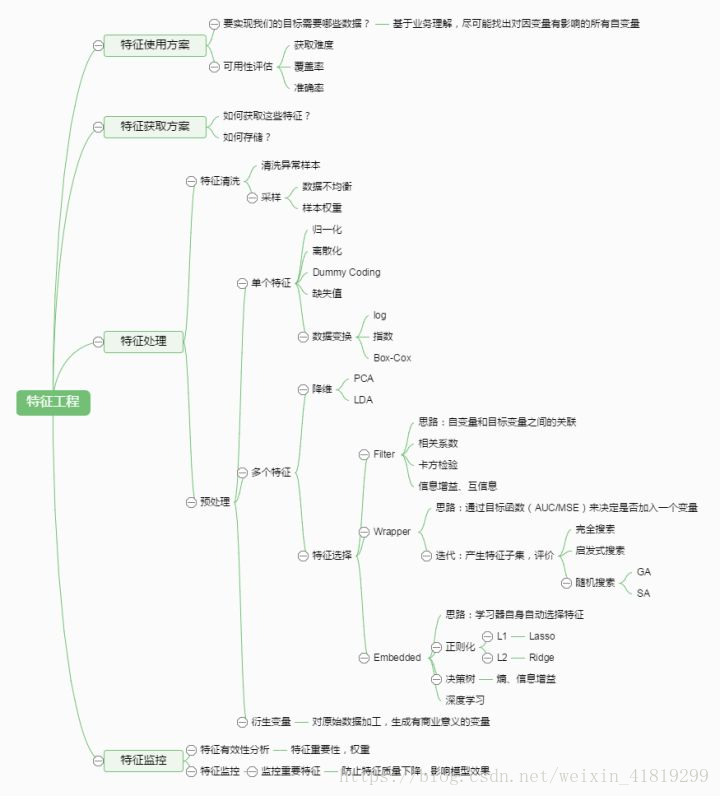
特征工程目的:
降维/降低过拟合/泛化、解释性、加快训练速度、性能
特征工程框图:
- 数据预处理
无量纲化:转化不同规格的特征到同一规格
(1)标准化/z标准化
将符合正态分布的特征值转化为标准正态分布
使用sklearn.preproccessing库的StandardScaler类
(2)区间缩放法/线性归一化/0-1标准化
返回缩放到[0,1]区间的数据
使用sklearn.preproccessing库的MinMaxScaler类
(3)归一化
将每个样本缩放到单位范数,转化为单位向量
离散化:
对定量特征二值化:大于阈值设为1
使用sklearn.preproccessing库的Binarizer类
对字符特征编码:
对定性特征哑编码:
使用sklearn.preproccessing库的OneHotEncoder类
缺失值处理:
删除缺失行、删除特征、补中值、补均值、将NaN作为一个特征、随机森林等算法填充
使用sklearn.preproccessing库的Imputer类
数据变换:
基于多项式、基于指数函数、基于对数函数



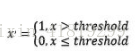
- 特征选择
选择标准:方差大(发散性)、与目标的相关性
Filter过滤法:
(1) 设定发散性的阈值
使用sklearn.feature_selection库的VarianceThreshold类
(2)设定皮尔森相关系数相关性的阈值(衡量服从正态分布的随机变量的线性相关性)
皮尔森相关系数计算速度快,取值区间[-1,1],衡量正负相关性
使用皮尔森相关系数库pearsonr结合sklearn.feature_selection库的SelectKBest类
(3)卡方检验,检验定性自变量对定性因变量的相关性(分类问题)
使用sklearn.feature_selection库的SelectKBest类 和chi2
(4)互信息,检验定性自变量对定性因变量的相关性(回归问题、衡量线性及非线性关系)
使用MINE和klearn.feature_selection库的SelectKBest类
Wrapper包装法/包装法:每次选择或排除若干特征,选择最佳特征子集
(1)前向搜索
在开始时,按照特征数来划分子集,每个子集只有一个特征,对每个子集进行评价。然后在最优的子集上逐步增加特征,使模型性能提升最大,直到增加特征并不能使模型性能提升为止。
(2)后向搜索
在开始时,将特征集合分别减去一个特征作为子集,每个子集有N—1个特征,对每个子集进行评价。然后在最优的子集上逐步减少特征,使得模型性能提升最大,直到减少特征并不能使模型性能提升为止。
(3)双向搜索
结合(1)(2)
(4) 递归特征消除法
反复的训练模型,并剔除每次的最优或者最差的特征,将剔除完毕的特征集进入下一轮训练,直到所有的特征被剔除,被剔除的顺序度量了特征的重要程度。
Embedded集成法/嵌入法:通过机器学习得到各个特征的权值系数
(1)基于L1、L2正则化的特征选择法
增加L2的做法:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型:
使用feature_selection库的SelectFromModel类结合sklearn.linear_model库的 LogisticRegression逻辑回归类
(2)基于树模型的特征选择法
基于信息增益、信息增益比(应对偏向问题)、基尼指数
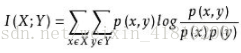
基于gbdt
使用feature_selection库的SelectFromModel类结合sklearn.ensemble 库的GradientBoostingClassifier类
基于RF
(1)方法一
分类问题:基尼不纯度或者信息增益
回归问题:方差或者最小二乘拟合
两个主要问题:1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。
(2)方法二:平均精确率减小
打乱每个特征的特征值顺序,度量顺序变动对模型精确率的影响
基于xgboost
分离点时根据基尼指数,特征评分基于特征被选择的次数(稳定性选择?)
- 降维
基于L1惩罚项的模型:
PCA主成分分析:
选择方差大的新坐标轴
使用decomposition 库的PCA类
LDA线性判别分析(有监督):
选择分类情况更好的投影方式,投影后不同类中心点距离远,同类点离散性小
使用lda库的LDA类
ICA独立成分分析:
寻找分离矩阵W,逼近独立元矩阵s,找到相互独立的属性
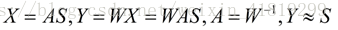
在计算机有限空间上降维:
1、关闭其他程序
2、随机采样数据集,行采样
3、PCA挑选大方差成分
4、在线学习
5、删去关联特征
6、随机梯度下降
7、基于对业务的理解主观判断
相关文章推荐:
sklearn库介绍:
https://blog.csdn.net/kevinelstri/article/details/60960574
特征工程:
https://www.zhihu.com/question/29316149