论文地址:https://arxiv.org/pdf/2102.12122.pdf
源码:https://github.com/whai362/PVT
Abstract
VIT很难用于密集检测任务,作者提出了PVT,(1)不同于产生低分辨率输出和引起高计算和内存成本的VIT,PVT不仅可以训练密集分区的图像来实现高输出分辨率,也使用图像金字塔来减少大型特征地图的计算。(2) PVT继承了CNN和transformer的优点,使其成为各种transformer架构的视觉任务的统一骨干,可以作为CNN骨干的直接替代。(3)我们通过大量的实验验证了PVT,结果表明它提高了许多下游任务的性能优异,包括目标检测、实例和语义分割。
1. Introduction
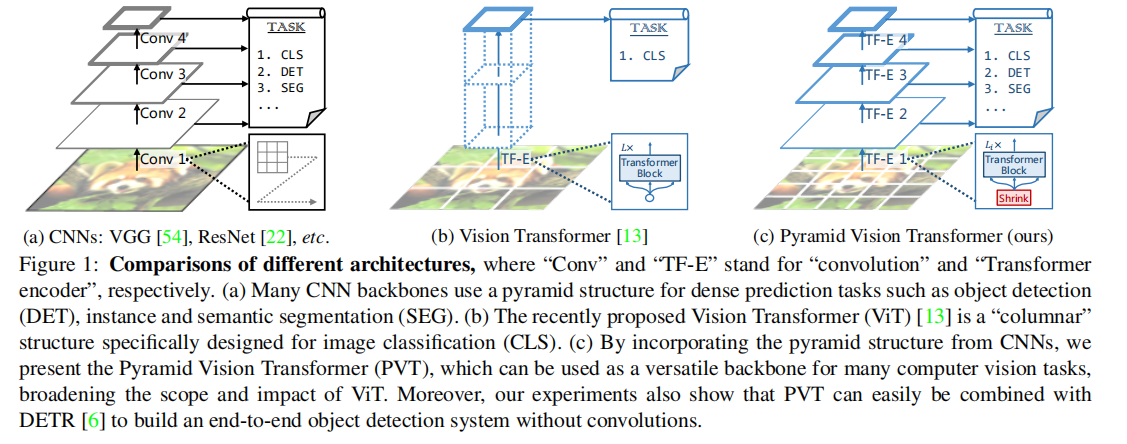
虽然ViT适用于图像分类,它是很难直接适应像素级密集预测如目标检测和分割,因为(1)其输出特征地图是单尺度和低分辨率,和(2)其计算和内存成本相对较高即使对于常见的输入图像大小(800*800)
为了解决上述局限性,本工作提出了一种纯的transformer主干,称为PVT,它可以作为许多下游任务中CNN主干的替代方案,包括图像级预测和像素级密集预测。具体来说,如图1 (c)所示,我们的PVT克服了传统transformer的困难:(1)以细粒度的图像补丁(即每个补丁4×4像素)作为输入来学习高分辨率表示,这对于密集的预测任务是必不可少的;(2)随着网络的加深,减少transformer的序列长度,显著降低计算成本,(3)在学习高分辨率特征时采用空间减少注意(SRA)层,进一步降低资源消耗。
总的来说,所提出的PVT具有以下优点。首先,与传统的CNN骨干网局部接受域随着网络深度的增加而增加(见图1 (a))相比,我们的PVT总是产生一个全局的接受域,更适合检测和分割。其次,与ViT相比(见图1 (b))相比,由于其先进的金字塔结构,我们的方法可以更容易地插入许多具有代表性的密集预测管道,如RetinaNet和Mask R-CNN [21]。第三,我们可以通过将我们的PVT与其他特定任务的transformer解码器相结合,构建一个无卷积的管道,如PVT+DETR [6]。据我们所知,这是第一个完全无卷积的对象检测管道。
我们的主要贡献如下:
(1)我们提出了PVT,这是第一个为各种像素级密集预测任务设计的纯transformer主干。结合我们的PVT和DETR,我们可以构建一个端到端目标检测系统,而不需要卷积和手工制作的组件,如密集的锚点和非最大抑制(NMS)。
(2)通过设计一个渐进收缩的金字塔和一个空间减少注意(SRA),我们克服了将transformer移植到密集预测时的许多困难。这些都能够减少transformer的资源消耗,使PVT能够灵活地学习多尺度和高分辨率的特性。
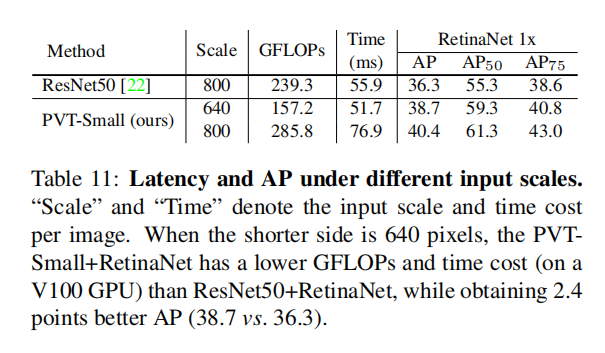
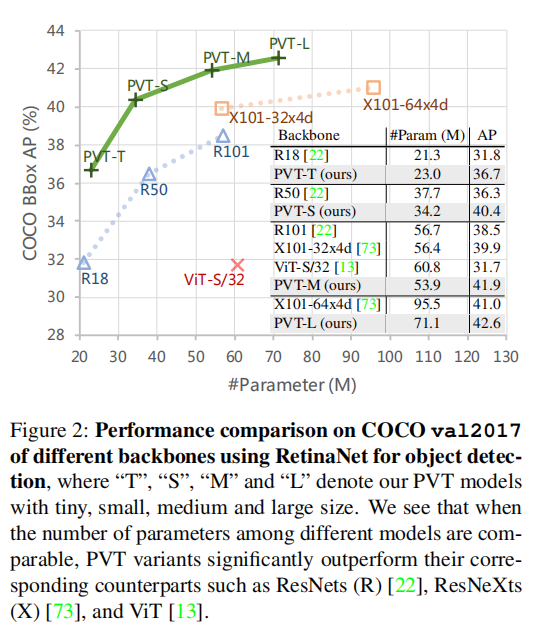
(3)我们在图像分类、目标检测、实例和语义分割等不同任务上评估了所提出的PVT,并将其与流行的ResNets [22]和ResNeXts [73]进行了比较。如图2所示.

3. Pyramid Vision Transformer (PVT)
3.1. Overall Architecture
我们的目标是将金字塔结构引入变压器框架,使它可以生成多尺度特征映射的密集预测任务(如目标检测和语义分割)。图3描述了PVT的概述。与CNN骨干[22]类似,我们的方法有四个阶段来生成不同尺度的特征图。所有的阶段都有一个相似的架构,由一个补丁嵌入层和Li变压器编码器层组成。

在第一阶段,给定一个大小为H×W×3的输入图像,我们首先将其划分为补丁,每个补丁的大小为4×4×3。然后,我们将patch序列输入线性投影,得到大小为
![]() 的嵌入patch。然后,向patch加入位置编码,通过L1层transformer编码器,输出重塑为大小为
的嵌入patch。然后,向patch加入位置编码,通过L1层transformer编码器,输出重塑为大小为![]() 的特征图F1。同样,使用前一阶段的特征图作为输入,我们得到了以下特征图: F2、F3和F4,它们相对于输入图像的步幅分别为8、16和32像素。利用特征金字塔{F1、F2、F3、F4},我们的方法可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
的特征图F1。同样,使用前一阶段的特征图作为输入,我们得到了以下特征图: F2、F3和F4,它们相对于输入图像的步幅分别为8、16和32像素。利用特征金字塔{F1、F2、F3、F4},我们的方法可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
3.2. Feature Pyramid for Transformer
与CNN骨干网络使用不同的卷积步幅来获得多尺度特征图不同,我们的PVT使用一种渐进收缩策略,通过补丁嵌入层来控制特征图的尺度。
这节的含义是特征图的缩小的实现:
对于输入的特征图![]() ,首先将其划分为大小为
,首先将其划分为大小为![]() 的patch,然后在经过线性投影映射到C_i个通道,此时特征图维度为
的patch,然后在经过线性投影映射到C_i个通道,此时特征图维度为![]()
3.3. Transformer Encoder
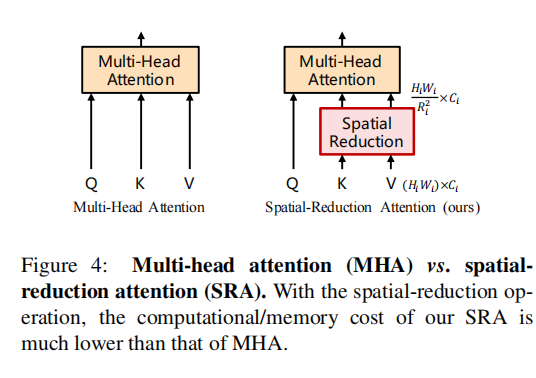
阶段i中的变压器编码器具有Li编码器层,每个编码器层由注意层和前馈层[64]组成。由于PVT需要处理高分辨率(例如,4步幅)特征图,我们提出了一个空间减少注意(SRA)层来取代编码器中传统的多头注意(MHA)层[64]。
具体来说,就是类似于上一节特征图的缩小,首先将特征图划分为 ![]() 的patch,此时特征图的维度为
的patch,此时特征图的维度为![]() ,然后再经过线性层将通道数投影回
,然后再经过线性层将通道数投影回通道,公式如下:

其核心思想就是通过重构特征矩阵并进行线性投影映射减少key和value的特征图的HW,以达到减少运算的目的,由于通道数C依然不改变,因此对value无影响
从源码具体实现的角度,首先经过一层kernel=R*R ,stride=R的卷积,卷积后C保持不变,此时query [B,HW,C],key [B,HW/R^2,C],value [B,HW/R^2,C],首先[email protected](-2,-1),矩阵运算为 attn=[B,HW,C]*[B,C,HW/R^2]=[B,HW,HW/R^2],经过softmax后,点乘value,即attn*value=[B,HW,HW/R^2]*[B,HW/R^2,C]=[B,HW,C]
5. Experiments
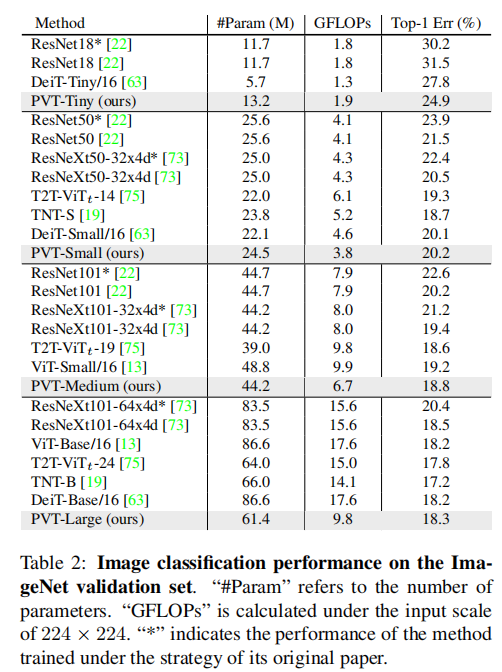
5.1. Image Classifification
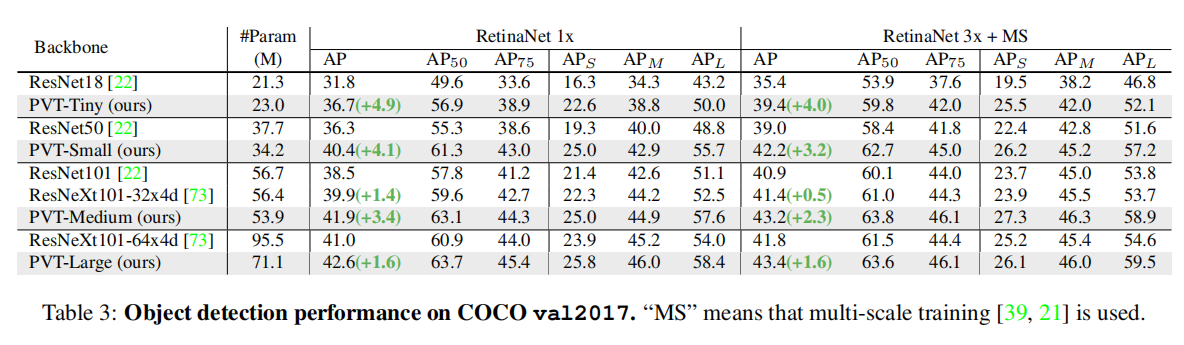
5.2. Object Detection

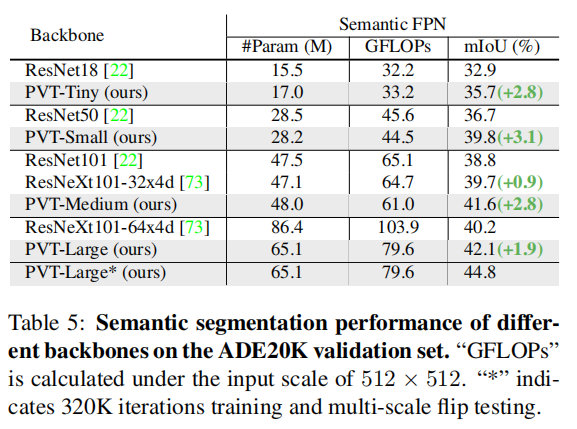
5.3. Semantic Segmentation
5.4. Pure Transformer Detection & Segmentation


5.5. Ablation Study
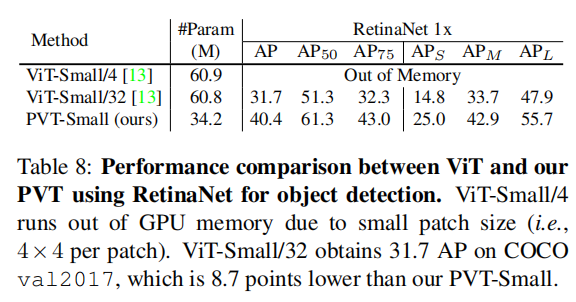
Pyramid Structure. 当使用大的图像补丁(32*32)的时候,效果非常差,当使用小的图像补丁时,内存占用太大,因此PVT使用图像金字塔解决这个问题
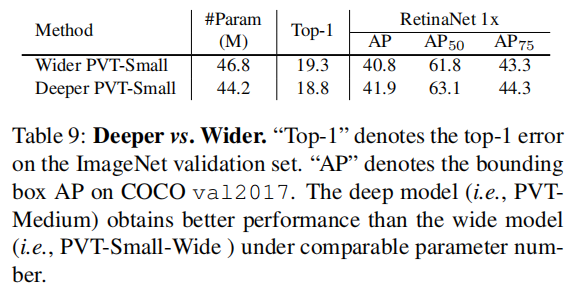
Deeper vs. Wider 因此,在PVT的设计中,越深比越宽更有效。基于此观察结果,在表1中,我们通过增加模型的深度来开发不同尺度的PVT模型。
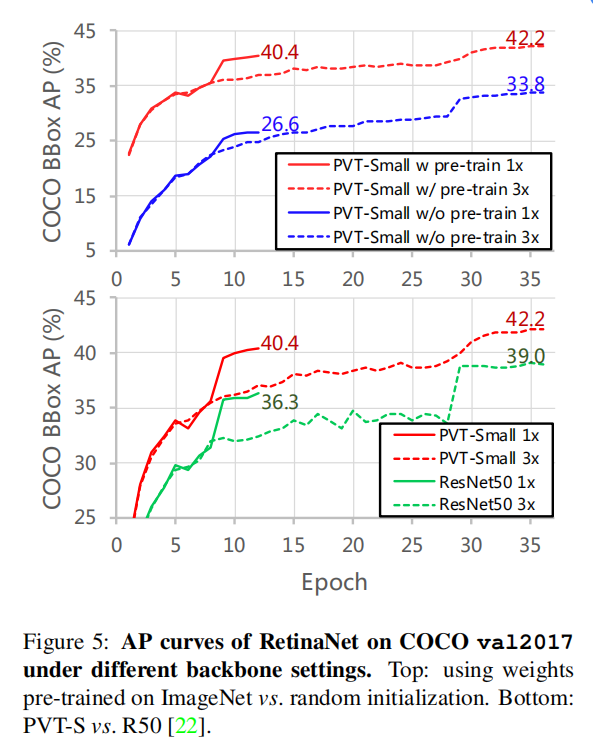
Pre-trained Weights 预训练的模型比没有经过预训练的模型收敛性更好 ,基于pvt的模型(红色曲线)的收敛速度比基于resnet的模型(绿色曲线)要快。
PVT vs. “CNN w/ Non-Local”
虽然单一的全局注意层(如非局部[70]或多头注意(MHA)[64])可以获得全局接受域特征,但随着模型的加深,模型的性能不断提高。这说明堆叠多个mha可以进一步增强特征的表示能力。
(2)正则卷积可以看作是空间注意机制[84]的特殊实例。换句话说,MHA的格式比常规卷积更灵活。例如,对于不同的输入,卷积的权值是固定的,但MHA的注意权值随输入而动态变化。因此,充满MHA层的纯变压器主干所学习到的特征可以更加灵活和富有表现力。
Computation Overhead.