一、Keepalived 高可用方案
1、HA高可用集群概述
1. 高可用集群简介
高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低到最小程度。
2. HA集群中的相关术语
1)节点(node)
运行集群进程的一个独立主机,称为节点,节点是集群的核心组成部分,每个节点上运行着操作系统和高可用软件服务,在高可用集群中,节点有主次之分,分别称为主节点和备用/备份节点,每个节点拥有唯一的主机名,并且拥有属于自己的一组资源,例如,磁盘、文件系统、网络地址和应用服务等。主节点上一般运行着一个或多个应用服务。而备用节点一般处于监控状态。
2)资源(resource)
资源是一个节点可以控制的实体,并且当节点发生故障时,这些资源能够被其它节点接管,集群软件中,可以当做资源的实体有:
1. 磁盘分区、文件系统;
2. IP地址 VIP;
3. 应用程序服务;
4. NFS文件系统;
3)事件(event)
也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障、应用程序故障等。这些事件都会导致节点的资源发生转移,集群的测试也是基于这些事件来进行的。
4)动作(action)
事件发生时HA的响应方式,动作是由shell脚步控制的,例如,当某个节点发生故障后,备份节点将通过事先设定好的执行脚本进行服务的关闭或启动。进而接管故障节点的资源。
3. 高可用集群的衡量标准
要保证集群服务100%时间永远完全可用,几乎可以说是一件不可能完成的任务。比如,淘宝在这几年双十一刚开始的时候,一下子进来买东西的人很多,访问量大,都出现一些问题,如下单后却支付不了。所以说只能保证服务尽可能的可用,当然有些场景相信还是可能做到100%可用的。
通常用平均无故障时间(MTTF:mean time to failure)来度量系统的可靠性,用平均故障维修时间(MTTR:mean time to restoration)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%。
具体HA衡量标准:
4. 自动切换/故障转移(FailOver)
自动切换阶段某一主机如果确认对方故障,则正常主机除继续进行原来的任务,还将依据各种容错备援模式接管预先设定的备援作业程序,并进行后续的程序及服务。
通俗地说,即当A无法为客户服务时,系统能够自动地切换,使B能够及时地顶上继续为客户提供服务,且客户感觉不到这个为他提供服务的对象已经更换。
通过上面判断节点故障后,将高可用集群资源(如VIP、httpd等)从该不具备法定票数的集群节点转移到故障转移域(Failover Domain,可以接收故障资源转移的节点)。
5. 自动侦测
自动侦测阶段由主机上的软件通过冗余侦测线,经由复杂的监听程序,逻辑判断,来相互侦测对方运行的情况。
常用的方法是:集群各节点间通过心跳信息判断节点是否出现故障。
6. 脑裂简介
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
脑裂产生的原因:
1)因心跳线坏了(包括断了,老化)。
2)因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。
3)因心跳线间连接的设备故障(网卡及交换机)。
4)因仲裁的机器出问题(采用仲裁的方案)。
5)高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输。
6)高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败。
7)其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等。
常见的解决方案:
1)添加冗余的心跳线
例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
2)启用磁盘锁
正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
3)设置仲裁机制
例如设置参考IP(如网关IP或某一个服务器),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
4)监控报警
在问题发生时人为第一时间介入仲裁,降低损失。
当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路 发送关机命令关闭主节点的电源。
当然,在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站常规业务.这个损失是可容忍的。
2、集群的分类
1)高可用集群
高可用集群的英文全称是High Availability Cluster,简称HA Cluster, 高可用的含义是最大限度的可以使用,从集群的名字上可以看出,此类集群实现的功能是保障用户的应用程序持久、不间断的提供服务。
当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以自动、快速从一个节点切换到另一个节点,从而保证应用持续、不间断的对外提供服务,这就是高可用集群实现的功能。

双机热备是最简单的应用模式,即经常说的active/standby方式,它使用两台服务器,一台作为主服务器(action),运行应用程序对外提供服务,另一台作为备机(standby),安装和主服务器一样的应用程序,但是并不启动服务,处于待机状态。主机和备机之间通过心跳技术相互监控,监控的资源可以是网络、操作系统、也可以是服务,用户可以根据自己的需要,选择需要监控的资源,当备机监控到主机的某个资源出现故障时,根据预先设定好的策略,首先将IP切换过来,然后将应用程序服务也接管过来,接着就由备机对外提供服务,由于切换过程时间非常端,用户根本感觉不到程序出了问题,而且还进行了切换,从而保障了应用程序持久、不间断的服务。
高可用集群一般是通过高可用软件来实现的,在linux下常用的高可用软件有:开源heartbea HA、Redhat提供的RHCS、商业软件ROSE、keepalived等。在下面的章节中我们会详细介绍heartbea HA的配置和使用。
2)负载均衡集群
负载均衡系统的英文全称为Load Balance Cluster,简称LB Cluster,负载均衡集群也是有两台或者两台以上的服务器组成,分为前端负载调度和后端节点服务两个部分,负载调度部分负责把客户端的请求按照不同的策略分配给后端服务节点,而后端节点是真正提供应用程序服务的部分。

与HA Cluster不同的是,在负载均衡集群中,所有的后端节点都处于活动状态,它们都对外提供服务,分摊系统的工作负载。
负载均衡集群可以把一个高负荷的应用分散到多个节点来共同完成,适用于业务繁忙、大负荷访问的应用系统,但是它也有不足的地方:当一个节点出现故障时,前端调度系统并不知道此节点已经不能提供服务,仍然会把客户端的请求调度到故障节点上来,这样访问就会失败,为了解决这个问题,负载调度系统一般都引入了节点监控系统。
节点监控系统位于前端负载调度机上,负责监控下面的服务节点,当某个节点出现故障后,节点监控系统会自动将故障节点从集群中剔除,当此节点恢复正常后,节点监控系统又会自动将其加入集群中,而这一切,对用户来说是完全透明的。
3)分布式计算集群
分布式计算集群,这类集群致力于提供单个计算机所不能提供的强大的计算能力,包括数值计算和数据处理,并且倾向于追求综合性能。

在Hadoop的系统中,会有一台或多台master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台slave,每一台slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
3、Keepalived 简介
Keepalived是Linux下一个轻量级的高可用解决方案,它与HACMP、RoseHA实现的功能类似,都可以实现服务或者网络的高可用,但是又有差别:HACMP是一个专业的、功能完善的高可用软件,它提供了HA软件所需的基本功能,比如心跳检测和资源接管,监测集群中的系统服务,在群集节点间转移共享IP地址的所有者等,HACMP功能强大,但是部署和使用相对比较麻烦,同时也是商业化软件;与HACMP相比,Keepalived主要是通过虚拟路由冗余来实现高可用功能,虽然它没有HACMP功能强大,但Keepalived部署和使用非常简单,所有配置只需一个配置文件即可完成。这也是本课程重点介绍Keepalived的原因。
1)Keepalived的用途
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态。它根据layer3, 4 & 5交换机制检测每个服务节点的状态,如果某个服务节点出现异常,或工作出现故障,Keepalived将检测到,并将出现故障的服务节点从集群系统中剔除,而在故障节点恢复正常后,Keepalived又可以自动将此服务节点重新加入到服务器集群中,这些工作全部自动完成,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
Keepalived后来又加入了VRRP的功能,VRRP是Virtual Router Redundancy Protocol(虚拟路由器冗余协议)的缩写,它出现的目的是为了解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断地、稳定地运行。因此,Keepalived一方面具有服务器状态检测和故障隔离功能,另一方面也具有HA cluster功能.下面详细介绍下VRRP协议的实现过程。
2)VRRP协议与工作原理
在现实的网络环境中,主机之间的通信都是通过配置静态路由(默认网关)完成的,而主机之间的路由器一旦出现故障,通信就会失败,因此,在这种通信模式中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
熟悉网络的学员对VRRP协议应该并不陌生。它是一种主备模式的协议,通过VRRP可以在网络发生故障时透明地进行设备切换而不影响主机间的数据通信,这其中涉及两个概念:物理路由器和虚拟路由器。
VRRP可以将两台或多台物理路由器设备虚拟成一个虚拟路由器,这个虚拟路由器通过虚拟IP(一个或多个)对外提供服务,而在虚拟路由器内部,是多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由器被称为主路由器(处于MASTER角色)。一般情况下MASTER由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如ARP请求、ICMP、数据转发等。而其他物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为备份路由器(处于BACKUP角色)。当主路由器失效时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色继续提供对外服务,整个切换过程对用户来说完全透明。
在一个虚拟路由器中,只有处于MASTER角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只接收MASTER发过来的报文信息,用来监控MASTER运行状态,因此,不会发生MASTER抢占的现象,除非它的优先级更高。而当MASTER不可用时,BACKUP也就无法收到MASTER发过来的报文信息,于是就认定MASTER出现故障,接着多台BACKUP就会进行选举,优先级最高的BACKUP将成为新的MASTER,这种选举并进行角色切换的过程非常快,因而也就保证了服务的持续可用性。
3)Keepalived的体系结构
Keepalived是一个高度模块化的软件,结构简单,但扩展性很强。
Keepalived体系结构拓扑图:
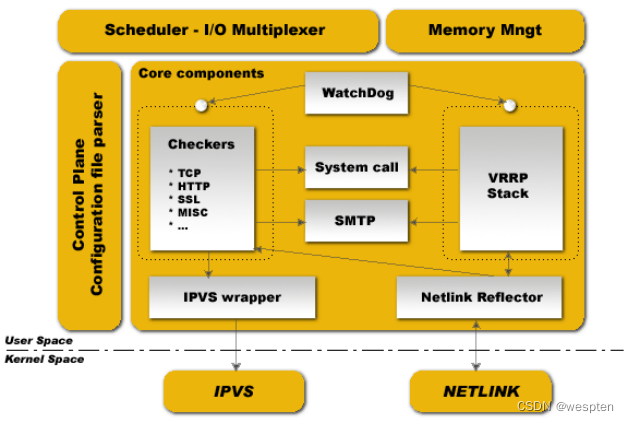
设计模块:
1. core模块:为keepalived的核心组件,负责主进程的启动、维护以及全局配置文件的加载和解析;
2. check模块:负责real server 节点池内的节点的健康检测;
3. VRRP模块:在master与backup之间执行心跳检测;
热备实现过程:将多个主机以软件的方式组成一个热备组,通过共有的虚拟ip(VIP)地址对外提供服务,同一时刻,热备组中只有一台主机在工作,别的主机冗余状态,当当前在线的主机失效时,其他冗余的主机会自动接替虚拟ip地址,继续提供服务,以保证架构的稳定性。
可以看出,Keepalived的体系结构从整体上分为两层,分别是用户空间层(User Space)和内核空间层(Kernel Space),下面介绍Keepalived两层结构的详细组成及实现的功能。
内核空间层处于最底层,它包括IPVS和NETLINK两个模块。IPVS模块是Keepalived引入的一个第三方模块,通过IPVS可以实现基于IP的负载均衡集群。IPVS默认包含在LVS集群软件中。
Keepalived最初就是为LVS提供服务的,由于Keepalived可以实现对集群节点的状态检测,而IPVS可以实现负载均衡功能,因此,Keepalived借助于第三方模块IPVS就可以很方便地搭建一套负载均衡系统。
在这里有个误区,由于Keepalived可以和IPVS一起很好地工作,因此很多初学者都以为Keepalived就是一个负载均衡软件,这种理解是错误的。
在Keepalived中,IPVS模块是可配置的,如果需要负载均衡功能,可以在编译Keepalived时打开负载均衡功能,反之,也可以通过配置编译参数关闭。
NETLINK模块主要用于实现一些高级路由框架和一些相关的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求。
用户空间层位于内核空间层之上,Keepalived的所有具体功能都在这里实现.
4、Keepalived安装与配置
1. Keepalived的安装过程
keepalived的安装非常简单,以操作系统环境Centos7.5为例,建议通过yum方式直接安装:
[root@233server ~]# yum install keepalived如果需要lvs功能,还需要安装ipvs模块:
[root@233server ~]# yum install ipvsadm也可以通过源码安装,过程如下:
[root@keepalived-master app]# yum install -y gcc gcc-c++ wget popt-devel openssl openssl-devel
[root@keepalived-master app]#yum install -y libnl libnl-devel libnl3 libnl3-devel
[root@keepalived-master app]#yum install -y libnfnetlink-devel
[root@keepalived-master app]#tar zxvf keepalived-2.0.5.tar.gz
[root@keepalived-master app]# cd keepalived-2.0.5
[root@keepalived-master keepalived-2.0.5]#./configure --sysconf=/etc
[root@keepalived-master keepalived-2.0.5]# make
[root@keepalived-master keepalived-2.0.5]# make install
[root@keepalived-master keepalived-2.0.5]# systemctl enable keepalived在编译选项中,“--sysconf”指定了keepalived配置文件的安装路径,即路径为/etc/keepalived/keepalived.conf。
2. Keepalived的全局配置
安装Keepalived过程中,指定了Keepalived配置文件的路径为/etc/Keepalived/Keepalived.conf,Keepalived的所有配置均在这个配置文件中完成。由于Keepalived.conf文件中可配置的选项比较多,这里根据配置文件所实现的功能,将Keepalived配置分为三类,分别是:
① 全局配置(Global Configuration);
② VRRPD配置;
③ LVS配置;
下面将主要介绍下Keepalived配置文件中一些常用配置选项的含义和用法。
Keepalived的配置文件都是以块(block)的形式组织的,每个块的内容都包含在{}中,以“#”和“!”开头的行都是注释。全局配置就是对整个Keepalived都生效的配置,基本内容如下:
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
}
notification_email_from Keepalived@localhost
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}全局配置以“global_defs”作为标识,在“global_defs”区域内的都是全局配置选项,其中:
notification_email用于设置报警邮件地址,可以设置多个,每行一个。
注意,如果要开启邮件报警,需要开启本机的Sendmail服务。
notification_email_from用于设置邮件的发送地址。
smtp_server用于设置邮件的smtp server地址。
smtp_connect_timeout用于设置连接smtp server的超时时间。
router_id表示运行Keepalived服务器的一个标识,是发邮件时显示在邮件主题中的信息。
3. Keepalived的VRRPD配置
VRRPD配置是Keepalived所有配置的核心,主要用来实现Keepalived的高可用功能。下面进入VRRP实例的配置,也就是配置Keepalived的高可用功能。VRRP实例段主要用来配置节点角色(主或从)、实例绑定的网络接口、节点间验证机制、集群服务IP等。
下面是实例VI_1的一个配置样例:
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 151
priority 100
advert_int 1
track_interface {
eth0
eth1
}
authentication {
auth_type PASS
auth_pass qwaszx
}
virtual_ipaddress {
192.168.200.16
192.168.200.17 dev eth1
192.168.200.18 dev eth2
}
nopreempt
preemtp_delay 300
notify_master "/etc/keepalived/master.sh "
notify_backup "/etc/keepalived/backup.sh"
notify_fault "/etc/keepalived/fault.sh"
}以上VRRP配置以“vrrp_instance”作为标识,在这个实例中包含了若干配置选项,分别介绍如下:
vrrp_instance:是VRRP实例开始的标识,后跟VRRP实例名称。
state:用于指定Keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器。
interface:用于指定HA监测网络的接口。
virtual_router_id:是虚拟路由标识,这个标识是一个数字,同一个vrrp实例使用唯一的标识,即在同一个vrrp_instance下,MASTER和BACKUP必须是一致的。
priority:用于定义节点优先级,数字越大表示节点的优先级就越高。在一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级。
advert_int:用于设定MASTER与BACKUP主机之间同步检查的时间间隔,单位是秒。
track_interface:用于设置一些额外的网络监控接口,其中任何一个网络接口出现故障,Keepalived都会进入FAULT状态。
authentication:用于设定节点间通信验证类型和密码,验证类型主要有PASS和AH两种,在一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信。
virtual_ipaddress:用于设置虚拟IP地址(VIP),又叫做漂移IP地址。可以设置多个虚拟IP地址,每行一个。之所以称为漂移IP地址,是因为Keepalived切换到Master状态时,这个IP地址会自动添加到系统中,而切换到BACKUP状态时,这些IP又会自动从系统中删除。Keepalived通过“ip address add”命令的形式将VIP添加进系统中。
要查看系统中添加的VIP地址,可以通过“ip add”命令实现。“virtual_ipaddress”段中添加的IP形式可以多种多样,例如可以写成 “192.168.16.189/24 dev eth1” 这样的形式,而Keepalived会使用IP命令“ip addr add 192.168.16.189/24 dev eth1”将IP信息添加到系统中。因此,这里的配置规则和IP命令的使用规则是一致的。
nopreempt:设置的是高可用集群中的不抢占功能。在一个HA Cluster中,如果主节点死机了,备用节点会进行接管,主节点再次正常启动后一般会自动接管服务。这种来回切换的操作,对于实时性和稳定性要求不高的业务系统来说,还是可以接受的,而对于稳定性和实时性要求很高的业务系统来说,不建议来回切换,毕竟服务的切换存在一定的风险和不稳定性,在这种情况下,就需要设置nopreempt这个选项了。设置nopreempt可以实现主节点故障恢复后不再切回到主节点,让服务一直在备用节点工作,直到备用节点出现故障才会进行切换。在使用不抢占时,只能在“state”状态为“BACKUP”的节点上设置,而且这个节点的优先级必须高于其他节点。
preemtp_delay:用于设置切换的延时时间,单位是秒。有时候系统启动或重启之后网络需要经过一段时间才能正常工作,在这种情况下进行发生主备切换是没必要的,此选项就是用来设置这种情况发生的时间间隔。在此时间内发生的故障将不会进行切换,而如果超过“preemtp_delay”指定的时间,并且网络状态异常,那么才开始进行主备切换。
notify_master:指定当Keepalived进入Master状态时要执行的脚本,这个脚本可以是一个状态报警脚本,也可以是一个服务管理脚本。Keepalived允许脚本传入参数,因此灵活性很强。
notify_backup:指定当Keepalived进入Backup状态时要执行的脚本,同理,这个脚本可以是一个状态报警脚本,也可以是一个服务管理脚本。
notify_fault:指定当Keepalived进入Fault状态时要执行的脚本,脚本功能与前两个类似。
notify_stop:指定当Keepalived程序终止时需要执行的脚本。
4. Keepalived的LVS配置
由于Keepalived属于LVS的扩展项目,因此, Keepalived可以与LVS无缝整合,轻松搭建一套高性能的负载均衡集群系统。下面介绍下Keepalived配置文件中关于LVS配置段的配置方法。
LVS段的配置以“virtual_server”作为开始标识,此段内容有两部分组成,分别是real_server段和健康检测段。下面是virtual_server段常用选项的一个配置示例:
virtual_server 192.168.12.200 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
persistence_granularity <NETMASK>
protocol TCP
sorry_server <IPADDR> <PORT>下面介绍每个选项的含义:
virtual_server:设置虚拟服务器的开始,后面跟虚拟IP地址和服务端口,IP与端口之间用空格隔开。
delay_loop:设置健康检查的时间间隔,单位是秒。
lb_algo:设置负载调度算法,可用的调度算法有rr、wrr、lc、wlc、lblc、sh、dh等,常用的算法有rr和wlc。
lb_kind:设置LVS实现负载均衡的机制,有NAT、TUN和DR三个模式可选。
persistence_timeout:会话保持时间,单位是秒。这个选项对动态网页是非常有用的,为集群系统中的session共享提供了一个很好的解决方案。有了这个会话保持功能,用户的请求会一直分发到某个服务节点,直到超过这个会话的保持时间。需要注意的是,这个会话保持时间是最大无响应超时时间,也就是说,用户在操作动态页面时,如果在50秒内没有执行任何操作,那么接下来的操作会被分发到另外的节点,但是如果用户一直在操作动态页面,则不受50秒的时间限制。
persistence_granularity:此选项是配合persistence_timeout的,后面跟的值是子网掩码,表示持久连接的粒度。默认是255.255.255.255,也就是一个单独的客户端IP。如果将掩码修改为255.255.255.0,那么客户端IP所在的整个网段的请求都会分配到同一个real server上。
protocol:指定转发协议类型,有TCP和UDP两种可选。
ha_suspend:节点状态从Master到Backup切换时,暂不启用real server节点的健康检查。
sorry_server:相当于一个备用节点,在所有real server失效后,这个备用节点会启用。
下面是real_server段的一个配置示例:
real_server 192.168.12.132 80 {
weight 3
inhibit_on_failure
notify_up <STRING> | <QUOTED-STRING>
notify_down <STRING> | <QUOTED-STRING>
}下面介绍每个选项的含义:
real_server:是real_server段开始的标识,用来指定real server节点,后面跟的是real server的
weight:用来配置real server节点的权值。权值大小用数字表示,数字越大,权值越高。设置权值的大小可以为不同性能的服务器分配不同的负载,为性能高的服务器设置较高的权值,而为性能较低的服务器设置相对较低的权值,这样才能合理地利用和分配了系统资源。
inhibit_on_failure:表示在检测到real server节点失效后,把它的“weight”值设置为0,而不是从IPVS中删除。
notify_up:此选项与上面介绍过的notify_maser有相同的功能,后跟一个脚本,表示在检测到real server节点服务处于UP状态后执行的脚本。
notify_down:表示在检测到real server节点服务处于DOWN状态后执行的脚本。
健康检测段允许多种检查方式,常见的有HTTP_GET、SSL_GET、TCP_CHECK、SMTP_CHECK、MISC_CHECK。首先看TCP_CHECK检测方式示例:
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
} 下面介绍每个选项的含义:
connect_port:健康检查的端口,如果无指定,默认是real_server指定的端口。
connect_timeout:表示无响应超时时间,单位是秒,这里是3秒超时。
nb_get_retry:表示重试次数,这里是3次。
delay_before_retry:表示重试间隔,这里是间隔3秒。
下面是HTTP_GET和SSL_GET检测方式的示例:
HTTP_GET |SSL_GET
{
url {
path /index.html
digest e6c271eb5f017f280cf97ec2f51b02d3
status_code 200
}
connect_port 80
bindto 192.168.12.80
connect_timeout 3
nb_get_retry 3
delay_before_retry 2
} 下面介绍每个选项的含义。
url:用来指定HTTP/SSL检查的URL信息,可以指定多个URL。
path:后跟详细的URL路径。
digest:SSL检查后的摘要信息,这些摘要信息可以通过genhash命令工具获取。例如:genhash -s 192.168.12.80 -p 80 -u /index.html。
status_code:指定HTTP检查返回正常状态码的类型,一般是200。
bindto:表示通过此地址来发送请求对服务器进行健康检查。
下面是MISC_CHECK检测方式的示例:
MISC_CHECK
{
misc_path /usr/local/bin/script.sh
misc_timeout 5
! misc_dynamic
}MISC健康检查方式可以通过执行一个外部程序来判断real server节点的服务状态,使用非常灵活。
以下是常用的几个选项的含义:
misc_path:用来指定一个外部程序或者一个脚本路径。
misc_timeout:设定执行脚本的超时时间。
misc_dynamic:表示是否启用动态调整real server节点权重,“!misc_dynamic”表示不启用,相反则表示启用。在启用这功能后,Keepalived的healthchecker进程将通过退出状态码来动态调整real server节点的“weight”值,如果返回状态码为0,表示健康检查正常,real server节点权重保持不变;如果返回状态码为1,表示健康检查失败,那么就将real server节点权重设置为0;如果返回状态码为2~255之间任意数值,表示健康检查正常,但real server节点的权重将被设置为返回状态码减2,例如返回状态码为10,real server节点权重将被设置为8(10-2)。
到这里为止,Keepalived配置文件中常用的选项已经介绍完毕,在默认情况下,Keepalived在启动时会查找/etc/Keepalived/Keepalived.conf配置文件,如果配置文件放在其他路径下,通过“Keepalived -f”参数指定配置文件的路径即可。在配置Keepalived.conf时,需要特别注意配置文件的语法格式,因为Keepalived在启动时并不检测配置文件的正确性,即使没有配置文件,Keepalived也照样能够启动,所以一定要保证配置文件正确。
5、Keepalived基础双机热备演示
案例拓扑:
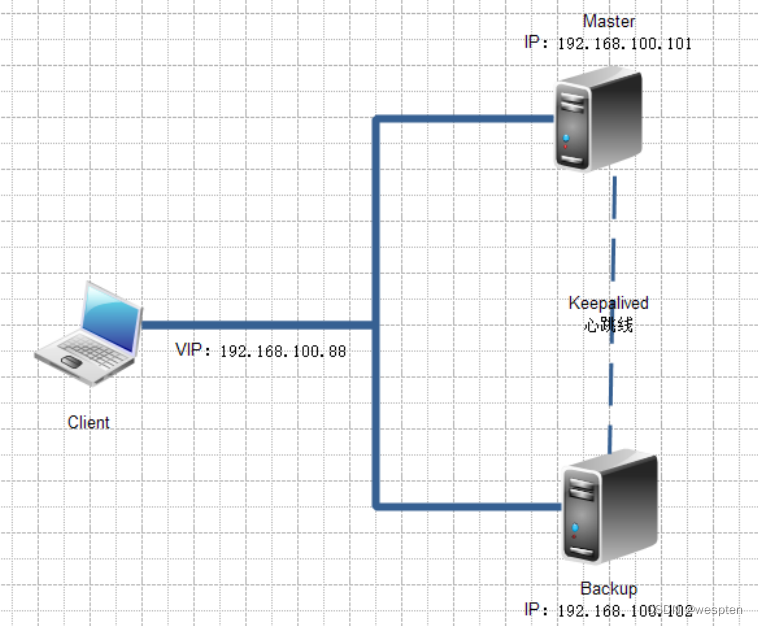
案例环境:
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 7.4 1708 64bit |
192.168.100.101 |
node1.linuxfan.cn |
keepalived-1.2.13.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.102 |
node2.linuxfan.cn |
keepalived-1.2.13.tar.gz |
案例步骤:
- 安装node1节点上的httpd的服务;
- 安装node2节点上的httpd的服务;
- 在两台node节点上安装keepalived软件程序(两台安装步骤一致,在此只列出一台);
- 配置node1上master主节点;
- 配置node2上backup从节点;
- 客户端访问测试双机热备的效果;
1. 安装node1节点上的httpd的服务
[root@node1 ~]# yum -y install httpd
[root@node1 ~]#cat <<END >>/var/www/html/index.html
192.168.100.101
END
[root@node1 ~]# systemctl start httpd
[root@node1 ~]# systemctl enable httpd
[root@node1 ~]# netstat -utpln |grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 13891/httpd2. 安装node1节点上的httpd的服务
[root@node2 ~]# yum -y install httpd
[root@node2 ~]#cat <<END >>/var/www/html/index.html
192.168.100.101
END
[root@node2 ~]# systemctl start httpd
[root@node2 ~]# systemctl enable httpd
[root@node2 ~]# netstat -utpln |grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 13891/httpd3. 在两台node节点上安装keepalived软件程序(两台安装步骤一致,在此只列出一台)
[root@node1 ~]# yum -y install kernel-devel openssl-devel popt-devel ##安装内核开发包,popt支持库等工具;
[root@node1 ~]# tar -zxvf keepalived-1.2.13.tar.gz -C /usr/src/
[root@node1 ~]# cd /usr/src/keepalived-1.2.13/
[root@node1 keepalived-1.2.13]# ./configure --prefix=/usr/local/keepalived
[root@node1 keepalived-1.2.13]# make &&make install
[root@node1 keepalived-1.2.13]# cd
[root@node1 ~]# mkdir -p /etc/keepalived ##程序的主配置目录
[root@node1 ~]# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ ##复制主配置文件
[root@node1 ~]# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ ##复制启动时需要加载的配置文件
[root@node1 ~]# cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ ##复制服务的控制脚本
[root@node1 ~]# cp /usr/local/keepalived/sbin/keepalived /usr/sbin/ ##复制keepalived的命令
[root@node1 ~]# chmod 755 /etc/init.d/keepalived ##为控制脚本指定权限4. 配置node1上master主节点
[root@node1 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R1 ##本服务器的名称,若环境中有多个keepalived时,此名称不能一致
}
vrrp_instance VI_1 { ##定义VRRP热备实例,每一个keep组都不同
state MASTER ##MASTER表示主服务器
interface eth0 ##承载VIP地址的物理接口
virtual_router_id 1 ##虚拟路由器的ID号,每一个keep组都不同
priority 100 ##优先级,数值越大优先级越高
advert_int 1 ##通告检查间隔秒数(心跳频率)
authentication { ##认证信息
auth_type PASS ##认证类型
auth_pass 123456 ##密码字串
}
virtual_ipaddress {
192.168.100.95 ##指定漂移地址(VIP)
}
}
virtual_server 192.168.100.95 80 { #vip配置
delay_loop 2 #每隔2秒检查一次real_server状态
lb_algo wrr ##指定lvs的调度算法
lb_kind DR ##lvs集群模式
persistence_timeout 60 ##会话保持时间
protocol TCP ##选择协议
real_server 192.168.100.101 80 { ##本机地址
weight :3 ##服务器的权重
notify_down /etc/keepalived/check.sh ##指定节点失效后,采用的脚本,notify_up表示节点正常后,采用的脚本
##健康检查方式一共有HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK这些
TCP_CHECK {
connect_timeout 10 ##连接超时时间
nb_get_retry 3 ##重连次数
delay_before_retry 3 ##重连间隔时间
connect_port 80 ##健康检查端口
}
}
}
:wq
[root@node1 ~]# vi /etc/keepalived/check.sh
#!/bin/bash
/etc/init.d/keepalived stop
echo -e "$(ip a |grep eth0 |grep inet |awk '{print $2}'|awk -F'/' '{print $1}') (httpd) is down on $(date +%F-%T)" >>/root/check_httpd.log
:wq
[root@node1 ~]# chmod 777 /etc/keepalived/check.sh
[root@node1 ~]# /etc/init.d/keepalived start
Starting keepalived (via systemctl): [ 确定 ]
[root@node1 ~]# ip a |grep 192.168.100.95
inet 192.168.100.95/32 scope global eth05. 配置node2上backup从节点
[root@node2 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R2 ##本服务器的名称
}
vrrp_instance VI_1 {
state BACKUP ##BACKUP表示从服务器
interface eth0
virtual_router_id 1
priority 99 ##优先级,低于主服务器
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.100.95
}
}
virtual_server 192.168.100.95 80 { ##vip配置
delay_loop 2 ##每隔2秒检查一次real_server状态
lb_algo wrr
lb_kind DR
persistence_timeout 60 ##会话保持时间
protocol TCP
real_server 192.168.100.102 80 { ##本机地址
weight :3
notify_down /etc/keepalived/check.sh
TCP_CHECK {
connect_timeout 10 ##连接超时时间
nb_get_retry 3 ##重连次数
delay_before_retry 3 ##重连间隔时间
connect_port 80 ##健康检查端口
}
}
}
[root@node2 ~]# vi /etc/keepalived/check.sh
#!/bin/bash
service keepalived stop
echo -e "$(ip a |grep eth0 |grep inet |awk '{print $2}'|awk -F'/' '{print $1}') (httpd) is down on $(date +%F-%T)" >>/root/check_httpd.log
:wq
[root@node2 ~]# chmod 777 /etc/keepalived/check.sh
[root@node2 ~]# /etc/init.d/keepalived start
Starting keepalived (via systemctl): [ 确定 ]
[root@node2~]# ip a |grep 192.168.100.956. 客户端访问测试双机热备的效果
当node1与node2均正常状态:
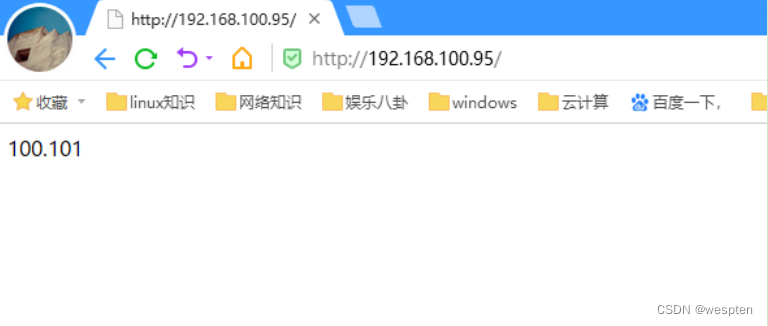
当node1的httpd服务关闭:



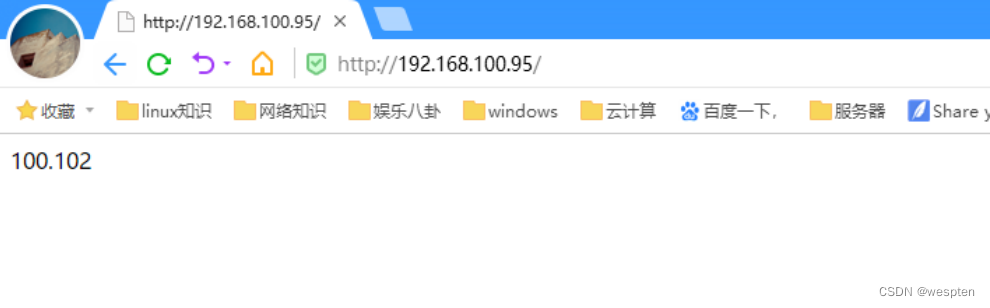

将node1节点的http和keepalived服务重新启动:


6、Keepalived HA模块功能演示
Keepalived提供了vrrp_script、notify_master、notify_backup等多个功能模块,通过这些模块可以实现对集群资源的托管以及集群服务的监控。
在默认情况下,Keepalived可以实现对系统死机、网络异常及Keepalived本身进行监控,也就是说当系统出现死机、网络出现故障或Keepalived进程异常时,Keepalived会进行主备节点的切换。但这些还是不够的,因为集群中运行的服务也随时可能出现问题,因此,还需要对集群中运行服务的状态进行监控,当服务出现问题时也进行主备切换。
Keepalived作为一个优秀的高可用集群软件,也考虑到了这一点,它提供了一个vrrp_script模块专门用来对集群中服务资源进行监控。
1. 配置Keepalived
下面将通过配置一套Keepalived集群系统来实际演示一下Keepalived高可用集群的实现过程。这里以操作系统CentOS release 7.5、keepalived-1.2.12版本为例,更具体的集群部署环境如下表所示。
主机名 主机IP地址 集群角色 集群服务 虚拟IP地址
keepalived-master 192.168.66.11 Master(主节点) HTTPD 192.168.66.80
keepalived-backup 192.168.66.12 Backup(备用节点) HTTPD 通过此表可以看出,这里要部署一套基于HTTPD的高可用集群系统。
关于Keepalived的安装,之前已经做过详细介绍,这里不再多说。下面给出keepalived-master节点的keepalived.conf文件的内容:
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script check_httpd {
script "killall -0 httpd"
interval 2
}
vrrp_instance HA_1 {
state MASTER
interface eth0
virtual_router_id 80
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass qwaszx
}
notify_master "/etc/keepalived/master.sh "
notify_backup "/etc/keepalived/backup.sh"
notify_fault "/etc/keepalived/fault.sh"
track_script {
check_httpd
}
virtual_ipaddress {
192.168.66.80/24 dev eth0
}
}
其中,master.sh文件的内容为:
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Master]" >> $LOGFILE
date >> $LOGFILEbackup.sh文件的内容为:
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Backup]" >> $LOGFILE
date >> $LOGFILEfault.sh文件的内容为:
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Fault]" >> $LOGFILE
date >> $LOGFILE这三个脚本的作用是监控Keepalived角色的切换过程,从而帮助读者理解notify参数的执行过程。
keepalived-backup节点上的keepalived.conf配置文件内容与keepalived-master节点上的基本相同,需要修改的地方有两个:
1. 将“state MASTER”更改为“state BACKUP”。
2. 将priority 100更改为一个较小的值,这里改为“priority 80”。
2. Keepalived启动过程分析
将配置好的keepalived.conf文件及master.sh、backup.sh、fault.sh三个文件一起复制到keepalived-backup备用节点对应的路径下,然后在两个节点启动http服务,最后启动Keepalived服务,下面介绍具体的操作过程。
首先在keepalived-master节点启动keepalived服务,执行如下操作:
[root@keepalived-master keepalived]# chkconfig --level 35 httpd on
[root@keepalived-master keepalived]# /etc/init.d/httpd start
[root@keepalived-master keepalived]# /etc/init.d/keepalived startKeepalived正常运行后共启动了3个进程,其中一个进程是父进程,负责监控其余两个子进程(分别是vrrp子进程和healthcheckers子进程),然后观察keepalived-master上Keepalived的运行日志。
从日志可以看出,在keepalived-master主节点启动后,VRRP_Script模块首先运行了check_httpd的检查,发现httpd服务运行正常,然后进入Master角色,如果检查httpd服务异常,将进入Fault状态,最后将虚拟IP地址添加到系统中,完成Keepalived在主节点的启动。此时在主节点通过命令“ip add”就能查看到已经添加到系统中的虚拟IP地址。
再查看/var/log/keepalived-mysql-state.log日志文件,内容如下:
[root@keepalived-master keepalived]#tail -f /var/log/keepalived-mysql-state.log
[Master]
Tue Mar 4 17:23:23 CST 2014通过上面给出的三个脚本的内容可知,Keepalived在切换到Master角色后,执行了/etc/keepalived/master.sh这个脚本,从这里也可以看出notify_master的作用。
接着在备用节点keepalived-backup上也启动keepalived服务,执行如下操作:
[root@keepalived-backup keepalived]# chkconfig --level 35 httpd on
[root@keepalived-backup keepalived]# /etc/init.d/httpd start
[root@keepalived-backup keepalived]# /etc/init.d/keepalived start然后观察keepalived-backup上Keepalived的运行日志。

日志输出可以看出,keepalived-backup备用节点在启动Keepalived服务后,由于自身角色为Backup,所以会首先进入Backup状态,接着也会运行VRRP_Script模块检查httpd服务的运行状态,如果httpd服务正常,将输出“succeeded”。
在备用节点查看下/var/log/keepalived-mysql-state.log日志文件,内容如下:
[root@keepalived-backup keepalived]#tail -f /var/log/keepalived-mysql-state.log
[Backup]
Tue Mar 4 17:27:15 CST 2014由此可知,备用节点在切换到Backup状态后,执行了/etc/keepalived/backup.sh这脚本。
3. Keepalived的故障切换过程分析
下面开始测试一下Keepalived的故障切换(failover)功能,首先在keepalived-master节点关闭httpd服务,然后看看Keepalived是如何实现故障切换的。在keepalived-master节点关闭httpd服务后,紧接着查看Keepalived运行日志,操作如下图所示。
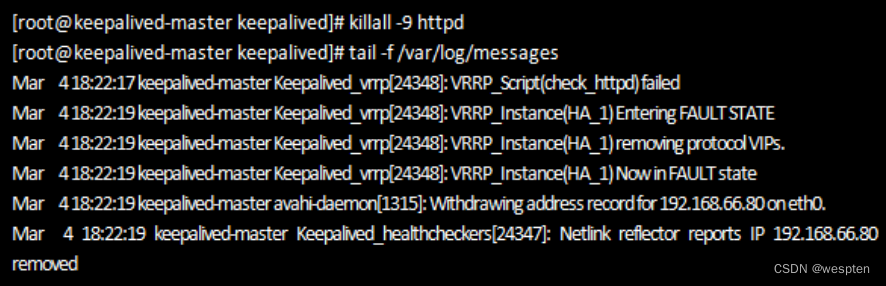
从日志可以看出,在keepalived-master节点的httpd服务被关闭后,VRRP_Script模块很快就能检测到,然后进入了Fault状态,最后将虚拟IP地址从eth0上移除。紧接着查看keepalived-backup节点上Keepalived运行日志,信息如下图所示。

从日志可以看出,在keepalived-master节点出现故障后,备用节点keepalived-backup立刻检测到,此时备用机变为Master角色,并且接管了keepalived-master主机的虚拟IP资源,最后将虚拟IP绑定在eth0设备上。
Keepalived在发生故障时进行切换的速度是非常快的,只有几秒钟的时间,如果在切换过程中,持续ping虚拟IP地址,几乎没有延时等待时间。
4. 故障恢复切换分析
由于设置了集群中的主、备节点角色,因此,主节点在恢复正常后会自动再次从备用节点夺取集群资源,这是常见高可用集群系统的运行原理。下面继续演示下故障恢复后Keepalived的切换过程。
首先在keepalived-master节点上启动httpd服务:
[root@keepalived-master ~]# /etc/init.d/httpd start紧接着查看Keepalived运行日志,信息如下图所示: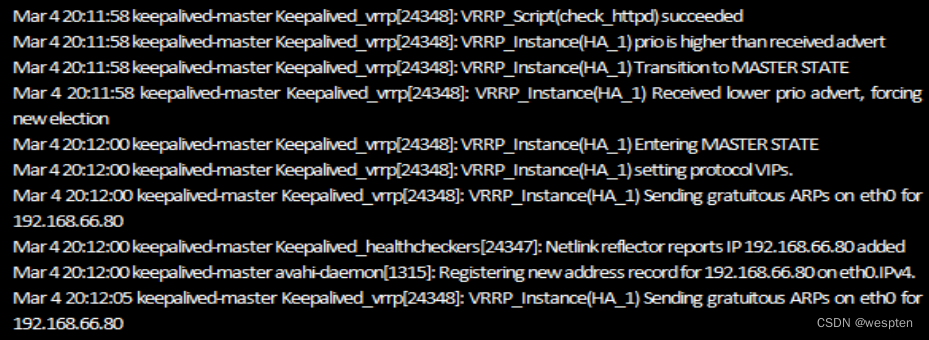
从日志可知,keepalived-master节点通过vrrp_script模块检测到httpd服务已经恢复正常,然后自动切换到Master状态,同时也夺回了集群资源,将虚拟IP地址再次绑定在eth0设备上。
继续查看keepalived-backup节点Keepalived的运行日志信息,如下图所示:
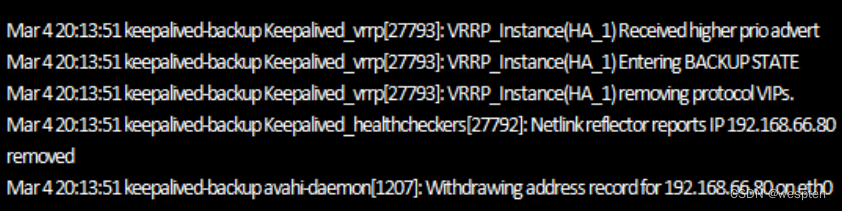
从上面图中可以看出,keepalived-backup节点在发现主节点恢复正常后,释放了集群资源,重新进入了Backup状态,于是整个集群系统恢复了正常的主、备运行状态。
纵观Keepalived的整个运行过程和切换过程,看似合理,事实上并非如此:在一个高负载、高并发、追求稳定的业务系统中,执行一次主、备切换对业务系统影响很大,因此,不到万不得已,尽量不要进行主、备角色的切换,也就是说,在主节点发生过程后,必须要切换到备用节点,而在主节点恢复后,不希望再次切回主节点,直到备用节点发生故障时才进行切换,这就是前面绍过的不抢占功能,可以通过Keepalived的“nopreempt”选项来实现。
7、通过vrrp_script实现对集群资源的监控
1. 通过killall命令探测服务运行状态
这种监控集群服务的方式主要是通过killall命令实现的。killall会发送一个信号到正在运行的指定命令的进程。如果没指定信号名,则发送SIGTERM。SIGTERM也是信号名的一种,代号为15,它表示以正常的方式结束程序的运行。
其实killall可用的信号名有很多,可通过“killall -l”命令显示所有信号名列表,其中每个信号名代表对进程的不同执行方式,例如,代号为9的信号表示将强制中断一个程序的运行。这里要用到的信号为0,代号为0的信号并不表示要关闭某个程序,而表示对程序(进程)的运行状态进行监控,如果发现进程关闭或其他异常,将返回状态码1,反之,如果发现进程运行正常,将返回状态码0。vrrp_script模块正是利用了killall命令的这个特性,变相的实位现了对服务运行状态的监控。下面看一个实例:
vrrp_script check_mysqld {
script "killall -0 mysqld"
interval 2
}
track_script {
check_mysqld
}在这个例子中,定义了一个服务监控模块check_mysqld,其采用的监控的方式是通过“killall -0 mysqld”的方式,其中“interval”选项检查的时间间隔,即2秒钟执行一次检测。
在mysql服务运行正常情况下,通过killall命令检测结果如下:
[root@keepalived-master ~]# killall -0 mysqld
[root@keepalived-master ~]# echo $?
0这里通过“echo $?”方式显示了上个命令的返回状态码,mysql服务运行正常,因此返回的状态码为0,此时check_mysqld模块将返回服务检测正常的提示。接着将mysql服务关闭,再次执行检测,结果如下:
[root@keepalived-master ~]# killall -0 mysqld
mysqld: no process killed
[root@keepalived-master ~]# echo $?
1由于mysql服务被关闭,因此返回的状态码为1,此时check_mysqld模块将返回服务检测失败的提示。然后根据vrrp_script模块中设定的“weight”值重新设置Keepalived主、备节点的优先级,进而引发主、备节点发生切换。
从这个过程可以看到,vrrp_script模块其实并不关注监控脚本或监控命令是如何实现的,它仅仅通过监控脚本的返回状态码来识别集群服务是否正常,如果返回状态码为0,那么就认为服务正常,如果返回状态码为1,则认为服务故障。明白了这个原理之后,在进行自定义监控脚本的时候,只需按照这个原则来编写即可。
2. 检测测端口运行状态
检测端口的运行状态,也是最常见的服务监控方式,在Keepalived的vrrp_script模块中可以通过如下方式对本机的端口进行检测:
vrrp_script check_httpd {
script "</dev/tcp/127.0.0.1/80"
interval 2
fall 2
rise 1
}
track_script {
check_httpd
}在这个例子中,通过“</dev/tcp/127.0.0.1/80”这样的方式定义了一个对本机80端口的状态检测,其中,“fall”选项表示检测到失败的最大次数,也就是说,如果请求失败两次,就认为此节点资源发生故障,将进行切换操作;“rise”表示如果请求一次成功,就认为此节点资源恢复正常。
3. 通过shell语句进行状态监控
在Keepalived的vrrp_script模块中甚至可以直接引用shell语句进行状态监控,例如下面这个示例:
vrrp_script chk_httpd {
script "if [ -f /var/run/httpd/httpd.pid ]; then exit 0; else exit 1; fi"
interval 2
fall 1
rise 1
}
track_script {
chk_httpd
}在这个例子中,通过一个shell判断语句,检测httpd.pid文件是否存在,如果存在,就认为状态正常,否则认为状态异常,这种监测方式对于一些简单的应用监控或者流程监控非常有用。从这里也可以得知,vrrp_script模块支持的监控方式十分灵活。
4. 通过脚本进行服务状态监控
这是最常见的监控方式,其监控过程类似于Nagios的执行方式,不同的是,这里只有0、1两种返回状态,例如下面这个示例:
vrrp_script chk_mysqld {
script "/etc/keepalived/check_mysqld.sh"
interval 2
}
track_script {
chk_mysqld
}其中,check_mysqld.sh的内容为:
#!/bin/bash
MYSQL=/usr/bin/mysql
MYSQL_HOST=localhost
MYSQL_USER=root
MYSQL_PASSWORD='xxxxxx'
$MYSQL -h $MYSQL_HOST -u $MYSQL_USER -p$MYSQL_PASSWORD -e "show status;" > /dev/null 2>&1
if [ $? = 0 ] ;then
MYSQL_STATUS=0
else
MYSQL_STATUS=1
fi
exit $MYSQL_STATUS这个一个最简单的实现mysql服务状态检测的shell脚本,它通过登录mysql数据库后执行查询操作来检测mysql运行是否正常,如果检测正常,将返回状态码0,否则返回状态码1。其实很多在Nagios下运行的脚本,只要稍作修改,即可在这里使用,非常方便。
8、keepalived问题排查技巧
检测两个keepalived主机之间是否能通信的办法有:
1. 停掉一个keepalived,看另外一个keepalived的日志/var/log/messages 里是否有新的日志。
2. 用嗅探器抓包,例如:
tcpdump -v -i eth1 host 224.0.0.18
tcpdump -vvv -n -i eth1 host 224.0.0.18其中,224.0.0.18是VRRP组播使用的目的地址,默认为组播每秒发送一次。
另外,在做集群的时候,尽量关闭每个主机上的selinux服务和iptables服务,这样会减少很多问题。
二、heartbeat 高可用方案
1、heartbeat简介
通过heartbeat,可以将资源(IP及程序服务等资源)从一台己经故障的计算机快速转移到另一台正常运转的机器上继续提供服务,一般称之为高可用服务。在实际生产应用场景中,heartbeat的功能和另一个高可用开源软件keepalived有很多相同之处。
heartbeat官方地址:Download - Linux-HA
heartbeat和keepalived的应用场景区别:
1)对于一般的web、db、负载均衡(nginx、haproxy)等等,heartbeat和keepalived都可以实现。
2) lvs负载均衡最好和keepalived结合,虽然heartbeat也可以调用带有ipvsadm命令的脚本来启动和停止lvs负载均衡,但是heartbeat本身并没有对下面节点rs的健康检查功能,heartbeat的这个缺陷可以通过ldircetord插件来弥补,所以,当你搜索heartbeat+lvs+ldirectord可以有lvs的另外解决方案。
3)需要数据同步(配合drbd)的高可用业务最好用heartbeat,例如:mysql双主多从,NFS/MFS存储,他们的特点是需要数据同步,这样的业务最好用heartbeat。因为hearbeat自带了drbd的脚本,可以利用强大的drbd同步软件配合实现同步。如果你解决了数据同步可以不用drbd,例如:共享存储或者inotify+rsync(sersync+rsync),那么就可以考虑keepalived。
4)运维人员对哪个更熟悉就用哪个,其实,就是你要能控制维护你部署的服务。目前,总体网友们更倾向于使用keepalived软件的多一些。
2、heartbeat工作原理
通过修改heartbeat软件的配置文件,可以指定哪一台Heartbeat服务器作为主服务器,则另一台将自动成为热备服务器。然后在热备服务器上配置Heartbeat守护程序来监听来自主服务器的心跳消息。如果热备服务器在指定时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务的所有权,接替主服务器继续不间断的提供服务,从而达到资源及服务高可用性的目的。
以上描述的是heartbeat主备的模式,heartbeat还支持主主模式,即两台服务器互为主备,这时它们之间会相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未受到对方发送的心跳报文,那么,一方就会认为对方失效或者宕机了,这时每个运行正常的主机就会启动自身的资源接管模块来接管运行在对方主机上的资源或者服务,继续为用户提供服务。一般情况下,可以较好的实现一台主机故障后,企业业务仍能够不间断的持续运行。注意:所谓的业务不间断,再故障转移期间也是需要切换时间的,heartbeat的切换时间一般是在5-20秒左右。
另外:和keepahved服务一样,heartbeat高可用是服务器级别的,不是服务级别的。切换的常见条件:
l)服务器宕机。
2)Heartbeat服务本身故障。
3)心跳连接故障。
服务故障不会导致切换,可以通过服务宕机把heartbeat服务停掉。
3、heartbeat心跳连接
经过前面的叙述,读者应该很清楚了,要部署heartbeat服务,至少需要两台主机来完成。那么,要实现高可用服务,这两台主机之间是如何做到互相通信和互相监测的呢?下面是两台heartbeat主机之间通信的一些常用的可行方法:
l)串行电缆(首选,缺点是距离不能太远)
2)一根以太网电缆两网卡直连(推荐,老男孩老师在生产环境常用的方式)
3)以太网电缆,通过交换机等网络设备连接(次选)
次选,增加了交换机故障点,同时,线路不是专用心跳线,容易受其他数据传输的影响,导致心跳报文发送问题。
注意:高可用服务器对上的Heartbeat软件会利用这条心跳线来性查对端的机器是否存活,进而决定是否做故障转移,资源切换,来保证业务的连续性。如条件允许,以上的连接可同时使用,来加大保险系数防止裂脑问题发生。在我的生产环境中,常使用前两者之一或者结合使用。
一根以太网电缆两网卡直连,也是近几年,老男孩在生产环境中选用的。选用原因:简单、容易部署、效果也不错。做一件事情有多种选择,往往到最后都是性价比方面的考虑。如:部居简单,维护方便,效果不是最好的,但也是不错的。这样就好了,并不是做什么都选最好的。实际工作中往往最好的是最不现实的(成本、维护都要考虑)。
4、heartbeat裂脑
1. 什么是裂脑
由于两台高可用服务器对之间在指定时间内,无法互相检测到对方心跳而各自启动故障转移功能,取得了资源及服务的所有权,而此时的两台高可用服务器对都还活着并在正常运行,这样就会导致同一个IP或服务在两端同时启动,存在两个相同的VIP,而发生冲突的严重问题。
两台主机占用同一个VIP地址,当用户写入数据时可能会分别写入到两端,这样可能会导致服务器两端的数据不一致或造成数据丢失,这种情况就被称为裂脑,也有的人称其为分区集群或大脑垂直分割,英文为splitbrain。
2. 导致裂脑发生的原因
一般来说,裂脑的发生,有以下几个原因导致:
1. 高可用服务器对之间心跳线链路故障,导致无法正常通信。
① 心跳线坏了(包括断了,老化)。
② 网卡及相关驱动坏了,IP配置及冲突问题(网卡直连)
③ 心跳线间连接的设备故障(网卡及交换机)
④ 仲裁的机器出问题。
2. 高可用服务器对上开启了防火墙阻挡了心跳消息传输。
3. 高可用服务器对上心跳网卡地址等信息配置不正确,导致发送心跳失败。
4. 其它服务配置不当等原因,如心跳方式不同,心跳广播冲突、软件BUG等。
5、防止裂脑发生的秘籍
发生裂脑时,对业务的影响是极其严重的,有时甚至是致命的。如:两台高可用服务器对之间发生裂脑,导致互相争用同一IP资源,就如同我们在局域网内常见的IP地址冲突一样,两个机器就会有一个或者两个都不正常,影响用户正常访问服务器。如果是应用在数据库或者存储服务这种极重要的高可用上,那就可能会导致用户发布的数据间断的写在两台不同服务器上的恶果,最终数据恢复极困难或难以恢复(当然,有NAS等公共存储的硬件也许会好一些)。
实际生产环境中,我们可以从以下几个方面来防止裂脑问题的发生:
1. 同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还是好的,依然能传送心跳消息。(网卡设备和网线设备)。
2. 检测到裂脑时强行关闭一个心跳节点。(这个功能需特殊设备支持,如Stonith、fence)。相当于程序上备节点发现心跳线故障,发送关机命令到主节点。
3. 做好对裂脑的监控报警(如邮件及手机短信等),在问题发生时人为第一时间介入仲裁,降低损失。百度监控有上行和下行。和人工交互的过程。当然,在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站业务,这个损失是可控的。
4. 启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即,正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
5. 报警报在服务器接管之前,给人员处理留足够时间。
6. 报警后,不直接自动服务器接管,而是由人为人员控制接管。
增加仲裁机制,确定谁该获得资源。这又有几个参考的思路:
l)加一个仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端,不仅心跳线、还有对外服务的本地网络链路断了,这样就主动放弃竞争,让能够ping通参考IP的一端去接管服务。ping不通参考IP的一方可以自我重启,以彻底释放有可能还占用着的那些共享资源(heartbeat也有此功能)。
2)通过第三方软件仲裁谁该获得资源,这个在阿里的集团有类似的软件应用。
6、有关fence设备和仲裁机制案例说明
先说fence,fence只是HA集群环境下的术语,在硬件领域,fence设备其实就是一个智能电源管理设备(IPMI),也叫做Intelligent PowerManagement Interface,如果你去和服务器代理商说fence,他们一定不知道是什么东西(原厂可能知道),你得和他们说是智能电源管理设备或远程管理卡,他们就理解了,老师在视频里说这是一个特殊的插线板,这是fence设备的一种,叫做外部fence,还有一种叫内部fence,是插在服务器里的,不管是内部还是外部fence,这些设备都是带有以太网口的,用来在HA切换触发时通过网络重启服务器。
先说下内部fence的设备,以主流的服务器举例,fence设备在不同的服务器种的名称是不一样的,以下是不同服务器对应的fence设备名称:
1. IBM:RSA(我接触过的最新的设备是RSA II)
2. HP:ILO(我接触过的最新的设备是ILO 2)
3. DELL:1iDRAC(我接触过的最新设备是iDRAC 3)
7、heartbeat消息类型
Heartbeat高可用软件在工作过程中,一般来说,有三种消息类型,具体为:心跳消息、集群转换消息、重传请求。
1. 心跳消息
心跳消息为约150字节的数据包,可能为单播、广播或多播的方式,控制心跳频率及出现故障要等待多久进行故障转换。
2. 集群转换消息
ip-request和ip-request-resp
当主服务器恢复在线状态时,通过ip-request消息要求备机释放主服务器失败时备服务器取得的资源,然后备份服务器关闭释放主服务器失败时取得的资源及服务。
备服务器释放主服务器失败时取得的资源及服务后,就会通过ip-request-resp消息通知主服务器它不在拥有该资源及服务,主服务器收到来自备节点的ip-request-esp消息通知后,启动失败时释放的资源及服务,并开始提供正常的访问服务。
3. 重传请求
rexmit-request控制重传心跳请求。此消息不太重要,细节就不浪费笔墨了。
提示:以上心跳控制消息都使用UDP协议发送到/etc/ha.d/ha.cf文件指定的任意端口,或指定的多播地址。
8、heartbeat IP地址接管和故障转移
Heartbcat是通过IP地址接管和ARP广播进行故障转移的。
ARP广播:在主服务器故障时,备用节点接管资源后,会立即强制更新所有客户端本地的ARP表(即清除客户端本地缓存的失败服务器的vip地址和mac地址的解析记录)。确保客户端和新的主服务器对话。
本节提到的客户端机器是和Heartbeat高可用服务器对在同一网络中的客户机,并不是最终的互联网用户,这里的客户端机器是相对Heartbeat高可用服务器对说的,这点,请读者朋友注意下。
9、VIP/IP别名/辅助IP
真实IP,又被称为管理IP,一般是配置在物理网卡上的实际IP,这可以看作你本人的姓名,如:张三。在负载均衡及高可用环境中,管理IP是不对外提供用户访问服务的,而仅是管理服务器用,如SSH可以通过这个管理IP连接服务器。
VIP是虚拟IP,这只是个概念而己,可能会误导你,实际上就是heartbeat临时绑定在物理网卡上的别名IP(heartbeat 3以上也采用了辅助IP),如etho0:x,x为0-255的任意数字,你可以在一块网卡上绑定多个别名。这个VIP可以看作是你上网的QQ网名、呢称、外号等,需要在DNS配置中把网站域名地址解析到这个VIP地址,由这个VIP对用户提供服务。如:把www.etiantian.org解析到VIP 211.100.98.99上。
这样做的好处就是当提供服务的服务器宕机以后,在接管的服务器上会直接会自动配置上同样的VIP提供服务。如果是使用管理IP的话,来回迁移就难以做到,而且,管理IP迁移走了。我们就只能去机房连接服务器了。VIP的实质就是确保两台服务器各有一个管理IP不动,就是随时可以连上机器,然后,增加绑定其他的IP,这样就算VIP转移走了,也不至于服务器本身连不上,因为还有管理IP呢,读者应该明白了吧?
手工配置VIP的方法:
ifconfig eth0:1 114.44.28.228 netmask 255.255.255.224 up #ip别名
#heartbeat2软件默认是使用这个命令来添加VIP的
ip addr add 10.0.15.1/24 broadcast 10.0.15.255 dev eth0 #辅助IP
#keepalived软件默认使用这个命令来添加VIP,Heartbeat3采用的方案
ip addr可以查看包括别名和辅助ip,用ifconfig无法查到辅助IP配置情况提示:heartbeat和keepalived在启动时就是分别利用上面命令来配置VIP的。在停止时利用下面的命令来删除VIP。以上两种方式配置VIP,在高可用环境中作用是一样的,没什么区别,只是由于当时的系统环境等历史原因,选择的配里命令方式不同。
手工删除VIP的方法:
ip addr del 10.0.15.1/24 broadcast 10.0.15.255 dev eth0 #辅助IP
ifconfig eth0:1 114.44.28.228 netmask 255.255.255.224 down #ip别名
ifconfig eth0:1 down #ip别名特别提示:heartbeat3版本起,不再使用别名,而是使用辅助IP提供服务。
10、部署heartbeat高可用需求
1. 业务需求描述
假设有两台服务器data-l/data-2,其实际IP分别为192.168.80.103(data-1机器),192.168.80.104(data-2机器)。
配置目标:要求heartbeat服务启动后,data-1机器上初始启动VIP:10.0.0.103, data-2机器上初始启动VIP:10.0.0.104,一旦服务器data-1或data-2任意一台机器宕机,在宕机的机器上初始启动的虚拟VIP就会自动切换到在运转正常的机器上,实现了IP资源的自动接管,从而达到高可用无业务影响的目的。
Tips:建议大家把内外网IP配成最后8位相同的方式,这样容易记忆,便于管理。另外,存储服务器之间、存储服务器和交换机之间可配成双千兆网卡绑定(bonding)来提升网卡性能。在我的生产环境中,未做双千兆网卡绑定(bonding)
2. 环境准备
| 名称 |
接口 |
IP |
用途 |
| MASTER |
eth0 |
192.168.80.103 |
管理IP,用于WAN数据转发 |
| eth1 |
192.168.10.103 |
用于服务器间心跳连接(直连) |
|
| VIP |
192.168.80.203 |
用于提供应用程序A挂载服务 |
|
| BACKUP |
eth0 |
192.168.80.104 |
管理IP,用于WAN数据转发 |
| eth1 |
192.168.10.104 |
用于服务器间心跳连接(直连) |
|
| VIP |
192.168.80.204 |
用于提供应用程序B挂载服务 |
在/etc/hosts文件及/etc/sysconfig/network文件中修改主机名。
特别强调:机器名必须和uname -n显示的结果一样。
tips:hosts的配里在heartbeat服务中会用到,后文的drbd及存储的高可用性配里都会用的到。在实际生产环境中,我们会把所有的机器名对应上所有的机器,地址,然后通过cfengine或Puppet或sshkey+rsync工具分发到所有的机器上。网内增加机器时,就会通过分发工具统一分发到所有机器的/etc/hosts中。
3. 配置服务器间心跳连接
eth1 192.168.10.103 和 eth1 192.168.10.104两块网卡之间是通过普通网线直连连接的,即不通过交换机,直接将两块网卡通过网线连在一起,用于做心跳检测或传输数据等。
在两台机器上分别增加一条主机路由,来实现两台机器检查对端时通过这个心跳线线路检查。
data-1 server上添加如下路由:
/sbin/route add -host 192.168.10.104 dev eth1
echo "/sbin/route add -host 192.168.10.104 dev eth1" >>/etc/rc.local
route -ndata-2 server上添加如下路由:
/sbin/route add -host 192.168.10.103 dev eth1
echo "/sbin/route add -host 192.168.10.103 dev eth1" >>/etc/rc.local
route -n4. 安装heartbeat软件
yum install heartbeat -y
yum install heartbeat -y
Or
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum install heartbeat* -y说明:
1. yum install heartbeat -y此处注意一下,安装heartbeat需要执行两遍。
2. heartbeat属于不直接对外服务的软件,又没有特殊的性能需求。
因此,该类软件一般使用yum安装效果更好,部署简单,快速,维护容易。推荐大家使用。在我的3000万pv的生产环境中,heartbeat软件的部署都是yum安装的,跑了几年都没任何问题,所以,才敢在这里推荐给大家。最后,大家选择yum/rpm安装,还是编译安装时,请慎重,当然编译安装也不是不可以的。
5. heartbeat配置文件
默认配置文件目录/etc/ha.d/,常用配置文件:
启动脚本: /etc/init.d/
资源目录: /etc/ha.d/resource.d/
heartbeat的默认配置文件目录为/etc/ha.d。heartbeat常用的配置文件有三个,分别为ha.cf、authkey、haresource,如果你细看,可以发现名字信息就如其实际功能,这里列成表格方便大家学习了解。
cd /usr/share/doc/heartbeat-3.0.4/
cp ha.cf haresources authkeys /etc/ha.d/| 配置名称 |
作用 |
备注 |
| ha.cf |
heartbeat参数配置文件 |
在这里配置heartbeat的一些基本参数 |
| authkey |
heartbeat认证文件 |
高可用服务器对之间根据对端的authkey,对对端进行认证 |
| haresource |
heartbeat资源配置文件 |
如配置IP资源及脚本程序等 |
ha.cf文件设置了heartbeat的检验机制,没有执行机制。haresources用来设置当主服务器出现问题时heartbeat的执行机制。其内容为:当主服务器宕机后,该怎样进行切换操作。切换内容通常有IP地址的切换、服务的切换、共享存储的切换,从而使从服务器具有和主服务器同样的IP、SERVICE、SHARESTORAGE,从而使client没有察觉。在两个HA节点上该文件必须完全一致。
6. ha.cf文件详细说明
| 参数 |
说明 |
| debugfile /var/log/ha-debug |
heartbeat调试日志存放位置 |
| logfile /var/log/ha-log |
heartbeat日志存放位置 |
| logfacility local1 |
在syslog服务中配置通过local1设备接收日志 |
| keepalive 2 |
指定心跳间隔时间为2s(即每2s在eth1上发一次广播) |
| deadtime 30 |
指定若备用节点在30秒内没有收到主节点的心跳信号,则立即接管主节点的服务资源。 |
| warntime 10 |
指定心跳延迟的时间为10秒。当10秒钟内备份节点不能接收到主节点的心跳信号时,就会往日志中写入一个警告日志,但此时不会切换服务 |
| initdead 120 |
指定在HEARTBEAT首次运行后,需要等待120秒才启动主服务器的任何资源。该选项用于解决这种情况产生的时间间隔。取值至少为deadtime的两倍.单机启动时会遇到vip绑定很慢,为正常现象。该值设置的长的原因 |
| bcast eth1 |
指明心跳使用以太网广播方式在ethl接口上进行广播。如使用两个实际网络来传送心跳则#bcast eth0 ethl |
| mcast eth1 225.0.0.1 694 1 0 |
设置广播通信使用的端口,694为默认使用的端口号. |
| auto_failback on |
用来定义当主节点恢复后,是否将服务自动切回。 |
| node data-1 |
主节点主机名,可以通过命令uanme -n查看 |
| node data-2 |
备节点主机名,可以通过命令uanme -n查看 |
| crm no |
是否开启cluster Resource Manager(集群资源管理)功能 |
7. 配置ha.cf文件
[root@data-1 ha.d]# cat ha.cf
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local1
keepalive 2
deadtime 30
warntime 10
initdead 60
mcast eth1 225.0.0.1 694 1 0
auto_failback on
node data-1
node data-2
crm no其中mcast为单播方式IP地址分别为对方的ip地址
8. 配置authkey文件
[root@data-1 ha.d]# cat authkeys
#
# Authentication file. Must be mode 600
#
#
# Must have exactly one auth directive at the front.
# auth send authentication using this method-id
#
# Then, list the method and key that go with that method-id
#
# Available methods: crc sha1, md5. Crc doesn't need/want a key.
#可以设置的认证方法
# You normally only have one authentication method-id listed in this file
#
# Put more than one to make a smooth transition when changing auth
# methods and/or keys.
#
#
# sha1 is believed to be the "best", md5 next best.
#sha1被认为是最好的
# crc adds no security, except from packet corruption.
# Use only on physically secure networks.
#
#auth 1
#1 crc
#2 sha1 HI!
#3 md5 Hello!选择对应的1,2,3选项,去除前面的#即可。
如果您的Heartbeat运行于安全网络之上,如本例中的交叉线,可以使用crc,从资源的角度来看,这是代价最低的方法。如果网络并不安全,但您也希望降低CPU使用,则使用md5。最后,如果您想得到最好的认证,而不考虑CPU使用情况,则使用sha1,它在三者之中最难破解。
默认的配置使用crc方法,这是不加密的,不够安全,下面老男在给大家一个authkcy,其实呢生产配置,就是两行。
[root@data-2 ha.d]# cat authkeys
auth 1
1 sha1 key-for-sha1-any-text-you-want对于md5,只要将上面内容中的sha1换成md5就可以了。 对于crc,可作如下配置:
auth 2
2 crc不论您在关键字auth后面指定的是什么索引值,在后面必须要作为键值再次出现。如果您指定“auth 4”,则在后面一定要有一行的内容为“4 ”。
简单吧,两行搞定。提醒啊,authkeys需要为600,否则heartbeat服务会报错无法开启服务。
chmod 600 authkeys9. 配置haresource文件
生产环境配置如下:
[root@data-1 ha.d]# cat haresources
data-1 IPaddr::192.168.80.203/24/eth0
data-2 IPaddr::192.168.80.204/24/eth0说明:
- ata-1为主机名,表示初始状态会在data-l绑定IP 192.168.80.203
- IPaddr为heartbeat配置IP的默认脚本,其后的IP等都是脚本的参数
- 192.168.80.203/eth0为集群对外服务的VIP,初始启动在dsta-l上
- 24为子网掩码
- etho为IP绑定的实际物理网卡,为heartbeat提供对外服务的通信接口
同理192.168.80.204/eth0为集群对外服务的VIP,初始启动在data-2上,24为子网掩码,etho为iP绑定的实际物理网卡,为heartbeat提供对外服务的通信接口。
data-1 IPaddr:: 192.168.80.203/24/eth0 drbddisk::data Filesystem::/dev/drbd0::/data::ext3 rsdata
192.168.80.203/24/eth0为集群对外服务的VIP,初始启动在dsta-l上,24为子网掩码, etho为iP绑定的实际物理网卡, 为heartbeat提供对外服务的通信接口,这里相当于执行:
/etc/ha.d/resource.d/IPaddr 192.168.80.203/24/eth0 stop/start
drbddisk::data 启动drbddata资源,这里相当于执行/etc/ha.d/resource.d/drbddisk data stop/start
Filesystem::/dev/drbd0::/data::ext3 drbd分区挂载到/data目录,这里相当于执行/etc/ha.d/resource.d/Filesystem /dev/drbd0 /data ext3 stop/start
rsdata 启动mysql服务脚本,这里相当于执行/etc/ha.d/resource.d/rsdata stop/start提示:
以上haresource的配置,实际就是在两台机器上分别执行/etc/ha.d/resource.d/IPaddr 192.168.80.203/24/eth0 stop或/etc/ha.d/resource.d/IPaddr 192.168.80.203/24/eth0 start。
10. 检测heartbeat部署成果
[root@data-1 ha.d]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
INFO: Resource is stopped
Done.
[root@data-2 ha.d]# ip addr
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:49:82:0e brd ff:ff:ff:ff:ff:ff
inet 192.168.80.104/24 brd 192.168.80.255 scope global eth0
inet 192.168.80.204/24 brd 192.168.80.255 scope global secondary eth0
inet6 fe80::20c:29ff:fe49:820e/64 scope link
valid_lft forever preferred_lft forever11. heartbeat实现web高可用案例
1)在两台机器上分别安装http服务,并测试成功,安装配置过程不再阐述。
/etc/init.d/httpd stop
chkconfig httpd off2)配置httpd启动脚本
在两台机器上分别拷贝httpd启动脚本到/etc/ha.d/resource.d/下。并确保具备可执行权限。
cp /etc/init.d/httpd /etc/ha.d/resource.d/
#如果不执行拷贝也ok,heartbeat也可以找到/etc/init.d/httpd3)修改haresource配置文件
data-1 IPaddr::192.168.80.203/24/eth0 httpd #仅仅在之后添加服务名即可4)测试
[root@data-1 ~]# /etc/init.d/heartbeat stop
Stopping High-Availability services: Done.
[root@data-1 ~]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
INFO: Resource is stopped
Done.
[root@data-1 ~]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
httpd 7958 root 8u IPv6 37912 0t0 TCP *:http (LISTEN)
httpd 7960 apache 8u IPv6 37912 0t0 TCP *:http (LISTEN)在备机上查看:
[root@data-2 ~]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
INFO: Resource is stopped
Done.
[root@data-2 ~]# lsof -i:80 #未运行httpd停止主上的heartbeat:
[root@data-1 ~]# /etc/init.d/heartbeat stop
Stopping High-Availability services: Done.在备机上查看:
[root@data-2 ~]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
httpd 7350 root 8u IPv6 28591 0t0 TCP *:http (LISTEN)
httpd 7352 apache 8u IPv6 28591 0t0 TCP *:http (LISTEN)因为heartbeat高可用是服务器级别的,所以停止一台服务器的heartbeat服务,发现备用节点启用,并且启用相关的httpd服务,代表高可用成功。
12. 有关heartbeat调用httpd脚本的说明
- httpd脚本需要放在/etc/init.d下或者/etc/ha.d/resource.d下
- httpd脚本需要具备可执行权限
- httpd必须支持如下的启动方式(完全可以自己写)
[root@data-1 ~]# /etc/init.d/httpd
Usage: httpd {start|stop|restart|condrestart|try-restart|force-reload|reload|status|fullstatus|graceful|help|configtest}13. 有关heartbeat调用资源的生产场景应用
在实际工作中有两种常见方法实现高可用问题:
1)heartbeat可以仅控制vip资源的漂移,不负责服务资源的启动及停止,本节的httpd服务就可以这样做。----适合web服务。
2)heartbeat即控制vip资源的漂移,同时又控制服务资源启动及停止,本节的httpd服务例子既是。-----适合数据库和存储,只能一端写。
VIP正常,httpd服务宕了。这个时候不会做高可用切换。写个简单的脚本定时或守护进程判断httpd服务,如果有问题,则停止heartbeat,主动使其上的业务到另一台。
14. heartbeat服务生产环境下维护要点
修改配置文件要点:
在我们每天的实战运维工作中,当有新项目上线或者VIP更改需求时,可能会进行添加修改服务VIP的操作,那么,下面我们就以heartbeat+haproxy/nginx高可用负载均衡为例给大家讲解下生产环境下的维护方法。
常见的情况就是配置文件,我们知道配置文件有3个,ha.cf、authkey、haresourrc。
1)在修改配置前执行/init.d/heartbeat stop或/usr/lib64/heartbeat/hb_standby(此命令最好)把本机业务推到备节点工作,当确认备节点工作正常后,开始修改本地的配置,修改好后可以在执行/init.d/heartbeat start把资源服务接管回来。记得在把业务推到备节点时及修改配置接管回服务时都要立即检查服务是否工作正常,特别是所有的vip(新的旧的)是否启动OK,URL地址是不是能够打开,这个检查过程可以写成脚本放heartbeat服务启动脚本的参数里等。
2)先修改好一端的配置,然后同步到另一端,此时,准备好如下的命令操作:
/etc/init.d/heartbeat stop
/etc/init.d/heartbeat start
ip addr|egrep "ip1|ip2"
wget url准备好后,拷贝粘贴同时执行上面3条命令,执行完毕后看看iP是否OK,如果5秒内IP不OK,则需要回滚配置或者再次推到备节点。
3)通过hearbeat自带的如下命令脚本临时增加IP,并修改配置但不重启,然后在流量低谷或者夜里在重启服务器(老男孩推荐的方式)。
/etc/ha.d/resource.d/IPaddr 192.168.80.203/24/eth0 start4)流量高峰期不允许轻易操作负载均衡服务器上的相关配置等。
总结:负载均衡和高可用服务器的位置一般来说都非常重要,因此,操作时一定要谨慎小心,一定要记得事先写好操作步骤及回滚步骤,然后再去实施操作,不要逞匹夫之勇,直接动手操作,那样会极容易导致网站宕机影响用户体验,特别是涉及到数据库和存储高可用的heartbeat的维护就要更加小心了。
总结:
1. 日志很重要。不管是heartbeat,所有服务的日志都很重要。有问题时多查看相关日志。
2. httpd的高可用还可以是两边都处于启动状态,即httpd不需要交给ha起,而是默认状态就先启动运行。
3. 这个httpd高可用性配置在生产环境中用的很少,但它确是生产环境需求的一个初级模型。如:heartbeat+drbd+mysql实现数据库高可用性配置,heartbeat+acove/active+nfs/mfs实现存储高可用性配置。
三、Pacemaker 高可用方案
1、集群背景
云计算与集群系统密不可分,作为分布式计算和集群计算的集大成者,云计算的基础设施必须通过集群进行管理控制,而作为拥有大量资源与节点的集群,必须具备一个强大的集群资源管理器(Cluster system Manager, CSM)来调度和管理集群资源。对于任何集群而言,集群资源管理器是整个集群能够正常运转的大脑和灵魂,任何集群资源管理器的缺失和故障都会导致集群陷人瘫痪混乱的状态。
Openstack的众多组件服务既可以集成到单个节点上运行,也可以在集群中分布式运行。但是,要实现承载业务系统的高可用集群, Openstack服务必须部署到高可用集群上,并在实现 Openstack服务无单点故障的同时,实现故障的自动转移和自我愈合,而这些功能是 Openstack的多数服务本身所不具备的。因此,在生产环境中部署 OpenStack高可用集群时,必须引人第三方集群资源管理软件,专门负责 Openstack集群资源的高可用监控调度与管理。
集群资源管理软件种类众多,并有商业软件与开源软件之分。在传统业务系统的高可用架构中,商业集群管理软件的使用非常普遍,如 IBM的集群系统管理器、 PowerHA SystemMirror(也称为 HACMP)以及针对 DB2的 purescale数据库集群软件;再如orcale的 Solaris Cluster系列集群管理软件,以及 oracle数据库的 ASM和 RAC集群管理软件等商业高可用集群软件都在市场上占有很大的比例。此外,随着开源社区的发展和开源生态系统的扩大,很多商业集群软件也正在朝着开源的方向发展,如 IBM开源的 xCAT集软件而在 Linux开源领域。
Pacemaker/Corosync、 HAproxy/Keepalived等组合集群资泖管理软件也有着极为广泛的应用。
2、Pacemaker简介
Pacemaker是 Linux环境中使用最为广泛的开源集群资源管理器, Pacemaker利用集群基础架构(Corosync或者 Heartbeat)提供的消息和集群成员管理功能,实现节点和资源级别的故障检测和资源恢复,从而最大程度保证集群服务的高可用。从逻辑功能而言, pacemaker在集群管理员所定义的资源规则驱动下,负责集群中软件服务的全生命周期管理,这种管理甚至包括整个软件系统以及软件系统彼此之间的交互。 Pacemaker在实际应用中可以管理任何规模的集群,由于其具备强大的资源依赖模型,这使得集群管理员能够精确描述和表达集群资源之间的关系(包括资源的顺序和位置等关系)。同时,对于任何形式的软件资源,通过为其自定义资源启动与管理脚本(资源代理),几乎都能作为资源对象而被 Pacemaker管理。此外,需要指出的是, Pacemaker仅是资源管理器,并不提供集群心跳信息,由于任何高可用集群都必须具备心跳监测机制,因而很多初学者总会误以为 Pacemaker本身具有心跳检测功能,而事实上 Pacemaker的心跳机制主要基于 Corosync或 Heartbeat来实现
从起源上来看, Pacemaker是为 Heartbeat项目而开发的 CRM项目的延续, CRM最早出现于2003年,是专门为 Heartbeat项目而开发的集群资源管理器,而在2005年,随着 Heartbeat2.0版本的发行才正式推出第一版本的 CRM,即 Pacemaker的前身。在2007年末, CRM正式从 Heartbeat2.1.3版本中独立,之后于2008年 Pacemaker0.6稳定版本正式发行,随后的2010年3月 CRM项目被终止,作为 CRM项目的延续, Pacemaker被继续开发维护,如今 Pacemaker已成为开源集群资源管理器的事实标准而被广泛使用。此外, Heartbeat到了3.0版本后已经被拆分为几个子项目了,这其中便包括 Pacemaker、 Heartbeat3.0、 Cluster Glue和 Resource Agent。
1)Heartbeat
Heartbeat项目最初的消息通信层被独立为新的 Heartbeat项目,新的 Heartbeat只负责维护集群各节点的信息以及它们之间的心跳通信,通常将 Pacemaker与 Heartbeat或者 Corosync共同组成集群管理软件, Pacemaker利用 Heartbeat或者Corosync提供的节点及节点之间的心跳信息来判断节点状态。
2)Cluster Clue
Cluster Clue 相当于一个中间层,它用来将Heartbeat和Pacemaker关联起来,主要包含两个部分,即本地资源管理器(Local Resource Manager,LRM)和Fencing设备(Shoot The Other Node In The Head,STONITH)
3)Resource Agent
资源代理(Resource Agent,RA)是用来控制服务的启停,监控服务状态的脚本集合,这些脚本会被位于本节点上的LRM调用从而实现各种资源的启动、停止、监控等操作。
4) pacemaker
Pacemaker是整个高可用集群的控制中心,用来管理整个集群的资源状态行为,客户端通过 pacemaker来配置、管理、监控整个集群的运行状态。Pacemaker是一个功能非常强大并支持众多操作系统的开源集群资源管理器,Pacemaker支持主流的 Linux系统,如 Redhat的 RHEL系列、 Fedora系列、 openSUSE系列、Debian系列、 Ubuntu系列和 centos系列,这些操作系统上都可以运行 Pacemaker并将其作为集群资源管理器。
pacemaker的主要功能包括以下几方面:
1. 监测并恢复节点和服务级别的故障。
2. 存储无关,并不需要共享存储。
3. 资源无关,任何能用脚本控制的资源都可以作为集群服务。
4. 支持节点 STONITH功能以保证集群数据的完整性和防止集群脑裂。
5. 支持大型或者小型集群。
6. 支持 Quorum机制和资源驱动类型的集群。
7. 支持几乎是任何类型的冗余配置。
8. 自动同步各个节点的配置文件。
9. 可以设定集群范围内的 Ordering、 Colocation and Anti-colocation等约束。
10. 高级服务类型支持,例如:Clone功能,即那些要在多个节点运行的服务可以通过 Clone功能实现, Clone功能将会在多个节点上启动相同的服务;Multi-state功能,即那些需要运行在多状态下的服务可以通过 Multi--state实现,在高可用集群的服务中,有很多服务会运行在不同的高可用模式下,如:Active/Active模式或者 Active/passive模式等,并且这些服务可能会在 Active 与standby(Passive)之间切换。
11. 具有统一的、脚本化的集群管理工具。
3、pacemaker的服务模式
Pacemaker对用户的环境没有特定的要求,这使得它支持任何类型的高可用节点冗余配置,包括 Active/Active、 Active/Passive、N+1、 N+M、 N-to-1 and N-to-N模式的高可用集群,用户可以根据自身对业务的高可用级别要求和成本预算,通过 Pacemaker部署适合自己的高可用集群。
1) Active/Active模式
在这种模式下,故障节点上的访问请求或自动转到另外一个正常运行节点上,或通过负载均衡器在剩余的正常运行的节点上进行负载均衡。这种模式下集群中的节点通常部署了相同的软件并具有相同的参数配置,同时各服务在这些节点上并行运行。
2) Active/Passive模式
在这种模式下,每个节点上都部署有相同的服务实例,但是正常情况下只有一个节点上的服务实例处于激活状态,只有当前活动节点发生故障后,另外的处于 standby状态的节点上的服务才会被激活,这种模式通常意味着需要部署额外的且正常情况下不承载负载的硬件。
3)N+1模式
所谓的N+1就是多准备一个额外的备机节点,当集群中某一节点故障后该备机节点会被激活从而接管故障节点的服务。在不同节点安装和配置有不同软件的集群中,即集群中运行有多个服务的情况下,该备机节点应该具备接管任何故障服务的能力,而如果整个集群只运行同一个服务,则N+1模式便退变为 Active/Passive模式。
4) N+M模式
在单个集群运行多种服务的情况下,N+1模式下仅有的一个故障接管节点可能无法提供充分的冗余,因此,集群需要提供 M(M>l)个备机节点以保证集群在多个服务同时发生故障的情况下仍然具备高可用性, M的具体数目需要根据集群高可用性的要求和成本预算来权衡。
5) N-to-l模式
在 N-to-l模式中,允许接管服务的备机节点临时成为活动节点(此时集群已经没有备机节点),但是,当故障主节点恢复并重新加人到集群后,备机节点上的服务会转移到主节点上运行,同时该备机节点恢复 standby状态以保证集群的高可用。
6) N-to-N模式
N-to-N是 Active/Active模式和N+M模式的结合, N-to-N集群将故障节点的服务和访问请求分散到集群其余的正常节点中,在N-to-N集群中并不需要有Standby节点的存在、但是需要所有Active的节点均有额外的剩余可用资源。
4、Pacemaker的架构
从高层次的集群抽象功能来看, Pacemaker的核心架构主要由集群不相关组件、集群资源管理组件和集群底层基础模块三个部分组成。
1)底层基础模块
底层的基础架构模块主要向集群提供可靠的消息通信、集群成员关系和等功能,底层基础模块主要包括像 corosync、 CMAN和 Heartbeat等项目组件。
2)集群无关组件
在 Pacemaker架构中,这部分组件主要包括资源本身以及用于启动、关闭以及监控资源状态的脚本,同时还包括用于屏蔽和消除实现这些脚本所采用的不同标准之间差异的本地进程。虽然在运行多个实例时,资源彼此之间的交互就像一个分布式的集群系统,但是,这些实例服务之间仍然缺乏恰当的 HA机制和独立于资源的集群治理能力,因此还需要后续集群组件的功能支持。
3)资源管理
Pacemaker就像集群大脑,专门负责响应和处理与集群相关的事件,这些事件主要包括集群节点的加人、集群节点脱离,以及由资源故障、维护、计划的资源相关操作所引起的资源事件,同时还包括其他的一些管理员操作事件,如对配置文件的修改和服务重启等操作。在对所有这些事件的响应过程中, Pacemaker会计算出当前集群应该实现的最佳理想状态并规划出实现该理想状态后续需要进行的各种集群操作,这些操作可能包括了资源移动、节点停止,甚至包括使用远程电源管理模块来强制节点下线等。
当Pacemaker与 Corosync集成时, Pacemaker也支持常见的主流开源集群文件系统,而根据集群文件系统社区过去一直从事的标准化工作,社区使用了一种通用的分布式锁管理器来实现集群文件系统的并行读写访问,这种分布式锁控制器利用了 Corosync所提供的集群消息和集群成员节点处理能力(节点是在线或离线的状态)来实现文件系统 集群,同时使用Pacemaker来对服务进行隔离。
5、Pacemake内部组件
Pacemaker作为一个独立的集群资源管理器项目,其本身由多个内部组件构成,这些内部组件彼此之间相互通信协作并最终实现了集群的资源管理, Pacemaker项目由五个内部组件构成,各个组件之间的关系如右图所示。
CIB:集群信息基础( Cluster Information Base)。
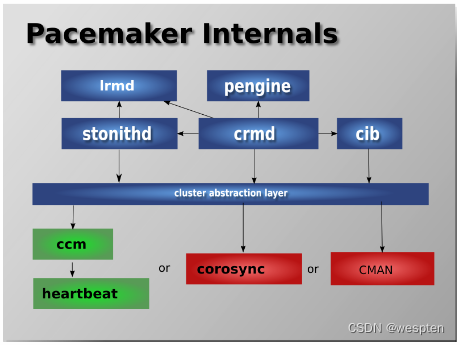
CRMd:集群资源管理进程( Cluster Resource Manager deamon)。
LRMd:本地资源管理进程(Local Resource Manager deamon)。
PEngine(PE):策略引擎(PolicyEngine)。
STONITHd:集群 Fencing进程( Shoot The Other Node In The Head deamon)。
CIB主要负责集群最基本的信息配置与管理,Pacemaker中的 CIB主要使用 XML的格式来显示集群的配置信息和集群所有资源的当前状态信息。CIB所管理的配置信息会自动在集群节点之间进行同步, PE将会使用 CIB所提供的集群信息来规划集群的最佳运行状态。并根据当前 CIB信息规划出集群应该如何控制和操作资源才能实现这个最佳状态,在 PE做出决策之后,会紧接着发出资源操作指令,而 PE发出的指令列表最终会被转交给集群最初选定的控制器节点( Designated controller,DC),通常 DC便是运行 Master CRMd的节点。
在集群启动之初, pacemaker便会选择某个节点上的 CRM进程实例来作为集群 Master CRMd,然后集群中的 CRMd便会集中处理 PE根据集群 CIB信息所决策出的全部指令集。在这个过程中,如果作为 Master的 CRM进程出现故障或拥有 Master CRM进程的节点出现故障,则集群会马上在其他节点上重新选择一个新的 Master CRM进程。
在PE的决策指令处理过程中, DC会按照指令请求的先后顺序来处理PEngine发出的指令列表,简单来说, DC处理指令的过程就是把指令发送给本地节点上的 LRMd(当前节点上的 CRMd已经作为 Master在集中控制整个集群,不会再并行处理集群指令)或者通过集群消息层将指令发送给其他节点上的 CRMd进程,然后这些节点上的 CRMd再将指令转发给当前节点的 LRMd去处理。当集群节点运行完指令后,运行有 CRMd进程的其他节点会把他们接收到的全部指令执行结果以及日志返回给 DC(即 DC最终会收集全部资源在运行集群指令后的结果和状态),然后根据执行结果的实际情况与预期的对比,从而决定当前节点是应该等待之前发起的操作执行完成再进行下一步的操作,还是直接取消当前执行的操作并要求 PEngine根据实际执行结果再重新规划集群的理想状态并发出操作指令。
在某些情况下,集群可能会要求节点关闭电源以保证共享数据和资源恢复的完整性,为此, Pacemaker引人了节点隔离机制,而隔离机制主要通过 STONITH进程实现。 STONITH是一种强制性的隔离措施, STONINH功能通常是依靠控制远程电源开关以关闭或开启节点来实现。在 Pacemaker中, STONITH设备被当成资源模块并被配置到集群信息 CIB中,从而使其故障情况能够被轻易地监控到。同时, STONITH进程( STONITHd)能够很好地理解 STONITH设备的拓扑情况,因此,当集群管理器要隔离某个节点时,只需 STONITHd的客户端简单地发出 Fencing某个节点的请求, STONITHd就会自动完成全部剩下的工作,即配置成为集群资源的 STONITH设备最终便会响应这个请求,并对节点做出 Fenceing操作,而在实际使用中,根据不同厂商的服务器类型以及节点是物理机还是虚拟机,用户需要选择不同的 STONITH设备。
6、Pacemaker集群管理工具pcs
可以用用 cibadmin命令行工具来查看和管理 pacemaker的集群配置信息,集群 CIB中的配置信息量非常大而且以 XML语言呈现,对于仅由极少数节点和资源所组成的集群,cibadmin也许是个可行方案。但是,对于拥有大量节点和资源的大规模集群,通过编辑 XML文件来查看修改集群配置显然是非常艰难而且极为不现实的工作由于 XML文件内容条目极多,因此用户在修改 XML文件的过程中极易出现人为错误。而在开源社区里,简单实用才是真正开源精神的体现,对于开源系统中任何文件配置参数的修改,简化统一的命令行工具才是最终的归宿。
随着开源集群软件Pacemaker版本的不断更新,社区推出了两个常用的集群管理命令行工具,即集群管理员最为常用的 pcs和 crmsh命令。本文使用的是 pcs命令行工具,关于 crmsh的更多使用方法和手册可以参考Pacemaker的官方网站。在 pacemaker集群中PCS命令行工具几乎可以实现集群管理的各种功能,例如,全部受控的 pacemaker和配置属性的变更管理都可以通过 pcs实现。此外,需要注意的是, pcs命令行的使用对系统中安装的 pacemaker和 corosync软件版本有一定要求,即 Pacemaker1.1.8及其以上版本, Corosync 2.0及其以上版本才能使用 pcs命令行工具进行集群管理。
pcs命令可以管理的集群对象类别和具体使用方式可以通过pcs --help参数查看:
[root@controller1 ~]# pcs --help
Usage: pcs [-f file] [-h] [commands]...
Control and configure pacemaker and corosync.
Options:
-h, --help Display usage and exit.
-f file Perform actions on file instead of active CIB.
--debug Print all network traffic and external commands run.
--version Print pcs version information.
--request-timeout Timeout for each outgoing request to another node in
seconds. Default is 60s.
Commands:
cluster Configure cluster options and nodes.
resource Manage cluster resources.
stonith Manage fence devices.
constraint Manage resource constraints.
property Manage pacemaker properties.
acl Manage pacemaker access control lists.
qdevice Manage quorum device provider on the local host.
quorum Manage cluster quorum settings.
booth Manage booth (cluster ticket manager).
status View cluster status.
config View and manage cluster configuration.
pcsd Manage pcs daemon.
node Manage cluster nodes.
alert Manage pacemaker alerts.最为常用的管理命令有:
cluster:配置集群选项和节点。
status:查看当前集群资源和节点以及进程状态。
resource:创建和管理集群资源。
constraint:管理集群资源约束和限制。
property:管理集群节点和资源属性。
config:以用户可读格式显示完整集群配置信息。
7、Pacemaker集群资源管理
1. 集群资源代理
在 pacemaker高可用集群中,资源就是集群所维护的高可用服务对象。根据用户的配置,资源有不同的种类,其中最为简单的资源是原始资源(primitive Resource),此外还有相对高级和复杂的资源组(Resource Group)和克隆资源(Clone Resource)等集群资源概念。在 Pacemaker集群中,每一个原始资源都有一个资源代理(Resource Agent, RA), RA是一个与资源相关的外部脚本程序,该程序抽象了资源本身所提供的服务并向集群呈现一致的视图以供集群对该资源进行操作控制。通过 RA,几乎任何应用程序都可以成为 Pacemaker集群的资源从而被集群资源管理器和控制。RA的存在,使得集群资源管理器可以对其所管理的资源“不求甚解",即集群资源管理器无需知道资源具体的工作逻辑和原理( RA已将其封装),资源管理器只需向 RA发出 start、 stop、Monitor等命令, RA便会执行相应的操作。从资源管理器对资源的控制过程来看,集群对资源的管理完全依赖于该资源所提供的,即资源的 RA脚本功能直接决定了资源管理器可以对该资源进行何种控制,因此一个功能完善的 RA在发行之前必须经过充分的功能测试。在多数情况下,资源 RA以 shell脚本的形式提供,当然也可以使用其他比较流行的如 c、 python、 perl等语言来实现 RA。
在 pacemaker集群中,资源管理器支持不同种类的资源代理,这些受支持的资源代理包括 OCF、LSB、 Upstart、 systemd、 service、 Fencing、 Nagios Plugins,而在 Linux系统中,最为常见的有 OCF(open Cluster Framework)资源代理、 LSB( Linux standard Base)资源代理、systemd和 service资源代理。
1) OCF
OCF是开放式集群框架的简称,从本质上来看, OCF标准其实是对 LSB标准约定中 init脚本的一种延伸和扩展。 OCF标准支持参数传递、自我功能描述以及可扩展性,此外,OCF标准还严格定义了操作执行后的返回代码,集群资源管理器将会根据0资源代理返回的执行代码来对执行结果做出判断。因此,如果OCF脚本错误地提供了与操作结果不匹配的返回代码,则执行操作后的集群资源行为可能会变得莫名其妙,而对于不熟悉OCF脚本的用户,这将会是个非常困惑和不解的问题,尤其是当集群依赖于OCF返回代码来在资源的完全停止状态、错误状态和不确定状态之间进行判断的时候。因此,在OCF脚本发行使用之前一定要经过充分的功能测试,否则有问题的OCF脚本将会扰乱整个集群的资源管理。在Pacemaker集群中,OCF作为一种可以自我描述和高度灵活的行业标准,其已经成为使用最多的资源类别。
2) LSB
LSB是最为传统的 Linux“资源标准之一,例如在 Redhat的 RHEL6及其以下版本中(或者对应的 centos版本中),经常在/etc/init.d目录下看到的资源启动脚本便是LSB标准的资源控制脚本。通常,LSB类型的脚本是由操作系统的发行版本提供的,而为了让集群能够使用这些脚本,它们必须遵循 LSB的规定, LSB类型的资源是可以配置为系统启动时自动启动的,但是如果需要通过集群资源管理器来控制这些资源,则不能将其配置为自动启动,而是由集群根据策略来自行启动。
3) Systemd
在很多 Linux的最新发行版本中, systemd被用以替换传统“sysv"风格的系统启动初始化进程和脚本,如在 Redhat的 RHEL7和对应的 centos7操作系统中,systemd已经完全替代了 sysvinit启动系统,同时 systemd提供了与 sysvinit以及 LSB风格脚本兼容的特性,因此老旧系统中已经存在的服务和进程无需修改便可使用 systemd在 systemd中,服务不再是/etc/init.d目录下的 shell脚本,而是一个单元文件( unit-file),Systemd通过单元文件来启停和控制服务, Pacemaker提供了管理 Systemd类型的应用服务的功能。
4) Service
Service是 Pacemaker支持的一种特别的服务别名,由于系统中存在各种类型的服务(如 LSB、 Systemd和 OCF), Pacemaker使用服务别名的方式自动识别在指定的集群节点上应该使用哪一种类型的服务。当一个集群中混合有 Systemd、 LSB和 OCF类型资源的时候,Service类型的资源代理别名就变得非常有用,例如在存在多种资源类别的情况下,Pacemaker将会自动按照 LSB、 Systemd、 Upstart的顺序来查找启动资源的脚本。在 pacemaker中,每个资源都具有属性,资源属性决定了该资源 RA脚本的位置,以及该资源隶属于哪种资源标准。例如,在某些情况下,用户可能会在同一系统中安装不同版本或者不同来源的同一服务(如相同的 RabbitMQ Cluster安装程序可能来自 RabbitMQ官方社区也可能来自 Redhat提供的 RabbitMQ安装包),在这个时候,就会存在同一服务对应多个版本资源的情况,为了区分不同来源的资源,就需要在定义集群资源的时候通过资源属性来指定具体使用哪个资源。
在pacemaker集群中,资源属性由以下几个部分构成:
Resource_id:用户定义的资源名称。
Standard:脚本遵循的标准,允许值为OCF、Service、Upstart、Systemd、LSB、Stonith。
Type:资源代理的名称,如常见的IPaddr便是资源的。
Provider:OCF规范允许多个供应商提供同一资源代理,Provider即是指资源脚本的提供者,多数OCF规范提供的资源代均使用Heartbeat作为Provider。
例如在集群中创建一个名称为VirtualIP:
Resource_id Standard:Provider:Type
pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 nic=eth2 常用的命令方法:
pcs resource list:查看集群中所有可用资源列表。
pcs resource standards:查看支持的资源代理标准。
pcs resource providers:查看集群中可用资源代理提供程序列表。
pcs resource describe Standard:Provider:Type 查看Standard:Provider:Type指定的资源代理的详细信息。
pcs resource cleanup resource_id:重置资源状态。
1、查看http的资源代理
[root@controller1 ~]# pcs resource list |grep http
service:httpd - systemd unit file for httpd
systemd:httpd - systemd unit file for httpd
2、查看怎么创建http资源:
[root@controller1 ~]# pcs resource describe systemd:httpd
systemd:httpd - systemd unit file for httpd
Cluster Controlled httpd
Default operations:
start: interval=0s timeout=100
stop: interval=0s timeout=100
monitor: interval=60 timeout=100
3、创建http资源:
[root@controller1 ~]# pcs resource create http systemd:httpd2. 集群资源约束
集群是由众多具有特定功能的资源组成的集合,集群中的每个资源都可以对外提供独立服务,但是资源彼此之间存在依赖与被依赖的关系。如资源B的启动必须依赖资源A的存在,因此资源A必须在资源B之前启动,再如资源A必须与资源B位于同一节点以共享某些服务,则资源 B与 A在故障切换时必须作为一个逻辑整体而同时迁移到其他节点,在 pacemaker中,资源之间的这种关系通过资源约束或限制(Resource constraint)来实现。
pacemaker集群中的资源约束可以分为以下几类:
位置约束(Location):位置约束限定了资源应该在哪个集群节点上启动运行。
顺序约束(Order):顺序约束限定了资源之间的启动顺序。
资源捆绑约束(Colocation):捆绑约束将不同的资源捆绑在一起作为一个逻辑整体,即资源 A位于 c节点,则资源 B也必须位于 c节点,并且资源 A、 B将会同时进 行故障切换到相同的节点上。
在资源配置中, Location约束在限定运行资源的节点时非常有用,例如在 Openstack高可用集群配置中,我们希望 Nova-ompute资源仅运行在计算节点上,而nova-api和 Neutron-sever等资源仅运行在控制节点上,这时便可通过资源的Location约束来实现。例如,我们先给每一个节点设置不同的 osprole属性(属性名称可自定义),计算节点中该值设为 compute,控制节点中该值设为 controller,如下:
pcs property set --node computel Osprole=compute
pcs property set --node computel osprole=compute
pcs property set --node controller1 osprole=controller
pcs property set --node controller2 osprole=controller
pcs property set --node controller3 osprole=controller然后,通过为资源设置 Location约束,便可将 Nova-compute资源仅限制在计算节点上运行,Location约束的设置命令如下:
pcs constraint location nova-compute-clone rule resource-discovery=exclusive score=0 osprole eq compute即资源 Nova-compute-clone仅会在 osprole等于 compute的节点上运行,也即计算节点上运行。
在 pacemaker集群中,order约束主要用来解决资源的启动依赖关系,资源启动依赖在Linux系统中非常普遍。例如在Openstack高可用集群配置中,需要先启动基础服务如 RabbitMQ和 MySQL等,才能启动 Openstack的核心服务,因为这些服务都需要使用消息队列和数据库服务;再如在网络服务 Neutron中,必须先启动Neutron-server服务,才能启动Neutron的其他 Agent服务,因为这些 Agent在启动时均会到 Neutron-sever中进行服务注册。 Pacemaker集群中解决资源启动依赖的方案便是 order约束。
例如,在 openstack的网络服务 Neutron配置中,与 Neutron相关的资源启动顺序应该如下:Keystone-->Neutron-server-->Neutron-ovs-cleanup-->Neutron-netns-cleanup-->Neutron-openvswitch-agent-->Neutron-dncp-agent-->Neutron-l3-agent。上述依赖关系可以通过如下Order约束实现:
pcs constraint order start keystone-clone then neutron-server-api-clone
pcs constraint order start neutron-server-api-clone then neutron-ovs-cleanup-clone
pcs constraint order start neutron-ovs-cleanup-clone then Neutron-netns-cleanup-clone
pcs constraint order start Neutron-netns-cleanup-clonethen Neutron-openvswitch-agent-clone
pcs constraint order start Neutron-openvswitch-agent-clone then Neutron-dncp-agent-clone
pcs constraint order start Neutron-dncp-agent-clone then Neutron-l3-agent-cloneColocation约束主要用于根据资源 A的节点位置来决定资源 B的位置,即在启动资源 B的时候,会依赖资源 A的节点位置。例如将资源 A与资源 B进行 Colocation约束,假设资源A已经运行在 node1上,则资源 B也会在node1上启动,而如果node1故障,则资源B与 A会同时切换到node2而不是其中某个资源切换到 node3。在 Openstack高可用集群配置中,通常需要将 Libvirtd-compute与 Neutron-openvswitch-agent进行资源捆绑,要将 Nova-compute与 Libvirtd-compute进行资源捆绑,则 Colocation约束的配置如下:
pcs constraint colocation add nova-compute-clone with libvirtd-compute-clone
pcs constraint colocation add libvirtd-compute-clone with neutron-openvswitch-agent-compute-cloneLocation约束、 Order约束和 Colocation约束是 Pacemaker集群中最为重要的三个约束通过这几个资源约束设置,集群中看起来彼此独立的资源就会按照预先设置有序运行。
3. 集群资源类型
在 Pacemaker集群中,各种功能服务通常被配置为集群资源,从而接受资源管理器的调度与控制,资源是集群管理的最小单位对象。在集群资源配置中,由于不同高可用模式的需求,资源通常被配置为不同的运行模式,例如 Active/Active模式、 Active/Passive模式以及 Master/Master模式和 Master/Slave模式,而这些不同资源模式的配置均需要使用 Pacemaker提供的高级资源类型,这些资源类型包括资源组、资源克隆和资源多状态等。
1)资源组
在Pacemaker集群中,经常需要将多个资源作为一个资源组进行统一操作,例如将多个相关资源全部位于某个节点或者同时切换到另外的节点,并且要求这些资源按照一定的先后顺序启动,然后以相反的顺序停止,为了简化同时对多个资源进行配置,供了高级资源类型一资源组。通过资源组,用户便可并行配置多个资源,资源组的创建很简单,其语法格式如下:
pcs resource group add group_name resource_id ... [resource_id] [--before resource_id] --after resource_id使用该命令创建资源组时,如果指定的资源组目前不存在,则此命令会新建一个资源组,如果指定的资源组已经存在,则此命令会将指定的资源添加到该资源组中并且组中的资源会按照该命令中出现的先位置顺序启动,并以相反的顺序停止。在该命令中,还可使用--before和--after参数指定所添加的资源与组中已有资源的相对启动顺序。在为资源组添加资源时,不仅可以将已有资源添加到组中,还可以在创建资源的同时顺便将其添加到指定的资源组中,命令语法如下:
pcs resource create resource_id Standard:Provider:Type丨 type [ resource_options] [op operation_action operation_options] --group group_name如下是资源组操作中经常使用的命令语法:
将资源从组中删除,如果该组中没有资源,这个命令会将该组删除:
pcs resource group remove group_name resource_id ...查看目前巳经配置的资源组:
pcs resource group list创建名为Mygroup的资源组,并添加资源 IPaddr和 HAproxy:
pcs resource group add MyGroup IPaddr HAproxy在 Pacemaker集群中,资源组所包含的资源数目是不受限的,资源组中的资源具有如下的基本特性:
资源按照其指定的先后顺序启动,如在前面示例的 MyGroup资源组中,首先启动 IPaddr,然后启动 HAproxy。
资源按照其指定顺序的相反顺序停止,如首先停止 HAproxy,然后停止 IPaddr。
如果资源组中的某个资源无法在任何节点启动运行,那么在该资源后指定的任何资源都将无法运行,如 IPaddr不能启动,则 HAproxy也不能启动。
资源组中后指定资源不影响前指定资源的运行,如 HAproxy不能运行,但IPaddr却可以正常运行。
在集群资源配置过程中,随着资源组成员的增加,集群资源的配置工作将会明显减少,因为管理员只需要添加资源到资源组中,然后便可对资源组进行整体操作。资源组具有组属性,并且资源组会继承组成员的部分属性,主要被继承的资源属性包括 Priority、Targct-role、Is-managed等,资源属性决定了资源在集群中的行为规范,以及资源管理器可以对其进行哪些操作,因此,了解资源的常见属性也是非常有必要的,如下是资源属性中比较重要的几个属性解释及其默认值。
Priority:资源优先级,其默认值是0,如果集群无法保证所有资源都处于运行状态,则低优先权资源会被停止,以便让高优先权资源保持运行状态。
Target-role:资源目标角色,其默认值是started'表示集群应该让这个资源处于何种状态,允许值为:
Stopped:表示强制资源停止;
Started:表示允许资源启动,但是在多状态资源的情况下不能将其提升为 Master资源;
Master:允许资源启动,并在适当时将其提升为 Master。
is-managed:其默认值是true,表示是否允许集群启动和停止该资源,false表示不允许。
Resource-stickiness:默认值是0,表示该资源保留在原有位置节点的倾向程度值。
Requires:默认值为 fencing,表示资源在什么条件下允许启动。
2)资源克隆
克隆资源是Pacemaker集群中的高级资源类型之一,通过资源克隆,集群管理员可以将资源克隆到多个节点上并在启动时使其并行运行在这些节点上,例如可以通过资源克隆的形式在集群中的多个节点上运行冗余IP资源实例,并在多个处于 Active状态的资源之间实现负载均衡。通常而言,凡是其资源代理支持克隆功能的资源都可以实现资源克隆,但需要注意的是,只有己经规划为可以运行在Active/Active高可用模式的资源才能在集群中配置为克隆资源。配置克隆资源很简单,通常在创建资源的过程中同时对其进行资源克隆,克隆后的资源将会在集群中的全部节点上存在,并且克隆后的资源会自动在其后添加名为 clone的后缀并形成新的资源 ID,资源创建并克隆资源的语法如下:
pcs resource create resource_id standard:provider: type| type [resource options] --clone[meta clone_options]克隆后的资源 ID不再是语法中指定的 Resource_id,而是 Resource_id-clone并且该资源会在集群全部节点中存在。在 Pacemaker集群中,资源组也可以被克隆,但是资源组克隆不能由单一命令完成,必须先创建资源组然后再对资源组进行克隆,资源组克隆的命令语法如下:
pcs resource clone resource_id group_name [clone_optione] ...克隆后资源的名称为 Resource_id-clone或 Group_name-clone在资源克隆命令中,可以指定资源克隆选项(clone_options),如下是常用的资源克隆选项及其意义。
Priority/Target-role/ls-manage:这三个克隆资源属性是从被克隆的资源中继承而来的,具体意义可以参考上一节中的资源属性解释。
Clone-max:该选项值表示需要存在多少资源副本才能启动资源,默认为该集群中的节点数。
Clone-node-max:表示在单一节点上能够启动多少个资源副本,默认值为1。
Notify:表示在停止或启动克隆资源副本时,是否在开始操作前和操作完成后告知其他所有资源副本,允许值为 False和 True,默认值为 False。
Globally-unique:表示是否允许每个克隆副本资源执行不同的功能,允许值为 False和 True。如果其值为 False,则不管这些克隆副本资源运行在何处,它们的行为都是完全和同的,因此每个节点中有且仅有一个克隆副本资源处于 Active状态。其值为 True,则运行在某个节点上的多个资源副本实例或者不同节点上的多个副本实例完全不一样。如果Clone-node-max取值大于1,即一个节点上运行多个资源副本,那么 Globally-unique的默认值为 True,否则为 False。
Ordered:表示是否顺序启动位于不同节点上的资源副本,“。为顺序启动,、为并行启动,默认值是 False。
Interleave:该属性值主要用于改变克隆资源或者 Masters资源之间的 ordering约束行为, Interleave可能的值为 True和 False,如果其值为 False,则位于相同节点上的后一个克隆资源的启动或者停止操作需要等待前一个克隆资源启动或者停止完成才能进行,而如果其值为 True,则后一个克隆资源不用等待前一个克隆资源启动或者停止完成便可进行启动或者停止操作。 Interleave的默认值为 False。
在通常情况下,克隆资源会在集群中的每个在线节点上都存在一个副本,即资源副本数目与集群节点数目相等,但是,集群管理员可以通过资源克隆选项Clone-max将资源副本数目设为小于集群节点数目,如果通过设置使得资源副本数目小于节点数目,则需要通过资源位置约束( Location Constraint)将资源副本指定到相应的节点上,设置克隆资源的位置约束与设置常规资源的位置约束类似。例如要将克隆资源 Web-clone限制在 node1节点上运行,则命令语法如下:
pcs constraint location web-clone prefers node13)资源多态
多状态资源是 Pacemaker集群中实现资源 Master/Master或 Master/S1ave高可用模式的机制,并且多态资源是一种特殊的克隆资源,多状态资源机制允许资源实例在同一时刻仅处于 Master状态或者Slave状态。多状态资源的创建只需在普通资源创建的过程中指定一 Master参数即可,Master/Slave多状态类型资源的创建命令语法如下:
pcs resource create resource_id standard:provider: type| type [resource options] --master [meta master_options]多状态资源是一种特殊的克隆资源,默认情况下,多状态资源创建后也会在集群的全部节点中存在,多状态资源创建后在集群中的资源名称形如 Resource_id-master。需要指出的是,在 Master/Slave高可用模式下,尽管在集群中仅有一个节点上的资源会处于 Master状态,其他节点上均为 Slave状态,但是全部节点上的资源在启动之初均为 Slave状态,之后资源管理器会选择将某个节点的资源提升为 Master。另外,用户还可以将已经存在的资源或资源组创建为多状态资源,命令语法如下:
pcs resource master master/slave_name resource_id group_name [master_options]在多状态资源的创建过程中,可以通过Master选项( Master_options)来设置多状态资源的属性,Master_options主要有以下两种属性值:
Master-max:其值表示可将多少个资源副本由Slave状态提升至 Master状态,默认值为1,即仅有一个 Master。
Master-node-max:其值表示在同一节点中可将多少资源副本提升至 Master状态,默认值为1。
在通常情况下,多状态资源默认会在每个在线的集群节点中分配一个资源副本,如果希望资源副本数目少于节点数目,则可通过资源的Location约束指定运行资源副本的集群节点,多状态资源的Location约束在实现的命令语法上与常规资源没有任何不同。此外,在配置多状态资源的Ordering约束时,可以指定对资源进行的操作是提升(Promote)还是降级(Demote)操作:
Promote操作即是将对应的资源(resource_id)提升为 Master状态, Demote操作即是将资源(resource_id)降级为 Slave状态,通过 ordering约束即可设定被提升或降级资源的顺序。
4)集群资源规则
资源规则(Rule)使得 pacemaker集群资源具备了更强的动态调节能力,资源规则最常见的使用方式就是在集群资源运行时设置一个合理的粘性值(Resource-stickness)'以防止资源回切到资源创建之初指定的高优先级节点上,即动态改变资源粘性值以防止资源意外回切。在大规模的集群资源配置中,资源规则的另一重要作用就是通过设置节点属性,将多个具有某一相同属性值的物理节点聚合到一个逻辑组中,然后通过资源的 Location约束,利用节点组的这个共有节点属性值,将资源限制在该节点组上运行,即只允许此节点组中的节点运行该资源,在 Openstack高可用集群配置中,将会使用这种方式来限制不同的资源运行在不同的节点组上(控制节点组和计算节点组),大致的配置方式就是先为选定的节点设置某一自定义属性,以将其归纳到一个节点组,如下配置命令将计算节点和控制节点分别设置为不同的节点属性:
pcs property set --node computel osprole=compute
pcs property set --node computel osprole=compute
pcs property set --node controller1 osprole=controller
pcs property set --node controller2 osprole=controller
pcs property set --node controller3 osprole=controller此处通过为节点分别设置不同的osprole属性值,将节点划分为两个集合,即计算节点组和控制节点组,将节点 compute1和 compte2归纳到 compute节点组,节点controller1、controller2以及 controller3归纳到 controller节点组,然后通过资源的 Location约束将资源限制到不同的节点组中运行,配置命令如下:
pcs constraint location nova-compute-clone rule resource-discovery=exclusive score=0 osprole eq compute
pcs constraint location nova-api-clone rule resource-discovery=exclusive score=0 osprole eq controller在上述命令中,当Rule表达式“osprole-compute" 或者"osprole=controller"成立,即Rule为True,则执行对应资源的Location约束。此处,通过资源Location 约束的“ resource-discovery-exclusive"配置,资源nova-compute-clone只能运行在compute节点组中,而 compute组中只有 compute1和compute2节点,因此nova-compute-clone只能在 compute1和 compute2上运行,绝不会在 controller1、controller2及controller3上运行。同样, nova-api-clone资源只会在controller组中的三个节点上运行。绝不会在 compute1和 compute2节点上运行。
在Pacemaker集群中,每个资源的 Rule都会包含一个或多个数字、时间及日期表达式, Rule最终的取值则取决于多个表达式布尔运算的结果。布尔运算可以是管理员指定的逻辑与或者逻辑或操作,此外, Rule的效果总是以 constraint的形式体现。因此, Rule通常在 Constraint命令中配置,如下语句是配置资源 Rule的语法格式:
pcs constraint rule add constraint_id [rule_type] [score=score] (id=rule-id] expression丨date_expression丨date-spec options如果忽略 score值,则使用默认值 INFINITY,如果忽略 ID,则自动从 Constraint_id生成一个规则 ID,而 Rule-type可以是字符表达式或者日期表达式。需要注意的是,在删除资源 Rule时候,如果此 Rule是 Constraint中的最后一个 Rule,则该 Constraint将被删除,删除资源 Rule语法如下:
pcs constraint rule remove rule_id资源 Rule的表达式主要分为节点属性表达式和时间/日期表达式,节点属性表达式由以下几个部分组成。
Value:用户提供的用于同节点属性值进行比较的值。
Attribute:节点属性变量名,其值即是 value要匹配的节点属性值。
Type:确定使用哪种类型的值匹配,允许的值包括字符串、整数、版本号(Version)。
Operation:操作符,确定用户提供的1“与节点 Attribute的值如何匹配,主要包括以下几种操作符。
lt:如果 value 小于 Attribute的值,表达式为正 True;
gt:如果 value 大于 Attribute的值,表达式为正 True;
lte:如果value 小于等于 Attribute的值,表达式为正 True;
gte:如果 value 大于等于 Attribute的值,表达式为正 True;
eq:如果 value 等于 Attribute的值,表达式为正;
ne:如果 value不等于 Attribute的值,表达式为正 True;
defined:如果表达式中的 Attribute在节点中有定义,则表达式为 True;
not_defined:如果节点中没有定义表达式中的 Attribute,则表达式为True。
要通过Rule的节点属性表达式来确定资源的Location,则通常的命令语法如下:
pcs resource constraint location resource_id rule [rule_id] [role=master|slave] [score=score expression]此处的表达式可以是以下几种形式:
defined|not_defined attribute
attribute lt|gt|Ite|gte|eq|ne value
date [start=start] [end=end] operation=gt|lt|in-range
date-spec date_spec_options在 Openstack高可用集群配置中,使用最多的是第二种形式的表达式,例如要限制 Nova-compute服务仅运行在计算节点上,则可以通过如下 Rule和 Location配置实现:
pcs constraint location nova-compute-clone rule resource-discovery=exclusive score=0 osprole eq compute上述命令中,"osprole eq compute"即是 Rule的表达式,其中 osprole是节点的Atfribute, Compute是用户指定的节点属性值,该表达式的操作符是等于符号(该命令语句中的规则表达式的意思就是,当节点的值等于用户指定值( compute)的时候,则 Rule表达式为 True(计算节点属性中已经预先设置了osprole属性值为compute )。
四、LVS四层负载均衡集群
1、LVS简介
Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。我国章文嵩博士在1998年五月创建,默认编译为ip_vs内核模块,而在linux kernel的2.6版本之后kernel是直接支持ipvs的,优势:LVS承受负载能力高、稳定、占用服务器资源小,缺点:适配场景、配置较麻烦、不支持节点的健康检查机制。
1. LVS集群概述
至少包含两个节点服务器,对外表示为一个整体,只提供一个访问入口。
负载均衡(load balance cluster):将整个平台的负载均衡到多台单位;
高可用(high availablity cluster):使整个应用平台拥有容错能力;
可伸缩性(Scalability):当服务的负载增长时,系统能被扩展来满足需求,且不降低服务质量;
高可用性(Availability):尽管部分硬件和软件会发生故障,整个系统的服务必须是每天24小时每星期7天可用的;
可管理性(Manageability):整个系统可能在物理上很大,但应该容易管理;
价格有效性(Cost-effectiveness):整个系统实现是经济的、易支付的;
集群的分层结构:
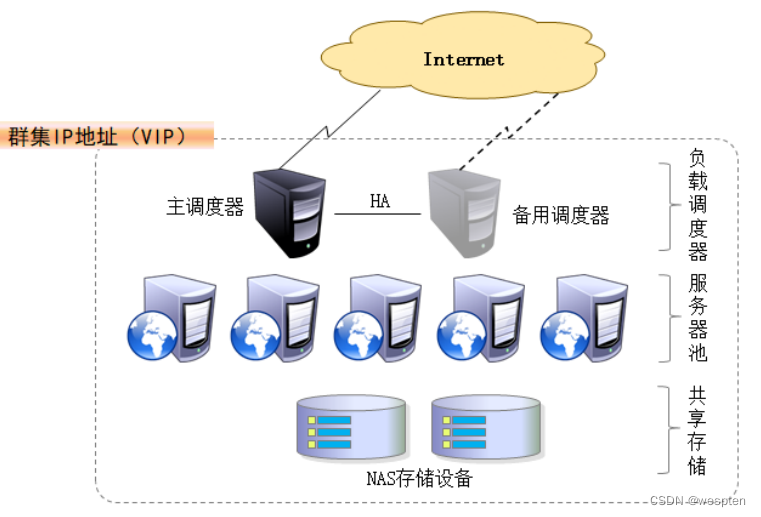
第一层:负载调度器(load balancer或director),访问群集的唯一入口,对外使用所有服务器共有的VIP(virtual ip)地址,也称为群集IP地址。
第二层:节点层(real server pool),服务器池群集所提供的应用服务由服务器池承担,其中的每个节点具有独立的RIP(real IP真实地址),只处理调度服务器分发过来的客户机请求。当某个节点暂时失效时,负载调度器的容错机制会将其隔离,等待错误排除以后再重新纳入服务器池。
第三层:共享存储层或数据库层,共享存储为服务器池中的所有节点提供稳定,一致的文件存取服务,确保整个群集的统一性。
2. LVS内核模型
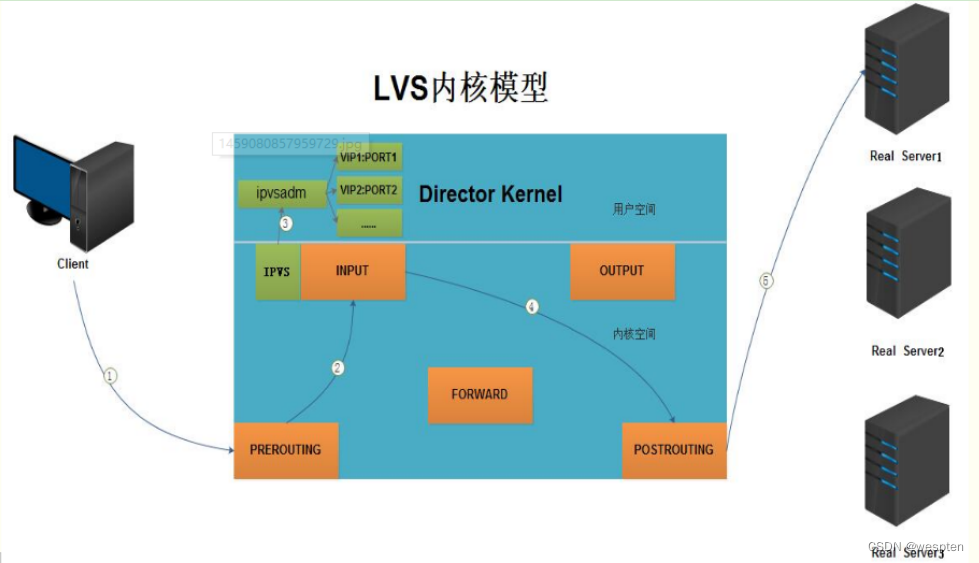
调度条件:基于IP(效率最高)、基于端口、基于内容。
2、LVS体系结构
使用LVS架设的服务器集群系统有三个部分组成:最前端的负载均衡层,用Load Balancer表示,中间的服务器群组层,用Server Array表示,最底端的数据共享存储层,用Shared Storage表示,在用户看来,所有的内部应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。
LVS体系结构如下图所示:
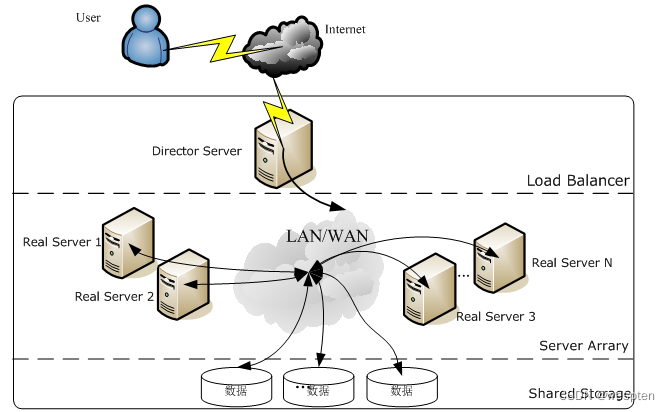
下面对LVS的各个组成部分进行详细介绍:
Load Balancer层:位于整个集群系统的最前端,有一台或者多台负载调度器(Director Server)组成,LVS模块就安装在Director Server上,而Director的主要作用类似于一个路由器,它含有完成LVS功能所设定的路由表,通过这些路由表把用户的请求分发给Server Array层的应用服务器(Real Server)上。同时,在Director Server上还要安装对Real Server服务的监控模块Ldirectord,此模块用于监测各个Real Server服务的健康状况。在Real Server不可用时把它从LVS路由表中剔除,恢复时重新加入。
Server Array层:由一组实际运行应用服务的机器组成,Real Server可以是WEB服务器、MAIL服务器、FTP服务器、DNS服务器、视频服务器中的一个或者多个,每个Real Server之间通过高速的LAN或分布在各地的WAN相连接。在实际的应用中,Director Server也可以同时兼任Real Server的角色。
Shared Storage层:是为所有Real Server提供共享存储空间和内容一致性的存储区域,在物理上,一般有磁盘阵列设备组成,为了提供内容的一致性,一般可以通过NFS网络文件系统共享数据,但是NFS在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件系统,例如Red hat的GFS文件系统,oracle提供的OCFS2文件系统等。
从整个LVS结构可以看出,Director Server是整个LVS的核心,目前,用于Director Server的操作系统只能是Linux和FreeBSD,linux2.6内核不用任何设置就可以支持LVS功能,对于Real Server,几乎可以是所有的系统平台,Linux、windows、Solaris、AIX、BSD系列都能很好的支持。
3、IP负载均衡与负载调度算法
负载均衡技术有很多实现方案,有基于DNS域名轮流解析的方法、有基于客户端调度访问的方法、有基于应用层系统负载的调度方法,还有基于IP地址的调度方法,在这些负载调度算法中,执行效率最高的是IP负载均衡技术。
LVS的IP负载均衡技术是通过IPVS模块来实现的,IPVS是LVS集群系统的核心软件,lvs集群整个执行流程为:访问的请求首先经过VIP到达负载调度器,然后由负载调度器从Real Server列表中选取一个服务节点响应用户的请求。
当用户的请求到达负载调度器后,调度器如何将请求发送到提供服务的Real Server节点,而Real Server节点如何返回数据给用户,是IPVS实现的重点技术,IPVS实现负载均衡机制有三种,分别是NAT、TUN和DR,详述如下:
1. DR模式
DR模式数据传输图:

DR模式: 即Virtual Server via Direct Routing,也就是用直接路由技术实现虚拟服务器。各节点并不是分散在各地,而是与调度服务器位于同一个物理网络。负载调度器与各节点服务器通过本地网络连接,不需要建立专用的IP隧道。VS/DR通过改写请求报文的MAC地址,将请求发送到Real Server,而Real Server将响应直接返回给客户。这种调度方式的性能最好,安全性较高。
DR模式特点:
1. DR模式是通过在调度器LB上修改数据包的目的MAC地址实现转发。因此数据包来源地址保持不变,目的地址仍然是VIP地址。
2. 请求的报文经过调度器,而RS响应处理后的报文无需经过调度器LB,因此并发访问量大时使用效率很高(和NAT模式比)。
3. 因为DR模式是通过MAC地址改写机制实现转发,因此所有RS节点和调度器LB只能在一个局域网里面。
4. RS主机需要绑定VIP地址在LO接口上,并且需要配置ARP抑制。
5. RS节点的默认网关不需要配置成LB,而是直接配置为上级路由的网关,能让RS直接出网就可以。
6. 由于DR模式的调度器仅做MAC地址的改写,所以调度器LB就不能改写目标端口,那么RS服务器就得使用和VIP相同的端口提供服务。
2. NAT/FULL NAT模式
NAT模式: 即Virtual Server via Network Address Translation,也就是网络地址翻译技术实现虚拟服务器。

当用户请求到达调度器时,调度器将请求报文的目标地址(即虚拟IP地址)改写成选定的Real Server地址,同时将报文的目标端口也改成选定的Real Server的相应端口,最后将报文请求发送到选定的Real Server。
在服务器端得到数据后,Real Server将数据返回给用户时,需要再次经过负载调度器将报文的源地址和源端口改成虚拟IP地址和相应端口,然后把数据发送给用户,完成整个负载调度过程。
NAT模式优缺点:
1. NAT 模式不需要 LB IP 和realserver ip 在同一个网段。
2. NAT技术将请求的报文和响应的报文都需要通过LB进行地址改写,因此网站访问量比较大的时候,LB负载均衡调度器有比较大的瓶颈,一般要求最多之能10-20台节点
3. 只需要在LB上配置一个公网IP地址就可以了。
4. 每台内部的realserver服务器的网关地址必须是调度器LB的内网地址。
5. NAT模式支持对IP地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致。
FULL NAT模式优缺点与注意事项:
FULL NATT模式,与NAT模式基本一样,不同之处在于对报文的处理方面:
1. NAT模式client请求VIP 时,仅替换了package 的dst ip。
2. FULL NAT 在client请求VIP 时,不仅替换了package 的dst ip,还替换了package的 src ip;VIP返回给client时也替换了src ip。
3. FULL NAT模式也不需要LB IP和realserver ip 在同一个网段。
4. FULL NAT因为要更新Source IP所以性能正常比NAT模式下降10%。
3. IP TUNNEL模式
TUN :即Virtual Server via IP Tunneling 也就是通过IP隧道技术实现虚拟服务器。

在VS/TUN方式中,采用开放是的网络结构,调度器采用IP隧道技术将用户请求转发到某个Real Server,而这个Real Server将直接响应用户的请求,负载调度器仅作为客户机的访问入口,不再经过前端调度器。此外,对Real Server的地域位置没有要求,可以和Director Server位于同一个网段,也可以在独立的一个网络中。因此,在TUN方式中,调度器将只处理用户的报文请求,从而使集群系统的吞吐量大大提高。
它和NAT模式不同的是,它在LB和RS之间的传输不用改写IP地址。而是把客户请求包封装在一个IP tunnel里面,然后发送给RS节点服务器,节点服务器接收到之后解开IP tunnel后,进行响应处理。并且直接把包通过自己的外网地址发送给客户不用经过LB服务器。
IP TUNNEL 模式的注意事项:
1. TUNNEL 模式必须在所有的realserver 机器上面绑定VIP的IP地址。
2. TUNNEL 模式的vip ------>realserver 的包通信通过TUNNEL 模式,不管是内网和外网都能通信,所以不需要lvs vip跟realserver 在同一个网段内。
3. TUNNEL 模式 realserver会把packet 直接发给client 不会给lvs了。
4. TUNNEL 模式走的隧道模式,所以运维起来比较难,所以一般不用。
4、LVS负载调度算法
Lvs的调度算法决定了如何在集群节点之间分布工作负荷。当director调度器收到来自客户端访问VIP的上的集群服务的入站请求时,director调度器必须决定哪个集群节点应该处理请求。
Director调度器用的调度方法基本分为两类:
静态调度算法:rr,wrr,dh,sh
动态调度算法:wlc,lc,sed,nq,lblc,lblcr
| 算法 |
说明 |
| rr |
轮询算法,它将请求依次分配给不同的rs节点,也就是RS节点中均摊分配。 这种算法简单,但只适合于RS节点处理性能差不多的情况 |
| wrr |
加权轮训调度,它将依据不同RS的权值分配任务。权值较高的RS将优先获得任务, 并且分配到的连接数将比权值低的RS更多。相同权值的RS得到相同数目的连接数。 |
| wlc | 加权最小连接数调度,假设各台RS的权重依次为Wi,当前tcp连接数依次为Ti, 依次去Ti/Wi为最小的RS作为下一个分配的RS |
| dh |
目的地址哈希调度(destination hashing)以目的地址为关键字查找一个静态hash表来获得需要的RS |
| sh | 源地址哈希调度(source hashing)以源地址为关键字查找一个静态hash表来获得需要的RS |
| lc | 最小连接数调度(least-connection),IPVS表存储了所有活动的连接。 LB会比较将连接请求发送到当前连接最少的RS. |
| sed | 最短延迟调度:在wlc基础上改进,Overhead = (ACTIVE+1)*256/加权,不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的,接受下次请求,+1的目的是为了考虑加权的时候,非活动连接过多缺陷:当权限过大的时候,会倒置空闲服务器一直处于无连接状态。 |
| nq | 永不排队/最少队列调度:无需队列。如果有台 realserver的连接数=0就直接分配过去,不需要再进行sed运算,保证不会有一个主机很空间。在SED基础上无论+几,第二次一定给下一个,保证不会有一个主机不会很空闲着,不考虑非活动连接,才用NQ,SED要考虑活动状态连接,对于DNS的UDP不需要考虑非活动连接,而httpd的处于保持状态的服务就需要考虑非活动连接给服务器的压力。 |
| lblc | 基于局部性的最少链接:基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。 |
| lblcr | 带复制的基于局部性最少连接:带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按”最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。 |
5、LVS调度算法的生产环境选型
1. 一般的网络服务,如www,mail,mysql等常用的LVS调度算法为:
① 基本轮询调度rr
② 加权最小连接调度wlc
③ 加权轮询调度wrr
2. 基于局部性的最小连接lblc和带复制的给予局部性最小连接lblcr主要适用于web cache和DB cache
3. 源地址散列调度SH和目标地址散列调度DH可以结合使用在防火墙集群中,可以保证整个系统的出入口唯一。
实际适用中这些算法的适用范围很多,工作中最好参考内核中的连接调度算法的实现原理,然后根据具体的业务需求合理的选型。
6、LVS的安装与使用
IPVS的官网:IPVS Software - Advanced Layer-4 Switching
提供的软件包有源码方式的也有rpm方式的,这里介绍通过yum方式安装IPVS,这里采用的操作系统为Centos7.5版本,因此,在服务器上直接执行如下操作进行安装:
[root@localhost ~]#yum -y install ipvsadm
[root@localhost ~]# ipvsadm --help 如果看到帮助提示,表明IPVS已经成功安装。
7、通过Keepalived搭建LVS高可用性集群系统
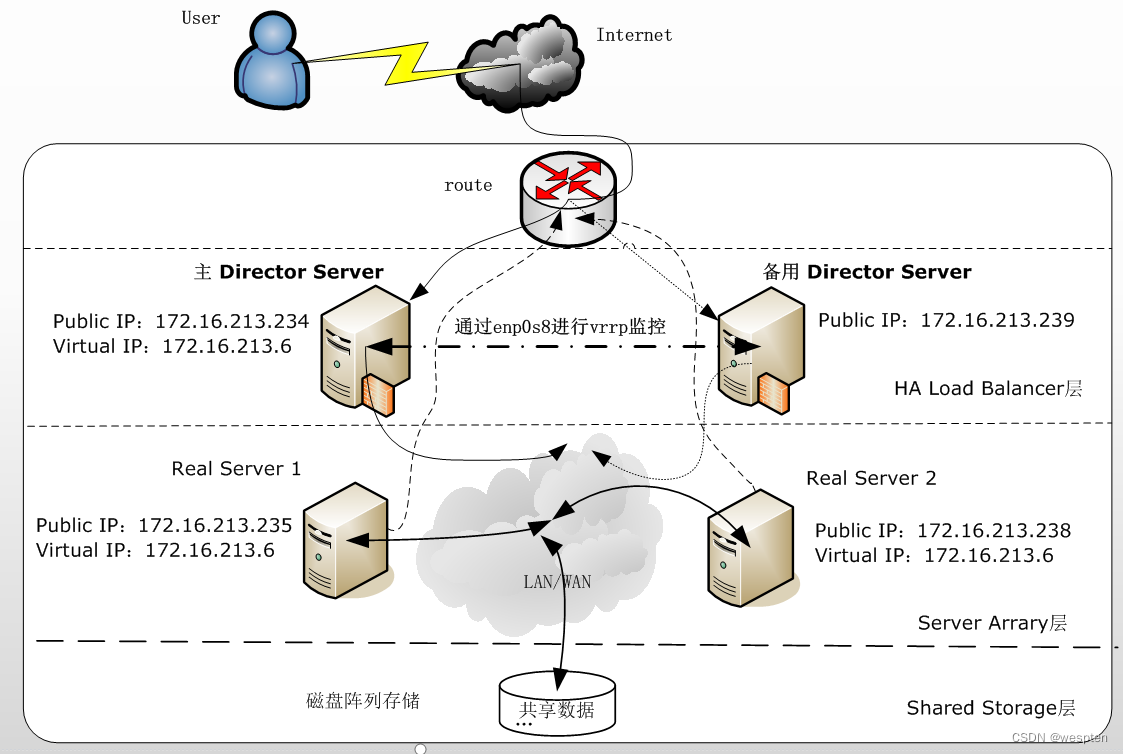
1. 实例环境介绍
LVS集群有DR、TUN、NAT三种配置模式,可以对WWW服务、FTP服务、MAIL服务等进行负载均衡。下面通过3个实例详细讲述如何搭建WWW服务的高可用LVS集群系统,以及基于DR模式的LVS集群配置。在进行实例介绍之前进行约定:操作系统采用Centos7.5,地址规划如下表所示。
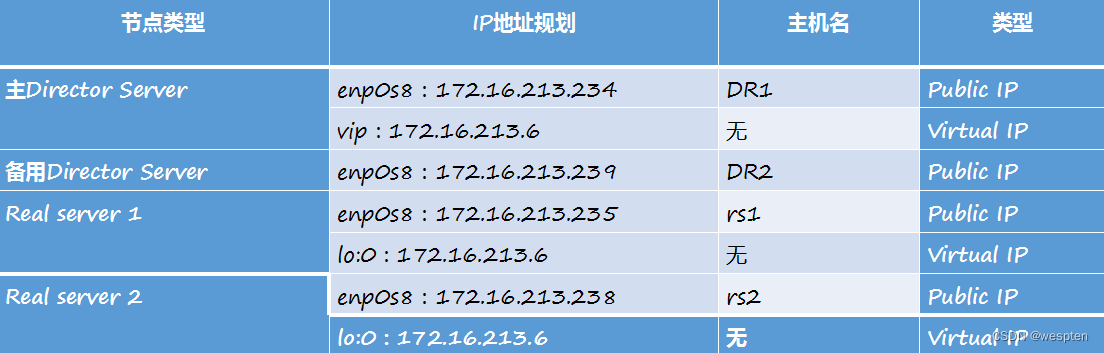
整个高可用LVS集群系统的拓扑结构如下图所示:
2. 配置Keepalived
Keepalived的配置非常简单,仅需要一个配置文件即可完成对HA cluster和LVS服务节点监控。Keepalived的安装已经在前面介绍过,在通过Keepalived搭建高可用的LVS集群实例中,主、备Director Server都需要安装Keepalived软件,安装成功后,默认的配置文件路径为/etc/Keepalived/Keepalived.conf。
一个完整的keepalived配置文件由三个部分组成,分别是:
1. 全局定义部分
2. vrrp实例定义部分
3. 虚拟服务器定义部分
下面详细介绍这个配置文件中每个选项的详细含义和用法:
! Configuration File for keepalived
#全局定义部分
global_defs {
notification_email {
[email protected] #设置报警邮件地址,可以设置多个,
#每行一个。注意,如果要开启邮件报警,
#需要开启本机的Sendmail服务
[email protected]
}
notification_email_from Keepalived@localhost #设置邮件的发送地址
smtp_server 192.168.200.1 #设置smtp server地址
smtp_connect_timeout 30 #设置连接smtp server的超时时间
router_id LVS_DEVEL #表示运行Keepalived服务器的一个
#标识。发邮件时显示在邮件主题中的信息
}vrrp实例定义部分:
vrrp_instance VI_1 {
state MASTER #指定Keepalived的角色,MASTER表示
# 此主机是主服务器,BACKUP表示
#此主机是备用服务器
interface eth0 #指定HA监测网络的接口
virtual_router_id 51 #虚拟路由标识,这个标识是一个数字,
#同一个vrrp实例使用唯一的标识,
#即同一个vrrp_instance下,MASTER和
#BACKUP必须是一致的
priority 100 #定义优先级,数字越大,优先级越高。
#在一个vrrp_instance下,MASTER的
#优先级必须大于BACKUP的优先级
advert_int 1 #设定MASTER与BACKUP负载均衡器之
#间同步检查的时间间隔,单位是秒
authentication { #设定验证类型和密码
auth_type PASS #设置验证类型,主要有PASS和AH两种
auth_pass 1111 #设置验证密码,在一个vrrp_instance下,
#MASTER与BACKUP必须使用相同的密码
#才能正常通信
}
virtual_ipaddress { #设置虚拟IP地址,可以设置多个虚拟IP地址,每行一个。
172.16.213.6
}
}
虚拟服务器定义部分:
virtual_server 172.16.213.6 80 { #设置虚拟服务器,需要指定虚拟IP地址和服务
#端口,IP与端口之间用空格隔开
delay_loop 6 #设置运行情况检查时间,单位是秒
lb_algo rr #设置负载调度算法,这里设置为rr,即轮询算法
lb_kind DR #设置LVS实现负载均衡的机制,有NAT、TUN
#和DR三个模式可选
persistence_timeout 50 #会话保持时间,单位是秒。这个选项对动态网页是非常有用的,为集群系统中的session共享提供了一个很好的解决方案。有了这个会话保持功能,用户的请求会被一直分发到某个服务节点,直到超过这个会话的保持时间。需要注意的是,这个会话保持时间是最大无响应超时时间,也就是说,用户在操作动态页面时,如果在50秒内没有执行任何操作,那么接下来的操作会被分发到另外节点,但是如果用户一直在操作动态页面,则不受50秒的时间限制。
protocol TCP #指定转发协议类型,有TCP和UDP两种
real_server 172.16.213.235 80 { #配置服务节点1,需要指定real server的真实IP地址和端口,IP与端口之间用空格隔开
weight 3 #配置服务节点的权值,权值大小用数字表示,数字越大,权值越高,设置权值的大小可以为不同性能的服务器分配不同的负载,可以为性能高的服务器设置较高的权值,而为性能较低的服务器设置相对较低的权值,这样才能合理地利用和分配了系统资源
TCP_CHECK { #realserve的状态检测设置部分,单位是秒
connect_timeout 3 #表示3秒无响应超时
retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
}
}
real_server 172.16.213.238 80 { #配置服务节点2
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
在配置Keepalived.conf时,需要特别注意配置文件的语法格式,因为Keepalived在启动时并不检测配置文件的正确性,即使没有配置文件,Keepalived也照样能够启动,所以一定要保证配置文件正确。
在默认情况下,Keepalived在启动时会查找/etc/Keepalived/Keepalived.conf配置文件,如果配置文件放在了其他路径下,可以通过“Keepalived -f”参数指定配置文件的路径即可。
Keepalived.conf配置完毕后,将此文件复制到备用Director Server对应的路径下,然后进行两个简单的修改即可:
1. 将“state MASTER”更改为“state BACKUP”;
2. 将priority 100更改为一个较小的值,这里改为“priority 80”;
3. 配置Real server节点
与heartbeat+LVS类似,Keepalived+LVS也需要为Real server节点配置VIP,抑制ARP,以达到与Director Server相互通信的目的。
在lvs的DR和Tun模式下,用户的访问请求到达真实服务器后,是直接返回给用户的,而不再经过前端的Director Server,因此,就需要在每个Real server节点上增加虚拟的VIP地址,这样数据才能直接返回给用户,增加VIP地址的操作可以通过创建脚本的方式来实现,创建文件/etc/init.d/lvsrs,脚本内容如下:
#!/bin/bash
VIP=172.16.213.6
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
echo “1″ >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo “2″ >/proc/sys/net/ipv4/conf/lo/arp_announce
echo “1″ >/proc/sys/net/ipv4/conf/all/arp_ignore
echo “2″ >/proc/sys/net/ipv4/conf/all/arp_announce
sysctl -p
#end此操作是在回环设备上绑定了一个虚拟IP地址,并设定其子网掩码为255.255.255.255,与Director Server上的虚拟IP保持互通,然后禁止了本机的ARP请求。
上面脚本也可以写成可启动与停止的服务脚本,内容如下:
[root@localhost ~]#more /etc/init.d/lvsrs
#!/bin/bash
#description : Start Real Server
VIP=172.16.213.6
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo " Start LVS of Real Server"
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
stop)
/sbin/ifconfig lo:0 down
echo "close LVS Director server"
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac
然后,修改lvsrs有可执行权限:
[root@localhost ~]#chomd 755 /etc/init.d/lvsrs最后,可以通过下面命令启动或关闭lvsrs
service lvsrs {start|stop}由于虚拟ip,也就是上面的VIP地址,是Director Server和所有的Real server共享的,如果有ARP请求VIP地址时,Director Server与所有Real server都做应答的话,就出现问题了,因此,需要禁止Real server响应ARP请求,而lvsrs脚本的作用就是使Real Server不响应arp请求。
4. 启动Keepalived+LVS集群系统
在主、备Director Server上分别启动Keepalived服务,可以执行如下操作:
[root@DR1 ~]#/etc/init.d/Keepalived start接着在两个Real server上执行如下脚本:
[root@rs1~]#/etc/init.d/lvsrs start至此,Keepalived+LVS高可用的LVS集群系统已经运行起来了。
补充:
参考详细介绍这个配置文件中每个选项的详细含义和用法。
! Configuration File for keepalived
#全局定义部分
global_defs {
notification_email { #设置报警邮件地址,可以设置多个,
[email protected] #每行一个。注意,如果要开启邮件报警,
#需要开启本机的 Sendmail 服务
[email protected]
}
notification_email_from Keepalived@localhost
#设置邮件的发送地址
smtp_server 192.168.200.1
#设置smtp server地址
smtp_connect_timeout 30
#设置连接 smtp server 的超时时间
router_id_LVS_DEVEL #表示运行 Keepalived服务器的一个标识。发邮件时显示在邮件主题中的信息
}
#vrrp 实例定义部分
vrrp_instance VI_1 {
state MASTER #指定 Keepalived 的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器.
interface eth0 #指定HA监测网络的接口
virtual_router_id 51 #虚拟路由标识,这个标识是一个数字,同一个 vrrp 实例使用唯一的标识,即同一个vrrp_instance下,MASTER和BACKUP 必须是一致的
priority 100 #定义优先级,数字越大,优先级越高。在一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级
advert_int 1 #设定MASTER与BACKUP 负载均衡器之间同步检查的时间间隔,单位是秒
authentication{ #设定验证类型和密码
auth_type PASS #设置验证类型,主要有PASS和AH两种
auth_pass 1111
#设置验证密码,在一个vrrp_instance下,MASTER与BACKUP 必须使用相同的密码才能正常通信
}
virtual_ipaddress {
#设置虚拟IP地址,可以设置多个虚拟IP地址,每行一个。
192.168.12.200
}
}
#虚拟服务器定义部分
virtual_server 192.168.12.200 80 {
#设置虚拟服务器,需要指定虚拟IP地址和服务端口IP与端口之间用空格隔开
delay_loop 6
#设置健康检查的时间间隔,单位是秒
lb_algo rr
#设置负载调度算法,这里设置为rr,即轮询算法
lb_kind DR
#设置LVS实现负载均衡的机制,有 NAT、TUN和DR三个模式可选
persistence_timeout 50
#会话保持时间,单位是秒。这个选项对动态网页是非常有用的,为集群系统中的 session共享提供了一个很好的解决方案。有了这个会话保持功能,用户的请求会被一直分发到某个服务节点,直到超过这个会话的保持时间。需要注意的是,这个会话保持时间是最大无响应超时时间,也就是说,用户在操作动态页面时,如果在 50秒内没有执行任何操作,那么接下来的操作会被分发到另外节点,但是如果用户一直在操作动态页面,则不受50秒的时间限制。
protocol TCP
#指定转发协议类型,有TCP和UDP两种
real_server 192.168.12.132 80 {
#配置服务节点 1,需要指定 real server的真实IP地址和端口,IP与端口之间用空格隔开
weight 3
#配置服务节点的权值,权值大小用数字表示,数字越大,权值越高,设置权值的大小可以为不同性能的服务器分配不同的负载,可以为性能高的服务器设置较高的权值,而为性能较低的服务器设置相对较低的权值,这样才能合理地利用和分配了系统资源
TCP_CHECK {
#realserve的状态检测设置部分,单位是秒
connect_timeout 3
#表示3秒无响应超时
nb_get_retry 3
#表示重试次数
delay_before_retry 3
#表示重试间隔
connect_port 80
#检查80端口
}
}
real_server 192.168.12.133 80 {
#配置服务节点 2
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}8、测试高可用LVS负载均衡集群系统
高可用的LVS负载均衡系统能够实现LVS的高可用性、负载均衡特性和故障自动切换特性,因此,对其进行的测试也针对这三个方面进行,这里对Keepalived+LVS实例进行测试。
1. 高可用性功能测试
高可用性是通过LVS的两个Director Server完成的,为了模拟故障,先将主Director Server上面的Keepalived服务停止,然后观察备用Director Server上Keepalived的运行日志。
2. 负载均衡测试
这里假定两个Real Server节点上配置WWW服务的网页文件的根目录均为/webdata/www目录,然后分别执行如下操作:
在real server1 执行:
echo "This is real server1" /webdata/www/index.html在real server2 执行:
echo "This is real server2" /webdata/www/index.html接着打开浏览器,访问http://172.16.213.6这个地址,然后不断刷新此页面,如果能分别看到“This is real server1”和“This is real server2”就表明LVS已经在进行负载均衡了。
3. 故障切换测试
故障切换是测试在某个节点出现故障后,Keepalived监控模块是否能及时发现,然后屏蔽故障节点,同时将服务转移到正常节点上执行。
这里将real server 1节点服务停掉,假定这个节点出现故障,然后查看主、备机日志信息。
9、搭建LVS的NAT模式负载均衡集群
案例拓扑:
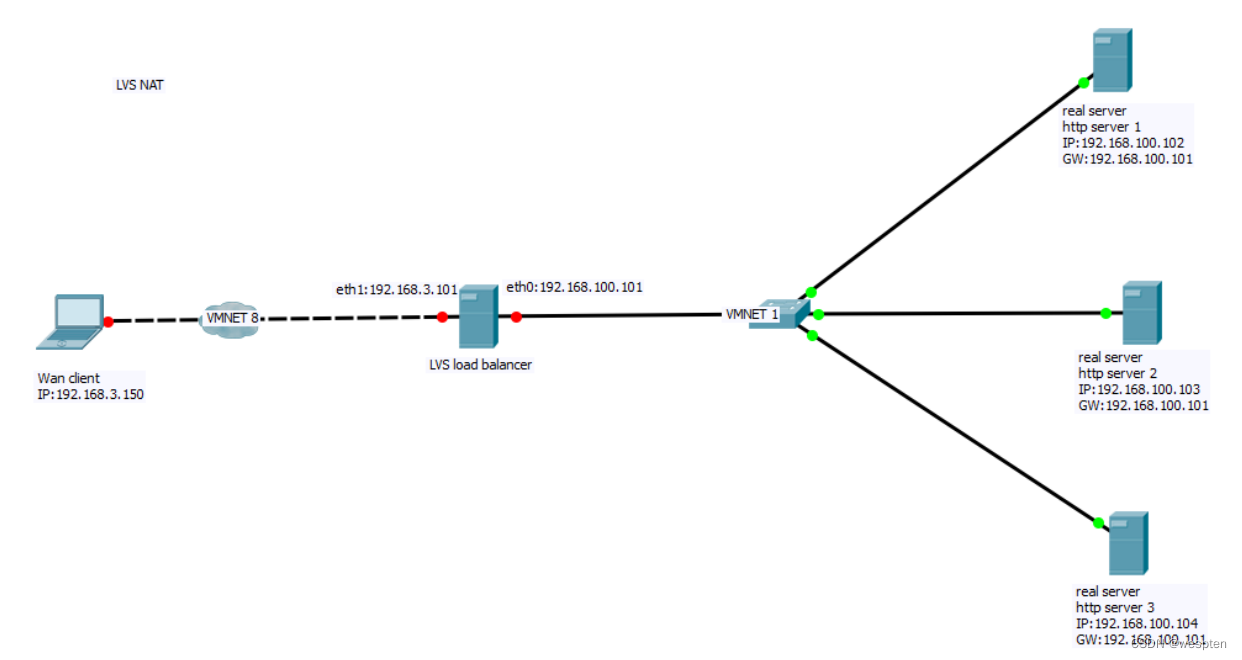
案例环境:
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 7.4 1708 64bit |
192.168.100.101 192.168.3.101 |
ld.linuxfan.cn |
ipvsadm、内核模块ip_vs |
| Centos 7.4 1708 64bit |
192.168.100.102 |
real1.linuxfan.cn |
httpd |
| Centos 7.4 1708 64bit |
192.168.100.103 |
real2.linuxfan.cn |
httpd |
| Centos 7.4 1708 64bit |
192.168.100.104 |
real3.linuxfan.cn |
httpd |
| win7 |
192.168.3.150 |
win7-1 |
案例步骤:
- 搭建real server 节点池中的三台http服务节点(在此只列出一台配置,其他两台相同);
- 配置LD负载调度器的环境以及安装软件程序;
- 配置LD负载调度服务器的调度服务;
- 公网客户端测试访问集群;
1. 搭建real server 节点池中的三台http服务节点(在此只列出一台配置,其他两台相同)
[root@real1 ~]# ip a |grep 192.168.100.102 ##设置ip地址
inet 192.168.100.102/24 brd 192.168.100.255 scope global eth0
[root@real1 ~]# ip r |grep 192.168.100.101 ##设置默认网关地址
default via 192.168.100.101 dev eth0 proto static metric 100
[root@real1 ~]# yum -y install httpd
[root@real1 ~]# cat <<END >/var/www/html/index.html
I am real1.linuxfan.cn
END
[root@real1 ~]# systemctl start httpd
[root@real1 ~]# systemctl enable httpd ##设置开机自动启动
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.2. 配置LD负载调度器的环境以及安装软件程序
[root@ld ~]# ip a |grep 101
inet 192.168.100.101/24 brd 192.168.100.255 scope global eth0
inet 192.168.3.101/24 brd 192.168.3.255 scope global eth1
[root@ld ~]# echo "net.ipv4.ip_forward = 1" >>/etc/sysctl.conf ##开启路由转发功能,因为调度器同时承载着网关的角色
[root@ld ~]# sysctl -p
net.ipv4.ip_forward = 1
[root@ld ~]# modprobe ip_vs ##加载内核模块ip_vs
[root@ld ~]# lsmod |grep ip_vs
ip_vs 141092 0
nf_conntrack 133387 1 ip_vs
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack3. 配置LD负载调度服务器的调度服务
[root@ld ~]# yum -y install ipvsadm ##安装ip_vs模块的规则编写工具
[root@ld ~]# systemctl stop ipvsadm ##清空内部规则
[root@ld ~]# ipvsadm -A -t 192.168.3.101:80 -s rr ##指定集群的VIP地址(Virtual IP),rr指定轮询调度算法
[root@ld ~]# ipvsadm -a -t 192.168.3.101:80 -r 192.168.100.102:80 -m -w 1 ##-m表示NAT模式,-w指定权重值
[root@ld ~]# ipvsadm -a -t 192.168.3.101:80 -r 192.168.100.103:80 -m -w 1
[root@ld ~]# ipvsadm -a -t 192.168.3.101:80 -r 192.168.100.104:80 -m -w 1
[root@ld ~]# ipvsadm-save ##保存规则
-A -t ld.linuxfan.cn:http -s rr
-a -t ld.linuxfan.cn:http -r 192.168.100.102:http -m -w 1
-a -t ld.linuxfan.cn:http -r 192.168.100.103:http -m -w 1
-a -t ld.linuxfan.cn:http -r 192.168.100.104:http -m -w 1
[root@ld ~]# ipvsadm -L ##查看规则
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP ld.linuxfan.cn:http rr
-> 192.168.100.102:http Masq 1 0 0
-> 192.168.100.103:http Masq 1 0 0
-> 192.168.100.104:http Masq 1 0 04. 公网客户端测试访问集群


10、搭建LVS的DR模式负载均衡集群
案例拓扑:

案例环境:
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 6.5 64bit |
192.168.100.100 192.168.3.100 |
GW |
iptables |
| Centos 7.4 1708 64bit |
192.168.100.101 |
ld.linuxfan.cn |
ipvsadm、内核模块ip_vs |
| Centos 7.4 1708 64bit |
192.168.100.102 |
real1.linuxfan.cn |
httpd |
| Centos 7.4 1708 64bit |
192.168.100.103 |
real2.linuxfan.cn |
httpd |
| Centos 7.4 1708 64bit |
192.168.100.104 |
real3.linuxfan.cn |
httpd |
| win7-1 |
192.168.100.66 |
lan-client |
浏览器 |
| win7-2 |
192.168.3.150 |
wan-client |
浏览器 |
| VIP(virtual-ip) |
192.168.100.88 |
案例步骤:
- 搭建real server 节点池中的三台http服务节点(在此只列出一台配置,其他两台相同);
- 设置负载调度器上的VIP地址;
- 调整负载调度器的响应参数;
- 配置负载调度器负载分配策略;
- 配置real server节点池内节点服务器的网络参数(在此只列出一台配置,其他两台相同);
- 内网客户端访问测试集群;
- 在GW服务器上设置iptables的DNAT规则;
- 外网客户端访问测试集群;
- 测试LVS是否支持节点的健康检查功能;
1. 搭建real server 节点池中的三台http服务节点(在此只列出一台配置,其他两台相同)
[root@real1 ~]# ip a |grep 192.168.100.102 ##设置ip地址
inet 192.168.100.102/24 brd 192.168.100.255 scope global eth0
[root@real1 ~]# ip r |grep 192.168.100.100 ##设置默认网关地址
default via 192.168.100.100 dev eth0 proto static metric 100
[root@real1 ~]# yum -y install httpd
[root@real1 ~]# cat <<END >/var/www/html/index.html
I am real1.linuxfan.cn
END
[root@real1 ~]# systemctl start httpd
[root@real1 ~]# systemctl enable httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.2. 设置负载调度器上的VIP地址
[root@ld ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=192.168.100.101
PREFIX=24
GATEWAY=192.168.100.100
DNS1=192.168.100.100
[root@ld ~]# cp /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/sysconfig/network-scripts/ifcfg-eth0:0
[root@ld ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0:0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
NAME=eth0:0
DEVICE=eth0:0
ONBOOT=yes
IPADDR=192.168.100.88
PREFIX=24
GATEWAY=192.168.100.100
DNS1=192.168.100.100
[root@ld ~]# systemctl restart network
[root@ld ~]# ip a |grep 192.168.100
inet 192.168.100.101/24 brd 192.168.100.255 scope global eth0
inet 192.168.100.88/24 brd 192.168.100.255 scope global secondary eth0:03. 调整负载调度器的响应参数
[root@ld ~]# vi /etc/sysctl.conf ##最后添加
net.ipv4.conf.all.send_redirects = 0 ##禁止转发重定向报文
net.ipv4.conf.default.send_redirects = 0 ##禁止默认转发重定向报文
net.ipv4.conf.eth0.send_redirects = 0 ##禁止eth0网卡转发重定向报文
:wq
[root@ld ~]# sysctl -p4. 配置负载调度器负载分配策略
[root@ld ~]# modprobe ip_vs
[root@ld ~]# lsmod |grep ip_vs
ip_vs_rr 12600 1
ip_vs 141092 3 ip_vs_rr
nf_conntrack 133387 1 ip_vs
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
[root@ld ~]# yum -y install ipvsadm
[root@ld ~]# ipvsadm --clear
[root@ld ~]# systemctl stop ipvsadm
[root@ld ~]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
[root@ld ~]# ipvsadm -A -t 192.168.100.88:80 -s rr
[root@ld ~]# ipvsadm -a -t 192.168.100.88:80 -r 192.168.100.102:80 -g -w 1 ##表示DR模式
[root@ld ~]# ipvsadm -a -t 192.168.100.88:80 -r 192.168.100.103:80 -g -w 1
[root@ld ~]# ipvsadm -a -t 192.168.100.88:80 -r 192.168.100.104:80 -g -w 1
[root@ld ~]# ipvsadm-save
-A -t ld.linuxfan.cn:http -s rr
-a -t ld.linuxfan.cn:http -r 192.168.100.102:http -g -w 1
-a -t ld.linuxfan.cn:http -r 192.168.100.103:http -g -w 1
-a -t ld.linuxfan.cn:http -r 192.168.100.104:http -g -w 1
[root@ld ~]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP ld.linuxfan.cn:http rr
-> 192.168.100.102:http Route 1 0 0
-> 192.168.100.103:http Route 1 0 0
-> 192.168.100.104:http Route 1 0 05. 配置real server节点池内节点服务器的网络参数(在此只列出一台配置,其他两台相同)
[root@real1 ~]# cat <<END >/etc/sysconfig/network-scripts/ifcfg-lo:0
DEVICE=lo:0
IPADDR=192.168.100.88
NETMASK=255.255.255.255
ONBOOT=yes
NAME=lo:0
END
[root@ real1 ~]# systemctl restart network
[root@real1 ~]# ip a |grep 88
inet 192.168.100.88/32 brd 192.168.100.88 scope global lo:06. 内网客户端访问测试集群
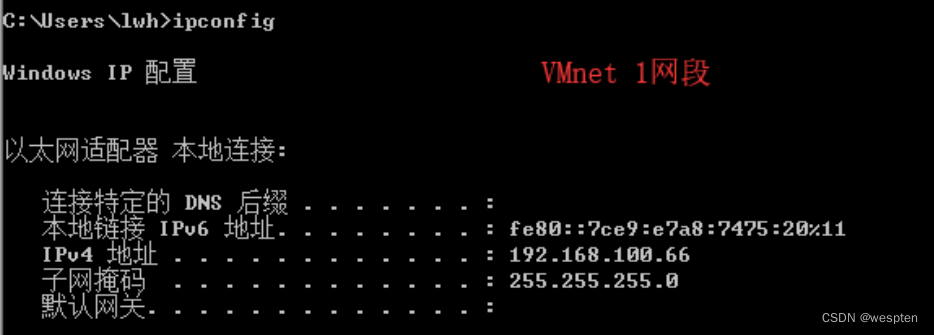


7. 在GW服务器上设置iptables的DNAT规则
[root@GW ~]# iptables -t nat -A PREROUTING -i eth1 -d 192.168.3.100 -p tcp --dport 80 -j DNAT --to-destination 192.168.100.88
[root@ GW ~]# iptables -t nat -L -n
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 192.168.3.100 tcp dpt:80 to:192.168.100.88
...8. 外网客户端访问测试集群


9. 测试LVS是否支持节点的健康检查功能
[root@real1 ~]# ifconfig lo:0 down ##断开real1的lo:0的网卡,使其脱离集群
[root@real1 ~]# ip a |grep 192.168.100.
inet 192.168.100.102/24 brd 192.168.100.255 scope global eth0客户端访问集群测试:

11、通过piranha搭建LVS高可用性集群
在LVS集群当中Director的作用是很关键的,所以我们在生产环境中要保证其高可用。
高可用架构图:

piranha是REDHAT 提供的一个基于Web的LVS 配置软件,通过piranha可以省去手工配置LVS 的繁琐工作;同时,piranha也可以单独提供集群功能,例如,可以通过piranha激活Director Server的备用主机。这里利用piranha来配置Director Server的双机热备功能。
1. 安装与配置piranha
通过yum命令直接在线安装,过程如下:
[root@DR2 ~]# yum install ipvsadm modcluster piranha system-config-cluster php php-cli php-common通过WEB 界面配置Piranha服务需要设置下面步骤:
#/usr/sbin/piranha-passwd //设置密码,请设置你的piranha服务WEB配置登陆密码. http://192.168.12.130:3636/输入用户名: piranha 及刚才设置的密码登陆.
/etc/sysconfig/ha/lvs.cf //由http://ip:3636 web 界面配置的配置文件写入此文件.
/etc/init.d/piranha-gui start //启动piranha服务的WEB配置界面.
/etc/init.d/pulse //启动piranha服务读取的就是/etc/sysconfig/ha/lvs.cf.piranha安装完毕后,会产生/etc/sysconfig/ha/lvs.cf配置文件。可以通过 piranha提供的 Web界面配置此文件(默认的网址地址为 `主机IP`:3636)

也可以直接手动编辑此文件。编辑好的 lvs.cf文件内容类似如下所示, 注意,“#”号后面的内容为注释:
[root@DR1 ~]# more /etc/sysconfig/ha/lvs.cf
serial_no=18#序号
primary=192.168.60.130 #指定主用 Director Server 的真实IP地址
service=lvs#指定双机的服务名
backup_active=1#是否激活备用Director Server。“0”表示不激活,“1”表示激活。这里选择激活方式
backup=192.168.12.131 #这里指定备用 Director Server 的真实 IP 地址,如果没有备用 #Director Server,可以用“0.0.0.0”代替
heartbeat=1#是否开启心跳,1 表示开启,0 表示不开启
heartbeat_port=539 #指定心跳的 UDP 通信端口。
keepalive=5 #心跳间隔时间,单位是秒
deadtime=10 #如果主 Director Server在deadtime(秒)后没有响应,那么备份Director Server就会接管主Director Server的服务
network=direct #指定 LVS 的工作模式,direct表示DR模式,nat表示NAT模式,tunnel表示TUN模式
debug_level=NONE #定义debug调试信息级别
virtual www.ixdba.net{ #指定虚拟服务的名称
active=1 #是否激活此服务
address=192.168.12.200 eth0:0 #虚拟服务绑定的虚拟IP及网络设备名
port=80 #虚拟服务的端口
send="GET / HTTP/1.0\r\n\r\n" #向real server发送的验证字符串
expect="HTTP"
#服务器正常运行时应该返回的文本应答信息,用来判断 Real Server
#是否工作正常
use_regex=0
#expect选项中是否使用正则表达式,0 表示不使用,1 表示使用。
load_monitor=none
#LVS中的Director Server 能够使用rup或ruptime来监视各个
Real Server的负载状态。该选项有3个可选值,rup、ruptime和none,如果选择 rup,每个 Real Server 就必须运行 rstatd 服务。如果选择了ruptime,每个 Real Server 就必须运行 rwhod 服务
scheduler=rr #指定LVS的调度算法
protocol=tcp #虚拟服务使用的协议类型
timeout=6
#Real Server 失效后从 LVS 路由列表中移除失效Real Server所必须经过
的时间,以秒为单位
reentry=15
#某个Real Server被移除后,重新加入LVS路由列表中必须经过的#时间,
以秒为单位
quiesce_server=0
#如果此选项为1.那么当某个新的节点加入集群时,最少连接数会被重设
为零,因此 LVS 会发送大量请求到此服务节点,造成新的节点服务阻塞,建议设置为 0
server RS1 { #指定 Real Server 服务名
address=192.168.12.132 #指定 Real Server 的 IP 地址
active=1 #是否激活此 Real Server 服务
weight=1
#指定此 Real Server 的权值,是整数值.权值是相对于所有 Real Server
节点而言的,权值高的 Real Server 处理负载的性能相对较强
}
server RS2 {
address = 192.168.12.133
active = 1
weight = 1
}
} 接着,还需要对两个 Real Server节点进行配置,也就是创建/etc/init.d/lvsrs脚本,创建文件/etc/init.d/lvsrs,脚本内容如下:
[root@rs1 ~]#more /etc/init.d/lvsrs
#!/bin/bash
#description : Start Real Server
VIP=192.168.12.200
./etc/rc.d/init.d/functions
case "$1" in
start)
echo " Start LVS of Real Server "
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
echo "1" >/proc /sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc /sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc /sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc /sys/net/ipv4/conf/all/arp_announce
stop)
/sbin/ifconfig lo:0 down
echo "close LVS Director server"
echo "0" >/proc /sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc /sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc /sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc /sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac 2. 启动通过piranha 配置的LVS集群系统
将编辑好的 lvs.cf 从 Director Server 的主节点复制到备用节点,然后在主、备节点分别启动pulse服务,即启动LVS 服务,过程如下:
[root@DR1 ~]#service pulse start接下来,还要在主、备节点启用系统的包转发功能(其实只有在NAT模式下需要),命令如下:
[root@DR1 ~]#echo "1" >/proc/sys/net/ipv4/ip_forward 最后,在两个Real server节点上执行lvsrs 脚本,命令如下:
[root@rs1 ~]#/etc/init.d/lvsrs start 到此为止,利用piranha工具搭建的高可用LVS 集群系统已经运行起来了。
12、LVS使用需要注意的问题
LVS经常使用的集群网络架构:
1. 内网集群,外网映射VIP

2. 全外网LVS集群(DR)模式
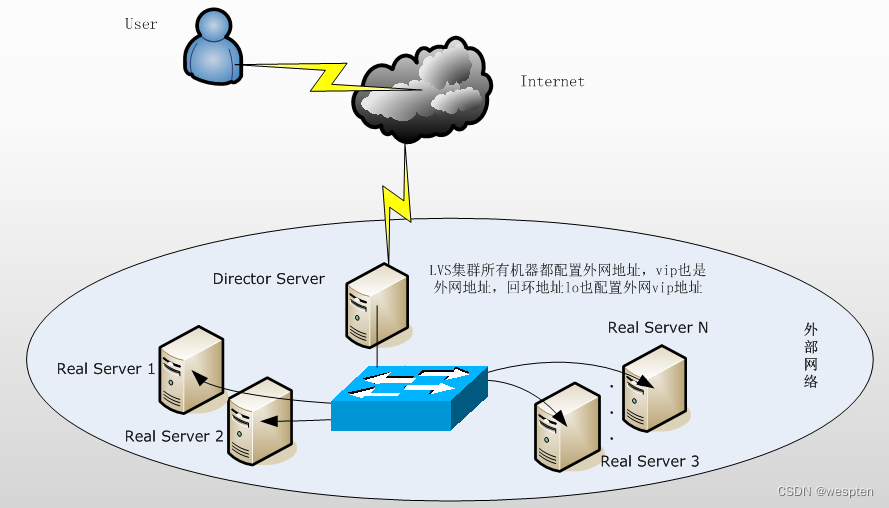
LVS使用需要注意的问题:
1. 网络方面,推荐关闭selinux;
2. 推荐lvs+keepalived组合;
3. dr模式需要realserver绑定vip地址;
五、HAproxy七层负载均衡集群
1、HAProxy简介
Haproxy是一个开源的高性能的反向代理或者说是负载均衡服务软件之一,由C语言编写而成,支持会话保持、七层处理、健康检查、故障修复后自动加载、动静分离。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接;
Haproxy软件引入了frontend,backend的功能,frontend(acl规则匹配)可以运维管理人员根据任意HTTP请求头做规则匹配,然后把请求定向到相关的backend(server pools等待前端把请求转过来的服务器组)。
借助HAProxy可以快速、可靠地提供基于TCP和HTTP应用的负载均衡解决方案,HAProxy作为一款专业的负载均衡软件,它的显著优点如下:
1. 可靠性和稳定性非常好,可以与硬件级的F5负载均衡设备相媲美。
2. 最高可以同时维护40000~50000个并发连接,单位时间内处理的最大请求数为20000个,最大数据处理能力可达10Gbps。作为软件级别的负载均衡来说,HAProxy的性能强大可见一斑。
3. 支持多于8种负载均衡算法,同时也支持session保持。
4. 支持虚拟主机功能,这样实现Web负载均衡更加灵活。
5. 从HAProxy1.3版本后开始支持连接拒绝、全透明代理等功能,这些功能是其他负载均衡器所不具备的。
6. HAProxy拥有一个功能强大的服务器状态监控页面,通过此页面可以实时了解系统的运行状况。
7. HAProxy拥有功能强大的ACL支持,能给使用带来很大方便。
8. HAProxy是借助于操作系统的技术特性来实现性能最大化的,因此,在使用HAProxy时,对操作系统进行性能调优是非常重要的。在业务系统方面,HAProxy非常适用于那些并发量特别大且需要持久连接或七层处理机制的Web系统,例如门户网站或电商网站等。另外HAProxy也可用于Mysql数据库(读操作)的负载均衡。
2、四层和七层负载均衡的区别
HAProxy是一个四层和七层负载均衡器。下面简单介绍下四层和七层的概念与区别。
所谓的四层就是OSI参考模型中的第四层。四层负载均衡也称为四层交换机,它主要是通过分析IP层及TCP/UDP层的流量实现的基于IP加端口的负载均衡。常见的基于四层的负载均衡器有LVS、F5等。
以常见的TCP应用为例,负载均衡器在接收到第一个来自客户端的SYN请求时,会通过设定的负载均衡算法选择一个最佳的后端服务器,同时将报文中目标IP地址修改为后端服务器IP,然后直接转发给该后端服务器,这样一个负载均衡请求就完成了。从这个过程来看,一个TCP连接是客户端和服务器直接建立的,而负载均衡器只不过完成了一个类似路由器的转发动作。在某些负载均衡策略中,为保证后端服务器返回的报文可以正确传递给负载均衡器,在转发报文的同时可能还会对报文原来的源地址进行修改。
整个过程如下图所示:

同理,七层负载均衡器也称为七层交换机,位于OSI的最高层,即应用层,此时负载均衡器支持多种应用协议,常见的有HTTP、FTP、SMTP等。七层负载均衡器可以根据报文内容,再配合负载均衡算法来选择后端服务器,因此也称为“内容交换器”。比如,对于Web服务器的负载均衡,七层负载均衡器不但可以根据“IP+端口”的方式进行负载分流,还可以根据网站的URL、访问域名、浏览器类别、语言等决定负载均衡的策略。例如,有两台Web服务器分别对应中英文两个网站,两个域名分别是A、B,要实现访问A域名时进入中文网站,访问B域名时进入英文网站,这在四层负载均衡器中几乎是无法实现的,而七层负载均衡可以根据客户端访问域名的不同选择对应的网页进行负载均衡处理。常见的七层负载均衡器有HAproxy、Nginx等。
这里仍以常见的TCP应用为例,由于负载均衡器要获取到报文的内容,因此只能先代替后端服务器和客户端建立连接,接着,才能收到客户端发送过来的报文内容,然后再根据该报文中特定字段加上负载均衡器中设置的负载均衡算法来决定最终选择的内部服务器。纵观整个过程,七层负载均衡器在这种情况下类似于一个代理服务器。
整个过程如下图所示:
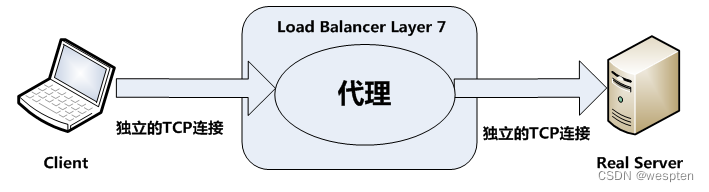
3、HAProxy与LVS的异同
下面就这两种负载均衡软件的异同做一个简单总结:
1. 两者都是软件负载均衡产品,但是LVS是基于Linux操作系统实现的一种软负载均衡,而HAProxy是基于第三应用实现的软负载均衡。
2. LVS是基于四层的IP负载均衡技术,而HAProxy是基于四层和七层技术、可提供TCP和HTTP应用的负载均衡综合解决方案。
3. LVS工作在ISO模型的第四层,因此其状态监测功能单一,而HAProxy在状态监测方面功能强大,可支持端口、URL、脚本等多种状态检测方式。
4. HAProxy虽然功能强大,但是整体处理性能低于四层模式的LVS负载均衡,而LVS拥有接近硬件设备的网络吞吐和连接负载能力。
综上所述,HAProxy和LVS各有优缺点,没有好坏之分,要选择哪个作为负载均衡器,要以实际的应用环境来决定。
Nginx、LVS、Haproxy对比:
| Nginx(七层代理) |
LVS(四层代理) |
Haproxy(四层、七层) |
|
| 优势 |
1.跨平台性; 2.配置简单,容易上手; 3.非阻塞、高并发连接; 4.事件驱动:通信机制采用 epoll 模型,支持更大的并发连接 Master/Worker 结构; 5.内存消耗小; 6.内置的健康检查功能; 7.支持 GZIP 压缩; 8.稳定性高:用于反向代理,宕机的概率微乎其微; 9.会话保持:通过调度算法实现; 10.动静分离:基于location匹配正则; |
1.抗负载能力强,强大的四层代理,媲美F5硬件的四层代理; 2.对内存和 cpu 资源消耗比较低; 3.配置性比较低; 4.工作稳定,自身有完整的双机热备方案如 LVS+Keepalived; 5.无流量,LVS 只分发请求,而流量并不从它本身出去,这点保证了均衡器 IO 的性能不会受到大流量的影响。 6.会话保持; |
1.支持 Session 的保持,Cookie 的引导;同时支持通过获取指定的 url 来检测后端服务器的状态。 2.基于TCP协议的负载效率高于Nginx; 3.负载均衡策略非常多; 4.动静分离:支持acl规则匹配; 5.高效稳定; 6.节点健康检查:支持多种方式检测,如端口、url; |
| 劣势 |
1.适用性低:仅能支 持http、https 和 Email 协议,这样就在适用范围上面小些; 2.对后端服务器的健康检查,只支持通过端口来检测,不支持通过 ur l来检测; 3.不支持 Session 的直接保持,但能通过 ip_hash 来解决; 4.不适用于高负载量的并发集群; |
1.健康检查:无法检查后端节点的健康情况; 2.动静分离:不支持正则,无法区分请求; 3.实现比较麻烦; 4.网络环境依赖性较大; |
1.扩展性差:添加新功能很费劲,对不断扩展的新业务,haproxy很难应对; 2.在四层代理时,仅支持tcp协议的代理; |
总结:
- 大型网站架构:对性能有严格要求的时候可以使用lvs或者硬件F5,就单纯从负载均衡的角度来说,lvs也许会成为主流,更适合现在大型的互联网公司;
- 中型网站架构:对于页面分离请求由明确规定,并且性能有严格要求时,可以使用haproxy;
- 中小型网站架构:比如日 PV 小于1000万,需要进行高并发的网站或者对网络不太严格的时候,可以使用nginx;
4、HAProxy原理
代理模式:
1. 四层tcp代理:例如:可用于邮件服务内部协议通信服务器、Mysql服务等;
2.七层应用代理:例如:HTTP代理或https代理。在4层tcp代理模式下,Haproxy仅在客户端和服务器之间双向转发流量。但是在7层模式下Haproxy会分析应用层协议,并且能通过运行、拒绝、交换、增加、修改或者删除请求(request)或者回应(reponse)里指定内容来控制协议。
四层代理:
ISO参考模型中的第四层传输层。四层负载均衡也称为四层交换机,它主要是通过分析IP层及TCP/UDP层的流量实现的基于IP加端口的负载均衡。常见的基于四层的负载均衡器有LVS、F5等。以常见的TCP应用为例,负载均衡器在接收到第一个来自客户端的SYN请求时,会通过设定的负载均衡算法选择一个最佳的后端服务器,同时将报文中目标IP地址修改为后端服务器IP,然后直接转发给该后端服务器,这样一个负载均衡请求就完成了。从这个过程来看,一个TCP连接是客户端和服务器直接建立的,而负载均衡器只不过完成了一个类似路由器的转发动作。在某些负载均衡策略中,为保证后端服务器返回的报文可以正确传递给负载均衡器,在转发报文的同时可能还会对报文原来的源地址进行修改。
整个过程下图所示:

七层代理:
ISO参考模型中的最高层第七层应用层。七层负载均衡也称为七层交换机,此时负载均衡器支持多种应用协议,常见的有HTTP、FTP、SMTP等。七层负载均衡器可以根据报文内容,再配合负载均衡算法来选择后端服务器,因此也称为“内容交换器”。比如,对于Web服务器的负载均衡,七层负载均衡器不但可以根据“IP+端口”的方式进行负载分流,还可以根据网站的URL、访问域名、浏览器类别、语言等决定负载均衡的策略。例如,有两台Web服务器分别对应中英文两个网站,两个域名分别是A、B,要实现访问A域名时进入中文网站,访问B域名时进入英文网站,这在四层负载均衡器中几乎是无法实现的,而七层负载均衡可以根据客户端访问域名的不同选择对应的网页进行负载均衡处理。常见的七层负载均衡器有HAproxy、Nginx等。
这里仍以常见的TCP应用为例,由于负载均衡器要获取到报文的内容,因此只能先代替后端服务器和客户端建立连接,接着,才能收到客户端发送过来的报文内容,然后再根据该报文中特定字段加上负载均衡器中设置的负载均衡算法来决定最终选择的内部服务器。纵观整个过程,七层负载均衡器在这种情况下类似于一个代理服务器。
整个过程如下图所示:
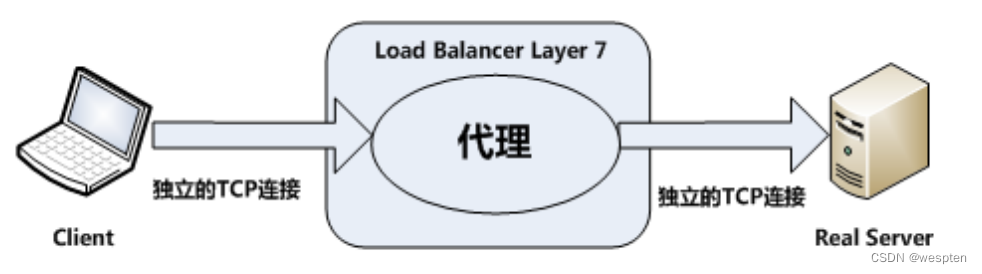
调度算法:
balance roundrobin:表示简单的轮询,负载均衡基础算法;
balance static-rr:表示根据权重;
balance leastconn:表示最少连接者先处理;
balance source:表示根据请求源IP;
balance uri:表示根据请求的URI;
balance url_param:表示根据请求的URl参数来进行调度;
balance hdr(name):表示根据HTTP请求头来锁定每一次HTTP请求;
balance rdp-cookie(name):表示根据据cookie(name)来锁定并哈希每一次TCP请求;
5、HAProxy安装过程与日志输出配置
1. HAProxy安装
可以在HAProxy的官网HAProxy - The Reliable, High Performance TCP/HTTP Load Balancer下载HAProxy的源码包。
这里以操作系统Centos7.4版本为例,下载的HAProxy是目前的稳定版本haproxy-1.8.12.tar.gz,安装过程如下:
[root@haproxy-server app]# tar zcvf haproxy-1.8.12.tar.gz
[root@haproxy-server app]#cd haproxy-1.8.12
[root@haproxy-server haproxy-1.8.12]#make TARGET=linux2628 PREFIX=/usr/local/haproxy
[root@haproxy-server haproxy-1.8.12]#make install PREFIX=/usr/local/haproxy
#将haproxy安装到/usr/local/haproxy下
[root@haproxy-server haproxy-1.8.12]#mkdir /usr/local/haproxy/conf
[root@haproxy-server haproxy-1.8.12]#mkdir /usr/local/haproxy/logs
#haproxy默认不创建配置文件目录和日志目录,这里是创建haproxy配置文件目录和日志文件目录
[root@haproxy-server haproxy-1.8.12]# cp examples/ option-http_proxy.cfg /usr/local/haproxy/conf/haproxy.cfg #haproxy安装完成后,默认安装目录中没有配置文件,这里是将源码包里面的示例配置文件拷贝到配置文件目录。这样,HAProxy就安装完成了。
2. 编写日志输出文件
rsyslog是linux系默认的日志输出系统,配置文件为/etc/rsyslog.conf,此主配置文件默认会读取/etc/rsyslog.d/*.conf目录下所有已.conf结尾的文件。
[root@localhost logs]# cat /etc/rsyslog.conf|grep IncludeConfig
$IncludeConfig /etc/rsyslog.d/*.conf因此,这里我们为haproxy单独创建一个独立的配置文件,将文件命名为haproxy.conf,并放到/etc/rsyslog.d目录下,然后添加如下内容:
$ModLoad imudp
$UDPServerRun 514
local3.* /var/log/haproxy.log
&~ #如果不加这个配置,则除了在/var/log/haproxy.log中写入日志外,也会将haproxy日志写入message文件中。3. 配置rsyslog的主配置文件,开启远程日志
打开 /etc/sysconfig/rsyslog文件,将SYSLOGD_OPTIONS修改为如下内容:
SYSLOGD_OPTIONS=”-c 2 -r -m 0″说明:
-c 2 使用兼容模式,默认是 -c 5。
-r 开启远程日志。
-m 0 标记时间戳。单位是分钟,为0时,表示禁用该功能。配置完成后,需要重启haproxy和rsyslog服务,以保证配置生效:
systemctl restart rsyslog
/etc/init.d/haproxy restart6、HAProxy的常用负载均衡器算法
1. HAProxy支持的负载均衡算法
roundrobin:表示简单的轮询,负载均衡基础算法(静态web系统);
static-rr:表示根据权重(静态web系统);
leastconn:表示最少连接者先处理(db系统);
source:表示根据请求源IP(动态web系统);
uri:表示根据请求的URI;
url_param:表示根据请求的URl参数来进行调度;
hdr(name):表示根据HTTP请求头来锁定每一次HTTP请求;
rdp-cookie(name):表示根据据cookie(name)来锁定并哈希每一次TCP请求;
2. 常用的负载均衡算法
roundrobin:轮询算法;
source:根据请求源IP算法;
lestconn:最少连接者先处理算法;
7、HAProxy基础配置使用案例
1)HAProxy配置文件的组成部分
HAProxy配置文件根据功能和用途,主要有5个部分组成,但有些部分并不是必须的,可以根据需要选择相应的部分进行配置。
(1)global部分
用来设定全局配置参数,属于进程级的配置,通常和操作系统配置有关。
(2)defaults部分
默认参数的配置部分。在此部分设置的参数值,默认会自动被引用到下面的frontend、backend和listen部分中,因此,如果某些参数属于公用的配置,只需在defaults部分添加一次即可。而如果在frontend、backend和listen部分中也配置了与defaults部分一样的参数,那么defaults部分参数对应的值自动被覆盖。
(3)frontend部分
此部分用于设置接收用户请求的前端虚拟节点。frontend是在HAProxy1.3版本之后才引入的一个组件,同时引入的还有backend组件。通过引入这些组件,在很大程度上简化了HAProxy配置文件的复杂性。frontend可以根据ACL规则直接指定要使用的后端backend。
(4)backend部分
此部分用于设置集群后端服务集群的配置,也就是用来添加一组真实服务器,以处理前端用户的请求。添加的真实服务器类似于LVS中的real server节点。
(5)listen部分
此部分是frontend部分和backend部分的结合体。在HAProxy1.3版本之前,HAProxy的所有配置选项都在这个部分中设置。为了保持兼容性,HAProxy新的版本仍然保留了listen组件的配置方式。目前在HAProxy中,两种配置方式任选其一即可。
2)HAProxy配置文件详解
1. global部分
全局配置区域参数是进程级的,通常是和操作系统相关。这些参数一般只设置一次,如果配置无误,就不需要再次进行修改。

配置示例如下:
global
log 127.0.0.1 local0 info
maxconn 4096
user nobody
group nobody
daemon
nbproc 1
pidfile /usr/local/haproxy/logs/haproxy.pid下面介绍每个选项的含义:
log:全局的日志配置,local0是日志设备,info表示日志级别。其中日志级别有err、warning、info、debug四种可选。这个配置表示使用127.0.0.1上的rsyslog服务中的local0日志设备,记录日志等级为info。
maxconn:设定每个haproxy进程可接受的最大并发连接数,此选项等同于Linux命令行选项“ulimit -n”。
user/ group:设置运行haproxy进程的用户和组,也可使用用户和组的uid和gid值来替代。
daemon:设置HAProxy进程进入后台运行。这是推荐的运行模式。
nbproc:设置HAProxy启动时可创建的进程数,此参数要求将HAProxy运行模式设置为“daemon”,默认只启动一个进程。根据使用经验,该值的设置应该小于服务器的CPU核数。创建多个进程,能够减少每个进程的任务队列,但是过多的进程可能会导致进程的崩溃。
pidfile:指定HAProxy进程的pid文件。启动进程的用户必须有访问此文件的权限。
2. defaults部分
配置默认参数,这些参数可以被用到frontend,backend,Listen组件。
配置示例如下:
defaults
mode http
retries 3
timeout connect 10s
timeout client 20s
timeout server 30s
timeout check 5smode:设置HAProxy实例默认的运行模式,有tcp、http、health三个可选值。
tcp模式:在此模式下,客户端和服务器端之间将建立一个全双工的连接,不会对七层报文做任何类型的检查,默认为tcp模式,经常用于SSL、SSH、SMTP等应用。
http模式:在此模式下,客户端请求在转发至后端服务器之前将会被深度分析,所有不与RFC格式兼容的请求都会被拒绝。
health模式:目前此模式基本已经废弃,不在多说。
retries:设置连接后端服务器的失败重试次数,连接失败的次数如果超过这里设置的值,HAProxy会将对应的后端服务器标记为不可用。此参数也可在后面部分进行设置。
timeout connect:设置成功连接到一台服务器的最长等待时间,默认单位是毫秒,但也可以使用其他的时间单位后缀。
timeout client:设置连接客户端发送数据时最长等待时间,默认单位是毫秒,也可以使用其他的时间单位后缀。
timeout server:设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒,也可以使用其他的时间单位后缀。
timeout check:设置对后端服务器的检测超时时间,默认单位是毫秒,也可以使用其他的时间单位后缀。
3. frontend部分
处理请求的虚拟节点,Frontend可以将匹配到本地区域的请求交给下边的。
配置示例如下:
frontend www
bind *:80
mode http
option httplog
option forwardfor
option httpclose
log global
default_backend htmpool这部分通过frontend关键字定义了一个名为“www”的前端虚拟节点,下面介绍每个选项的含义:
bind:此选项只能在frontend和listen部分进行定义,用于定义一个或几个监听的套接字。bind的使用格式为:
bind [<address>:<port_range>] interface <interface>其中,address为可选选项,其可以为主机名或IP地址,如果将其设置为“*”或“0.0.0.0”,将监听当前系统的所有IPv4地址。port_range可以是一个特定的TCP端口,也可是一个端口范围,小于1024的端口需要有特定权限的用户才能使用。interface为可选选项,用来指定网络接口的名称,只能在Linux系统上使用。
option httplog:在默认情况下,haproxy日志是不记录HTTP请求的,这样很不方便HAProxy问题的排查与监控。通过此选项可以启用日志记录HTTP请求。
option forwardfor:如果后端服务器需要获得客户端的真实IP,就需要配置此参数。由于HAProxy工作于反向代理模式,因此发往后端真实服务器的请求中的客户端IP均为HAProxy主机的IP,而非真正访问客户端的地址,这就导致真实服务器端无法记录客户端真正请求来源的IP,而“X-Forwarded-For”则可用于解决此问题。通过使用“forwardfor”选项,HAProxy就可以向每个发往后端真实服务器的请求添加“X-Forwarded-For”记录,这样后端真实服务器日志可以通过“X-Forwarded-For”信息来记录客户端来源IP。
option httpclose:此选项表示在客户端和服务器端完成一次连接请求后,HAProxy将主动关闭此TCP连接。这是对性能非常有帮助的一个参数。
log global:表示使用全局的日志配置,这里的“global”表示引用在HAProxy配置文件global部分中定义的log选项配置格式。
default_backend:指定默认的后端服务器池,也就是指定一组后端真实服务器,而这些真实服务器组将在backend段进行定义。这里的htmpool就是一个后端服务器组。
4. backend部分
后端服务集群的配置,是真实服务器,一个Back对应一个或多个实体服务器。
配置示例如下:
backend htmpool
mode http
option redispatch
option abortonclose
balance roundrobin
cookie SERVERID
option httpchk GET /index.php
server web1 10.200.34.181:80 cookie server1 weight 6 check inter 2000 rise 2 fall 3
server web2 10.200.34.182:8080 cookie server2 weight 6 check inter 2000 rise 2 fall 3这个部分通过backend关键字定义了一个名为“htmpool”的后端真实服务器组。下面介绍每个选项的含义。
option redispatch:此参数用于cookie保持的环境中。在默认情况下,HAProxy会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性。而如果后端的服务器出现故障,客户端的cookie是不会刷新的,这就出现了问题。
此时,如果设置此参数,就会将客户的请求强制定向到另外一个健康的后端服务器上,以保证服务的正常。
option abortonclose:如果设置了此参数,可以在服务器负载很高的情况下,自动结束掉当前队列中处理时间比较长的链接。
balance:此关键字用来定义负载均衡算法。目前HAProxy支持多种负载均衡算法,常用的有如下几种:
roundrobin:是基于权重进行轮叫调度的算法,在服务器的性能分布比较均匀的时候,这是一种最公平、最合理的算法。此算法经常使用。
static-rr:也是基于权重进行轮叫的调度算法,不过此算法为静态方法,在运行时调整其服务器权重不会生效。
source:是基于请求源IP的算法。此算法先对请求的源IP进行hash运算,然后将结果与后端服务器的权重总数相除后转发至某个匹配的后端服务器。这种方式可以使同一个客户端IP的请求始终被转发到某特定的后端服务器。
leastconn:此算法会将新的连接请求转发到具有最少连接数目的后端服务器。在会话时间较长的场景中推荐使用此算法,例如数据库负载均衡等。此算法不适合会话较短的环境中,例如基于HTTP的应用。
uri:此算法会对部分或整个URI进行hash运算,再经过与服务器的总权重相除,最后转发到某台匹配的后端服务器上。
uri_param:此算法会根据URL路径中的参数进行转发,这样可保证在后端真实服务器数量不变时,同一个用户的请求始终分发到同一台机器上。
hdr(<name>):此算法根据http头进行转发,如果指定的http头名称不存在,则使用roundrobin算法进行策略转发。
cookie:表示允许向cookie插入SERVERID,每台服务器的SERVERID可在下面的server关键字中使用cookie关键字定义。
option httpchk:此选项表示启用HTTP的服务状态检测功能。HAProxy作为一款专业的负载均衡器,它支持对backend部分指定的后端服务节点的健康检查,以保证在后端backend中某个节点不能服务时,把从frotend端进来的客户端请求分配至backend中其他健康节点上,从而保证整体服务的可用性。“option httpchk”的用法如下:
option httpchk <method> <uri> <version>其中,各个参数的含义如下:
method:表示HTTP请求的方式,常用的有OPTIONS、GET、HEAD几种方式。一般的健康检查可以采用HEAD方式进行,而不是才采用GET方式,这是因为HEAD方式没有数据返回,仅检查Response的HEAD是不是200状态。因此相对与GET来说,HEAD方式更快,更简单。
uri:表示要检测的URL地址,通过执行此URL,可以获取后端服务器的运行状态。在正常情况下将返回状态码200,返回其他状态码均为异常状态。
version:指定心跳检测时的HTTP的版本号。
server:这个关键字用来定义多个后端真实服务器,不能用于defaults和frontend部分。使用格式为:
server <name> <address>[:port] [param*]其中,每个参数含义如下:
<name>:为后端真实服务器指定一个内部名称,随便定义一个即可。
<address>:后端真实服务器的IP地址或主机名。
<port>:指定连接请求发往真实服务器时的目标端口。在未设定时,将使用客户端请求时的同一端口。
[param*]:为后端服务器设定的一系参数,可用参数非常多,这里仅介绍常用的一些参数:
check:表示启用对此后端服务器执行健康状态检查。
inter:设置健康状态检查的时间间隔,单位为毫秒。
rise:设置从故障状态转换至正常状态需要成功检查的次数,例如。“rise 2”表示2次检查正确就认为此服务器可用。
fall:设置后端服务器从正常状态转换为不可用状态需要检查的次数,例如,“fall 3”表示3次检查失败就认为此服务器不可用。
cookie:为指定的后端服务器设定cookie值,此处指定的值将在请求入站时被检查,第一次为此值挑选的后端服务器将在后续的请求中一直被选中,其目的在于实现持久连接的功能。上面的“cookie server1”表示web1的serverid为server1。同理,“cookie server2”表示web2的serverid为server2。
weight:设置后端真实服务器的权重,默认为1,最大值为256。设置为0表示不参与负载均衡。
backup:设置后端真实服务器的备份服务器,仅仅在后端所有真实服务器均不可用的情况下才启用。
5. listen部分
HAProxy配置文件的第五部分是关于listen部分的配置,配置示例如下:
listen admin_stats
bind 0.0.0.0:9188
mode http
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /haproxy-status
stats realm welcome login\ Haproxy
stats auth admin:admin~!@
stats hide-version
stats admin if TRUE这个部分通过listen关键字定义了一个名为“admin_stats”的实例,其实就是定义了一个HAProxy的监控页面,每个选项的含义如下:
stats refresh:设置HAProxy监控统计页面自动刷新的时间。
stats uri:设置HAProxy监控统计页面的URL路径,可随意指定。例如,指定“stats uri /haproxy-status”,就可以通过http://IP:9188/haproxy-status 查看。
stats realm:设置登录HAProxy统计页面时密码框上的文本提示信息。
stats auth:设置登录HAProxy统计页面的用户名和密码。用户名和密码通过冒号分割。可为监控页面设置多个用户名和密码,每行一个。
stats hide-version:用来隐藏统计页面上HAProxy的版本信息。
stats admin if TRUE:通过设置此选项,可以在监控页面上手工启用或禁用后端真实服务器,仅在haproxy1.4.9以后版本有效。
至此,完整的一个HAProxy配置文件介绍完毕了。当然,这里介绍的仅仅是最常用的一些配置参数,要深入了解HAProxy的功能,可参阅官方文档。
6. 完整配置文件案例
haproxy 配置中分成五部分内容:
① global: 设置全局配置参数,属于进程的配置,通常是和操作系统相关。
② defaults:配置默认参数,这些参数可以被用到frontend,backend,Listen组件;
③ frontend:接收请求的前端虚拟节点,Frontend可以更加规则直接指定具体使用后端的backend;
④ backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器;
⑤ Listen :frontend和backend的组合体。
vim /etc/haproxy/haproxy.cfg
gloab:全局配置
log:日志配置
maxconn:最大连接限制(优先级低)
uid:用户
gid:组用户
deamon:守护进程运行
nbproc :haproxy进程数,该值的设置应该和服务器的CPU核心数一致,比如设置为 16,即常见的2颗8核心CPU的服务器,即共有16核心,则可以将其值设置为:<=16 ,创建多个进程数,可以减少每个进程的任务队列,但是过多的进程数也可能会导致进程的崩溃。
pidfile /run/haproxy.pid :haproxy进程ID存储位置
defaults:针对(listen和backend块进行设置没如果块中没设置,则使用默认设置)默认配置
log:日志使用全局配置
mode:模式7层LB
maxconn:最大连接数(优先级中)
retries:健康检查。3次连接失败就认为服务不可用
option:服务不可用后的操作,重定向到其他健康服务器
contimeout :(重传计时器)定义haproxy将客户端!!!请求!!!转发至后端服务器,所等待的超时时长
clitimeout:(向后长连接)haproxy作为客户,和后端服务器之间!!!空闲连接!!!的超时时间,到时候发送fin指令
srvtimeout :(向前长连接)haproxy作为服务器,和用户之间空闲连接的超时时间,到时候发送fin指令
option abortonclose :当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
stats uri /admin?stats:设置统计页面的uri为/admin?stats
stats realm Private lands:设置统计页面认证时的提示内容
stats auth admin:password:设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats hide-version:隐藏统计页面上的haproxy版本信息
frontend:前端配置块。面对用户侧
bind:面对用户监听地址和端口
mode:http模式的LB
log:日志使用全局配置
option httplog:默认日志格式非常简陋,仅包括源地址、目标地址和实例名称,而“option httplog参数将会使得日志格式变得丰富许多,其通常包括但不限于HTTP请求、连接计时器、会话状态、连接数、捕获的首部及cookie、“frontend”、“backend”及服务器名称,当然也包括源地址和端口号等。
option http close: 每次请求完毕后,关闭http通道
acl html url_reg -i \.html$ :1. 访问控制列表名称html。规则要求访问以html结尾的url时
use_backend html-server if html :2.如果满足acl html规则,则推送给后端服务器 html-server
default_backend html-server 3:默认的后端服务器是 html-server
backend html-server:后端服务器名称为 html-server
mode http:模式为7层代理
balance roundrobin:算法为轮训
option httpchk GET /index.html :允许用http协议检查server 的健康
cookie SERVERID insert indirect nocache:轮询的同时,根据插入的cookie SERVERID 的值来做会话保持,将相同的用户请求,转发给相同的真实服务器。
server html-A web1:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5:cookie 3 服务器ID,避免rr算法将客户机请求转发给其他服务器 ,对后端服务器的健康状况检查间隔为2000毫秒,连续2次健康检查成功,则认为是有效的,连续5次健康检查失败,则认为服务器宕机
server html-B web2:80 weight 1 cookie 4 check inter 2000 rise 2 fall 5补充:
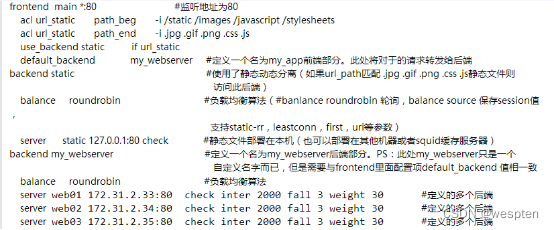
8、管理与维护HAProxy
HAProxy安装完成后,会在安装根目录的sbin目录下生成一个可执行的二进制文件haproxy,对HAProxy的启动、关闭、重启等维护操作都是通过这个二进制文件来实现的,执行“haproxy -h”即可得到此文件的用法。
haproxy [-f < 配置文件>] [ -vdVD ] [-n 最大并发连接总数] [-N 默认的连接数]haproxy常用的参数以及含义如下所示:
参数 含义
-v 显示当前版本信息;“-vv”显示已知的创建选项。
-d 表示让进程运行在debug模式;“-db”表示禁用后台模式,让程序跑在前台。
-D 让程序以daemon模式启动,此选项也可以在HAProxy配置文件中设置。
-q 表示安静模式,程序运行不输出任何信息。
-c 对HAProxy配置文件进行语法检查。此参数非常有用。如果配置文件错误,会输出对应的错误位置和错误信息。
-n 设置最大并发连接总数。
-m 限制可用的内存大小,以MB为单位。
-N 设置默认的连接数,
-p 设置HAProxy的PID文件路径。
-de 不使用epoll模型。
-ds 不使用speculative epoll
-dp 不使用poll模型。
-sf 程序启动后向PID文件里的进程发送FINISH信号,这个参数需要放在命令行的最后。
-st 程序启动后向PID文件里的进程发送TERMINATE信号,这个参数放在命令行的最后,经常用于重启HAProxy进程。介绍完haproxy常用的参数后,下面开始启动HAProxy,操作如下:
[root@haproxy-server haproxy]#/usr/local/haproxy/sbin/haproxy -f \
> /usr/local/haproxy/conf/haproxy.cfg如果要关闭HAProxy,执行执行如下命令即可:
[root@haproxy-server haproxy]#killall -9 haproxy而如果要平滑重启HAProxy,可执行如下命令:
[root@haproxy-server haproxy]# /usr/local/haproxy/sbin/haproxy -f \
/usr/local/haproxy/conf/haproxy.cfg -st `cat /usr/local/haproxy/logs/haproxy.pid`Haproxy安装完成后,会在/etc/init.d/目录下生成一个haproxy的脚本文件,这个脚本也可以用来启动和管理haproxy服务。
[root@localhost keepalived]# /etc/init.d/haproxy
Usage: /etc/init.d/haproxy {start|stop|status|checkconfig|restart|try-restart|reload|force-reload}
9、使用HAProxy的Web监控平台
HAProxy虽然实现了服务的故障转移,但是在主机或者服务出现故障的时候,并不能发出通知告知运维人员,这对于及时性要求很高的业务系统来说,是非常不便的,不过,HAProxy似乎也考虑到了这一点,在新的版本中HAProxy推出了一个基于Web的监控平台,通过这个平台可以查看此集群系统所有后端服务器的运行状态,在后端服务或服务器出现故障时,监控页面会通过不同的颜色来展示故障信息,这在很大程度上解决了后端服务器故障报警的问题,运维人员可通过监控这个页面来第一时间发现节点故障,进而修复故障。
在这个监控页面中,详细记录了HAProxy中配置的frontend、backend等信息,在backend中有各个后端真实服务器的运行状态,正常情况下,所有后端服务器都以浅绿色展示,当某台后端服务器出现故障时,将以深橙色显示。其实每个颜色代表什么状态,在上面这个图中都有详细的说明。
在这个监控页面中,还可以执行关闭自动刷新、隐藏故障状态的节点、手动刷新、导出数据为CSV文件等各种操作。在新版的HAProxy中,又增加了对backend后端节点的管理功能,例如可以在Web页面下执行Disable、Enable、Soft Stop、Soft Start等对后端节点的管理操作。这个功能在后端节点升级、故障维护时非常有用。
10、haproxy 解决集群session共享问题
Haproxy二种方法保持客户端session一致:
1. 用户IP识别
haroxy 将用户IP经过hash计算后 指定到固定的真实服务器上(类似于nginx 的IP hash 指令)
配置指令:
balance source2. cookie 识别
haproxy 将WEB服务端发送给客户端的cookie中插入(或添加加前缀)haproxy定义的后端的服务器COOKIE ID。
配置指令例举:
cookie SESSION_COOKIE insert indirect nocache用firebug可以观察到用户的请求头的cookie里有类似:
"Cookie 9ai9=0bc588656ca05ecf7588c65f9be214f5; SESSION_COOKIE=server1" SESSION_COOKIE=server1就是haproxy添加的内容。
11、通过HAProxy的ACL规则实现智能负载均衡
由于HAProxy可以工作在七层模型下, 因此,要实现HAProxy的强大功能,一定要使用强大灵活的ACL规则,通过ACL规则可以实现基于HAProxy的智能负载均衡系统。HAProxy通过ACL规则完成两种主要的功能,分别是:
1. 通过设置的ACL规则检查客户端请求是否合法。如果符合ACL规则要求,那么就将放行,反正,如果不符合规则,则直接中断请求。
2. 符合ACL规则要求的请求将被提交到后端的backend服务器集群,进而实现基于ACL规则的负载均衡。
HAProxy中的ACL规则经常使用在frontend段中,使用方法如下:
acl 自定义的acl名称 acl方法 -i [匹配的路径或文件]其中:
acl:是一个关键字,表示定义ACL规则的开始。后面需要跟上自定义的ACL名称 。
acl方法:这个字段用来定义实现ACL的方法,HAProxy定义了很多ACL方法,经常使用的方法有hdr_reg(host)、hdr_dom(host)、hdr_beg(host)、url_sub、url_dir、path_beg、path_end等。
-i:表示忽略大小写,后面需要跟上匹配的路径或文件或正则表达式。
与ACL规则一起使用的HAProxy参数还有use_backend,use_backend后面需要跟上一个backend实例名,表示在满足ACL规则后去请求哪个backend实例,与use_backend对应的还有default_backend参数,它表示在没有满足ACL条件的时候默认使用哪个后端backend。
下面列举几个常见的ACL规则例子:
acl www_policy hdr_reg(host) -i ^(www.z.cn|z.cn)
acl bbs_policy hdr_dom(host) -i bbs.z.cn
acl url_policy url_sub -i buy_sid=
use_backend server_www if www_policy
use_backend server_app if url_policy
use_backend server_bbs if bbs_policy
default_backend server_cache这里仅仅列出了HAProxy配置文件中ACL规则的配置部分,其它选项并未列出。
在这个例子中,定义了www_policy、bbs_policy、url_policy三个ACL规则,第一条规则表示如果客户端以www.z.cn或z.cn开头的域名发送请求时,则此规则返回true,同理第二条规则表示如果客户端通过bbs.z.cn域名发送请求时,则此规则返回true,而第三条规则表示如果客户端在请求的url中包含“buy_sid=”字符串时,则此规则返回true。
第四、第五、第六条规则定义了当www_policy、bbs_policy、url_policy三个ACL规则返回true是要调度到哪个后端backend,例如当用户的请求满足www_policy规则时,那么HAProxy会将用户的请求直接发往名为server_www的后端backend,其它以此类推。而当用户的请求不满足任何一个ACL规则时,HAProxy就会把请求发往由default_backend选项指定的server_cache这个后端backend。
再看下面这个例子:
acl url_static path_end .gif .png .jpg .css .js
acl host_www hdr_beg(host) -i www
acl host_static hdr_beg(host) -i img. video. download. ftp.
use_backend static if host_static || host_www url_static
use_backend www if host_www
default_backend server_cache与上面的例子类似,本例中也定义了url_static、host_www和host_static三个ACL规则,其中,第一条规则通过“path_end”参数定义了如果客户端在请求的url中以.gif或 .png或.jpg或.css或.js结尾时返回true,第二条规则通过“hdr_beg(host)”参数定义了如果客户端以www开头的域名发送请求时则返回true,同理,第三条规则也是通过“hdr_beg(host)”参数定义了如果客户端以img.或video.或download.或ftp.开头的域名发送请求时则返回true。
第四、第五条规则定义了当满足acl规则后要调度到哪个后端backend,例如当用户的请求同时满足host_static规则与url_static规则,或同时满足host_www和url_static规则时,那么会将用户请求直接发往名为static的后端backend,如果用户请求满足host_www规则,那么请求将被调度到名为www的后端backend,如果所有规则都不满足,那么将用户请求默认调度到名为server_cache的这个后端backend。
案例架构:

12、HAProxy动静分离
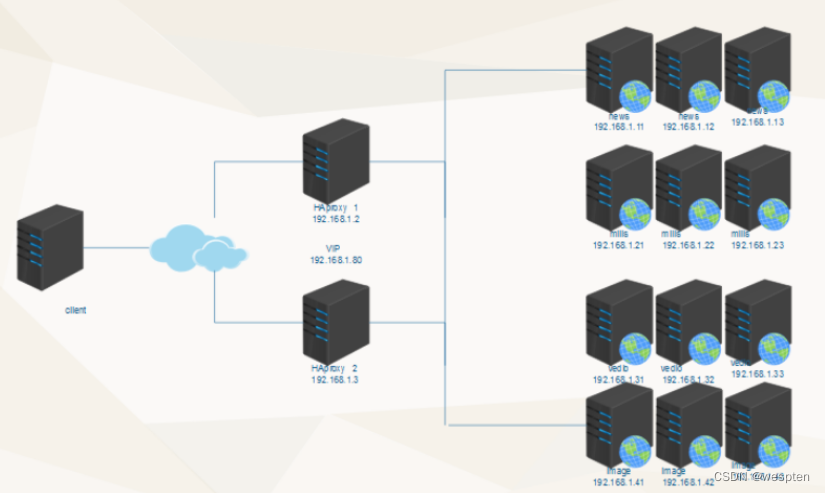
环境:
Client:192.168.19.1/24
HAproxy:192.168.19.103/24
HTML A: 192.168.19.100/24
HTML B: 192.168.19.102/24
PHP A:192.168.19.104/24HTML A & HTML B:
yum install httpd
分别创建测试页面 index.html ,开启服务PHP A:
yum install httpd php
创建测试页面 index.php ,开启服务安装HAproxy:
tar xf haproxy-1.4.27.tar.gz
cd haproxy-1.4.27
make TARGET=linux26 PREFIX=/usr/local/haproxy install生成HAproxy配置文件:
######## 全局配置信息 #########
######参数是进程级的,通常和操作系统相关#######
global
log 127.0.0.1 local3 info #日志服务器
maxconn 4096 #最大连接数
user nobody #用户身份
group nobody #组身份
daemon #守护进程方式后台运行
nbproc 1 #工作进程数量
####### ###########默认设置 ###################
#####这些参数是配置 frontend,backend,listen 组的 ###########
defaults #这些参数可以被利用配置到frontend,backend,listen组件
log global
mode http #工作模式 http ,tcp 是 4 层,http是 7 层
maxconn 2048 #最大连接数
retries 3 #3 次连接失败就认为服务器不可用
option redispatch #如果 cookie 写入了 serverId 而客户端不会刷新 cookie,当serverId 对应的服务器挂掉后,强制定向到其他健康的服务器
stats uri /haproxy #使用浏览器访问 http://192.168.122.254/haproxy,可以看到服务器状态
stats auth wing:123 #用户认证,客户端使用elinks浏览器的时候不生效
contimeout 5000 #连接超时时间,单位毫秒ms
clitimeout 50000 #客户端超时
srvtimeout 50000 #服务器超时
frontend http-in
bind 0.0.0.0:80 #监听端口
mode http
log global
option httplog #日志类别 http 日志格式
option httpclose #打开支持主动关闭功能,每次请求完毕后主动关闭http通道 ,ha-proxy不支持keep-alive,只能模拟这种模式的实现
acl php url_reg -i \.php$ #acl <ACL名字> <类型> <大小写> <规则>
acl html url_reg -i \.html$ #use_backend <服务器组> if <ACL名字>
use_backend php-server if php
use_backend html-server if html
default_backend html-server #默认使用的服务器组
backend php-server
mode http
balance roundrobin #负载均衡的方式
option httpchk GET /index.php #健康检查
cookie SERVERID insert indirect nocache #客户端的 cookie 信息,允许插入serverid到cookie中,此处cookie号不同
server php-A 192.168.19.104:80 weight 1 cookie 1 check inter 2000 rise 2 fall 5
#cookie 1 标识 serverid 为 1
#check inter 2000 检测心跳频率
#rise 2 2 次正确认为服务器可用
#fall 5 5 次失败认为服务器不可用
backend html-server
mode http
balance roundrobin
option httpchk GET /index.html
cookie SERVERID insert indirect nocache
server html-A 192.168.19.100:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5
server html-B 192.168.19.102:80 weight 1 cookie 4 check inter 2000 rise 2 fall 5启动HAproxy:
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg查看HAproxy状态:
http://localhost/haproxy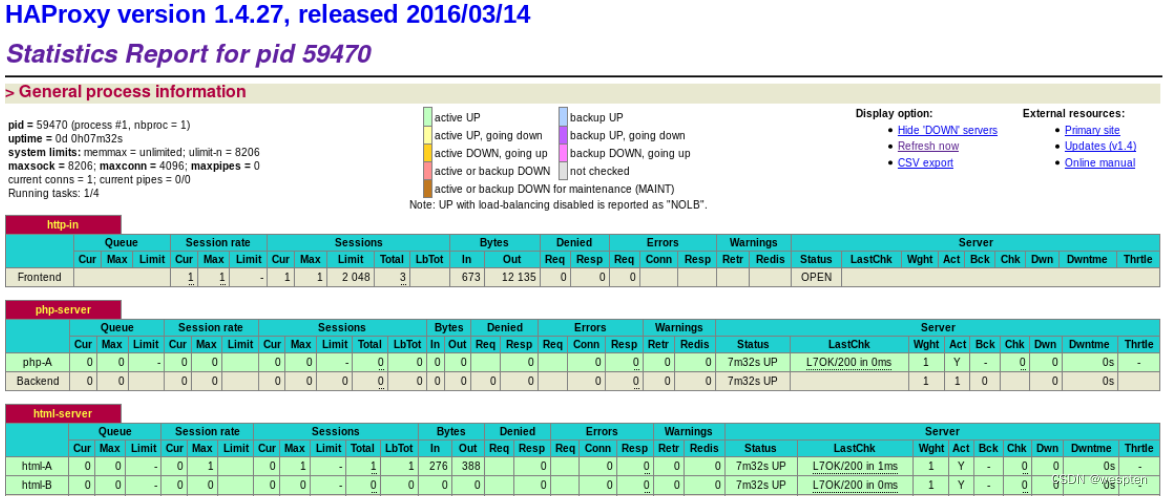
在客户端访问 HAproxy 测试:


13、HAproxy Apache 负载均衡
环境:
Client:192.168.19.104/24
HAproxy:192.168.19.103/24
web1:192.168.19.100/24
web2:192.168.19.102/24HTML A & HTML B 创建测试页面:
做好域名解析
systemctl stop firewalld && setenforce 0
ntpdate 时间服务器ip(略)
yum install httpd
echo web1 > /var/www/html/index.html
echo web2 > /var/www/html/index.html安装HAproxy:
# yum install epel-release -y
# yum install haproxy -y配置HAproxy:
# vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local3 info
maxconn 4096
uid nobody
gid nobody
daemon
nbproc 1
pidfile /run/haproxy.pid
defaults
log global
mode http
maxconn 2048
retries 3
option redispatch
contimeout 5000
clitimeout 50000
srvtimeout 50000
option abortonclose
stats uri /admin?stats
stats realm Private lands
stats auth admin:password
stats hide-version
frontend http-in
bind 0.0.0.0:80
mode http
log global
option httplog
option httpclose
acl html url_reg -i \.html$
use_backend html-server if html
default_backend html-server
backend html-server
mode http
balance roundrobin
option httpchk GET /index.html
cookie SERVERID insert indirect nocache
server html-A web1:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5
server html-B web2:80 weight 1 cookie 4 check inter 2000 rise 2 fall 5重启服务:
systemctl start haproxy.service测试结果:
测试HAproxy状态:
根据配置定义的地址。
stats uri /admin?stats
stats realm Private lands
stats auth admin:password访问:http://192.168.19.103/admin?status
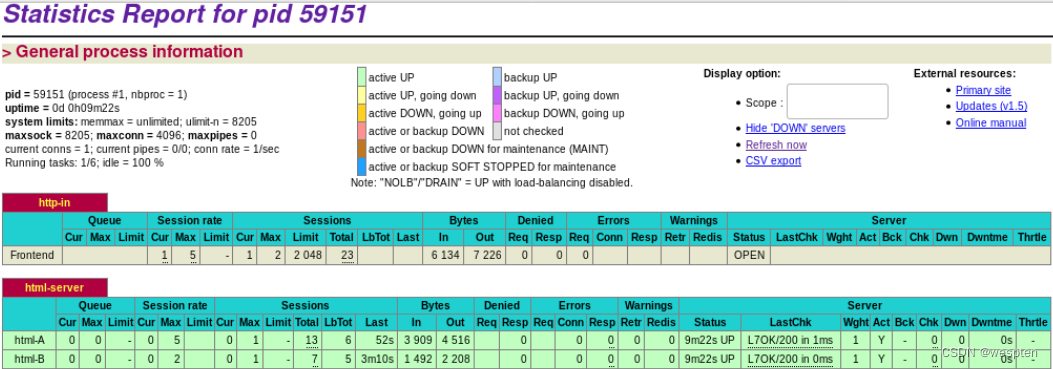
14、搭建 HAproxy+Nginx+Tomcat 负载均衡
案例拓扑:

案例环境:
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 7.4 1708 64bit |
192.168.100.101 |
ha.linuxfan.cn |
haproxy-1.4.24.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.102 |
ng1.linuxfan.cn |
nginx-1.12.2.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.103 |
ng2.linuxfan.cn |
nginx-1.12.2.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.104 |
tm1.linuxfan.cn |
jdk-8u171-linux-x64.tar.gz apache-tomcat-9.0.10.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.105 |
tm2.linuxfan.cn |
jdk-8u171-linux-x64.tar.gz apache-tomcat-9.0.10.tar.gz |
案例步骤:
- 搭建并配置nginx节点,准备网页,启动服务,测试节点(两台nginx配置相同,在此列出一台的配置);
- 搭建并配置tomcat节点,准备网页,启动服务,测试节点(两台tomcat配置相同,在此列出一台的配置);
- 安装Haproxy程序软件;
- 配置Haproxy服务;
- 启动Haproxy服务;
- 客户端访问测试验证集群;
- 将Haproxy的日志文件分离(便于查看);
- 配置Haproxy服务的日志管理界面;
- 客户端访问测试Haproxy的日志管理界面;
1. 建并配置nginx节点,准备网页,启动服务,测试节点(两台nginx配置相同,在此列出一台的配置)
[root@ng1 ~]# yum -y install pcre-devel zlib-devel
[root@ng1 ~]# useradd -M -s /sbin/nologin nginx
[root@ng1 ~]# tar zxvf nginx-1.12.2.tar.gz -C /usr/src/
[root@ng1 ~]# cd /usr/src/nginx-1.12.2/
[root@ng1 nginx-1.12.2]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_stub_status_module
[root@ng1 nginx-1.12.2]# make && make install
[root@ng1 nginx-1.12.2]# cd
[root@ng1 ~]# ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
[root@ng1 ~]# vi /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginxapi
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=kill -s HUP $(cat /usr/local/nginx/logs/nginx.pid)
ExecStop=kill -s QUIT $(cat /usr/local/nginx/logs/nginx.pid)
PrivateTmp=Flase
[Install]
WantedBy=multi-user.target
[root@ng1 ~]# echo "192.168.100.102" >>/usr/local/nginx/html/index.html
[root@ng1 ~]# systemctl start nginx
[root@ng1 ~]# systemctl enable nginx
[root@ng1 ~]# netstat -utpln |grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 3538/nginx: master2. 搭建并配置tomcat节点,准备网页,启动服务,测试节点(两台tomcat配置相同,在此列出一台的配置)
[root@tm1 ~]# ls
apache-tomcat-9.0.10.tar.gz jdk-8u171-linux-x64.tar.gz
[root@tm1~]# rpm -qa |grep java
[root@tm1 ~]# tar zxvf jdk-8u171-linux-x64.tar.gz
[root@tm1 ~]# mv jdk1.8.0_171/ /usr/local/java
[root@tm1 ~]# ls /usr/local/java
bin db javafx-src.zip lib man release THIRDPARTYLICENSEREADME-JAVAFX.txt
COPYRIGHT include jre LICENSE README.html src.zip THIRDPARTYLICENSEREADME.txt
[root@tm1 ~]# cat <<END >>/etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:/usr/local/java/bin
END
[root@tm1~]# source /etc/profile
[root@tm1 ~]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@tm1 ~]# tar zxvf apache-tomcat-9.0.10.tar.gz
[root@tm1 ~]# mv apache-tomcat-9.0.10 /usr/local/tomcat
[root@tm1 ~]# ls /usr/local/tomcat
bin conf lib LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt temp webapps work
[root@tm1 ~]# vi /usr/local/tomcat/conf/server.xml
150 <Context docBase="/web/webapp" path="" reloadable="false"></Context>
:wq
[root@tm1 ~]# mkdir -p /web/webapp
[root@tm1 ~]# vi /web/webapp/index.jsp
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>JSP TEST PAGE1 </title>
</head>
<body>
<% out.println("Welcome to test site;http://192.168.100.104");%>
</body>
</html>
[root@tm1 ~]# /usr/local/tomcat/bin/startup.sh ##启动apache-tomcat
[root@tm1 ~]# netstat -utpln |grep 8080
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 14758/java3. 安装HAProxy程序软件
[root@ha ~]# yum -y install pcre-devel bzip2-devel ##安装依赖软件包
[root@ha ~]# tar zxvf haproxy-1.4.24.tar.gz -C /usr/src/
[root@ha ~]# cd /usr/src/haproxy-1.4.24/
[root@ha haproxy-1.4.24]# uname -r
3.10.0-693.5.2.el7.x86_64
[root@ha haproxy-1.4.24# make TARGET=linux310 ##make编译,指定系统内核版本为3.10
[root@ha haproxy-1.4.24]# make install
[root@ha haproxy-1.4.24]# cd4. 配置Haproxy服务
[root@ha ~]# mkdir /etc/haproxy ##创建配置文件目录
[root@ha ~]# cp /usr/src/haproxy-1.4.24/examples/haproxy.cfg /etc/haproxy/
[root@ha ~]# vi /etc/haproxy/haproxy.cfg ##修改主配置文件如下
global
log 127.0.0.1 local0 info ##定义日志级别;
log 127.0.0.1 local1 notice
maxconn 4096 ##设定每个haproxy进程所接受的最大并发连接数
uid 99 ##指定运行服务的用户和组
gid 99
daemon ##指定运行模式为daemon,以守护进程的方式工作在后台
defaults
log global ##采取global中的日志配置
mode http ##默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
option httplog ##采用http日志格式记录日志
option dontlognull ##不记录健康检查的日志记录
option httpclose ##关闭保持连接
retries 3 ##检查节点最多失败次数
maxconn 2000 ##最大连接数,定义不得大于global中的值
contimeout 5000 ##连接超时时间,毫秒,在此期间,如若客户端与服务端无法成功建立连接,则断掉
clitimeout 50000 ##设置连接客户端发送数据时的成功连接最长等待时间,单位为毫秒,如若在这期间无法请求成功,则断掉
srvtimeout 50000 ##设置服务器端回应客户端数据发送的最长等待时间,如果在这期间还无法发送成功,则断掉
##################无分离页面需求的配置##############
#listen webcluster 0.0.0.0:80 ##指定haproxy服务监听地址和端口
# option httpchk GET /index.html ##指定http请求方法和默认文件
# balance roundrobin ##指定轮询调度算法
# server inst1 192.168.100.155:80 check inter 2000 fall 3 ##定义web节点,检测心跳频率,单位为毫秒,定义检查节点最多失败次数
# server inst2 192.168.100.156:80 check inter 2000 fall 3
##################有分离页面需求的配置##############
frontend http ##定义名称为http
bind *:80 ##指定监听地址和端口
acl linuxfan1 hdr_end(host) -i 192.168.100.101 ##指定类型为访问路径的域名,-i不区分大小写
acl linuxfan2 hdr_end(host) -i www.linuxfan.cn
acl linuxfan3 path_end -i .jsp .do .css .js ##指定请求文件格式为.jsp
#acl linuxfan3 hdr_reg -i \.(css|png|jpg|jpeg|gif|ico|swf|xml|txt|pdf|do|jsp|js)$ ##调用正则表达式
acl linuxfan4 path_end -i .html .css .png .jpg .jpeg .xml ##指定请求文件格式为.html
acl linuxfan5 path_beg -i /WebRoot ##指定访问URL中的路径,如http://www.linuxfan.cn/WebRoot/index.jsp
use_backend dongtai if linuxfan1 linuxfan3
use_backend dongtai if linuxfan2 linuxfan3
use_backend dongtai if linuxfan1 linuxfan5 linuxfan3
use_backend dongtai if linuxfan2 linuxfan5 linuxfan3
default_backend jingtai ##默认的请求使用backend dongtai
backend jingtai ##定义backend :jingtai
mode http ##定义模式
balance roundrobin ##定义调度算法为轮询
server jingtai01 192.168.100.102:80 check inter 2000 fall 3 ##定义节点
server jingtai02 192.168.100.103:80 check inter 2000 fall 3
backend dongtai
mode http
balance roundrobin
server dongtai01 192.168.100.104:8080 check inter 2000 fall 3
server dongtai02 192.168.100.105:8080 check inter 2000 fall 35. 启动Haproxy服务
[root@ha ~]# cp /usr/src/haproxy-1.4.24/examples/haproxy.init /etc/init.d/haproxy
[root@ha ~]# chmod +x /etc/init.d/haproxy
[root@ha ~]# ln -s /usr/local/sbin/haproxy /usr/sbin/
[root@ha ~]# /etc/init.d/haproxy start
[root@ha ~]# netstat -utpln |grep haproxy
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1264/haproxy
udp 0 0 0.0.0.0:52177 0.0.0.0:* 1264/haproxy
6. 客户端访问测试验证集群


7. 将Haproxy的日志文件分离(便于查看)
[root@ha ~]# vi /etc/rsyslog.conf
15 $ModLoad imudp
16 $UDPServerRun 514
##打开此配置项的注释,使rsyslog服务可以接受udp协议514端口的系统日志消息
74 local0.* /var/log/haproxy/ha-info.log
75 local1.* /var/log/haproxy/ha-notice.log
##在haproxy主配置文件中所指定的日志设备和日志级别将其输出到不同的文件中,以方便查看;
:wq
[root@ha ~]# vi /etc/sysconfig/rsyslog
SYSLOGD_OPTIONS="-r -m 0 -c 2"
##-r 接收udp 514号端口的系统日志消息;-m 0 为日志消息添加时间等的标记 ;-c 2表示使用兼容模式
:wq
[root@ha ~]# systemctl restart rsyslog
[root@ha ~]# /etc/init.d/haproxy restart
[root@ha ~]# tail -f /var/log/haproxy/ha-info.log
Jul 27 18:14:44 localhost haproxy[1375]: 192.168.100.1:52965 [27/Jul/2018:18:14:44.167] http dongtai/dongtai01 0/0/0/2/3 200 349 - - ---- 0/0/0/0/0 0/0 "GET /index.jsp HTTP/1.1"8. 配置Haproxy服务的日志管理界面
[root@ha ~]# vi /etc/haproxy/haproxy.cfg ###在后边添加
listen status 0.0.0.0:8080 ##监控8080端口
stats enable ##开启stats的模块
stats uri /stats ##指定访问的url
stats auth admin:123456 ##指定登陆监控页面的用户名密码
stats realm (Haproxy\ statistic) ##定义页面的提示信息
[root@ha ~]# /etc/init.d/haproxy restart9. 客户端访问测试Haproxy的日志管理界面

15、搭建HAProxy+KeepAlived高可用负载均衡系统
1. 搭建环境描述
下面介绍如何通过KeepAlived搭建高可用的HAProxy负载均衡集群系统,在进行实例介绍之前先进行约定:操作系统采用Centos7.5,地址规划如下表所示 。
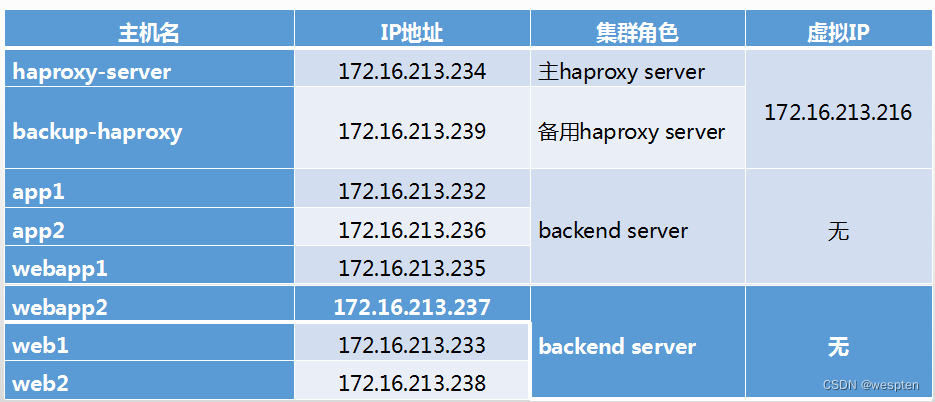
整个高可用HAproxy集群系统的拓扑结构如下图所示:

2. 配置HAproxy负载均衡服务器
关于HAproxy的安装、配置以及日志支持,前面已经做过详细的介绍,这里不再重复介绍。
首先在主、备HAproxy服务器上安装好HAproxy,并且配置好日志支持,然后进入haproxy的配置阶段,这里仅仅给出HAproxy的配置文件,主、备两个节点的haproxy.conf文件内容完全相同,这里假定HAproxy的安装路径为/usr/local/haproxy。
/usr/local/haproxy/conf/haproxy.conf文件内容:
global
log 127.0.0.1 local0 info
maxconn 4096
user nobody
group nobody
daemon
nbproc 2
pidfile /usr/local/haproxy/logs/haproxy.pid
defaults
mode http
retries 3
option forwardfor
timeout connect 5s
timeout client 30s
timeout server 30s
timeout check 2s
listen admin_stats
bind 0.0.0.0:19088
bind-process 2
mode http
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /haproxy-status
stats realm welcome login\ Haproxy
stats auth admin:admin123
stats hide-version
stats admin if TRUE
frontend www
bind *:80
mode http
option httplog
log global
acl host_www hdr_dom(host) -i www.zb.com
acl host_static hdr_dom(host) -i static.zb.com
acl host_video hdr_dom(host) -i video.zb.com
use_backend server_www if host_www
use_backend server_static if host_static
use_backend server_video if host_video
backend server_www
mode http
option redispatch
option abortonclose
balance roundrobin
option httpchk GET /index.jsp
server app1 172.16.213.232:8080 weight 6 check inter 2000 rise 2 fall 3
server app2 172.16.213.236:8080 weight 6 check inter 2000 rise 2 fall 3
backend server_static
mode http
option redispatch
option abortonclose
balance roundrobin
option httpchk GET /index.html
server webapp1 172.16.213.235:80 weight 6 check inter 2000 rise 2 fall 3
server webapp2 172.16.213.237:80 weight 6 check inter 2000 rise 2 fall 3
backend server_video
mode http
option redispatch
option abortonclose
balance roundrobin
option httpchk GET /index.html
server web1 172.16.213.238:8080 weight 6 check inter 2000 rise 2 fall 3
server web2 172.16.213.233:80 weight 6 check inter 2000 rise 2 fall 3
3. 配置主、备KeepAlived服务器
依次在主、备两个节点上安装Keepalived。关于Keepalived的安装这里不再介绍,直接给出配置好的keepalived.conf文件内容。在haproxy-server主机上。
keepalived.conf文件的内容如下:
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id haproxy_DEVEL
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 2
}
vrrp_instance HAproxy_1 {
state BACKUP
interface enp0s8
virtual_router_id 118
priority 100
advert_int 2
nopreempt
authentication {
auth_type PASS
auth_pass qwaszx
}
notify_master "/usr/bin/python /etc/keepalived/mail_notify.py master"
notify_backup "/usr/bin/python /etc/keepalived/mail_notify.py backup"
notify_fault "/usr/bin/python /etc/keepalived/mail_notify.py falut"
track_script {
check_haproxy
}
virtual_ipaddress {
172.16.213.216/24 dev enp0s8
}
}
其中/etc/keepalived/mail_notify.py文件是一个邮件通知程序,当KeepAlived进行master、backup、fault状态切换时,将会发送通知邮件给运维人员,这样可以及时了解高可用集群的运行状态,以便在适当的时候人为介入处理故障。
mail_notify.py文件的内容如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
reload(sys)
from email.MIMEText import MIMEText
import smtplib
import MySQLdb
sys.setdefaultencoding('UTF-8')
import socket, fcntl, struct
def send_mail(to_list,sub,content):
mail_host="smtp.163.com" #设置验证服务器,这里以163.com为例
mail_user="xxxxxx" #设置验证用户名
mail_pass="xxxxxx" #设置验证口令
mail_postfix="163.com" #设置邮箱的后缀
me=mail_user+"<"+mail_user+"@"+mail_postfix+">"
msg = MIMEText(content)
msg['Subject'] = sub
msg['From'] = me
msg['To'] = to_list
try:
s = smtplib.SMTP()
s.connect(mail_host)
s.login(mail_user,mail_pass)
s.sendmail(me, to_list, msg.as_string())
s.close()
return True
except Exception, e:
print str(e)
return False
def get_local_ip(ifname = 'enp0s8'):
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
inet = fcntl.ioctl(s.fileno(), 0x8915, struct.pack('256s', ifname[:15]))
ret = socket.inet_ntoa(inet[20:24])
return ret
if sys.argv[1]!="master" and sys.argv[1]!="backup" and sys.argv[1]!="fault":
sys.exit()
else:
notify_type = sys.argv[1]
if __name__ == '__main__':
strcontent = get_local_ip()+ " " +notify_type+"状态被激活,请确认HAProxy服务运行状态!"
mailto_list = ['[email protected]', '[email protected]']
for mailto in mailto_list:
send_mail(mailto, "HAproxy状态切换报警", strcontent.encode('UTF-8'))
最后,将keepalived.conf文件和mail_notify.py文件复制到backup-haproxy服务器上对应的位置,然后将keepalived.conf文件中priority值修改为90,由于配置的是不抢占模式,因此,还需要在backup-haproxy服务器上去掉nopreempt选项。
完成所有配置后,分别在haproxy-server和backup-haproxy主机上依次启动haproxy服务和keepalived服务。注意,这里一定要先启动haproxy服务,因为keepalived服务在启动的时候会自动检测haproxy服务是否正常,如果发现haproxy服务没有启动,那么主、备keepalived将自动进入fault状态。在依次启动服务后,在正常情况下VIP地址应该运行在haproxy-server服务器上,通过命令“ip a”可以查看VIP是否已经正常加载。
16、验证HAproxy+KeepAlived高可用负载均衡集群
1. 测试KeepAlived的高可用功能
高可用性是通过HAproxy的两个HAproxy server完成的。为了模拟故障,先将主haproxy-server上面的haproxy服务停止,接着观察haproxy-server上KeepAlived的运行日志,然后观察备机backup-haproxy上KeepAlived的运行日志。
从日志中可以看出,主机出现故障后,backup-haproxy立刻检测到,此时backup-haproxy变为MASTER角色,并且接管了主机的虚拟IP资源,最后将虚拟IP绑定在自己的网卡设备上。
2. 测试负载均衡功能
将www.zb.com、static.zb.com、video.zb.com这三个域名解析到172.16.213.216这个虚拟IP上来,然后依次访问网站,如果HAProxy运行正常,并且ACL规则设置正确,这三个网站应该都能正常访问,如果出现错误,可通过查看HAproxy的运行日志判断哪里出了问题。
六、LVS+Keepalived+Nginx+Tomcat 企业级负载均衡高可用集群架构
1、架构说明
此架构中keepalived所起到的作用就是对lvs架构中的调度器进行热备份,至少包含两台热备的负载调度器,两台台web的节点服务器。
LVS架构中需要通过ipvsadm工具来对ip_vs这个模块进行编写规则,使用keepalived+lvs时,不需要用到ipvsadm管理工具,不需要ipvsadm手动编写规则,用在keepalived的配置文件中指定配置项来将其取代。
keepalived的节点健康检查可以通过对real server的某个端口进行节点健康检查,来执行相应的操作,由notify_down配置项来完成。
项目拓扑:

项目环境:
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 7.4 1708 64bit |
192.168.100.101 |
ld1.linuxfan.cn |
keepalived-1.2.13.tar.gz sendEmail-v1.56.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.102 |
ld2.linuxfan.cn |
keepalived-1.2.13.tar.gz sendEmail-v1.56.tar.gz |
| Centos 7.4 1708 64bit |
192.168.100.103 |
ng1.linuxfan.cn |
nginx-1.12.2.tar.gz rpcbind nfs |
| Centos 7.4 1708 64bit |
192.168.100.104 |
ng2.linuxfan.cn |
nginx-1.12.2.tar.gz rpcbind nfs |
| Centos 7.4 1708 64bit |
192.168.100.105 |
tm1.linuxfan.cn |
apache-tomcat-9.0.10.tar.gz jdk-8u171-linux-x64.tar.gz rpcbind nfs |
| Centos 7.4 1708 64bit |
192.168.100.106 |
tm2.linuxfan.cn |
apache-tomcat-9.0.10.tar.gz jdk-8u171-linux-x64.tar.gz rpcbind nfs |
| Centos 7.4 1708 64bit |
192.168.100.107 |
st.linuxfan.cn |
rpcbind nfs mariadb-server mysql |
2、实验步骤
- 安装并配置后端两台tomcat(两台tomcat服务器配置相同,在此只列出其中一台配置);
- 安装并配置两台nginx服务器(两台nginx服务器配置相同,在此只列出其中一台配置);
- 安装前端两台负载调度器的keepalived服务与lvs服务(两台调度器配置相同,在此只列出一台配置);
- 配置master主调度器的keepalived服务并启动;
- 配置backup从调度器的keepalived服务并启动;
- 配置两台nginx在LVS_DR模式中的网络参数(两台nginx服务器配置相同,在此只列出一台配置);
- 客户端测试访问集群;
- 安装配置后端存储主机上的mysql服务;
- 安装配置后端存储主机上的nfs服务,并且将动态项目和静态项目上传并设置nfs共享;
- 两台nginx服务器挂载并读取nfs共享的静态网页资源(两台nginx服务器配置相同,在此只列出一台配置);
- 两台tomcat服务器挂载并读取nfs共享的动态网站项目(由java编写的超市管理项目),(两台tomcat服务器配置相同,在此只列出其中一台配置);
- 配置后端mysql数据库;
- 客户端访问测试静态网页资源;
- 客户端测试访问动态网站资源;
- 将nginx1模拟故障,客户端测试访问以及查看邮件情况;
- 将master主调度器模拟故障,测试客户端访问情况;
1. 安装并配置后端两台tomcat(两台tomcat服务器配置相同,在此只列出其中一台配置)
[root@tm1 ~]# ls
apache-tomcat-9.0.10.tar.gz jdk-8u171-linux-x64.tar.gz
[root@tm1~]# rpm -qa |grep java
[root@tm1 ~]# tar zxvf jdk-8u171-linux-x64.tar.gz
[root@tm1 ~]# mv jdk1.8.0_171/ /usr/local/java
[root@tm1 ~]# ls /usr/local/java
bin db javafx-src.zip lib man release THIRDPARTYLICENSEREADME-JAVAFX.txt
COPYRIGHT include jre LICENSE README.html src.zip THIRDPARTYLICENSEREADME.txt
[root@tm1 ~]# cat <<END >>/etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:/usr/local/java/bin
END
[root@tm1~]# source /etc/profile
[root@tm1 ~]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@tm1 ~]# tar zxvf apache-tomcat-9.0.10.tar.gz
[root@tm1 ~]# mv apache-tomcat-9.0.10 /usr/local/tomcat
[root@tm1 ~]# ls /usr/local/tomcat
bin conf lib LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt temp webapps work
[root@tm1 ~]# /usr/local/tomcat/bin/startup.sh ##启动apache-tomcat
[root@tm1 ~]# netstat -utpln |grep 8080
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 14758/java2. 安装并配置两台nginx服务器(两台nginx服务器配置相同,在此只列出其中一台配置)
[root@ng1 ~]# yum -y install pcre-devel zlib-devel
[root@ng1 ~]# useradd -M -s /sbin/nologin nginx
[root@ng1 ~]# tar zxvf nginx-1.12.2.tar.gz -C /usr/src/
[root@ng1 ~]# cd /usr/src/nginx-1.12.2/
[root@ng1 nginx-1.12.2]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_stub_status_module
[root@ng1 nginx-1.12.2]# make && make install
[root@ng1 nginx-1.12.2]# cd
[root@ng1 ~]# ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
[root@ng1 ~]# vi /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginxapi
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=kill -s HUP $(cat /usr/local/nginx/logs/nginx.pid)
ExecStop=kill -s QUIT $(cat /usr/local/nginx/logs/nginx.pid)
PrivateTmp=Flase
[Install]
WantedBy=multi-user.target
[root@ng1 ~]# vi /usr/local/nginx/conf/nginx.conf
34 upstream tomserver {
35 server 192.168.100.105:8080 weight=1;
36 server 192.168.100.106:8080 weight=1;
37 }
50 location ~ \.(asp|aspx|php|jsp|do|js|css|png|jpg)$ {
51 proxy_pass http://tomserver;
52 }
[root@ng1 ~]# systemctl start nginx
[root@ng1 ~]# systemctl enable nginx
[root@ng1 ~]# netstat -utpln |grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 3538/nginx: master3. 安装前端两台负载调度器的keepalived服务与lvs服务(两台调度器配置相同,在此只列出一台配置)
[root@ld1 ~]# yum -y install kernel-devel openssl-devel popt-devel
[root@ld1 ~]# ls keepalived-1.2.13.tar.gz
keepalived-1.2.13.tar.gz
[root@ld1 ~]# tar zxvf keepalived-1.2.13.tar.gz -C /usr/src/
[root@ld1 ~]# cd /usr/src/keepalived-1.2.13/
[root@ld1 keepalived-1.2.13]# ./configure --prefix=/usr/local/keepalived
[root@ld1 keepalived-1.2.13]# make && make install
[root@ld1 keepalived-1.2.13]# cd
[root@ld1 ~]# mkdir -p /etc/keepalived
[root@ld1 ~]# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
[root@ld1 ~]# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
[root@ld1 ~]# cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
[root@ld1 ~]# cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
[root@ld1 ~]# chmod 755 /etc/init.d/keepalived4. 配置master主调度器的keepalived服务并启动
[root@ld1 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R1 ##本服务器的名称
}
vrrp_instance VI_1 { ##定义VRRP热备实例
state MASTER ##MASTER表示主服务器
interface eth0 ##承载VIP地址的物理接口
virtual_router_id 1 ##虚拟路由器的ID号
priority 100 ##优先级,数值越大优先级越高
advert_int 1 ##通告间隔秒数(心跳频率)
authentication { ##认证信息
auth_type PASS ##认证类型
auth_pass 123456 ##密码字串
}
virtual_ipaddress {
192.168.100.95 ##指定漂移地址(VIP)
}
virtual_server 192.168.100.95 80 { ##指定vip地址
delay_loop 5 ##每隔5秒检测一次real server
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.100.103 80 { ##指定web集群节点1,在此为nginx1
weight 1
notify_down /etc/keepalived/check.sh ##real server检测失败后执行的脚本
TCP_CHECK {
connect_port 80
connect_timeout 3 ##连接超时
nb_get_retry 3 ##重试连接次数
delay_before_retry 4 ##重试间隔
}
}
real_server 192.168.100.104 80 { ##指定web集群节点2,在此为nginx2
weight 1
notify_down /etc/keepalived/check.sh ##real server检测失败后执行的脚本
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 4
}
}
}
[root@ld1 ~]# vi /etc/keepalived/check.sh
#!/bin/bash
echo -e " nginx1(192.168.100.103) or nginx2(192.168.100.104) is down on $(date +%F-%T)" >/root/check_httpd.log
cat /root/check_httpd.log |/usr/local/bin/sendEmail -o message-charset=utf8 -f [email protected] -t [email protected] -s smtp.163.com -u "It's up to it" -xu [email protected] -xp 854365897huhu
:<<END
解释:
-f 表示发送者的邮箱
-t 表示接收者的邮箱
-s 表示SMTP服务器的域名或者ip
-u 表示邮件的主题
-xu 表示SMTP验证的用户名
-xp 表示SMTP验证的密码(注意,这个密码貌似有限制,例如我用d!5neyland就不能被正确识别)
-m 表示邮件的内容
END
:wq[root@ld1 ~]# chmod +x /etc/keepalived/check.sh
[root@ld1 ~]# wget http://caspian.dotconf.net/menu/Software/SendEmail/sendEmail-v1.56.tar.gz
[root@ld1 ~]# tar zxf sendEmail-v1.56.tar.gz ##安装发送邮件工具
[root@ld1 ~]# cd sendEmail-v1.56
[root@ld1 sendEmail-v1.56]# mv sendEmail /usr/local/bin/
[root@ld1 sendEmail-v1.56]# cd
[root@ld1 ~]# cat /etc/fstab |/usr/local/bin/sendEmail -o message-charset=utf8 -f [email protected] -t [email protected] -s smtp.163.com -u "It's up to it" -xu [email protected] -xp ########## ##发送测试邮件,也可用-m指定邮件内容
[root@ld1 ~]# modprobe ip_vs ##启动ip_vs模块
[root@ld1 ~]# lsmod |grep ip_vs
[root@ld1 ~]# echo "modprobe ip_vs" >>/etc/rc.local
[root@ld1 ~]# chmod +x /etc/rc.local
[root@ld1 ~]# /etc/init.d/keepalived start
Reloading systemd: [ 确定 ]
Starting keepalived (via systemctl): [ 确定 ]
[root@ld1 ~]# ip a |grep 192.168.100.95
inet 192.168.100.95/32 scope global eth05. 配置backup从调度器的keepalived服务并启动
[root@ld2 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R2 ##本服务器的名称
}
vrrp_instance VI_1 { ##定义VRRP热备实例
state BACKUP ##MASTER表示主服务器
interface eth0 ##承载VIP地址的物理接口
virtual_router_id 1 ##虚拟路由器的ID号
priority 99 ##优先级,数值越大优先级越高
advert_int 1 ##通告间隔秒数(心跳频率)
authentication { ##认证信息
auth_type PASS ##认证类型
auth_pass 123456 ##密码字串
}
virtual_ipaddress {
192.168.100.95 ##指定漂移地址(VIP)
}
virtual_server 192.168.100.95 80 { ##指定vip地址
delay_loop 5 ##每隔5秒检测一次real server
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.100.103 80 { ##指定web集群节点1,在此为nginx1
weight 1
notify_down /etc/keepalived/check.sh ##real server检测失败后执行的脚本
TCP_CHECK {
connect_port 80
connect_timeout 3 ##连接超时
nb_get_retry 3 ##重试连接次数
delay_before_retry 4 ##重试间隔
}
}
real_server 192.168.100.104 80 { ##指定web集群节点2,在此为nginx2
weight 1
notify_down /etc/keepalived/check.sh ##real server检测失败后执行的脚本
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 4
}
}
}[root@ld2 ~]# vi /etc/keepalived/check.sh
#!/bin/bash
echo -e " nginx1(192.168.100.103) or nginx2(192.168.100.104) is down on $(date +%F-%T)" >/root/check_httpd.log
cat /root/check_httpd.log |/usr/local/bin/sendEmail -o message-charset=utf8 -f [email protected] -t [email protected] -s smtp.163.com -u "It's up to it" -xu [email protected] -xp ############
:<<END
解释:
-f 表示发送者的邮箱
-t 表示接收者的邮箱
-s 表示SMTP服务器的域名或者ip
-u 表示邮件的主题
-xu 表示SMTP验证的用户名
-xp 表示SMTP验证的密码(注意,这个密码貌似有限制,例如我用d!5neyland就不能被正确识别)
-m 表示邮件的内容
END
:wq[root@ld2 ~]# chmod +x /etc/keepalived/check.sh
[root@ld2 ~]# wget http://caspian.dotconf.net/menu/Software/SendEmail/sendEmail-v1.56.tar.gz
[root@ld2 ~]# tar zxf sendEmail-v1.56.tar.gz ##安装发送邮件工具
[root@ld2 ~]# cd sendEmail-v1.56
[root@ld2 sendEmail-v1.56]# mv sendEmail /usr/local/bin/
[root@ld2 sendEmail-v1.56]# cd
[root@ld2 ~]# modprobe ip_vs ##启动ip_vs模块
[root@ld2 ~]# lsmod |grep ip_vs
[root@ld2 ~]# echo "modprobe ip_vs" >>/etc/rc.local
[root@ld2 ~]# chmod +x /etc/rc.local
[root@ld2 ~]# /etc/init.d/keepalived start
Reloading systemd: [ 确定 ]
Starting keepalived (via systemctl): [ 确定 ]
[root@ld2 ~]# ip a |grep 192.168.100.956. 配置两台nginx在Lvs_DR模式中的网络参数(两台nginx服务器配置相同,在此只列出一台配置)
[root@ng1 ~]# cat <<END >/etc/sysconfig/network-scripts/ifcfg-lo:0
DEVICE=lo:0
IPADDR=192.168.100.95
NETMASK=255.255.255.255
ONBOOT=yes
NAME=lo:0
END
[root@ng1 ~]# systemctl restart network
[root@ng1 ~]# ip a |grep 95
inet 192.168.100.95/32 brd 192.168.100.88 scope global lo:07. 客户端测试访问集群
访问静态网页资源并查看服务器日志:


访问动态网站资源并查看服务器日志:
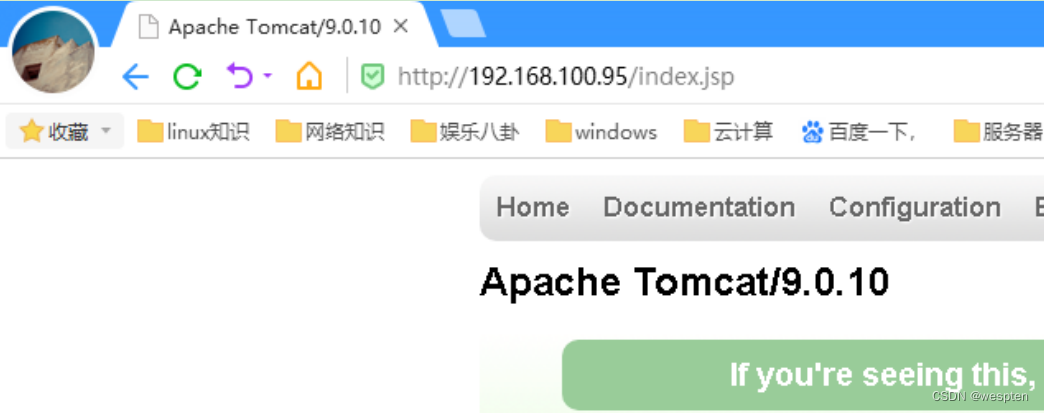


8. 安装配置后端存储主机上的mysql服务
[root@st ~]# yum -y install mariadb-server mysql
[root@st ~]# systemctl start mariadb
[root@st ~]# systemctl enable mariadb
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
[root@st ~]# mysqladmin -uroot password ##设置密码为123123
[root@st ~]# mysql -uroot -p123123
MariaDB [(none)]> exit9. 安装配置后端存储主机上的nfs服务,并且将动态项目和静态项目上传并设置nfs共享
[root@st ~]# for i in rpcbind nfs;do systemctl enable $i; done
[root@st ~]# for i in rpcbind nfs;do systemctl enable $i; done
[root@st ~]# mkdir /opt/nginx
[root@st ~]# chmod 777 /opt/nginx/
[root@st ~]# echo "this is a beautiful page!!!" >>/opt/nginx/index.html ##准备nginx的静态网页资源
[root@st ~]# mkdir /opt/tom
[root@st ~]# chmod 777 /opt/tom/
[root@st ~]# ls /opt/tom/ ##上传超市管理项目的源码
WebRoot
[root@st ~]# vi /opt/tom/WebRoot/WEB-INF/classes/database.properties
url=jdbc:mysql://192.168.100.107:3306/smbms?useUnicode=true&characterEncoding=utf-8
user=linuxfan
password=123123
:wq
[root@st ~]# vi /etc/exports
/opt/nginx 192.168.100.0/24(rw,sync,no_root_squash)
/opt/tom 192.168.100.0/24(rw,sync,no_root_squash)
[root@st ~]# systemctl start rpcbind
[root@st ~]# systemctl start nfs
Job for nfs-server.service failed because the control process exited with error code. See "systemctl status nfs-server.service" and "journalctl -xe" for details.
[root@st ~]# kill -HUP `cat /run/gssproxy.pid`
[root@st ~]# systemctl start nfs
[root@st ~]# systemctl enable rpcbind nfs
[root@st ~]# showmount -e 192.168.100.107
Export list for 192.168.100.107:
/opt/tom 192.168.100.0/24
/opt/nginx 192.168.100.0/2410. 两台nginx服务器挂载并读取nfs共享的静态网页资源(两台nginx服务器配置相同,在此只列出一台配置)
[root@ng1 ~]# yum -y install nfs-utils rpcbind
[root@ng1 ~]# systemctl start rpcbind
[root@ng1 ~]# systemctl start nfs
Job for nfs-server.service failed because the control process exited with error code. See "systemctl status nfs-server.service" and "journalctl -xe" for details.
[root@ng1 ~]# kill -HUP `cat /run/gssproxy.pid`
[root@ng1 ~]# systemctl start nfs
[root@ng1 ~]# systemctl enable rpcbind nfs
[root@ng1 ~]# showmount -e 192.168.100.107
Export list for 192.168.100.107:
/opt/tom 192.168.100.0/24
/opt/nginx 192.168.100.0/24
[root@ng1 ~]# echo "192.168.100.107:/opt/nginx /usr/local/nginx/html/ nfs defaults,_netdev 0 0" >>/etc/fstab
[root@ng1 ~]# mount -a
[root@ng1 ~]# ls /usr/local/nginx/html/
index.html
[root@ng1 ~]# mount |tail -1
192.168.100.107:/opt/nginx on /usr/local/nginx/html type nfs4 (rw,relatime,vers=4.1,rsize=65536,wsize=65536,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.100.103,local_lock=none,addr=192.168.100.107,_netdev)11. 两台tomcat服务器挂载并读取nfs共享的动态网站项目(由java编写的超市管理项目),(两台tomcat服务器配置相同,在此只列出其中一台配置)
[root@tm1 ~]# yum -y install nfs-utils rpcbind
[root@tm1 ~]# systemctl start rpcbind
[root@tm1 ~]# systemctl start nfs
Job for nfs-server.service failed because the control process exited with error code. See "systemctl status nfs-server.service" and "journalctl -xe" for details.
[root@tm1 ~]# kill -HUP `cat /run/gssproxy.pid`
[root@tm1 ~]# systemctl start nfs
[root@tm1 ~]# systemctl enable rpcbind nfs
[root@tm1 ~]# showmount -e 192.168.100.107
Export list for 192.168.100.107:
/opt/tom 192.168.100.0/24
/opt/nginx 192.168.100.0/24
[root@tm1 ~]# echo "192.168.100.107:/opt/tom /usr/local/tomcat/webapps/ nfs defaults,_netdev 0 0" >>/etc/fstab
[root@tm1 ~]# mount -a
[root@tm1 ~]# ls /usr/local/tomcat/webapps/
WebRoot
[root@tm1 ~]# mount |tail -1
192.168.100.107:/opt/tom on /usr/local/tomcat/webapps type nfs4 (rw,relatime,vers=4.1,rsize=65536,wsize=65536,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.100.105,local_lock=none,addr=192.168.100.107,_netdev)12. 配置后端mysql数据库
[root@st ~]# ls smbms_db.sql
smbms_db.sql
[root@st ~]# mysql -uroot -p123123<smbms_db.sql
[root@st ~]# mysql -uroot -p123123
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| smbms |
| test |
+--------------------+
5 rows in set (0.00 sec)
MariaDB [(none)]> grant all on smbms.* to 'linuxfan'@'192.168.100.%' identified by "123123";
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> exit
Bye13. 客户端访问测试静态网页资源
14. 客户端测试访问动态网站资源
登录后如若访问不了,可以尝试重启tomcat:
15. 将nginx1模拟故障,客户端测试访问以及查看邮件情况

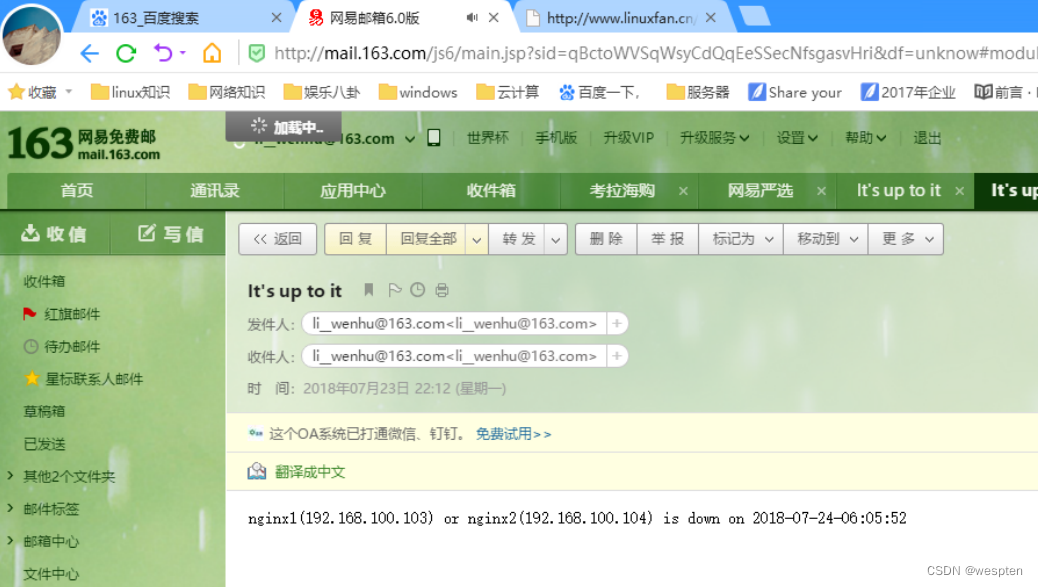

16. 将master主调度器模拟故障,测试客户端访问情况