论文下载地址:XGBoost: A Scalable Tree Boosting System
一句话讲:
读前先问
读论文之前首先要问几个问题:
- 这篇论文大方向的目标是什么?
机器学习中的有监督学习问题,让模型分类/回归的效果更好。 - 这个方向目前有什么问题?
① 由于大数据导致训练时长激增;② 稀疏特征和缺失值越来越多。 - 这篇论文要解决什么问题?
提升模型训练效率和可扩展性。 - 为什么会有这些问题?
① 数据量越来越大;② 没有通用的框架。 - 作者是怎么解决这些问题的?
开发了一个通用、高效、可扩展的框架。 - 怎么验证论文的解决方法是否有效?
民心所向就完了,用的人越多,效果越好,说明框架越牛逼。
论文精华翻译
摘要
提升树模型是一种高效且广泛使用机器学习方法。在本文中,我们提出了一个可扩展的端到端提升树系统,称为XGBoost,它被数据科学家广泛使用,在许多机器学习挑战中取得了最先进的结果。我们提出了一种新的针对稀疏数据的稀疏感知算法和针对近似树学习的加权分位点算法。更重要的是,我们对缓存访问模式、数据压缩和分片进行了深入的研究,构建了一个可扩展的提升树系统。通过结合这些见解,XGBoost可以使用比现有系统少得多的资源来扩展数十亿个示例。
关键字:大规模可扩展机器学习
论文分享文稿
作者介绍

本硕就读于上海交通大学,博士就读于华盛顿大学,XGB也是作者在博士期间创建的一个框架。现在是卡耐基梅隆大学的助理教授,同时是OctoML的首席技术专家。其实除了XGB之后,陈天奇老师也致力于推动机器学习和深度学习系统的开源,他是Apache MXNet的联合创作者,这是一个非常经典的深度学习框架,曾经和TensorFlow与PyTorch齐名,然后也是Apache TVM的CTO,这也是一个自动化端到端深度学习框架,编译优化做的非常好。

巴西圣保罗大学机电一体化工程师,斯坦福大学的硕士和博士。这位大佬的履历非常丰富,2003年-2004年在英特尔研究实验室担任高级研究员,2004年-2012年在卡耐基梅隆大学担任副教授,2012年-2021年在华盛顿大学担任亚马逊机器学习教授,并且在此期间,也就是2016年-2021年,他在苹果担任人工智能高级总监。
背景知识
- 什么是机器学习?
机器学习,顾名思义就是让机器,也就是让计算机去学习。那么怎么学习呢?举个简单的例子,做计算机视觉的话有个方向叫图像识别,这个领域的目标就是教会计算机认识各种猫、狗、狮子、老虎和大象等等。回想一下我们小时候是怎么认识这些动物的呢,是爸爸妈妈把各式各样动物的图片拿到我们面前,然后告诉我们哪个是猫,哪个是狗。

人工智能也是一样,就是我们把成千上万张图片或者叫数据,交给计算机去看,告诉它哪个是猫,哪个是狗,不停的训练它,最后它就可以学会识别的功能。
所以我有的时候经常会感慨,做人工智能就像是带孩子一样,一开始要教它怎么识字、怎么说话,到现在要教它怎么开车、怎么做题,真的太神奇了,感觉它像一个孩子一样逐渐长大,学习更多的技能。
- 机器学习有哪些科目?
既然要学习,这个我们会对吧,我们从小到大都在上学学习,学了好多科目,语数英理化生政史地,那么让机器去学习,它都有哪些科目呢?首先人工智能是一个大方向,然后机器学习是基础,机器学习中有三个科目:有监督学习、无监督学习和强化学习。
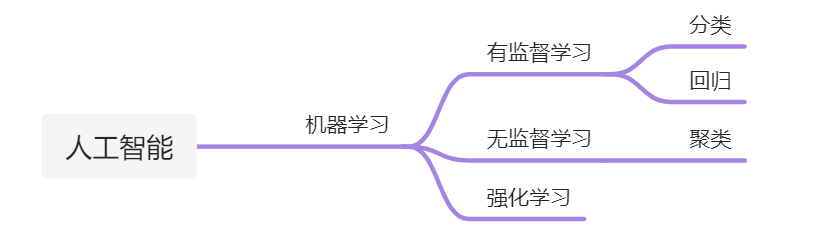
分类问题,顾名思义,就是分类问题。举个例子,人分三六九等,上智中人下愚,我之前在京东做白条的时候,其实就是要对人进行分类,看人下菜碟。那么怎么分类呢?我们来看一个最简单的例子,判断一个人是不是打游戏,打游戏就是1,不打游戏就是0,这就是分类问题。那么什么是回归问题呢?其实可以这么理解,分类问题的的值域是[0, 1],回归问题的值域是[-∞, +∞],这个不是我们今天研究的重点。
- 怎么分类?
我们分类并不是拍脑袋就直接分类了,说你打游戏,他不打游戏,而是要有特征的,比如年龄、性别之类的,我们就需要通过这些特征进行分类,比如一般年龄小的比较喜欢打游戏,然后一般男生比女生更喜欢打游戏,当然其它还有很多特征,比如使用电脑的频率啊等等。有效特征越多,分类效果越好,也就是说,你知道的越多越好。
论文思想
集成树模型
举个例子,假如我们有一堆人,然后我们要判断他们每个人是否打游戏。假如说我们只有一个年龄特征,然后我们按照常识拍脑袋认为,年龄越小越喜欢打游戏,但是多小算小呢,小于18岁还是小于20岁,这里我们常识就判断不出来了,所以这个阈值其实就是模型要学习的,它可以通过大量数据统计出来,到底是小于18岁的喜欢打游戏的多,还是小于20岁的喜欢打游戏的多。
在这里我们其实可以看到,根据某个特征进行切分可以得到一个树形结构,1个特征可以切分出来两伙人,然后我们可以在两伙人里面继续用另外的特征进行切分,然后一层一层的切分下去,最终可以形成一个树结构,这个就是决策树。
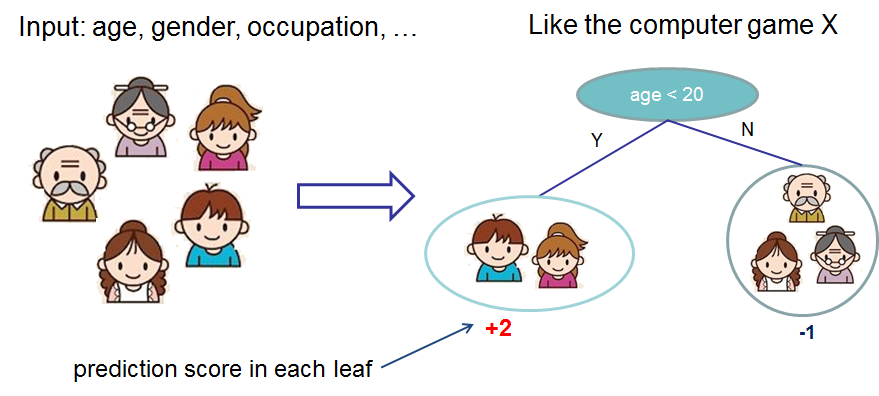
刚才是只看了年龄这一个特征对吧,但其实我们可以收集很多特征,所以并不是通过年龄一下就判断出来这个人是不是打游戏,而是通过这个特征给不同的人群打一个分数。比如,对于是不是打游戏这个问题,我们按照年龄是不是小于20岁这个特征来切分,小于20岁的,分到一个叶子节点上,+2分,大于20岁的,分到另外一个节点上,-1分。
一般来说,一棵树的效果并不是很好。假如说我们一棵树里面只用一个特征进行切分的话,那么有多少特征就需要建立多少棵树,这个其实就是集成模型,最终的分类结果就是多棵树的预测汇总在一起的结果。
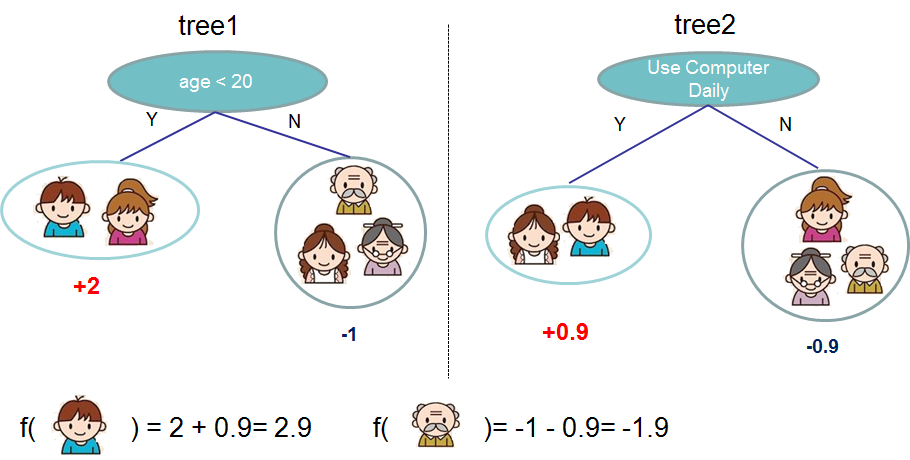
当然每棵树里面也可能不止用一个特征进行切分,还有可能切分完一次之后用另外一个特征继续切分,比如我们看下面这个例子。
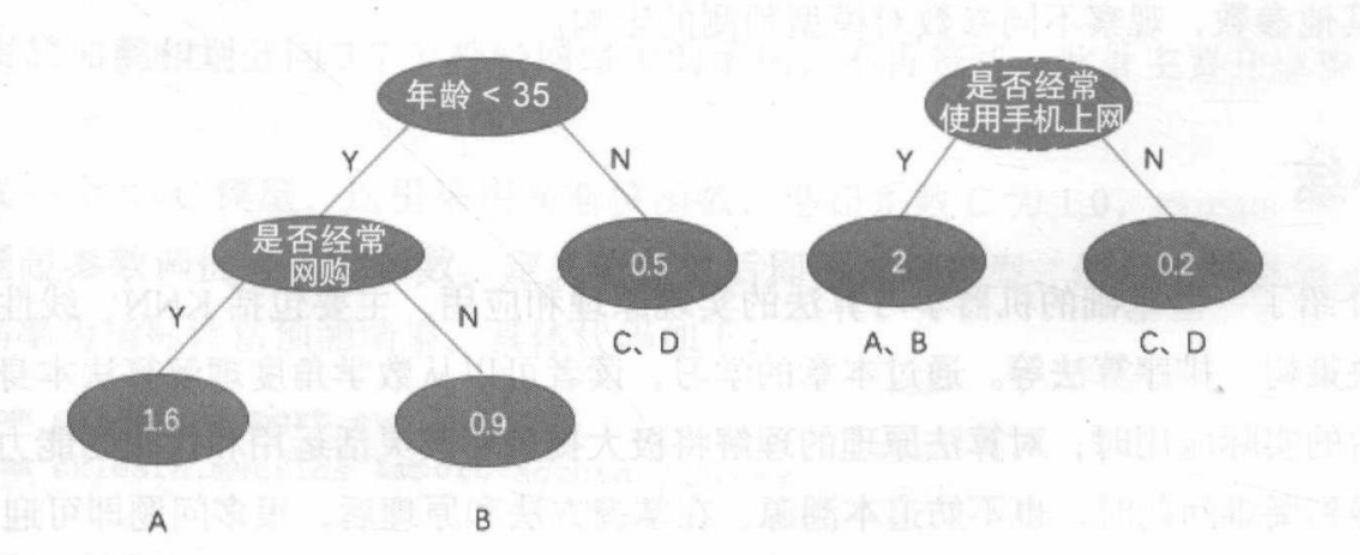
我们有A、B、C、D四个人,然后每棵树里面用的特征分别是:年龄是否小于35岁、是否经常网上购物、是否经常使用收集上网。经过这两棵树的四次判断之后,每个样本最终都会被分到一个叶子节点上,叶子节点的值就表示被分到该节点的样本的预测值。我们可以计算一下: f ( A ) = 1.6 + 2 = 3.6 f(A)=1.6+2=3.6 f(A)=1.6+2=3.6、 f ( B ) = 0.9 + 2 = 2.9 f(B)=0.9+2=2.9 f(B)=0.9+2=2.9、 f ( C ) = 0.5 + 0.2 = 0.7 f(C)=0.5+0.2=0.7 f(C)=0.5+0.2=0.7、 f ( D ) = 0.5 + 0.2 = 0.7 f(D)=0.5+0.2=0.7 f(D)=0.5+0.2=0.7。预测结果表明A、B用户比C、D用户更喜欢打游戏。
目标函数
当然现在只是一个非常简单的例子,只有两棵树集成在一起,实际上最终可能是好多棵树集成在一起。现在我们是通过图片的形式展示了一下它实现的一个主要思路,那么具体体现到实践当中要怎么做呢,我们需要把它这个思路转换成计算机能够理解的形式。
还是之前说的,计算机计算机,顾名思义他就是用来做计算的,所以我们要把这个方法转换成数学形式: y ^ i = ∑ k = 1 K f k ( x i ) , f k ∈ F \hat{y}_i = \sum_{k=1}^K f_k(x_i), f_k \in \mathcal{F} y^i=∑k=1Kfk(xi),fk∈F,其中输入是样本 i i i, K K K表示最终有多少棵树, f k f_k fk表示第k棵树的得分,然后我们把所有样本 i i i的 K K K个输出都累加起来,得到的就是 i i i的输出。
但是还有一个问题,前面我们说过,这个模型它要学习的就是每个特征的切分点,举个例子,还是年龄这个特征,到底是小于20岁的更喜欢打游戏还是小于30岁的更喜欢打游戏,这个就是模型要学习的。
那么我们怎么判断模型学习的好不好呢?或者说模型学习的目标是什么?我们说是想让这个模型根据输入人的特征判断这个人是不是喜欢打游戏,但是这是我们自己口语化的表达,模型是没有办法理解的,所以这个目标也要转换成数学形式,即目标函数: obj ( θ ) = ∑ i n l ( y i , y ^ i ) + ∑ k = 1 K ω ( f k ) \text{obj}(\theta) = \sum_i^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \omega(f_k) obj(θ)=∑inl(yi,y^i)+∑k=1Kω(fk)。
在目标函数中有那么几项:
- y i y_{i} yi:真实值
- y i ^ \hat{y_{i}} yi^: 预测值
- l l l:损失函数,用于评估模型预测值和真实值之间的误差,必须是可微分的凸函数
- ω \omega ω:正则化项,用来控制模型的复杂度,避免过拟合
最终的目标是希望目标函数值越小越好。
切分点查找
到目前为止,其实我们未知的内容只有 f k f_{k} fk,也就是我们每棵树的参数,这个参数包括两部分:① 特征切分的阈值,② 叶子节点的分值。我们先来看第一部分,切分点查找。
其实XGB的树生成步骤:
- 计算所有可能的特征及它们所有可能的切分点分裂后的平方误差;
- 从根节点开始分裂;
- 选择使平方误差最小的特征和切分点进行分裂生成两个子节点;
- 重复上述步骤,直到到达某个阈值或满足停止条件。
XGB提供了很多种切分点查找算法,我们可以来看一种最简单也是最精确的方法——精确贪心算法。
切分的目标是希望找到一个最优的阈值,也就是说,到底是年龄小于20岁打游戏的多还是年龄小于35岁打游戏的多,那么这个阈值应该怎么得到呢,一种最暴力的方法就是遍历,我把阈值从1岁遍历到100岁,那么肯定可以找到那个最优的阈值,对于特征也是,遍历所有的特征和所有的切分点,都计算出来误差,选择误差最小的那个特征和切分点即可。
这个就是精确贪心算法,它的精确就体现在要找所有的组合,这其实一个一种启发式算法。
思考:贪心体现在哪?精确贪心算法找到的特征和切分点一定是最好的么?
训练
XGB并不是一下得到所有的树,而是先建立第一棵树,可能只用到了其中一个特征或几个特征,所以效果可能并不好,然后我们再建立第二棵树,再注意,第二棵树就不是简单的再预测了,而是要修复,修复前面的树的误差,也叫拟合残差。
什么意思?我们先把前面累加形式的 y y y函数展开:
y ^ i ( 0 ) = 0 y ^ i ( 1 ) = f 1 ( x i ) = y ^ i ( 0 ) + f 1 ( x i ) y ^ i ( 2 ) = f 1 ( x i ) + f 2 ( x i ) = y ^ i ( 1 ) + f 2 ( x i ) … y ^ i ( t ) = ∑ k = 1 t f k ( x i ) = y ^ i ( t − 1 ) + f t ( x i ) \begin{split}\hat{y}_i^{(0)} &= 0\\ \hat{y}_i^{(1)} &= f_1(x_i) = \hat{y}_i^{(0)} + f_1(x_i)\\ \hat{y}_i^{(2)} &= f_1(x_i) + f_2(x_i)= \hat{y}_i^{(1)} + f_2(x_i)\\ &\dots\\ \hat{y}_i^{(t)} &= \sum_{k=1}^t f_k(x_i)= \hat{y}_i^{(t-1)} + f_t(x_i)\end{split} y^i(0)y^i(1)y^i(2)y^i(t)=0=f1(xi)=y^i(0)+f1(xi)=f1(xi)+f2(xi)=y^i(1)+f2(xi)…=k=1∑tfk(xi)=y^i(t−1)+ft(xi)
注意我们第 t t t轮建立的树,它的输出其实是第 t − 1 t-1 t−1棵树的输出: y ^ i ( t − 1 ) \hat{y}_i^{(t-1)} y^i(t−1),加上第 t t t棵树的输出: f t ( x i ) f_t(x_i) ft(xi)。那么当对第 t t t棵树进行训练的时候,再引入前面提到的目标函数,第 t t t棵树的目标函数为:
obj ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t ) ) + ∑ i = 1 t ω ( f i ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + ω ( f t ) + c o n s t a n t \begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t)}) + \sum_{i=1}^t\omega(f_i) \\ & = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \omega(f_t) + \mathrm{constant}\end{split} obj(t)=i=1∑nl(yi,y^i(t))+i=1∑tω(fi)=i=1∑nl(yi,y^i(t−1)+ft(xi))+ω(ft)+constant
注意,重点来了,XGB为了近似和简化目标函数,引入了泰勒公式。泰勒公式其实是用函数某个点的信息来描述它在附近的取值,理论上讲,如果函数曲线足够平滑,就可以通过某一点的各阶导数值构建一个多项式来近似表示函数在这个点邻域的值。
听到这,疯了,什么玩意,老子不学了。所以,简单说一下泰勒公式。
在数学中,有些函数看起来是比较友好的,比如 y = a x + b y=ax+b y=ax+b、 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c、 y = a x 3 + b x 2 + c x + d y=ax^3+bx^2+cx+d y=ax3+bx2+cx+d,这些都是多项式函数,比较友好。
为什么说比较友好呢?因为给定一个x的值,可以很快的求出y值,其它比如像三角函数,给定一个x并不能很快很精确计算出y值。
伟大的数学家泰勒就提出了一个问题,能不能用一个多项式函数近似的去拟合复杂函数?
例如我们要拟合上面这条曲线的某一点,假设这是一个路程-时间图,那么结合物理常识,如果我们要让某一点完全拟合,那么首先起点必须相等,然后速度即一阶导数也必须相等,之后加速度即二阶导数也必须相等。
我们是希望找到一个多项式函数来拟合 e x e^x ex,所以我们可以先用待定系数法。
先假设 e x = a 0 + a 1 x + a 2 x 2 + . . . e^x=a_0+a_1x+a_2x^2+... ex=a0+a1x+a2x2+...,为简单的起见,就假设三项,下面的任务就是要求出 a 0 a_0 a0、 a 1 a_1 a1、 a 2 a_2 a2。
令 f ( x ) = e x , g ( x ) = a 0 + a 1 x + a 2 x 2 f(x)=e^x,g(x)=a_0+a_1x+a_2x^2 f(x)=ex,g(x)=a0+a1x+a2x2,根据上面说的,我们要让起点、一阶导数、二阶导数都相等,根据这个条件就可以求出三个系数, a 0 = 1 a_0=1 a0=1、 a 1 = 1 a_1=1 a1=1、 a 2 = 1 2 a_2=\frac{1}{2} a2=21。
所以泰勒展开式就是将一个复杂函数在某一点的转换为多项式函数。

在XGB中,使用了二阶泰勒展开式进行近似: f ( x + Δ x ) ≅ f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ x 2 f(x+\Delta x) \cong f(x)+f^{\prime}(x) \Delta x+\frac{1}{2} f^{\prime \prime}(x) \Delta x^{2} f(x+Δx)≅f(x)+f′(x)Δx+21f′′(x)Δx2。
代入目标函数: obj ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + ω ( f t ) \text{obj}^{(t)} =\sum_{i=1}^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \omega(f_t) obj(t)=∑i=1nl(yi,y^i(t−1)+ft(xi))+ω(ft),将 y ^ i ( t − 1 ) \hat{y}_i^{(t-1)} y^i(t−1)看作是 x x x, f t ( x i ) f_t(x_i) ft(xi)看作是 Δ x \Delta x Δx,那么目标函数即可整理为:
O b j ( t ) ≅ ∑ i = 1 n [ L ( y i , y ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) \mathrm{Obj}{ }^{(t)} \cong \sum_{i=1}^{n}\left[L\left(y_{i}, \hat{y}^{(t-1)}\right)+g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\Omega\left(f_{t}\right) Obj(t)≅i=1∑n[L(yi,y^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)
其中 s i s_i si为损失函数的一阶梯度, g i g_i gi为二阶梯度:
g i = ∂ L ( y i , y ^ ( s − 1 ) ) ∂ y ^ ( s − 1 ) h i = ∂ 2 L ( y i , y ^ ( s − 1 ) ) ∂ y ^ ( s − 1 ) \begin{array}{l} g_{i}=\frac{\partial L\left(y_{i}, \hat{y}^{(s-1)}\right)}{\partial \hat{y}^{(s-1)}} \\ h_{i}=\frac{\partial^{2} L\left(y_{i}, \hat{y}^{(s-1)}\right)}{\partial \hat{y}^{(s-1)}} \end{array} gi=∂y^(s−1)∂L(yi,y^(s−1))hi=∂y^(s−1)∂2L(yi,y^(s−1))
由于常数项并不影响优化结果,因此可以进一步简化,去掉常数项:
O b j ( t ) ≅ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + constant + Ω ( f t ) \mathrm{Obj}{ }^{(t)} \cong \sum_{i=1}^{n}\left[g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\text{constant}+\Omega\left(f_{t}\right) Obj(t)≅i=1∑n[gift(xi)+21hift2(xi)]+constant+Ω(ft)
读后再问
读完论文之后也要问自己几个问题:
- 我发现了什么问题?
- 我要解决什么问题?
- 能不能借鉴论文中的方法?
- 我的问题要怎么解决?
思考题
- XGB梯度提升树的梯度体现在哪?
- XGB为什么要拟合残差?它跟随机森林有什么区别?