因为有很多事情耽搁了,今天终于完成了Transformer的完整学习,接下来,将分为三篇文章来进行记录:
1. Transformer介绍
Transformer问世至今已经有不短的时间了,促使我看Transformer是因为谷歌的BERT,BERT在前阵子可谓是NLP界无人不知无人不晓,但是用来实现BERT的基础模型Transformer我却知之甚少,所以,我立下决心,不理解好Transformer不回头。
由于网络上已经有很多有关Transformer的介绍以及对《Attention is all you need》的解读,所以我也不再进行一些重复的工作,这篇文章更多是我个人的一些记录而已。
一. 什么是Transformer?
Transformer是谷歌在2017年发布的一个用来替代RNN和CNN的新的网络结构,Transformer本质上就是一个Attention结构,它能够直接获取全局的信息,而不像RNN需要逐步递归才能获得全局信息,也不像CNN只能获取局部信息,并且其能够进行并行运算,要比RNN快上很多倍。
二. Transformer的结构
下面贴出Transformer的模型图。
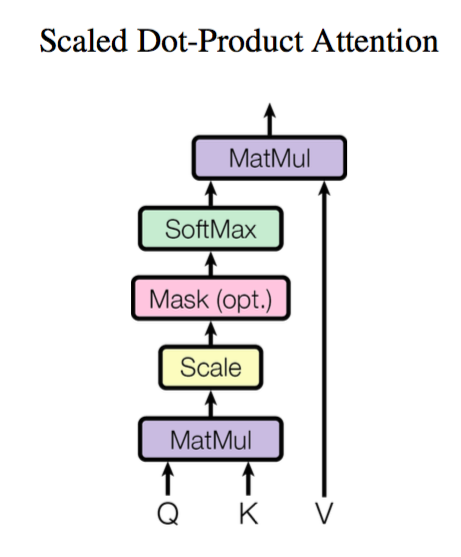
可以看出,这个模型非常简单,模型的公式如下:
但是,表面看起来这么简单,其实并不然,看似好像只需要将Q,K,V进行一些基本数学运算就ok了,但其实,中间省略了两部分结构,一个是传播用的全连接层,一个是用于mask的mask层。
当然,除去没有表现出来的这两部分,模型确实就是这么简单,需要注意的另一点是,Q来自于query,而,K,V是来自与同一个矩阵的。这个Attention层的目的是,先计算Q与K的相关度,然后根据计算Q与K的相关度矩阵后,再使用这个相关度矩阵与V相乘,得出最终结果。而其中,K和V来自于同一个矩阵(但是是通过不同的全连接层计算得来的),那么Q,K计算的目的就是为了计算出Q应该关注V中的哪些值,关注度达到多少。
接下来,我们介绍本篇论文另一个重要的结构:multi-head Attention。
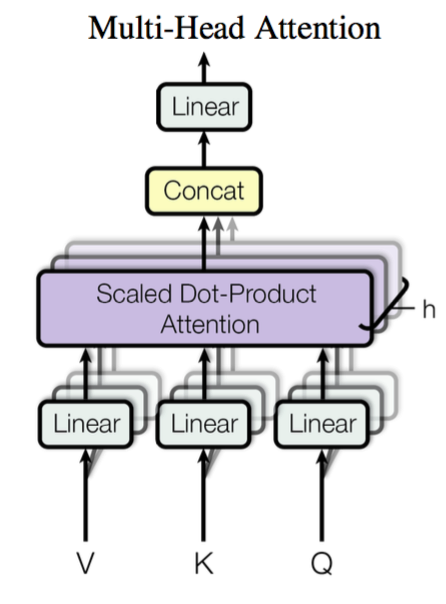
这里的multi-head的含义是,每个Transformer结构会有多层结构完全一样的,但权重矩阵不同的Attention组成,也就是我们上面提到的Attention结构。这么做的目的是为了防止模型只关注到模型的一部分特征,却忽略了其他特征,所以增加模型的厚度,让模型拥有多层结构相同,但是权重不同的Attention,每一个head都关注到了不同的特征,那么模型整体就会关注到更多的特征。
三. Transformer的特性
Transformer相较于RNN的最大优势在于其速度上的优势,相较于CNN,其能直接获取全局信息。
在论文的介绍中,Transformer在当时的机器翻译WMT2014英德翻译任务中获得了最好的结果,所以其无论是速度,还是性能都是当时最好的。
四. 参考
1.苏剑林大佬的博客:https://kexue.fm/archives/4765,这篇讲得比我好多了,苏大佬最后还有代码实现,感兴趣的可以看一下。
2. 当然,还是要贴一下google的论文的:《Attention is all you need》