简介
受人类视觉注意力系统的启发,文章提出了一个叫Patchwork的模型,利用了记忆和注意力之间的微妙的相互作用来进行高效的视频处理。
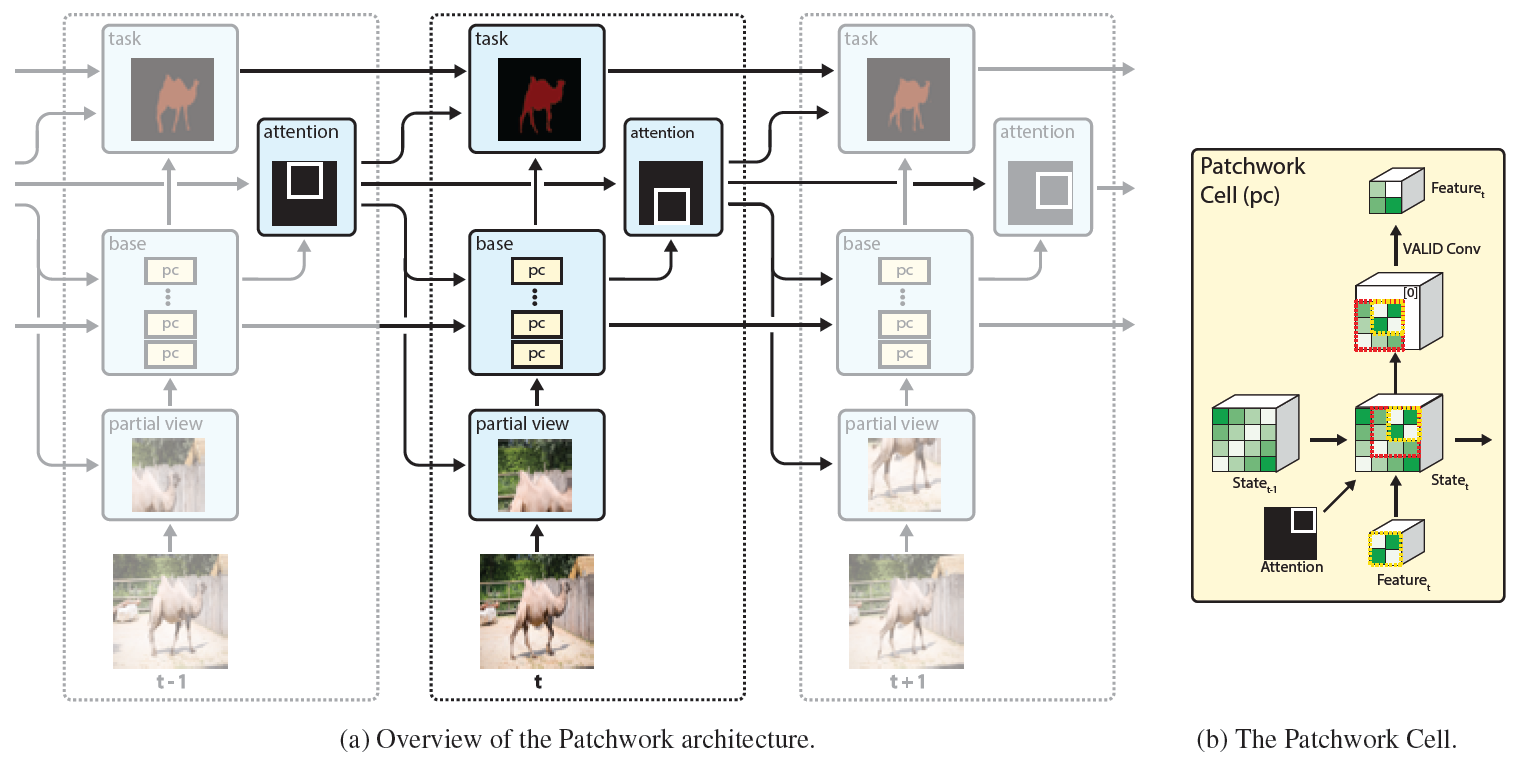
图1:a) 视频流中的每个时间步,我们的方法仅仅处理当前帧的一个小的局部窗,但由于一系列有状态的Patchwork cells,仍然能解释整张输入帧。
b) 状态patchwork cell的放大视图,通过之前状态的时间上下文特征来对当前特征进行调整。
图1a列出了Patchwork的概览。在每一个时间步,patchwork从输入帧上裁剪一个小窗送入一个特殊的特征提取网络,这个特征提取网络包含了一系列分散在网络主体中的专用记忆单元,
网络最终预测出检测结果或分割结果。此外,网络还会预测下一帧中最有可能包含有用信息的的attention window。
Patchwork的原始motivation是进行高效的视频流处理。换句话说就是在高质量地进行检测或分割任务的同时降低延迟和计算开销。在不需要考虑延迟的应用上,我们还能将节省下的资源用于提高质量。
我们在两个数据集上证明了延迟下降和质量提高,分别是ImageNet VID,对应视频目标检测任务;DAVIS,对应视频目标分割。延迟的降低受一组超参数的控制。我们解释了一些超参数的选择在实验章节。
一些选择有效地降低了延迟但是对精度造成了一些影响,另一些节省了资源并且达到了相似的精度。还有一些在相当的计算量下精度得到提高的配置。
文章的贡献有三方面:1.提出了patchwork,一个受人类视觉感知系统启发的能高效处理视频流的循环结构。2.我们的方法利用Patchwork Cell作为存储单元,随时间传输环境信息。3.注意力模型可以预测下一帧中的要关注的最佳位置。
我们的方法通过使用了独特的目标检测和分割reward函数的Q-learning来训练。
Patchwork
如图1a中所示,patchwork结构是一个循环结构,对当前帧的预测可能会依耐于之前的所有帧。在每一个时间步,输入帧要经过四个步骤:裁剪小窗,特征提取,特定任务的预测,下一帧的attention预测。
在裁剪过程中,需要从当前帧上裁剪一个固定大小的窗,裁剪框的位置由之前帧预测。我们之所以选择固定窗的大小是考虑到计算开销同窗大小直接相关。在特征提取的stage,我们使用了mobileNetV2.我们
将其中含有大于1x1卷积核的卷积层都做了替换,换成了我们的状态patchwork单元。最后,attention和结果预测基于适当的层上面。
patchwork有两个意思。第一个是,它是PATCH-wise attention netWORK的混用词。此外,patchwork也是一个英语单词,表示将多块织物缝合在一起形成一个更大的设计,这类似推理过程中的每个patchwork单元。
recurrent attention
图1a展示了recurrent attention网络的大概结构。在之前的文章中,注意力窗使用它的中心和大小进行参数化。训练中,在边界上使用有梯度的光滑关注窗,因此可以以有监督的方式来进行端到端的训练;此外,利用好
策略梯度进行强化学习。注意,这些先前工作中的实验仅限于MNIST和Cifar等数据集,这解释了为什么我们在复杂的真实场景的目标检测和分割任务中使用这两种方法只取得了有限的成功。我们最好的结果来源于离散动作空间
的Q-learning方法。
这个离散动作空间包含了所有可能的attention局部窗,由两个整数M和N来参数化。M表示一个维度被均分的份数,即将原图均分为M x M块,每一块的长宽是[w/M,h/M];N表示构成一个attention窗的连续块数的个数,一个attention窗
由N x N个小块组成(个人感觉这个地方原文表述不太清楚)。我们的实验中包含了下面三种配置。M=2,N=1,则有4个可能的窗,每个相对原图的大小为[1/2,1/2]。将这些窗用左上角开始编号,[i/2,j/2],i=0,1;j=0,1.M=4,N=2有9个可能的窗,每个相对原图大小为[1/2,1/2]。将这些窗用左上角开始编号,[i/4,j/4],i=0,1,2;j=0,1,2。M=4,N=1有16个可能的窗,每个相对大小为[1/4,1/4],,用左上角编号,[i/4,j/4],i=0,1,2,3;j=0,1,2,3。
注意M和N控制了计算推理的计算量。举个例子,M=2,M=1的配置将每个attention窗的大小控制为原图的25%,总的计算量也粗略地降为原来的25%。
接下来,我们构建了attention网络,从时间t的网络中得到一系列特征并将它们映射到用于deep Q-learning(DQN)的的Q值\(Q(S_t,A_t;\Theta)\).