一、概述
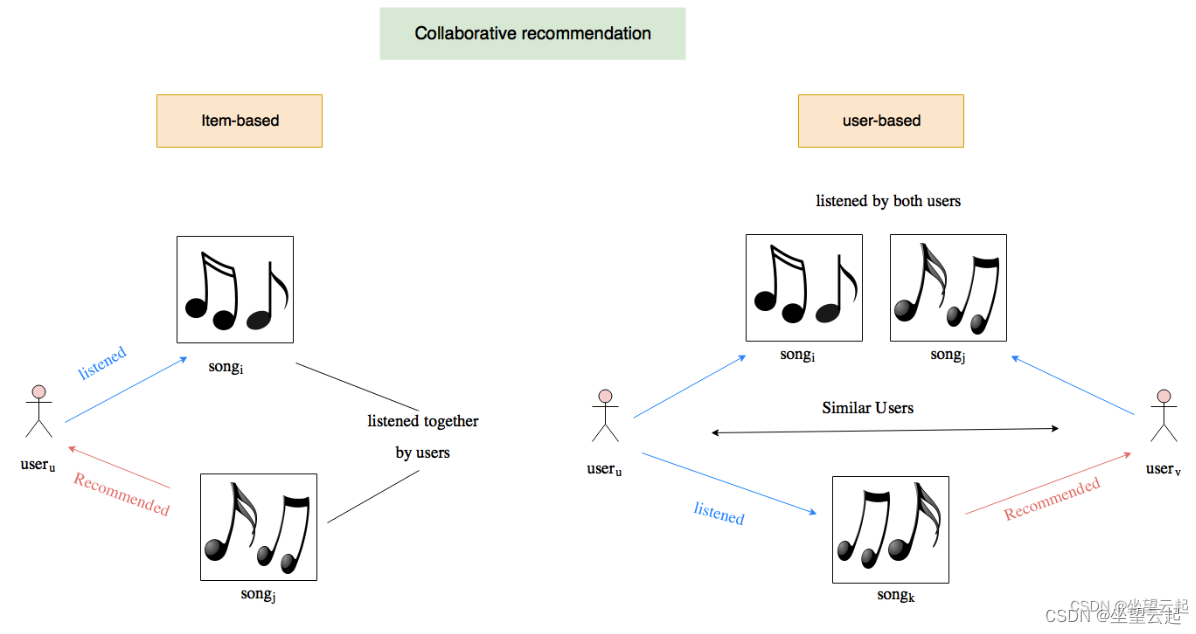
协同过滤算法最常用于推荐系统的应用中。由于互联网的使用和产生的大量信息,用户找到自己的喜好成为一项非常繁琐的任务。用户对物品的偏好以评分矩阵的形式表示,用于建立用户和物品之间的关系以找到用户的相关物品。因此,如今的协同过滤算法面临着数据集大、评分矩阵稀疏的问题。
在各种协同过滤技术中,矩阵分解是最流行的一种,它将用户和项目投影到共享的潜在空间中,使用潜在特征向量来表示用户或项目。之后,用户对项目的交互被建模为其潜在向量的内积。
尽管矩阵分解对协同过滤有效,但众所周知,它的性能可能会受到交互函数的简单选择的阻碍:内积。例如,对于显式反馈的评分预测任务,众所周知,矩阵分解模型的性能可以通过将用户和项目偏差项合并到交互函数中来提高。虽然这对于内部产品操作员来说似乎只是一个微不足道的调整,但它指出了设计一个更好的、专用的交互功能来建模用户和项目之间的潜在特征交互的积极效果。简单地线性组合潜在特征的乘法的内积可能不足以捕捉用户交互数据的复杂结构。
在这里将探讨使用多层感知器进行协同过滤。多层感知器是一种前馈神经网络,在输入层和输出层之间具有多个隐藏层。它可以被解释为非线性变换的堆叠层来学习分层特征表示。它是一个简洁但实用的网络,可以将任何可测量的函数逼近到任何所需的准确度(这种现象称为通用逼近定理)。因此,它是众多先进方法的基础,并被广泛用于许多领域。
二、相关论文推荐
1、广泛和深度学习
记忆和泛化对于推荐系统都至关重要。Google的论文“Wide and Deep Learning for Recommender Systems”(2016 年)提出了一个框架,可以结合宽线性模型和深度神经网络的优势来解决这两个问题。
论文见下面地址
https://arxiv.org/pdf/1606.07792.pdf如下图所示,广域学习组件是一个单层感知器,可以使用叉积特征变换有效地记忆稀疏特征交互。深度学习组件是一个多层感知器,可以通过低维嵌入泛化到以前看不见的特征交互。

从数学上讲,广泛学习被定义为:

其中 y 是预测,x 是特征向量,W 是模型参数向量,b 是偏差。特征集包括原始输入和转换后的输入(通过叉积转换来捕获特征之间的相关性)。
在深度学习组件中,每个隐藏层执行以下计算:
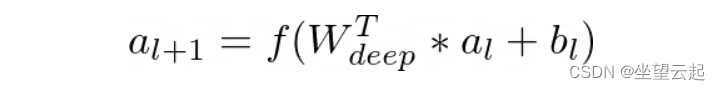
其中 l 是层数,f 是激活函数,是激活向量,
是偏差向量,
是第 l 层的模型权重向量。
通过融合这些模型获得了广泛而深入的学习模型:
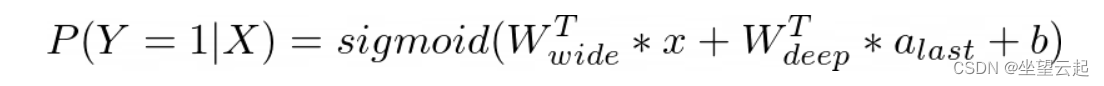
其中 Y 是二元类标签, 是所有宽模型权重的向量,
是应用于最终激活
的权重向量,b 是偏置项。
import torch
from layer import FeaturesLinear, FeaturesEmbedding, MultiLayerPerceptron
class WideAndDeepModel(torch.nn.Module):
"""
A Pytorch implementation of wide and deep learning.
Reference:
HT Cheng, et al. Wide & Deep Learning for Recommender Systems, 2016.
"""
def __init__(self, field_dims, embed_dim, mlp_dims, dropout):
"""
:param field_dims: Number of input dimensions
:param embed_dim: Number of dense embedding dimensions
:param mlp_dims: Number of hidden layers
:param dropout: dropout rate
"""
super().__init__()
# Wide Learning Component
self.linear = FeaturesLinear(field_dims)
# Deep Learning Component
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.embed_output_dim = len(field_dims) * embed_dim
self.mlp = MultiLayerPerceptron(self.embed_output_dim, mlp_dims, dropout)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
# Get feature embeddings
embed_x = self.embedding(x)
# Joint learning of the wide component and the deep component
x = self.linear(x) + self.mlp(embed_x.view(-1, self.embed_output_dim))
return torch.sigmoid(x.squeeze(1))2、深度分解机
作为 Wide and Deep Learning 方法的扩展,Huifeng Guo 等人的“DeepFM: A Factorization-Machine Based Neural Network for CTR Prediction”(2017)。是一个端到端模型,无缝集成了因子分解机(宽组件)和多层感知器(深层组件)。与 Wide and Deep 模型相比,DeepFM 不需要繁琐的特征工程。
论文见下面地址:
https://arxiv.org/pdf/1703.04247.pdf如下图所示,Factorization Machine 利用加法和内积运算来捕捉特征之间的线性和成对交互。多层感知器利用非线性激活和深层结构来模拟高阶交互。
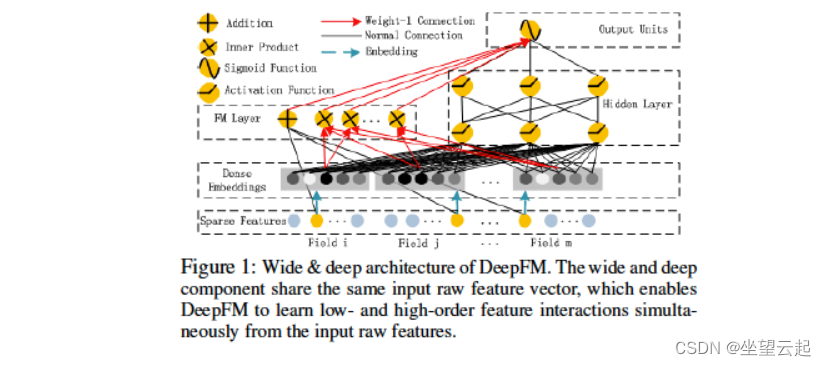
从数学上讲,DeepFM 的输入是由对 (u, i) 组成的 m 字段数据——它们是用户和项目的身份和特征,以及表示用户点击行为的二进制标签 y(y = 1 表示用户单击该项目,否则 y = 0)。这里的任务是建立一个预测模型来估计用户在给定上下文中点击特定应用程序的概率。
对于任何特定的特征 i,标量 用于衡量其一阶重要性,而潜在向量
用于衡量其与其他特征交互的影响。
被输入到宽组件中以对二阶特征交互进行建模,并在深度组件中输入以对高阶特征交互进行建模。所有参数,包括
、
和网络参数都针对组合预测模型进行联合训练:
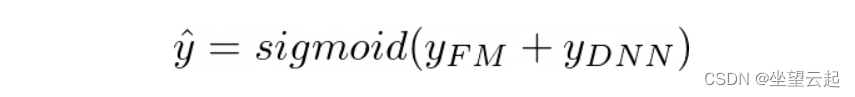
其中是预测的 CTR(介于 0 和 1 之间),
是宽因子分解机组件的输出,
是多层感知器组件的输出。
在宽分量中,除了特征之间的线性(一阶)交互之外,因子分解机将成对(二阶)特征交互建模为各个特征潜在向量的内积。这有助于在数据集稀疏时非常有效地捕获二阶特征交互。Factorization Machine 的输出是一个加法单元和几个内积单元的总和:
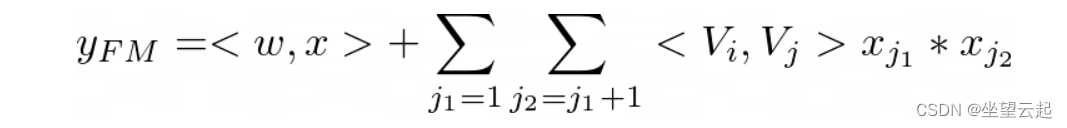
给定特征 i 和 j。加法单元(第一项)反映一阶特征的重要性,内积单元(第二项)代表二阶特征交互的影响。
在深层组件中,多层感知器的输出如下所示:

其中 |H| 是隐藏层的数量,a是嵌入层的向量输出,W是模型权重的向量,b是偏置单元的向量。
import torch
from layer import FactorizationMachine, FeaturesEmbedding, FeaturesLinear, MultiLayerPerceptron
class DeepFactorizationMachineModel(torch.nn.Module):
"""
A Pytorch implementation of DeepFM.
Reference:
H Guo, et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, 2017.
"""
def __init__(self, field_dims, embed_dim, mlp_dims, dropout):
super().__init__()
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.embed_output_dim = len(field_dims) * embed_dim
self.mlp = MultiLayerPerceptron(self.embed_output_dim, mlp_dims, dropout)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
embed_x = self.embedding(x)
x = self.linear(x) + self.fm(embed_x) + self.mlp(embed_x.view(-1, self.embed_output_dim))
return torch.sigmoid(x.squeeze(1))3、极端深度分解机
作为深度分解机的扩展,“xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems”(2018 年)来自 Jianxun Lian 等人。可以联合建模显式和隐式特征交互。显式高阶特征交互是通过压缩交互网络学习的,而隐式高阶特征违规是通过多层感知器学习的。该模型也不需要手动特征工程,并将数据科学家从繁琐的特征搜索工作中解放出来。
论文见下面地址
https://arxiv.org/pdf/1803.05170.pdf压缩交互网络的设计考虑了以下几点:
- 交互是在向量级别应用的,而不是在位级别。
- 高阶特征交互是明确测量的。
- 网络的复杂性不会随着交互程度的增加而呈指数增长。
压缩交互网络的结构与循环神经网络非常相似,其中下一个隐藏层的输出取决于最后一个隐藏层和附加输入。各层嵌入向量的结构保持现状;因此,交互作用是在向量层面应用的。

- 看上面的图 4a,中间张量
是隐藏层
和原始特征矩阵 x⁰ 的每个嵌入维度的外积。计算每个隐藏层
是一个过滤器。
- 如图 4b 所示,作者沿着嵌入维度在
——在计算机视觉中通常称为特征图。因此,
个不同特征图的集合。
- 图 4c 概述了压缩交互网络的架构。让 T 表示网络的深度。每个隐藏层
都有与输出单元的连接。作者在隐藏层的每个特征图上应用 sum pooling,得到第 k 个隐藏层的长度为
。来自隐藏层的所有池化向量在连接到输出单元之前被连接:p+ = [p¹, p², ...,
]
xDeepFM 通过广泛和深度学习框架将上述压缩交互网络与普通多层感知器相结合。一方面,该模型包括低阶和高阶特征交互;另一方面,它还包含隐式和显式特征交互。架构如图所示。

从数学上讲,得到的输出单位是:
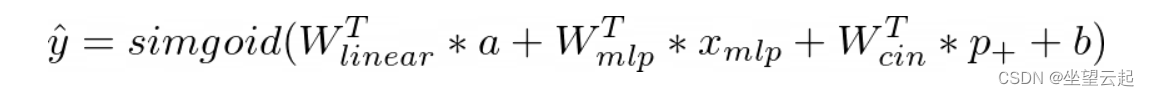
其中 a 是原始特征的向量, 是普通多层感知器的输出向量,p+ 是交叉交互网络的输出向量。W 和 b 是可学习的参数——分别是权重和偏差。
import torch
from layer import CompressedInteractionNetwork, FeaturesEmbedding, FeaturesLinear, MultiLayerPerceptron
class ExtremeDeepFactorizationMachineModel(torch.nn.Module):
def __init__(self, field_dims, embed_dim, mlp_dims, dropout, cross_layer_sizes, split_half=True):
super().__init__()
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.embed_output_dim = len(field_dims) * embed_dim
self.cin = CompressedInteractionNetwork(len(field_dims), cross_layer_sizes, split_half)
self.mlp = MultiLayerPerceptron(self.embed_output_dim, mlp_dims, dropout)
self.linear = FeaturesLinear(field_dims)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
embed_x = self.embedding(x)
x = self.linear(x) + self.cin(embed_x) + self.mlp(embed_x.view(-1, self.embed_output_dim))
return torch.sigmoid(x.squeeze(1))4、神经分解机
另一个无缝集成因子分解机和多层感知器的并行工作是向南和 Tat-Seng Chua 的“用于稀疏预测分析的神经因子分解机”(2017 年)。该模型将线性分解机器的有效性与用于稀疏预测分析的非线性神经网络的强大表示能力结合在一起。
https://arxiv.org/pdf/1708.05027.pdf如下所示,其架构的关键是一种称为双线性交互池的操作,它允许神经网络模型在较低级别学习更多信息的特征交互。通过在 Bilinear-Interaction 层之上堆叠非线性层,作者能够加深浅层线性因子分解机,有效地建模高阶和非线性特征交互,以提高因子分解机的表达能力。与在低层简单地连接或平均嵌入向量的传统深度学习方法相比,双线性交互池的这种使用编码了更多信息的特征交互,极大地促进了以下“深度”层学习有意义的信息。
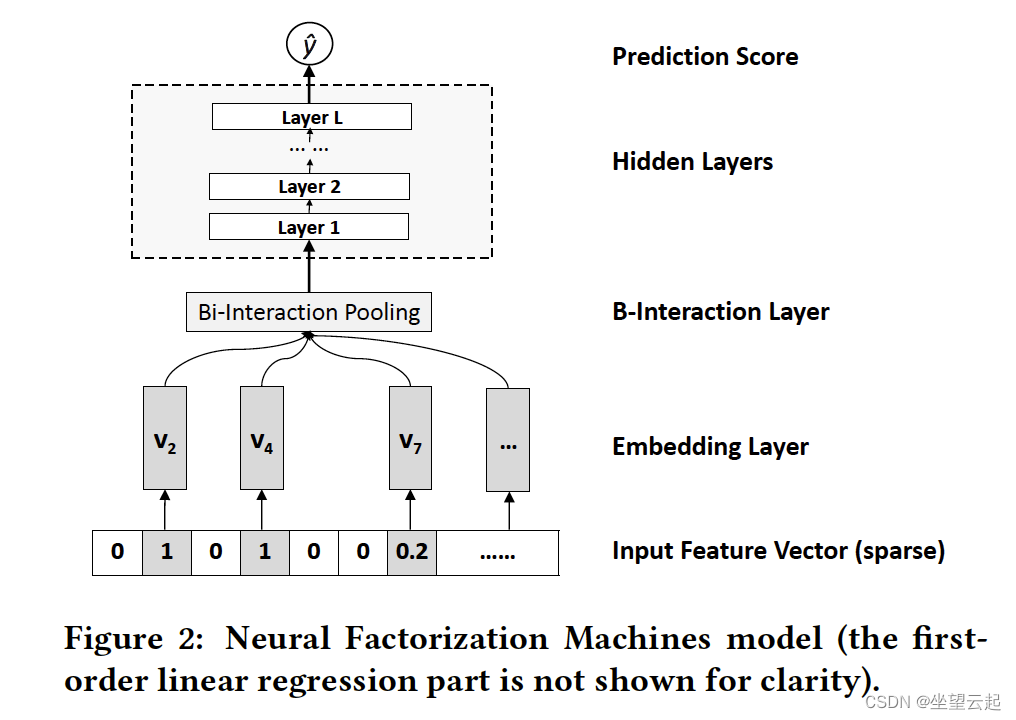
神经因子分解机模型的数学。给定一个稀疏向量 x 作为输入,模型将目标估计为:

其中第一项对特征数据的全局偏差进行建模,第二项对特征权重的全局偏差进行建模,第三项 f(x) 是对特征交互进行建模的多层感知器(如图 2 所示)。f(x) 的设计由以下层组件组成:
嵌入层
这是一个全连接层,将每个特征投影到一个密集的向量表示。令 v_i 为第 i 个特征的嵌入向量。然后在嵌入步骤之后,作者获得一组嵌入向量来表示输入特征向量 x。
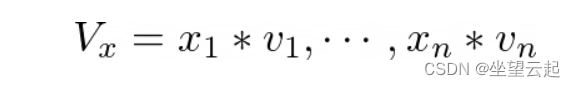
由于 x 可能的稀疏表示,作者只包括非零特征的嵌入向量,其中 x_i 不等于 0。
双线性交互层
然后将嵌入集 V_x 输入到 Bilinear-Interaction 层,这是一个池化操作,将一组嵌入向量转换为一个向量:

其中 表示两个向量
和
的元素乘积。这个池化的输出是一个 k 维向量,它对嵌入空间中特征之间的二阶交互进行编码。
隐藏层
在双线性交互池层之上是一堆全连接层,它们能够学习特征之间的高阶交互。这些隐藏层的定义是:

其中 L 是隐藏层的数量;、
和
分别对应第 l 层的权重矩阵、偏置向量和激活函数。激活函数的选择可以是 sigmoid、tanh 或 ReLU,以非线性地学习高阶特征交互。
预测层
最后,将最后一个隐藏层 z_L 的输出向量转化为最终的预测分数:

其中 表示预测层的神经元权重。
import torch
from layer import FactorizationMachine, FeaturesEmbedding, MultiLayerPerceptron, FeaturesLinear
class NeuralFactorizationMachineModel(torch.nn.Module):
def __init__(self, field_dims, embed_dim, mlp_dims, dropouts):
super().__init__()
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.linear = FeaturesLinear(field_dims)
self.fm = torch.nn.Sequential(
FactorizationMachine(reduce_sum=False),
torch.nn.BatchNorm1d(embed_dim),
torch.nn.Dropout(dropouts[0])
)
self.mlp = MultiLayerPerceptron(embed_dim, mlp_dims, dropouts[1])
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
cross_term = self.fm(self.embedding(x))
x = self.linear(x) + self.mlp(cross_term)
return torch.sigmoid(x.squeeze(1))5、神经协同过滤
何向南等人的论文“神经协同过滤(2018)”,进一步推动了使用多层感知器从数据中学习交互功能。请注意,他们也是上述神经因子分解机器论文的同一作者。他们形式化了一种用于协同过滤的建模方法,该方法侧重于隐式反馈,通过观看视频、购买商品、点击商品等行为间接反映用户的偏好。与诸如评级和评论之类的显式反馈相比,隐式反馈可以自动跟踪,因此对于内容提供者来说收集起来更加自然。然而,使用起来更具挑战性,因为没有观察到用户满意度,并且负反馈固有的稀缺性。
https://www.comp.nus.edu.sg/~xiangnan/papers/ncf.pdf用于建模用户隐式反馈的用户-项目交互值 y_ui 可以为 1 或 0。值为 1 表示用户 u 与项目 i 之间存在交互,但并不表示 u 喜欢 i。这对从隐式数据中学习提出了挑战,因为它只提供有关用户偏好的噪声信号。虽然观察到的条目至少反映了用户对项目的兴趣,但未观察到的条目可能只是缺少数据,并且自然缺乏负面反馈。
作者采用多层表示来对用户-项目交互 y_ui 进行建模,如下所示,其中一层的输出作为下一层的输入。
- 底部输入层由 2 个描述用户 u 和项目 i 的特征向量组成,可以对其进行定制以支持对用户和项目的广泛建模。特别是,该论文仅使用用户和项目的身份作为输入特征,将其转换为具有 one-hot 编码的二值化稀疏向量。有了这样一个通用的输入特征表示,这个框架可以很容易地通过使用内容特征来表示用户和项目来解决冷启动问题。
- 输入层之上是嵌入层——一个将稀疏表示投影到密集向量的全连接层。获得的用户/项目嵌入可以看作是潜在因子模型上下文中用户/项目的潜在向量。
- 然后将用户嵌入和项目嵌入输入到多层神经架构(称为神经协同过滤层)中,以将潜在向量映射到预测分数。神经协同过滤层的每一层都可以定制,以发现用户-项目交互的特定潜在结构。最后一个隐藏层 X 的维度决定了模型的能力。
- 最终的输出层是预测得分 y-hat_ui,通过最小化 y-hat_ui 与其目标值 y_ui 之间的逐点损失来进行训练。
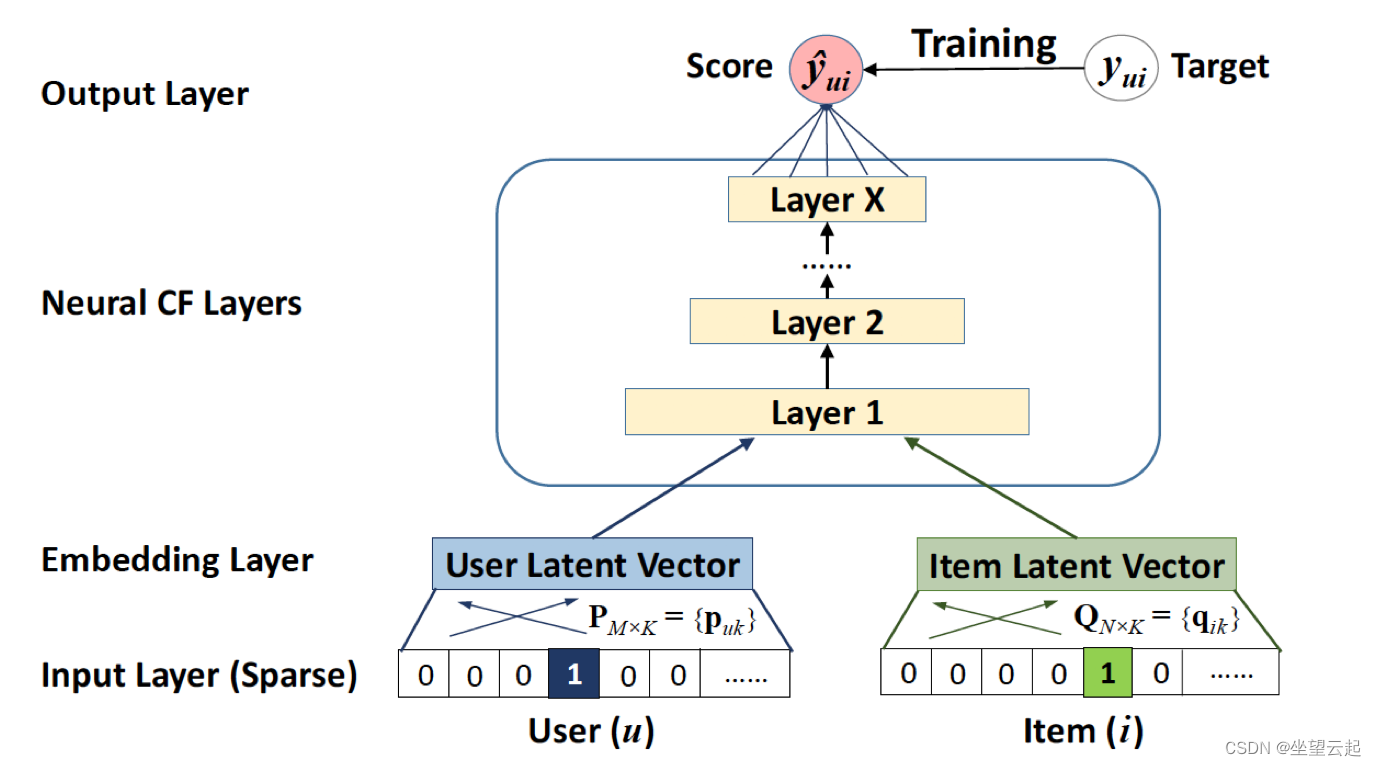
上面的框架可以用下面的评分函数来概括:

其中y-hat_ui是交互y_ui的预测得分,theta表示模型参数。f 是将模型参数映射到预测分数的多层感知器。更具体地说,P 是用户的潜在因子矩阵,Q 是项目的潜在因子矩阵,v_u^U 是与用户特征相关的辅助信息,v_i^I 是与项目特征相关的辅助信息。
该论文认为,传统的矩阵分解可以看作是神经协同过滤的一个特例。因此,可以方便地将矩阵分解的神经解释与多层感知器相融合,形成一个更通用的模型,利用矩阵分解的线性和多层感知器的非线性来提高推荐质量。
import torch
from layer import FeaturesEmbedding, MultiLayerPerceptron
class NeuralCollaborativeFiltering(torch.nn.Module):
def __init__(self, field_dims, user_field_idx, item_field_idx, embed_dim, mlp_dims, dropout):
super().__init__()
self.user_field_idx = user_field_idx
self.item_field_idx = item_field_idx
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.embed_output_dim = len(field_dims) * embed_dim
self.mlp = MultiLayerPerceptron(self.embed_output_dim, mlp_dims, dropout, output_layer=False)
self.fc = torch.nn.Linear(mlp_dims[-1] + embed_dim, 1)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_user_fields)``
"""
x = self.embedding(x)
user_x = x[:, self.user_field_idx].squeeze(1)
item_x = x[:, self.item_field_idx].squeeze(1)
x = self.mlp(x.view(-1, self.embed_output_dim))
gmf = user_x * item_x
x = torch.cat([gmf, x], dim=1)
x = self.fc(x).squeeze(1)
return torch.sigmoid(x)三、模型评估
数据集是MovieLens 1M,类似于矩阵分解实验。目标是预测用户对特定电影的评分——评分在 1 到 5 之间。
唯一的区别是,为了使用为点击率预测而设计的基于分解机的模型,我使用二元评级。小于等于 3 的评分被视为 0,大于 3 的评分被视为 1。
因此,评估指标是AUC,考虑到这是一个二元分类问题(而不是像上次那样的 RMSE)。
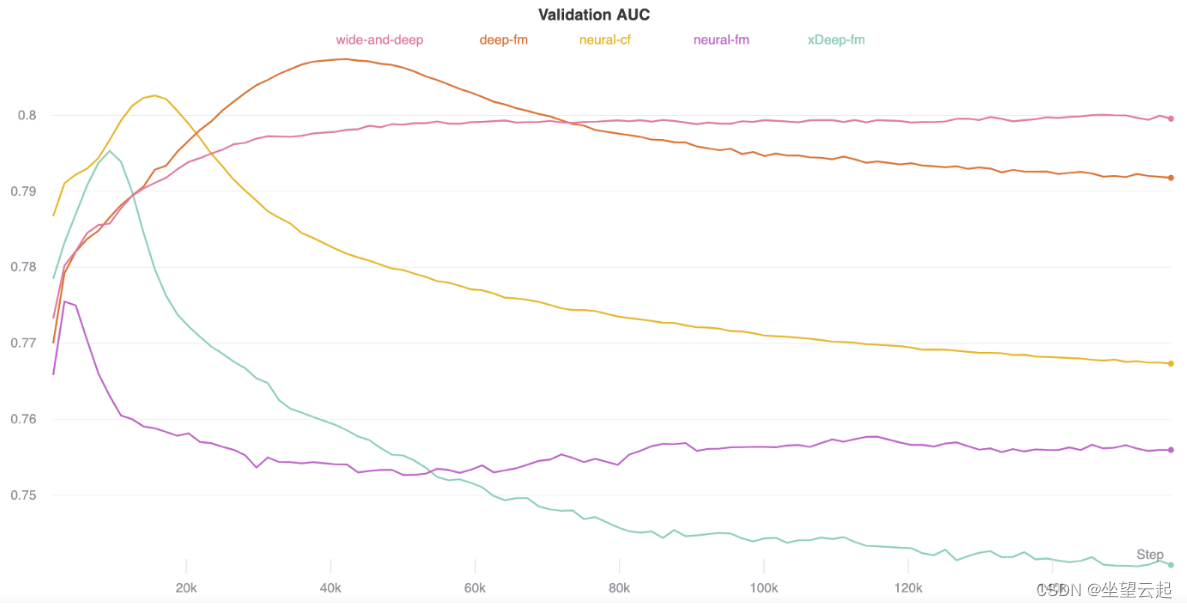
Wide and Deep Learning 模型在测试和验证集中都有最好的 AUC 结果。
另一方面,极端深度分解机分别具有最低的 AUC。
神经协同过滤的运行时间最快,极端深度分解机的运行时间最慢。
