Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
swin:shifted window
因为之前的ViT已经将transformer用于图像分类。本文的研究动机是使transformer兼容所有视觉领域的下游任务,包括检测、分割、视频等等。
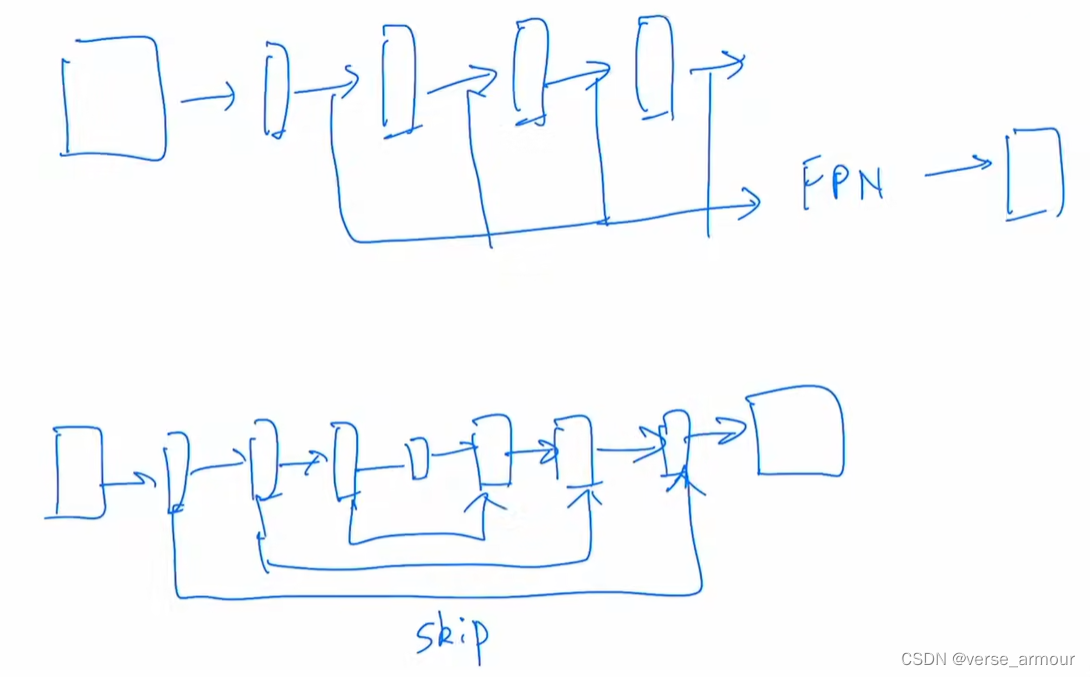
对于检测、分割这类密集预测类任务(dense prediction tasks),需要多级的特征提取。抓住物体不同尺度的特征,从而处理物体不同尺寸的问题。在以卷积网络为主干网络的模型中,检测中有FPN结构来提取不同尺寸的特征,分割中U-Net有Skip connection来提取不同尺寸的特征。此外,分割还有PspNet和DeepLab。(这些方法通过空洞卷积、psp、aspp层处理多尺寸的问题)
- 分级结构

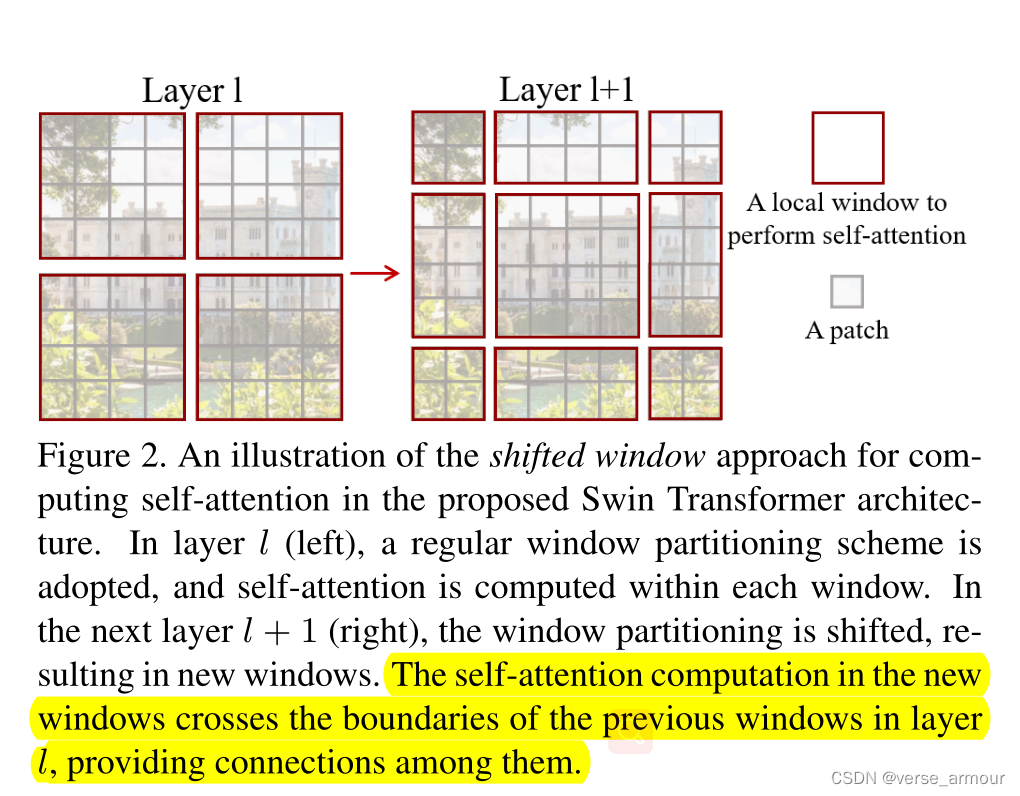
- 窗口移位
shift of the window partition between consecutive self-attention layers
连续自注意力层之间窗口分区的移位。
| ViT | Swin Transfomer |
|---|---|
| 图片中不同物体的尺寸差异。transformer在处理语言序列时,基本元素是一个个的单词,长度差异不会很大。而在处理图像时,一张图片中可能有一辆车和一个行人,行人的尺寸非常小,而车的尺寸非常大,如果只是下采样16倍会一定程度上损失其他尺寸的特征信息,不利于最终对不同尺寸物体的预测。 | 提出patch merging操作,相邻的两个小patch合成一个大patch。一个大patch就能看到之前4个小patch看到的内容。重复的patch emerging操作就形成了Hierarchical多级结构(相当于借鉴了卷积神经网络中利用pooling层增大感受野,每次池化后的特征抓住了物体不同尺度的特征) |
| 对整图进行全局自注意力操作,计算复杂度与图像尺寸的平方成正相关。但对于视觉任务来说,有点浪费资源,因为图像信息不同于语言信息,具有很多先验知识,比如局部性和平移等变性等等。 | 将整图划分成很多小窗口,在小窗口之内算自注意力,只要窗口的大小是固定的,计算自注意力的复杂度就是固定的。整张图的计算复杂度和窗口数量成线性关系。比如图片增大X倍,窗口数量增大X倍,自注意力计算复杂度增大X倍(相当于借鉴了卷积神经网络中局部性的先验知识:同一物体的不同部位,语义相近的不同物体大概率会出现在相连的地方) |
Method
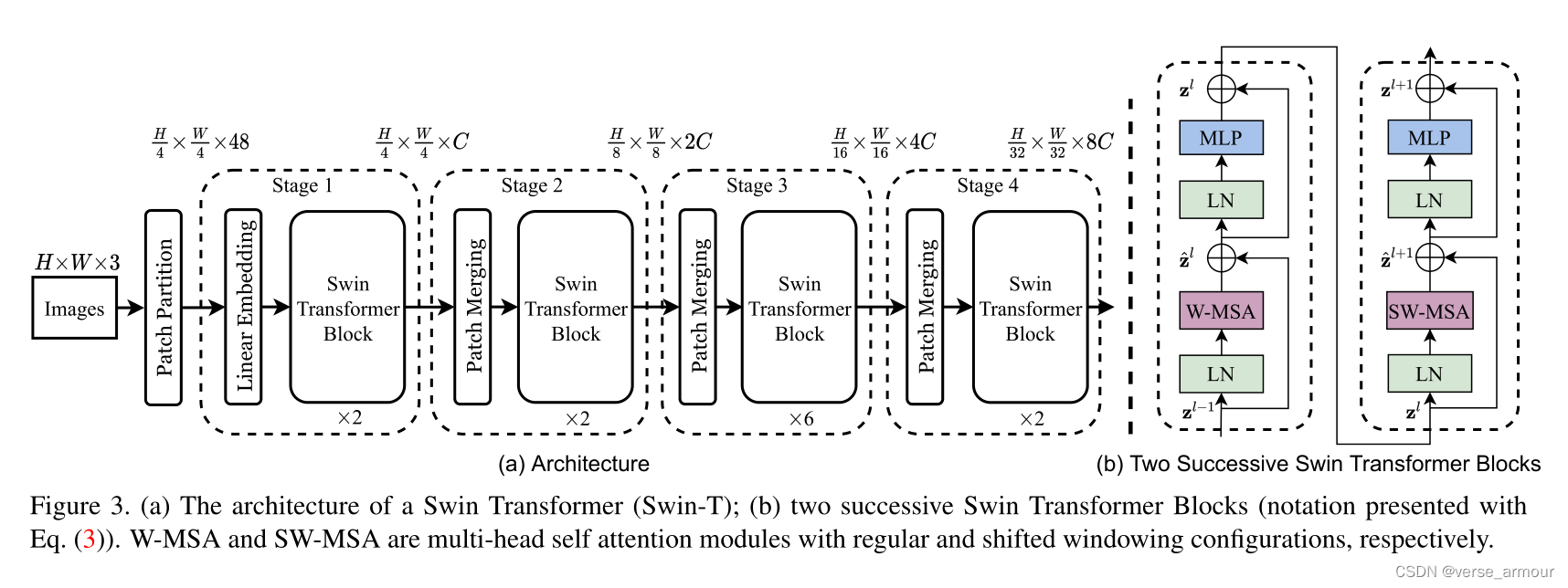
技术细节
