目录
1. 论文&代码源
《Improving Disentangled Representation Learning for Gait Recognition using Group Supervision》
论文地址:https://ieeexplore.ieee.org/document/9767609
代码下载地址: 作者未提供
2. 论文亮点
-
首次提出群体监督的DRL方法来解决步态识别问题
输入序列被明确分为姿势、步态、外观和视角四种特征,分解后的四种特征被用于最终的步态识别。 -
使用“解缠”和“纠缠聚合”模块
为提高特征的效率和独立性,在编码-解码过程中特别使用了“解缠”模块;为提高特征的可靠性和有效性,特别使用了“纠缠聚合”模块。 -
少量步态帧采样下性能优异
本方法在仅有少量步态帧采样的情况下,就能取得较为优异的识别性能。
3. 相关工作
DRL(Disentangled Representation Learning)
分解特征学习:旨在通过将数据的底层结构解耦为互不相干的、有意义的部分来进行学习。某种程度上,DRL有助于解释深度模型,并指出模型在训练过程中实际学到了哪些隐藏特征。
4. 模型架构
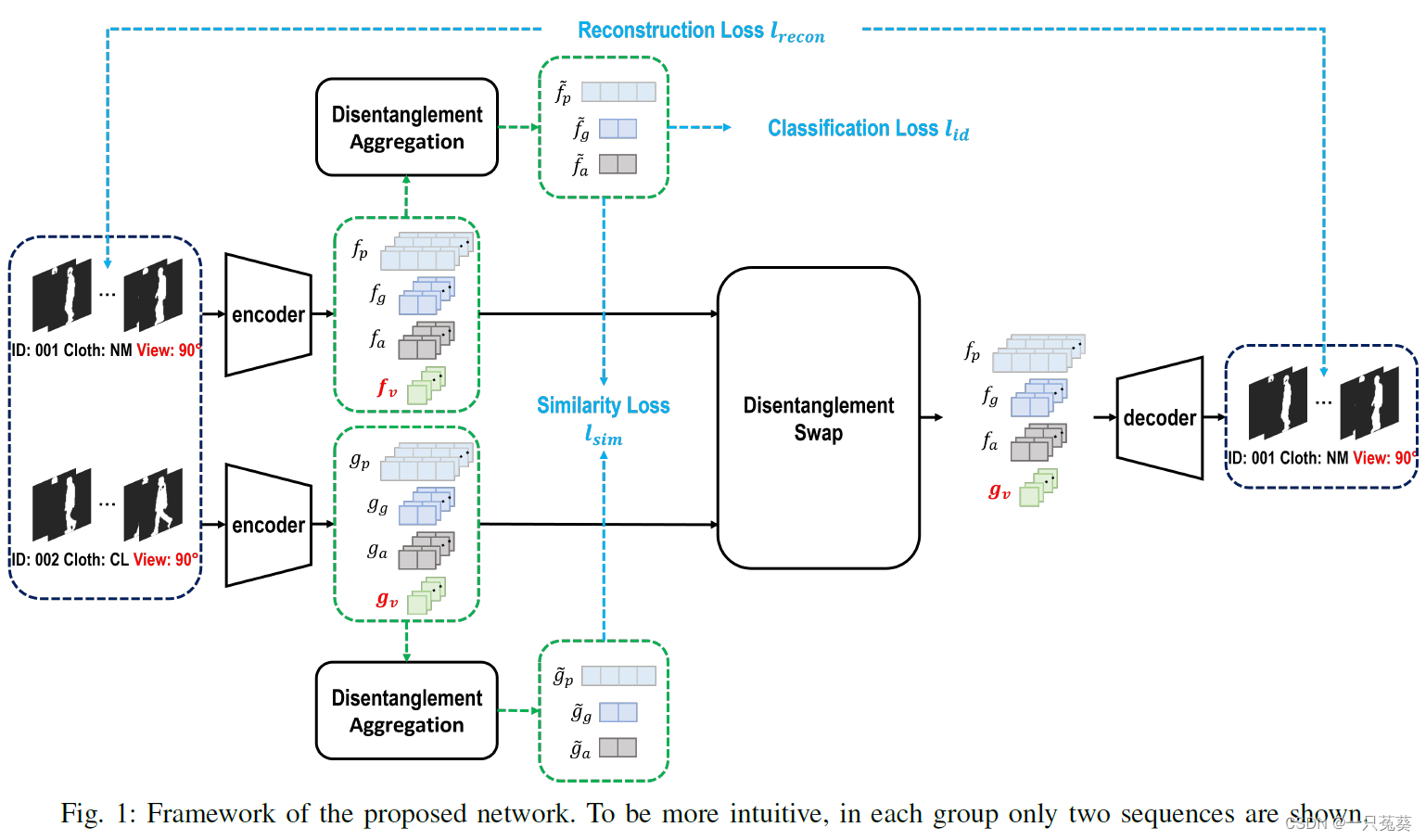
4.1 群体监督下的特征分解
4.1.1 群体监督学习
每组序列包含四个序列,其中一个为Anchor,其余的是参考序列,在Anchor序列和每一个参考序列之间至少有一个相同属性。
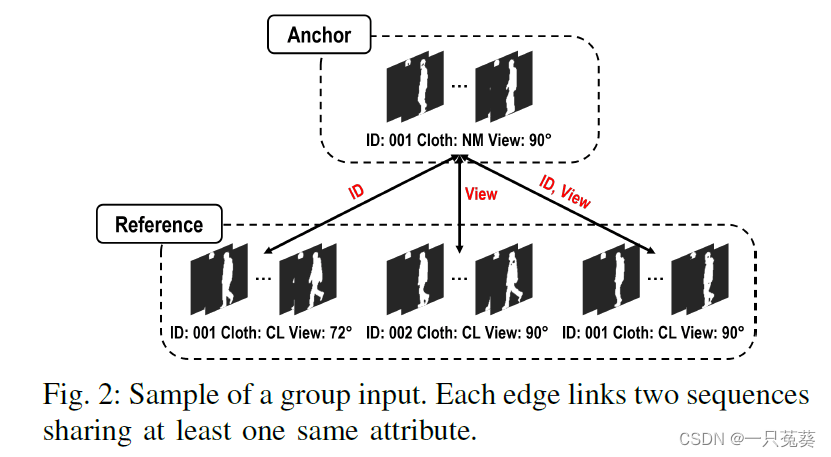
4.1.2 特征分解
编码器对每个帧进行编码,并将编码后的特征表示明确地分割成一些独立部分,分割部分可以完全描述编码的帧,可以用解码器解码回编码帧。
输入序列 X ~ ⊂ X i \tilde X \subset X_i X~⊂Xi, i = 1 , 2 , . . . , n i= 1,2,...,n i=1,2,...,n是 N N N个随机采样剪影;由 E \mathcal E E编码的特征表示为 f = { f 1 , f 2 , . . . , f N } f=\{f^1, f^2, ...,f^N\} f={ f1,f2,...,fN};其中第 k k k个剪影 f k f^k fk被分解为视角特征 f v k f_v^k fvk和视角无关特征 f d v k f_{dv}^k fdvk,二者用公式表示为: f k = f v k ⋅ f d v k ( 1 ) f^k = f_v^k \cdot f_{dv}^k\qquad (1) fk=fvk⋅fdvk(1)其中, f v k = ∣ ∣ f k ∣ ∣ 2 , f d v k = f k ∣ ∣ f k ∣ ∣ 2 f_v^k = ||f^k ||_2, f_{dv}^k = \frac { f^k} {||f^k ||_2} fvk=∣∣fk∣∣2,fdvk=∣∣fk∣∣2fk

视角无关特征被进一步细分为姿势特征 f p k f_p^k fpk,步态特征 f g k f_g^k fgk,外观特征 f a k f_a^k fak,用公式表示为: f d v k = [ f p k , f g k , f a k ] ( 2 ) f_{dv}^k = [f_p^k, f_g^k, f_a^k]\qquad (2) fdvk=[fpk,fgk,fak](2)
相应的,用于解码器重建的潜在表征也分为两个阶段进行:首先将姿势、步态和外观特征串联,然后与视角特征相乘。
4.1.3 解除纠缠交换
共享相同属性值的两个样本对于这一共享属性具有相同的潜伏值。模型提出解缠交换模块,以帮助通过共享语义属性强制实现每组特征的一致性。
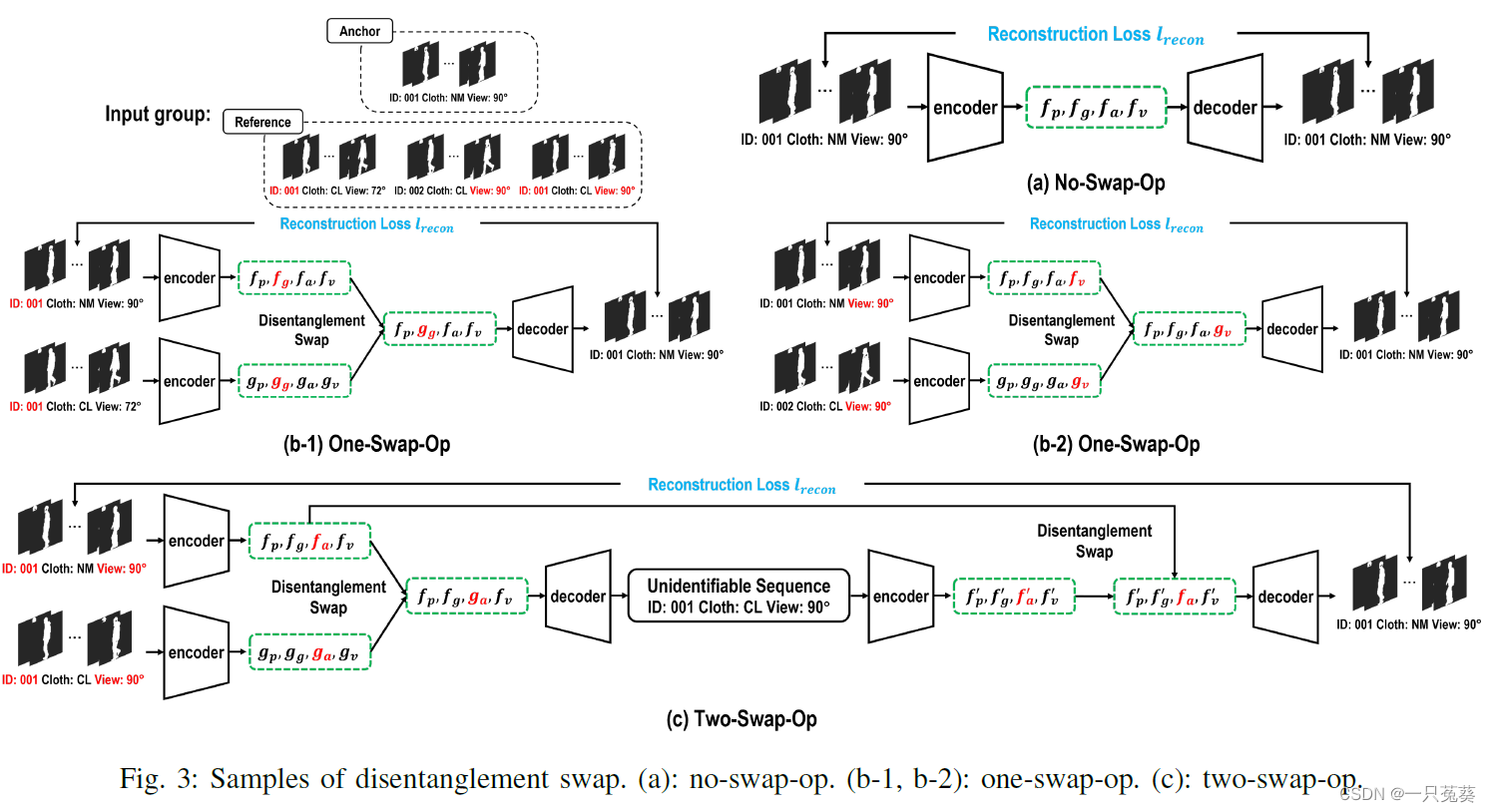
根据共享属性,交换操作可以分为三种类型:
a) no -swap-op
仅适用于Anchor序列,不进行任何交换操作,如Fig.3( a ),目的是证明分解的特征部分可以被组装并解码回它们的原始序列。
b) one-swap-op
只包含一个交换操作,适用于每个Anchor和参考序列只有主体ID和视角相同的情况,如Fig.3( b-1 )只有主体ID保持不变,Fig.3( b-2 )只有视角特征不变。
此处避免姿势特征的交换,是因为姿势特征的本质是不同的。
c) two-swap-op
两次交换操作,适用于衣着特征变化的情况,因为衣着属性无法量化,只能定义其数值的一般概念。
如Fig.3 ( c )所示,两组序列相应的外观特征进行交换,将 g a g_a ga交换到 f a f_a fa所在序列中【第一次交换】,然后根据交换后的特征 g a g_a ga生成一个无法识别的序列;对这一序列进行编码,生成外观特征 f a ′ f_a' fa′,与原外观特征 f a f_a fa进行替代【第二次交换】。
如果两次交换后的序列能够恢复到原始序列( f p , f g , f a , f v f_p, f_g, f_a, f_v fp,fg,fa,fv),说明这种衣着模式下的属性交换并不会影响其他属性分解的潜在信息。
4.1.4 重建损失
每次交换后,重建序列应当与Anchor序列相似,每次重建后都要计算MSE损失,以加强相似性。 l r e c o n l_{recon} lrecon表示上图中四个重建损失的总和。
- 分解的四个特征对于每个步态序列都具有代表性
- 交换操作保证了分解的特征的可用性和独立性
4.2 特征学习和聚合
- 提高分解的步态和外观特征的识别能力
- 将基于帧的姿势、步态和外观特征转化为序列的特征
4.2.1 姿势特征聚合
对于每一帧,分解后的姿势特征只能表征一个特定实例的行走姿势,可能与另一个人的实例具有相似性。
时间信息通过max-pooling操作进行,公式为: f ~ p = maxpool ( f p ) ( 3 ) \tilde f_p = \text {maxpool}(f_p)\qquad(3) f~p=maxpool(fp)(3)
此处不使用LSTM的原因是:一方面LSTM受最后一次输入的影响很大,另一方面,虽然此方法在较长输入下效果好,但计算资源增加。
因此使用更易实现、稳定高效、所需资源更少的max-pooing方法。
4.2.2 步态特征聚合
前提条件:认为步态特征主要代表每个人身体的静态和内部信息,因此,对于每个人来说,他们分解的步态特征被假定为随时间变化而保持不变,这也揭示了模型无需提取他们的时间变化信息。
a) first stage
使用特征内和跨帧的相关性来提高特征的有效性。
因为步态可以被认为是一个动态耦合的钟摆模型,而且所有的人体部位是以有规律的方式连接的,所以这种潜在的相关性是合理的。
在此模型中,两个统计函数首先在每个通道和他们相邻通道之间进行组合,为了提取更稳健的表征信息,引入通道注意力机制,重新权衡分解的步态特征。
f g a 1 = [ Avgpool1d ( f g ) , Maxpool1d ( f g ) ] f g l o g i t s 1 = Conv1dNet ( f g a 1 ) f g c h = f g × Sigmoid ( f g l o g i t s 1 ) ( 4 ) f_g^{a_1} = [\text{Avgpool1d}(f_g), \text{Maxpool1d}(f_g)]\\ f_g^{logits_1} = \text{Conv1dNet}(f_g^{a_1}) \\ f_g^{ch} = f_g \times \text{Sigmoid}(f_g^{logits_1}) \qquad(4) fga1=[Avgpool1d(fg),Maxpool1d(fg)]fglogits1=Conv1dNet(fga1)fgch=fg×Sigmoid(fglogits1)(4)
类似在不同标记间进行通信,此模型采用了一种通信机制来提高不同输入帧的特征鲁棒性。
(模型采用不同帧的相关性是合理的,因为在每个序列中,我们分解的步态特征可以始终保持稳定,从而减少离群值的出现)
f g a 2 = [ Avgpool1d ( f g c h ) , Maxpool1d ( f g c h ) ] f g l o g i t s 2 = Conv1dNet ( f g a 2 ) f g f r = f g c h × Sigmoid ( f g l o g i t s 2 ) ( 5 ) f_g^{a_2} = [\text{Avgpool1d}(f_g^{ch}), \text{Maxpool1d}(f_g^{ch})]\\ f_g^{logits_2} = \text{Conv1dNet}(f_g^{a_2}) \\ f_g^{fr} = f_g^{ch} \times \text{Sigmoid}(f_g^{logits_2}) \qquad(5) fga2=[Avgpool1d(fgch),Maxpool1d(fgch)]fglogits2=Conv1dNet(fga2)fgfr=fgch×Sigmoid(fglogits2)(5)
具体而言,第一阶段的操作有两部分,一部分是通道操作,旨在为每一帧的不同通道之间进行通信;另一部分是帧操作,旨在为每一通道的不同帧进行通信。总体而言,这两种操作对于每个序列都是结合在一起的,以实现跨空间和跨时间的交互。
b) second stage
采用max-pooling操作,将基于帧的改进步态特征映射为完整序列的特征,与前一小节的姿势特征聚合类似。
f ~ g = Maxpool ( f g f r ) ( 6 ) \tilde f_g = \text{Maxpool}(f_g^{fr}) \qquad(6) f~g=Maxpool(fgfr)(6)
4.2.3 外观特征聚合
分解的外观特征一般指人体的形状信息,与可以一直保持稳定的步态特征不同,这些特征受衣着变化影响显著,此模块目的是减少这种衣着变化引起的不利影响。受使用移位码来合成某一方向的图像的启发,此模型也采用移位码来减少服装变化造成的影响。与上一小节步态特征的分析类似,此部分的特征有效性也在每个特征内部和不同帧之间得到了提升。
首先,采用一种类似步态特征聚合的方法来把握特征中最突出的部分 f a c h f_a^{ch} fach,与步态特征 f g c h f_g^{ch} fgch不同, f a c h f_a^{ch} fach更关注的是每个人固有的不太信息,因此它们应该被排除在我们分解的外观特征之外,公式表示为: f ~ a c h = f a − α 1 ∗ f a c h ( 7 ) \tilde f_a^{ch} =f_a -\alpha_1 * f_a^{ch} \qquad(7) f~ach=fa−α1∗fach(7)
其中 α 1 \alpha_1 α1是一个可学习的移位码。
后续帧间特征改进使用移位码 α 2 \alpha_2 α2与其类似。
利用max-pooling操作将基于帧的外观特征转换为基于序列的外观特征。
4.2.4 相似度损失和分类损失
聚合步态特征基本上提取了人类步态独特的和固有的信息,因此对于每个人来说,他们的聚合步态特征被认为在不同的序列中具有相似性。同样,对于每组中共享相同ID和视角的序列,在以自我监督的方式削弱其衣着特性,聚合外观特征也应保持相似。
为了加强特征的效率和一致性,模型使用基于L1损失的相似性损失 l s i m l_{sim} lsim;
为了提高最终步态相关特征的有效性,使用Batch All(BA+)triplet loss作为分类损失 l i d l_{id} lid。
完整的训练损失计算公式为: l = l i d + λ s ∗ l s i m + λ r ∗ l r e c o n ( 8 ) l=l_{id}+\lambda_s *l_{sim}+\lambda_r * l_{recon} \qquad(8) l=lid+λs∗lsim+λr∗lrecon(8)
5.实验过程及结果
5.1 训练及测试细节
网络提出了一个不平衡的编码-解码框架。
编码器 E \mathcal E E与GaitSet模型相似,由三个卷积单元、一个Batch Normalization和一个Leaky RuLU层组成;解码器 D \mathcal D D与GaitNet模型相同,由三个连续的步长为2的转置卷积、Batch Normalization和一个Leaky RuLU层组成;顶部利用一个Sigmoid函数,将数值固定在 [ 0 , 1 ] [0,1] [0,1]的范围内,并作为输入序列;此外,分解姿势、步态、外观和视角特征根据经验分别设置为512、256、256和1维向量。
在训练阶段,每个输入是一组四个剪影序列,每个序列是由10个随机抽样的剪影帧建立的,大小为 64 × 64 64 \times 64 64×64,每次训练抽取大小为 8 × 8 8 \times 8 8×8,即每个人和每个人的组数都是8;优化器使用Adam,其学习率设定为0.0001;对于 l i d l_{id} lid BA+三元组损失函数的阈值设为0.2;此外,在公式(8)中的 λ s \lambda_s λs和 λ r \lambda_r λr设为1。
在测试阶段,batch大小设置为1,输入的是整个剪影序列,而不是随机抽样的剪影帧。
5.2 实验结果
5.2.1 CASIA-B数据集
a) 平均Rank-1准确率
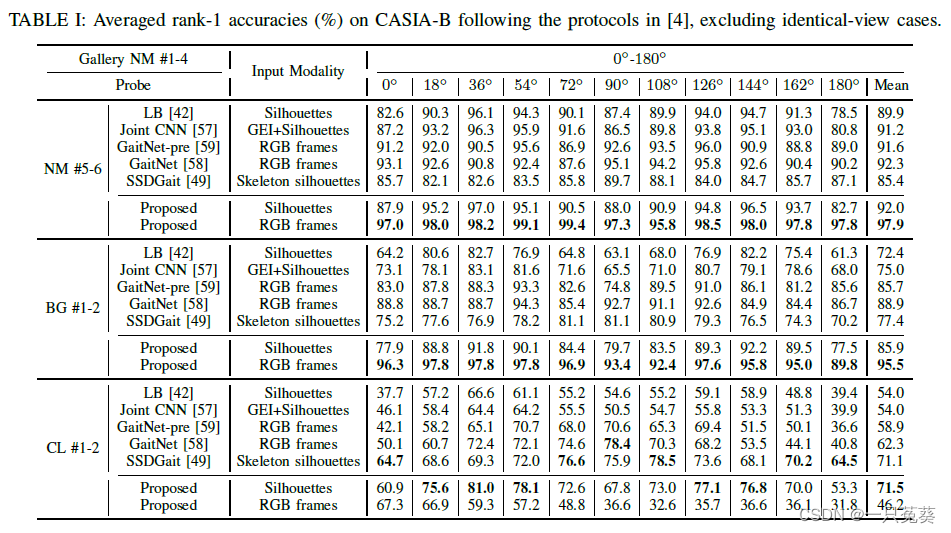
表中给出了这一模型的两种数据输入方法:RGB和剪影输入。
可以看到RGB帧在NM-NM和NM-BG实验条件下表现能够达到最佳(剪影输入的结果也不错),与剪影输入相比,RGB数据可以提供更丰富的信息,从而为提取更多与步态相关的特征提供更大的可能性。但是在NM-CL实验条件下,剪影输入获得了更高的识别精度,潜在原因可能是:在NM-CL实例中,剪影与人的形状更相关,RGB更关注的纹理外观则不那么重要了。
此外,本方法在检测视角为90°左右时,性能严重下降,原因之一是步态特征在0~90° 的正面视图和90~180° 的背面视图是不同的(临界点特征不好区分);另一个原因是,在本方法中没有采用视角转换。
b) Gaitganv2协议下的probe-gallery比较
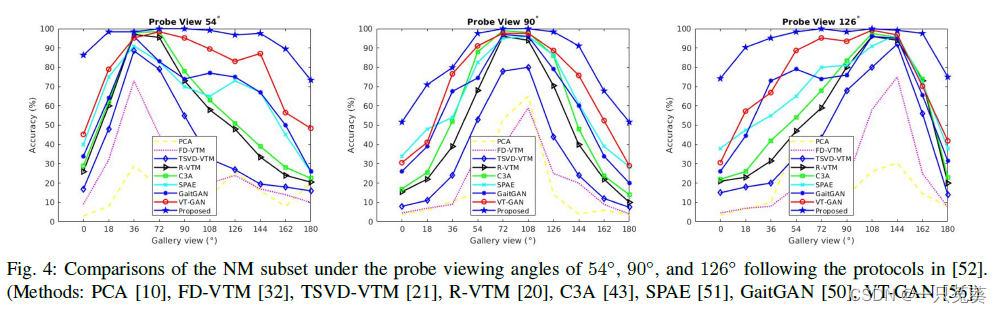
在probe-gallery测试中,根据Fig.4可以看出识别效果较其他方法还是比较显著的。(这里作者只给出了54°、90°和126°的情况,其他角度条件的实验结果咱们不好说……)
c) CASIA-B的NM下Rank-1准确率
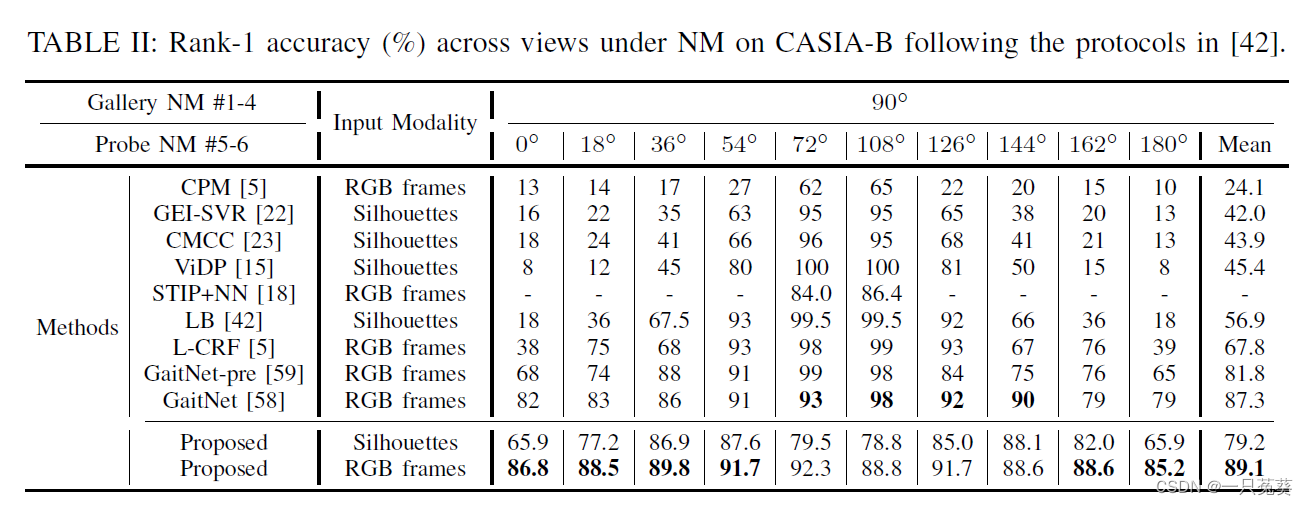
侧重行走方向变化的训练测试,同样取得了最高的平均准确率。
d) BG和CL子集下各视角的Rank-1准确率
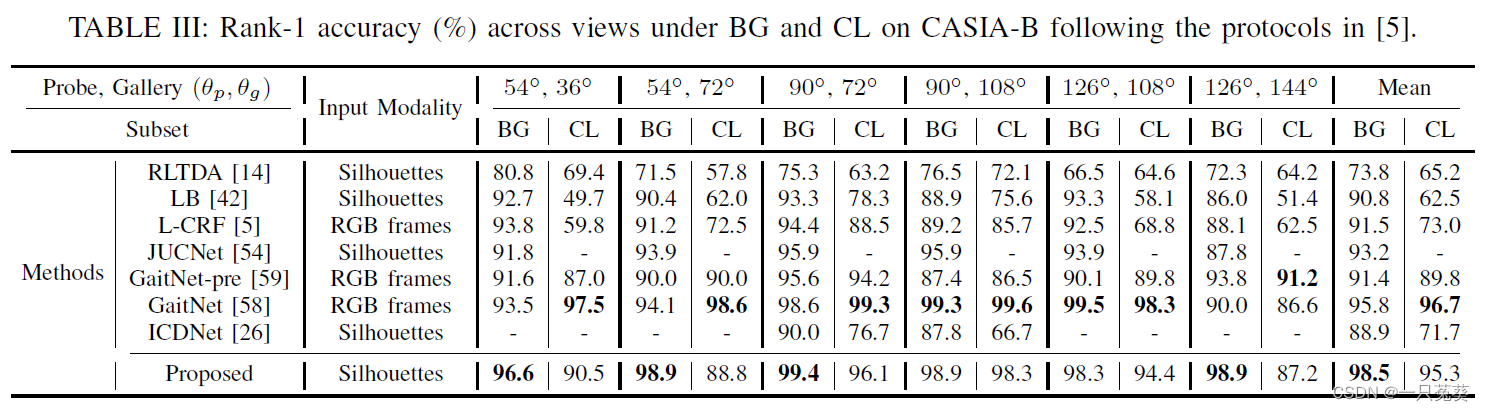
在BG子集上能够达到最高平均精度;对于CL子集,同样显示了与GaitNet-pre和GaitNet相当的性能。
在上述评估准则下,本方法都能够表现出较为突出的步态识别性能,在许多情况下超过了最先进的方法,由此表明在不同变化下为步态识别提取稳健的分解表示的有效性。
5.2.2 OU-ISIR数据集
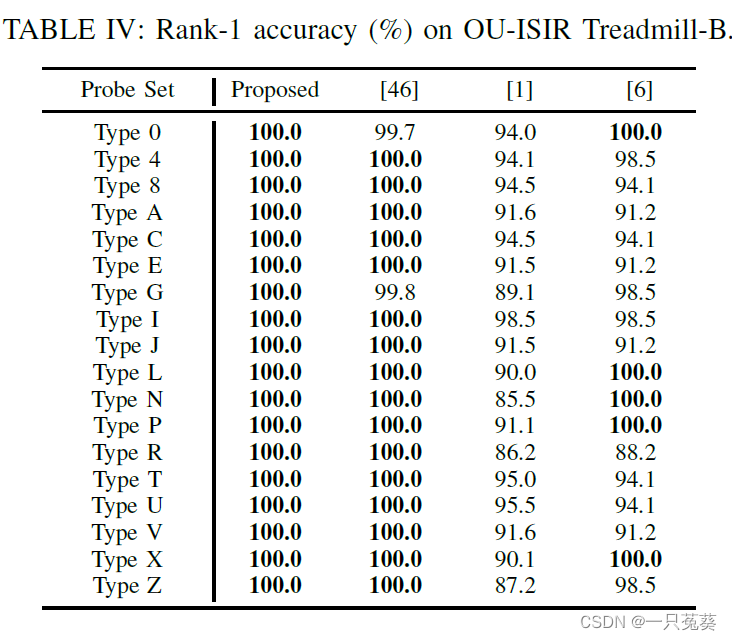
OU-ISIR-B数据集不包含视角变化,因此实验时忽略视角特征,只有姿势、步态和外观特征从每个输入序列中被提取分解。
根据表格显示的比较数据可以看出本方法对于衣着变化具有更强的鲁棒性,一旦一个服装组合存在于训练集中,那么它肯定会在评估过程中被识别。
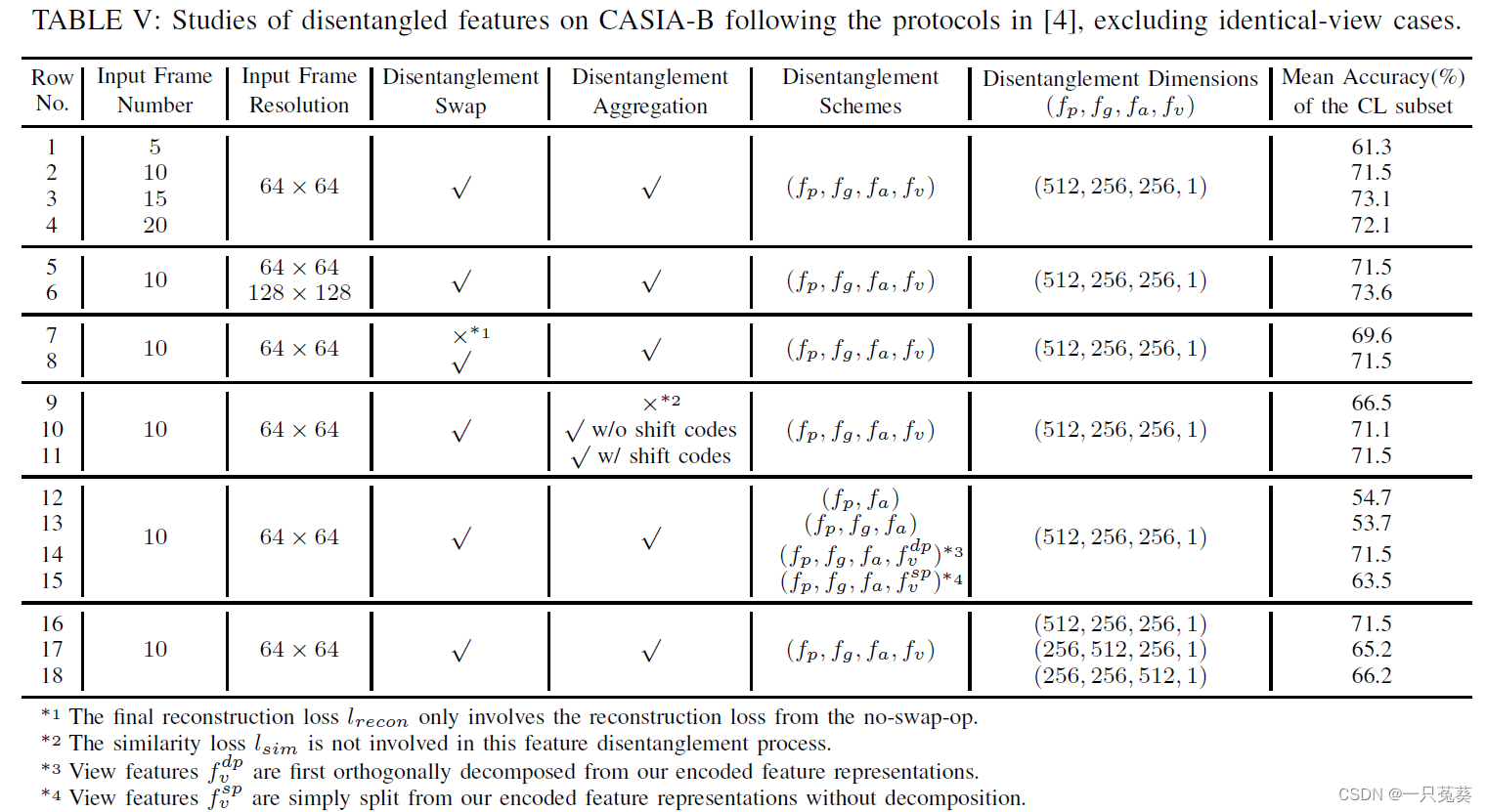
5.3 CAISA-B数据集上的消融实验
6.总结
步态识别明显受到各种因素的影响,如观察角度、衣着变化等因素。因此,本文提出了一种分组监督的DRL方法,以掌握对这些因素不变的特征。
首先,通过一个编码器-解码器框架将每个序列明确地分解为姿势、步态、外观和视图特征。为了确保特征的适应性和独立性,特别利用了一个分解交换模块,根据特征属性进行了一系列的交换操作。此外,为了提高特征的实用性和有效性,还在特征分解后专门使用了分解聚合模块。最后,聚合的姿势、步态和外观特征被串联起来用于步态识别。
使用相关数据集进行的实验,验证了该方法比其他DRL步态识别方法能取得更突出的效果。