百度飞桨零基础实践深度学习目标检测系列学习笔记
目录
YOLOv3结构
YOLOv3网络结构特点:
1.只有卷积没有池化
2.3个特征图检测不同尺寸物体
3.使用ResNet结构
4.3个特征图使用add进行拼接
5.使用sigmoid来实现多类别
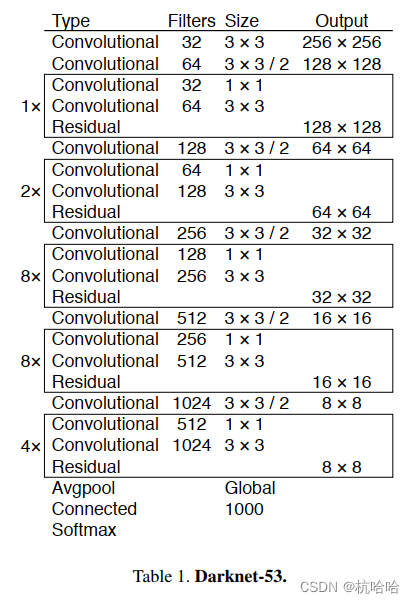
Backbone**:Darknet53** 使用主干网络中的1/8,1/16,1/32的三个特征图进行特征图融合。网络中使用残差结构。
为什么使用它:比同精度的ResNet快很多,比Darknet19慢点但精度更高。


shape格式与先验框
SxSx3x(C+5):尺寸,先验框数量3个,检测框位置(XYHW4),检测置信度(1),类别维度(C)
使用聚类对标签框,得到9个框,来作为先验框:
(10 × 13), (16 × 30), (33 × 23), (30 × 61), (62 × 45), (59 ×
119), (116 × 90), (156 × 198), (373 × 326).
网络输出检测框如下:
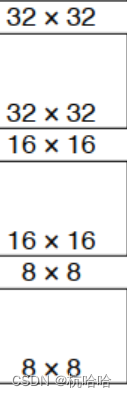
box的处理流程
1.通过三个特征图获取到:883,16163,32323 ,每个格子3个框,一共4032个数量的box。
2.送入loss计算。
3.推理时设置置信度阈值,然后使用NMS输出预测结果。
训练策略与损失函数
预测框: 正例 (positive) 、负例 (negative) 、忽略样例 (ignore)
正例: 取一个ground truth,与预测框全部计算IOU,最大的为正例,
正例产生置信度loss、检测框loss、类别loss。
负例: 与全部ground truth的IOU都小于闻值 (0.5) ,则为负例。
负例只有分类置信度产生loss,分类标签为0,边框回归不产生loss。
忽略样例: 正例除外,与任意一个ground truth的IOU大于阀值 (论文中使用0.5) ,则为忽略样例。忽略样例不产生任何loss。
记录:对于负例,只会参与分类置信度的Focal Loss的计算,不会对分类和边框回归的Loss产生影响。因为对于负例来说,它们不包含目标物体,所以它们不需要参与目标的分类和位置回归的Loss的计算。
负例,虽然它们不是目标,但是它们可能会被预测为某个目标。如果我们完全不考虑负例的情况,那么网络可能会忽略一些负例,而这些负例可能包含一些与目标非常相似的特征。因此,对于负例,我们需要在分类置信度的损失函数中进行惩罚,以鼓励网络对负例做出更准确的预测。这就是为什么负例也需要参与分类置信度的 Focal Loss 的计算的原因。
损失函数:置信度loss,检测框loss,类别loss
置信度loss:FOCAL = FocalLoss(gamma=2, alpha=1.0, reduction="none")
检测框loss:giou = tools.GIOU_xywh_torch(p_d_xywh, label_xywh).unsqueeze(-1)
类别loss:BCE = nn.BCEWithLogitsLoss(reduction="none")
YOLOv3代码解读
1.网络forward部分
def forward(self, x):
out = []
#通过Darknet53提取三个feature
x_s, x_m, x_l = self.__backnone(x)
#通过FPN进行concat与输出
x_s, x_m, x_l = self.__fpn(x_l, x_m, x_s)
#将三个不同尺寸的feature送入head进行解码
#也就是将三个输出解码成预测框!!
out.append(self.__head_s(x_s))
out.append(self.__head_m(x_m))
out.append(self.__head_l(x_l))
if self.training:
p, p_d = list(zip(*out))
return p, p_d # smalll, medium, large
else:
p, p_d = list(zip(*out))
return p, torch.cat(p_d, 0)
2.YOLOv3_head部分
原理是这些公式的实现:
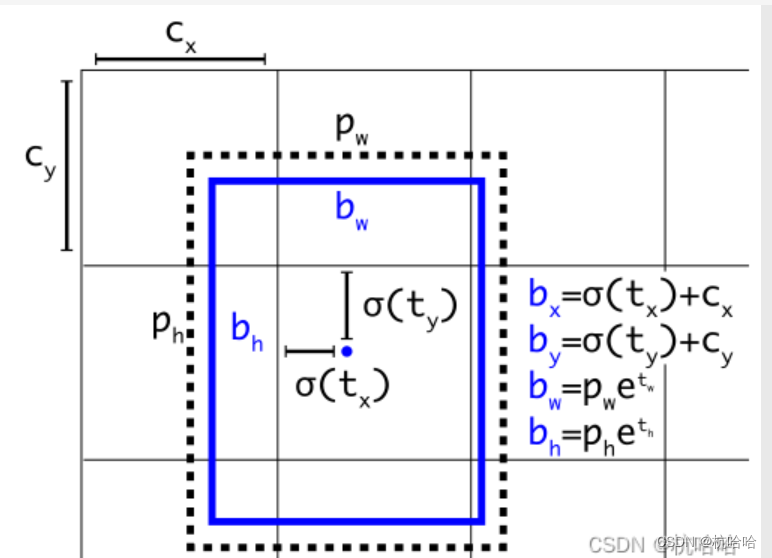
class Yolo_head(nn.Module):
def __init__(self, nC, anchors, stride):
super(Yolo_head, self).__init__()
# anchors是先验框(v3中是每个尺度三个先验框),nA是先验框的个数,nC是类别的个数,stride是步长
self.__anchors = anchors
self.__nA = len(anchors)
self.__nC = nC
self.__stride = stride
def forward(self, p):
# 获取输入的batch_size和特征图大小
bs, nG = p.shape[0], p.shape[-1]
# 将p转为bs,nA,nC+5,nG,nG的形状,注意这里将类别+5是因为每个anchor对应的输出包含:tx,ty,tw,th,confidence,类别概率
# 因此5+C的形状
p = p.view(bs, self.__nA, 5 + self.__nC, nG, nG).permute(0, 3, 4, 1, 2)
# 将预测的特征图解码,返回解码后的预测值
p_de = self.__decode(p.clone())
return (p, p_de)
def __decode(self, p):
# 获取batch_size和输出大小
batch_size, output_size = p.shape[:2]
# 获取当前设备
device = p.device
# 获取步长和先验框,转化为device类型
stride = self.__stride
anchors = (1.0 * self.__anchors).to(device)
# 预测中心坐标、宽高、置信度以及类别概率
conv_raw_dxdy = p[:, :, :, :, 0:2]
conv_raw_dwdh = p[:, :, :, :, 2:4]
conv_raw_conf = p[:, :, :, :, 4:5]
conv_raw_prob = p[:, :, :, :, 5:]
# 将特征图中心坐标转为全图坐标
y = torch.arange(0, output_size).unsqueeze(1).repeat(1, output_size)
x = torch.arange(0, output_size).unsqueeze(0).repeat(output_size, 1)
grid_xy = torch.stack([x, y], dim=-1)
grid_xy = grid_xy.unsqueeze(0).unsqueeze(3).repeat(batch_size, 1, 1, 3, 1).float().to(device)
# 计算预测的坐标和宽高
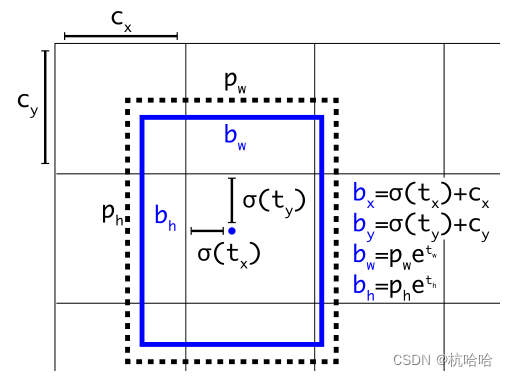
pred_xy = (torch.sigmoid(conv_raw_dxdy) + grid_xy) * stride
pred_wh = (torch.exp(conv_raw_dwdh) * anchors) * stride
# 将预测的坐标和宽高拼接在一起得到预测的边界框
pred_xywh = torch.cat([pred_xy, pred_wh], dim=-1)
# 计算预测的置信度和类别概率
pred_conf = torch.sigmoid(conv_raw_conf)
pred_prob = torch.sigmoid(conv_raw_prob)
# # 将预测的边界框、置信度和类别概率拼接在一起得到最终的预测
pred_bbox = torch.cat([pred_xywh, pred_conf, pred_prob], dim=-1)
return pred_bbox.view(-1, 5 + self.__nC) if not self.training else pred_bbox
 代码中这段为确定anchor的中心点,中心点为每个网格的左上角,每个网格生成三个先验框。
代码中这段为确定anchor的中心点,中心点为每个网格的左上角,每个网格生成三个先验框。