目录
1. 基于内容的推荐算法(Content-based recommendations)
3. 基于梯度下降的协同过滤算法(Collaborative filtering)
4. 低秩矩阵分解(Low rank matrix factorization)
学习完吴恩达老师机器学习课程的推荐系统,简单的做个笔记。文中部分描述属于个人消化后的理解,仅供参考。
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~
0. 前言
在推荐系统中,主要有两种方法,基于内容的推荐算法和协同过滤算法,此文章采用电影推荐作为例子,初始作如下定义:
--- 用户数量
--- 电影数量
--- 用户
对电影
进行了评价
--- 用户
--- 用户
--- 拟合用户
--- 电影的特征数量
推荐系统的目标,就是通过用户已经评价的电影和电影的特征,预测用户未评价的电影的评分,由此进行推荐。
1. 基于内容的推荐算法(Content-based recommendations)
给出如下例子(图源:吴恩达机器学习),基于内容的推荐算法已知每部电影的特征值:
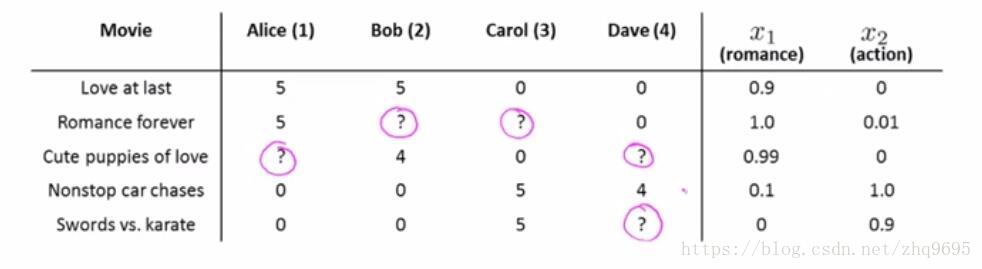
对于用户 ,每一部的电影的特征为
,用户的评分为
,用数据集
,进行拟合,得到参数
,对于需要预测的电影
,由
得到评分,可根据预测的评分进行推荐。
单个用户的代价函数为:
消去 后,多个用户的代价函数为:
梯度下降为:
注:此时的 和
都增加了偏置
和
。
2. 计算电影特征
要求已知用户的参数 ,根据每个用户对电影的评价
,拟合出电影
的特征值。
单部电影的代价函数表示为:
多部电影的代价函数表示为:
所以,结合基于内容的推荐算法,我们可首先假设 ,然后拟合
,再优化
,
3. 基于梯度下降的协同过滤算法(Collaborative filtering)
基于内容的推荐算法通过 求解
,计算电影特征通过
求解
,如此往复计算复杂度大,可将两个代价函数合并:
通过初始化 和
为较小的值,通过梯度下降降低代价函数:
注:此时的 和
都不需要偏置
和
。
4. 低秩矩阵分解(Low rank matrix factorization)
如果对预测评分过程向量化,将评分表示为矩阵 ,每一行为电影,每一列为用户,则
,
,
, 则有
5. 应用到推荐
根据电影 推荐相似的电影
给用户,可取使得
距离最小的
。
若一个用户对任何一部电影都未评分,则根据各个电影均值,进行推荐。
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~