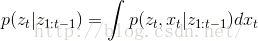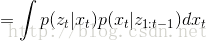1. 贝叶斯概率公式(后验概率):
p(x|y)=p(y|x)p(x)p(y)=ηp(y|x)p(x)
当条件概率涉及到的变量比较多,上式分母就会变得比较复杂,为表示方便这里定义 ηη 为归一化参数。
相似的,我们可以考虑 p(x|y,z)p(x|y,z) 的条件概率,这里可以看成在 zz 发生的条件下,将概率 p(x|y)p(x|y) 进行贝叶斯公式展开,代入二元贝叶斯公式得到:
p(x|y,z)=p(y|x,z)p(x|z)p(y|z)
2. 定义可信度:
bel(xt)=p(xt|z1:t,u1:t)
3. 根据贝叶斯概率公式将上式展开(参考1.中三个变量贝叶斯公式推导)为:
bel(xt)=p(xt|z1:t,u1:t)=ηp(zt|xt,z1:t−1,u1:t)(1)p(xt|z1:t−1,u1:t)(2)
4. 根据马尔科夫假设进行简化
在probability robotics 这本书里,马尔科夫假设是全书的基本假设,所有的公式都是在这个假设基础行推导而来的,马尔科夫假设核心思想是:已知当前时刻的状态 xtxt ,不会影响过去和将来的状态。
对于3.公式(1)部分, xtxt 可以根据之前 t−1t−1 个时刻的测量值 z1:t−1z1:t−1 和t个时刻控制输入 u1:tu1:t 得到(参考1. 中状态转移图)。所以(1)部分简化为:
p(zt|xt,z1:t−1,u1:t)=p(zt|xt)
对于公式(2)部分,在连续域进行展开:
p(xt|z1:t−1,u1:t)=∫xt−1p(xt|xt−1,z1:t−1,u1:t)p(xt−1|z1:t−1,u1:t)dxt−1
这一部分可以类比以下公式(B对应于上式
xt−1xt−1
):
p(A)=∫Bp(A|B)p(B)dB(连续域)∑Bp(A|B)p(B)(离散域)p(A)=∫Bp(A|B)p(B)dB(连续域)∑Bp(A|B)p(B)(离散域)
在马尔科夫假设前提下,已知将来的状态 utut 对估计 xt−1xt−1 没用提供任何信息,所以:
p(xt|z1:t−1,u1:t)=∫xt−1p(xt|xt−1,z1:t−1,u1:t)p(xt−1|z1:t−1,u1:t)dxt−1=∫xt−1p(xt|xt−1,z1:t−1,u1:t)p(xt−1|z1:t−1,u1:t−1)dxt−1=∫xt−1p(xt|xt−1,ut)bel(xt−1)dxt−1p(xt|z1:t−1,u1:t)=∫xt−1p(xt|xt−1,z1:t−1,u1:t)p(xt−1|z1:t−1,u1:t)dxt−1=∫xt−1p(xt|xt−1,z1:t−1,u1:t)p(xt−1|z1:t−1,u1:t−1)dxt−1=∫xt−1p(xt|xt−1,ut)bel(xt−1)dxt−1
5. 根据1-4推导,得到迭代的贝叶斯滤波公式:
bel(xt)=ηp(zt|xt)∫x(t−1)p(xt|xt−1,ut)bel(xt−1)dt−1bel(xt)=ηp(zt|xt)∫x(t−1)p(xt|xt−1,ut)bel(xt−1)dt−1
贝叶斯滤波的更新过程可以分为两个过程:
预测过程(由上一时刻状态 xt−1xt−1 和当前时刻控制量 utut 预测当前状态 xtxt ):
bel(xt)¯¯¯¯¯¯¯¯¯¯¯¯¯¯=∫x(t−1)p(xt|xt−1,ut)bel(xt−1)dt−1bel(xt)¯=∫x(t−1)p(xt|xt−1,ut)bel(xt−1)dt−1
校准过程(在已知当前状态 xtxt 的条件下,计算当前测量值 ztzt 的可信度):
bel(xt)=ηp(zt|xt)bel(xt−1)¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯bel(xt)=ηp(zt|xt)bel(xt−1)¯
贝叶斯滤波设计了以概率方式进行状态估计的框架,但没有规定状态变量需要服从哪种分布,在实际应用中,我们可以根据传感器和机器人实际参数进行相关分布律假设。
滤波过程一般分为两个步骤:预测和更新。贝叶斯滤波器当然也不例外。
预测过程中,不使用当前时刻的测量值,因此预测过程中的后验概率为:
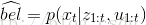
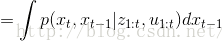
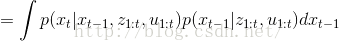
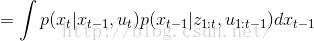
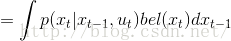
第一步到第三步的推导为全概率公式;第三步到第四步是由系统的状态方程可知,系统t时刻的状态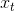
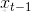
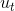
更新的过程中,需要用第t时刻(当前时刻)的测量值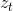
具体推导过程如下:
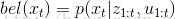
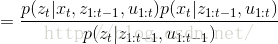
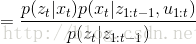
即可得到: 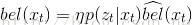

这里的