前言
最近被安排带几个学生搞基于预训练模型的文本生成课题,想给他们准备点学习资料,找的是沐神在B站的论文精读,于是自己先看了一遍,对视频质量把把关(事实证明根本不用把关,并感慨自己读研时为啥没有遇到这么nice的视频),顺便借此机会重温一下这几篇经典 paper。
Transformer
Attention is all you need.
论文地址:https://arxiv.org/pdf/1706.03762.pdf
视频地址:https://www.bilibili.com/video/BV1pu411o7BE
-
Google Brain 针对机器翻译而提出的,是首个只依赖self-attention机制的encoder-decoder架构模型
-
模型结构总览:编码器 encoder 将输入的n个词 ( x 1 , . . . , x n ) (x_1, ... , x_n) (x1,...,xn) 映射成 n 个向量 z = ( z 1 , . . . , z n ) z=(z_1, ... , z_n) z=(z1,...,zn);解码器 decoder 拿到编码器的输出 z z z,生成长为 m 个词的序列 ( y 1 , . . . , y m ) (y_1, ... , y_m) (y1,...,ym)。生成过程 t 时刻会用到前 t-1 时刻的所有输出,即自回归。
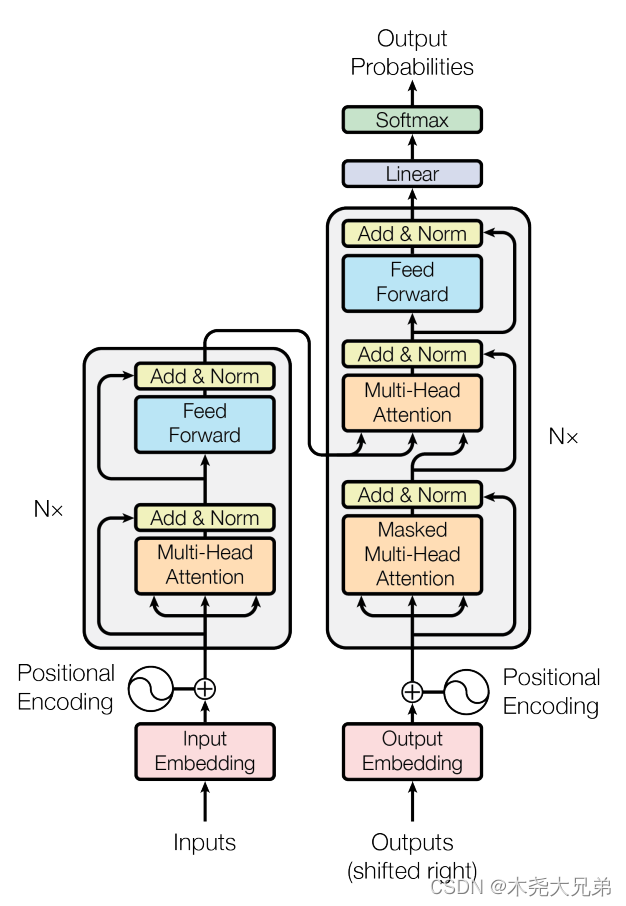
- 公用知识:
- BN和LN。以二维输入为例,batch norm是指:训练时把一个mini batch里的 “每一列” 即每个特征变成均值为0方差为1,预测时把全部测试集的每个特征做同样操作存起来;layer norm是指:对 “每一行” 即每个样本变成均值为0方差为1。本文用的三维输入 (batch * seq_len * embed_dim) 的 layer norm,原理跟二维一样,也是对样本做变换,比用batch norm稳定。
- Scaled Dot-Product Attention。相当于给各个输入向量做了加权求和,是最简单的attention形式,输入是 Value 向量 v v v(维度为 d v d_v dv),乘上通过计算 Query 向量 q q q 和 Key 向量 k k k(维度均为 d k d_k dk)相似度(内积,相当于cos)得来的权重,得到跟 Value 向量 v v v 一样维度的输出。下面是多个 q ( n 个 ) , k ( m 个 ) , v ( m 个 ) q(n个), k(m个), v(m个) q(n个),k(m个),v(m个) 分别拼成 Q ( n ∗ d k ) , K ( m ∗ d k ) , V ( m ∗ d v ) Q(n*d_k),K(m*d_k),V(m*d_v) Q(n∗dk),K(m∗dk),V(m∗dv) 便于并行计算,对每个独立的行结果做 softmax 得到 n 个权重。所谓 “Scaled” 就是除以 d k \sqrt{d_k} dk,是因为 d k = 512 d_k=512 dk=512 比较大的情况下,不除的话 softmax 结果可能会全是靠近0/1,导致梯度很小,训不起来。

- Multi-Head Attention:下面右图。通过 h = 8 h=8 h=8 次投影,创造了些可学习的参数矩阵,有点像CNN的多个channel,学习 h 个不同的距离空间,可能对不同任务有所偏依。具体用 Attention 时,上面图里 m 和 n 相等,且 d k = d v = d m o d e l / h = 512 / 8 = 64 d_k = d_v = d_{model}/h = 512/8 = 64 dk=dv=dmodel/h=512/8=64;三个地方用到注意力机制:
- encoder、decoder下面mask attention都是自注意力,因此 Q = K = V Q=K=V Q=K=V,可见最上面那个模型图的三分叉(从左到右分别是key、value、query);
- decoder上面那个中,key和value是encoder的输出(n个512维的向量),而query是decoder里下面那个masked attention的输入(已生成的m个512维的向量),如翻译任务输入hello world,decoder 输入单词 “你好” 的时间步中,hello对应的hidden state权重会大。
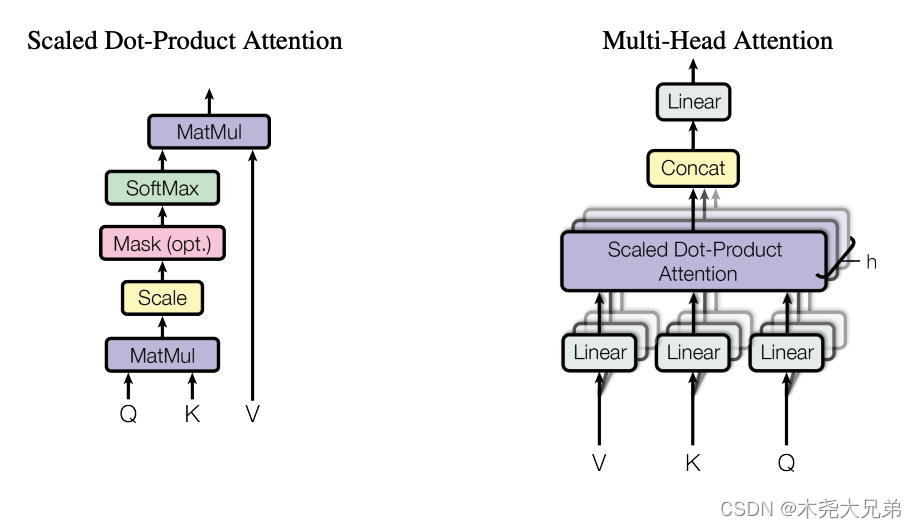
- Feed Forward:是个MLP,同样的MLP对输入的每个词单独作用一次。 F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2,其中 m a x max max是relu激活函数,输入 x x x 是 d m o d e l = 512 d_{model}=512 dmodel=512 维的词嵌入, W 1 W_1 W1 把 x x x 投影到4倍即 d f f = 2048 d_{ff}=2048 dff=2048, W 2 W_2 W2 又给投影回了 512,因为后面有残差连接,所以输入输出维度保持了一致。
- Embeddings:不管是编码器还是解码器,输入的token都转成embedding,这里对embedding乘以了 d m o d e l \sqrt{d_{model}} dmodel,原因是维度大,L2 norm的权重变小,乘的目的是为了时词嵌入跟位置嵌入的scale差不多(位置嵌入是三角函数值在-1到+1之间)。
- Positional Encoding:把token的位置 p o s pos pos(0,1,…)表示成 d m o d e l = 512 d_{model}=512 dmodel=512 维的向量, i i i 是第几维:
- P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
- P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
- 公用知识:
-
编码器:层数 N=6,也就是 6 个 block,每个block有2个子层,每个子层输出都可以表示为 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x)),只不过Sublayer(x)分别是多头自注意力和MLP。为了方便残差计算,就把每个层的输出都设置成了 d m o d e l = 512 d_{model} = 512 dmodel=512。
-
解码器:层数也是6,不过每个block有3个子层,上面第2、3子层跟encoder一样,第1 个子层用了个 Masked Multi-Head Attention,使得训练decoder时 t 时刻的 q t q_t qt 只能看到左边序列 y 1 , . . . , y t − 1 y_1, ...,y_{t-1} y1,...,yt−1 的信息 k 1 , . . . , k t − 1 k_1, ... , k_{t-1} k1,...,kt−1,不能看到 k t k_t kt及之后的信息,让训练和预测时行为一致。具体MASK做法是把 k t k_t kt 及之后的值换成贼大的负数如 − 1 × e 10 -1\times e^{10} −1×e10,这样softmax算出的权重结果就成0了。
-
实验:在WMT 2014 英译德数据(450w句对儿)训练模型,用BPE切词(词根词缀)成 37000 个 tokens 的英德token在一起词典;在WMT 2014 英译法数据(3600w句子)训练模型,用BPE切词成 32000 个 tokens 的英法token在一起词典;每个batch的句子们大概一共包括 25000 个source tokens和25000个target tokens。用了8块P100训练,base模型训了12小时共10w个steps,large模型训了3.5天共30w个steps。
-
优化器: Adam( β 1 = 0.9 , β 2 = 0.98 , ϵ = 1 0 − 9 \beta_1=0.9, \beta_2=0.98, \epsilon=10^{-9} β1=0.9,β2=0.98,ϵ=10−9)
-
动态学习率: l r = d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) = 1 / 512 × m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ 400 0 − 1.5 ) lr=d_{model}^{-0.5} · min(step\_num^{-0.5}, step\_num · warmup\_steps^{-1.5}) = 1/\sqrt{512}\times min(step\_num^{-0.5}, step\_num · 4000^{-1.5}) lr=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)=1/512×min(step_num−0.5,step_num⋅4000−1.5) 。
-
三个正则化:
- 两个地方用到 Residual Dropout:在进入【Add & Norm】层之前、【token embed+pos embed】层之后,均加了个 P d r o p = 0.1 P_{drop}=0.1 Pdrop=0.1 ,即10%的输出置0。
- Label Smoothing:用 softmax 学 label 正确是1错误是0,即正确值逼近1,但softmax输出难以逼近于1,于是让这个值逼近0.1即可( ϵ l s = 0.1 \epsilon_{ls}=0.1 ϵls=0.1),即预测正确的话softmax输出逼近0.1就OK。这么搞会增加模型不确信读增加,但能提升 accuracy 和 BLEU。
BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:https://arxiv.org/abs/1810.04805
视频地址:https://www.bilibili.com/video/BV1PL411M7eQ
- Google AI 提出的第一个基于 finetune 的双向预训练语言模型,使用双向的 MLM(完形填空)而非单向的 LM(预测未来)。前人工作有两个,一个是ELMo,基于RNN词嵌入,太老;另一个是 GPT,但只能处理双向信息。
- 模型为 pre-training + fine-tuning 框架。BERT-base(L=12层,H=768维,A=12头,参数量110M,即一亿),和GPT量级差不多;BERT-large层数翻 2 倍,又因为模型复杂度和层数是线性关系,和宽度(维度)是平方关系,所以宽度增加的平方即 102 4 2 1024^2 10242 大约是 base 宽度 76 8 2 768^2 7682 的 2 倍,而每个head的维度保持64不变(768/12=64),所以A设置为16(1024/16=64),最终large模型配置为(L=24,H=1024,A=16,参数量340M,即3.4亿)。参数量计算方法: 30 k ∗ H + L ∗ H 2 ∗ 12 30k * H + L * H^2 * 12 30k∗H+L∗H2∗12,详见视频 23:12,其中:
- 最下面 30 k ∗ H 30k*H 30k∗H 是词表大小乘以每个词隐藏层维度
- 在一个Transformer block里,中间对多头注意力机制的 Q、K、V、attention输出的四个投影矩阵的参数总量为 H ∗ H ∗ 4 = H 2 ∗ 4 H * H * 4 = H^2*4 H∗H∗4=H2∗4
- 在一个Transformer block里,最后两个全连接层,一个输入是H,输出是4H;第二个输入是4H,输出是H,因此参数总量是 H ∗ 4 H + 4 H ∗ H = H 2 ∗ 8 H*4H + 4H*H = H^2*8 H∗4H+4H∗H=H2∗8
- 因此BERT 总参数量为 30 k ∗ H + L ∗ H 2 ∗ 12 30k * H + L * H^2 * 12 30k∗H+L∗H2∗12
- 代入计算:bert-base参数量为 30000 ∗ 768 + 12 ∗ 76 8 2 ∗ 12 = 107 , 974 , 656 ≈ 1.1 亿 30000*768 + 12*768^2*12=107,974,656 ≈ 1.1亿 30000∗768+12∗7682∗12=107,974,656≈1.1亿,bert-large参数量为 30000 ∗ 1024 + 24 ∗ 102 4 2 ∗ 12 = 332 , 709 , 888 ≈ 3.4 亿 30000*1024 + 24*1024^2*12=332,709,888≈3.4亿 30000∗1024+24∗10242∗12=332,709,888≈3.4亿
- 模型输入使用 WordPiece 把单词切成 piece,有点像BPE,主要切成词根词缀,这样能使词表不会太巨大。输入序列的第一个token永远是 [ C L S ] [CLS] [CLS];对于区分两个句子,有两种方法,一是在每个句子结尾加 [ S E P ] [SEP] [SEP],二是学习一个 segment embedding 区分句子A和句子B(输入是2,即A还是B,输出是768,以方便跟token embedding和position embedding加起来输入到Transformer block中)。position embedding输入是序列长度上限如512,输出是768,不像Transformer是sincos定义的,bert的位置嵌入是模型学出来的。

- 预训练阶段,通过MLM和NSP两个任务,基于BookCorpus(800M,即8亿词)和Wikipedia(2500M,即25亿词)
- 微调阶段,在 [ C L S ] [CLS] [CLS]的最后一层hidden state后面加个输出层,拿TPU跑1h或者GPU跑几个小时就搞定
- 实验在GLUE、SQuAD、SWAG分别做分类、问答、句子推理等问题,且证明了直接拿bert静态向量做下游任务不如 finetune 效果好。
GPT / GPT2 / GPT3
视频地址:https://www.bilibili.com/video/BV1AF411b7xQ
GPT-1: Improving Language Understanding by Generative Pre-Training
-
GPT 是 OpenAI 搞的一个基于 Transformer Decoder 的预训练语言模型。
-
训练分两个阶段:一是用半监督学习(自监督)训练无标注的大规模数据;二是使用有监督下游任务数据进行微调
-
目标函数 L 3 L_3 L3 包含两部分:一是给出前面序列,预测下一个词( L 1 L_1 L1);二是给出完整序列,预测序列的标注结果( L 2 L_2 L2)。下面公式中, U = { u 1 , . . . , u n } U=\{u_1,...,u_n\} U={ u1,...,un} 是一条无监督语料的token序列; C = { x 1 , . . . , x m , y } C = \{x^1,...,x^m,y\} C={ x1,...,xm,y} 是有监督的标注数据,y是标签。权重 λ \lambda λ 是学出来的。
- L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(U)=\sum\limits_i logP(u_i|u_{i-k},...,u_{i-1};\Theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;Θ)
- L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , . . . , x m ) L_2(C)=\sum\limits_{(x,y)} logP(y|x^1,...,x^m) L2(C)=(x,y)∑logP(y∣x1,...,xm)
- L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(C)=L_2(C)+\lambda * L_1(C) L3(C)=L2(C)+λ∗L1(C)
-
对于不同下游任务,构造不同的输入,其中 “Extract” 对应的 token 作为输入的 hidden state 送入 Linear 层做预测。
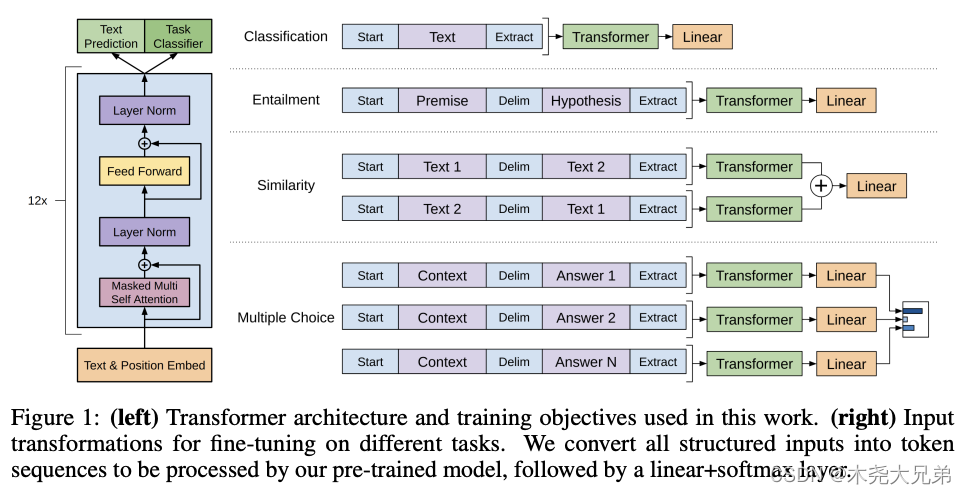
-
模型在 BooksCorpus 数据集(7000本未发表的书,800M即 8亿单词)上预训练
-
模型结构:12层decoder,每层维度768,12个注意力头(L=12,H=768,A=12 这不就是BERT base的配置嘛!)
GPT-2: Language Models are Unsupervised Multitask Learners
-
GPT-1 被 BERT 用差不多的配置(层数,维度等)+ 更大的数据集(BooksCorpus+Wikipedia)打败,GPT-2算是一个回应
-
搞了个百万级文本的 WebText 数据集,训了最大 1.5B(15亿)参数量的模型,这是不同大小的模型配置:

-
ZeroShot:下游任务直接做,不微调模型。这就要求训练时的文本要包含 prompt,比如翻译训练集可以是(translate to
french, english text, french text),MRC数据集可以是(answer the question, document,
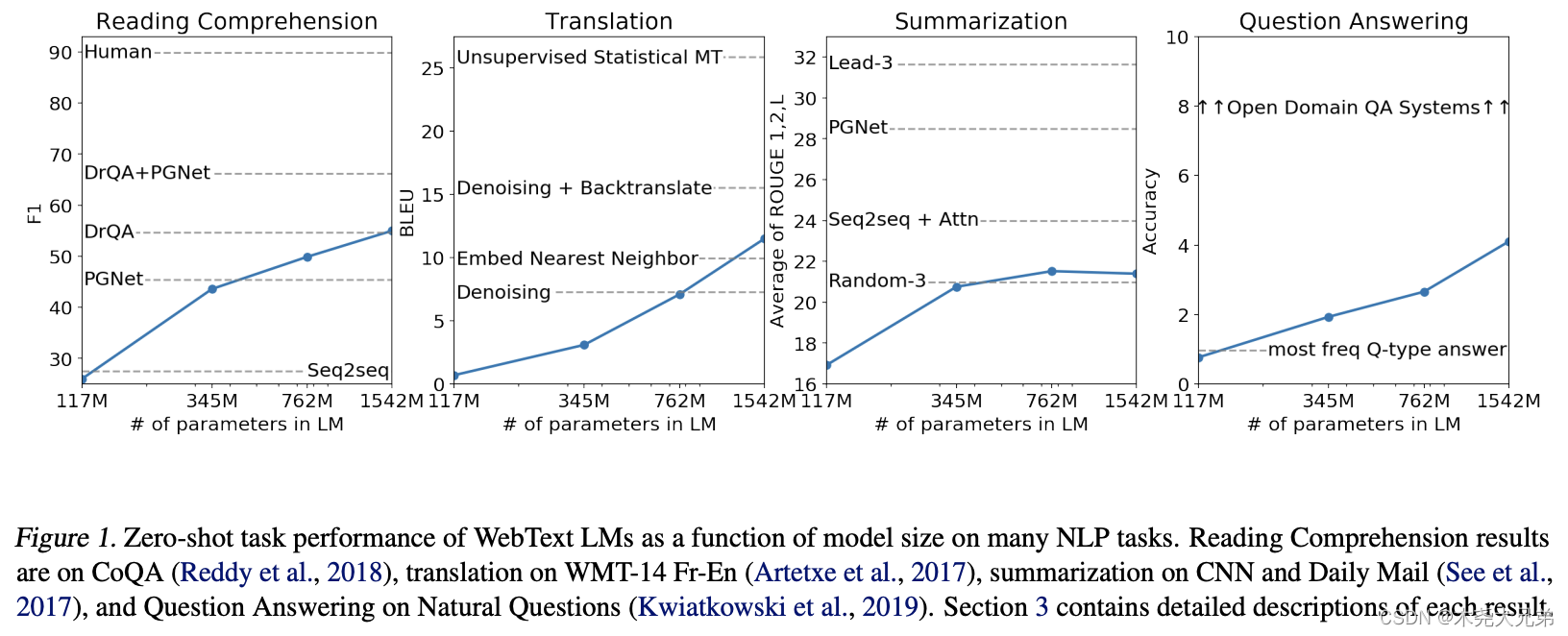
question, answer)。以下是不同大小的GPT2在各个任务上的得分,可以看到随着模型规模增大,性能也在上升,为后面大力出奇迹埋下伏笔。
GPT-3: Language Models are Few-Shot Learners
- 不再追求不给任何样例做 Zero-Shot,而是给出一些小样本做 Few-Shot,也就是只通过少量样本提供的信息去预测测试集的标签,而不去 finetune 更新模型权重(下图是finetune、zero-shot、one-shot、few-shot的区别)

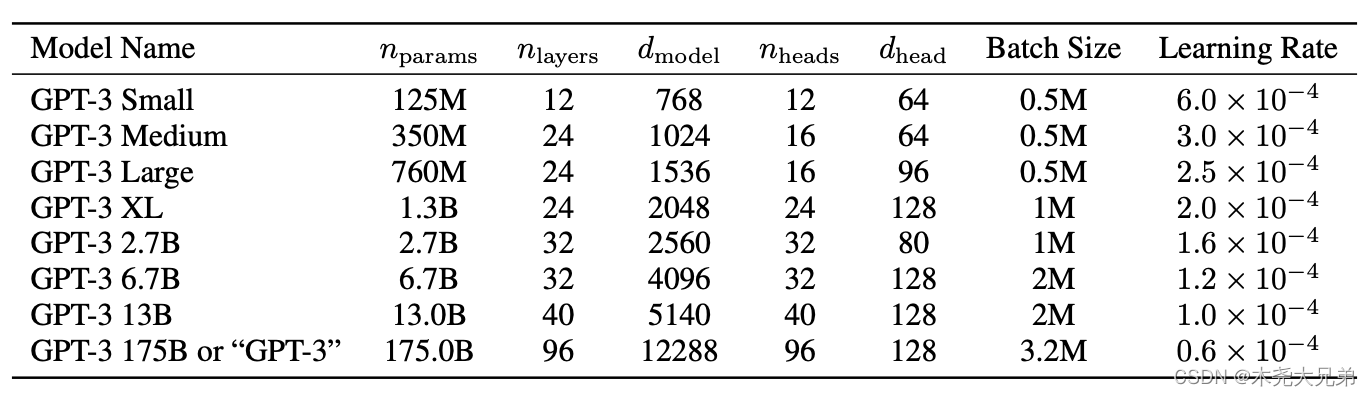
- 使用DGX-1集群(V100的卡)分布式训练了最大 175B(1750亿)参数的模型,配置如下:
- 数据集规模也是巨大,且每个batch 按表格中的比例进行采样(因为Common Crawl里脏数据多一些,所以并没有完全用全量采样)
