[2021.01] Survey - A Survey on Visual Transformer


Paper:https://arxiv.org/pdf/2012.12556.pdf

[2021.05] - LeViT- a Vision Transformer in ConvNet's Clothing for Faster Inference
![]()
Paper: https://arxiv.org/pdf/2104.01136.pdf



[2021.05] - Swin-Unet- Unet-like Pure Transformer for Medical Image Segmentation

Paper: https://arxiv.org/pdf/2105.05537.pdf


[2021.04] - Incorporating Convolution Designs into Visual Transformers
![]()
Paper: https://arxiv.org/pdf/2103.11816.pdf





[2021.04] - Going deeper with Image Transformers

Paper: https://arxiv.org/pdf/2103.17239.pdf

[2021.04] - DeepViT- Towards Deeper Vision Transformer
Paper: https://arxiv.org/pdf/2103.11886.pdf


[2021.04] - Emerging Properties in Self-Supervised Vision Transformers

Paper:https://arxiv.org/pdf/2104.14294.pdf


[2021.04] - Token Labeling- Training a 85.4% Top-1 Accuracy Vision Transformer with 56M Parameters on ImageNet

Paper: https://arxiv.org/pdf/2104.10858.pdf



[2021.03] 2021ICLR - Deformable DETR- Deformable Transformers for End-to-End Object Detection
Paper: https://arxiv.org/pdf/2010.04159.pdf



[2021.03] Pre-Trained Image Processing Transformer
Paper: https://arxiv.org/pdf/2012.00364.pdf


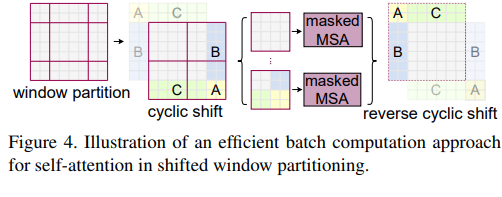
[2021.03] - Swin Transformer- Hierarchical Vision Transformer using Shifted Windows

Paper: https://arxiv.org/pdf/2103.14030.pdf




[2021.03] - Rethinking Spatial Dimensions of Vision Transformers

Paper: https://arxiv.org/pdf/2103.16302.pdf


[2021.03] - Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers

Paper: https://arxiv.org/pdf/2012.15840.pdf

[2021.03] - CvT- Introducing Convolutions to Vision Transformers
Paper: https://arxiv.org/pdf/2103.15808.pdf


[2021.03] - CrossViT- Cross-Attention Multi-Scale Vision Transformer for Image Classification
![]()
Paper: https://arxiv.org/pdf/2103.14899.pdf



[2021.03] - Tokens-to-Token ViT- Training Vision Transformers from Scratch on ImageNet
Paper: https://arxiv.org/pdf/2101.11986.pdf




[2020.11] - Visual transformer- Token-based image representation and processing for computer vision

Paper: https://arxiv.org/pdf/2006.03677.pdf




[2021.01] - Training data-efficient image transformers & distillation through attention

Paper: https://arxiv.org/pdf/2012.12877.pdf


[2021.01] - TransUnet- Transformers make strong encoders for medical image segmentation
Paper: https://arxiv.org/pdf/2102.04306.pdf


[2020.10] 2021ICLR- An Image is Worth 16x16 Words- Transformers for Image Recognition at Scale

Paper: https://arxiv.org/pdf/2010.11929.pdf


[2021.03] Learning Texture Transformer Network for Image Super-Resolution

Paper: https://arxiv.org/pdf/2006.04139.pdf


[2020.05] 2020ECCV - End-to-End Object Detection with Transformers

Paper: https://arxiv.org/pdf/2005.12872.pdf



