用于改进步态识别的拉格朗日运动分析和视角嵌入
paper题目:Lagrange Motion Analysis and View Embeddings for Improved Gait Recognition
paper是北航发表在CVPR 2022上的工作
paper链接:地址
Abstract
步态被认为是人体的行走模式,包括形状和运动线索。然而,主流的基于外观的步态识别方法依赖于轮廓的形状。目前尚不清楚运动是否可以在步态序列建模中明确表示。在本文中,我们使用拉格朗日方程分析了人类步行,并得出结论,时间维度中的二阶信息对于识别是必要的。我们根据得出的结论设计了二阶运动提取模块。此外,通过分析当前的交叉视图任务方法没有明确考虑视图本身的问题,设计了一个轻量级的视角嵌入模块。在 CASIA-B 和 OU-MVLP 数据集上的实验表明了我们方法的有效性,并且对提取的运动进行了一些可视化以显示我们的运动提取模块的可解释性。
1.Introduction
步态是一种生物特征,可呈现行人的步行模式以进行身份识别,并且比其他生物特征(例如面部、虹膜或指纹)具有优势,因为它可以在没有触摸和远距离的情况下进行识别。尽管已经研究了多年,但在步态识别方面仍然存在一些挑战。例如,携带条件 [4, 15, 16, 42, 46]、外套穿着和视角差异 [41, 45] 等变化可能会导致步态外观发生变化,从而难以区分行人。
现有的基于外观的步态识别方法在很大程度上依赖于剪影的视觉外观。
然而,当视角接近时,两个不同的人之间的外观差异可能比从两个不同的角度看同一个人的差异要小。
解决上述问题的一种常见方法是学习视角不变或稳健的特征[6,10,20,21,35,37,38,43]。然而,这些工作侧重于如何提取外观信息以及空间或时间特征的融合。视角的检测或估计被忽视,很少有模型明确利用视角。换句话说,这些方法的视角鲁棒性完全基于数据的覆盖范围,这是一个众所周知的不适定问题。
即使视点接近,外观信息仍然不是很可靠。如图1所示,仅从身体形状上很难区分三个样本的身份。这种现象解释了为什么纯粹基于外观的方法,如步态能量图像(GEI)[34]不能达到理想的性能。类似的情况也会出现在最先进的Gaitset方法[6]中,该方法也没有使用时间信息。

图1. 来自CASIA-B数据集的三个样本,其中A和B分别表示ID39和ID77。A-1和A-2是选自不同序列的A的两个样本。可以发现,在视觉上很难找到A和B之间的区别。甚至在某些帧上,A-2与B-1比A-1更相似。
我们认为,图1中所示问题的最终解决方案是步态运动。最近,一些利用时间特征的方法被提出[7, 20, 20, 28, 39]。尽管这些模型在识别精度上显示出较强的优势,但它们没有讨论步态中的运动信息,以至于可能会遗漏一些判别性的生物信息。
在本文中,通过数学建模分析,我们认为只用一阶时间信息是很难区分人的。为了有效地对行人的行走模式进行建模,二阶运动是必要的。为了验证这一观点,我们提出了一种新型的运动辅助步态识别方法。为了进一步减少视角差异的负面影响,我们还引入了一种视角感知的嵌入方法。它产生了一个多分支框架,该框架结合了剪影序列的视角、外观和内在运动。实验结果表明,所提出的模型可以有效地缩小由视角差异引起的类内距离。
本文的主要贡献可以归纳为以下四个方面。
-
我们通过拉格朗日方程对人类行走进行建模,并得出结论,除了一阶运动特征之外,我们还需要使用二阶运动特征来表示步态。
-
基于拉格朗日运动分析的结论,我们提出了一个二阶运动提取模块来提取高层特征图上的特征。
-
我们提出了一种新颖的、轻量级的视角嵌入,以缩小由视角变化引起的差异。
-
我们将我们提出的方法应用于广泛使用的CASIA-B和OU-MVLP数据集,并验证了我们方法的有效性。为了进一步证明我们想法的有效性,我们进行了一些可视化的研究。
2. Related Works
步态识别方法可分为两类,即分别基于模型的方法和基于外观的方法。
基于模型的步态识别方法[2, 17, 19, 24, 33]利用姿势信息来模拟人类姿势不变的身份信息。这种方法对衣服变化和携带物品等干扰项目具有天然的鲁棒性。然而,基于模型的方法在很大程度上受到姿势估计准确性的影响。行人姿势估计本身仍然是一个具有挑战性的问题[14, 18],特别是对于跨域姿势估计[44],这是一个与步态识别更接近的场景。
如今,随着深度学习的发展,基于外观的方法的性能有了较大的突破。Wu等人[37]和Chao等人[6]首先提出了适用于步态识别的网络。Wolf等人[36]、Lin等人[20]和Huang等人[12]将三维卷积用于步态识别。Fan等人[7]和Huang等人[11]将时间模型考虑在内。
视角变化是生物统计学中的一个挑战性问题,包括人脸识别和步态识别。与人脸相比,在步态识别中考虑视角的方法较少。He等人[9]提出了一个多任务GAN,并使用视角标签作为监督来训练GAN。Chai等人[5]采用不同的投影矩阵作为视角嵌入方法,并在多个backbone上实现了高增长。然而,这些模型很复杂,有太多的参数。
光流是运动的一种表现形式,光流估计是一项预测两个相邻帧之间的像素到像素的对应关系的任务。最近,许多深度学习方法[29, 40]被用于光流估计。在这些方法中,RAFT[32]是目前具有完美性能和最快速度的方法。光流已经被用于许多领域,包括动作识别[3, 26]和视频生成[1]。
3. Why second-order motion?
步态被认为是可以区分行人的步行模式[23]。然而,在早些年,基于外观的卷积神经网络方法现在主要关注轮廓的二维特征。即使是最先进的 Gaitset [6] 也不依赖于任何时间特征。很难证明当前最先进的方法是依赖于人体形状还是传统的“步态”。早些年,一些方法 [8, 27, 30] 已经探索了运动以及加速度(二阶运动)对步态识别的影响,但他们并没有深入研究其背后的理论和物理学。
因此,为了探索本质信息,我们提出使用拉格朗日方程[13]来分析人类的行走。如图3所示,我们假设人类的大腿和小腿是刚性的,并对其进行机械建模。两条大腿和两条腿的长度和质量分别表示为 l 1 , l 2 , m 1 , m 2 l_{1}, l_{2}, m_{1}, m_{2} l1,l2,m1,m2和 l 3 , l 4 , m 3 , m 4 l_{3}, l_{4}, m_{3}, m_{4} l3,l4,m3,m4。 θ i \theta_{i} θi代表它们与垂直线之间的角度。同时,假设人体向前移动一小段距离 x x x。
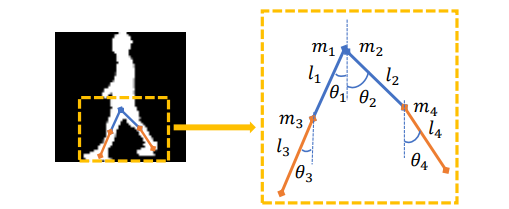
图3。行人行走分析图。
那么我们可以得到动能 T T T为:。
T = 1 2 ( m 1 + m 2 + m 3 + m 4 ) ( d x d t ) 2 + 1 6 ( m 1 l 1 2 ( d θ 1 d t ) 2 + m 2 l 2 2 ( d θ 2 d t ) 2 + m 3 l 3 2 ( d θ 3 d t ) 2 + m 4 l 4 2 ( d θ 4 d t ) 2 ) \begin{aligned} T &=\frac{1}{2}\left(m_{1}+m_{2}+m_{3}+m_{4}\right)\left(\frac{\mathrm{d} x}{\mathrm{~d} t}\right)^{2}+\frac{1}{6}\left(m_{1} l_{1}^{2}\left(\frac{\mathrm{d} \theta_{1}}{\mathrm{~d} t}\right)^{2}\right.\\ &\left.+m_{2} l_{2}^{2}\left(\frac{\mathrm{d} \theta_{2}}{\mathrm{~d} t}\right)^{2}+m_{3} l_{3}^{2}\left(\frac{\mathrm{d} \theta_{3}}{\mathrm{~d} t}\right)^{2}+m_{4} l_{4}^{2}\left(\frac{\mathrm{d} \theta_{4}}{\mathrm{~d} t}\right)^{2}\right) \end{aligned} T=21(m1+m2+m3+m4)( dtdx)2+61(m1l12( dtdθ1)2+m2l22( dtdθ2)2+m3l32( dtdθ3)2+m4l42( dtdθ4)2)
势能 V V V为:
V = − 1 2 m 1 g l 1 cos θ 1 − m 3 g ( l 1 cos θ 1 + l 3 2 cos θ 3 ) − 1 2 m 2 g l 2 cos θ 2 − m 4 g ( l 2 cos θ 2 + l 4 2 cos θ 4 ) \begin{aligned} V &=-\frac{1}{2} m_{1} g l_{1} \cos \theta_{1}-m_{3} g\left(l_{1} \cos \theta_{1}+\frac{l_{3}}{2} \cos \theta_{3}\right) \\ &-\frac{1}{2} m_{2} g l_{2} \cos \theta_{2}-m_{4} g\left(l_{2} \cos \theta_{2}+\frac{l_{4}}{2} \cos \theta_{4}\right) \end{aligned} V=−21m1gl1cosθ1−m3g(l1cosθ1+2l3cosθ3)−21m2gl2cosθ2−m4g(l2cosθ2+2l4cosθ4)
让我们计算一下 L = T − V L=T-V L=T−V。然后用 L a L a La的拉格朗日方程,系统可以用 x , θ 1 , θ 2 , θ 3 , θ 4 , t x, \theta_{1}, \theta_{2}, \theta_{3}, \theta_{4}, t x,θ1,θ2,θ3,θ4,t表述为。
( m 1 + m 2 + m 3 + m 4 ) d 2 x d t 2 = Q 0 1 3 m 1 l 1 2 d 2 θ 1 d t 2 − 1 2 ( m 1 + m 3 ) g l 1 sin θ 1 d θ 1 d t = Q 1 1 3 m 2 l 2 2 d 2 θ 2 d t 2 − 1 2 ( m 2 + m 4 ) g l 2 sin θ 2 d θ 2 d t = Q 2 , 1 3 m 3 l 3 2 2 d 2 θ 3 d t 2 − 1 2 m 3 g l 3 sin θ 3 d θ 3 d t = Q 3 1 3 m 4 l 4 2 d 2 θ 4 d t 2 − 1 2 m 4 g l 4 sin θ 4 d θ 4 d t = Q 4 ( 3 ) \begin{aligned} \left(m_{1}+m_{2}+m_{3}+m_{4}\right) \frac{\mathrm{d}^{2} x}{\mathrm{~d} t^{2}} &=Q_{0} \\ \frac{1}{3} m_{1} l_{1}^{2} \frac{\mathrm{d}^{2} \theta_{1}}{\mathrm{~d} t^{2}}-\frac{1}{2}\left(m_{1}+m_{3}\right) g l_{1} \sin \theta_{1} \frac{\mathrm{d} \theta_{1}}{\mathrm{~d} t} &=Q_{1} \\ \frac{1}{3} m_{2} l_{2}^{2} \frac{\mathrm{d}^{2} \theta_{2}}{\mathrm{~d} t^{2}}-\frac{1}{2}\left(m_{2}+m_{4}\right) g l_{2} \sin \theta_{2} \frac{\mathrm{d} \theta_{2}}{\mathrm{~d} t} &=Q_{2}, \\ \frac{1}{3} m_{3} l_{3}^{2^{2}} \frac{\mathrm{d}^{2} \theta_{3}}{\mathrm{~d} t^{2}}-\frac{1}{2} m_{3} g l_{3} \sin \theta_{3} \frac{\mathrm{d} \theta_{3}}{\mathrm{~d} t} &=Q_{3} \\ \frac{1}{3} m_{4} l_{4}^{2} \frac{\mathrm{d}^{2} \theta_{4}}{\mathrm{~d} t^{2}}-\frac{1}{2} m_{4} g l_{4} \sin \theta_{4} \frac{\mathrm{d} \theta_{4}}{\mathrm{~d} t} &=Q_{4} \end{aligned}(3) (m1+m2+m3+m4) dt2d2x31m1l12 dt2d2θ1−21(m1+m3)gl1sinθ1 dtdθ131m2l22 dt2d2θ2−21(m2+m4)gl2sinθ2 dtdθ231m3l322 dt2d2θ3−21m3gl3sinθ3 dtdθ331m4l42 dt2d2θ4−21m4gl4sinθ4 dtdθ4=Q0=Q1=Q2,=Q3=Q4(3)
其中 Q 0 , Q 1 , Q 2 , Q 3 , Q 4 Q_{0}, Q_{1}, Q_{2}, Q_{3}, Q_{4} Q0,Q1,Q2,Q3,Q4是广义的力,包括来自人体肌肉的力和阻力。这些力是行人的本质,它们在一个步态周期中逐渐连续变化。
可以看出,在式(3)中,为了维持这个动力系统,除了一阶导数 d 2 x d t 2 , d 2 θ 1 d t 2 , d 2 θ 2 d t 2 , d 2 θ 3 d t 2 , d 2 θ 4 d t 2 \frac{\mathrm{d}^{2} x}{\mathrm{~d} t^{2}}, \frac{\mathrm{d}^{2} \theta_{1}}{\mathrm{~d} t^{2}}, \frac{\mathrm{d}^{2} \theta_{2}}{\mathrm{~d} t^{2}}, \frac{\mathrm{d}^{2} \theta_{3}}{\mathrm{~d} t^{2}}, \frac{\mathrm{d}^{2} \theta_{4}}{\mathrm{~d} t^{2}} dt2d2x, dt2d2θ1, dt2d2θ2, dt2d2θ3, dt2d2θ4外,还需要二阶导数 d θ 1 d t , d θ 2 d t , d θ 3 3 d t , d θ 4 d t \frac{\mathrm{d} \theta_{1}}{\mathrm{~d} t}, \frac{\mathrm{d} \theta_{2}}{\mathrm{~d} t}, \frac{\mathrm{d} \theta_{3}^{3}}{\mathrm{~d} t}, \frac{\mathrm{d} \theta_{4}}{\mathrm{~d} t} dtdθ1, dtdθ2, dtdθ33, dtdθ4。如果只有一阶变量,方程组就不是唯一的。
基于三维卷积的方法[12,20,21,36]表现更好并不奇怪,因为级联的三维卷积层可以在最佳情况下提取二阶信息。我们认为三维卷积可以提取时间信息,但很难证明级联的三维卷积层是否一定可以提取二阶运动信息。我们无法知道3D卷积是在进行运动,还是只是对特征图求和。
根据人体运动系统得出的结论,我们根据光流估计[32]中使用的方法设计了一个提取二阶运动特征的模块。与三维卷积相比,它可以明确地提取相邻帧之间的运动。
4. Methods
在本节中,我们提出了一个新的框架,称为LagrangeGait。如图4所示,该框架由三个分支组成。上分支为运动分支,根据第3节的结论提取二阶运动特征。中间分支是提取外观特征的主要分支,可以是Gaitset[6]或GaitGL[21]等任意主干。将主分支中浅层计算得到的特征图应用于运动分支。底部分支为视角分支,对输入轮廓序列的视角进行预测,生成可学习的视角嵌入。
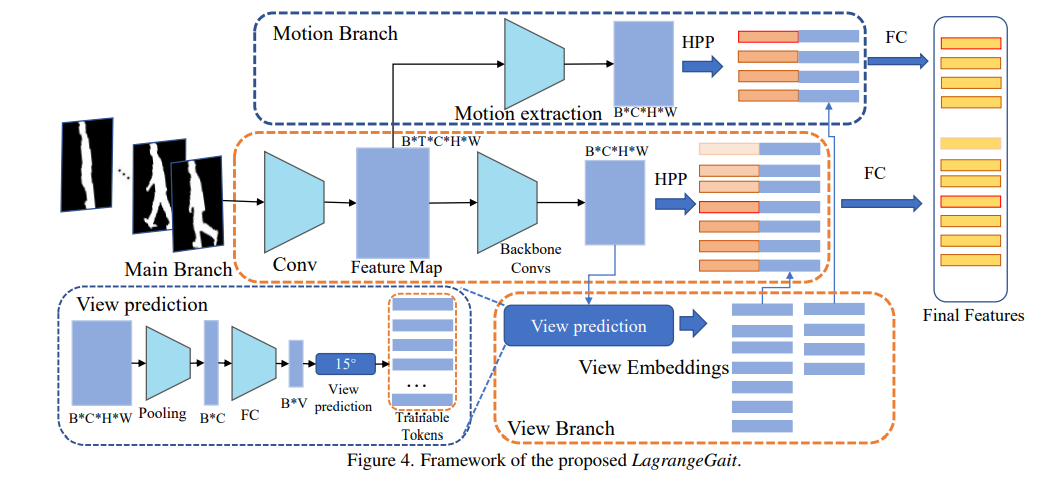
图4。提出的LagrangeGait框架。
给定一个剪影序列,我们将其表示为 I = \boldsymbol{I}= I= { I 1 , I 2 , I 3 , … I T } \left\{\boldsymbol{I}_{1}, \boldsymbol{I}_{2}, \boldsymbol{I}_{3}, \ldots \boldsymbol{I}_{T}\right\} {
I1,I2,I3,…IT}和 T T T是序列的长度。从浅层提取的特征映射记为 X origin = [ X 1 , X 2 , … X t ] \boldsymbol{X}_{\text {origin }}=\left[\boldsymbol{X}_{1}, \boldsymbol{X}_{2}, \ldots \boldsymbol{X}_{t}\right] Xorigin =[X1,X2,…Xt],其中 X i ∈ R C × H × W \boldsymbol{X}_{i} \in \mathbb{R}^{C \times H \times W} Xi∈RC×H×W和 X origin ∈ R t × C × H × W \boldsymbol{X}_{\text {origin }} \in \mathbb{R}^{t \times C \times H \times W} Xorigin ∈Rt×C×H×W, t t t表示池化后特征映射在时间维度上的长度,例如:在Gaitset[6]中 t = T t=T t=T,在GaitGL[21]中 t = T 3 t=\frac{T}{3} t=3T,因为GaitGL有一个 3 × 1 × 1 3 \times 1 \times 1 3×1×1的池化层,核大小和步长相同。将得到的 X origin \boldsymbol{X}_{\text {origin }} Xorigin 送入到不同的分支中,运动特征图 X motion \boldsymbol{X}_{\text {motion }} Xmotion ,外观特征图 X a p p e a r a n c e \boldsymbol{X}_{a p p e a r a n c e} Xappearance,视角特征 f v i e w f_{v i e w} fview分别计算为
X origin = F 3 d ( I ) , X motion = F motion ( X origin ) X appearance = F backbone ( X origin ) f view = F view ( X appearance ) ( 4 ) \begin{aligned} \boldsymbol{X}_{\text {origin }} &=F_{3 d}(\boldsymbol{I}), \\ \boldsymbol{X}_{\text {motion }} &=F_{\text {motion }}\left(\boldsymbol{X}_{\text {origin }}\right) \\ \boldsymbol{X}_{\text {appearance }} &=F_{\text {backbone }}\left(\boldsymbol{X}_{\text {origin }}\right) \\ \boldsymbol{f}_{\text {view }} &=F_{\text {view }}\left(\boldsymbol{X}_{\text {appearance }}\right) \end{aligned}(4) Xorigin Xmotion Xappearance fview =F3d(I),=Fmotion (Xorigin )=Fbackbone (Xorigin )=Fview (Xappearance )(4)
其中 X appearance , X motion , ∈ R C 2 × H × W , f view ∈ R C 3 \boldsymbol{X}_{\text {appearance }}, \boldsymbol{X}_{\text {motion }}, \in \mathbb{R}^{C_{2} \times H \times W}, \boldsymbol{f}_{\text {view }} \in \mathbb{R}^{C_{3}} Xappearance ,Xmotion ,∈RC2×H×W,fview ∈RC3和 F backbone , F motion , F view F_{\text {backbone }}, F_{\text {motion }}, F_{\text {view }} Fbackbone ,Fmotion ,Fview 是对应的分支
然后我们首先预测序列的视角,然后将其与 X a p p e a r a n c e \boldsymbol{X}_{a p p e a r a n c e} Xappearance和 X motion \boldsymbol{X}_{\text {motion }} Xmotion 融合:
p ^ = F predict ( f view ) , f motion = F fusion 1 ( X motion , p ^ ) , f appearance = F fusion 2 ( X appearance , p ^ ) \begin{aligned} \hat{p} &=F_{\text {predict }}\left(\boldsymbol{f}_{\text {view }}\right), \\ \boldsymbol{f}_{\text {motion }} &=F_{\text {fusion }_{1}}\left(\boldsymbol{X}_{\text {motion }}, \hat{p}\right), \\ \boldsymbol{f}_{\text {appearance }} &=F_{\text {fusion }_{2}}\left(\boldsymbol{X}_{\text {appearance }}, \hat{p}\right) \end{aligned} p^fmotion fappearance =Fpredict (fview ),=Ffusion 1(Xmotion ,p^),=Ffusion 2(Xappearance ,p^)
其中 p ^ \hat{p} p^为预测视角, p ^ ∈ R M , M \hat{p} \in \mathbb{R}^{M}, M p^∈RM,M为离散视图的个数。 f motion \boldsymbol{f}_{\text {motion }} fmotion 和 f appearance \boldsymbol{f}_{\text {appearance }} fappearance 是运动和外观的最终特征, f motion ∈ R n motion × c 3 \boldsymbol{f}_{\text {motion }} \in \mathbb{R}^{n_{\text {motion }} \times c_{3}} fmotion ∈Rnmotion ×c3, f appearance ∈ R n appearance × c 3 f_{\text {appearance }} \in \mathbb{R}^{n_{\text {appearance }} \times c_{3}} fappearance ∈Rnappearance ×c3。 n motion , n appearance n_{\text {motion }}, n_{\text {appearance }} nmotion ,nappearance 表示使用HPP模块[6]为运动特征映射和外观特征映射切片的条带数量。 c 3 c_{3} c3表示特征图的通道数。
最后,用于步态识别的特征可以表示为
f final = [ f motion ; f appearance ] ( 6 ) \boldsymbol{f}_{\text {final }}=\left[\boldsymbol{f}_{\text {motion }} ; \boldsymbol{f}_{\text {appearance }}\right](6) ffinal =[fmotion ;fappearance ](6)
4.1. Motion Extraction Module
根据第3节,设计了一个二阶运动提取模块。如图5所示,我们使用3D卷积作为一阶特征提取层。在二阶阶段,参考了RAFT[32]的结构,利用相邻的帧响应关系。
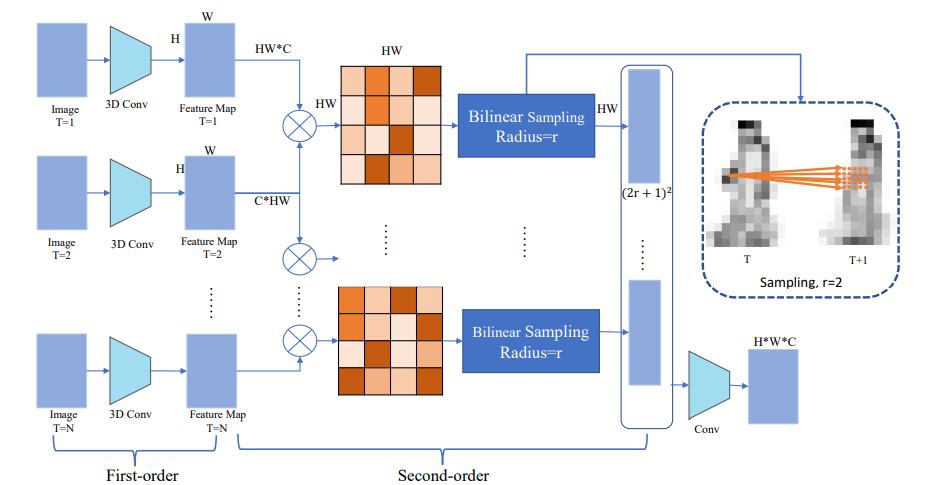
图5。二阶运动提取模块的结构。我们以三维卷积作为一阶运动提取模块,计算像素对像素的对应矩阵作为二阶运动特征。由于像素不能离原点太远,所以我们采用双线性采样来减少计算成本。
由式(4)得到 X origin \boldsymbol{X}_{\text {origin }} Xorigin ,我们将 T i T_{i} Ti和 T i + 1 T_{i+1} Ti+1时刻的feature map分别记为 X origin,i \boldsymbol{X}_{\text {origin,i }} Xorigin,i 和 X origin , i + 1 \boldsymbol{X}_{\text {origin }, i+1} Xorigin ,i+1。然后相邻帧的相关性可以计算为
X 0 = F Q ( X origin , i ) X 1 = F K ( X origin , i + 1 ) , Att ( X 0 , X 1 ) = Softmax ( X 0 T X 1 ) \begin{aligned} \boldsymbol{X}_{\mathbf{0}} &=F_{Q}\left(\boldsymbol{X}_{\text {origin }, i}\right) \\ \boldsymbol{X}_{\mathbf{1}} &=F_{K}\left(\boldsymbol{X}_{\text {origin }, i+1}\right), \\ \operatorname{Att}\left(\boldsymbol{X}_{\mathbf{0}}, \boldsymbol{X}_{\mathbf{1}}\right) &=\operatorname{Softmax}\left(\boldsymbol{X}_{\mathbf{0}}^{T} \boldsymbol{X}_{\mathbf{1}}\right) \end{aligned} X0X1Att(X0,X1)=FQ(Xorigin ,i)=FK(Xorigin ,i+1),=Softmax(X0TX1)
其中 F Q F_{Q} FQ和 F k F_{k} Fk为卷积层的组合,滤波器大小为 1 × 1 1 \times 1 1×1,并进行维数合并操作。 Att ( X 0 , X 1 ) ∈ R H W × H W \operatorname{Att}\left(\boldsymbol{X}_{\mathbf{0}}, \boldsymbol{X}_{\mathbf{1}}\right) \in \mathbb{R}^{H W \times H W} Att(X0,X1)∈RHW×HW。然后将相关图重构为 Cor ( X 0 , X 1 ) ∈ R H × W × H W \operatorname{Cor}\left(\boldsymbol{X}_{\mathbf{0}}, \boldsymbol{X}_{\mathbf{1}}\right) \in \mathbb{R}^{H \times W \times H W} Cor(X0,X1)∈RH×W×HW。对于 X origin,i \boldsymbol{X}_{\text {origin,i }} Xorigin,i 中的像素,它在下一帧Xorigin中对应的像素 X origin , i + 1 \boldsymbol{X}_{\text {origin }, i+1} Xorigin ,i+1,我们假设它没有移动太多。所以对于 X origin, , i \boldsymbol{X}_{\text {origin, }, i} Xorigin, ,i中的每一个像素 x = ( u , v ) \boldsymbol{x}=(u, v) x=(u,v),特征图 X origin , i + 1 \boldsymbol{X}_{\text {origin }, i+1} Xorigin ,i+1中的对应点为 x ′ = ( u + f 1 ( u ) , v + f 1 ( v ) ) \boldsymbol{x}^{\prime}=\left(u+f^{1}(u), v+f^{1}(v)\right) x′=(u+f1(u),v+f1(v))。
采样范围为
N ( x ) r = { x + d x ∣ d x ∈ Z 2 , ∥ d x ∥ 1 ≤ r } N(x)_{r}=\left\{\boldsymbol{x}+\boldsymbol{d} \boldsymbol{x} \mid \boldsymbol{d} \boldsymbol{x} \in \mathbb{Z}^{2},\|\boldsymbol{d} \boldsymbol{x}\|_{1} \leq r\right\} N(x)r={
x+dx∣dx∈Z2,∥dx∥1≤r}
其中, d x \boldsymbol{d} \boldsymbol{x} dx为采样偏移量, r r r为采样半径。对于 Cor ( X 0 , X 1 ) \operatorname{Cor}\left(\boldsymbol{X}_{\mathbf{0}}, \boldsymbol{X}_{\mathbf{1}}\right) Cor(X0,X1)上的每个像素 x x x,我们按照 N ( x ) r N(x)_{r} N(x)r对其进行采样,得到 X c o r r , i ′ ∈ R H × W × ( 2 r + 1 ) 2 X_{c o r r, i}^{\prime} \in \mathbb{R}^{H \times W \times(2 r+1)^{2}} Xcorr,i′∈RH×W×(2r+1)2。然后我们交换通道,形成 X c o r r , i ∈ R ( 2 r + 1 ) 2 × H × W \boldsymbol{X}_{c o r r, i} \in \mathbb{R}^{(2 r+1)^{2} \times H \times W} Xcorr,i∈R(2r+1)2×H×W。
最后,将二阶特征图在时间维度上进行整合,得到序列的特征图:
X c o r r = [ X c o r r , 1 ; X c o r r , 2 ; … ; X c o r r , t − 1 ] X_{c o r r}=\left[X_{c o r r, 1} ; X_{c o r r, 2} ; \ldots ; X_{c o r r, t-1}\right] Xcorr=[Xcorr,1;Xcorr,2;…;Xcorr,t−1]
这里 X corr ∈ R ( 2 r + 1 ) 2 × t − 1 × H × W X_{\text {corr }} \in \mathbb{R}^{(2 r+1)^{2} \times t-1 \times H \times W} Xcorr ∈R(2r+1)2×t−1×H×W。我们使用 3D 卷积来提取最终特征:
X motion = F 3 d c o n v ( X c o r r ) \boldsymbol{X}_{\text {motion }}=F_{3 d c o n v}\left(X_{c o r r}\right) Xmotion =F3dconv(Xcorr)
其中 F 3 dconv F_{3 \text { dconv }} F3 dconv 是内核大小为 3 × 3 \times 3× 3 × 3 3 \times 3 3×3的卷积层。 X motion ∈ R C 2 × T × H × W \boldsymbol{X}_{\text {motion }} \in \mathbb{R}^{C_{2} \times T \times H \times W} Xmotion ∈RC2×T×H×W。
4.2. View Embedding
对于步态识别,很少有方法将视角本身考虑在内。在本文中,我们提出了一种更轻量级的视角嵌入方法。
首先,我们使用等式(4)中获得的特征图 X origin \boldsymbol{X}_{\text {origin }} Xorigin 计算输入序列的视角特征为
KaTeX parse error: Expected '}', got '_' at position 171: …_{\text {Global_̲Avg }}\left(\bo…
其中 P M a x P_{M a x} PMax是时间维度上的最大池化, P G l o b a l A v g P_{G l o b a l_{A} v g} PGlobalAvg是全局平均池化。
然后使用 f view f_{\text {view }} fview 的预测可以表示为
p ^ = W view f view + B view \hat{p}=W_{\text {view }} \boldsymbol{f}_{\text {view }}+B_{\text {view }} p^=Wview fview +Bview
y ^ = arg max i p ^ i ( 12 ) \hat{y}=\underset{i}{\arg \max } \hat{p}_{i}(12) y^=iargmaxp^i(12)
这里 M M M是视角数量,对于 CASIA-B [41] M = 11 M=11 M=11和 OUMVLP [31] M = 14 M=14 M=14。 W view ∈ R M × C 2 W_{\text {view }} \in \mathbb{R}^{M \times C_{2}} Wview ∈RM×C2是 F C \mathrm{FC} FC层的权重, B view B_{\text {view }} Bview 是 F C \mathrm{FC} FC层的偏差。 y ^ ∈ { 0 , 1 , 2 , … , M − 1 } \hat{y} \in\{0,1,2, \ldots, M-1\} y^∈{
0,1,2,…,M−1}是视图预测的结果。
对于每个离散视角 y ^ \hat{y} y^,我们将训练两个嵌入 E m , y ^ ∈ C 0 , E a , y ^ ∈ C 0 E_{m, \hat{y}} \in \mathbb{C}_{0}, E_{a, \hat{y}} \in \mathbb{C}_{0} Em,y^∈C0,Ea,y^∈C0用于运动和外观特征,它们将用于水平金字塔池化模块 [6]。 C 0 C_{0} C0是从图 4 中的第一个卷积层获得的特征图的维度。
4.3. HPP with View Embedding
在步态识别中,水平金字塔池化(HPP)[6]是一个广泛使用的模块。在本文中,除了在外观特征图上使用HPP,我们还对运动特征图进行了相同的操作。池化后,将特征与提出的视角嵌入连接,以进行最终的特征投影。
对于水平金字塔池化后得到的外观特征图,我们表示为:
f a p p , 1 , f a p p , 2 , … f a p p , n , \boldsymbol{f}_{a p p, 1}, \boldsymbol{f}_{a p p, 2}, \ldots \boldsymbol{f}_{a p p, n}, fapp,1,fapp,2,…fapp,n,
其中 n n n是要拆分的条带数, f a p p , i ∈ R C 2 \boldsymbol{f}_{a p p, i} \in \mathbb{R}^{C_{2}} fapp,i∈RC2。对于外观分支和运动分支,条带的数量是 n appearance n_{\text {appearance }} nappearance 和 n motion n_{\text {motion }} nmotion
假设 X appearance \boldsymbol{X}_{\text {appearance }} Xappearance 的预测视角是 z z z。那么 F fusion 1 \boldsymbol{F}_{\text {fusion } 1} Ffusion 1的过程可以表述为:
f a v , i = [ f a p p , i ; E a , z ] f finala , i = W p , i f a v , i , i = 1 , 2 , … n appearance f app = [ f finala , 1 , f finala , 2 , … , f finala , n a p p ] ( 14 ) \begin{aligned} \boldsymbol{f}_{a v, i} &=\left[\boldsymbol{f}_{a p p, i} ; E_{a, z}\right] \\ \boldsymbol{f}_{\text {finala }, i} &=W_{p, i} \boldsymbol{f}_{a v, i}, i=1,2, \ldots n_{\text {appearance }} \\ \boldsymbol{f}_{\text {app }} &=\left[\boldsymbol{f}_{\text {finala }, 1}, \boldsymbol{f}_{\text {finala }, 2}, \ldots, \boldsymbol{f}_{\text {finala }, n_{a p p}}\right] \end{aligned}(14) fav,iffinala ,ifapp =[fapp,i;Ea,z]=Wp,ifav,i,i=1,2,…nappearance =[ffinala ,1,ffinala ,2,…,ffinala ,napp](14)
这里 f a v , i ∈ R C 2 + C 0 , f f inala , i ∈ R C 2 , f a p p ∈ R n a p p × C 2 \boldsymbol{f}_{a v, i} \in \mathbb{R}^{C_{2}+C_{0}}, \boldsymbol{f}_{f \text { inala }, i} \in \mathbb{R}^{C_{2}}, \boldsymbol{f}_{a p p} \in \mathbb{R}^{n_{a p p} \times C_{2}} fav,i∈RC2+C0,ff inala ,i∈RC2,fapp∈Rnapp×C2。
F fusion 2 F_{\text {fusion } 2} Ffusion 2的过程与 F fusion 1 F_{\text {fusion } 1} Ffusion 1类似:
f m v , i = [ f motion, i ; E m , z ] f finalm,i = W p f m v , i , i = 1 , 2 , … n motion f motion = [ f finalm , 1 , f finalm , 2 , … , f finalm , n motion ] ( 15 ) \begin{aligned} \boldsymbol{f}_{m v, i} &=\left[\boldsymbol{f}_{\text {motion, } i} ; E_{m, z}\right] \\ \boldsymbol{f}_{\text {finalm,i }} &=W_{p} \boldsymbol{f}_{m v, i}, i=1,2, \ldots n_{\text {motion }} \\ \boldsymbol{f}_{\text {motion }} &=\left[\boldsymbol{f}_{\text {finalm }, 1}, \boldsymbol{f}_{\text {finalm }, 2}, \ldots, \boldsymbol{f}_{\text {finalm }, n_{\text {motion }}}\right] \end{aligned}(15) fmv,iffinalm,i fmotion =[fmotion, i;Em,z]=Wpfmv,i,i=1,2,…nmotion =[ffinalm ,1,ffinalm ,2,…,ffinalm ,nmotion ](15)
其中 f m v , i ∈ R C 2 + C 0 , f finalm,i ∈ R C 2 , f motion ∈ \boldsymbol{f}_{m v, i} \in \mathbb{R}^{C_{2}+C_{0}}, \boldsymbol{f}_{\text {finalm,i }} \in \mathbb{R}^{C_{2}}, \boldsymbol{f}_{\text {motion }} \in fmv,i∈RC2+C0,ffinalm,i ∈RC2,fmotion ∈ R n motion × C 2 \mathbb{R}^{n_{\text {motion }} \times C_{2}} Rnmotion ×C2。
最后,可以通过将等式(14)和(15)带入(6)来接近最终特征。其中 f final ∈ f_{\text {final }} \in ffinal ∈ R ( n motion + n appearance ) × C 2 \mathbb{R}^{\left(n_{\text {motion }}+n_{\text {appearance }}\right) \times C_{2}} R(nmotion +nappearance )×C2。
4.4. Joint Losses
在提出的框架中,我们的损失包括交叉熵(CE)和三元组损失。结合等式(12),CE损失可以表示为
L C E = − ∑ i = 1 N ∑ j = 1 M y i j log ( p i j ) w.r.t. p i j = e p ^ i j ∑ j = 1 M e p ^ i j ( 16 ) \mathcal{L}_{C E}=-\sum_{i=1}^{N} \sum_{j=1}^{M} y_{i j} \log \left(p_{i j}\right) \text { w.r.t. } p_{i j}=\frac{e^{\hat{p}_{i j}}}{\sum_{j=1}^{M} e^{\hat{p}_{i j}}}(16) LCE=−i=1∑Nj=1∑Myijlog(pij) w.r.t. pij=∑j=1Mep^ijep^ij(16)
其中 N N N是样本数, M M M是视角数, y i j y_{i j} yij是第 i i i个样本的视角是否为 j j j。
假设步态轮廓序列的三元组为 ( Q , P , N ) (Q, P, N) (Q,P,N),其中 Q Q Q和 P P P来自同一受试者, Q Q Q和 N N N来自两个不同的受试者。将固定恒等式的 K K K个三元组表示为 { T i ∣ T i = ( f final Q i , f final P i , f final N i ) , i = \left\{T_{i} \mid T_{i}=\left(f_{\text {final }}^{Q_{i}}, f_{\text {final }}^{P_{i}}, f_{\text {final }}^{N_{i}}\right), i=\right. {
Ti∣Ti=(ffinal Qi,ffinal Pi,ffinal Ni),i= 1 , 2 , … , K } 1,2, \ldots, K\} 1,2,…,K}。那么三元组损失可以表示为
L t r i p = 1 K ∑ i = 1 K ∑ j = 1 n max ( m − d i j − + d i j + , 0 ) ( 17 ) \mathcal{L}_{t r i p}=\frac{1}{K} \sum_{i=1}^{K} \sum_{j=1}^{n} \max \left(m-d_{i j}^{-}+d_{i j}^{+}, 0\right)(17) Ltrip=K1i=1∑Kj=1∑nmax(m−dij−+dij+,0)(17)
其中 d i j − = ∥ f final, , Q i − f fina,j N i ∥ 2 2 d_{i j}^{-}=\left\|f_{\text {final, },}^{Q_{i}}-f_{\text {fina,j }}^{N_{i}}\right\|_{2}^{2} dij−=∥∥∥ffinal, ,Qi−ffina,j Ni∥∥∥22 and d i j + = ∥ f final, j Q i − d_{i j}^{+}=\| f_{\text {final, } j}^{Q_{i}}- dij+=∥ffinal, jQi− f final , j P i ∥ 2 2 f_{\text {final }, j}^{P_{i}} \|_{2}^{2} ffinal ,jPi∥22。
结合式(16)和(17),最终的损失可以表示为:
L = L t r i p + λ C E L C E \mathcal{L}=\mathcal{L}_{t r i p}+\lambda_{C E} \mathcal{L}_{C E} L=Ltrip+λCELCE
其中 λ C E \lambda_{C E} λCE是一个超参数。
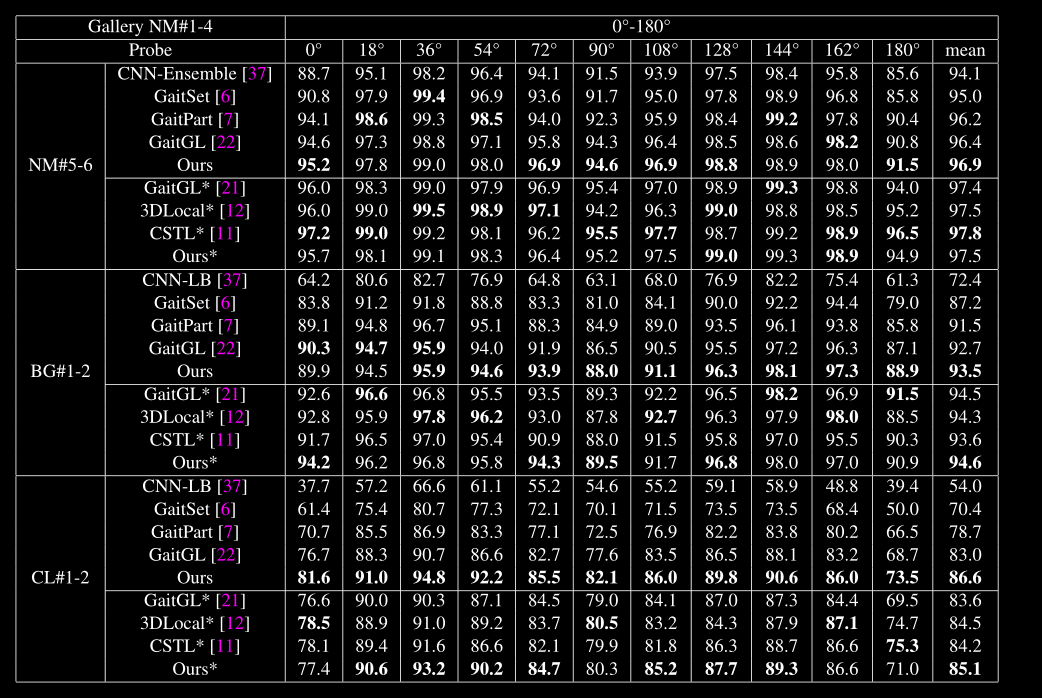
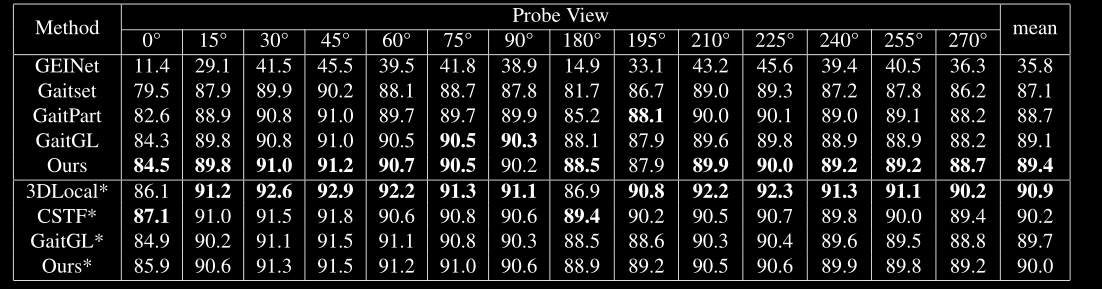
Results
References

