论文地址:https://arxiv.org/abs/2103.00112
1.Abstract
vision transformer首先将输入图像划分为几个局部patch,然后计算表示及其关系。由于自然图像复杂度高,细节丰富,颜色信息丰富,因此patch分割的粒度不够好,无法挖掘不同尺度和位置的物体特征。在本文中,作者指出这些局部patch内部的注意力对于构建高性能的vision transformer也是必不可少的,提出了Transformer in transformer。具体来说,将局部补丁(例如,16×16)视为“视觉句子”,并进一步将它们划分为更小的补丁(例如,4×4)视为“视觉单词”。每个单词的注意力将用给定的视觉句子中的其他单词来计算,计算成本可以忽略不计。将单词和句子的特征进行聚合,以提高表现能力。
2. Introduction
虽然 vision transformer在提高模型性能方面做了很大的努力,但现有的工作大多遵循ViT中使用的传统表示方案,即将输入图像分割成patch。这种精细的范式可以有效地捕获视觉序列信息,并估计不同图像patch之间的注意力。然而,在现代基准测试中,自然图像的多样性非常高,例如,在ImageNet数据集[30]集中有超过1.2亿张图像和1000个不同的类别。如图1所示,将给定的图像表示为局部patch可以帮助我们找到它们之间的关系和相似性。然而,其中也有一些相似性很高的sub-patch。
在本文中,作者提出了一种新的Transformer-iN-Transformer(TNT)的视觉识别架构,如图1所示。为了增强vision transformer的特征表示能力,首先将输入的图像分成几个patch,划分为“视觉句子”,然后再将其划分为“视觉词汇”。除了传统的提取视觉句子的特征和注意事项的变压器块外,还在架构中嵌入了一个子变压器,以挖掘较小的视觉单词的特征和细节。具体来说,每个视觉句子中视觉单词之间的特征和注意是使用共享网络独立计算的,这样增加的参数和计算量(浮点运算)的数量可以忽略不计。然后,将单词的特征聚合成相应的视觉句子。该class token也通过一个完全连接的头部用于后续的视觉识别任务。通过所提出的TNT模型,可以提取出较细粒度的视觉信息,并提供更多细节的特征。
3. Approach
2.1 Preliminaries
首先简要描述了transformer[39]的基本组件,包括MSA(多头自注意)、MLP(多层感知器)和LN(层归一化)。
MSA. Q,K,V均是X通过线性投影而来,通常使用多头注意力,即将Q,K,V划分为h个部分

MLP MLP应用于自注意层之间进行特征变换和非线性:
 其中,W和b分别为全连接层的权值项和偏差项,σ(·)为GELU [14]等激活函数。
其中,W和b分别为全连接层的权值项和偏差项,σ(·)为GELU [14]等激活函数。
LN. 层归一化[1]是transformer稳定训练和快速收敛的关键部分。LN应用于每个样本![]() ,如下所示:
,如下所示:

其中,µ∈R,δ∈R,δ∈R分别为特征的均值和标准差,◦为元素级点积,γ∈Rd,β∈Rd为可学习的仿射变换。
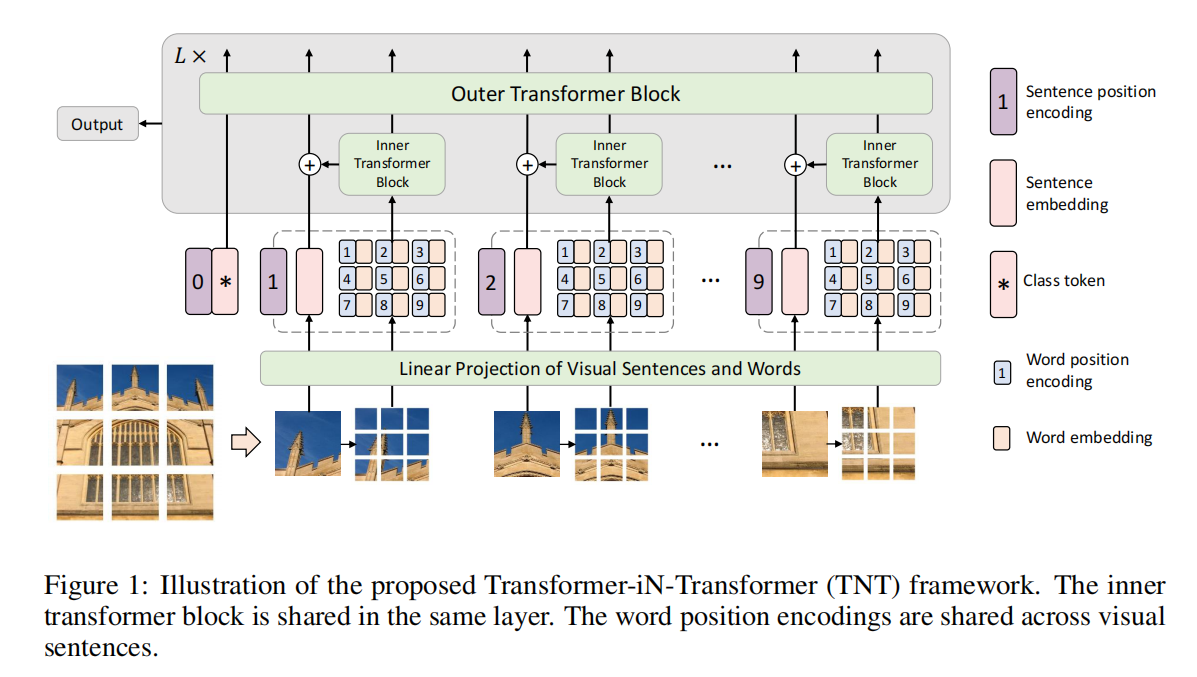
2.2 Transformer in Transformer
给定一个二维图像,我们将其均匀地分割成n个补丁![]() ,其中(p,p)是每个图像patch的分辨率。图1(a).所示,在TNT中,将补丁视为代表图像的视觉句子。每个补丁被进一步划分为m个子补丁,即一个视觉句子由一系列的视觉单词组成:
,其中(p,p)是每个图像patch的分辨率。图1(a).所示,在TNT中,将补丁视为代表图像的视觉句子。每个补丁被进一步划分为m个子补丁,即一个视觉句子由一系列的视觉单词组成:

通过线性投影,我们将视觉单词转换为一系列的单词embeding:

对于word embeding,使用transformer进行特征提取:

在句子级别,相关序列:![]() ,其中Zclass是类似于ViT [10]的class token,它们都被初始化为零。在每一层中,将word embeding的序列通过线性投影转换到sentence embeding的域中,并添加到sentence embeding中:
,其中Zclass是类似于ViT [10]的class token,它们都被初始化为零。在每一层中,将word embeding的序列通过线性投影转换到sentence embeding的域中,并添加到sentence embeding中:
 使用标准的transformer块来转换sentence embeding:
使用标准的transformer块来转换sentence embeding:

这个外部转换器块Tout用于建模sentence embeding之间的关系。综上所述,TNT块的输入和输出包括视觉word embeding和sentence embeding,如图1(b)所示,因此TNT可以表述为:

在我们的TNT块中,内部transformer模块用于建模视觉单词之间的关系,用于局部特征提取,而外部转换块从句子序列中捕获内在信息。通过将TNT块堆叠L次,建立了transformer网络。最后,将class token作为图像表示,并采用全连接层进行分类。
Position encoding. 空间信息是图像识别中的一个重要因素。对于sentence embeding和word embeding,我们都添加了相应的位置编码来保留空间信息,如图1所示。这里使用了标准的可学习的一维位置编码。具体来说,每个句子都被分配有一个位置编码:

其中,![]() 为句子位置编码。对于句子中的视觉单词,在每个word embeding中添加一个单词位置编码:
为句子位置编码。对于句子中的视觉单词,在每个word embeding中添加一个单词位置编码:

其中,![]() 是在句子之间共享的单词位置编码。这样,句子位置编码可以保持全局空间信息,而单词位置编码则用于保持局部相对位置。
是在句子之间共享的单词位置编码。这样,句子位置编码可以保持全局空间信息,而单词位置编码则用于保持局部相对位置。
2.3 Complexity Analysis
标准transformer模块包括多头自注意和多层感知器两部分。MSA的计算量为![]() ,MLP的计算量为
,MLP的计算量为![]() ,其中r为MLP中隐藏层的维度扩展比。总的来说,一个标准transformer的计算量是
,其中r为MLP中隐藏层的维度扩展比。总的来说,一个标准transformer的计算量是

需要说明的是,其中 表示的是X线性投影为Q,K,V的运算量,至于为什么是这个形式,我也没有看懂,从源码实现的角度,这部分计算方式应该为:nd(d_k+d_q+d_v),代码实现上Q和K的维度d一定相同,v的维度数可以设置,此时这部分的计算量应为2ndd_k+ndd_v。
表示的是X线性投影为Q,K,V的运算量,至于为什么是这个形式,我也没有看懂,从源码实现的角度,这部分计算方式应该为:nd(d_k+d_q+d_v),代码实现上Q和K的维度d一定相同,v的维度数可以设置,此时这部分的计算量应为2ndd_k+ndd_v。
 表示的是点积的计算量。
表示的是点积的计算量。
因为对这个计算量的公式有些疑惑,因此计算量这个模块将不进行展开。
2.4 Network Architecture
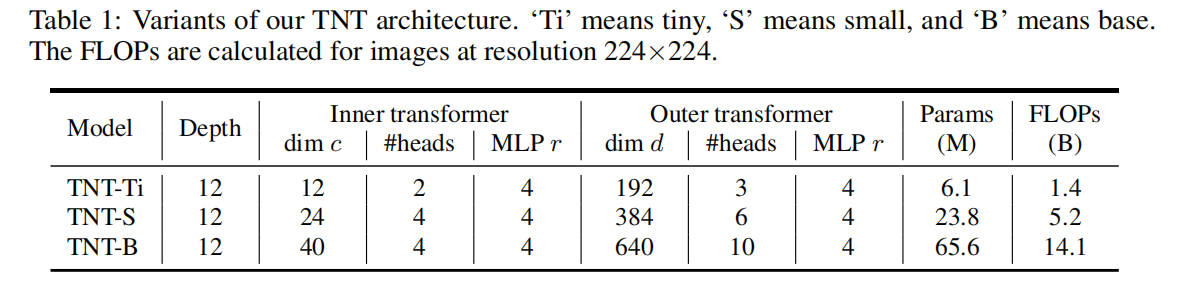
遵循ViT [10]和DeiT [35]的基本配置来构建TNT架构。补丁的大小设置为16×16。子补丁的数量默认设置为m = 4·4 = 16。其他尺寸值在消融研究中进行了评估。如表1所示,不同模型大小的TNT网络有三种变体,即TNT-Ti、TNT-S和TNT-B。它们分别由6.1M、23.8M和65.6M的参数组成。用于处理224×224图像的相应FLOPs分别为1.4B、5.2B和14.1B
3 Experiments

3.1 Datasets and Experimental Settings
Implementation Details.

3.2 TNT on ImageNet

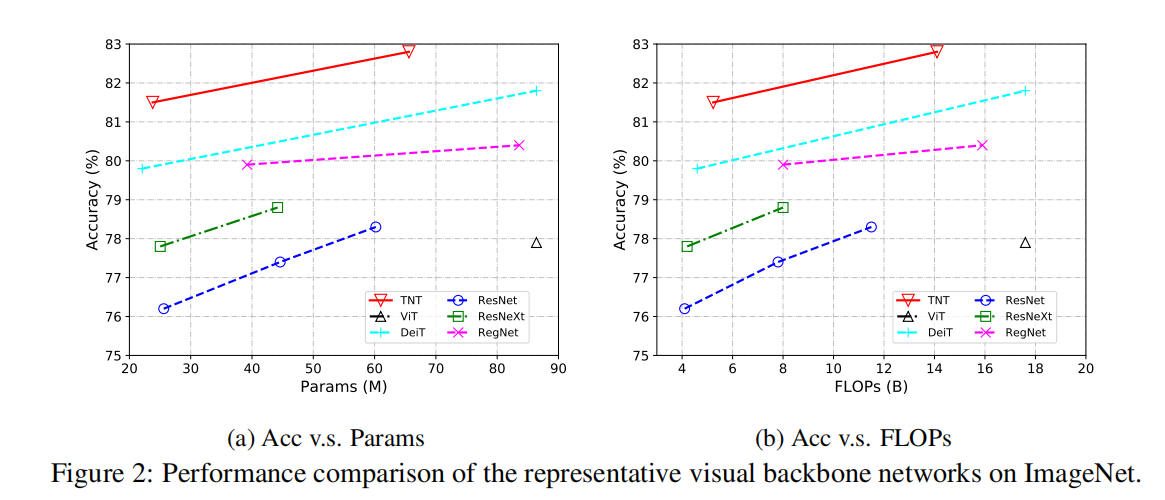
Inference speed.
 3.3 Ablation Studies
3.3 Ablation Studies
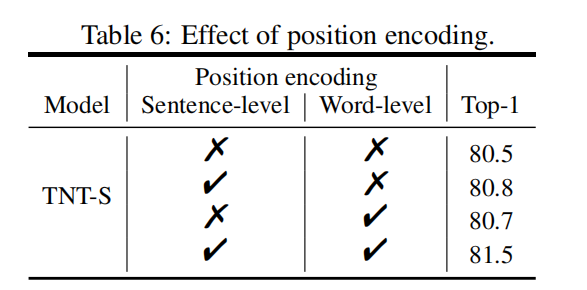
位置编码的影响。位置信息对图像识别非常重要。在TNT结构中,句子位置编码用于保持全局空间信息,而单词位置编码用于保持局部相对位置。
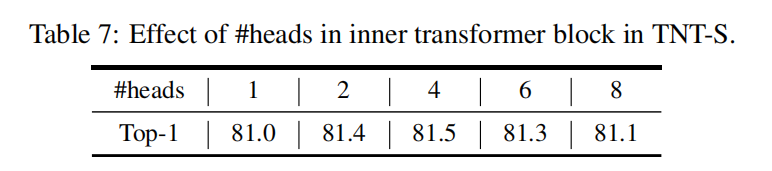
Number of heads. 2或4个head效果比较好
视觉单词的数量。在TNT中,输入图像被分割成16个×16个补丁,每个补丁被进一步分割成m个大小为(s,s)的子补丁(视觉单词),以提高计算效率。这里测试了超参数m对TNT-S体系结构的影响。当改变m时,嵌入维数c也相应地改变以控制浮动。如表8所示,可以看到m的值对性能的影响很小,默认使用m = 16作为其效率。

3.4 Visualization
特征图的可视化。可以看到,TNT的特性比DeiT更多样化,包含更丰富的信息。这些好处是因为引入了内部transformer块来建模局部特征。

除了补丁级的特征外,图4中可视化了TNT的像素级嵌入。对于每个补丁,根据其空间位置对单词嵌入进行重塑,形成特征图,然后根据通道维度对这些特征图进行平均。14×14 patch对应的平均特征图如图4所示。可以看到,局部信息在浅层中得到了很好的保存,随着网络的深入,其表示也逐渐变得更加抽象。

注意地图的可视化。在TNT模块中有两个自我注意层,即内部自我注意层和外部自我注意层,分别用于建模视觉单词和句子之间的关系。在图5中显示了内部转换器中不同查询的注意力映射。对于给定的查询视觉词,外观相似的视觉词的注意值较高,说明其特征与查询的交互作用更相关。这些交互作用在ViT和DeiT等系统中被遗漏了。外部变压器中的注意图可以在补充材料中找到。

3.5 Transfer Learning
Pure Transformer Image Classifification.

Pure Transformer Object Detection.

Pure Transformer Semantic Segmentation.
