经常是错误的动作,没有reward,只能随机动作,很慢
引导的reward

需要领域知识,与实际任务相关

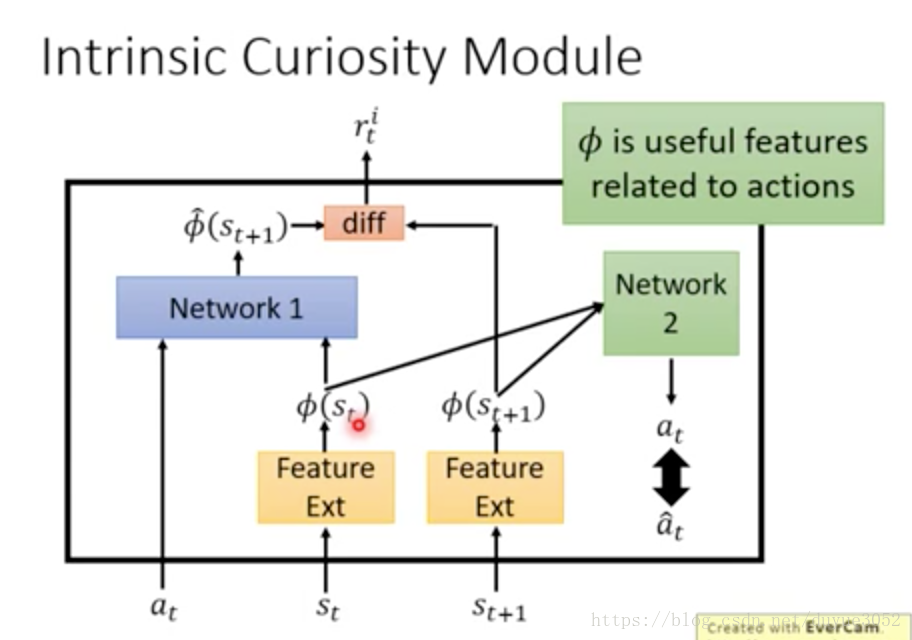
好奇心reward——期待状态变化——重要的状态
network2是要从两个状态之间的到action,说明是重要的

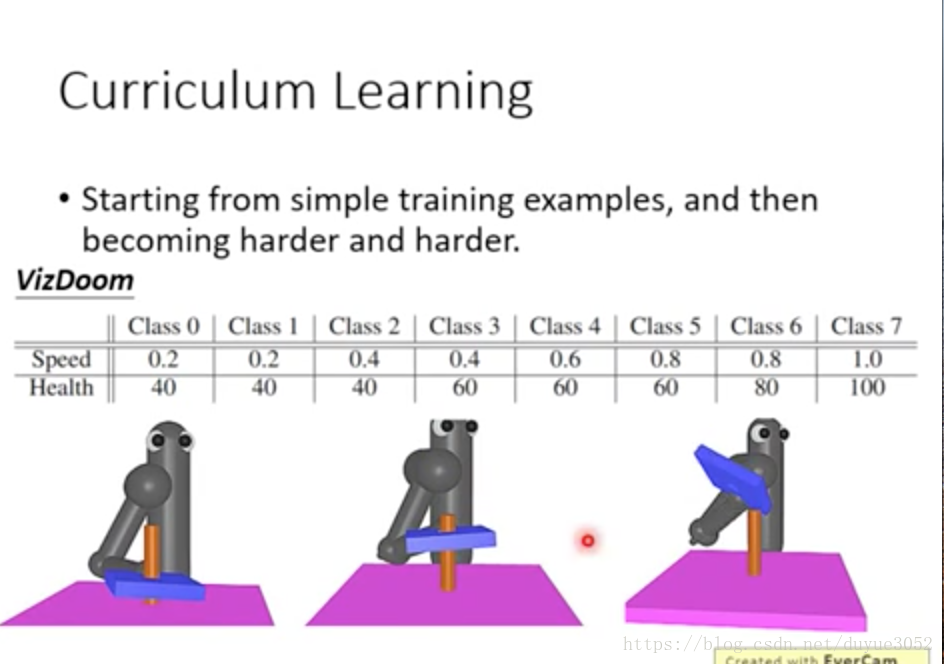
train data要有顺序,从易到难——ML的通用技巧
阶层学习——大目标到小而具体的目标



黄色的是上层agent的目标,紫色的是上层agent给下层agent提出的目标。
经常是错误的动作,没有reward,只能随机动作,很慢
引导的reward
需要领域知识,与实际任务相关
好奇心reward——期待状态变化——重要的状态
network2是要从两个状态之间的到action,说明是重要的
train data要有顺序,从易到难——ML的通用技巧
阶层学习——大目标到小而具体的目标
黄色的是上层agent的目标,紫色的是上层agent给下层agent提出的目标。