YOLO
一.背景
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。在2017年CVPR上,Joseph Redmon和Ali Farhadi又发表的YOLO 2,进一步提高了检测的精度和速度。

二.YOLO算法的网络结构
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )。

三.YOLO算法流程 与 步骤
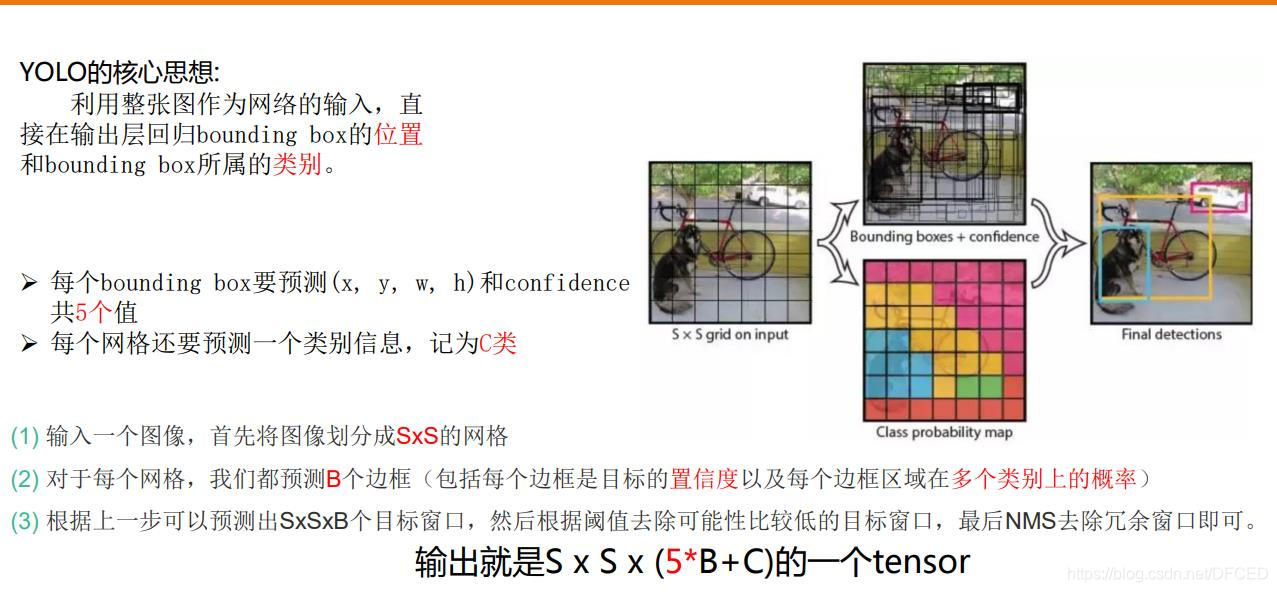
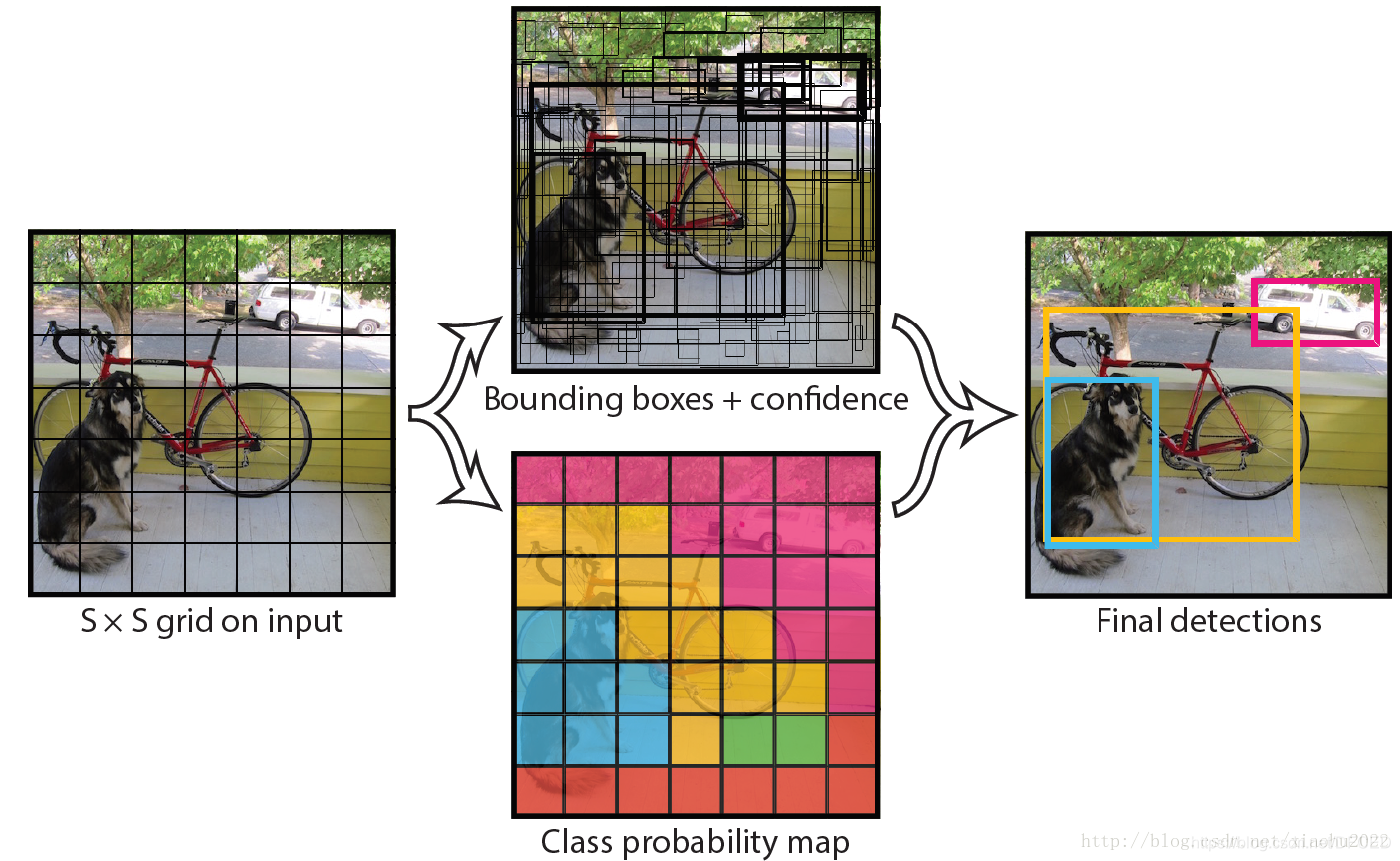
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。
流程
- 将图片resize到448*448大小。
- 将图片放到网络里面进行处理。
- 进行非极大值抑制处理得到结果。
3.1 图像分割
Yolo的CNN网络将输入的图片分割成S×S网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。

(图片来自网络)
YOLO图像分割流程
假设图像的大小是100∗100,然后在图像上放一个网格,为了描述的简洁,在此使用3∗3的网格,实际中会使用更加精细复杂的网格,可能是19∗19.
- 基本思想是使用图像分类和定位算法(image classification and Localization algorithm)然后将算法应用到九个格子上
- 然后需要对每个小网格定义一个5+k(k为预测类别个数)维向量的目标标签
- YOLO算法使用的是取目标对象边框中心点的算法,即考虑边框的中心点在哪个格子中
3.2 图片在网格中的处理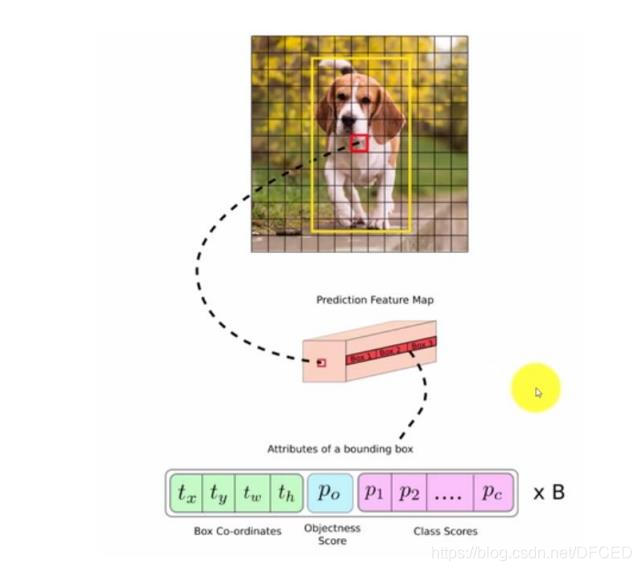
每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0。而当该边界框包含目标时,Pr(object)=1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOUtruthpredI。因此置信度可以定义为Pr(object)∗IOUtruthpred。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x,y,w,h),其中(x,y)是边界框的中心坐标,而w和h是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的w和h预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0,1]范围。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。
还有分类问题,对于每一个单元格其还要给出预测出C个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率,即Pr(classi|object)。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores):Pr(classi|object)∗Pr(object)∗IOUtruthpred=Pr(classi)∗IOUtruth。边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。
每个单元格需要预测(B∗5+C)个值。如果将输入图片划分为S×S网格,那么最终预测值为S×S×(B∗5+C)大小的张量。整个模型的预测值结构如下图所示。对于PASCAL VOC数据,其共有20个类别,如果使用S=7,B=2S=7,B=2,那么最终的预测结果就是7×7×307×7×30大小的张量。
3.3用非极大值抑制得到结果
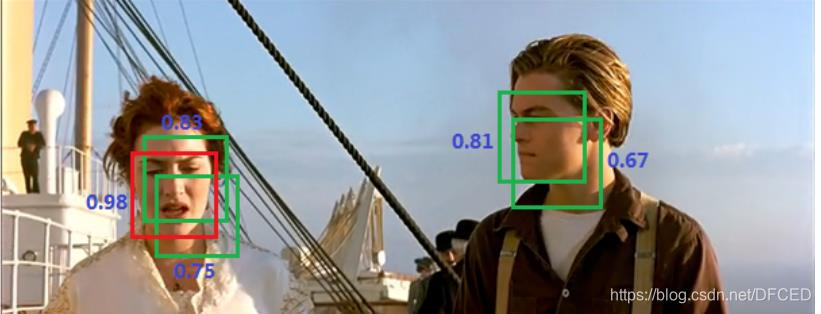
非极大值抑制算法(non maximum suppression, NMS),这个算法不单单是针对Yolo算法的,而是所有的检测算法中都会用到。NMS算法主要解决的是一个目标被多次检测的问题,如图中人脸检测,可以看到人脸被多次检测,但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于美女,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。Yolo预测过程也需要用到NMS算法
四.YOLO算法网络的训练过程
yolo的基础网络灵感来源于GoogLeNet,但是并没有采取其inception的结构,而是简单的使用了1×1的卷积核。base model共有24个卷积层,后面接2个全连接层
在训练网络的时候,作者首先用ImageNet预训练前20个卷积层,作者训练的结果是top-5 accuracy = 88%
训练好分类网络后,进行检测的训练,由于检测一般需要较大的分辨率,所以作者将输入图像大小修改为448*448
另外yolo并没有使用Relu激活函数,而是使用了leaky rectified linear激活函数,如下:

五.损失函数
5.1 bounding box的(x, y, w, h)的坐标预测误差。
缩进在检测算法的实际使用中,一般都有这种经验:对不同大小的bounding box预测中,相比于大box大小预测偏一点,小box大小测偏一点肯定更不能被忍受。所以在Loss中同等对待大小不同的box是不合理的。为了解决这个问题,作者用了一个比较取巧的办法,即对w和h求平方根进行回归。从后续效果来看,这样做很有效,但是也没有完全解决问题。
5.2 bounding box的confidence预测误差
缩进由于绝大部分网格中不包含目标,导致绝大部分box的confidence=0,所以在设计confidence误差时同等对待包含目标和不包含目标的box也是不合理的,否则会导致模型不稳定。作者在不含object的box的confidence预测误差中乘以惩罚权重λnoobj=0.5。
缩进除此之外,同等对待4个值(x, y, w, h)的坐标预测误差与1个值的conference预测误差也不合理,所以作者在坐标预测误差误差之前乘以权重λcoord=5(至于为什么是5而不是4,我也不知道T_T)。
5.3 分类预测误差
缩进即每个box属于什么类别,需要注意一个网格只预测一次类别,即默认每个网格中的所有B个bounding box都是同一类。
综上所述,YOLO的最终误差为下:
Loss = λcoord * 坐标预测误差 + (含object的box confidence预测误差 + λnoobj * 不含object的box confidence预测误差) + 类别预测误差

六.YOLO 算法 的 不足

参考:
复旦大学 《深度学习》