8.1.推荐系统(协同过滤算法)
1)题目:
在本次练习中,你将实现协同过滤算法并将它运用在电影评分的数据集上,最后根据新用户的评分来给新用户推荐10部电影。这个电影评分数据集由1到5的等级组成。数据集有
个用户和
部电影。在计算完协同过滤的代价函数以及梯度后,将使用牛顿共轭梯度法求得参数。
数据集中,Y是一个(1682, 943)的矩阵,存储了从1到5的评分,矩阵R为二值指标矩阵,其中如果用户j对电影i进行评级,则
,否则
。协同过滤的目的就是预测用户尚未评分的电影的评分,即
的条目。这样我们就可以向用户推荐预测评分最高的电影。
X是电影的特征矩阵,Theta是用户的特征矩阵,X的第i行对应
,表示第i部电影的特征向量(即描述第i部电影内容的特征量),Theta的第j行对应
,表示第j个用户的特征向量(即第j个用户对不同类型电影的偏好)。这里
和
都是100维的向量,因此X的维数是(1682100),Theta的维数是(943100)。
数据集链接: https://pan.baidu.com/s/1cEgQIvehUcLxZ0WVhxcPuQ 提取码: xejn
2)知识点概括:
-
推荐系统(recommender systems)
表示用户数量
表示电影数量
表示用户j对电影i打分了
表示用户j对电影i给出的评分
表示用户j的参数向量(n维向量)
表示电影i的特征向量(n维向量) -
基于内容的推荐算法(content based recommendations)
假设我们已经有了电影的特征向量 (即描述电影内容的特征量),还需要得到每个用户的参数向量 (即每个用户对不同类型电影的偏好),即对每个用户应用了一个不同的线性回归,然后就可以得到预测的评分为 。
优化的目标函数为:
再用梯度下降等方法求解。

-
基于用户的推荐算法
假设我们已经有了每个用户的参数向量 (即每个用户对不同类型电影的偏好),用这个来得到电影的特征向量 (即描述电影内容的特征量),同样对每个用户应用了一个不同的线性回归,然后就可以得到预测的评分为 。
优化的目标函数为:
-
协同过滤(collaborative filtering)
用用户的参数量来学习电影的特征量,再用电影的特征量来学习用户的参数量,如此迭代下去,得到一个最优解。

两个合起来优化目标就变成了
-
计算步骤:
1、随机初始化
2、最小化,使用梯度下降法或其他高等优化算法
3、对用户有参数 ,电影有特征 ,预测的评分矩阵即为 -
协同过滤的矩阵表示(也叫低秩矩阵分解low rank matrix factorization)

-
如何寻找和电影 相关的电影 呢?
衡量两个电影的相关度,即两个电影的特征向量的距离 ,如果想要找到5部与电影i最相似的电影,只需找到 中最小的五个即可。 -
均值标准化,即 可以避免出现因为某个用户对所有电影没有评分而导致该用户所有预测的评分都为零的情况。再在预测完之后加回这个均值 。相当于对于没有评分的用户预测的评分为这个所有用户评分的均值。

3)大致步骤:
- 数据导入及可视化。计算第一部电影《玩具总动员》的平均得分,然后可视化评分矩阵。
- 协同过滤的代价函数。先导入训练好的参数(电影的特征和用户的特征),然后截取一小部分数据集用于验证写好的代价函数,注意这里传入代价函数的参数包含两部分(电影的参数和用户的参数),而且是一个向量形式,因为后面要使用fmin_ncg函数,和之前在神经网络的处理类似,需要展开和reshape,最后得到代价函数的值为22.22。
- 梯度函数与梯度检查。根据公式求出梯度,注意这里的参数是x和theta两个矩阵展开,因此梯度展开后也应该是对每个参数求导,所以最后出来的维数应该和参数一样;关于梯度检验给出的参考代码里又重新随机化一个很小的测试数据,我这里直接用之前取的小样本数据来检查梯度了,效果一样,免得麻烦了,梯度检查的具体方法和之前神经网络时的梯度检查原理一样,也是用斜率来逼近,最后求出来两个梯度的差不超过1e-9。
- 正则化的代价函数和梯度函数。修改前面的两个函数,加上正则化的部分,取lmbda=1.5可以得到修改后的代价函数为31.34,同样进行梯度检验。
- 增加新用户评分。首先读入电影列表,注意这里有一些法文电影名称,运行的时候会出现编码错误,对于这个问题还不是很熟悉,所以就修改了源文件把法文写为英文再进行读入;然后再增加自己的评分列,打印出评分以及对应的电影。
- 训练模型。在原来的评分矩阵的基础上加上我的评分,再进行标准化,这里注意对未评分的电影不需要进行标准化,然后再随机初始化参数,用牛顿共轭梯度算法训练得到参数。
- 最后得到预测的评分矩阵,并基于我的评分给我推荐10部电影。
4)关于Python:
- plt.colorbar( )函数在加颜色渐变条。
- 当两个矩阵形状相同时,即维数一样,可以用A[np.where(B的条件)]来筛选满足B的条件的位置的A的值,这样计算比较方便。
- strip( ) 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
- join( )返回通过指定字符连接序列中元素后生成的新字符串,例如str = “-”;seq = (“a”, “b”, “c”); print str.join( seq )为a-b-c,’ ‘.join([‘a’,‘b’]) 会得到a b
- [::-1]用在数组后可以让数组倒序。
5)代码与结果:
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as scio
import scipy.optimize as opt
'''============================part1 数据导入及可视化========================='''
data = scio.loadmat('ex8_movies.mat')
y = data['Y']
r = data['R']
#第一部电影《玩具总动员》的平均得分
print('Average rating for movie 1 (Toy Story): %f / 5\n\n'%np.mean(y[0, np.where(r[0, :]==1)]))
#可视化评分矩阵
#MATLAB中imagesc(A)将矩阵A中的元素数值按大小转化为不同颜色,并在坐标轴对应位置处以这种颜色染色
plt.figure(figsize=(5,9))
plt.imshow(y)
plt.colorbar() #加颜色条
plt.ylabel('Movies')
plt.xlabel('Users')
'''============================part2 协同过滤的代价函数=============================='''
#导入训练好的参数
parameters = scio.loadmat('ex8_movieParams.mat')
x = parameters['X'] #电影的特征矩阵
theta = parameters['Theta'] #用户的特征矩阵
num_users = parameters['num_users']
num_movies = parameters['num_movies']
num_features = parameters['num_features']
#减小数据集用来更快的测试代价函数的正确性
num_users = 4
num_movies = 5
num_features = 3
X = x[0:num_movies, 0:num_features]
Theta = theta[0:num_users, 0:num_features]
Y = y[0:num_movies, 0:num_users]
R = r[0:num_movies, 0:num_users]
'''代价函数'''
#这里的params包含x和theta两个矩阵,它是一维的,因为要使用fmin_ncg函数的原因需要展开
def cofiCostFunc(params, y, r, num_users, num_movies, num_features, lmd=0):
#reshape得到x和theta矩阵
x = np.reshape(params[0:num_movies*num_features], (num_movies,num_features))
theta = np.reshape(params[num_movies*num_features:], (num_users,num_features))
#代价函数
J = np.sum(np.square((x@theta.T-y))[np.where(r==1)])/2
reg = (lmd/2) * (np.sum(x*x) + np.sum(theta*theta))
return J+reg
#展开参数
params = np.r_[X.flatten(), Theta.flatten()]
#测试代价函数是否正确
J = cofiCostFunc(params, Y, R, num_users, num_movies, num_features, lmd=0)
print('Cost at loaded parameters: %f \n(this value should be about 22.22)\n'% J)
'''============================part3 梯度函数与梯度检验=============================='''
'''梯度函数'''
def cofiGradFunc(params, y, r, num_users, num_movies, num_features, lmd=0):
#reshape得到x和theta矩阵
x = np.reshape(params[0:num_movies*num_features], (num_movies,num_features))
theta = np.reshape(params[num_movies*num_features:], (num_users,num_features))
#梯度函数
x_grad = ((x@theta.T-y)*r)@theta + lmd*x #shape和x一样,为(num_movies,num_features)
theta_grad = ((x@theta.T-y)*r).T@x + lmd*theta #shape和theta一样,为(num_users,num_features)
grad = np.r_[x_grad.flatten(), theta_grad.flatten()]
return grad
cofiGradFunc(params, Y, R, num_users, num_movies, num_features, lmd=0).shape #(27,)
'''梯度检查'''
#数值梯度
def computeNumericalGradient(J, params):
numgrad = np.zeros(params.shape)
perturb = np.zeros(params.shape)
e =1e-4
for p in range(len(params)):
perturb[p] = e
loss1 = J(params - perturb)
loss2 = J(params + perturb)
numgrad[p] = (loss2 - loss1) / (2*e)
perturb[p] = 0
return numgrad
#重写一下代价函数,以免重复写其他参数(Y, R, num_users, num_movies, num_features, lmd=0)
def cost_func(t):
return cofiCostFunc(t, Y, R, num_users, num_movies, num_features, lmd=0)
#计算数值梯度与理论梯度之间的差值
numgrad = computeNumericalGradient(cost_func, params)
grad = cofiGradFunc(params, Y, R, num_users, num_movies, num_features, lmd=0)
diff = np.linalg.norm(numgrad-grad) / np.linalg.norm(numgrad+grad)
print('If your cost function implementation is correct, then \n'
'the relative difference will be small (less than 1e-9). \n'
'\nRelative Difference: %g\n'% diff)
'''============================part4 正则化的代价函数和梯度函数========================'''
#修改前面的两个函数,加上正则化的部分
J = cofiCostFunc(params, Y, R, num_users, num_movies, num_features, lmd=1.5)
print('Cost at loaded parameters (lambda = 1.5): %f \n(this value should be about 31.34)\n'% J)
#正则化之后的梯度检验
def cost_func(t):
return cofiCostFunc(t, Y, R, num_users, num_movies, num_features, lmd=1.5)
#计算数值梯度与理论梯度之间的差值
numgrad = computeNumericalGradient(cost_func, params)
grad = cofiGradFunc(params, Y, R, num_users, num_movies, num_features, lmd=1.5)
diff = np.linalg.norm(numgrad-grad) / np.linalg.norm(numgrad+grad)
print('If your cost function implementation is correct, then \n'
'the relative difference will be small (less than 1e-9). \n'
'\nRelative Difference: %g\n'% diff)
'''============================part5 新用户增加评分=============================='''
#电影名称的文件里有一些电影好像是法文电影,所以编码上有些问题,会出现UnicodeDecodeError,所以进行以下步骤
#检查文件中哪些字符的编码转不过来
f = open('movie_ids.txt',"rb")#二进制格式读文件
lines = f.readlines()
for line in lines:
try:
line.decode('utf8') #解码
except:
#打印编码有问题的行
print(str(line))
f.close
#修改那些好像是法文的字符,文件另存为movie_ids_mod.txt,再进行电影列表读入
t = open('movie_ids_mod.txt')
movie_list = []
for line in t:
#先用strip去掉开头结尾的空格,然后用split对空格切片,选取从编号之后的所有字符串,再用jion空格连接成一个字符串
movie_list.append(' '.join(line.strip().split(' ')[1:]))
t.close
len(movie_list) #得到了长度为1682的电影列表
#初始化我的评分
my_ratings = np.zeros((1682, 1))
#添加电影评分,注意这里的索引比作业中少1,从0开始的
my_ratings[0] = 4
my_ratings[97] = 2
my_ratings[6] = 3
my_ratings[11] = 5
my_ratings[53] = 4
my_ratings[63] = 5
my_ratings[65] = 3
my_ratings[68] = 5
my_ratings[182] = 4
my_ratings[225] = 5
my_ratings[354] = 5
#查看评分以及对应的电影
print('\n\nNew user ratings:\n')
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print('Rated %d for %s\n' %(my_ratings[i], movie_list[i]))
'''============================part6 训练协同过滤算法=============================='''
#y和r是part1中的矩阵,在此基础上加上my_ratings构成新的评分矩阵
Y = np.c_[my_ratings, y] #(1682, 944)
R = np.c_[(my_ratings != 0), r] #(1682, 944)
'''标准化'''
def normalizeRatings(y, r):
#为了下面可以直接矩阵相减,将(1682,)reshape成(1682,1)
mu = (np.sum(y, axis=1)/np.sum(r, axis=1)).reshape((len(y),1))
y_norm = (y - mu)*r #未评分的依然为0
return y_norm, mu
#标准化
Ynorm, Ymean = normalizeRatings(Y, R)
num_users = Y.shape[1]
num_movies = Y.shape[0]
num_features = 10
#随机初始化参数
X = np.random.randn(num_movies, num_features)
Theta = np.random.randn(num_users, num_features)
initial_parameters = np.r_[X.flatten(), Theta.flatten()]
#训练模型
lmd = 10
#params = opt.fmin_ncg(f=cofiCostFunc, fprime=cofiGradFunc, x0=initial_parameters, args=(Y, R, num_users, num_movies, num_features, lmd), maxiter=100)
#上面的方法不知道为什么特别慢,跑不出来,但其实应该是一样的啊,不解~
res = opt.minimize(fun=cofiCostFunc,
x0=initial_parameters,
args=(Y, R, num_users, num_movies, num_features, lmd),
method='TNC',
jac=cofiGradFunc,
options={'maxiter': 100})
#得到模型参数
params = res.x
X = np.reshape(params[0:num_movies*num_features], (num_movies,num_features))
Theta = np.reshape(params[num_movies*num_features:], (num_users,num_features))
'''============================part7 预测评分并推荐=============================='''
#预测的评分矩阵
p = X @ Theta.T
#我的预测评分
my_predictions = (p[:,0].reshape(len(p),1) + Ymean).flatten() #为了矩阵相加,后面展开是为了打印方便
#为我推荐的10部电影
ix = np.argsort(my_predictions)[::-1] #逆序,由大到小得到索引
print('\nTop recommendations for you:\n')
for i in range(10):
j = ix[i]
print('Predicting rating %.1f for movie %s\n' %(my_predictions[j], movie_list[j]))
#我原来的评分
print('\nOriginal ratings provided:\n')
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print('Rated %d for %s\n' %(my_ratings[i], movie_list[i]))
第一部电影《玩具总动员》的平均得分
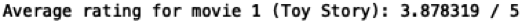
评分矩阵可视化结果

不带正则项的代价函数验证结果

不带正则化的梯度函数检查结果

正则化之后的代价函数和梯度检验

增加自己的评分列

最后的推荐结果,为我推荐的10部电影以及预测的评分(注意这里可能因为初始化的随机性导致推荐的结果和评分不一样)

