一、自动编码器概述
自动编码器是一种适用于无监督学习任务的神经网络,包括生成建模、降维和高效编码。它在学习计算机视觉、语音识别和语言建模等许多领域的底层特征表示方面表现出了优越性。关于更详细的自动编码器以及相关分类,可以参考下面链接。
二、自动编码器用于协同过滤
1、AutoRec
从自动编码器的角度考虑协同过滤问题的最早模型之一是来自 Suvash Sedhain、Aditya Krishna Menon、Scott Sanner 和 Lexing Xie 的“Autoencoders Meet Collaborative Filtering ”的 AutoRec。
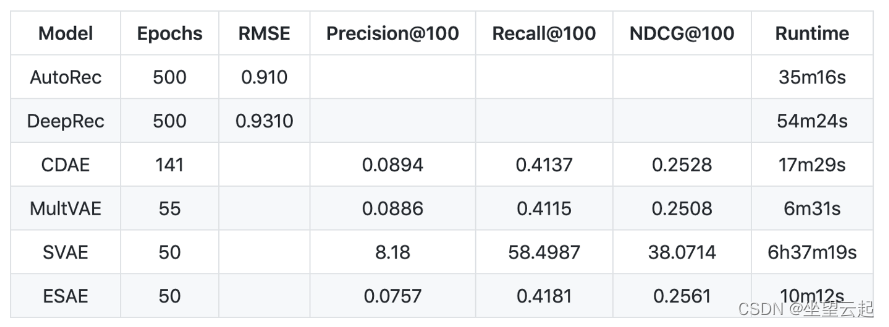
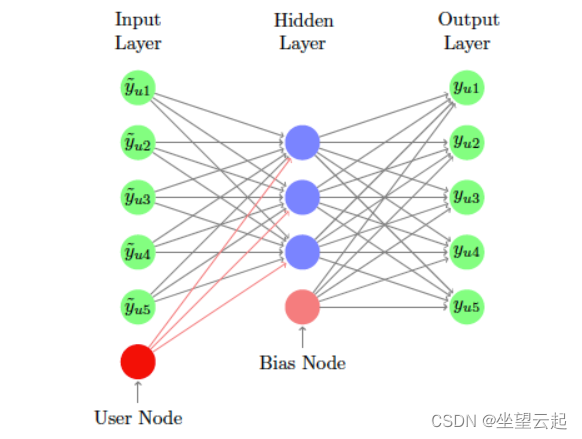
在论文中,有 m 个用户,n 个项目,以及一个部分填充的用户-项目交互/评分矩阵 R,维度为 mx n。每个用户 u 可以用一个部分填充的向量 rᵤ 表示,每个项目 i 可以用一个部分填充的向量 rᵢ 表示。AutoRec 直接将用户评分向量 rᵤ 或项目评分 rᵢ 作为输入数据,并在输出层获得重构评分。根据两种类型的输入,AutoRec 有两种变体:基于项目的 AutoRec ( I-AutoRec ) 和基于用户的 AutoRec ( U-AutoRec )。它们都具有相同的结构。
上图描述了I-AutoRec 的结构。灰色节点对应于观察到的评级,实线连接对应于为输入 rᵢ 更新的权重。
class AutoRec:
def prepare_model(self):
"""
Function to build AutoRec
"""
self.input_R = tf.compat.v1.placeholder(dtype=tf.float32,
shape=[None, self.num_items],
name="input_R")
self.input_mask_R = tf.compat.v1.placeholder(dtype=tf.float32,
shape=[None, self.num_items],
name="input_mask_R")
V = tf.compat.v1.get_variable(name="V", initializer=tf.compat.v1.truncated_normal(
shape=[self.num_items, self.hidden_neuron],
mean=0, stddev=0.03), dtype=tf.float32)
W = tf.compat.v1.get_variable(name="W", initializer=tf.compat.v1.truncated_normal(
shape=[self.hidden_neuron, self.num_items],
mean=0, stddev=0.03), dtype=tf.float32)
mu = tf.compat.v1.get_variable(name="mu", initializer=tf.zeros(shape=self.hidden_neuron), dtype=tf.float32)
b = tf.compat.v1.get_variable(name="b", initializer=tf.zeros(shape=self.num_items), dtype=tf.float32)
pre_Encoder = tf.matmul(self.input_R, V) + mu
self.Encoder = tf.nn.sigmoid(pre_Encoder)
pre_Decoder = tf.matmul(self.Encoder, W) + b
self.Decoder = tf.identity(pre_Decoder)
pre_rec_cost = tf.multiply((self.input_R - self.Decoder), self.input_mask_R)
rec_cost = tf.square(self.l2_norm(pre_rec_cost))
pre_reg_cost = tf.square(self.l2_norm(W)) + tf.square(self.l2_norm(V))
reg_cost = self.lambda_value * 0.5 * pre_reg_cost
self.cost = rec_cost + reg_cost
if self.optimizer_method == "Adam":
optimizer = tf.compat.v1.train.AdamOptimizer(self.lr)
elif self.optimizer_method == "RMSProp":
optimizer = tf.compat.v1.train.RMSPropOptimizer(self.lr)
else:
raise ValueError("Optimizer Key ERROR")
if self.grad_clip:
gvs = optimizer.compute_gradients(self.cost)
capped_gvs = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gvs]
self.optimizer = optimizer.apply_gradients(capped_gvs, global_step=self.global_step)
else:
self.optimizer = optimizer.minimize(self.cost, global_step=self.global_step)2、Deep Autoencoders
DeepRec是由 NVIDIA 的 Oleisii Kuchaiev 和 Boris Ginsburg 创建的模型,如“ Training Deep Autoencoders for Collaborative Filtering ”中所示。该模型受上述 AutoRec 模型的启发,有几个重要区别:

网络要深得多。
该模型使用“缩放指数线性单位”(SELUs)。
辍学率很高。
作者在训练期间使用迭代输出重新馈送。
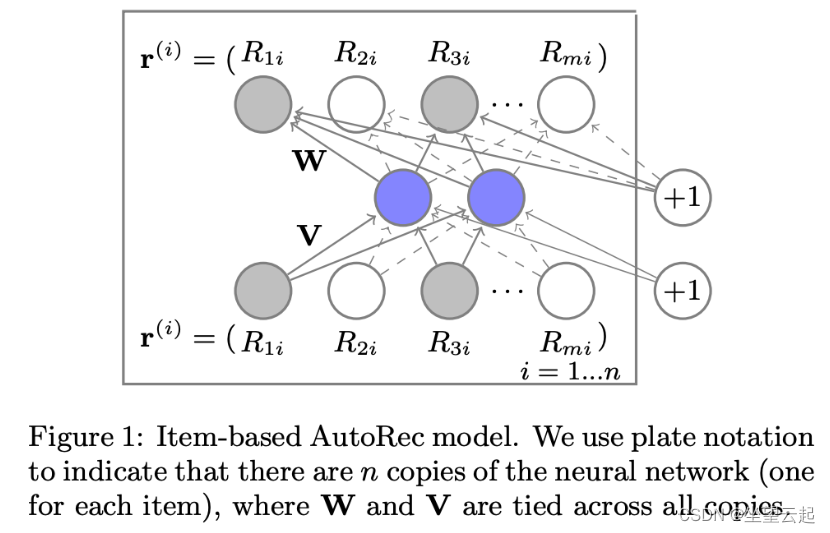
上图描绘了一个典型的 4 层自编码器网络。编码器有 2 层 e_1 和 e_2,而解码器有 2 层 d_1 和 d_2。它们在表示 z 上融合在一起。这些层表示为 f(W * x + b),其中 f 是一些非线性激活函数。如果激活函数的范围小于数据的范围,解码器的最后一层应该保持线性。作者发现隐藏层中的激活函数 f 包含非零负部分非常重要,并且在他们的大多数实验中都使用 SELU 单元。
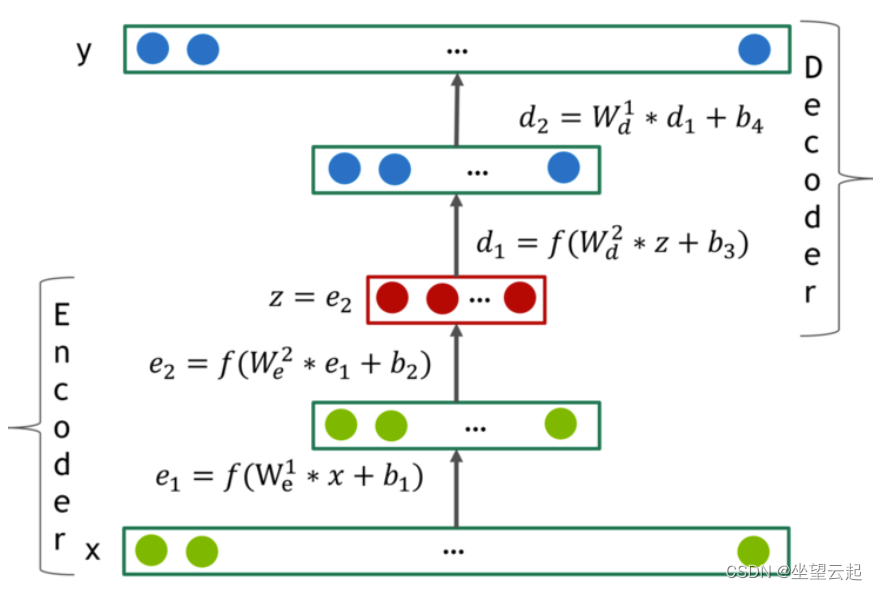
作者优化了Masked Mean Squared Error损失:
其中 是实际评分,
是重建评分,
是一个掩码函数,如果
不为 0,则
,否则
。
def Deep_AE_model(X, layers, activation, last_activation, dropout, regularizer_encode,
regularizer_decode, side_infor_size=0):
"""
Function to build the deep autoencoders for collaborative filtering
:param X: the given user-item interaction matrix
:param layers: list of layers (each element is the number of neurons per layer)
:param activation: choice of activation function for all dense layer except the last
:param last_activation: choice of activation function for the last dense layer
:param dropout: dropout rate
:param regularizer_encode: regularizer for the encoder
:param regularizer_decode: regularizer for the decoder
:param side_infor_size: size of the one-hot encoding vector for side information
:return: Keras model
"""
# Input
input_layer = x = Input(shape=(X.shape[1],), name='UserRating')
# Encoder Phase
k = int(len(layers) / 2)
i = 0
for l in layers[:k]:
x = Dense(l, activation=activation,
name='EncLayer{}'.format(i),
kernel_regularizer=regularizers.l2(regularizer_encode))(x)
i = i + 1
# Latent Space
x = Dense(layers[k], activation=activation,
name='LatentSpace',
kernel_regularizer=regularizers.l2(regularizer_encode))(x)
# Dropout
x = Dropout(rate=dropout)(x)
# Decoder Phase
for l in layers[k + 1:]:
i = i - 1
x = Dense(l, activation=activation,
name='DecLayer{}'.format(i),
kernel_regularizer=regularizers.l2(regularizer_decode))(x)
# Output
output_layer = Dense(X.shape[1] - side_infor_size, activation=last_activation, name='UserScorePred',
kernel_regularizer=regularizers.l2(regularizer_decode))(x)
# This model maps an input to its reconstruction
model = Model(input_layer, output_layer)
return model3、协作去噪自动编码器
Yao Wu、Christopher DuBois、Alice Zheng 和 Martin Ester 的“用于 Top-N 推荐系统的协作去噪自动编码器”是一个具有一个隐藏层的神经网络。与 AutoRec 和 DeepRec 相比,CDAE有以下区别:
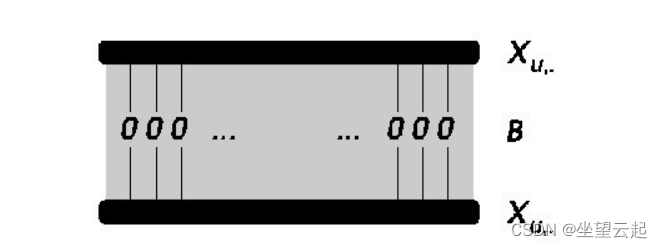
CDAE 的输入不是用户项目评分,而是部分观察到的隐式反馈 r(用户的项目偏好)。如果用户喜欢一部电影,则对应的条目值为 1,否则为 0。
与前两种用于评分预测的模型不同,CDAE 主要用于排名预测(也称为 Top-N 偏好推荐)。
class CDAE(BaseModel):
"""
Collaborative Denoising Autoencoder model class
"""
def __init__(self, model_conf, num_users, num_items, device):
"""
:param model_conf: model configuration
:param num_users: number of users
:param num_items: number of items
:param device: choice of device
"""
super(CDAE, self).__init__()
self.hidden_dim = model_conf.hidden_dim
self.act = model_conf.act
self.corruption_ratio = model_conf.corruption_ratio
self.num_users = num_users
self.num_items = num_items
self.device = device
self.user_embedding = nn.Embedding(self.num_users, self.hidden_dim)
self.encoder = nn.Linear(self.num_items, self.hidden_dim)
self.decoder = nn.Linear(self.hidden_dim, self.num_items)
self.to(self.device)
def forward(self, user_id, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
# normalize the rating matrix
user_degree = torch.norm(rating_matrix, 2, 1).view(-1, 1) # user, 1
item_degree = torch.norm(rating_matrix, 2, 0).view(1, -1) # 1, item
normalize = torch.sqrt(user_degree @ item_degree)
zero_mask = normalize == 0
normalize = torch.masked_fill(normalize, zero_mask.bool(), 1e-10)
normalized_rating_matrix = rating_matrix / normalize
# corrupt the rating matrix
normalized_rating_matrix = F.dropout(normalized_rating_matrix, self.corruption_ratio, training=self.training)
# build the collaborative denoising autoencoder
enc = self.encoder(normalized_rating_matrix) + self.user_embedding(user_id)
enc = apply_activation(self.act, enc)
dec = self.decoder(enc)
return torch.sigmoid(dec)4、多项式变分自动编码器
最有影响力的论文之一是来自 Netflix 的 Dawen Liang、Rahul Krishnan、Matthew Hoffman 和 Tony Jebara的“ Variational Autoencoders for Collaborative Filtering ”。它提出了一种 VAE 变体,用于使用隐式数据进行推荐。特别是,作者介绍了一种有原则的贝叶斯推理方法来估计模型参数,并显示出比常用似然函数更好的结果。
本文使用 U 索引所有用户,使用 I 索引所有项目。user-by-item 交互矩阵称为 X(维度为 U x I)。小写的 xᵤ 是一个词袋向量,其中包含来自用户 u 的每个项目的点击次数。对于隐式反馈,这个矩阵被二值化为只有 0 和 1。
class MultVAE(BaseModel):
"""
Variational Autoencoder with Multninomial Likelihood model class
"""
def __init__(self, model_conf, num_users, num_items, device):
"""
:param model_conf: model configuration
:param num_users: number of users
:param num_items: number of items
:param device: choice of device
"""
super(MultVAE, self).__init__()
self.num_users = num_users
self.num_items = num_items
self.enc_dims = [self.num_items] + model_conf.enc_dims
self.dec_dims = self.enc_dims[::-1]
self.dims = self.enc_dims + self.dec_dims[1:]
self.total_anneal_steps = model_conf.total_anneal_steps
self.anneal_cap = model_conf.anneal_cap
self.dropout = model_conf.dropout
self.eps = 1e-6
self.anneal = 0.
self.update_count = 0
self.device = device
self.encoder = nn.ModuleList()
for i, (d_in, d_out) in enumerate(zip(self.enc_dims[:-1], self.enc_dims[1:])):
if i == len(self.enc_dims[:-1]) - 1:
d_out *= 2
self.encoder.append(nn.Linear(d_in, d_out))
if i != len(self.enc_dims[:-1]) - 1:
self.encoder.append(nn.Tanh())
self.decoder = nn.ModuleList()
for i, (d_in, d_out) in enumerate(zip(self.dec_dims[:-1], self.dec_dims[1:])):
self.decoder.append(nn.Linear(d_in, d_out))
if i != len(self.dec_dims[:-1]) - 1:
self.decoder.append(nn.Tanh())
self.to(self.device)
def forward(self, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
# encoder
h = F.dropout(F.normalize(rating_matrix), p=self.dropout, training=self.training)
for layer in self.encoder:
h = layer(h)
# sample
mu_q = h[:, :self.enc_dims[-1]]
logvar_q = h[:, self.enc_dims[-1]:] # log sigmod^2 batch x 200
std_q = torch.exp(0.5 * logvar_q) # sigmod batch x 200
# reparametrization trick
epsilon = torch.zeros_like(std_q).normal_(mean=0, std=0.01)
sampled_z = mu_q + self.training * epsilon * std_q
# decoder
output = sampled_z
for layer in self.decoder:
output = layer(output)
if self.training:
kl_loss = ((0.5 * (-logvar_q + torch.exp(logvar_q) + torch.pow(mu_q, 2) - 1)).sum(1)).mean()
return output, kl_loss
else:
return output5、序列变分自动编码器
在“用于协同过滤的序列变分自动编码器”中,Noveen Sachdeva、Giuseppe Manco、Ettore Ritacco 和 Vikram Pudi 通过探索过去偏好历史中存在的丰富信息,提出了对 MultVAE 的扩展。他们引入了一个循环版本的 MultVAE,而不是传递整个历史的一个子集而不考虑时间依赖性,而是通过循环神经网络传递消费序列子集。他们表明,处理时间信息对于提高 VAE 的准确性至关重要。
class SVAE(nn.Module):
"""
Function to build the SVAE model
"""
def __init__(self, hyper_params):
super(Model, self).__init__()
self.hyper_params = hyper_params
self.encoder = Encoder(hyper_params)
self.decoder = Decoder(hyper_params)
self.item_embed = nn.Embedding(hyper_params['total_items'], hyper_params['item_embed_size'])
self.gru = nn.GRU(
hyper_params['item_embed_size'], hyper_params['rnn_size'],
batch_first=True, num_layers=1
)
self.linear1 = nn.Linear(hyper_params['hidden_size'], 2 * hyper_params['latent_size'])
nn.init.xavier_normal(self.linear1.weight)
self.tanh = nn.Tanh()
def sample_latent(self, h_enc):
"""
Return the latent normal sample z ~ N(mu, sigma^2)
"""
temp_out = self.linear1(h_enc)
mu = temp_out[:, :self.hyper_params['latent_size']]
log_sigma = temp_out[:, self.hyper_params['latent_size']:]
sigma = torch.exp(log_sigma)
std_z = torch.from_numpy(np.random.normal(0, 1, size=sigma.size())).float()
self.z_mean = mu
self.z_log_sigma = log_sigma
return mu + sigma * Variable(std_z, requires_grad=False) # Reparameterization trick
def forward(self, x):
"""
Function to do a forward pass
:param x: the input
"""
in_shape = x.shape # [bsz x seq_len] = [1 x seq_len]
x = x.view(-1) # [seq_len]
x = self.item_embed(x) # [seq_len x embed_size]
x = x.view(in_shape[0], in_shape[1], -1) # [1 x seq_len x embed_size]
rnn_out, _ = self.gru(x) # [1 x seq_len x rnn_size]
rnn_out = rnn_out.view(in_shape[0] * in_shape[1], -1) # [seq_len x rnn_size]
enc_out = self.encoder(rnn_out) # [seq_len x hidden_size]
sampled_z = self.sample_latent(enc_out) # [seq_len x latent_size]
dec_out = self.decoder(sampled_z) # [seq_len x total_items]
dec_out = dec_out.view(in_shape[0], in_shape[1], -1) # [1 x seq_len x total_items]
return dec_out, self.z_mean, self.z_log_sigma6、Shallow Autoencoders
Harald Steck 的“ Embarrassingly Shallow Autoencoders for Sparse Data ”是一个引人入胜的文章,我想将其引入本次讨论。这里的动机是,根据他的文献综述,与只有一个、两个或三个隐藏层的“深度”模型相比,具有大量隐藏层的深度模型在协同过滤中的排名准确性通常 没有 显着提高层。这与 NLP 或计算机视觉等其他领域形成鲜明对比。
class ESAE(BaseModel):
"""
Embarrassingly Shallow Autoencoders model class
"""
def forward(self, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
G = rating_matrix.transpose(0, 1) @ rating_matrix
diag = list(range(G.shape[0]))
G[diag, diag] += self.reg
P = G.inverse()
# B = P * (X^T * X − diagMat(γ))
self.enc_w = P / -torch.diag(P)
min_dim = min(*self.enc_w.shape)
self.enc_w[range(min_dim), range(min_dim)] = 0
# Calculate the output matrix for prediction
output = rating_matrix @ self.enc_w
return output三、模型评估
数据集是MovieLens 1M,类似于我之前使用Matrix Factorization和Multilayer Perceptron所做的两个实验。目标是预测用户对电影的评分,评分在 1 到 5 之间。
对于 AutoRec 和 DeepRec 模型,评估指标是评分预测(回归)设置中的掩蔽均方根误差 (RMSE)。
对于 CDAE、MultVAE、SVAE 和 ESAE 模型,评估指标是排名预测(分类)设置中的Precision、Recall和Normalized Discounted Cumulative Gain (NDCG)。如上节所述,这些模型使用隐式反馈数据,其中评级被二值化为 0(小于等于 3)和 1(大于 3)。