这个博客让我们来讨论一下推荐系统,首先我们来讨论一下为什么学习推荐系统:
1. 推荐系统是机器学习中的一个重要应用,它已经用于很多企业中,比如淘宝、今日头条、亚马逊等。它们会根据你的浏览记录,当你再次访问时,会给你推荐一些你感兴趣的东西。
2. 我们从前面学过的机器学习知道,对于一个算法特征的选择,对算法性能的影响很大。而后面讲到的推荐系统的建立过程中,该算法可以自动的学习一套很好的特征,而不需要试图手动设计。
下面我们用一个例子来简单的介绍什么是推荐系统的问题:
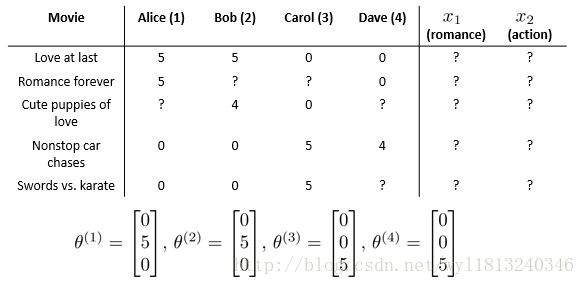
假如我们有一个电影推荐的问题,其中我们已有的数据为5部电影和4个用户,用户给电影打分,具体的打分如下:
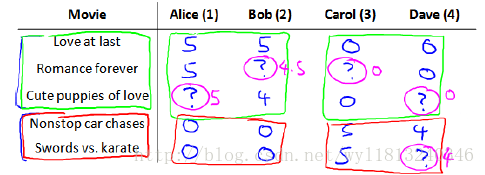
其中,前三部是爱情片,后两部是动作片,“?”代表该用户没有给这不电影打分。
推荐问题是我们希望构建一个算法来预测他们每个人可能会给他们没有看过的电影打多少分,根据这个预测结果的高低来判断是否将其推荐给用户。
基于内容的推荐系统:
基于内容的推荐系统我们假设对于我们推荐的东西有一些数据,这些数据也就是这些东西的特征。
我们还是以上面的那个例子来说明一下基于内容的推荐系统,我们假设每部电影有两个特征,其中
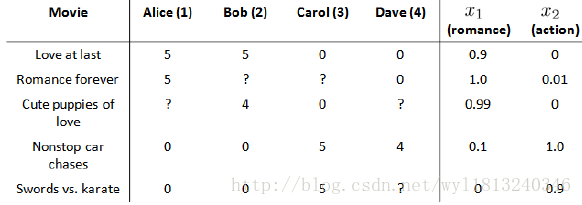
下面我们基于这些特征来构建一个推荐系统的算法。假设我们采用线性回归模型,我们对每一个用户都训练一个线性回归模型,首先我们对使用的参数进行介绍。
于是针对用户j,该线性模型的代价函数为预测误差的平方,所以该代价函数的表达式为(带有正则项):
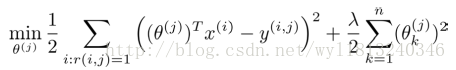
对于推荐系统,我们对上式进行了简化,将原来除以2m去掉,对最终的结果没有影响。
上面的表达式只是针对第j个用户建立的,为了学习所有用户,我们可以将代价函数形式表示为:
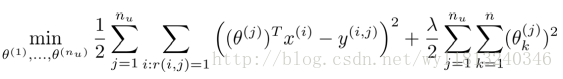
我们使用梯度下降法来求解最优解,我们的代价函数对参数求偏导数之后的更新公式为:
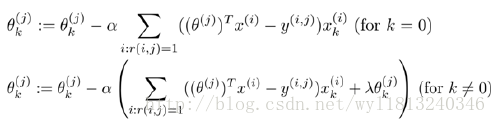
上述的过程就是基于内容的推荐系统的构建过程。
协同过滤算法:
前面我们讲述了基于内容的推荐系统的设计,它是在我们掌握了可用的特征之后,使用这些特征训练出每一个用户的参数;相反地,如果我们拥有用户的参数,我们也可以学习得出电影的特征,数据集的形式如下:
则对应的第i个电影的特征建立的代价函数的表达式为:
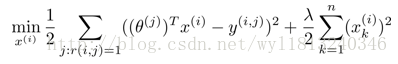
同样我们可以学习所有电影的特征,我们可以将代价函数的形式表示为:
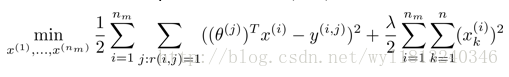
所以对于给定的
但是,如果我们既没有用户的参数,也没有电影的特征,以上两种方法都不能适用,所以我们引入了一种新的方法——协同过滤。它可以同时学习参数以及特征,下面我们讨论一下协同过滤算法的构建过程:
1. 初始化
2.
3. 使用梯度下降法最小化代价函数,对于每一个
4. 在训练算法完成后,我们预测
协同过滤的过程可以理解为,初始化参数
推荐过程的实现为:如果我们得到用户j对于电影i的评价很高,同时电影的特征向量为
协同过滤算法(低秩矩阵分解)的向量化:
协同过滤算法也称为低秩矩阵分解,它可以通过向量化的方式实现。
对于上面的数据集我们可以通过右边的矩阵表示,同时我们能够对每个用户对每个电影的评估也可以用矩阵表示:

所以我们可以将每个电影的特征逐行表示,将每个用户的参数按行表示:
则预测值可以通过
实施过程中的细节——均值归一化:
如果我们对于上面的例子,新增加了一个用户Eve,他没有对任何电影评分,那么我们怎么对他进行电影推荐呢?也就是现在的数据集如下所示:
如果我们直接使用前面的协同过滤算法来最小化代价函数:
由于对于Eve来说,没有
处理的方法为对数据进行均值归一化:我们首先对结果矩阵Y进行均值归一化处理,将每一个用户对某一部电影的评分减去所有用户对该电影评分的平均值:
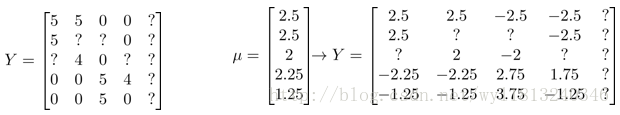
然后我们使用新的矩阵Y来训练算法。如果我们要用新训练的算法来预测评分则需要将平均值重新加回去,预测结果为: