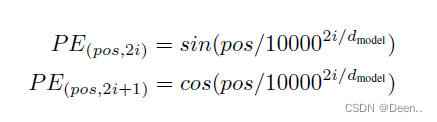导读
个人学习笔记
论文地址:Attention Is All You Need
参考视频:Transformer论文逐段精读
区别于常见的CNN、RNN体系,Transformer是一个完全依赖注意力机制的模型,它在这篇论文里首次被提出,作为完全区别于RNN时序循环神经网络的存在,完成对时序数据的处理。后续不同涌出以Transform思想为基础的一些列工作,扩展到了各个领域。
这篇文章假设以中英文翻译为目的,将一串英文翻译成中文,进一步来解读。、
摘要

摘要部分首先点到现存主要的序列转换模型都是基于RNN或者CNN网络,表现最好的模型也是用了注意力机制。所以该团队直接提出一个完全基于注意力机制的模型。【Transformer】,然后讲述这个模型在德语翻英语数据集上的表现。
背景介绍
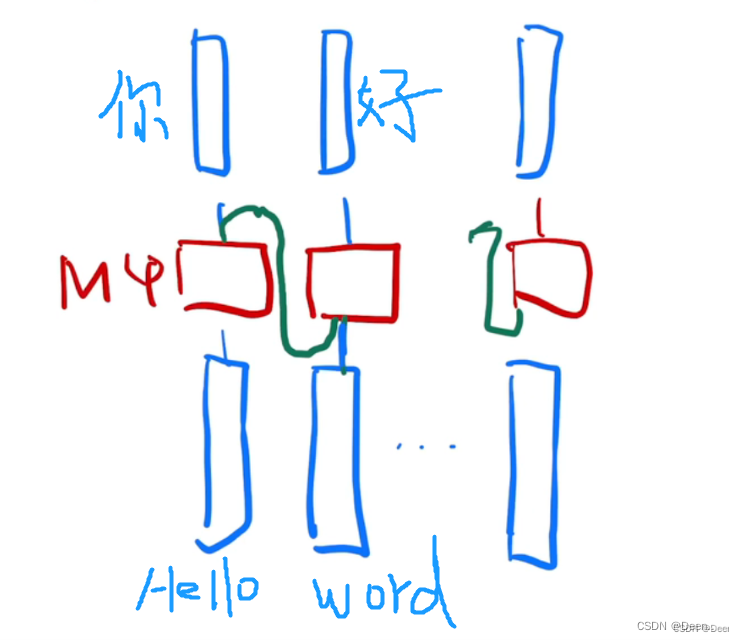
背景介绍里主要讲了一下RNN怎么去做序列转换这个工作,拿李沐老师的图解释一下:
假设做中英文翻译,下图是可以看成是RNN模型做翻译的一个流程:
红色部分是因子计算,下面蓝色方块为英文序列信息,第一个方块里存的 H e l l o Hello Hello,它通过因子计算后输出你,然后将输出作为下一次因子计算的输入,与第二时刻的序列信息 W o r d Word Word一起输入到模型中。这种方法无法实现并行工作,下一步的生成受限与上一步的结果。
而Transformer可以实现并行工作,是第一个完全依赖于自注意力机制的模型
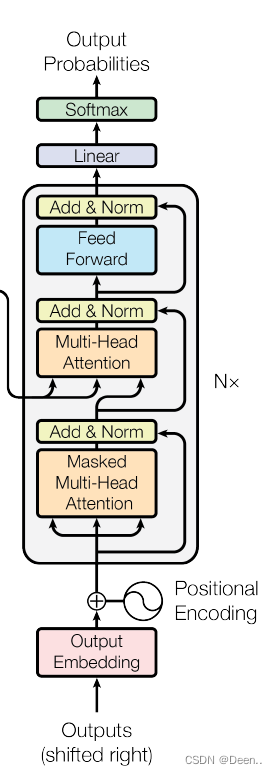
模型介绍
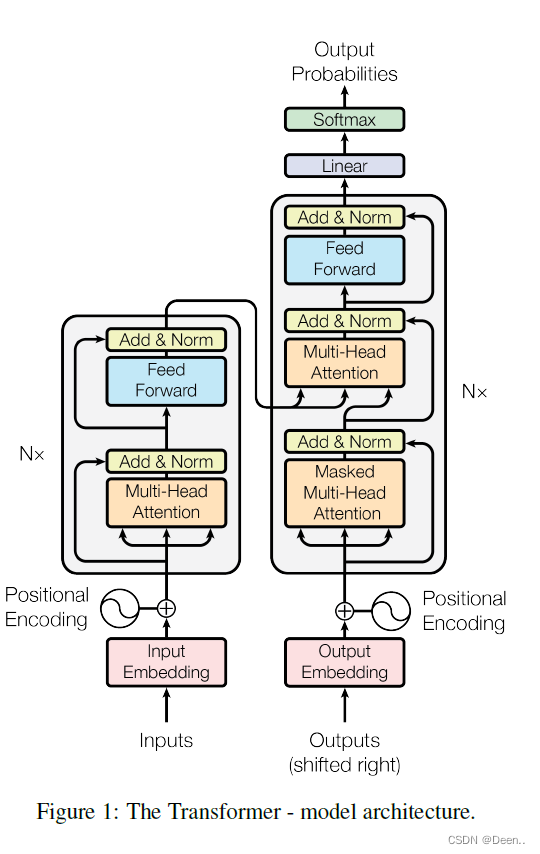
这张图现在来看是一张很经典的模型示意图,简介简单。
先按着图过一下数据处理流程:
-
输入的英文时序数据,比如输入【Hello World nice to meet you】一共有6个单词,
-
这6个单词可以看成6个query,也就是6个序列信息,然后将序列信息进行编码,文章编码长度为512,也就是每个单词用512位的编码来表示,Hello变成512位的数据了,这时候数据为[6,512]。
-
然后进行位置编码Positional Encoding,因为Transformer可以并行输出,就是一次性解读到全局信息,这时候少了时序的信息,也就是单词的前后位置,比如world在Hello后面,这时候用位置编码,来告诉模型Hello在第一个位置,World在第二个位置。
-
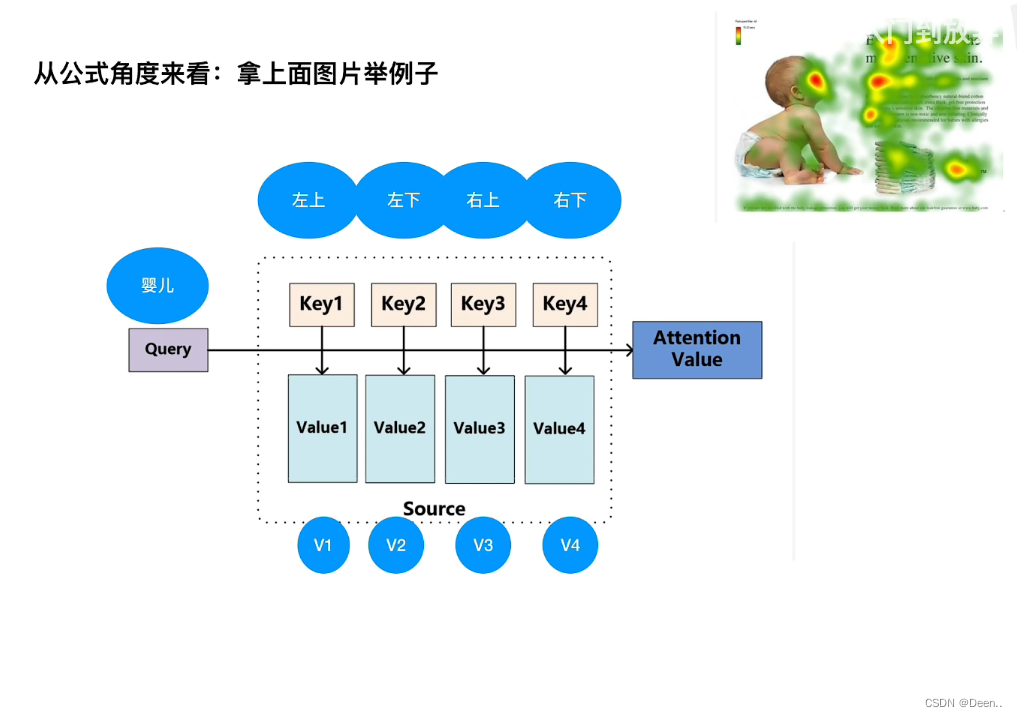
然后进入一个编码器,编码器具体为,将编码跟加位置信息后的Hello这个序列信息,复制成三份,进行多头注意力机制后进行残差运输,然后进一步的向前传播,再进行一个残存跟layer Norm(层归一化)。这一个编码器可以取N个模块,文章里取了8个。:
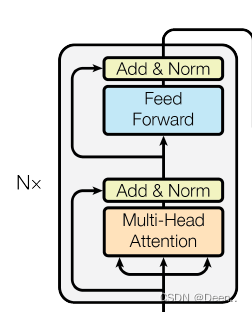
-
编码器输出的内容,传到解码器,编码器的内容传出了是固定的两组数,解码器最下面的(shifted right)滑动这一块只有在训练的时候才启用,训练的时候,一个英文字母翻译完了,滑动到下一个英文字母,作为输入,然后进行Masked多头注意力机制,最后再与解码器的内容进行一个计算,最后先前传播,输出一个结果。这里的Masked Multi-Head 多头注意力机制主要作用就是遮挡住还没训练的单词后面的单词,比如数据是【Hello World nice to meet you】,标注为【你好世界很高兴见到你】,当训练序列滑动到nice的时候,训练的数据是【Hello World nice 0 0 0】翻译结果应该对应到【你好世界很高兴0 0 0 】这个Masked就是挡住还没生成的后面的序列信息。:
这里把Mask的操作提一下:训练的时候用,将序列qt的第t个数变成很大的负数,这样子softmax后,t位置后面的值就变成0了。
单注意力机制
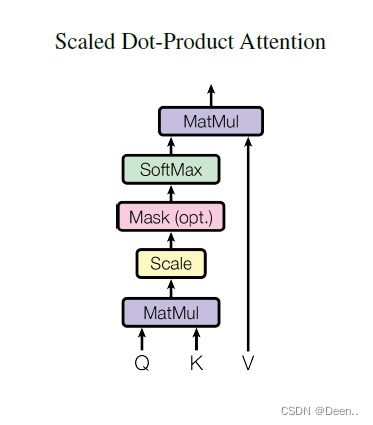
下图显示的是单个的注意力机制计算流程,Q与K进行点积,然后乘V得到输出。
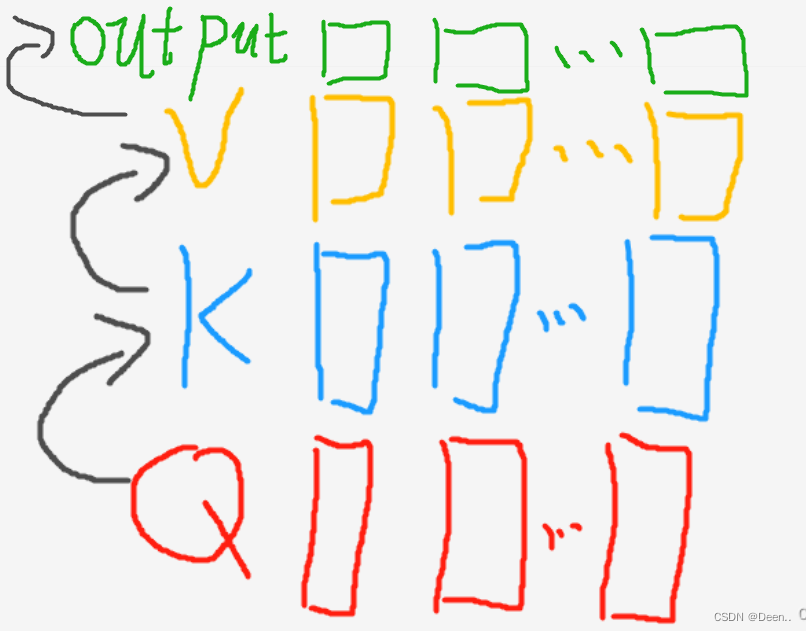
公式如图,简单来讲,这个Q就是序列,也就是编码后的Hello,它的长度是512。这里有6个单词,也就是[6,512]的矩阵,然后K是Key可以把它看成一个权值,V是Value,Value经过Q跟K的点乘后就得到注意力机制输出的值。
按我的理解,就拿活字印刷比喻,这个V就是活字印刷的那个模板,这个K是权值,跟输入进来的序列Q点乘后得到的值等于是索引,根据这个索引找到活字印刷上这个索引对应的汉字,然后将其打印出来。
Q跟K都是向量,两个向量点乘值越大,两个向量就越相似。
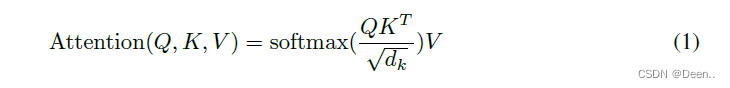
下图是李沐老师视频里的一张截图:
按我举的例子来解释一下:
- Q是英文短句【Hello World nice to meet you】编码后的结果,也就是【6,512】,K对应的是【512,m】,
- 这个K的长度m可以跟Q的序列一样长也可以不一样长,文章里取一样长了,所以这个K就是【512,512】,然后 Q ∗ K Q*K Q∗K得到的结果为【6,512】
- 最后跟这个模板也就是V进行加权计算,V的长度是V,为了跟K能计算,它的数量是m,【m,v】,输出结果的长度跟V的长度是一样的,因为输出结果本质就是V的加权结果,这里的m跟v都取512。
- 所以Q经过K跟V两套计算后得到【n,v】,也就是【6,512】的值。这个过程就是注意力机制过程
- QK点积分后,还除了dk,这是因为dk大的时候两个序列相对的差距就笔记大,softmax的结果会向两边靠,这样子求梯度的时候梯度小,不容易训练。

从图象角度来看,这个注意力机制学到了什么。
图片如下图右上角所示,取观察婴儿关注哪个区域,这个key跟Value都是这一次观察里通用的一套工具,如Key表达了四个方位,Value表达关注程度。Q表达这个主体,也就是婴儿。Q跟K点乘,Q跟K越相似得到的值越大,也就意味着婴儿对该位置的权值越大,越关注这个位置的信息。
多头注意力机制
上述讲的只是一组注意力机制,为了能更好的自学习时序数据的信息,文章提到了多头注意力机制。

这里的h是注意力机制的组数,文中h取8,也就是8组。
这里的关键在橘色部分,Q,K,V还是原来的那些QKV,分别是序列信息(Q),权值信息(K),要加权的值(V)。
但是在进行注意力机制计算 A t t e n t i o n ( Q ; K ; V ) Attention(Q;K; V ) Attention(Q;K;V)时候,进行了 l i n e a r linear linear。文中用 l i n e a r linear linear的参数矩阵用W表示:

这8套 l i n e a r linear linear的参数矩阵,以8种形式去映射QKV的值,然后分别对映射完的QKV进行单注意力的计算,最后将8组计算结果合在一起输出。
输出的结果复制成两份,在训练的时候,作为解码器的K跟V,然后解码器输入Q,进行计算。
位置编码
如下图所示,假设Transformer的输入信息是6个单词,经过编码后变成【6,512】,如果没有进行位置编码,这个6中的6个单词经过Transformer得到的值是一样的,只是顺序不一样,这样子单词短句的前后就是失去了位置信息,所以这里进行了位置编码。
编码公式如下,简单来说,就是用一串数字表示这个序列在哪个位置,将位置编码跟正常编码后的序列数据相加,就可以进行下一步的计算。