论文地址:https://arxiv.org/abs/2106.13797
源码地址:https://github.com/whai362/PVT
Abstract
在这项工作中,作者改进了PVT v1,提出了新的基线,包括(1)线性复杂度注意层,(2)重叠patch嵌入,(3)卷积前馈网络。通过这些修改,PVT v2将PVT v1的计算复杂度降低到线性,并在分类、检测和分割等基本视觉任务上取得了显著的改进。
3. Methodology
3.1. Limitations in PVT v1
PVT v1 [33]有三个主要限制: (1)与ViT [8]类似,当处理高分辨率输入(例如,短边为800像素)时,PVT v1的计算复杂度相对较大。(2) PVT v1 [33]将图像视为一系列不重叠的斑块,在一定程度上失去了图像的局部连续性;(3)PVTv1中的位置编码是固定大小的,对于任意大小的处理图像是不灵活的。这些问题限制了PVT v1在视觉任务上的性能。
3.2. Linear Spatial Reduction Attention
首先,为了降低注意操作引起的高计算成本,我们提出了线性空间减少注意(SRA)层,如图1所示。与使用卷积进行空间约简的SRA [33]不同,线性SRA使用平均池化将空间维数(即h×w)降低到固定的大小(即P×P)。因此,线性SRA就像卷积层一样具有线性计算和内存成本。具体来说,给定大小为h××的输入,SRA和线性SRA的复杂度为:

3.3. Overlapping Patch Embedding
其次,为了对局部连续性信息进行建模,我们利用重叠斑块嵌入技术对图像进行标记化。如图2(a)所示,我们扩大了补丁窗口,使相邻的窗口重叠了一半的区域,并用零填充特征图以保持分辨率。在这项工作中,我们使用卷积与零的补丁来实现重叠的补丁嵌入。具体来说,给定大小为h×w×c的输入,我们将其与S的步幅、2S−1的核大小、S−1的填充大小和的核数进行卷积。输出大小为
![]() 。
。
3.4. Convolutional Feed-Forward
第三,受[17,6,20]的启发,我们删除了固定大小的位置编码[8],并在PVT中引入零填充位置编码。如图2(b)所示,我们在前馈网络中第一个全连接(FC)层和GELU [15]之间添加了3×3的深度可分离卷积[16]。
在PVT V1中,位置编码是使用nn.Parameter生成一组可学习的位置编码,在PVT V2中,直接删除了位置编码,作者直接删除了位置编码,在MLP层中添加了深度卷积(用0进行权重初始化)

3.5. Details of PVT v2 Series
参考resnet的设置
 3.6. Advantages of PVT v2
3.6. Advantages of PVT v2
结合这些改进,PVT v2可以(1)获得更多的图像和特征图的局部连续性;(2)更灵活地处理可变分辨率的输入;(3)享受与CNN相同的线性复杂度。
4. Experiment
4.1. Image Classifification

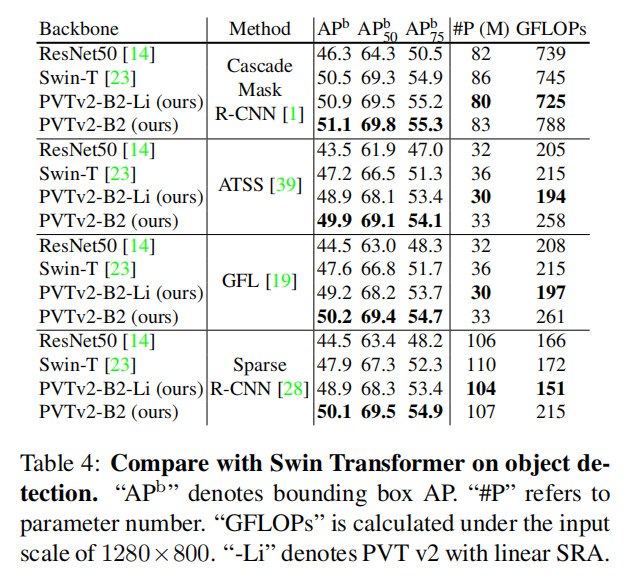
4.2. Object Detection

4.3. Semantic Segmentation

4.4. Ablation Study
4.4.1 Model Analysis
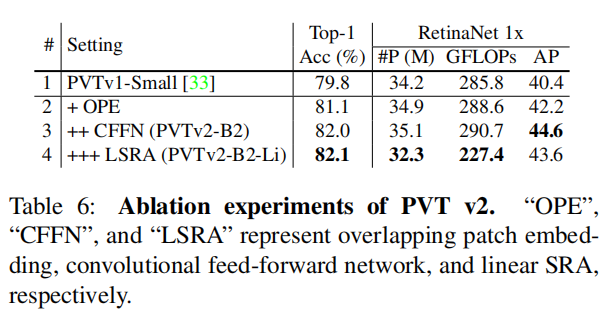
Overlapping patch embedding (OPE) is important.
OPE是有效的,因为它可以通过重叠的滑动窗口来建模图像和特征图的局部连续性。
Convolutional feed-forward network (CFFN) matters.
与原始的前馈网络(FFN)[8]相比,我们的CFFN包含了一个零填充的卷积层。它可以捕获输入张量的局部连续性。此外,由于OPE和CFFN中的零加法引入的位置信息,我们可以删除PVT v1中使用的固定大小的位置嵌入,使模型能够灵活地处理可变分辨率的输入。
Linear SRA (LSRA) contributes to a better model.
LSRA的计算成本低,效果好。
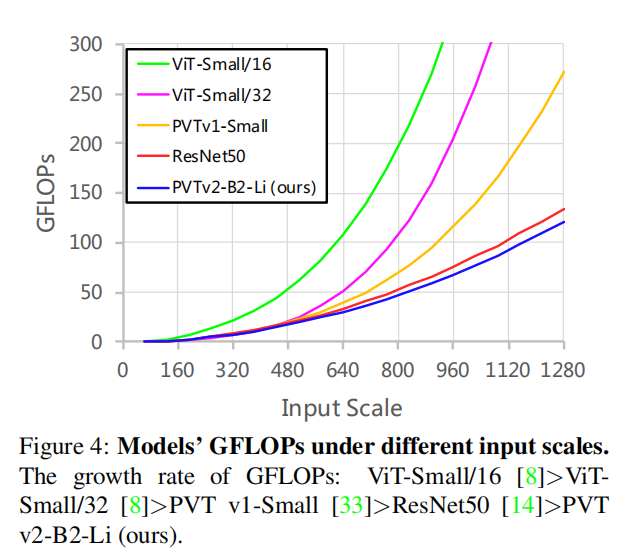
4.4.2 Computation Overhead Analysis
PVT V2开销更低