贝叶斯定理及其在机器学习中的应用——朴素贝叶斯方法
一、关于贝叶斯定理
每一种定理的提出基本都是划时代的,定理的属性代表着它是受逻辑限制的证明为真的陈述,与许多定理一样,可以广泛应用于多种领域,正如热力学中熵的概念,香农则将其迁移到了信息论中,提出了信息论的概念,也有助于后来机器学习决策树中Gini系数的应用。德摩根定理则也有其形式逻辑表示方式,集合论表示方式与概率论表示方式,应用广泛。
而贝叶斯定理是关于随机事件A和B的条件概率(或边缘概率)的一则定理。其中P(A|B)是在B发生的情况下A发生的可能性。
1.定理的提出
早在18世纪,英国数学家托马斯·贝叶斯Thomas Bayes曾提出计算条件概率的公式用来解决下面这类问题:假设x1,x2,…,xn彼此相互独立且构成一个完全事件,已知它们的概率P(xi)(i=1,2…n),现观察到某事件Y与x1,x2,…,xn相伴随机出现,且已知条件概率P(y|xi),求P(xi|y)。
2.研究意义
人们根据不确定性信息作出推理和决策需要对各种结论的概率作出估计,这类推理称为概率推理。概率推理是概率学和逻辑学,同样也是心理学的研究对象,它们各自有着不同的研究角度。概率学和逻辑学研究的是客观概率经数学方法推算的公式或规则;而心理学研究人们主观概率估计的认知过程的规律。贝叶斯推理的问题是条件概率推理问题,关于该定理的探讨对揭示人们对概率信息的认知加工过程与规律、指导人们进行有效的学习和判断决策具有重要的理论意义和实践意义。
3.贝叶斯定理的兴盛
尽管贝叶斯定理的思想出现在18世纪,但真正大规模使用发生在计算机出现之后。因为这个定理在大规模的数据计算推理体现出的效果被放大,它在很多互联网应用领域中都有所应用,如自然语言处理、机器学习、推荐系统、图像识别、博弈论,等等。
二、贝叶斯定理在机器学习中的应用
1.朴素贝叶斯算法推导
在机器学习的有监督学习中,我们应用贝叶斯定理思想的一种体现即为朴素贝叶斯方法。朴素贝叶斯算法通过预测指定样本属于特定类别的概率来预测该样本的所属类别,即: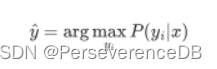
而P(yi|x)可以写成: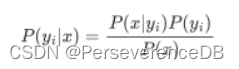
其中x=(x1,x2,…,xn)为样本对应的特征向量,P(x)为样本的先验概率。对于特定样本x和任意类别yi,P(x)的取值均相同,并不会影响P(yi|x)取值的相对大小,因此在计算中可以被忽略。"朴素"的假设了特征x1,x2,…xn相互独立,可以得到:
其中 ,P(x1|yi),…,P(xn|yi)以及P(yi)可以通过训练样本统计得到。
此时,若要将其应用于机器学习中,我们还需要明确我们的目标函数。因为是有监督机器学习,所以已知哪条样本属于哪个类别。则我们的目标函数: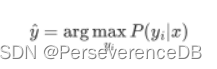
即为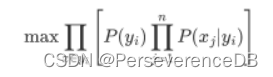
此时,已经得到我们的目标函数,但它还有一个缺陷,P的取值范围在0~1之间,连乘易造成数值下溢的现象,数据看起来会较为不友好,同时因为计算机处理的机制,易将产生数值下溢的数据给记为0,因此我们继续对目标函数进行处理,取log。
根据log(xy)=log(x)+log(y),原目标函数变为: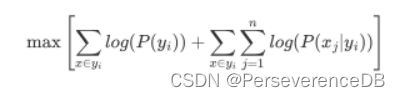
此时我们预测x属于哪个类别时,只需要预先计算P(yi)和P(xj|yi),然后带入公式得出相应目标函数值,因为P取值在0~1之间,而且函数logx单调递增,此时对应目标函数值越大的类别对应P也越大,则将目标函数值最大的类别即判别为该样本所属类别。而对于不同的朴素贝叶斯分类器,其P(xj|yi)是有区别的,因为它们对于P(xj|yi)分布的假设不同。
2.朴素贝叶斯算法的优缺点
关于朴素贝叶斯算法的优缺点,尽管它假设的n个特征相互独立过于简化,但naive Bayes分类器仍然可以在在许多实际情况下都能很好地工作,比如常见的文档分类和垃圾邮件过滤。它需要一些训练数据来估计必要的参数。
与其他更复杂的方法相比,朴素贝叶斯学习器和分类器执行速度非常快。类别条件特征分布的分解意味着每个分布都可以独立地作为
一维分布进行估计。
另一方面,尽管朴素贝叶斯被认为是一个不错的分类器,但它却是一个糟糕的估计器,因为目标函数经过我们处理后得出的概率往往不是真实概率,所以predict_proba输出的概率并太靠谱。
朴素贝叶斯学习器有很多种模型,比如高斯朴素贝叶斯,多项式朴素贝叶斯和伯努利朴素贝叶斯等。这里我们以多项式朴素贝叶斯及其在文本分类应用中举例说明。
3.朴素贝叶斯算法优化应用——多项式朴素贝叶斯
多项式朴素贝叶斯,通过假设P(x|yi)概率分布为多项式分布,换句话说就是,假定各个特征x1,x2,…,xn在各个类别yi下是服从多项式分布的,即: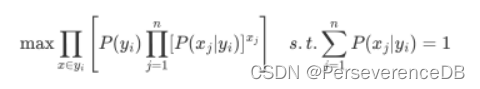
关于该模型参数的求解,此处使用的是最大似然估计的方法,即对参数P(xj|yi)求偏导,然后将导数设为0,反推出表达式。
因此其实这里问题会转化为多项式分布的最大似然估计问题: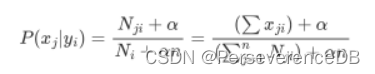
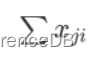
:将属于yi类别的样本第j个维度的特征值加和。
α:平滑先验α≥0 ,让学习样本中不存在的特征也占一定的比例,防止在进一步的计算中出现零概率。
α=1时为拉普拉斯(Laplace)平滑,α<1时为李德斯通(Lidstone)平滑。
4.多项式朴素贝叶斯在文本分类中应用举例
关于其在文本分类中的举例。多项式分布数据的朴素贝叶斯算法,是文本分类中使用的两种经典的朴素贝叶斯变体之一,其中数据通常表示为单词计数向量,虽然tf−idf向量在实践中也很有效。
文本分类任务中,特征数量n是词典大小,则对于单词j属于类别i的文章的概率表达式我们可以得出为:
然后我们可以推出在未来预测单条样本类别时的概率目标函数: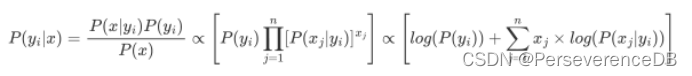
之前关于朴素贝叶斯算法说明时已经得出,P越大,则logP也越大,因此此时带入数据后,使得P(yi|x)最大的文章类别,即是我们的预测类别。
关于贝叶斯的应用范围非常广泛,涉及领域也很多,欢迎大家讨论!