论文地址:https://arxiv.org/pdf/2112.11010.pdf
官方代码:https://github.com/youngwanLEE/MPViT
Multi-Path Vision Transformer for Dense Prediction
1. 论文阅读
Abstract
在这项工作中,探索多尺度patches嵌入和多路径结构,构建多路径视觉Tansformer( MPViT )。
MPViT使用重叠卷积块嵌入,将相同大小的(即序列长度)特征与不同尺度的patches同时嵌入。然后,不同尺度的token通过多条路径独立地馈入Transformer编码器,并将得到的特征进行聚合,从而在同一特征级别上实现精细和粗略的特征表示。得益于多样的、多尺度的特征表示,MPViTs从Tiny( 5M )到Base( 73M )的缩放在ImageNet分类、目标检测、实例分割和语义分割上取得了优于最先进的Vision Transformers的性能。这些广泛的结果表明MPViT可以作为一个通用的骨干网络用于各种视觉任务。
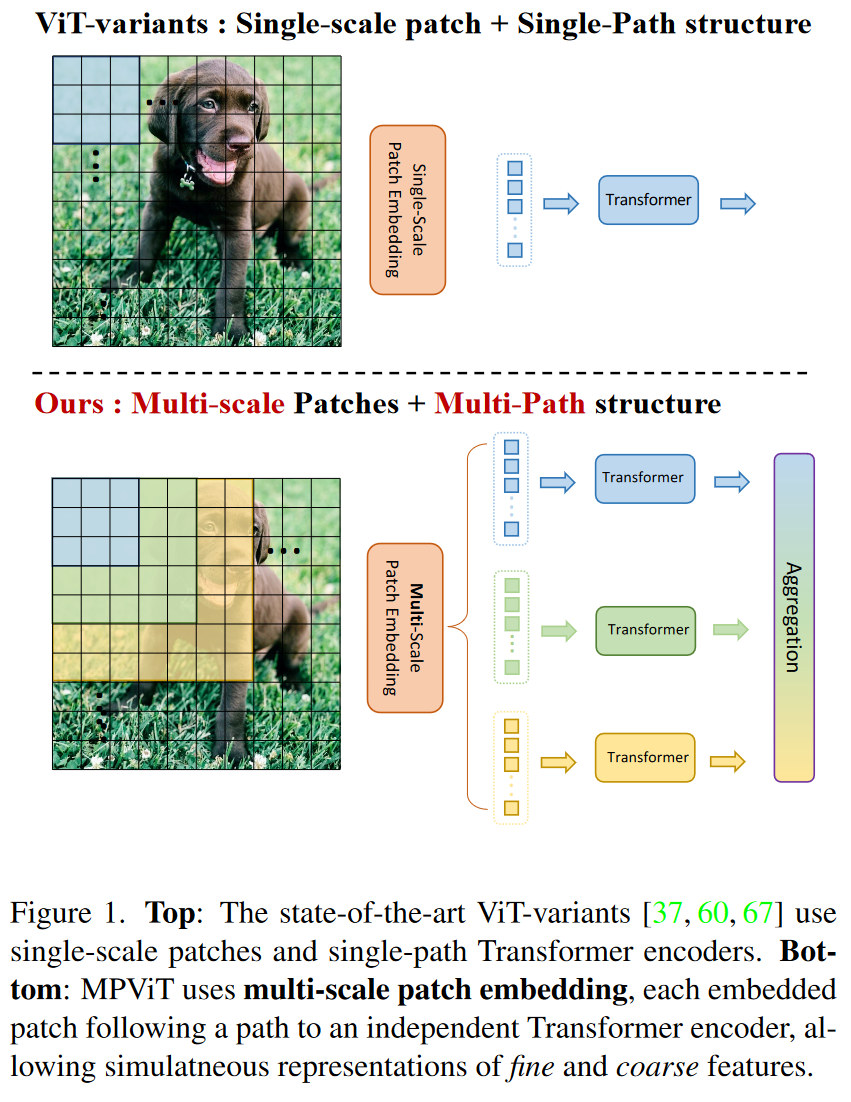
1. Introduction
随着Transformer的出现,不仅在NLP领域大放异彩,在计算机视觉领域也起到了强有力的推动作用。
对于目标检测和分割等密集预测任务,在多个尺度上表示特征以区分不同大小的目标或区域是至关重要的。现在的CNN backbone利用多尺度卷积核进行稠密预测取得了更好的表现。
其中Inception Network和VoVNet利用同一特征层的多粒度卷积核产生多样化的感受野以提高检测性能。
HRNet通过在整个卷积层同时聚合细特征和粗特征来表示多尺度特征。
ViT的一些变体在应用于高分辨率的稠密预测时,主要关注如何解决自注意力的二次复杂度(quadratic complexity)问题,较少关注构建有效的多尺度表示。
Vision Tranformer Backbone使用单尺度patch构造了一个简单的多阶段结构,从细到粗的结构。
CoaT通过使用允许跨层注意力并行的共尺度机制同时表示细特征和粗特征,提高了检测性能。但是需要更多的计算力和存储空间,因为引入了跨层注意力。
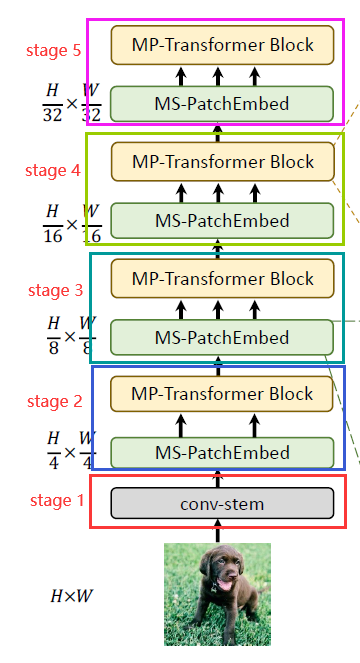
受CNN模型利用多粒度卷积核获取多个感受野的启发,本论文提出了一种用于Transformer的多尺度patch嵌入和多路径结构。多尺度patch嵌入通过重叠卷积操作将不同大小的visual patches同时进行表征,适当调整卷积的padding/stride后得到具有相同序列长度(即特征分辨率)的特征。然后,来自不同尺度的token独立并行地馈入Transformer编码器。每个具有不同大小的token的Transformer编码器执行全局注意力,然后将得到的特征进行聚合,使细特征和粗特征在同一特征水平上表示。在特征聚合步骤,引入全局-局部的特征交互过程,利用卷积的局部连通性(Local Connectivity)和Transformer的全局上下文语境将卷积局部特征与Transformer的全局特征连接起来。如上图Figure 1.
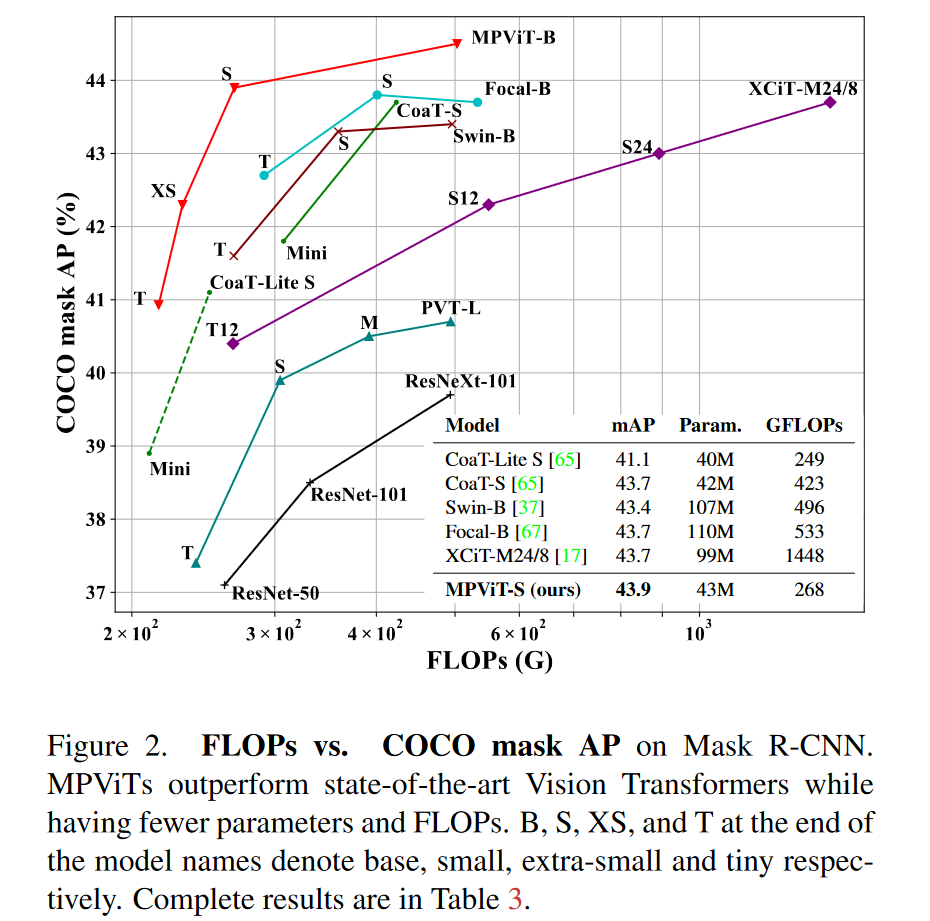
图二展示了各个模型的FLOPs和COCO mask AP的对比以及模型参数的对比。
总结,本文的贡献如下:
- 我们提出了一个具有多路径结构的多尺度嵌入,用于同时表征密集预测任务的精细和粗糙特征。
- 我们引入全局-局部特征交互来利用卷积的局部连通性和Transformer的全局上下文语境。
- 我们提供消融研究和定性分析,分析不同路经维度和patch规模的影响,发掘高效和有效的配置
- 我们验证了MPVit作为密集预测任务backbone的有效性,在ImageNet分类,COCO检测和ADE20K分割数据集上取得了最先进的性能。
2. Related work
Swin transformer、Vitae、Multi-scale vision longformer通过在局部区域使用细粒度限制了注意力范围并和滑动窗口或稀疏全局注意力机制结合。
Pyramid vision transformer通过空间缩图(spatial reduction)减少序列长度来利用粗粒度全局自注意力。
XCiT有一个和ViT一样的单阶段结构,当应用到稠密预测任务时,在ImageNet上进行预训练后,XCiT添加下/上采样层去提取多尺度特征。
Xu等人引入了有简单金字塔架构的CoaT-Lite和在CoaT-Lite顶部有跨层注意力的CoaT。跨层注意力允许CoaT表现得比CoaT-Lite好,但是需要更高的内存和计算资源,这也限制了模型的缩放。
CrossViT也是用来不同的patch大小(大和小)和双重路径在一个像ViT和XCiT的单阶段架构里。然而,CrossViT在分支之间的交互只通过[CLS]发生,而MPViT允许所有不同尺度的patch进行交互。(这一部分,论文中介绍了更多相关工作,涉及到更多的论文)
3. Multi-Path Vision Transformer
总结:
- Conv-stem
输入图像大小为:C2(高,宽,channel),经过两层卷积:采用两个3x3卷积,通道分别为C2和2,步长为2,生成特征的大小为H/4xW/4xC2,C2是stage 2的channel大小。每个卷积之后都经过Batch Normalization和Hardswish激活函数。 - Multi-Scale Patch Embedding
从stage 2到stage 5,对Multi-Scale Patch Embedding和Multi-Path Transformer块进行堆叠。通过改变stride和padding来调整token的序列长度,可以输出具有不同patch大小的相同大小的特征。作者并行地形成了几个具有不同卷积核大小的卷积patch embedding层。如图一所示可以生成相同序列长度的大小不同的vision token,patch大小分别为3x3,5x5,7x7。由于具有相同通道和滤波器大小的连续卷积操作扩大了感受野,并且需要更少的参数,如:2x3^2 < 5^2,为了减少参数量,在实践中选择两个连续的3x3卷积层代替5x5卷积层。对于triple-path结构,使用三个连续的3x3卷积,通道大小均为C’,padding为1,stride为s,其中s在降低空间分辨率的时候是2,其他时候均为1。因此,给定conv-stem的输出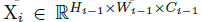 通过MS-PatchEmbed可以得到相同大小为
通过MS-PatchEmbed可以得到相同大小为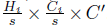 的特征
的特征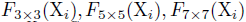
- 说明:为了减少模型参数和计算开销,采用3x3深度可分离卷积,包括3x3深度卷积和1x1点卷积(即使用了depthwise separable convolutions)
- 每个卷积之后都跟着Batch Normalization和Hardswish激活函数
接着不同大小的token embedding features分别输入到Tansformer encoder中。
-
Multi-path Transformer
Transformer中的self-attention可以捕获长期依赖关系,即捕获全局上下文信息,但它很可能会忽略每个patch中的结构性信息和局部关系,相反,CNN可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状,也就是一个整体,一个局部,整体兼顾不了局部的细节,而局部不能拥有整体的形状。
为了表示局部特征Li,采用了一个depthwise residual bottleneck block,包括1x1卷积,3x3深度卷积和1x1卷积和残差连接。为了减轻多路径结构的计算负担,使用了CoaT中提出的有效的因素分解自注意力。

-
Global-to-Local Feature Interaction
将局部特征和全局特征聚合到一起。
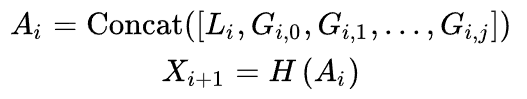
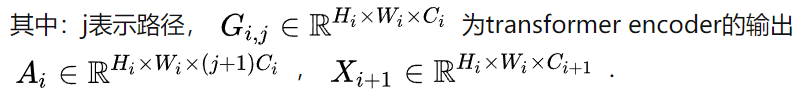
为了保持可比性的参数和FLOPs,增加路径的数量需要减少通道C或层数L(Transformer Encoder的数量),在消融实验中验证了减少C比减少L能取得更好的性能,由于stage 2的特征分辨率较高,导致计算成本较高,作者在stage 2中将triple-path模型的路径数设置为2。从stage 3开始,triple-path有三条路径。
作者还发现,虽然 triple-path和双路径在ImageNet分类中产生相似的精度,但 triple-path模型在密集预测任务中表现出更好的性能。因此,建立了基于 triple-path结构的MPViT模型。MPViT的详细情况见表1。
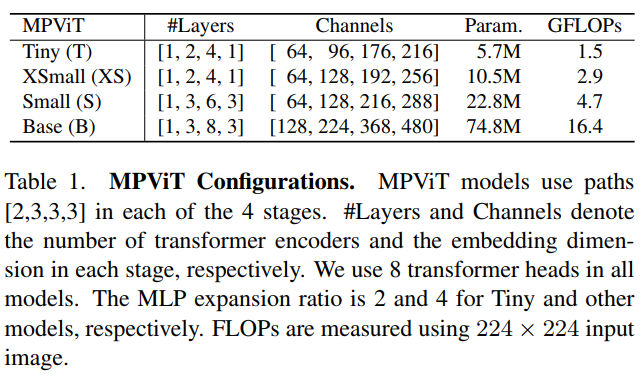
(讲真,这个表和模型图没对起来,有点不懂,希望可以得到解答)
3.1 Architecture
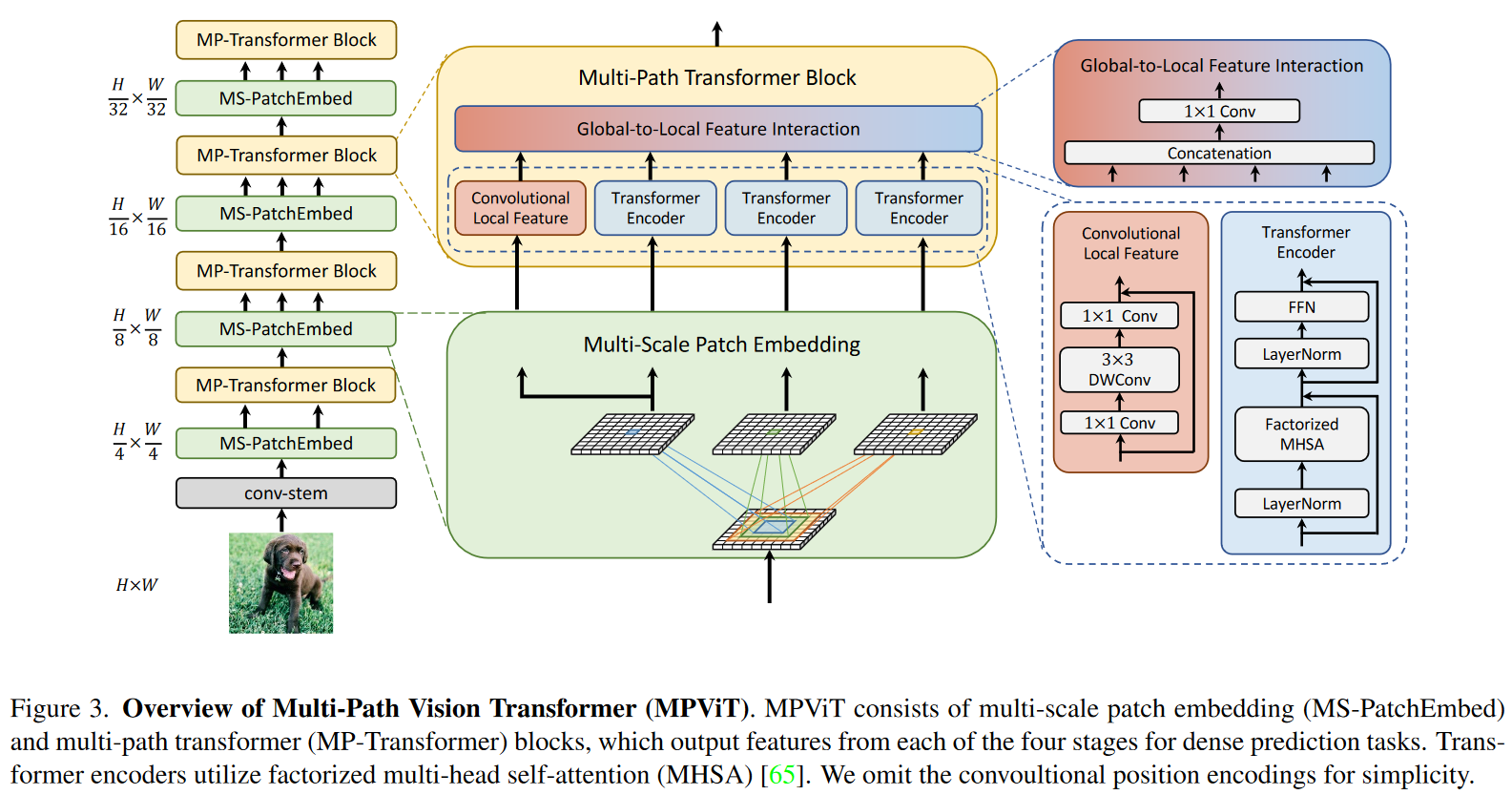
上图展示了MPViT结构,是一个four-stage(四阶段)的特征层次用于生成不同尺度的特征图。(图中省略了卷积位置编码)
作为一个有着高分辨率的特征的多阶段架构需要更多的计算资源,因此,考虑到整个模型的线性复杂度,我们采用CoaT中的带有分解自注意力的Transformer编码器。

3.2 Multi-Scale Patch Embedding
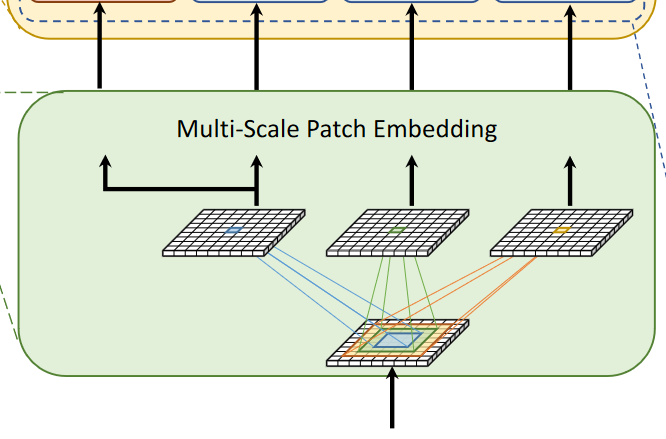


(这部分描述的是通过重叠卷积,对于不同大小的patch,通过padding和stride的设置,使得不同大小的patch卷积得到的特征序列大小一样,然后由特征和patch嵌入得到的token喂入Transformer Encoder吗?)
3.3 Global-to-Loacl Feature Interaction
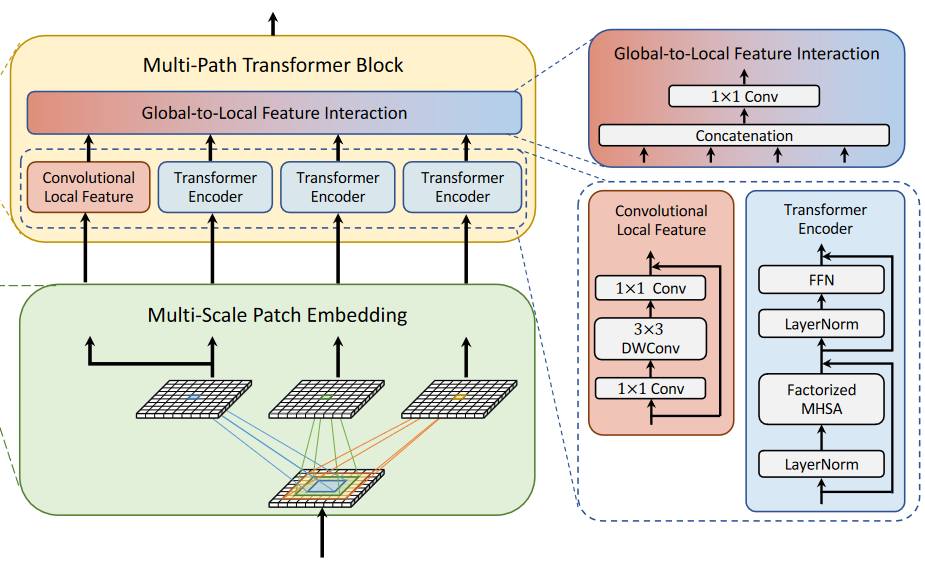
尽管Transformer中的自注意力可以捕获长程依赖关系(即全局上下文),但是很可能会忽略每个patch内的结构信息和局部关系,此外Transformer受益于形状偏差(shape bias),使其能够关注图像的重要部分。相反,卷积神经网络可以利用平移不变性中的局部连通性对图像中的每个patch进行相同的权重处理。这种归纳偏差促使CNN在对视觉对象进行分类时对纹理而非形状具有更强的依赖性。因此,MPViT将卷积神经网络的局部连通性与全局上下文transformers以互补的方式结合起来。为此,引入了一个全局-局部特征交互模块,该模块学习在局部和全局特征之间进行交互以丰富表示。
看结构图可以知道,Global-to-Local Feature Interaction以下面的Convolutional Local Feature的输出和Transformer Encoder的输出作为输入,结合了由卷积得到的局部连通性和由transformer encoder得到的全局上下文信息。
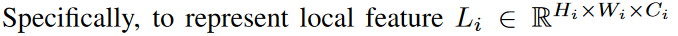

3.4 Model Configuration
为了缓解多路径结构带来的计算负担,我们使用CoaT中提出的高效的因子化自注意力。


Table 1:
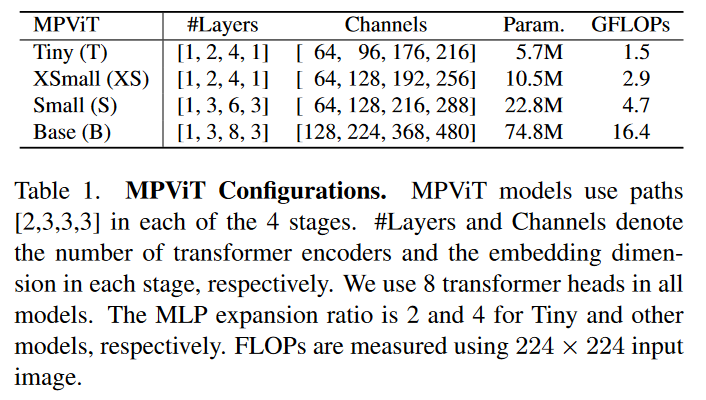
解释一下这个表格:
在这四个模型中,因为是four-stage,对于每个stage的transformer encoder数量的设置写入了Layers,对于每个stage的嵌入维度写入了Channels,对于四个stage,使用的paths是[2,3,3,3]。
4. Experiments
In this section, we evaluate the effectiveness and versatility of MPViT as a vision backbone on image classification (ImageNet-1K), dense predictions such as object detection and instance segmentation (COCO), and semantic segmentation (ADE20K).
在这一小节中,我们评估了在不同数据集上对于不同任务预测的有效性和通用性。
4.1 ImageNet Classification
我们遵循DeiT的训练公式,训练了300个epochs,使用AdamW优化器,batch size选择1024,权重衰减0.05,5个预热epoch,初始化学习率0.001,使用一个余弦衰减学习速率调度器进行缩放。裁剪每张图片到224x224的大小,使用和《Training data-efficient image transformers & distillation through attention》论文中一样的数据增强技术。在Small model和Base sized model上随机深度下降设置为0.05和0.3。下图是模型结果。
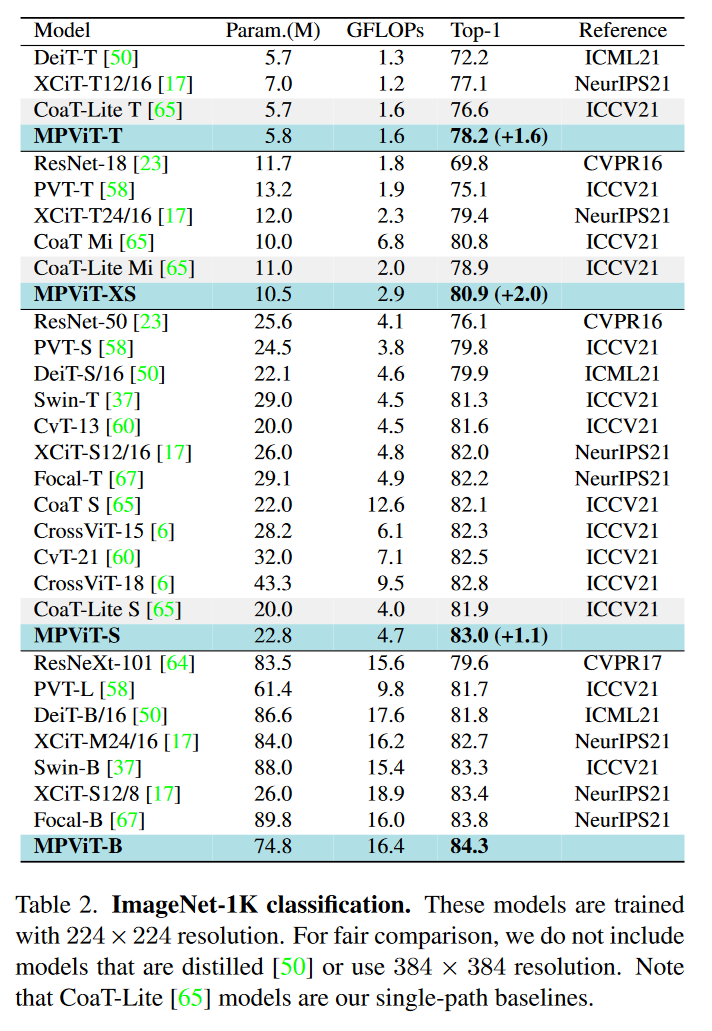
4.2 Object Detection and Instance Segmentation
我们分别使用RetinaNet和Mask R-CNN验证了MPViT作为目标检测和实例分割的有效的特征提取器。我们在ImageNet-1K上预训练了backbones然后把预训练好的backbones插入到RetainaNet和Mask R-CNN中,根据常用设置和Swin-Transformer的训练规则,我们使用多尺度训练策略训练训练3x schedule,36 epochs,使用AdamW优化器,初始化学习率0.0001,权重衰减0.05。基于detectron2库执行我们的模型。结果如下图所示:
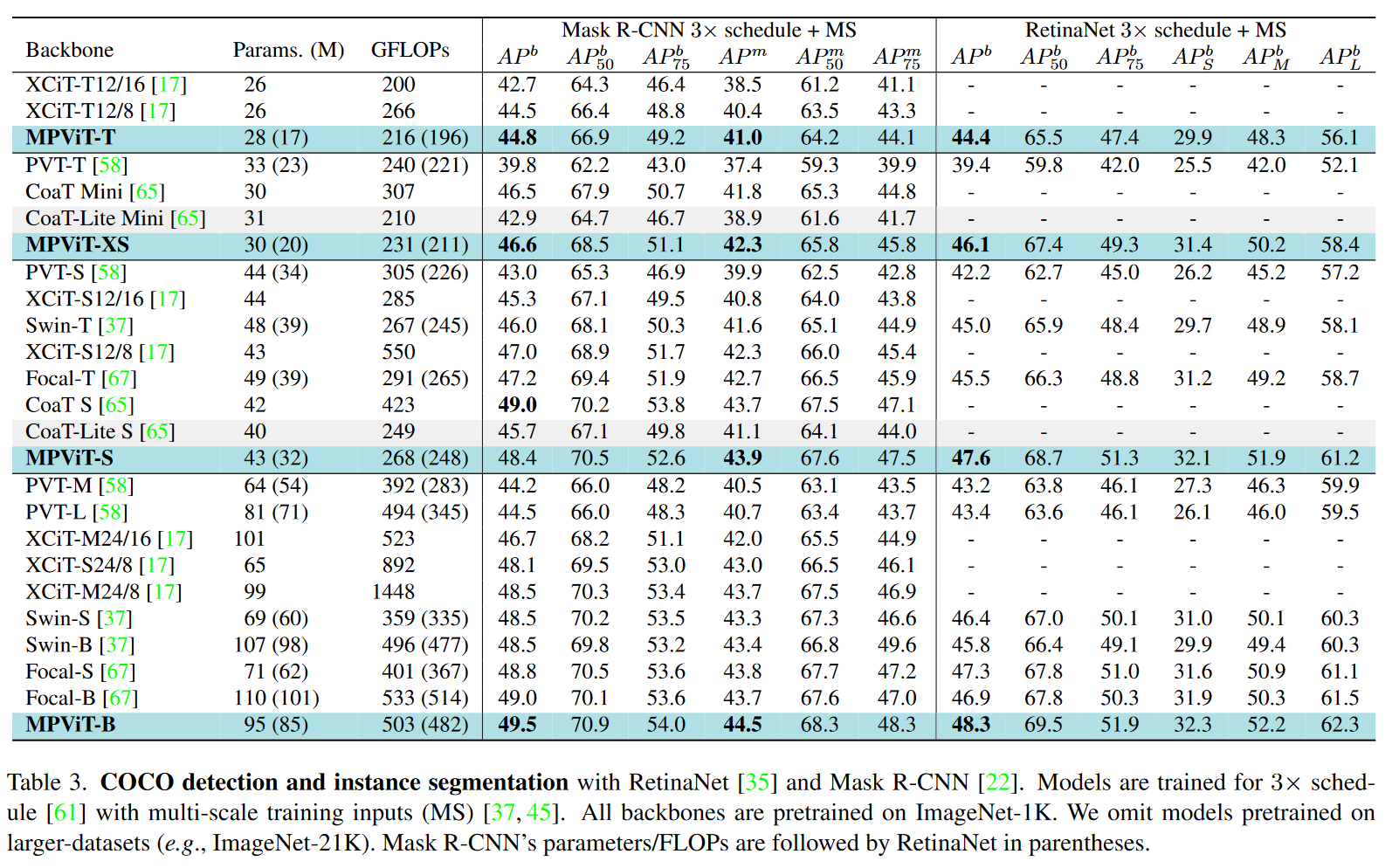
这些结果表明了我们提出的多尺度patch嵌入和多路径结构,比更简单的多尺度结构化目标检测模型能表征更多样的多尺度特征,这需要尺度不变性。
4.3 Semantic segmentation
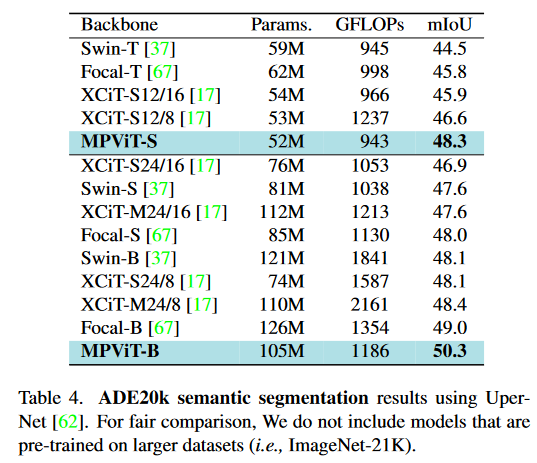
4.4 Ablation study
利用Mask R-CNN,采用1x schedule和单尺度输入,对MPViT-XS的每个分量进行消融研究,以考察所提出的多路径结构对图像分类和目标检测的有效性。
我们使用模型大小(即模型参数)、计算成本(GFLOPs)、GPU峰值内存和GPU吞吐量等多种指标进行实验。使用Coat-Lite Mini作为单路径基准,因为它利用了与MPViT相同的factorized self-attention机制。在相同模型大小和相同FLOPs的限制下,三路径是最好的选择。路径增多并不会增加更多的内存消耗,而嵌入维度C增大则会导致开销增大。这是因为 C 是一个比 L(layer)在内存使用上还要大的因素。
5. Discussion
Model Capacity Analysis
测量实际GPU吞吐量和内存使用量,分析MPViT-S的模型容量,并与近期SOTA Transformer进行对比,如下图所示:

我们在相同的Nvidia V100 GPU上测试所有模型,batch size为256,尽管CoaT Small因其额外的跨层注意力而获得了最好的检测性能,但与Swin-T和Focal-T类似的简单多级结构的CoaT-Lite Small相比,它表现出更重的内存使用和GPU计算。和CoaT Small相比,MPViT-S占用的内存更少,运行速度快4x,检测性能相当,说明MPViT可以高效地执行,其多尺度表示有效,无需CoaT额外的跨层注意力。此外,CoaT由于其穷举内存的使用,在扩展模型方面具有局限性,而MPViT可以扩展到更大的模型。对于具有单级结构的XCiT,XCiT-S12/16(16x16 patches:scale 4)具有更快的速度和更少的内存占用,而XCiT-S12/8由于具有更高的特征分辨率,需要比MPViT-S更多的计算和内存。我们注意到XCiT-S12/8表现出比MPViT-S(83.0%)更高的分类准确率(83.4%),而检测性能则相反。这一结果表明,对于密集预测任务,MPViT的多尺度嵌入和多路径结构都比XCiT的单阶段结构具有更高的效率和效果。MPViT也比大多数模型具有相对较小的内存占用。
Qualitative Analysis

在上图中,我们对triple-path和单路径的注意力图进行了可视化。由于三条路径嵌入了可视化,由于triple-path嵌入了不同的patch大小,我们对每条路径的注意力图进行可视化。CoaT-Lite和path-1的注意力图具有相似的patch大小,表现出相似的注意力图。有趣的是,我们观察到path-3的注意力图更多地以物体为中心,关注具有更高表征水平的更大的patch,精确地捕获了物体的范围。但同时,path-3抑制了小目标和噪声。相反,path-1由于使用了精细的patches而关注小物体,但由于使用了低层次的表示而没有精确地捕获大物体边界。这在上图的第三行中尤为明显,其中path-1捕获一个较小的球,而path-3关注一个较大的人。这些结果表明,通过多路径结构组合细特征和粗特征可以在给定的视觉输入中捕获不同尺度的对象。
Qualitative Analysis
大量的实验结果表明,MPViT不仅在图像级预测任务上,而且在稠密预测任务上都显著优于当前的SOTA Vision Transformers。我们的MPViT模型的一个可能限制是推断时间的延迟。如表7所示,MPViT-S的推理时间要慢于Swin-T和XCiT-S12/16。我们假设多路径结构导致了次优的GPU利用率,因为对分组卷积(例如GPU上下文切换、内核同步等)进行了类似的观测。为了缓解这个问题,它将不同尺度的特征集成到一个张量中,然后与张量进行多头自注意力。这将提高并行化和GPU利用率。此外,为了平衡精度/速度之间的权衡,我们将进一步考虑复合缩放策略中的路径尺寸,以考虑当递增递减为模型容量时,深度、宽度和分辨率的最优组合。
2. 读完论文产生的问题
-
读摘要的时候就对【MPViT embeds features of the same size (i.e., sequence length) with patches of different scales simultaneously by using overlapping convolutional patch embedding.】这句话产生了疑问,什么是overlapping convolutional patch embedding呢?如何得到相同尺寸的features呢?如何得到不同scales的patches呢?
overlapping convolutional重叠卷积是一种卷积方式,它在进行卷积操作时,将卷积核的步长设置为小于卷积核大小的值,从而使得相邻的卷积操作之间存在重叠区域。这种方式可以增加卷积操作的覆盖范围,从而提高特征提取的效果。在MPViT中,重叠卷积被用于将不同尺度的patch转换为相同尺寸的向量表示。通过卷积核的步长和padding的设置就可以得到相同尺寸的features。不同尺寸的patches只需要取不同的卷积核即可。 -
Tokens of different scales are then independently fed into the Transformer encoders via multiple paths and the resulting features are aggregated, enabling both fine and coarse feature representations at the same feature level.中的at the same feature level是什么?
指的是经过了相同层数的卷积操作,但是卷积核不一定一致。 -
文章中说的four-stage在architecture中是哪四个阶段?为什么后面又出现了【from stage 2 to stage 5】
每个MS-PatchEmbed和MP-Transformer构成了一个stage。
-
什么是depthwise separable convolutions?
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution,该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低,所以在一些轻量级网络中会碰到这种结构。
常规卷积操作:
对于一张5x5像素、三通道彩色输入图片,shape为5x5x3,经过3x3卷积核的卷积层,假设输出通道数为4,则卷积核shape为3x3x3x4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5x5),如果没有则为3x3(5x5的图像经过3x3卷积,没有same padding,N=(5-3+0)/1+1=3)。

Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
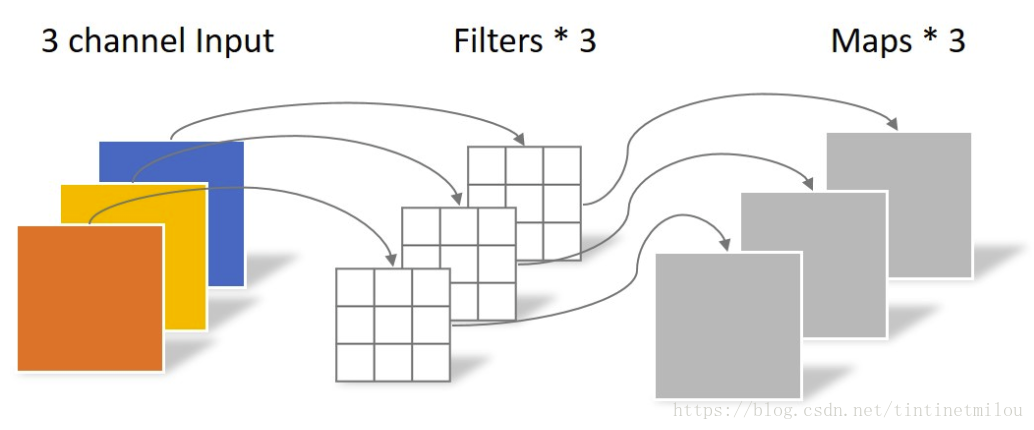
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
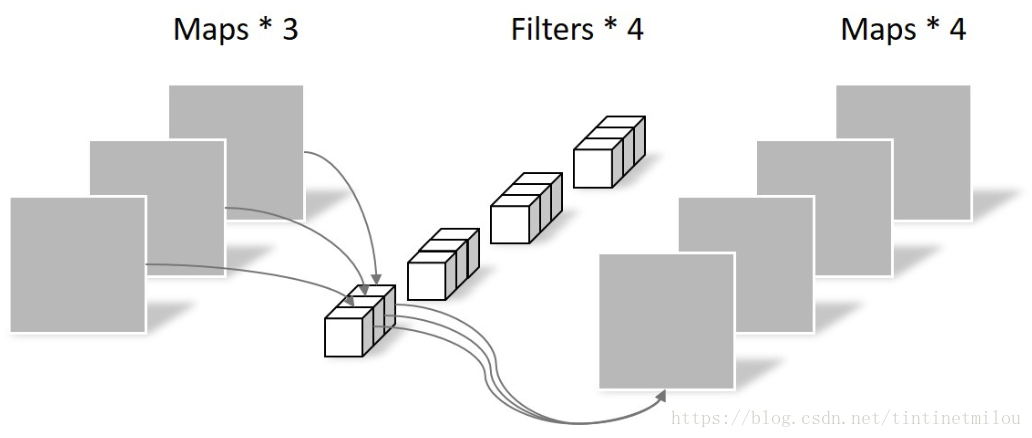
总结:depthwise separable convolution与常规卷积的区别:常规卷积每个卷积核是同时操作输入图片的每个通道,而depthwise separable convolutional包括depthwise convolution和point-wise convolutional,先使用depthwise convolution对卷积进行深度分离,也就是一个卷积核负责一个通道,一个通道只被一个卷积核卷积(缺点是:没有有效利用不同通道在相同空间位置上的feature信息,所以后面使用了point-wise convolutional进行维度扩展),然后又使用point-wise convolutional实现特征图维度扩展(卷积核尺寸1*1×M,M为上一层的通道数,进行操作时如同普通卷积,有几个卷积核就输出几个Feature Map)
参考文章:什么是depthwise separable convolutions -
目前还没解决Table 1和模型图对不起来的问题!(2023.3.23)