目录
- Abstract
- 1. INTRODUCTION
- 2. RELATED WORK
- 3. APPROACH
- 4. RESULTS
- 5. CONCLUSION
Abstract
目前基于模型自由学习的机器人抓取方法利用人工标记的数据集对模型进行训练。这样会带来一些缺点。
- 由于每个物体都可以通过多种方式被抓住,所以手动标记抓取位置并不是一项简单的任务;
- 人类的标签会受到语义学的影响。(下文提到:一个杯子可以从多个位置拿出来,但是人工标签默认设置在手柄上。)
- 虽然已经尝试使用试错实验来训练机器人,但在这类实验中使用的数据量仍然很低,因此使学习者容易过度拟合。
针对这些问题,作者提出了一下方法:
- 我们将可用的训练数据增加到之前工作的40倍,从而获得了在700小时的机器人抓取尝试中收集到的50K数据点的数据集大小。
- 训练一个卷积神经网络(CNN),在没有严重过度拟合的情况下能够预测抓取位置。
- 将回归问题重新定义为在图像补丁上的18种二值分类。
- 提出了一种多阶段学习方法,利用在一个阶段训练的CNN来收集后续阶段的硬负面信息。
1. INTRODUCTION

如何预测这个物体的抓取位置?
- 对这些对象拟合3D图形或使用3D深度传感器,执行3D推理预测抓取位置。然而,这种方法有两个缺点:(a)拟合3D模型本身就是一个极其困难的问题;(b)一种基于几何的方法,忽略了物体的密度和质量分布,这可能对预测抓取位置至关重要。
- 使用视觉识别来预测抓取的位置和配置,因为它不需要显式的对象建模。可为成百上千的对象创建一个抓取位置训练数据集,并使用标准的机器学习算法,如CNNs或自动编码器来预测测试数据中的抓取位置。但是人工标签的机器学习,会受到上述两个缺点的影响。
- 即使是最大的基于视觉的抓取数据集(2016年),也只有大约1K个孤立的物体图像(只有一个物体可见,没有任何杂乱)。
作者受强化学习(reinforcement learning)和人类经验学习(imitation learning)的启发,我们提出了一种自我监督算法,通过试错预测抓取位置。
我们认为,这种方法,其中训练数据大大少于模型参数的数量,必然会过拟合,并不能推广到新的不可见的对象。因此,我们需要的是一种收集成百上千个数据点的方法(可能通过让机器人与物体进行7天每天24小时的交互)来学习这个任务的有意义的表示。
我们提出了一个大规模的实验研究,不仅大大增加了学习要掌握的数据量,而且提供了完整的关于一个物体是否可以在特定的位置和角度被掌握的标记。
我们使用这个数据集对在ImageNet上预先训练过的AlexNet-CNN模型进行微调,在全连接层中学习1800万的新参数,用于预测抓取位置。
我们没有使用回归损失,而是将抓取问题表示为一个超过18个角度的18二元分类。受强化学习范式的启发,我们还提出了一个基于阶段-课程的学习算法,在那里我们学习如何掌握,并使用最近学习的模型来收集更多的数据。

2. RELATED WORK
| 使用分析方法和三维推理来预测抓取的位置和配置。 | 需要三维建模出给定的物体,以及物体的表面摩擦特性和质量分布。 | 感知和推断三维模型和其他属性,如来自RGB或RGBD相机的摩擦/质量是一个极其困难的问题。 | 为了解决这些问题,人们构建了抓取数据集。根据相似性对抓取值进行采样和排序,以抓取已有数据集中的实例。 |
|---|---|---|---|
| 预测抓取包括使用模拟器,如Graspit | 对抓取候选动作进行采样,并采用分析的方式对他们进行排序。 | 然而,经常会出现关于模拟环境如何反映真实世界的问题。 | 有论文已经分析出为什么一个模拟的环境不能与高度非结构化的真实世界平行。 |
| 利用视觉学习直接从RGB或RGB-d图像中预测抓取位置。 | 使用基于视觉的特征(边缘和纹理过滤器响应),并在合成数据上学习逻辑回归器。使用人类注释的抓取数据在RGB-D数据上训练抓取合成模型。 | 然而,如上所述,为抓取预测任务而大规模收集训练数据并不是很简单的,而且有几个问题。 | 因此,上述任何一种方法都不能扩展到使用大数据。(2016年) |
| 利用机器人自己的试错经验。 | 前人的工作只使用几百次试错运行来训练高容量的深度网络。但是存在过拟合和泛化能力差。 | 使用强化学习来学习一个杂乱场景的深度图像上的掌握属性。 | 抓取属性是基于超体素分割和小面检测。这就产生了一个抓取合成过程,对于复杂的对象可能不适合该方法。 |
我们提出了一个端到端自我监督分阶段的阶段-学习系统,它使用数千次试错运行来学习深度网络。然后,学习到的深度网络被用来收集更多的正负和硬负(模型认为是可获取的,但通常不是)数据,这有助于网络更快地学习。
3. APPROACH
Robot Grasping System
实验是在Rethink机器人公司的Baxter特机器人上进行,使用ROS作为我们的开发系统。
对于夹持器,我们使用双指平行夹持器,最大宽度(打开状态)为 75 m m 75mm 75mm,最小宽度(闭合状态)为 37 m m 37mm 37mm。
一个KinectV2连接到机器人的头部,可以提供 1920 × 1280 1920 \times 1280 1920×1280分辨率的工作空间图像(暗白色的桌面)。此外,一个 1280 × 720 1280 \times 720 1280×720分辨率的相机被连接到每个Baxter的末端执行器上,它提供了与Baxter交互的对象的丰富图像。
为了进行轨迹规划,使用了扩展空间树(Expansive Space Tree)规划器。使用这两个机器人臂来更快地收集数据。
在实验过程中,人类的参与仅限于打开机器人,并以任意的方式将物体放在桌子上。除了初始化之外,我们没有人类参与数据收集的过程。
Gripper Configuration Space and Parametrization
在本文中,我们只关注平面上的抓取力。
平面抓取是指抓取配置沿着并垂直于工作空间。因此,抓取配置为三维, ( x , y ) (x,y) (x,y):抓取点在桌子表面的位置,以及 θ \theta θ:抓取点的角度。
A. Trial and Error Experiments

该工作空间首先设置了多个不同难度的对象,随机放置在一张背景为暗白的桌子上。然后连续执行多次随机试验。
Region of Interest Sampling
从头戴式Kinect查询的桌面图像通过现成的高斯混合(MOG)背景减影算法识别该算法识别图像中感兴趣的区域。
这样做仅仅是为了减少在附近没有物体的空地上进行的随机试验的次数。
然后选择该图像中的一个随机区域作为特定试验实例的感兴趣区域。
Grasp Configuration Sampling
给定一个特定的感兴趣区域,机器人手臂移动到物体上方25厘米。
现在,从感兴趣区域的空间中均匀地采样一个随机点。这将是机器人的抓取点。
为了完成抓握配置,现在在范围 ( 0 , π ) (0,\pi) (0,π)内随机选择一个角度,因为两个指握器是对称的。
Grasp Execution and Annotation
现在给定抓取配置,机器人臂对对象执行抓取。
然后将物体抬高20厘米,并根据握把的力传感器读数标注为成功或失败。
在执行这些随机试验过程中,所有摄像机的图像、机器人手臂轨迹和握历史都被记录到磁盘上。
B. Problem Formulation
抓取综合问题被表述为在给定一个对象 I I I的图像时找到一个成功的抓取配置 ( x S , y S , θ S ) (x_{S},y_{S},\theta_{S}) (xS,yS,θS)。

CNN’s INPUT
我们的CNN的输入是一个在抓取点周围提取的图像补丁。
在我们的实验中,我们使用的补丁是指尖在图像上投影的 1.5 1.5 1.5倍,也包括上下文。
实验中使用的贴片尺寸为 380 × 380 380 \times 380 380×380。这个补丁的大小被调整为 227 × 227 227 \times 227 227×227,这是图像网络训练的AlexNet的输入图像大小。
CNN’s OUTPUT
首先学习一个二元分类器模型,该模型将物体分为可抓取与否,然后选择物体的抓取角。
然而,图像贴片的可抓性是夹持器角度的函数,因此图像贴片可以被标记为可抓的和不可抓的。
相反,在我们的例子中,给定一个图像补丁,我们估计一个18维似然向量,其中每个维度表示补丁的中心是否在 0 ° , 10 ° , ⋯ 170 ° 0°, 10°, \cdots170° 0°,10°,⋯170°。因此,我们的问题可以看作是一个18元二分类问题。
Testing
给定一个图像补丁,我们的CNN输出18个抓取角度的中心。
在机器人的测试时间,给定一个图像,我们对抓取位置进行采样,提取补丁输入CNN。
对于每个补丁,输出是18个值,它们描述了18个角度中的每个角度的可抓取性得分。
C. Training Approach
Data preparation
给定一个试验实验数据点 ( x i , y i , θ i ) (x_{i},y_{i},\theta_{i}) (xi,yi,θi),我们以 ( x i , y i ) (x_{i},y_{i}) (xi,yi)为中心抽取 380 × 380 380 \times 380 380×380贴片。
为了增加网络所看到的数据量,我们使用了旋转转换:通过 θ r a n d \theta_{rand} θrand旋转数据集补丁,并将相应的抓取方向标记为 θ i + θ r a n d θ_{i}+θ_{rand} θi+θrand。其中一些补丁可以在图4中看到。
Network Design
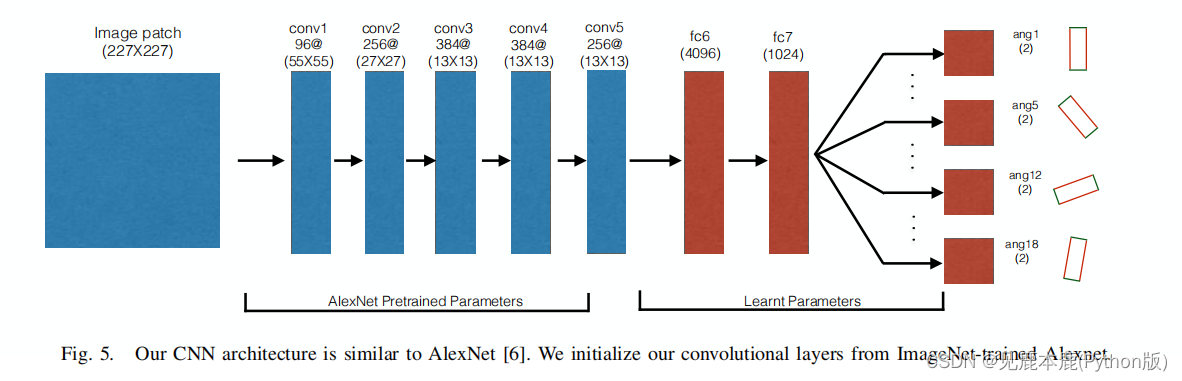
我们的CNN,是一个标准的网络架构。
我们的前五个卷积层取自预先训练过的AlexNet。我们还使用了两个完全连接的层,分别有4096个和1024个神经元。
这两个完全连接的层,fc6和fc7,用高斯初始化进行训练。
Loss Function
L B = ∑ i = 1 B ∑ j = 1 N = 18 δ ( j , θ i ) ⋅ s o f t m a x ( A j i , l i ) L_{B} = \sum_{i=1}^{B} \sum_{j=1}^{N=18} \delta(j, θ_{i})·softmax(A_{ji}, l_{i}) LB=i=1∑Bj=1∑N=18δ(j,θi)⋅softmax(Aji,li)
其中, δ ( j , θ i ) = 1 \delta(j,θ_{i})=1 δ(j,θi)=1时, θ i θ_{i} θi对应于第 j j j个类。
请注意,网络的最后一层包含18个二进制层,而不是一个多层分类器来预测最终的可抓取性分数。
因此,对于单个补丁,只有试验对应类的损失能被反向传播。
D. Multi-Staged Learning
在数据收集的这个阶段,我们同时使用以前看到的对象和新对象。这确保了在下一次迭代中,机器人纠正不正确的抓取模式,同时加强正确的抓取模式。
需要注意的是,在这一阶段的每次对象抓取试验中,都会随机抽取800块补丁,并由上一次迭代中学习到的深度网络进行评估。
这就产生了一个 800 × 18 800\times18 800×18的抓取能力先验矩阵,其中输入 ( i , j ) (i,j) (i,j)对应于第 i i i个补丁的第 j j j个类上的网络激活。抓取执行现在是由抓取能力先验矩阵的重要性抽样决定的。
受数据聚合技术的启发,在第 k k k次迭代的训练过程中,数据集 D k D_{k} Dk由 { D k } = { D k − 1 , Γ d k } \{D_{k}\}=\{D_{k−1},\Gamma d_{k}\} { Dk}={ Dk−1,Γdk}给出,其中 d k d_{k} dk是使用第 k − 1 k−1 k−1次迭代的模型收集的数据。
注意, D 0 D_{0} D0是随机抓取数据集,第 0 0 0次迭代只是简单地在 D 0 D_{0} D0上进行训练。
作为设计选择,重要性因素 Γ \Gamma Γ保持为3。

4. RESULTS
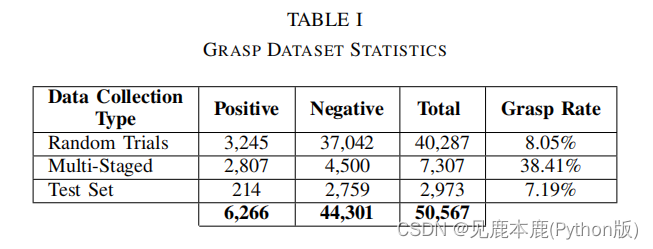
A. Training dataset
B. Testing and evaluation setting
通过3k次物理机器人交互收集了15个新颖的、不同的测试对象的多个位置。
这个测试集是通过从收集到的机器人交互中随机抽样来平衡的。
用于评估的精度度量是二元分类,即在测试集中给定一个补丁并执行抓取角,以预测对象是否被抓取。
该方法的评估保留了抓取的两个重要方面:(a)它确保了测试数据完全相同的比较,这与真实的机器人实验是不可能的;(b)数据来自一个真实的机器人,这意味着在这个测试集上工作良好的方法应该在真实的机器人上工作良好。
我们的基于深度学习的方法,然后是多阶段强化,在这个测试集上产生了 79.5 % 79.5\% 79.5%的准确率。
C. Comparison with heuristic baselines
为RGB图像输入任务修改的启发式算法,编码了明显的抓取规则。
- 抓住补丁的中心。这一规则隐含在我们的基于补丁的抓取公式中。
- 掌握最小的物体宽度。这是通过目标分割和特征向量分析来实现的。
- 不要抓住太薄的物体,因为抓手没有完全关闭。
获得的最大准确率为 62.11 % 62.11\% 62.11%,明显低于本方法的精度。
D. Comparison with learning based baselines
我们在以下两个baseline中都使用了HoG特征,因为它保留了旋转方差,这对抓取很重要。
- k最近邻(kNN):对于测试集中的每一个元素,对训练集中属于同一角度类的元素进行基于kNN的分类。不同k值情况下的最大准确率为 69.4 % 69.4\% 69.4%。
- 线性SVM:为18个角度箱中的每一个学习18个二进制支持向量机。通过验证选择正则化参数后,得到的最大准确率为 73.3 % 73.3\% 73.3%。
E. Ablative analysis
Effects of data
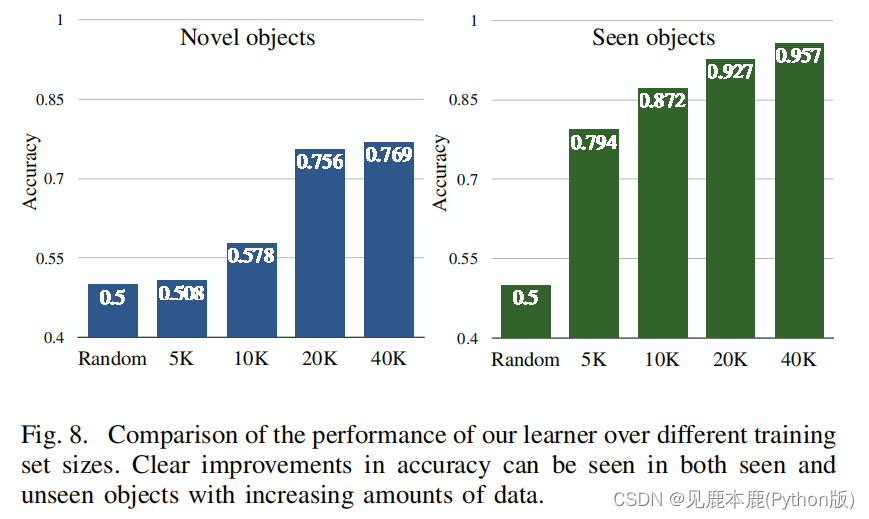
添加更多的数据肯定有助于提高准确性。这种增长更为显著,直到大约20K个数据点,之后增长幅度很小。
Effects of pretraining
我们的实验表明,这种提升是显著的:从网络的准确率为 64.6 % 64.6\% 64.6%到预训练网络的 76.9 % 76.9\% 76.9%。这意味着从图像分类任务中学习到的视觉特征辅助了抓取对象的任务
Effects of multi-staged learning
经过一个阶段的加固后,测试精度从 76.9 % 76.9\% 76.9%提高到 79.3 % 79.3\% 79.3%。这显示了训练中硬负的效果,只有2K抓取比20K随机抓取提高更多。然而,在3个阶段后,准确率的提高饱和到 79.5 % 79.5\% 79.5%。
Effects of data aggregation
我们注意到,在没有对数据进行聚合,并且仅使用当前阶段的数据来训练抓取模型的情况下,准确率从 76.9 % 76.9\% 76.9%下降到了 72.3 % 72.3\% 72.3%。
F. Robot testing results
Re-ranking Grasps
因此,为了考虑不精度,我们对前10个抓取进行采样,并基于邻域分析对其进行重新排序:给定一个顶部补丁的实例 ( P t o p K i , θ t o p K i ) (P^{i}_{topK},\theta^{i}_{topK}) (PtopKi,θtopKi),我们进一步在 P t o p K i P^{i}_{topK} PtopKi的邻域采样10个补丁。邻域斑块的最佳角度得分的平均值被分配为由 ( P t o p K i , θ t o p K i ) (P^{i}_{topK},\theta^{i}_{topK}) (PtopKi,θtopKi)定义的抓取配置的新补丁得分 R t o p K i R^{i}_{topK} RtopKi。然后执行与最大的 R t o p K i R^{i}_{topK} RtopKi相关联的抓取配置。
Grasp Result
请注意,一些抓握,如第二排的红色枪是合理的,但仍然不成功,因为握把的尺寸与物体的宽度不兼容。
Clutter Removal
我们尝试了5次尝试,以去除从新奇和以前看到的物体中提取的10个物体。平均而言,Baxter在26次互动中成功地清除了混乱。
5. CONCLUSION
未来的一个扩展将是在RGB-D数据领域中训练抓取模型,这给在深度网络中正确利用深度带来了挑战。
此外,将物体的三维信息可以扩展到预测非平面抓取。