2021-ICCV-Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions
Pyramid Vision Transformer:用于无卷积密集预测的多功能骨干
摘要
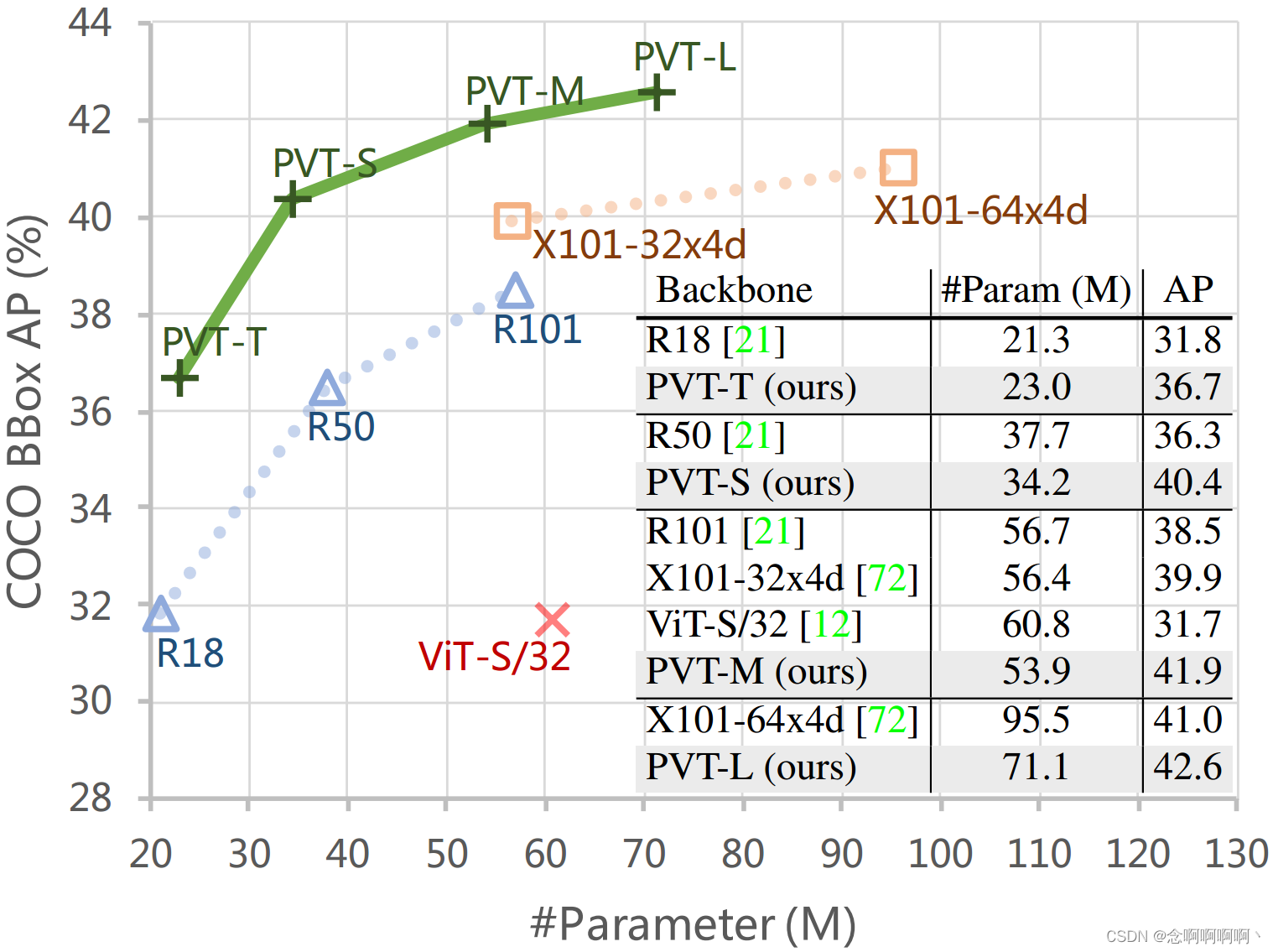
尽管卷积神经网络(CNN)在计算机视觉领域取得了巨大成功,但这项工作研究了一种更简单、无卷积的骨干网络,可用于许多密集预测任务。与最近提出的专为图像分类设计的 Vision Transformer(ViT)不同,我们引入了 Pyramid Vision Transformer(PVT),它克服了将 Transformer 移植到各种密集预测任务的困难。与当前的技术水平相比,PVT 有几个优点。(1)与通常产生低分辨率输出并导致高计算和内存成本的 ViT 不同,PVT 不仅可以在图像的密集分区上进行训练以获得高输出分辨率,这对于密集预测很重要,而且还使用渐进式收缩 金字塔以减少大型特征图的计算。(2)PVT 继承了 CNN 和 Transformer 两者的优点,使其成为无需卷积的各种视觉任务的统一骨干,可以直接替代 CNN 骨干。(3)我们通过大量实验验证了 PVT,表明它提高了许多下游任务的性能,包括对象检测、实例和语义分割。例如,在参数数量相当的情况下,PVT+RetinaNet 在 COCO 数据集上实现了 40.4 AP,超过 ResNet50+RetinNet(36.3 AP)4.1 个绝对 AP(见图 2)。我们希望 PVT 可以作为像素级预测的替代和有用的支柱,并促进未来的研究。
1. 引言
卷积神经网络(CNN)在计算机视觉领域取得了显着的成功,使其成为几乎所有任务的通用且占主导地位的方法 [53、21、72、48、20、38、8、31]。尽管如此,这项工作旨在探索 CNN 之外的替代骨干网络,除了图像分类 [11] 之外,它还可用于密集预测任务,例如对象检测 [39、13]、语义 [81] 和实例分割 [39]。
受 Transformer [63] 在自然语言处理方面的成功启发,许多研究人员探索了它在计算机视觉中的应用。例如,一些作品 [5、82、71、55、23、41] 将视觉任务建模为具有可学习查询的字典查找问题,并使用 Transformer 解码器作为 CNN 骨干之上的特定任务头。尽管一些现有技术也已将注意力模块 [69、47、78] 纳入 CNN,但据我们所知,很少研究探索干净且无卷积的 Transformer 骨干来解决计算机视觉中的密集预测任务。
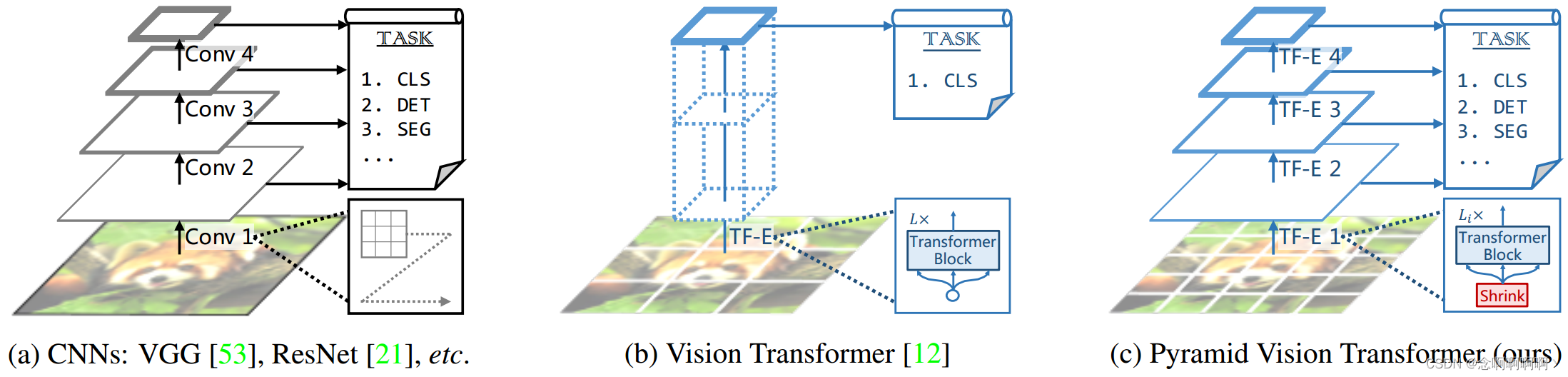
最近,Dosovitskiy 等人 [12] 介绍了用于图像分类的 Vision Transformer(ViT)。这是用无卷积模型代替 CNN 骨干的一次有趣且有意义的尝试。如图 1(b)所示,ViT 具有柱状结构,以粗糙的图像块作为输入。尽管 ViT 适用于图像分类,但将其直接应用于对象检测和分割等像素级密集预测具有挑战性,因为(1)它的输出特征图是单尺度和低分辨率的,(2)即使对于常见的输入图像尺寸(例如,COCO 基准测试中 800 像素的短边 [39]),它的计算和存储成本也相对较高。
为了解决上述限制,这项工作提出了一个纯 Transformer 骨干,称为 Pyramid Vision Transformer(PVT),它可以在许多下游任务中替代 CNN 骨干,包括图像级预测和像素级密集预测。具体来说,如图 1(c)所示,我们的 PVT 通过(1)将细粒度图像块(即每个块 4×4 像素)作为输入来学习高分辨率表示,从而克服了传统 Transformer 的困难,这对于密集预测任务至关重要;(2)引入渐进收缩金字塔随着网络加深减少 Transformer 的序列长度,显着降低计算成本,以及(3)采用空间减少注意力(SRA)层进一步减少学习高分辨率特征时的资源消耗。
总体而言,提出的 PVT 具有以下优点。首先,与具有随网络深度增加的局部感受野的传统 CNN 骨干(见图 1(a))相比,我们的 PVT 始终产生全局感受野,更适合检测和分割。其次,与 ViT(见图 1(b))相比,由于其先进的金字塔结构,我们的方法可以更容易地插入许多具有代表性的密集预测管道,例如 RetinaNet [38] 和 Mask R-CNN [20]。第三,我们可以通过将我们的 PVT 与其他任务特定的 Transformer 解码器(例如用于对象检测的 PVT+DETR [5])相结合来构建无卷积管道。据我们所知,这是第一个完全无卷积的对象检测管道。
我们的主要贡献如下:
- 我们提出 Pyramid Vision Transformer(PVT),这是第一个专为各种像素级密集预测任务设计的纯 Transformer 骨干。结合我们的 PVT 和 DETR,我们可以构建一个端到端的目标检测系统,无需卷积和手工制作的组件,例如密集锚点和非最大抑制(NMS)。
- 我们通过设计渐进收缩金字塔和空间缩减注意力(SRA),克服了将 Transformer 移植到密集预测时的许多困难。这些都能够减少 Transformer 的资源消耗,使 PVT 可以灵活地学习多尺度和高分辨率的特征。
- 我们在几个不同的任务上评估提出的 PVT,包括图像分类、对象检测、实例和语义分割,并将其与流行的 ResNets [21] 和 ResNeXts [72] 进行比较。如图 2 所示,与现有技术相比,我们具有不同参数尺度的 PVT 可以始终如一地提高性能。例如,在相当数量的参数下,使用 RetinaNet [38] 进行对象检测,PVT-Small 在 COCO val2017 上实现了 40.4 AP,比 ResNet50 高出 4.1 个点(40.4 对 36.3)。此外,PVT-Large 达到了 42.6 AP,比 ResNeXt101-64x4d 好 1.6 个点,参数减少了 30%。
2. 相关工作
2.1. CNN 骨干
CNN 是深度神经网络在视觉识别中的主力军。标准 CNN 在 [33] 中首次引入,用于区分手写数字。该模型包含具有特定感受野的卷积核,该感受野捕捉有利的视觉上下文。为了提供平移等方差,卷积核的权重在整个图像空间上共享。最近,随着计算资源(例如 GPU)的快速发展,在大规模图像分类数据集(例如 ImageNet [50])上成功训练堆叠卷积块 [32、53] 已成为可能。例如,GoogLeNet [58] 证明包含多个内核路径的卷积运算符可以获得非常有竞争力的性能。Inception 系列 [59、57]、ResNeXt [72]、DPN [9]、MixNet [64] 和 SKNet [35] 进一步验证了多路径卷积块的有效性。此外,ResNet [21] 在卷积块中引入了残差连接,使得创建 / 训练非常深的网络成为可能,并在计算机视觉领域取得了令人瞩目的成果。DenseNet [24] 引入了一种密集连接的拓扑结构,它将每个卷积块连接到所有先前的块。在最近的调查 / 评论论文 [30、52] 中可以找到更多最新进展。
与成熟的 CNN 不同,视觉 Transformer 骨干网仍处于早期发展阶段。在这项工作中,我们尝试通过设计适用于大多数视觉任务的新型多功能 Transformer 骨干来扩展 Vision Transformer 的范围。
2.2. 密集预测任务
Preliminary。密集预测任务旨在对特征图执行像素级分类或回归。对象检测和语义分割是两个具有代表性的密集预测任务。
Object Detection。在深度学习时代,CNN [33] 已成为目标检测的主要框架,其中包括单级检测器(例如,SSD [42]、RetinaNet [38]、FCOS [61]、GFL [36、34]、PolarMask [70] 和 OneNet [54])和多级检测器(Faster R-CNN [48]、Mask R-CNN [20]、Cascade R-CNN [4] 和 Sparse R-CNN [56])。大多数这些流行的物体检测器都是建立在高分辨率或多尺度特征图上以获得良好的检测性能。最近,DETR [5] 和可变形(deformable) DETR [82] 结合了 CNN 骨干和 Transformer 解码器来构建端到端对象检测器。同样,它们也需要高分辨率或多尺度特征图来进行准确的物体检测。
Semantic Segmentation。CNN 在语义分割中也起着重要作用。在早期阶段,FCN [43] 引入了一种全卷积架构来为任意大小的给定图像生成空间分割图。之后,Noh 等人 [46] 引入了反卷积操作,并在 PASCAL VOC 2012 数据集 [51] 上取得了令人印象深刻的性能。受 FCN 的启发,UNet [49] 被专门用于医学图像分割领域,桥接相同空间大小的相应低级和高级特征图之间的信息流。为了探索更丰富的全局上下文表示,Zhao 等人 [79] 设计了一个不同池化尺度的金字塔池化模块,而 Kirillov 等人 [31] 基于 FPN [37] 开发了一种称为语义 FPN 的轻量级分割头。最后,DeepLab 家族 [7、40] 应用扩张卷积来扩大感受野,同时保持特征图分辨率。与对象检测方法类似,语义分割模型也依赖于高分辨率或多尺度特征图。
2.3. 视觉中的 Self-Attention 和 Transformer
由于卷积过滤器的权重在训练后通常是固定的,因此它们不能动态适应不同的输入。已经提出了许多方法来使用动态过滤器 [29] 或自注意力操作 [63] 来缓解这个问题。非局部块(non-local block)[69] 试图在空间和时间上对远程依赖进行建模,这已被证明有利于准确的视频分类。然而,尽管取得了成功,但非局部运算符仍承受着高昂的计算和内存成本。Criss-cross [25] 通过交叉路径生成稀疏注意力图进一步降低了复杂性。Ramachandran 等人 [47] 提出了独立的自注意力来用局部自注意力单元代替卷积层。AANet [3] 在结合自注意力和卷积运算时取得了有竞争力的结果。LambdaNetworks [2] 使用 lambda 层,这是一种有效的自注意力来代替 CNN 中的卷积。DETR [5] 利用 Transformer 解码器将对象检测建模为具有可学习查询的端到端字典查找问题,成功消除了对 NMS 等手工处理的需求。在 DETR 的基础上,可变形 DETR [82] 进一步采用可变形注意层来关注一组稀疏的上下文元素,从而获得更快的收敛和更好的性能。最近,Vision Transformer(ViT)[12] 采用纯 Transformer [63] 模型通过将图像视为一系列块来进行图像分类。DeiT [62] 使用一种新的蒸馏方法进一步扩展了 ViT。与之前的模型不同,这项工作将金字塔结构引入到 Transformer 中,以呈现用于密集预测任务的纯 Transformer 骨干,而不是任务特定的头部或图像分类模型。
3. 金字塔视觉 Transformer(PVT)
3.1. 总体架构
我们的目标是将金字塔结构引入 Transformer 框架,使其能够为密集预测任务(例如,对象检测和语义分割)生成多尺度特征图。PVT 的概述如图 3 所示。与 CNN 骨干 [21] 类似,我们的方法有四个阶段,可生成不同尺度的特征图。所有阶段共享一个相似的架构,由块嵌入层(patch embedding)和 L i L_i Li Transformer 编码器层组成。
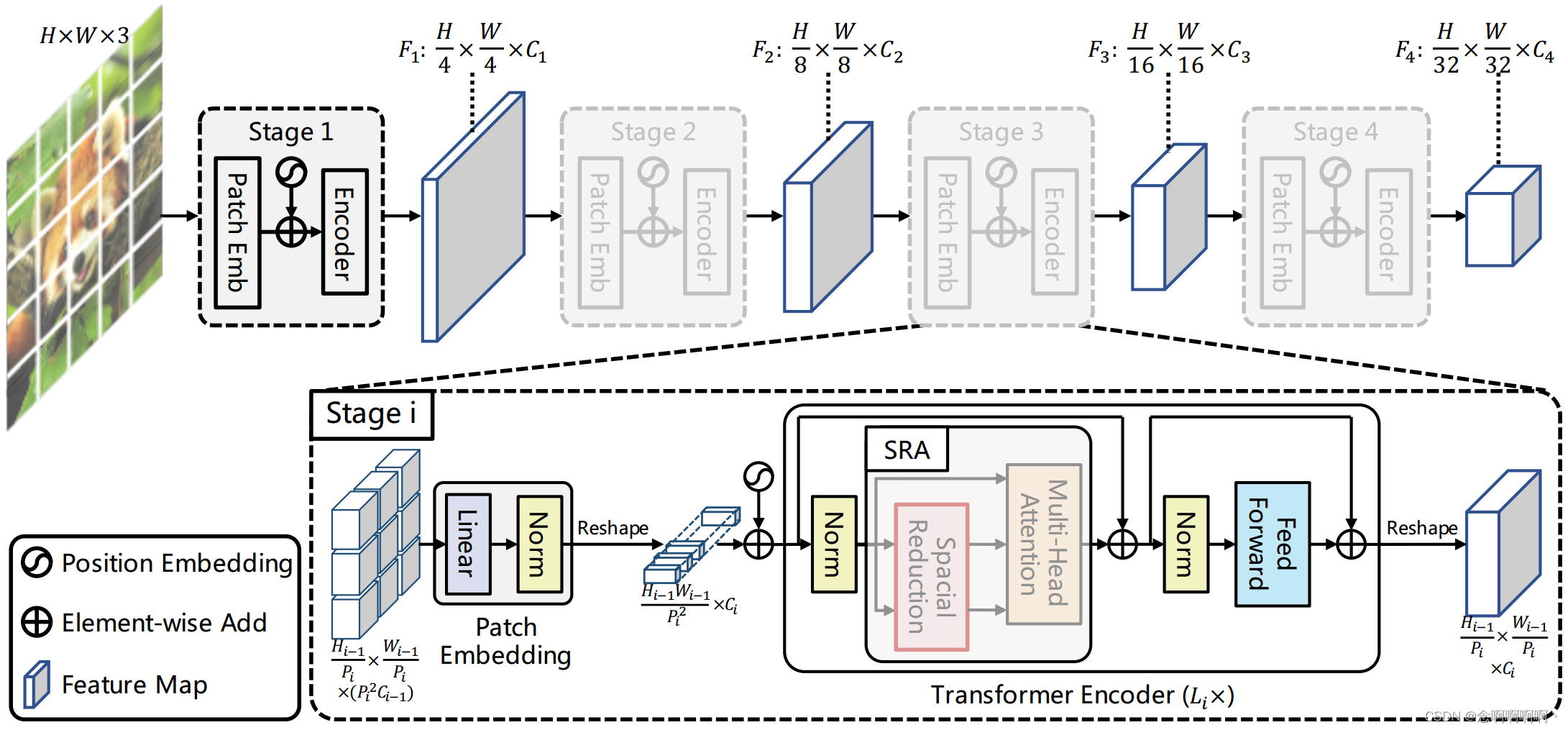
在第一阶段,给定大小为 H × W × 3 H\times W\times3 H×W×3 的输入图像,我们首先将其分成 H W 4 2 \frac{HW}{4^2} 42HW 个块,每个块大小为 4×4×3。然后,我们将展平的块提供给线性投影并获得大小为 H W 4 2 × C 1 \frac{HW}{4^2}\times C_1 42HW×C1 的嵌入块。之后,嵌入的块连同位置嵌入通过具有 L 1 L_1 L1 层的 Transformer 编码器传递,输出被重塑为大小为 H 4 × W 4 × C 1 \frac{H}{4}\times\frac{W}{4}\times C_1 4H×4W×C1 的特征图 F 1 F_1 F1。同样,使用前一阶段的特征图作为输入,我们得到以下特征图: F 2 F_2 F2、 F 3 F_3 F3 和 F 4 F_4 F4,其相对于输入图像的步幅分别为 8、16 和 32 像素。有了特征金字塔 { F 1 , F 2 , F 3 , F 4 } \left\{F_1,\ F_2,\ F_3,\ F_4\right\} { F1, F2, F3, F4},我们的方法可以轻松应用于大多数下游任务,包括图像分类、目标检测和语义分割。
3.2. Transformer 的特征金字塔
与使用不同卷积步幅获得多尺度特征图的 CNN 骨干网络 [53、21] 不同,我们的 PVT 使用渐进收缩策略通过块嵌入层控制特征图的尺度。
在这里,我们将第 i i i 个阶段的块大小表示为 P i P_i Pi。在第 i i i 阶段开始时,我们首先将输入的特征图 F i − 1 ∈ R H i − 1 × W i − 1 × C i − 1 F_{i-1}\in\mathbb{R}^{H_{i-1}\times W_{i-1}\times C_{i-1}} Fi−1∈RHi−1×Wi−1×Ci−1 平均划分为 H i − 1 × W i − 1 P i 2 \frac{H_{i-1}\times W_{i-1}}{P_i^2} Pi2Hi−1×Wi−1 块,然后将每个块压平并投影到 C i C_i Ci 维嵌入。线性投影后,嵌入块的形状可以看作是 H i − 1 P i × W i − 1 P i × C i \frac{H_{i-1}}{P_i}\times\frac{W_{i-1}}{P_i}\times C_i PiHi−1×PiWi−1×Ci,其中高度和宽度比输入小 P i P_i Pi 倍。
这样,我们就可以在每个阶段灵活调整特征图的尺度,从而为 Transformer 构建特征金字塔成为可能。
3.3. Transformer 编码器
第 i i i 阶段的 Transformer 编码器有 L i L_i Li 个编码器层,每个编码器层都由一个注意力层和一个前馈层组成 [63]。由于 PVT 需要处理高分辨率(例如,4 步长)特征图,我们提出了一个空间缩减注意力(SRA)层来取代编码器中传统的多头注意力(MHA)层 [63]。
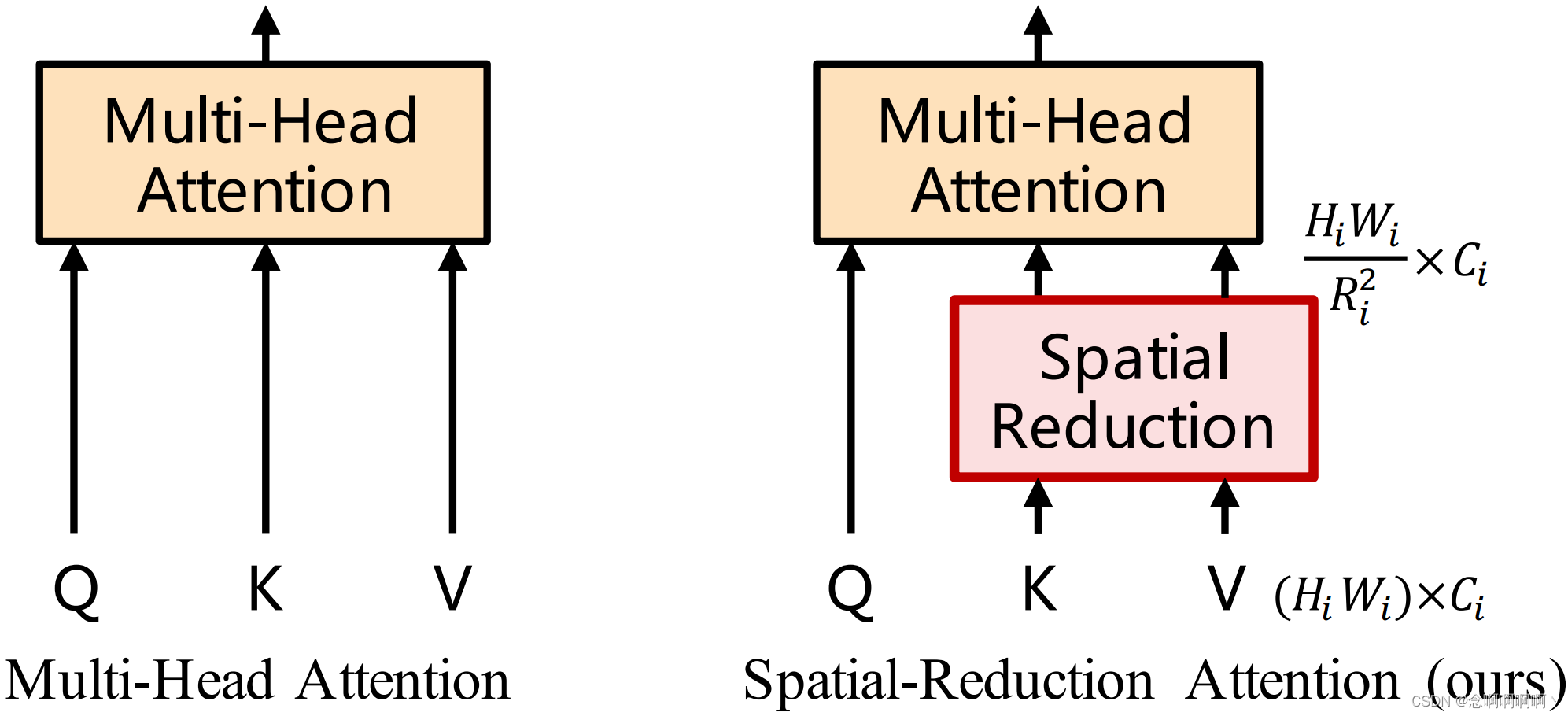
与 MHA 类似,我们的 SRA 接收一个查询 Q Q Q、一个键 K K K 和一个值 V V V 作为输入,并输出一个细化的特征。不同之处在于我们的 SRA 在注意力操作之前减少了 K K K 和 V V V 的空间尺度(见图 4),这在很大程度上减少了计算 / 内存开销。第 i i i 阶段 SRA 的详细信息可以表述如下:
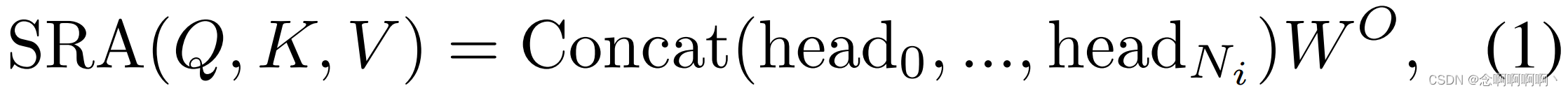
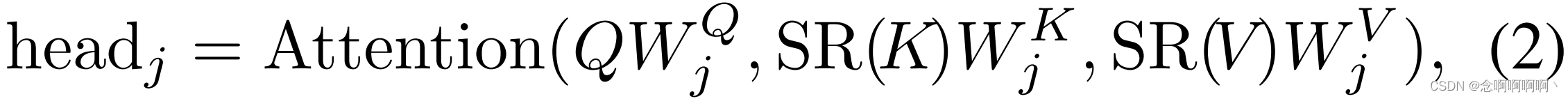
其中 C o n c a t ( ⋅ ) Concat(·) Concat(⋅) 是 [63] 中的串联操作。 W j Q ∈ R C i × d h e a d , W j K ∈ R C i × d h e a d , W j V ∈ R C i × d h e a d , W O ∈ R C i × C i W_j^Q\in\mathbb{R}^{C_i\times d_{head}}, W_j^K\in\mathbb{R}^{C_i\times d_{head}}, W_j^V\in\mathbb{R}^{C_i\times d_{head}}, W^O\in\mathbb{R}^{C_i\times C_i} WjQ∈RCi×dhead,WjK∈RCi×dhead,WjV∈RCi×dhead,WO∈RCi×Ci 为线性投影参数。 N i N_i Ni 是第 i i i 阶段注意力层的头编号。因此,每个头的尺寸(即 d h e a d d_{head} dhead)等于 C i N i \frac{C_i}{N_i} NiCi。 S R ( ⋅ ) SR(·) SR(⋅) 是对输入序列(即 K K K 或 V V V)进行空间维度降维的操作,写为:
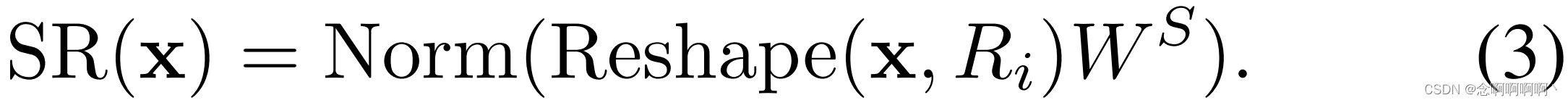
其中, x ∈ R ( H i W i ) × C i \mathbf{x}\in\mathbb{R}^{\left(H_iW_i\right)\times C_i} x∈R(HiWi)×Ci 表示输入序列, R i R_i Ri 表示阶段 i i i 中注意力层的缩减率。 R e s h a p e ( x , R i ) Reshape\left(\mathbf{x},\ R_i\right) Reshape(x, Ri) 是将输入序列 x \mathbf{x} x 整形为大小为 H i W i R i 2 × ( R i 2 C i ) \frac{H_iW_i}{R_i^2}\times\left(R_i^2C_i\right) Ri2HiWi×(Ri2Ci) 的序列的操作。
W s ∈ R ( R i 2 C i ) × C i W_s\in\mathbb{R}^{\left(R_i^2C_i\right)\times C_i} Ws∈R(Ri2Ci)×Ci 是一个线性投影,它将输入序列的维度降低到 C i C_i Ci。 N o r m ( ⋅ ) Norm(·) Norm(⋅) 指层归一化 [1]。与原始 Transformer [63] 一样,我们的注意力操作 A t t e n t i o n ( ⋅ ) Attention(·) Attention(⋅) 计算如下:

通过这些公式,我们可以发现我们的注意力操作的计算 / 内存成本比 MHA 低 R i 2 R_i^2 Ri2 倍,因此我们的 SRA 可以用有限的资源处理更大的输入特征图 / 序列。
3.4. 讨论
与我们的模型最相关的工作是 ViT [12]。在这里,我们讨论它们之间的关系和区别。首先,PVT 和 ViT 都是没有卷积的纯 Transformer 模型。它们之间的主要区别在于金字塔结构。与传统的 Transformer [63] 类似,ViT 的输出序列长度与输入相同,这意味着 ViT 的输出是单尺度的(见图 1(b))。此外,由于资源有限,ViT 的输入是粗粒度的(例如,patch 大小为 16 或 32 像素),因此其输出分辨率相对较低(例如,16-stride 或 32-stride)。因此,很难将 ViT 直接应用于需要高分辨率或多尺度特征图的密集预测任务。
我们的 PVT 打破了 Transformer 的套路,引入了渐进收缩的金字塔。它可以像传统的 CNN 骨干一样生成多尺度特征图。此外,我们还设计了一个简单但有效的注意力层—SRA,以处理高分辨率特征图并降低计算/内存成本。受益于上述设计,我们的方法与 ViT 相比具有以下优势:1)更灵活—可以在不同阶段生成不同尺度/通道的特征图;2)更通用—可以轻松地在大多数下游任务模型中即插即用;3)对计算 / 内存更友好—可以处理更高分辨率的特征图或更长的序列。
4. 应用于下游任务
4.1. 图像级预测
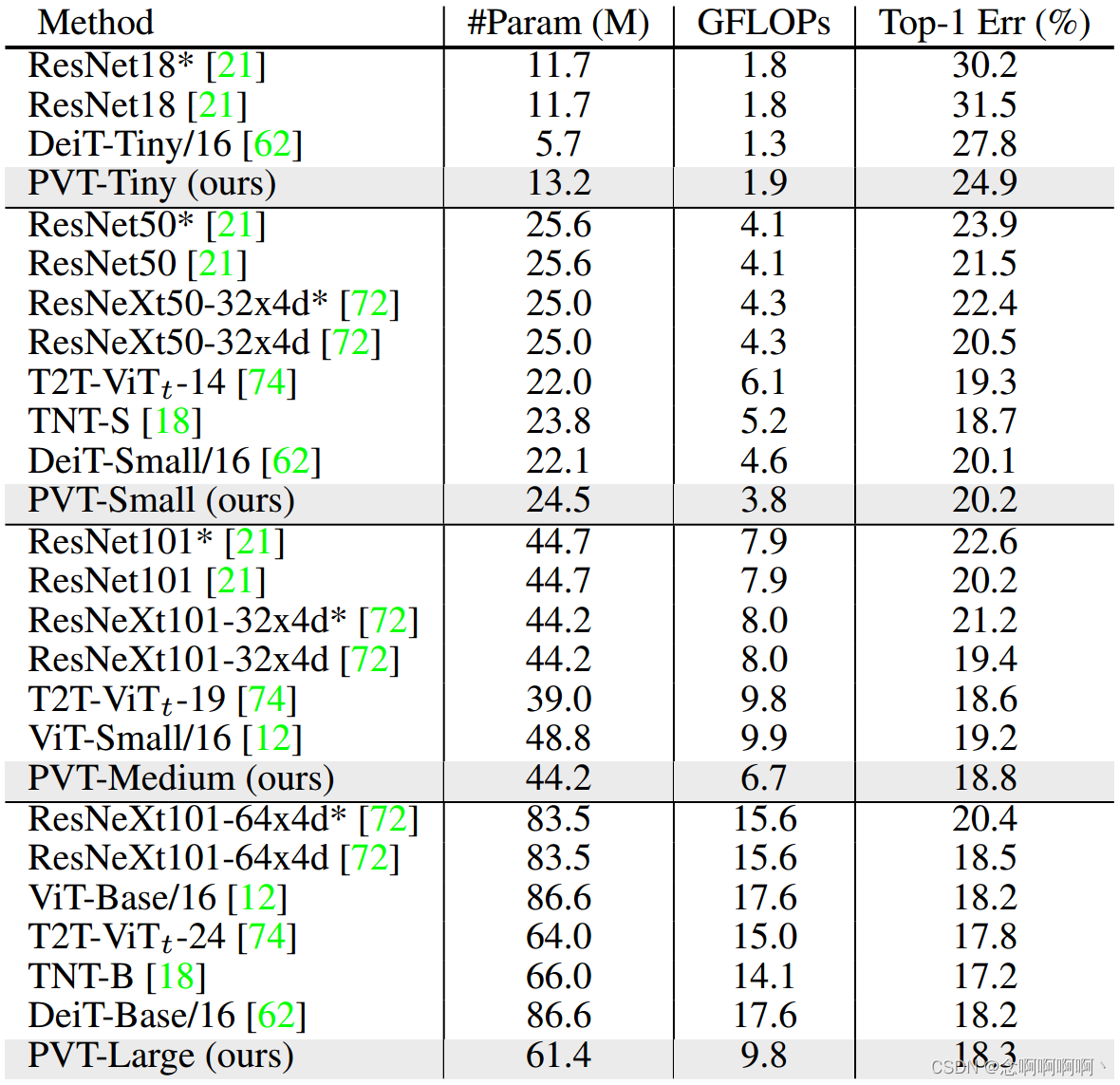
图像分类是图像级预测中最经典的任务。为了提供实例供讨论,我们设计了一系列不同尺度的 PVT 模型,即 PVT-Tiny、-Small、-Medium和 -Large,其参数数量分别与 ResNet18、50、101 和 152 相似。补充材料(SM)中提供了 PVT 系列的详细超参数设置。
对于图像分类,我们遵循 ViT [12] 和 DeiT [62] 将可学习的分类标记附加到最后阶段的输入,然后使用全连接(FC)层在标记之上进行分类。
4.2. 像素级密集预测
除了图像级别的预测,需要在特征图上执行像素级分类或回归的密集预测也经常出现在下游任务中。在这里,我们讨论两个典型的任务,即对象检测和语义分割。
我们将我们的 PVT 模型应用于三种具有代表性的密集预测方法,即 RetinaNet [38]、Mask RCNN [20] 和 Semantic FPN [31]。RetinaNet 是一种广泛使用的单级检测器,Mask R-CNN 是最流行的两级实例分割框架,而 Semantic FPN 是一种没有特殊操作(例如扩张卷积)的普通语义分割方法。使用这些方法作为基线使我们能够充分检查不同骨干的有效性。
实现细节如下:(1)和 ResNet 一样,我们使用在 ImageNet 上预训练的权重初始化 PVT 骨干;(2)我们将输出特征金字塔 { F 1 , F 2 , F 3 , F 4 } \left\{F_1,\ F_2,\ F_3,\ F_4\right\} { F1, F2, F3, F4} 作为 FPN [37] 的输入,然后将细化后的特征图馈送到后续的检测 / 分割头;(3)在训练检测/分割模型时,PVT 中的所有层都没有被冻结;(4)由于用于检测 / 分割的输入可以是任意形状,因此在 ImageNet 上预训练的位置嵌入可能不再有意义。因此,我们根据输入分辨率对预训练的位置嵌入进行双线性插值。
5. 实验
我们将 PVT 与两个最具代表性的 CNN 骨干进行比较,即 ResNet [21] 和 ResNeXt [72],它们广泛用于许多下游任务的基准测试。
5.1. 图像分类
Settings。图像分类实验是在 ImageNet 2012 数据集 [50] 上进行的,该数据集包括来自 1,000 个类别的 128 万张训练图像和 5 万张验证图像。为了公平比较,所有模型都在训练集上进行训练,并报告验证集上的 top-1 错误。我们遵循 DeiT [62] 并应用随机裁剪、随机水平翻转 [58]、标签平滑正则化 [59]、混合 [76]、CutMix [75] 和随机擦除 [80] 作为数据增强。在训练期间,我们使用动量为 0.9、小批量大小为 128 和权重衰减为 5×10−2 的 AdamW [45] 来优化模型。初始学习率设置为 1×10−3 并按照余弦时间表 [44] 减小。所有模型都在 8 个 V100 GPU 上从头开始训练 300 个时期。为了进行基准测试,我们在验证集上应用中心裁剪,裁剪 224×224 的块以评估分类准确性。
Results。在表 1 中,我们看到我们的 PVT 模型在相似的参数数量和计算预算下优于传统的 CNN 骨干。例如,当 GFLOPs 大致相似时,PVTSmall 的 top-1 错误达到 20.2,比 ResNet50 [21] 高 1.3 个百分点(20.2 对 21.5)。同时,在相似或较低的复杂性下,PVT 模型的性能与最近提出的基于 Transformer 的模型相当,,例如 ViT [12] 和 DeiT [62](PVT-Large:18.3 vs. ViT(DeiT)-Base / 16: 18.3)。在这里,我们澄清这些结果在我们的预期之内,因为金字塔结构有利于密集预测任务,但对图像分类带来的改进很小。
请注意,ViT 和 DeiT 有局限性,因为它们是专门为分类任务设计的,因此不适合密集预测任务,而密集预测任务通常需要有效的特征金字塔。
5.2. 物体检测
Settings。目标检测实验是在具有挑战性的 COCO 基准 [39] 上进行的。所有模型都在 COCO train2017(118k 图像)上进行训练,并在 val2017(5k 图像)上进行评估。我们验证了 PVT 骨干在两个标准检测器之上的有效性,即 RetinaNet [38] 和 Mask R-CNN [20]。在训练之前,我们使用在 ImageNet 上预训练的权重来初始化骨干,并使用 Xavier [17] 来初始化新添加的层。我们的模型在 8 个 V100 GPU 上以 16 的批量大小进行训练,并由 AdamW [45] 以 1×10−4 的初始学习率进行优化。按照常见做法 [38、20、6],我们采用 1× 或 3× 训练计划(即 12 或 36 个时期)来训练所有检测模型。调整训练图像的大小,使其短边为 800 像素,而长边不超过 1,333 像素。当使用 3× 训练计划时,我们在 [640, 800] 的范围内随机调整输入图像的短边。在测试阶段,输入图像的短边固定为 800 像素。
Results。如表 2 所示,当使用 RetinaNet 进行对象检测时,我们发现在相当数量的参数下,基于 PVT 的模型明显优于其对应模型。例如,在 1× 训练计划下,PVT-Tiny 的 AP 比 ResNet18 高 4.9 分(36.7 对 31.8)。此外,通过 3× 训练计划和多尺度训练,PVT-Large 存档了 43.4 的最佳 AP,超过了 ResNeXt101-64x4d(43.4 对 41.8),而我们的参数数量减少了 30%。这些结果表明,我们的 PVT 可以很好地替代 CNN 骨干进行对象检测。

在基于 Mask R-CNN 的实例分割实验中也发现了类似的结果,如表 3 所示。使用 1× 训练计划,PVT-Tiny 实现了 35.1 mask AP(APm),比 ResNet18 好 3.9 个点(35.1 vs. 31.2),甚至比 ResNet50 高出 0.7 个百分点(35.1 对 34.4)。PVT-Large 获得的最佳 APm 为 40.7,比 ResNeXt101-64x4d(40.7 vs. 39.7)高 1.0 个点,参数减少 20%。

5.3. 语义分割
Settings。我们选择 ADE20K [81],一个具有挑战性的场景解析数据集,来对语义分割的性能进行基准测试。ADE20K 包含 150 个细粒度语义类别,分别有 20,210、2,000 和 3,352 个图像用于训练、验证和测试。我们在语义 FPN [31] 的基础上评估我们的 PVT 骨干,这是一种没有扩张卷积的简单分割方法 [73]。在训练阶段,backbone 使用在 ImageNet [11] 上预训练的权重进行初始化,其他新添加的层使用 Xavier [17] 进行初始化。我们使用 AdamW [45] 优化我们的模型,初始学习率为 1e-4。按照常见做法 [31、7],我们在 4 个 V100 GPU 上训练模型进行 80k 次迭代,批量大小为 16。学习率按照幂为 0.9 的多项式衰减时间表衰减。我们随机将图像调整大小并裁剪为 512 × 512 以进行训练,并在测试期间重新调整为具有 512 像素的短边。
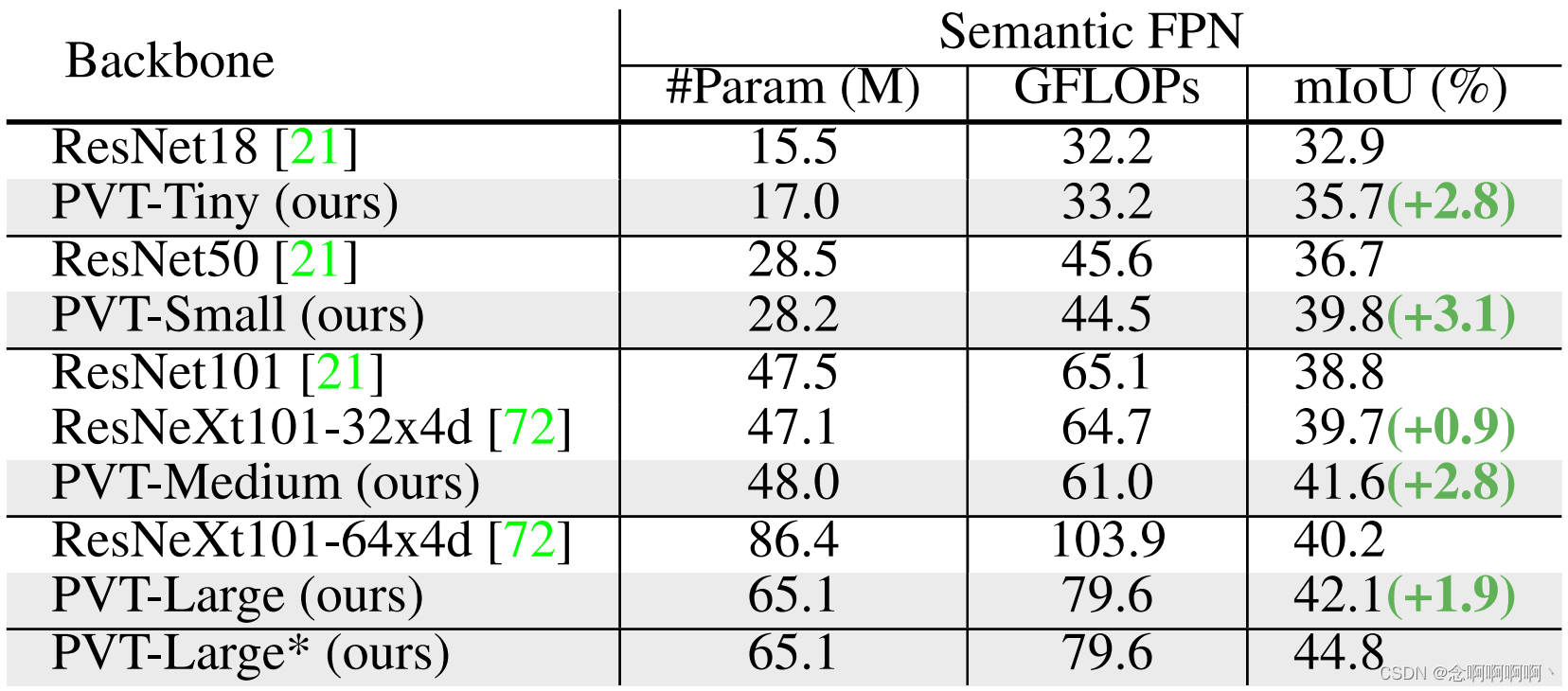
Results。如表 4 所示,当使用语义 FPN [31] 进行语义分割时,基于 PVT 的模型始终优于基于 ResNet [21] 或 ResNeXt [72] 的模型。例如,在参数和 GFLOP 数量几乎相同的情况下,我们的 PVT-Tiny/Small/Medium 比 ResNet-18/50/101 至少高出 2.8 个百分点。此外,虽然我们的 PVT-Large 的参数数量和 GFLOPs 比 ResNeXt101-64x4d 低 20%,但 mIoU 仍然高出 1.9 个点(42.1 对 40.2)。通过更长的训练时间和多尺度测试,PVT-Large+Semantic FPN 获得了 44.8 的最佳 mIoU,这非常接近 ADE20K 基准测试的最新性能。请注意,Semantic FPN 只是一个简单的分割头。这些结果表明,我们的 PVT 骨干可以提取比 CNN 骨干更好的语义分割特征,这得益于全局注意力机制。
5.4. 纯 Transformer 对象检测
为了达到无卷积的极限,我们通过简单地将我们的 PVT 与基于 Transformer 的检测头 DETR [5] 相结合,构建了一个用于对象检测的纯 Transformer 管道。我们在 COCO train2017 上训练模型 50 个时期,初始学习率为 1×10−4。在第 33 轮学习率除以 10。我们使用随机翻转和多尺度训练作为数据增强。所有其他实验设置与第二节中的相同。5.2. 如表 5 所示,基于 PVT 的 DETR 在 COCO val2017 上获得 34.7 AP,比最初基于 ResNet50 的 DETR 高出 2.4 分(34.7 对 32.3)。这些结果证明,纯 Transformer 检测器也可以很好地完成目标检测任务。在 SM 中,我们还尝试了纯 Transformer 模型 PVT+Trans2Seg [71] 进行语义分割。

5.5. 消融研究
Settings。我们对 ImageNet [11] 和 COCO [39] 数据集进行消融研究。ImageNet 上的实验设置与 5.1 节中的设置相同。 对于 COCO,所有模型都使用 1× 训练计划(即 12 个 epoch)进行训练,并且没有进行多尺度训练,其他设置遵循第 5.2 节中的设置。
Pyramid Structure。将 Transformer 应用于密集预测任务时,金字塔结构至关重要。ViT(见图 1(b))是一个柱状框架,其输出是单尺度的。当使用粗图像块(例如,每个块 32×32 像素)作为输入时,这会导致低分辨率输出特征图,从而导致检测性能不佳(COCO val2017 上的 31.7 AP),如表 6 所示。当使用 细粒度图像块(例如,每个块 4×4 像素)作为我们的 PVT 的输入,ViT 将耗尽 GPU 内存(32G)。我们的方法通过渐进收缩金字塔避免了这个问题。具体来说,我们的模型可以在浅层处理高分辨率特征图,在深层处理低分辨率特征图。因此,它在 COCO val2017 上获得了 40.4 的有希望的 AP,比 ViT-Small/32 高 8.7 分(40.4 对 31.7)。

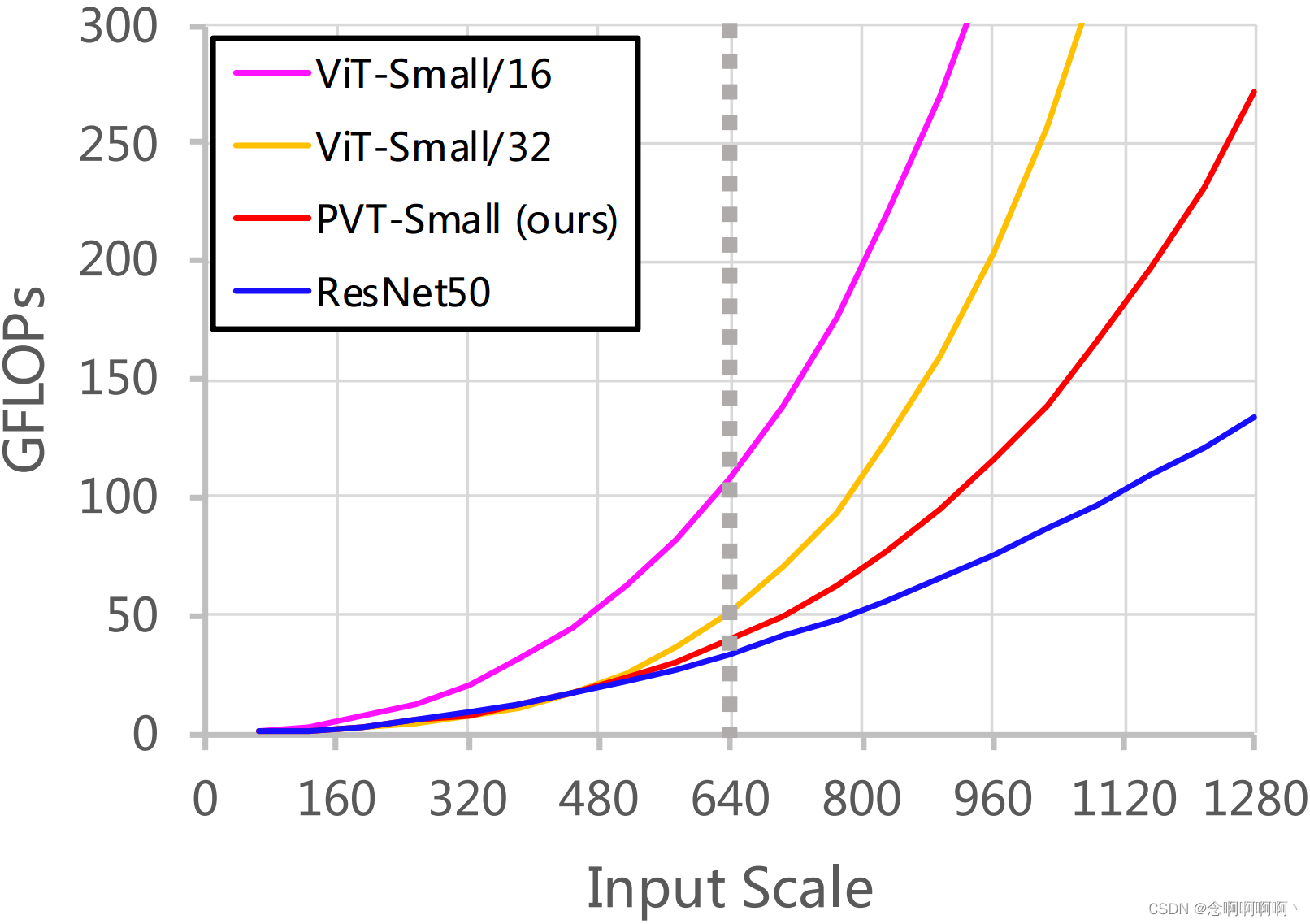
Computation Overhead。随着输入规模的增加,我们的 PVT 的 GFLOPs 的增长率大于 ResNet [21],但低于 ViT [12],如图 5 所示。但是,当输入规模不超过 640×640 像素时, PVT-Small 和 ResNet50 的 GFLOPs 相似。这意味着我们的 PVT 更适合中分辨率输入的任务。
6. 结论和未来工作
我们引入了 PVT,这是一种用于密集预测任务(例如对象检测和语义分割)的纯 Transformer 骨干。我们开发了一个渐进收缩金字塔和一个空间缩减注意层,以在有限的计算/内存资源下获得高分辨率和多尺度特征图。大量关于对象检测和语义分割基准的实验证实,我们的 PVT 在相当数量的参数下比精心设计的 CNN 骨干更强。
尽管 PVT 可以作为 CNN 骨干网(例如 ResNet、ResNeXt)的替代方案,但仍有一些专为 CNN 设计的特定模块和操作未在本工作中考虑,例如 SE [22]、SK [35]、扩张卷积 [73]、模型修剪 [19] 和 NAS [60]。此外,随着多年的快速发展,已经出现了许多精心设计的 CNN 骨干,例如 Res2Net [16]、EfficientNet [60] 和 ResNeSt [77]。相比之下,计算机视觉中基于 Transformer 的模型仍处于早期发展阶段。因此,我们相信未来有许多潜在的技术和应用(例如 OCR [67、65、68]、3D [27、10、26] 和医学 [14、15、28] 图像分析)有待探索, 并希望 PVT 可以作为一个好的起点。
参考文献
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016. 5
[2] Irwan Bello. Lambdanetworks: Modeling long-range interactions without attention. In Proc. Int. Conf. Learn. Representations, 2021. 3
[3] Irwan Bello, Barret Zoph, Ashish Vaswani, Jonathon Shlens, and Quoc V Le. Attention augmented convolutional networks. In Proc. IEEE Int. Conf. Comp. Vis., 2019. 3
[4] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018. 3
[5] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In Proc. Eur. Conf. Comp. Vis., 2020. 1, 2, 3, 7
[6] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019. 6
[7] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell., 2017. 3, 7
[8] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proc. Eur. Conf. Comp. Vis., 2018. 1
[9] Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, and Jiashi Feng. Dual path networks. Proc. Advances in Neural Inf. Process. Syst., 2017. 3
[10] Mingmei Cheng, Le Hui, Jin Xie, and Jian Yang. SSPCNet: Semi-supervised semantic 3D point cloud segmentation network. In Proc. AAAI Conf. Artificial Intell., 2021. 8
[11] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2009. 1, 7, 8
[12] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al An image is worth 16x16 words: Transformers for image recognition at scale. Proc. Int. Conf. Learn. Representations, 2021. 1, 2, 3, 5, 6, 8
[13] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. Int. J. Comput. Vision, 88(2):303– 338, 2010. 1
[14] Deng-Ping Fan, Ge-Peng Ji, Ming-Ming Cheng, and Ling Shao. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell., 2021. 8
[15] Deng-Ping Fan, Ge-Peng Ji, Tao Zhou, Geng Chen, Huazhu Fu, Jianbing Shen, and Ling Shao. Pranet: Parallel reverse attention network for polyp segmentation. In International Conference on Medical Image Computing and ComputerAssisted Intervention, 2020. 8
[16] Shanghua Gao, Ming-Ming Cheng, Kai Zhao, Xin-Yu Zhang, Ming-Hsuan Yang, and Philip HS Torr. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell., 2019. 8
[17] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proc. Int. Conf. Artificial Intell. & Stat., 2010. 6, 7
[18] Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. Transformer in transformer. arXiv preprint arXiv:2103.00112, 2021. 6
[19] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015. 8
[20] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´ shick. Mask r-cnn. In Proc. IEEE Int. Conf. Comp. Vis., 2017. 1, 2, 3, 5, 6, 7
[21] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016. 1, 2, 3, 4, 5, 6, 7, 8
[22] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018. 8
[23] Ronghang Hu and Amanpreet Singh. Transformer is all you need: Multimodal multitask learning with a unified transformer. arXiv preprint arXiv:2102.10772, 2211. 2
[24] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017. 3
[25] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In Proc. IEEE Int. Conf. Comp. Vis., 2019. 3
[26] Le Hui, Mingmei Cheng, Jin Xie, and Jian Yang. Efficient 3D point cloud feature learning for large-scale place recognition. arXiv preprint arXiv:2101.02374, 2021. 8
[27] Le Hui, Rui Xu, Jin Xie, Jianjun Qian, and Jian Yang. Progressive point cloud deconvolution generation network. In Proc. Eur. Conf. Comp. Vis., 2020. 8
[28] Ge-Peng Ji, Yu-Cheng Chou, Deng-Ping Fan, Geng Chen, Huazhu Fu, Debesh Jha, and Ling Shao. Progressively normalized self-attention network for video polyp segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 2021. 8
[29] Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc V Gool. Dynamic filter networks. In Proc. Advances in Neural Inf. Process. Syst., 2016. 3
[30] Asifullah Khan, Anabia Sohail, Umme Zahoora, and Aqsa Saeed Qureshi. A survey of the recent architectures of deep convolutional neural networks. Artificial Intelligence Review, 53(8):5455–5516, 2020. 3
[31] Alexander Kirillov, Ross Girshick, Kaiming He, and Piotr Dollar. Panoptic feature pyramid networks. In ´ Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019. 1, 3, 5, 6, 7
[32] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Proc. Advances in Neural Inf. Process. Syst., 2012. 3
[33] Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick ´ Haffner. Gradient-based learning applied to document recognition. 1998. 3
[34] Xiang Li, Wenhai Wang, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2021. 3
[35] Xiang Li, Wenhai Wang, Xiaolin Hu, and Jian Yang. Selective kernel networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019. 3, 8
[36] Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. In Proc. Advances in Neural Inf. Process. Syst., 2020. 3
[37] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, ´ Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017. 3, 5
[38] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´ Proc. IEEE Int. Conf. Comp. Vis., 2017. 1, 2, 3, 5, 6, 7
[39] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In Proc. Eur. Conf. Comp. Vis., 2014. 1, 2, 6, 8
[40] Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan L Yuille, and Li Fei-Fei. Autodeeplab: Hierarchical neural architecture search for semantic image segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019. 3
[41] Nian Liu, Ni Zhang, Kaiyuan Wan, Ling Shao, and Junwei Han. Visual saliency transformer. In Proc. IEEE Int. Conf. Comp. Vis., 2021. 2
[42] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In Proc. Eur. Conf. Comp. Vis., 2016. 3
[43] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2015. 3
[44] Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with warm restarts. In Proc. Int. Conf. Learn. Representations, 2017. 6
[45] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In Proc. Int. Conf. Learn. Representations, 2019. 6, 7
[46] Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han. Learning deconvolution network for semantic segmentation. In Proc. IEEE Int. Conf. Comp. Vis., 2015. 3
[47] Niki Parmar, Prajit Ramachandran, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens. Stand-alone self-attention in vision models. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alche-´ Buc, Emily B. Fox, and Roman Garnett, editors, Proc. Advances in Neural Inf. Process. Syst., 2019. 2, 3
[48] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proc. Advances in Neural Inf. Process. Syst., 2015. 1, 3
[49] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, 2015. 3
[50] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al Imagenet large scale visual recognition challenge. Int. J. Comput. Vision, 2015. 3, 6
[51] Suyash Shetty. Application of convolutional neural network for image classification on pascal voc challenge 2012 dataset. arXiv preprint arXiv:1607.03785, 2016. 3
[52] Connor Shorten and Taghi M Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of Big Data, 6(1):1–48, 2019. 3
[53] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Yoshua Bengio and Yann LeCun, editors, Proc. Int. Conf. Learn. Representations, 2015. 1, 3, 4
[54] Peize Sun, Yi Jiang, Enze Xie, Zehuan Yuan, Changhu Wang, and Ping Luo. Onenet: Towards end-to-end one-stage object detection. arXiv preprint arXiv:2012.05780, 2020. 3
[55] Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple-object tracking with transformer. arXiv preprint arXiv:2012.15460, 2020. 2
[56] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al Sparse r-cnn: End-to-end object detection with learnable proposals. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2021. 3
[57] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proc. AAAI Conf. Artificial Intell., 2017. 3
[58] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2015. 3, 6
[59] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016. 3, 6
[60] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proc. Int. Conf. Mach. Learn., 2019. 8
[61] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proc. IEEE Int. Conf. Comp. Vis., 2019. 3
[62] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou. Training ´ data-efficient image transformers & distillation through attention. In Proc. Int. Conf. Mach. Learn., 2021. 3, 5, 6
[63] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proc. Advances in Neural Inf. Process. Syst., 2017. 2, 3, 4, 5
[64] Wenhai Wang, Xiang Li, Jian Yang, and Tong Lu. Mixed link networks. Proc. Int. Joint Conf. Artificial Intell., 2018. 3
[65] Wenhai Wang, Xuebo Liu, Xiaozhong Ji, Enze Xie, Ding Liang, ZhiBo Yang, Tong Lu, Chunhua Shen, and Ping Luo. Ae textspotter: Learning visual and linguistic representation for ambiguous text spotting. In Proc. Eur. Conf. Comp. Vis., 2020. 8
[66] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pvtv2: Improved baselines with pyramid vision transformer. arXiv preprint arXiv:2106.13797, 2021. 8
[67] Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, and Shuai Shao. Shape robust text detection with progressive scale expansion network. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019. 8
[68] Wenhai Wang, Enze Xie, Xiang Li, Xuebo Liu, Ding Liang, Yang Zhibo, Tong Lu, and Chunhua Shen. Pan++: Towards efficient and accurate end-to-end spotting of arbitrarilyshaped text. IEEE Trans. Pattern Anal. Mach. Intell., 2021. 8
[69] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018. 2, 3
[70] Enze Xie, Peize Sun, Xiaoge Song, Wenhai Wang, Xuebo Liu, Ding Liang, Chunhua Shen, and Ping Luo. Polarmask: Single shot instance segmentation with polar representation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020. 3
[71] Enze Xie, Wenjia Wang, Wenhai Wang, Peize Sun, Hang Xu, Ding Liang, and Ping Luo. Segmenting transparent object in the wild with transformer. In Proc. Int. Joint Conf. Artificial Intell., 2021. 2, 8
[72] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and ´ Kaiming He. Aggregated residual transformations for deep neural networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017. 1, 2, 3, 5, 6, 7
[73] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. In Yoshua Bengio and Yann LeCun, editors, Proc. Int. Conf. Learn. Representations, 2016. 7, 8
[74] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet. arXiv preprint arXiv:2101.11986, 2021. 6
[75] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 6023–6032, 2019. 6
[76] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and ´ David Lopez-Paz. mixup: Beyond empirical risk minimization. In Proc. Int. Conf. Learn. Representations, 2018. 6
[77] Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Zhi Zhang, Haibin Lin, Yue Sun, Tong He, Jonas Mueller, R Manmatha, et al Resnest: Split-attention networks. arXiv preprint arXiv:2004.08955, 2020. 8
[78] Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. Exploring self-attention for image recognition. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020. 2
[79] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017. 3
[80] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In Proc. AAAI Conf. Artificial Intell., 2020. 6
[81] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017. 1, 6
[82] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: deformable transformers for end-to-end object detection. In Proc. Int. Conf. Learn. Representations, 2021. 2, 3