Abstract
多尺度推理是提升语义分割效果的常用方法。多个尺度的图像通过一个网络,然后采用平均或最大池化将结果结合。本文,提出了提出了一种注意力为基础的方法结合多尺度预测。我们的注意力机制是分层的,与当前的方法相比这将会有 4 倍的memory efficient。除了加速训练,这使我们训练更大的尺寸,得到更高的准确率。
结果:Cityscapes miou 85.1 Mapillary 61.1 miou
Introduction
语义分割中某些任务预测在低分辨率下得到好的结果,某些任务预测在高分辨率下得到好的结果。例如,物体的边缘或者 thin structures 在高分辨率下效果较好,同时对于 large structure 预测需要 global context,在小尺寸下更好。作者认为不同大小的物体应该使用不同分辨率的网络,大的物体应该缩小分辨率相当于扩大感受野,小的物体应该使用大分辨率,得到更多的细节。
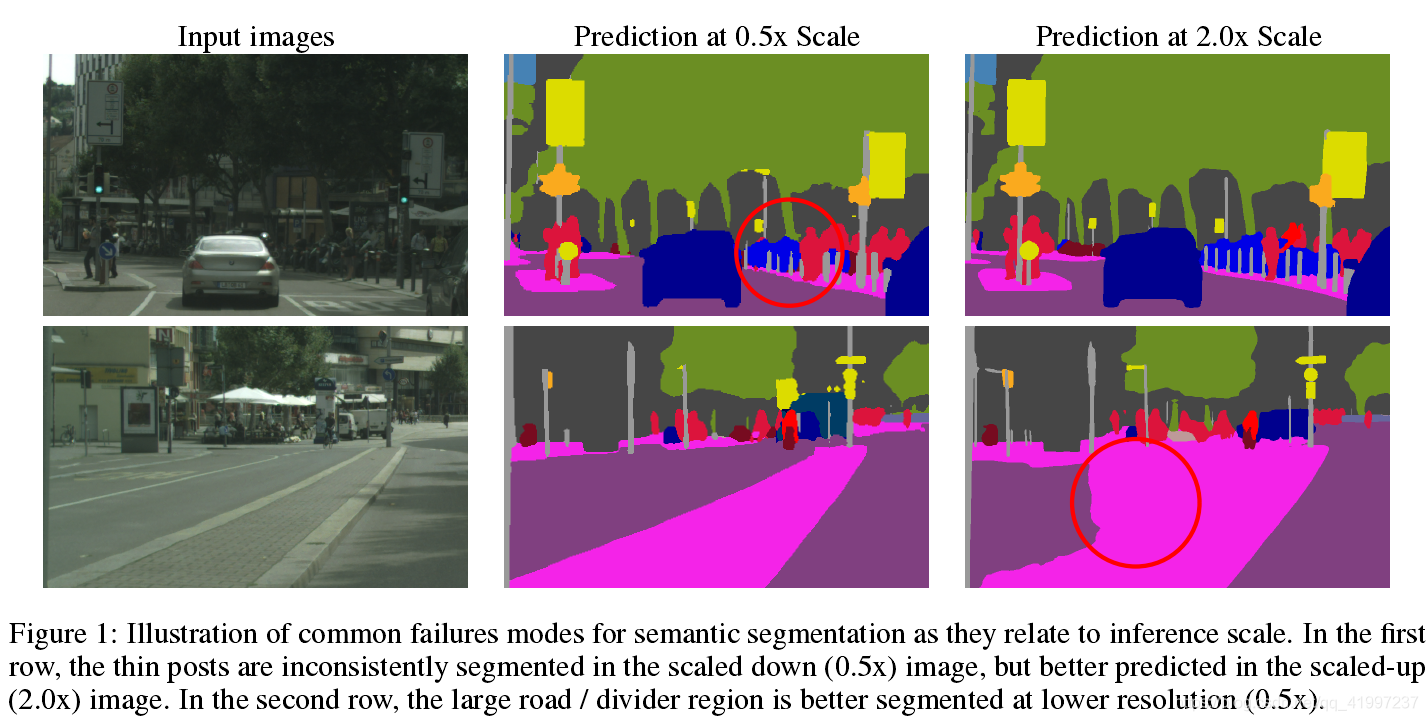 多尺度预测可以处理此问题。多个尺寸进行预测,然后使用 avgpool 或 maxpool 结合。使用 avgpool 通常会提升结果,但是会出现将最好的预测和最坏的预测结合在一起的问题,例如某一像素,最好的预测来自于 2x scale ,最坏的预测来自于 0.5 scale, 然后使用 avgpool 结合在一起,他们每一层的权重都是一样的,导致低于平均水平。 maxpool 选择N个尺寸中的一个,然而最佳结果可能是不同尺寸预测结果的加权组合。
多尺度预测可以处理此问题。多个尺寸进行预测,然后使用 avgpool 或 maxpool 结合。使用 avgpool 通常会提升结果,但是会出现将最好的预测和最坏的预测结合在一起的问题,例如某一像素,最好的预测来自于 2x scale ,最坏的预测来自于 0.5 scale, 然后使用 avgpool 结合在一起,他们每一层的权重都是一样的,导致低于平均水平。 maxpool 选择N个尺寸中的一个,然而最佳结果可能是不同尺寸预测结果的加权组合。
分层多尺度注意力
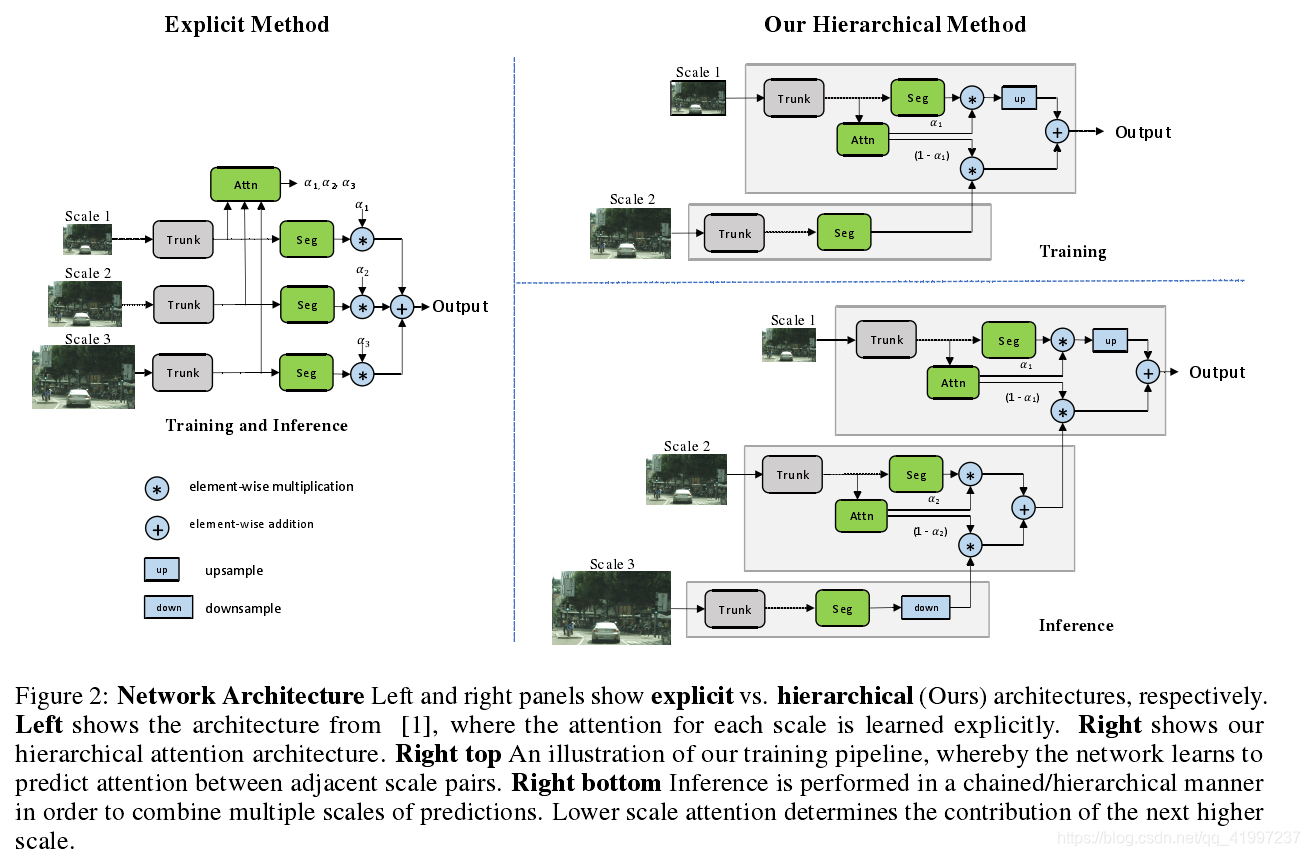 0.5倍,原始图像,2倍图像。我们优先考虑较低的尺度,然后逐步上升到较高的尺度,其想法是小的尺度能得到更多 global context,能选择大尺寸预测结果需要refine的地方。由公式可以看出低分辨率决定了相邻的下一个高分辨率的作用。
0.5倍,原始图像,2倍图像。我们优先考虑较低的尺度,然后逐步上升到较高的尺度,其想法是小的尺度能得到更多 global context,能选择大尺寸预测结果需要refine的地方。由公式可以看出低分辨率决定了相邻的下一个高分辨率的作用。
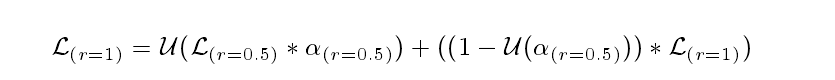
Backbone:消融实验采用Resnet-50,正式SOTA网络采用HRNet-OCR
SemanticHead(最后的预测):(3x3 conv) → (BN)→ (ReLU) → (3x3 conv) → (BN) → (ReLU) → (1x1 conv).The final convolution outputs num_classes channels.
Attention Head: Resnet-50做backbone时候,语义头和注意头是由ResNet-5最后阶段的特征提供的。HRNet-OCR做backbone时,语义头和注意头是由OCR block提供的。
auxiliary semantic head:使用HRNet-OCR时候还存在一个auxiliary semantic head:由(1x1 conv)→(BN)→(ReLU)→(1x1 conv)构成。在将注意力机制用到语义逻辑之后,再用双线性上采样将预测结果上采样到目标图像的大小。