文章目录
题记:在工作中有时会碰到LVS, Keepalived, HAproxy, Nginx。有时候用到了只是会用某项技术,但是并没有把他们融会贯通。此篇博文特意总结下。
LVS
1 什么是LVS
LVS是一种基于TCP/IP的负载均衡技术,也就是L4的的,转发效率极高(数据结构使用hash)。是由国内开源第一人,章文嵩博士期间开发完成。
LVS由前端的负载均衡器(Load Balancer,LB)和后端的真实服务器(Real Server,RS)群组成。RS间可通过局域网或广域网连接。LVS的这种结构对用户是透明的,用户只能看见一台作为LB的虚拟服务器(Virtual Server),而看不到提供服务的RS群。
当用户的请求发往虚拟服务器,LB根据设定的包转发策略和负载均衡调度算法将用户请求转发给RS。RS再将用户请求结果返回给用户。同请求包一样,应答包的返回方式也与包转发策略有关。

2 原理
2.1 后端调度算法
• Round Robin
• Weighted round robin
• Source ip hash(来自于同一个ip的请求调度到同一个real server)
• Destination hash
• Least connections
Weighted Least Connection(default)
2.2 如何实现
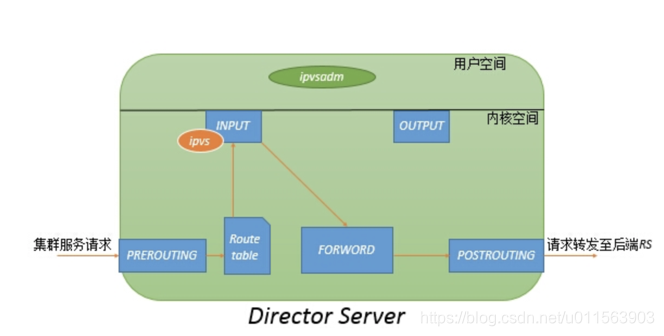
客户端请求vip+port后,经过input链,如果ipvs发现报文访问的vip+port与我们定义的lvs集群规则相符合。经过PREROUTING链,经检查本机路由表,送往INPUT链;在进入netfilter的INPUT链时,ipvs强行将请求报文通过ipvsadm定义的集群服务策略的路径改为FORWORD链,将报文转发至后端真实提供服务的主机。
3 怎么用
启动了两个http容器,然后用ipvsadm命令添加了3条规则
docker run -itd --name test1 -h test1 strm/helloworld-http:latest // 容器ip是172.17.0.4
docker run -itd --name test2 -h test2 strm/helloworld-http:latest // 容器ip是172.17.0.5
sudo ipvsadm -A -t 10.0.2.15:80 -s rr // rr表示用的是轮询算法
sudo ipvsadm -a -t 10.0.2.15:80 -r 172.17.0.4 -m
sudo ipvsadm -a -t 10.0.2.15:80 -r 172.17.0.5 -m
sudo ipvsadm -Ln // 可以看到输出的内容
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.2.15:80 rr
-> 172.17.0.4:80 Masq 1 0 0
-> 172.17.0.5:80 Masq 1 0 0
测试如下:因为用的是rr,所以流量是平均分配到后端的实例。
for in in `seq 1 100`; do curl -s 10.0.2.15:80; echo; done | sort | uniq -c
100
50 <html><head><title>HTTP Hello World</title></head><body><h1>Hello from test1</h1></body></html
50 <html><head><title>HTTP Hello World</title></head><body><h1>Hello from test2</h1></body></html
Keepalived
1 什么是Keepalived
keepalived是一个类似于layer3, 4 & 5交换机制的软件,也就是我们平时说的第3层、第4层和第5层交换。Keepalived的作用是检测web服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的web服务器从系统中剔除,当web服务器工作正常后Keepalived自动将web服务器加入到服务器群中,这些工作全部自动完成。
功能比较全面:内置了LVS和检测到异常状态发邮件等功能。
2 原理
典型的Web服务器架构图如下,两个运行keepalived的Server 暴露相同的VIP,对外提供VIP,和Keepalived Server运行LVS,将流量负载均衡到后端真是主机。
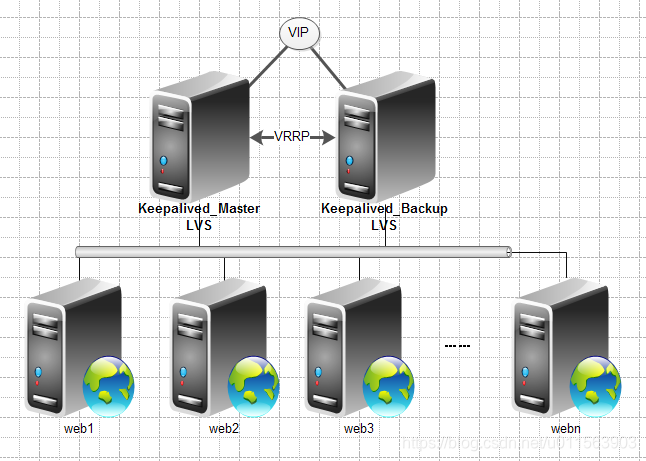
Layer3,4&5工作在IP/TCP协议栈的IP层,TCP层,及应用层,原理分别如下:
Layer3:Keepalived会定期向服务器群中的服务器发送一个ICMP的数据包,如果发现某台服务的IP地址没有激活,Keepalived便报告这台服务器失效,并将它从服务器群中剔除,这种情况的典型例子是某台服务器被非法关机。Layer3的方式是以服务器的IP地址是否有效作为服务器工作正常与否的标准。
Layer4:Layer4主要以TCP端口的状态来决定服务器工作正常与否。如web server的服务端口一般是80,如果Keepalived检测到80端口没有启动,则Keepalived将把这台服务器从服务器群中剔除。
Layer5:Layer5就是工作在具体的应用层了,比Layer3,Layer4要复杂一点,在网络上占用的带宽也要大一些。Keepalived将根据用户的设定检查服务器程序的运行是否正常,如果与用户的设定不相符,则Keepalived将把服务器从服务器群中剔除。
所以一般来讲,keepalived 会和负载均衡器配合使用。keepalived 提供负载均衡器的高可用。
3 怎么用
在 haproxy-master 机器上:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify haproxy's pid existance
interval 2 # check every 2 seconds
weight -2 # if check failed, priority will minus 2
}
vrrp_instance VI_1 {
state MASTER # Start-up default state
interface ens18 # Binding interface
virtual_router_id 51 # VRRP VRID(0-255), for distinguish vrrp's multicast
priority 105 # VRRP PRIO
virtual_ipaddress { # VIP, virtual ip
192.168.0.146
}
track_script { # Scripts state we monitor
chk_haproxy
}
}
在 haproxy-backup 机器上:
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface ens18
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.0.146
}
track_script {
chk_haproxy
}
}
我们为两台机器(master、backup)安装了 Keepalived 服务并设定了上述配置。
可以发现,我们绑定了一个虚拟 IP (VIP, virtual ip): 192.168.0.146,在 haproxy-master + haproxy-backup 上用 Keepalived 组成了一个集群。在集群初始化的时候,haproxy-master 机器的 被初始化为 MASTER。
间隔 2 seconds() 会定时执行
关于 参数的使用:
检测失败,并且 weight 为正值:无操作
检测失败,并且 weight 为负值:priority = priority - abs(weight)
检测成功,并且 weight 为正值:priority = priority + weight
检测成功,并且 weight 为负值:无操作
weight 默认值为 0,对此如果感到迷惑可以参考:HAProxy github code
故障切换工作流程:
当前的 MASTER 节点
一个 Keepalived 服务中可以有个 0 个或者多个 vrrp_instance
可以有多个绑定同一个 VIP 的 Keepalived 服务(一主多备),本小节中只是写了两个注意 <virtual_router_id>,同一组 VIP 绑定的多个 Keepalived 服务的 <virtual_router_id> 必须相同;多组 VIP 各自绑定的 Keepalived 服务一定与另外组不相同。否则前者会出现丢失节点,后者在初始化的时候会出错。
HAProxy
1 什么是HAProxy
HAProxy提供高可用性、负载均衡。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。
LVS只工作在4层,没有流量产生,使用范围广,对操作员的网络素质要求较高;HAproxy及支持7层也支持4层的负载均衡,更专业;
其功能是用来提供基于cookie的持久性,基于内容的交换,过载保护的高级流量管制,自动故障切换,以正则表达式为基础的标题控制运行事件,基于Web的报表,高级日志记录以帮助排除故障的应用或网络及其他功能。HAProxy系统自带管理页面。
HAProxy 的 Proxy 配置可以分为如下几个部分:
defaults,frontend,backend,listen
defaults 包含一些全局的默认环境变量,frontend 定义了如何把数据 forward 到 backend,backend 描述了一组接收 forward 来的数据的后端服务。listen 则把 frontend 和 backend 组合到了一起,定义出一个完整的 proxy。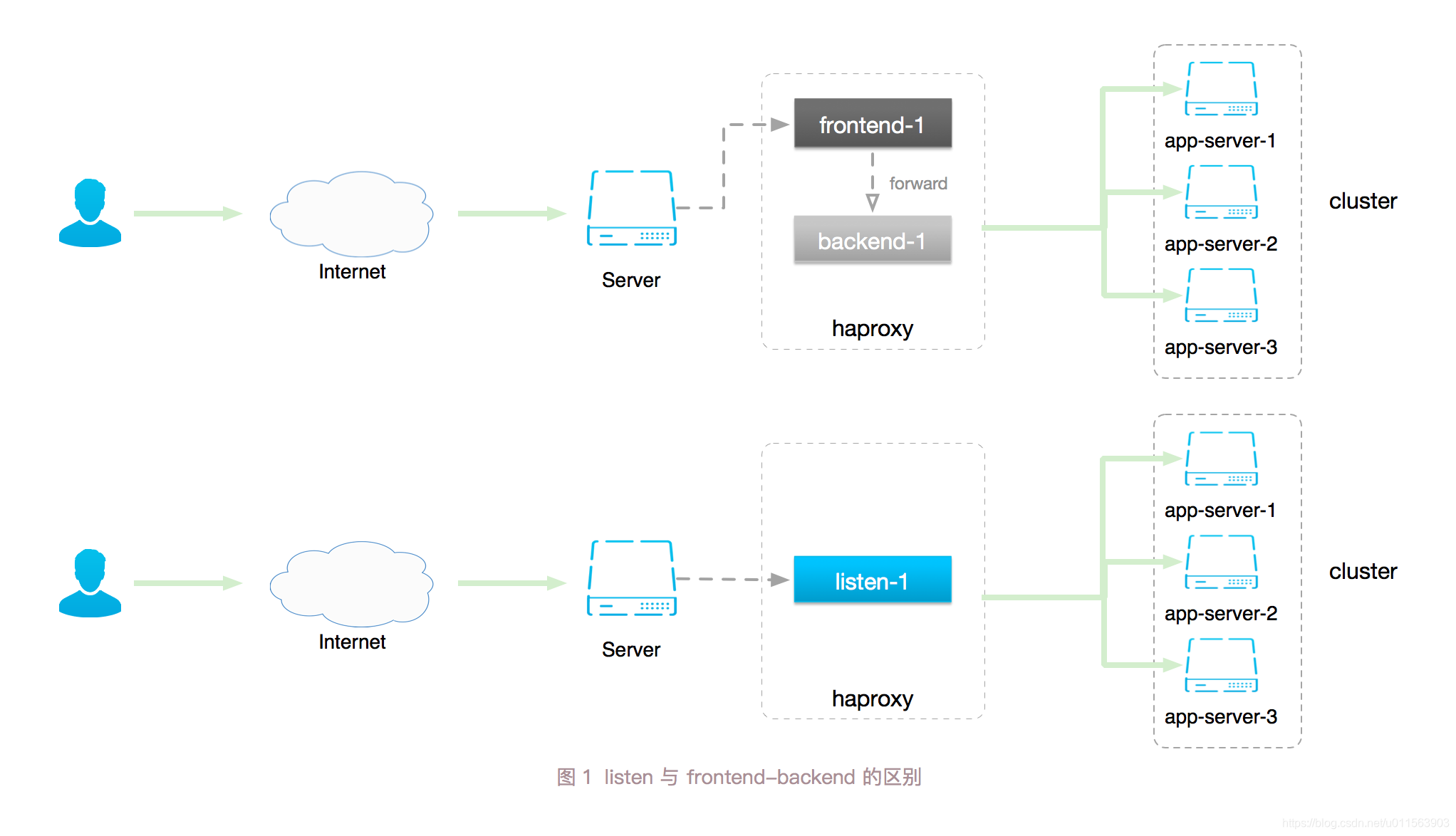
2 原理
下面是一段简单的 HAProxy 的配置:
listen app1-cluster
bind *:4000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:4004 maxconn 300 check
server server2 192.168.0.190:4004 maxconn 300 check
server server3 192.168.0.191:4004 maxconn 300 check
listen app2-cluster
bind *:5000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:5555 maxconn 300 check
server server2 192.168.0.190:5555 maxconn 300 check
server server3 192.168.0.191:5555 maxconn 300 check
HAProxy 的配置文件中定义了两个 listen 模块,分别监听在 4000、5000 端口。监听在 4000 端口的模块,使用 roundrobin (轮询)负载均衡算法,把请求分发到了三个后端服务。
3 怎么用
3.1 创建后端服务
首先搭建两台服务器,每台服务器上启动一个APP,这里用容器起后端Server。
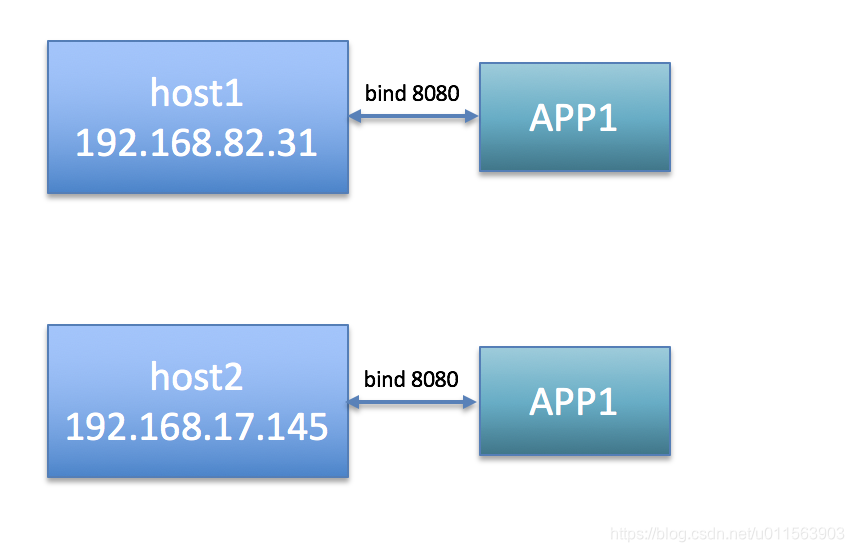
host1(192.168.82.31)
docker run -itd --name host1 -h host1 -p 8080:80 strm/helloworld-http:latest
host2(192.168.17.145):
docker run -itd --name host2 -h host2 -p 8080:80 strm/helloworld-http:latest
3.2 使用 HAProxy 做业务服务的高可用和负载均衡
我们现在有两台机器:ha-proxy-master、ha-proxy-backup。(为了方便,下边直接用 Docker 做了)。使用 haproxy:1.7.9 版本的 Docker 镜像。haproxy-master、haproxy-backup为了方便就使用host1 和 host2了,下面说的ha-proxy-master-ip,其实就是host1的ip。
haproxy.cfg如下:
global
daemon
maxconn 30000
log 127.0.0.1 local0 info
log 127.0.0.1 local1 warning
defaults
mode http
option http-keep-alive
option httplog
timeout connect 5000ms
timeout client 10000ms
timeout server 50000ms
timeout http-request 20000ms
# custom your own frontends && backends && listen conf
#CUSTOM
listen app1-cluster
bind *:8181
mode http
maxconn 300
balance roundrobin
server server1 192.168.82.31:8080 maxconn 300 check
server server2 192.168.17.145:8080 maxconn 300 check
listen stats
bind *:1080
stats refresh 30s
stats uri /stats
编译Docker image:
docker build -t custom-haproxy:1.7.9 .
在ha-proxy-master和ha-proxy-backup节点运行:
docker run -it --net=host --privileged --name haproxy-1 -d custom-haproxy:1.7.9
然后可以通过ha-proxy-master-ip:1080/stats 看到状态

也可以通过ha-proxy-master-ip:8181 去访问后端的服务。并且是轮流的访问到host1和host2。用ha-proxy-backup-ip也是一样的。
3.3 使用 Keepalived 做 HAProxy 服务的高可用
在上一小节中,在 ha-proxy-master、ha-proxy-backup 两台机器上搭了两套相同的 HAProxy 服务。我们希望在一个连续的时间段,只由一个节点为我们提供服务,并且在这个节点挂掉后另外一个节点能顶上。
本小节的目标是在haproxy-master、haproxy-backup 上分别搭 Keepalived 服务,并区分主、备节点,以及关停掉一台机器后保证 HAProxy 服务仍然正常运行。
两台ha-proxy机器上安装:
[root@instance-t9flxirx ~]# yum install -y keepalived
[root@instance-t9flxirx ~]# keepalived -v
Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
在ha-proxy-master上添加如下:
vi /etc/keepalived/keepalived.conf
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 105
virtual_ipaddress {
192.168.17.146
}
track_script {
chk_haproxy
}
}
在ha-proxy-slave节点添加如下:
vi /etc/keepalived/keepalived.conf
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.17.146
}
track_script {
chk_haproxy
}
}
然后都重启服务:
systemctl restart keepalived
这个时候在ha-proxy-master上的eth0下,会配置secondary ip为192.168.17.146,该IP就是VIP。
[root@instance-t9flxirx ~]# ip addr | grep 146
inet 192.168.17.146/32 scope global eth0
至此,一个简单的HAProxy + Keepalived 服务了。整体结构图如下所示:
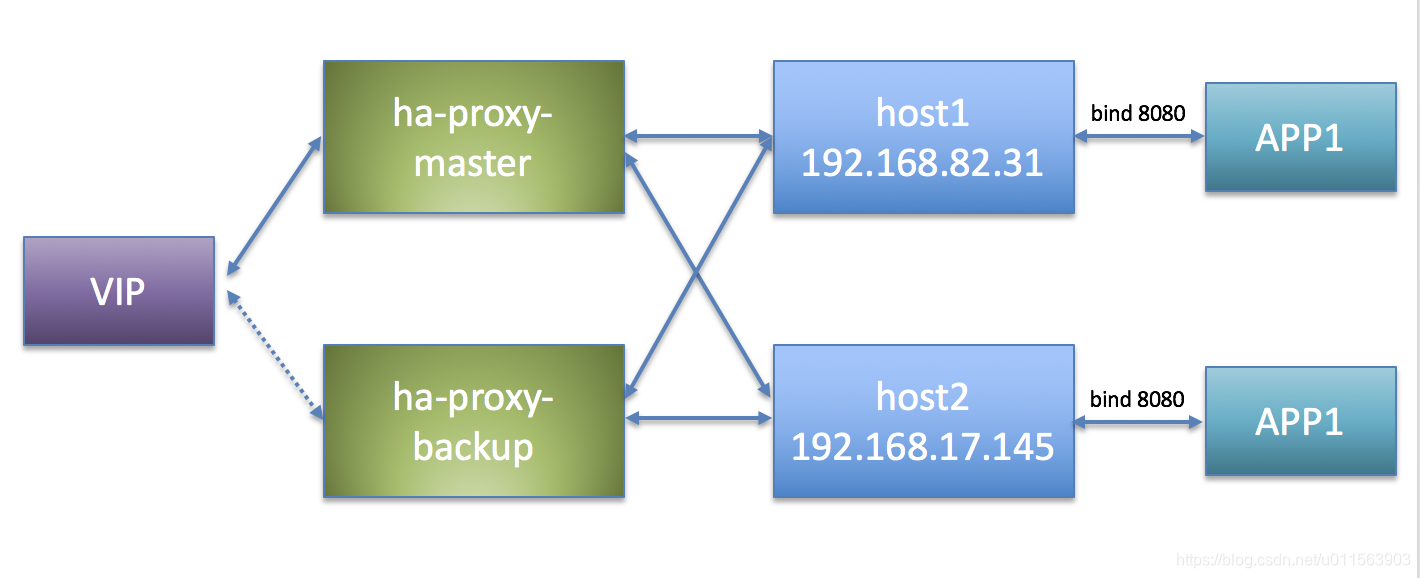
将ha-proxy-master 停机,则会发现VIP将配置到ha-proxy-slave上。但是服务正常可用。
Nginx
nginx重点是web服务器,替换的是apache,同时具备lb的作用,haproxy是单纯的lb,可以对照lvs进行比较